

Anfang April veröffentlichte Meta das erste grundlegende Bildsegmentierungsmodell in der Geschichte – SAM (Segment Anything Model) [1]. Als Segmentierungsmodell verfügt SAM über leistungsstarke Funktionen und ist sehr benutzerfreundlich. Wenn der Benutzer beispielsweise einfach auf das entsprechende Objekt klickt, wird das Objekt sofort segmentiert und das Segmentierungsergebnis ist sehr genau. Mit Stand vom 15. April hat das GitHub-Repository von SAM eine Sternanzahl von 26.000.

Es ist entscheidend, wie man ein so leistungsstarkes „Alles aufteilen“-Modell sinnvoll nutzen und auf Anwendungsszenarien mit praktischerem Bedarf erweitern kann. Welche Funken werden beispielsweise entstehen, wenn SAM auf praktische Bildinpainting-Aufgaben (Image Inpainting) trifft?
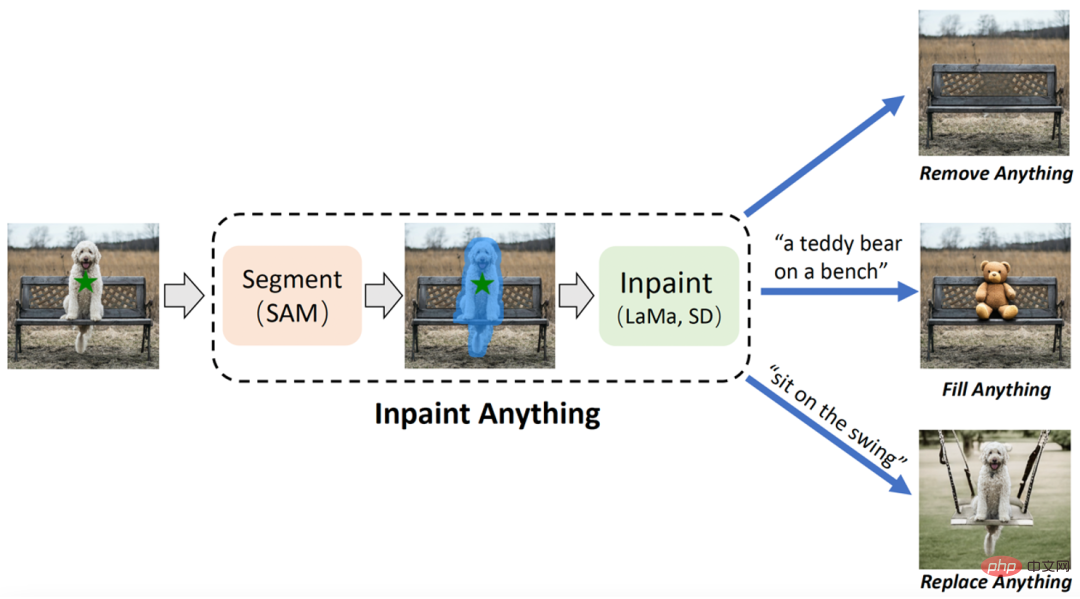
Das Forschungsteam der University of Science and Technology of China und des Eastern Institute of Technology gab eine verblüffende Antwort. Basierend auf SAM schlugen sie das Modell „Inpaint Anything“ (IA) vor. Im Gegensatz zum herkömmlichen Bildreparaturmodell erfordert das IA-Modell keine detaillierten Vorgänge zum Generieren von Masken und unterstützt das Markieren ausgewählter Objekte mit einem Klick. IA kann alles entfernen (Remove Anything), alles füllen (Fill Anything), alles ersetzen deckt eine Vielzahl typischer Bildreparatur-Anwendungsszenarien ab, einschließlich Zielentfernung, Zielfüllung, Hintergrundersetzung usw.
...

. IA hat drei Hauptfunktionen: (i) Alles entfernen: Benutzer müssen nur auf das Objekt klicken, das sie entfernen möchten, und IA entfernt das Objekt, ohne eine Spur zu hinterlassen, wodurch eine effiziente „magische Beseitigung“ erreicht wird; Alles ausfüllen: Gleichzeitig kann der Benutzer IA über eine Textaufforderung (Textaufforderung) weiter mitteilen, was er in das Objekt füllen möchte, und IA steuert dann das eingebettete AIGC-Modell (AI-Generated Content) (z. B. Stable Diffusion). [2]) generiert entsprechende inhaltsgefüllte Objekte, um nach Belieben eine „Inhaltserstellung“ zu erreichen; (iii) Alles ersetzen: Der Benutzer kann auch klicken, um die Objekte auszuwählen, die beibehalten werden müssen, und Textaufforderungen verwenden, um IA mitzuteilen, was er möchte Sie können den Hintergrund des Objekts durch den angegebenen Inhalt ersetzen, um eine lebendige „Umwelttransformation“ zu erzielen. Der Gesamtrahmen von IA ist in der folgenden Abbildung dargestellt: Inpaint Anything (IA)-Diagramm. Benutzer können jedes Objekt im Bild auswählen, indem sie darauf klicken. Mithilfe leistungsstarker Bildverarbeitungsmodelle wie SAM [1], LaMa [3] und Stable Diffusion (SD) [3] ist IA in der Lage, ausgewählte Objekte reibungslos zu entfernen (d. h. „Alles entfernen“). Darüber hinaus kann der Benutzer durch die Eingabe von Textaufforderungen in IA das Objekt mit jedem gewünschten Inhalt füllen (d. h. „Fill Anything“) oder das Objekt des Objekts willkürlich ersetzen (d. h. „Replace Anything“).
Alles entfernen

Schematische Darstellung von „Alles entfernen“
Die Schritte für „Alles entfernen“ sind wie folgt:
Fill Anything

Fill Anything-Diagramm, die im Bild verwendete Textaufforderung: ein Teddybär auf einer Bank
„Alles ausfüllen“ Die Schritte sind wie folgt:
Alles ersetzen
Alles ersetzen-Diagramm, die im Bild verwendete Textaufforderung: ein Mann im Büro
Die Schritte „Alles ausfüllen“ lauten wie folgt:
Alle Versuchsergebnisse entfernen


Alle Versuchsergebnisse ausfüllen

Textaufforderung: ein Kameraobjektiv in der Hand

Textaufforderung: ein Flugzeugträger auf dem Meer
Textaufforderung: ein Picasso-Gemälde an der Wand

Ersetzen Sie alle experimentellen Ergebnisse

Texteingabe: Auf der Schaukel sitzen
Texteingabe: Frühstück

Texteingabe: ein Bus, mitten auf einer Landstraße, Sommer

Textaufforderung: Kreuzung in der Stadt
Zusammenfassung
Die Forscher haben auf diese Weise ein interessantes Projekt entwickelt, um die Leistungsfähigkeit der Nutzung bestehender groß angelegter Modelle der künstlichen Intelligenz zu demonstrieren und das unbegrenzte Potenzial der „zusammensetzbaren KI“ aufzudecken. . Das vom Projekt vorgeschlagene Inpaint Anything (IA) ist ein multifunktionales Bildreparatursystem, das Objektentfernung, Inhaltsfüllung, Szenenersetzung und andere Funktionen integriert (weitere Funktionen sind in Vorbereitung, also bleiben Sie dran). IA kombiniert grundlegende visuelle Modelle wie SAM, Bildreparaturmodelle (wie LaMa) und AIGC-Modelle (wie Stable Diffusion), um eine benutzerfreundliche maskenlose Bildreparatur zu erreichen, und unterstützt gleichzeitig „Zum Löschen klicken, Füllen auffordern“ und andere humanisierte Operationen im „Narrenstil“. Darüber hinaus kann IA Bilder mit beliebigen Seitenverhältnissen und 2K-HD-Auflösung verarbeiten, unabhängig vom ursprünglichen Bildinhalt.

Projekt vollständig Open Source. Schließlich ist jeder willkommen, Inpaint Anything (IA) zu teilen und zu fördern, und ich freue mich darauf, weitere neue Projekte zu sehen, die auf IA basieren. In Zukunft werden Forscher das Potenzial von Inpaint Anything (IA) weiter erforschen, um praktischere neue Funktionen wie feinkörniges Ausschneiden, Bearbeiten usw. von Bildern zu unterstützen und es auf realere Anwendungen anzuwenden.
Das obige ist der detaillierte Inhalt vonWenn „Alles teilen' auf Bildreparatur trifft: Keine Feinmarkierung erforderlich, klicken Sie auf das Objekt, um das Objekt zu entfernen, den Inhalt zu füllen und die Szene zu ersetzen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



