
 Technologie-Peripheriegeräte
KI
Die University of Wisconsin-Madison und andere haben gemeinsam einen Artikel veröffentlicht! Das neueste multimodale große Modell LLaVA wird veröffentlicht und sein Niveau liegt nahe an GPT-4
Technologie-Peripheriegeräte
KI
Die University of Wisconsin-Madison und andere haben gemeinsam einen Artikel veröffentlicht! Das neueste multimodale große Modell LLaVA wird veröffentlicht und sein Niveau liegt nahe an GPT-4
Die University of Wisconsin-Madison und andere haben gemeinsam einen Artikel veröffentlicht! Das neueste multimodale große Modell LLaVA wird veröffentlicht und sein Niveau liegt nahe an GPT-4

Die Feinabstimmung visueller Befehle ist beliebt.
Dieses Papier heißt Visual Instruction Tuning und wird gemeinsam von der University of Wisconsin-Madison, Microsoft Research und der Columbia University erstellt.
Zu den Autoren gehören Haotian Liu, Chunyuan Li, Qingyang Wu und Yong Jae Lee.

Gleichzeitig stellten die Forscher ihren Code auch als Open Source auf GitHub zur Verfügung , Modelle und Datensätze. Das Papier ist auch auf Arxiv veröffentlicht.
Erklärung
Was genau ist also die Funktion von LLaVA? Wenn man sich mit dem Papier befasst, könnte es für diejenigen, die damit nicht vertraut sind, etwas seltsam wirken.
Schauen wir uns zunächst an, was LLaVA selbst sagt.
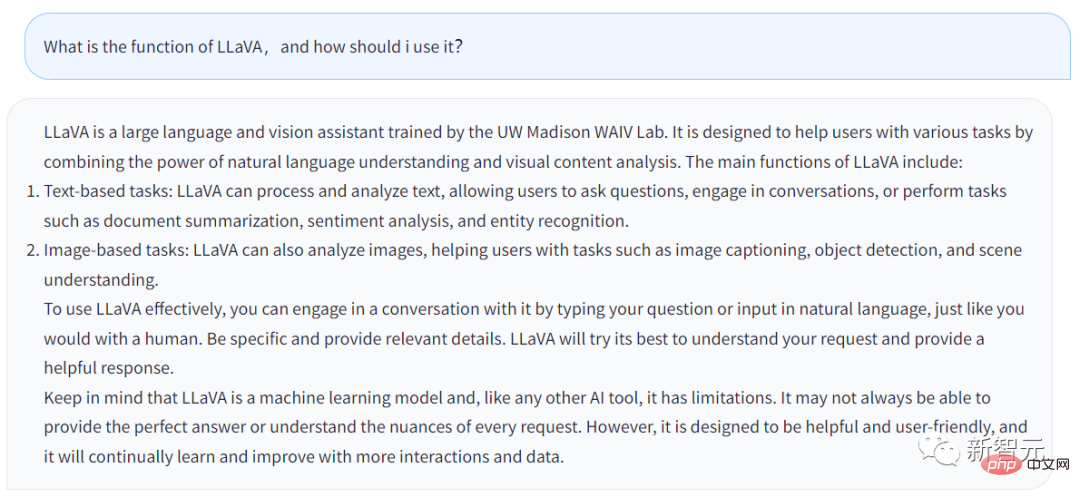
Die obige Antwort wird vom Chatbot von LLaVA generiert , Welche Funktion hat LLaVA und wie können Nutzer davon profitieren?
Die Antwort lautet wie folgt:
LLaVA ist ein großer Sprach- und visueller Assistent an der UW Madison WAIV Lab-Schulung erhalten. LLaVA soll Benutzern bei der Bewältigung verschiedener Aufgaben helfen, indem es seine Fähigkeiten zum Verstehen natürlicher Sprache und zur Analyse visueller Inhalte nutzt.
Zu den Hauptfunktionen von LLaVA gehören: Grundlegende Aufgaben: LLaVA kann Text verarbeiten und analysieren, Benutzern das Stellen von Fragen ermöglichen, LLaVA kann mit Benutzern sprechen oder von Benutzern eingegebene Aufgaben erledigen, wie die Verfeinerung von Dokumentzusammenfassungen, Stimmungsanalysen, Entitätserkennung usw.
· Bildbasierte Aufgaben: LLaVA kann Bilder analysieren, Bilder beschreiben, Objekterkennung durchführen sowie Szenen analysieren und verstehen.
Wenn Benutzer LLaVA besser anwenden möchten, können sie direkt mit LLaVA sprechen, genau wie mit Menschen. Geben Sie so viele Details wie möglich an und LLaVA wird eine vollständigere Antwort generieren.
Gleichzeitig sollten Sie bedenken, dass LLaVA schließlich ein Modell für maschinelles Lernen und ein KI-Tool ist. Solange es ein Werkzeug ist, hat es seine Grenzen. LLaVA beantwortet die vom Benutzer eingegebenen Fragen möglicherweise nicht jedes Mal perfekt.Natürlich lernt und verbessert sich LLaVA ständig und seine Funktionen werden immer leistungsfähiger.
Generell lässt sich aus der Antwort von LLaVA erkennen, dass sich die Funktionen von Chatbot nicht wesentlich von denen von GPT unterscheiden. Aber LLaVA kann einige Aufgaben im Zusammenhang mit Bildern erledigen. Die Forscher haben die technischen Details von LLaVA in ihrem Arxiv-Artikel detailliert beschrieben.
Es ist wichtig zu wissen, dass die Verwendung maschinengenerierter Anweisungen zur Verfolgung von Daten zur Feinabstimmung von Anweisungen für große Sprachmodelle (LLMs) die Nullpunktfähigkeit neuer Modelle verbessert Aufgaben, aber diese Idee ist im Multimodus begrenzt. Der dynamische Bereich ist weniger erforscht.
In der Arbeit versuchten die Forscher zunächst, das rein sprachbasierte GPT-4 zu verwenden, um Befehlsfolgedaten für multimodale Sprachbilder zu generieren.
Durch Konditionierung von Anweisungen auf diesen generierten Daten stellten die Forscher LLaVA vor: einen groß angelegten Sprach- und visuellen Assistenten, der durchgängig trainiert wird. Ein großes multimodales Modell, das verbindet einen visuellen Encoder und LLM für allgemeines Sehen und Sprachverständnis.
Frühe Experimente zeigen, dass LLaVA beeindruckende multimodale Chat-Fähigkeiten demonstriert, manchmal multimodale GPT-4-Leistung auf unsichtbaren Bildern/Anweisungen ausgibt und synthetische multimodale Anweisungen befolgt. Im Vergleich zu GPT-4 im Datensatz erreichte es eine relativer Wert von 85,1 %.
Bei der Feinabstimmung für das Science-Magazin erreichte die Synergie von LLaVA und GPT-4 eine neue, hochmoderne Genauigkeit von 92,53 %.
Forscher haben die von GPT-4 generierten Daten, Modelle und Codebasis für visuelle Befehlsanpassungen offengelegt.
Multimodales Modell
Klären Sie zunächst die Definition.
Groß angelegtes multimodales Modell bezieht sich auf ein Modell, das auf maschineller Lerntechnologie basiert und mehrere Eingabetypen wie Text und Bilder verarbeiten und analysieren kann.
Diese Modelle sind für ein breiteres Aufgabenspektrum konzipiert und in der Lage, verschiedene Datenformen zu verstehen. Durch die Verwendung von Text und Bildern als Eingabe verbessern diese Modelle ihre Fähigkeit, Erklärungen zu verstehen und zusammenzustellen, um genauere und relevantere Antworten zu generieren.
Menschen interagieren mit der Welt über mehrere Kanäle wie Vision und Sprache, da jeder einzelne Kanal einzigartige Vorteile bei der Darstellung und Vermittlung bestimmter Weltkonzepte hat und so zu einem besseren Verständnis der Welt beiträgt.
Eines der Kernziele der künstlichen Intelligenz ist die Entwicklung eines universellen Assistenten, der multimodalen visuellen und sprachlichen Anweisungen im Einklang mit menschlichen Absichten effektiv folgen und eine Vielzahl realer Aufgaben erledigen kann.
Infolgedessen verzeichnet die Entwicklergemeinschaft ein erneutes Interesse an der Entwicklung sprachgestützter grundlegender Visionsmodelle mit leistungsstarken Funktionen für das visuelle Verständnis in der offenen Welt, wie Klassifizierung, Erkennung, Segmentierung, Beschreibung sowie Visionsgenerierung und -bearbeitung.
Bei diesen Funktionen wird jede Aufgabe unabhängig von einem einzigen großen visuellen Modell gelöst, wobei die Aufgabenanweisungen implizit im Modelldesign berücksichtigt werden.
Darüber hinaus wird Sprache nur zur Beschreibung des Bildinhalts verwendet. Dadurch kann die Sprache eine wichtige Rolle bei der Zuordnung visueller Signale zur sprachlichen Semantik spielen – einem gemeinsamen Kanal für die menschliche Kommunikation. Dies führt jedoch dazu, dass Modelle häufig über feste Schnittstellen mit eingeschränkter Interaktivität und Anpassungsfähigkeit an Benutzeranweisungen verfügen.
Und große Sprachmodelle (LLM) zeigen, dass Sprache eine umfassendere Rolle spielen kann: Eine gemeinsame Schnittstelle für einen universellen Assistenten, verschiedene Aufgabenanweisungen können explizit in der Sprache ausgedrückt werden und den durchgängig trainierten neuronalen Assistenten beim Umschalten leiten zur interessierenden Aufgabe und lösen Sie sie.
Zum Beispiel hat der jüngste Erfolg von ChatGPT und GPT-4 die Fähigkeit dieses LLM bewiesen, menschlichen Anweisungen zu folgen, und großes Interesse an der Entwicklung von Open-Source-LLM geweckt.
LLaMA ist ein Open-Source-LLM, dessen Leistung GPT-3 entspricht. Die laufende Arbeit nutzt verschiedene maschinengenerierte, qualitativ hochwertige Anleitungsfolgebeispiele, um die Ausrichtungsfähigkeiten von LLM zu verbessern und berichtet über eine beeindruckende Leistung im Vergleich zu proprietären LLMs. Wichtig ist, dass dieser Arbeitsbereich nur aus Text besteht.
In diesem Artikel schlagen Forscher eine visuelle Befehlsabstimmung vor, die den ersten Versuch darstellt, die Befehlsabstimmung auf einen multimodalen Raum auszudehnen und den Weg für die Entwicklung eines universellen visuellen Assistenten zu ebnen. Zu den Hauptinhalten des Papiers gehören insbesondere:
Multimodale Anweisungsfolgedaten. Eine zentrale Herausforderung ist das Fehlen visueller Anweisungen zur Verfolgung der Daten. Wir stellen eine Datenreformperspektive und -pipeline vor, die ChatGPT/GPT-4 verwendet, um Bild-Text-Paare in geeignete Befehlsfolgenformate zu konvertieren.
Großes multimodales Modell. Die Forscher entwickelten ein großes multimodales Modell (LMM), indem sie den Open-Set-Visual-Encoder und den Sprachdecoder LaMA von CLIP verbanden und sie durchgängig anhand der generierten visuell-verbalen Lehrdaten verfeinerten. Empirische Studien verifizieren die Wirksamkeit der LMM-Anweisungsoptimierung anhand generierter Daten und liefern praktische Vorschläge für den Aufbau eines allgemeinen visuellen Agenten zur Befehlsfolge. Mit GPT 4 erreichte das Forschungsteam Spitzenleistungen beim multimodalen Inferenzdatensatz Science QA.
Open Source. Das Forschungsteam stellte der Öffentlichkeit Folgendes zur Verfügung: die generierten multimodalen Befehlsdaten, eine Codebibliothek für die Datengenerierung und das Modelltraining, Modellkontrollpunkte und eine visuelle Chat-Demonstration.
Ergebnisanzeige

Wie Sie sehen, kann LLaVA mit allen Arten von Problemen umgehen , und Die generierten Antworten sind sowohl umfassend als auch logisch.
LLaVA demonstriert einige multimodale Fähigkeiten, die dem Niveau von GPT-4 nahekommen, mit einem relativen GPT-4-Score von 85 % in Bezug auf visuellen Chat.
In Bezug auf die Argumentation von Frage und Antwort erreichte LLaVA sogar den neuen SoTA-92,53 % und besiegte damit die multimodale Denkkette.
Das obige ist der detaillierte Inhalt vonDie University of Wisconsin-Madison und andere haben gemeinsam einen Artikel veröffentlicht! Das neueste multimodale große Modell LLaVA wird veröffentlicht und sein Niveau liegt nahe an GPT-4. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Das Vollbild-Popup von Microsoft fordert Benutzer von Windows 10 auf, sich zu beeilen und auf Windows 11 zu aktualisieren
Jun 06, 2024 am 11:35 AM
Das Vollbild-Popup von Microsoft fordert Benutzer von Windows 10 auf, sich zu beeilen und auf Windows 11 zu aktualisieren
Jun 06, 2024 am 11:35 AM
Laut Nachrichten vom 3. Juni sendet Microsoft aktiv Vollbildbenachrichtigungen an alle Windows 10-Benutzer, um sie zu einem Upgrade auf das Betriebssystem Windows 11 zu ermutigen. Dabei handelt es sich um Geräte, deren Hardwarekonfigurationen das neue System nicht unterstützen. Seit 2015 hat Windows 10 fast 70 % des Marktanteils eingenommen und seine Dominanz als Windows-Betriebssystem fest etabliert. Der Marktanteil liegt jedoch weit über dem Marktanteil von 82 %, und der Marktanteil übersteigt den von Windows 11, das 2021 erscheinen wird, bei weitem. Obwohl Windows 11 seit fast drei Jahren auf dem Markt ist, ist die Marktdurchdringung immer noch langsam. Microsoft hat angekündigt, den technischen Support für Windows 10 nach dem 14. Oktober 2025 einzustellen, um sich stärker darauf zu konzentrieren
 Microsoft veröffentlicht das kumulative August-Update für Win11: Verbesserung der Sicherheit, Optimierung des Sperrbildschirms usw.
Aug 14, 2024 am 10:39 AM
Microsoft veröffentlicht das kumulative August-Update für Win11: Verbesserung der Sicherheit, Optimierung des Sperrbildschirms usw.
Aug 14, 2024 am 10:39 AM
Laut Nachrichten dieser Website vom 14. August veröffentlichte Microsoft während des heutigen August-Patch-Dienstags kumulative Updates für Windows 11-Systeme, darunter das Update KB5041585 für 22H2 und 23H2 sowie das Update KB5041592 für 21H2. Nachdem das oben genannte Gerät mit dem kumulativen Update vom August installiert wurde, sind die mit dieser Site verbundenen Versionsnummernänderungen wie folgt: Nach der Installation des 21H2-Geräts wurde die Versionsnummer auf Build22000.314722H2 erhöht. Die Versionsnummer wurde auf Build22621.403723H2 erhöht. Nach der Installation des Geräts wurde die Versionsnummer auf Build22631.4037 erhöht. Die Hauptinhalte des KB5041585-Updates für Windows 1121H2 sind wie folgt: Verbesserung: Verbessert
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an. Diese innovative Errungenschaft erzielte einen bedeutenden Durchbruch bei Codegenerierungsaufgaben, übertraf erfolgreich CodeLlama-70B-Instruct und erreichte die Spitze der Codegenerierungsleistungsliste. Die Einzigartigkeit von StarCoder2-15B-Instruct liegt in seiner reinen Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar. Das Modell generiert über StarCoder2-15B Tausende von Anweisungen als Reaktion auf die Feinabstimmung des StarCoder-15B-Basismodells, ohne auf teure manuelle Annotationen angewiesen zu sein.
 Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Um große Sprachmodelle (LLMs) an menschlichen Werten und Absichten auszurichten, ist es wichtig, menschliches Feedback zu lernen, um sicherzustellen, dass sie nützlich, ehrlich und harmlos sind. Im Hinblick auf die Ausrichtung von LLM ist Reinforcement Learning basierend auf menschlichem Feedback (RLHF) eine wirksame Methode. Obwohl die Ergebnisse der RLHF-Methode ausgezeichnet sind, gibt es einige Herausforderungen bei der Optimierung. Dazu gehört das Training eines Belohnungsmodells und die anschließende Optimierung eines Richtlinienmodells, um diese Belohnung zu maximieren. Kürzlich haben einige Forscher einfachere Offline-Algorithmen untersucht, darunter die direkte Präferenzoptimierung (Direct Preference Optimization, DPO). DPO lernt das Richtlinienmodell direkt auf der Grundlage von Präferenzdaten, indem es die Belohnungsfunktion in RLHF parametrisiert, wodurch die Notwendigkeit eines expliziten Belohnungsmodells entfällt. Diese Methode ist einfach und stabil
 Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
1. Einleitung In den letzten Jahren haben sich YOLOs aufgrund ihres effektiven Gleichgewichts zwischen Rechenkosten und Erkennungsleistung zum vorherrschenden Paradigma im Bereich der Echtzeit-Objekterkennung entwickelt. Forscher haben das Architekturdesign, die Optimierungsziele, Datenerweiterungsstrategien usw. von YOLO untersucht und erhebliche Fortschritte erzielt. Gleichzeitig behindert die Verwendung von Non-Maximum Suppression (NMS) bei der Nachbearbeitung die End-to-End-Bereitstellung von YOLO und wirkt sich negativ auf die Inferenzlatenz aus. In YOLOs fehlt dem Design verschiedener Komponenten eine umfassende und gründliche Prüfung, was zu erheblicher Rechenredundanz führt und die Fähigkeiten des Modells einschränkt. Es bietet eine suboptimale Effizienz und ein relativ großes Potenzial zur Leistungsverbesserung. Ziel dieser Arbeit ist es, die Leistungseffizienzgrenze von YOLO sowohl in der Nachbearbeitung als auch in der Modellarchitektur weiter zu verbessern. zu diesem Zweck
