

Visualisierung von Clustern mithilfe von Dendrogrammen

Im Allgemeinen verwenden wir Streudiagramme für die Cluster-Visualisierung, aber Streudiagramme sind für die Visualisierung einiger Cluster-Algorithmen nicht ideal. Daher stellen wir in diesem Artikel vor, wie man Dendrogramme (Dendrogramme) verwendet, um unsere Cluster-Ergebnisse zu visualisieren.
Dendogramm
Ein Dendrogramm ist ein Diagramm, das hierarchische Beziehungen zwischen Objekten, Gruppen oder Variablen zeigt. Ein Dendrogramm besteht aus Zweigen, die an Knoten oder Clustern verbunden sind und Gruppen von Beobachtungen mit ähnlichen Merkmalen darstellen. Die Höhe eines Astes oder der Abstand zwischen den Knoten gibt an, wie unterschiedlich oder ähnlich die Gruppen sind. Das heißt, je länger die Zweige oder je größer der Abstand zwischen den Knoten, desto weniger ähnlich sind die Gruppen. Je kürzer die Zweige oder je geringer der Abstand zwischen den Knoten, desto ähnlicher sind die Gruppen.
Dendogramme eignen sich zur Visualisierung komplexer Datenstrukturen und zur Identifizierung von Untergruppen oder Datenclustern mit ähnlichen Merkmalen. Sie werden häufig in der Biologie, Genetik, Ökologie, Sozialwissenschaften und anderen Bereichen verwendet, in denen Daten basierend auf Ähnlichkeit oder Korrelation gruppiert werden können.
Hintergrundwissen:
Das Wort „Dendrogramm“ kommt von den griechischen Wörtern „dendron“ (Baum) und „gramma“ (Zeichnung). Im Jahr 1901 verwendete der britische Mathematiker und Statistiker Karl Pearson Baumdiagramme, um die Beziehungen zwischen verschiedenen Pflanzenarten darzustellen. Er nannte dieses Diagramm ein „Clusterdiagramm“. Dies kann als die erste Verwendung von Dendrogrammen angesehen werden.
Datenaufbereitung
Wir werden die realen Aktienkurse mehrerer Unternehmen für die Clusterbildung nutzen. Für einen einfachen Zugriff werden die Daten mithilfe der kostenlosen API von Alpha Vantage erfasst. Alpha Vantage bietet sowohl eine kostenlose API als auch eine Premium-API. Für den Zugriff über die API ist ein Schlüssel erforderlich. Weitere Informationen finden Sie auf seiner Website.
import pandas as pd
import requests
companies={'Apple':'AAPL','Amazon':'AMZN','Facebook':'META','Tesla':'TSLA','Alphabet (Google)':'GOOGL','Shell':'SHEL','Suncor Energy':'SU',
'Exxon Mobil Corp':'XOM','Lululemon':'LULU','Walmart':'WMT','Carters':'CRI','Childrens Place':'PLCE','TJX Companies':'TJX',
'Victorias Secret':'VSCO','MACYs':'M','Wayfair':'W','Dollar Tree':'DLTR','CVS Caremark':'CVS','Walgreen':'WBA','Curaleaf':'CURLF'}20 ausgewählte Unternehmen aus den Bereichen Technologie, Einzelhandel, Öl und Gas und anderen Branchen.
import time
all_data={}
for key,value in companies.items():
# Replace YOUR_API_KEY with your Alpha Vantage API key
url = f'https://www.alphavantage.co/query?function=TIME_SERIES_DAILY_ADJUSTED&symbol={value}&apikey=<YOUR_API_KEY>&outputsize=full'
response = requests.get(url)
data = response.json()
time.sleep(15)
if 'Time Series (Daily)' in data and data['Time Series (Daily)']:
df = pd.DataFrame.from_dict(data['Time Series (Daily)'], orient='index')
print(f'Received data for {key}')
else:
print("Time series data is empty or not available.")
df.rename(columns = {'1. open':key}, inplace = True)
all_data[key]=df[key]Der obige Code legt eine Pause von 15 Sekunden zwischen API-Aufrufen fest, um sicherzustellen, dass er nicht zu häufig blockiert wird.
# find common dates among all data frames common_dates = None for df_key, df in all_data.items(): if common_dates is None: common_dates = set(df.index) else: common_dates = common_dates.intersection(df.index) common_dates = sorted(list(common_dates)) # create new data frame with common dates as index df_combined = pd.DataFrame(index=common_dates) # reindex each data frame with common dates and concatenate horizontally for df_key, df in all_data.items(): df_combined = pd.concat([df_combined, df.reindex(common_dates)], axis=1)
Integrieren Sie die oben genannten Daten in den von uns benötigten DF, der direkt unten verwendet werden kann
Hierarchisches Clustering
Hierarchisches Clustering ist ein Clustering-Algorithmus, der für maschinelles Lernen und Datenanalyse verwendet wird. Es verwendet eine Hierarchie verschachtelter Cluster, um ähnliche Objekte basierend auf ihrer Ähnlichkeit in Clustern zu gruppieren. Der Algorithmus kann entweder agglomerativ sein, also mit einzelnen Objekten beginnen und diese zu Clustern zusammenführen, oder divisiv, also mit einem großen Cluster beginnen und ihn rekursiv in kleinere Cluster aufteilen.
Es ist zu beachten, dass nicht alle Clustering-Methoden hierarchische Clustering-Methoden sind und Dendrogramme nur für einige wenige Clustering-Algorithmen verwendet werden können.
Clustering-Algorithmus Wir werden hierarchisches Clustering verwenden, das im Scipy-Modul bereitgestellt wird. 1. Top-Down-Clustering Anzahl der Farben. Die optimale Anzahl an Clustern ist um eins kleiner als die Anzahl an Farben. Gemäß dem Dendrogramm oben beträgt die optimale Anzahl von Clustern also zwei.
Eine weitere Möglichkeit, die optimale Anzahl von Clustern zu ermitteln, besteht darin, Punkte zu identifizieren, an denen sich der Abstand zwischen Clustern plötzlich ändert. Dies wird als „Wendepunkt“ oder „Ellenbogenpunkt“ bezeichnet und kann verwendet werden, um die Anzahl der Cluster zu bestimmen, die die Variation in den Daten am besten erfasst. In der obigen Abbildung können wir sehen, dass die maximale Abstandsänderung zwischen einer unterschiedlichen Anzahl von Clustern zwischen 1 und 2 Clustern auftritt. Auch hier beträgt die optimale Anzahl von Clustern zwei.
Erhalten Sie eine beliebige Anzahl von Clustern aus einem Dendrogramm.
Ein Vorteil der Verwendung eines Dendrogramms besteht darin, dass Objekte durch Betrachten des Dendrogramms in eine beliebige Anzahl von Clustern gruppiert werden können. Wenn Sie beispielsweise zwei Cluster finden müssen, können Sie sich die obere vertikale Linie im Dendrogramm ansehen und sich für die Cluster entscheiden. Wenn in diesem Beispiel beispielsweise zwei Cluster erforderlich sind, gibt es vier Unternehmen im ersten Cluster und 16 Unternehmen im zweiten Cluster. Wenn wir drei Cluster benötigen, können wir den zweiten Cluster weiter in 11 und 5 Unternehmen aufteilen. Wenn Sie mehr benötigen, können Sie diesem Beispiel folgen.
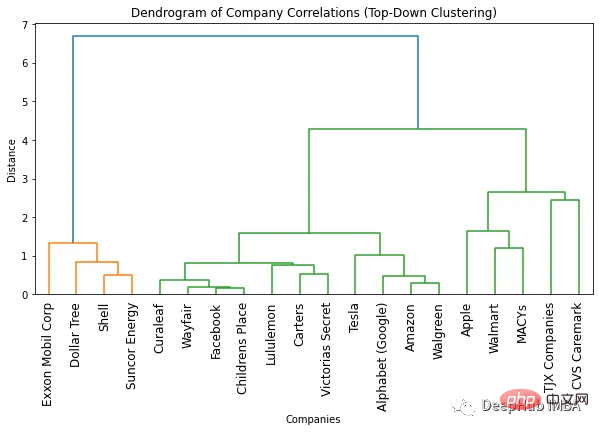 2. Bottom-up-Clustering
2. Bottom-up-Clustering
import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# Convert correlation matrix to distance matrix
dist_mat = 1 - df_combined.corr()
# Perform top-down clustering
clustering = sch.linkage(dist_mat, method='complete')
cuts = sch.cut_tree(clustering, n_clusters=[3, 4])
# Plot dendrogram
plt.figure(figsize=(10, 5))
sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90)
plt.title('Dendrogram of Company Correlations (Top-Down Clustering)')
plt.xlabel('Companies')
plt.ylabel('Distance')
plt.show()Das Dendrogramm, das wir für Bottom-up-Clustering erhalten, ähnelt dem Top-down-Clustering. Die optimale Clusteranzahl beträgt immer noch zwei (basierend auf der Anzahl der Farben und der „Wendepunkt“-Methode). Wenn wir jedoch mehr Cluster benötigen, werden einige subtile Unterschiede zu beobachten sein. Dies ist normal, da die verwendeten Methoden unterschiedlich sind, was zu geringfügigen Unterschieden in den Ergebnissen führt.
Zusammenfassung
Dendogramme sind ein nützliches Werkzeug zur Visualisierung komplexer Datenstrukturen und zur Identifizierung von Untergruppen oder Clustern von Daten mit ähnlichen Merkmalen. In diesem Artikel verwenden wir hierarchische Clustering-Methoden, um zu zeigen, wie man ein Dendrogramm erstellt und die optimale Anzahl von Clustern bestimmt. Denn unsere Datenbaumdiagramme sind hilfreich beim Verständnis der Beziehungen zwischen verschiedenen Unternehmen, können aber auch in einer Vielzahl anderer Bereiche eingesetzt werden, um die hierarchische Struktur von Daten zu verstehen.
Das obige ist der detaillierte Inhalt vonVisualisierung von Clustern mithilfe von Dendrogrammen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 Vier empfohlene KI-gestützte Programmiertools
Apr 22, 2024 pm 05:34 PM
Vier empfohlene KI-gestützte Programmiertools
Apr 22, 2024 pm 05:34 PM
Dieses KI-gestützte Programmiertool hat in dieser Phase der schnellen KI-Entwicklung eine große Anzahl nützlicher KI-gestützter Programmiertools zu Tage gefördert. KI-gestützte Programmiertools können die Entwicklungseffizienz verbessern, die Codequalität verbessern und Fehlerraten reduzieren. Sie sind wichtige Helfer im modernen Softwareentwicklungsprozess. Heute wird Dayao Ihnen 4 KI-gestützte Programmiertools vorstellen (und alle unterstützen die C#-Sprache). https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot ist ein KI-Codierungsassistent, der Ihnen hilft, Code schneller und mit weniger Aufwand zu schreiben, sodass Sie sich mehr auf Problemlösung und Zusammenarbeit konzentrieren können. Git
 Welcher KI-Programmierer ist der beste? Entdecken Sie das Potenzial von Devin, Tongyi Lingma und SWE-Agent
Apr 07, 2024 am 09:10 AM
Welcher KI-Programmierer ist der beste? Entdecken Sie das Potenzial von Devin, Tongyi Lingma und SWE-Agent
Apr 07, 2024 am 09:10 AM
Am 3. März 2022, weniger als einen Monat nach der Geburt von Devin, dem weltweit ersten KI-Programmierer, entwickelte das NLP-Team der Princeton University einen Open-Source-KI-Programmierer-SWE-Agenten. Es nutzt das GPT-4-Modell, um Probleme in GitHub-Repositorys automatisch zu lösen. Die Leistung des SWE-Agenten auf dem SWE-Bench-Testsatz ist ähnlich wie die von Devin, er benötigt durchschnittlich 93 Sekunden und löst 12,29 % der Probleme. Durch die Interaktion mit einem dedizierten Terminal kann der SWE-Agent Dateiinhalte öffnen und durchsuchen, die automatische Syntaxprüfung verwenden, bestimmte Zeilen bearbeiten sowie Tests schreiben und ausführen. (Hinweis: Der obige Inhalt stellt eine geringfügige Anpassung des Originalinhalts dar, die Schlüsselinformationen im Originaltext bleiben jedoch erhalten und überschreiten nicht die angegebene Wortbeschränkung.) SWE-A
 Erfahren Sie, wie Sie mobile Anwendungen mit der Go-Sprache entwickeln
Mar 28, 2024 pm 10:00 PM
Erfahren Sie, wie Sie mobile Anwendungen mit der Go-Sprache entwickeln
Mar 28, 2024 pm 10:00 PM
Tutorial zur Entwicklung mobiler Anwendungen in der Go-Sprache Da der Markt für mobile Anwendungen weiterhin boomt, beginnen immer mehr Entwickler damit, sich mit der Verwendung der Go-Sprache für die Entwicklung mobiler Anwendungen zu befassen. Als einfache und effiziente Programmiersprache hat die Go-Sprache auch großes Potenzial für die Entwicklung mobiler Anwendungen gezeigt. In diesem Artikel wird detailliert beschrieben, wie die Go-Sprache zum Entwickeln mobiler Anwendungen verwendet wird, und es werden spezifische Codebeispiele angehängt, um den Lesern den schnellen Einstieg und die Entwicklung eigener mobiler Anwendungen zu erleichtern. 1. Vorbereitung Bevor wir beginnen, müssen wir die Entwicklungsumgebung und die Tools vorbereiten. Kopf
 Zusammenfassung der fünf beliebtesten Go-Sprachbibliotheken: wesentliche Tools für die Entwicklung
Feb 22, 2024 pm 02:33 PM
Zusammenfassung der fünf beliebtesten Go-Sprachbibliotheken: wesentliche Tools für die Entwicklung
Feb 22, 2024 pm 02:33 PM
Zusammenfassung der fünf beliebtesten Go-Sprachbibliotheken: wesentliche Werkzeuge für die Entwicklung, die spezifische Codebeispiele erfordern Seit ihrer Geburt hat die Go-Sprache große Aufmerksamkeit und Anwendung gefunden. Als aufstrebende effiziente und prägnante Programmiersprache ist die schnelle Entwicklung von Go untrennbar mit der Unterstützung umfangreicher Open-Source-Bibliotheken verbunden. In diesem Artikel werden fünf beliebte Go-Sprachbibliotheken vorgestellt. Diese Bibliotheken spielen eine wichtige Rolle bei der Go-Entwicklung und bieten Entwicklern leistungsstarke Funktionen und praktische Entwicklungserfahrung. Um die Verwendung und Funktion dieser Bibliotheken besser zu verstehen, werden wir sie gleichzeitig anhand konkreter Codebeispiele erläutern.
 Fünf Auswahlmöglichkeiten an Visualisierungstools zur Erkundung von Kafka
Feb 01, 2024 am 08:03 AM
Fünf Auswahlmöglichkeiten an Visualisierungstools zur Erkundung von Kafka
Feb 01, 2024 am 08:03 AM
Fünf Optionen für Kafka-Visualisierungstools ApacheKafka ist eine verteilte Stream-Verarbeitungsplattform, die große Mengen an Echtzeitdaten verarbeiten kann. Es wird häufig zum Aufbau von Echtzeit-Datenpipelines, Nachrichtenwarteschlangen und ereignisgesteuerten Anwendungen verwendet. Die Visualisierungstools von Kafka können Benutzern dabei helfen, Kafka-Cluster zu überwachen und zu verwalten und Kafka-Datenflüsse besser zu verstehen. Im Folgenden finden Sie eine Einführung in fünf beliebte Kafka-Visualisierungstools: ConfluentControlCenterConfluent
 Welche Linux-Distribution eignet sich am besten für die Android-Entwicklung?
Mar 14, 2024 pm 12:30 PM
Welche Linux-Distribution eignet sich am besten für die Android-Entwicklung?
Mar 14, 2024 pm 12:30 PM
Die Android-Entwicklung ist eine arbeitsreiche und spannende Aufgabe, und die Auswahl einer geeigneten Linux-Distribution für die Entwicklung ist besonders wichtig. Welche der vielen Linux-Distributionen eignet sich am besten für die Android-Entwicklung? In diesem Artikel wird dieses Problem unter verschiedenen Aspekten untersucht und spezifische Codebeispiele aufgeführt. Werfen wir zunächst einen Blick auf einige derzeit beliebte Linux-Distributionen: Ubuntu, Fedora, Debian, CentOS usw. Sie alle haben ihre eigenen Vorteile und Eigenschaften.
 Erkundung der Front-End-Technologie der Go-Sprache: eine neue Vision für die Front-End-Entwicklung
Mar 28, 2024 pm 01:06 PM
Erkundung der Front-End-Technologie der Go-Sprache: eine neue Vision für die Front-End-Entwicklung
Mar 28, 2024 pm 01:06 PM
Als schnelle und effiziente Programmiersprache erfreut sich Go im Bereich der Backend-Entwicklung großer Beliebtheit. Allerdings assoziieren nur wenige Menschen die Go-Sprache mit der Front-End-Entwicklung. Tatsächlich kann die Verwendung der Go-Sprache für die Front-End-Entwicklung nicht nur die Effizienz verbessern, sondern Entwicklern auch neue Horizonte eröffnen. In diesem Artikel wird die Möglichkeit der Verwendung der Go-Sprache für die Front-End-Entwicklung untersucht und spezifische Codebeispiele bereitgestellt, um den Lesern ein besseres Verständnis dieses Bereichs zu erleichtern. In der traditionellen Frontend-Entwicklung werden häufig JavaScript, HTML und CSS zum Erstellen von Benutzeroberflächen verwendet
 VSCode verstehen: Wofür wird dieses Tool verwendet?
Mar 25, 2024 pm 03:06 PM
VSCode verstehen: Wofür wird dieses Tool verwendet?
Mar 25, 2024 pm 03:06 PM
„VSCode verstehen: Wofür wird dieses Tool verwendet?“ „Als Programmierer, egal ob Sie Anfänger oder erfahrener Entwickler sind, können Sie auf den Einsatz von Codebearbeitungstools nicht verzichten.“ Unter vielen Bearbeitungstools ist Visual Studio Code (kurz VSCode) bei Entwicklern als Open-Source-, leichter und leistungsstarker Code-Editor sehr beliebt. Wofür genau wird VSCode verwendet? Dieser Artikel befasst sich mit den Funktionen und Verwendungsmöglichkeiten von VSCode und stellt spezifische Codebeispiele bereit, um den Lesern zu helfen
