
 Technologie-Peripheriegeräte
KI
Bilder + Audios verwandeln sich in Sekundenschnelle in Videos! Der Open-Source-SadTalker der Xi'an Jiaotong University: übernatürliche Kopf- und Lippenbewegungen, zweisprachig in Chinesisch und Englisch und kann auch singen
Technologie-Peripheriegeräte
KI
Bilder + Audios verwandeln sich in Sekundenschnelle in Videos! Der Open-Source-SadTalker der Xi'an Jiaotong University: übernatürliche Kopf- und Lippenbewegungen, zweisprachig in Chinesisch und Englisch und kann auch singen
Bilder + Audios verwandeln sich in Sekundenschnelle in Videos! Der Open-Source-SadTalker der Xi'an Jiaotong University: übernatürliche Kopf- und Lippenbewegungen, zweisprachig in Chinesisch und Englisch und kann auch singen

Mit der Popularität des Konzepts der digitalen Menschen und der kontinuierlichen Weiterentwicklung der Generationstechnologie ist es kein Problem mehr, die Charaktere auf dem Foto entsprechend der Audioeingabe zu bewegen.
Allerdings gibt es immer noch viele Probleme beim „Generieren von Avatar-Videos für sprechende Charaktere anhand von Gesichtsbildern und einem Stück Sprachaudio“, wie z. B. Die Kopfbewegung ist nicht korrekt. Probleme wie Natürlichkeit, verzerrte Gesichtsausdrücke und übermäßige Gesichtsunterschiede zwischen den Charakteren in Videos und Bildern .
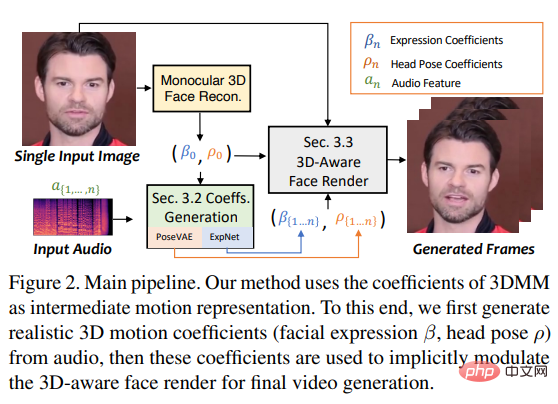
Kürzlich haben Forscher der Xi'an Jiaotong-Universität und andere das SadTalker-Modell vorgeschlagen, das auf einem dreidimensionalen Sportfeld lernt Generieren Sie 3DMM aus Audio-3D-Bewegungskoeffizienten (Kopfhaltung, Ausdruck) und verwenden Sie einen neuen 3D-Gesichtsrenderer, um Kopfbewegungen zu generieren.

Papierlink: https://arxiv.org /pdf/2211.12194.pdf
Projekthomepage: https://sadtalker.github.io/#🎜🎜 #
Der Ton kann Englisch, Chinesisch, Lied sein, und die Zeichen im Video können auch Blinkfrequenz steuern !
Um realistische Bewegungskoeffizienten zu lernen, haben die Forscher den Zusammenhang zwischen Audio und verschiedenen Arten von Bewegungskoeffizienten explizit separat modelliert: Durch Destillationskoeffizienten und 3D-gerenderte Gesichter lernen Sie genaue Gesichtsausdrücke von Audio; Design PoseVAE bis hin zu bedingtem VAE, um verschiedene Arten von Kopfbewegungen zu synthetisieren.
Schließlich werden die generierten dreidimensionalen Bewegungskoeffizienten dem unbeaufsichtigten dreidimensionalen Schlüsselpunktraum des Gesichtsrenderings zugeordnet und das endgültige Video synthetisiert.
Abschließend wurde in Experimenten gezeigt, dass diese Methode hinsichtlich Bewegungssynchronisation und Videoqualität Spitzenleistungen erzielt.
Das Plug-in für Stable-Diffusion-Webui wurde ebenfalls veröffentlicht!
Foto+Audio=VideoViele Bereiche wie digitale menschliche Schöpfung und Videokonferenzen müssen Sprachaudio verwenden, um statische Fotos zu animieren , aber derzeit ist dies immer noch eine sehr anspruchsvolle Aufgabe.
Frühere Arbeiten konzentrierten sich hauptsächlich auf die Erzeugung von „Lippenbewegungen“, da die Beziehung zwischen Lippenbewegungen und Sprache am stärksten ist, und andere Arbeiten versuchen auch, andere verwandte Videos zu generieren von Gesichtern in Bewegung (z. B. Kopfhaltungen), obwohl die Qualität der resultierenden Videos immer noch sehr unnatürlich ist und durch bevorzugte Posen, Unschärfe, Identitätsveränderung und Gesichtsverzerrung eingeschränkt wird.
Eine weitere beliebte Methode ist die latentbasierte Gesichtsanimation, die sich hauptsächlich auf bestimmte Bewegungskategorien in konversationsorientierten Gesichtsanimationen konzentriert, da es auch schwierig ist, qualitativ hochwertige Videos zu synthetisieren Obwohl das 3D-Gesichtsmodell stark entkoppelte Darstellungen enthält, die zum unabhängigen Erlernen der Bewegungsbahnen verschiedener Positionen im Gesicht verwendet werden können, werden dennoch ungenaue Ausdrücke und unnatürliche Bewegungsabläufe erzeugt.
Basierend auf den oben genannten Beobachtungen schlugen die Forscher SadTalker (Stylized Audio-Driven Talking-head) vor, eine stilisierte audiogesteuerte Videoerzeugung durch ein implizites dreidimensionales Koeffizientenmodulationssystem. Um dieses Ziel zu erreichen, betrachteten die Forscher den Bewegungskoeffizienten des 3DMM als Zwischendarstellung und unterteilten die Aufgabe in zwei Hauptteile (Ausdrücke und Gesten), mit dem Ziel, realistischere Bewegungskoeffizienten (wie Kopfhaltungen, Lippenbewegungen usw.) zu erzeugen Augenzwinkern) aus Audio und lernen Sie jede Bewegung einzeln, um Unsicherheit zu reduzieren.
Führt schließlich das Quellbild durch eine 3D-fähige Gesichtsdarstellung, die von face-vid2vid inspiriert wurde.
3D-Gesicht
Da reale Videos in einer dreidimensionalen Umgebung gedreht werden, sind dreidimensionale Informationen von entscheidender Bedeutung, um die Authentizität der generierten Videos zu verbessern. Bisherige Arbeiten berücksichtigten jedoch selten den dreidimensionalen Raum, da nur einer Es ist schwierig, die ursprüngliche 3D-Spärlichkeit eines flachen Bildes zu erhalten, und es ist schwierig, hochwertige Gesichtsrenderer zu entwerfen. Inspiriert durch neuere Einzelbildtiefen-3D-Rekonstruktionsmethoden nutzten die Forscher den Raum vorhergesagter dreidimensionaler Deformationsmodelle (3DMMs) als Zwischendarstellungen.
In 3DMM kann die dreidimensionale Gesichtsform S wie folgt entkoppelt werden:
#🎜🎜 #
wobei S die durchschnittliche Form des dreidimensionalen Gesichts ist, Uid und Uexp die regulären Formen der Identität und des Ausdrucks des LSFM-morphbaren Modells sind und die Koeffizienten α (80 Dimensionen) und β ( 64 Dimensionen) beschreiben die Identität bzw. den Ausdruck des Charakters. Um die Vielfalt der Körperhaltungen aufrechtzuerhalten, stellen die Koeffizienten r und t eine identitätsunabhängige Koeffizientengenerierung dar modelliert als {β, r, t}.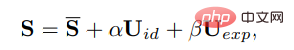
Das heißt, die Kopfhaltung ρ = [r, t] und der Ausdruckskoeffizient β werden separat vom gesteuerten Audio gelernt und dann implizit unter Verwendung dieser Bewegungskoeffizienten moduliert Für die endgültige Videokomposition wurde Gesichts-Rendering verwendet.
Bewegungssparsamkeit durch Audio erzeugen
Dreidimensionale Bewegungskoeffizienten Kopfhaltungen und -ausdrücke einschließen, wobei Kopfhaltungen globale Bewegungen sind, während Ausdrücke relativ lokal sind, so dass das vollständige Erlernen aller Koeffizienten eine große Unsicherheit für das Netzwerk mit sich bringt, da die Beziehung zwischen Kopfhaltungen und Audio relativ schwach ist und Lippenbewegungen stark ausgeprägt sind korreliert mit Audio.
So verwendet SadTalker die folgenden PoseVAE und ExpNet, um die Bewegung der Kopfhaltung bzw. des Ausdrucks zu erzeugen.
ExpNet
Lernen Sie eine Methode, die aus Audio generiert werden kann Ein universelles Modell des „genauen Ausdruckskoeffizienten“ ist aus zwei Gründen sehr schwierig:
1) Audio-to-Expression ist für verschiedene Zeichen nicht eins zu eins genau Mapping-Aufgabe;
2) Es gibt einige audiobezogene Aktionen im Ausdruckskoeffizienten, die sich auf die Genauigkeit der Vorhersage auswirken.
Das Designziel von ExpNet besteht darin, diese Unsicherheiten zu reduzieren; was das Problem der Charakteridentität betrifft, so haben die Forscher zunächst A Der Ausdruckskoeffizient des Rahmens verknüpft die Ausdrucksbewegung mit einer bestimmten Person.
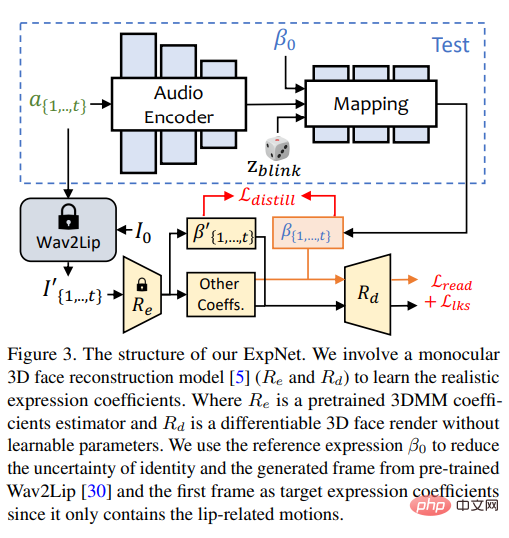
Um das Bewegungsgewicht anderer Gesichtskomponenten in natürlichen Gesprächen zu reduzieren, werden nur Lippenbewegungskoeffizienten (nur Lippenbewegung) als Koeffizientenziel verwendet.
Andere subtile Gesichtsbewegungen (z. B. Augenzwinkern) usw. können durch den zusätzlichen Verlust von Orientierungspunkten im gerenderten Bild verursacht werden.
PoseVAE Zum Erlernen realistischer, identitätsbewusster stilisierter Kopfbewegungen in sprechenden Videos.
Im Training wird ein Encoder-Decoder-basiertes Strukturpaar verwendet. Festes n Frames werden für das Pose-VAE-Training verwendet, bei dem sowohl der Encoder als auch der Decoder zweischichtige MLPs sind. Die Eingabe enthält eine kontinuierliche T-Frame-Kopfpose, die in eine Gaußsche Verteilung eingebettet ist, aus der das Netzwerk abgetastet wird Verteilung Lernen Sie, T-Frame-Posen zu generieren.
Es ist zu beachten, dass PoseVAE die Pose nicht direkt generiert, sondern den Rest der bedingten Pose des ersten Frames lernt, wodurch diese Methode auch die bedingte Pose unter der Bedingung des ersten Frames generieren kann Rahmen im Test. Längere, stabilere, kontinuierlichere Kopfbewegung.
Laut CVAE werden PoseVAE auch entsprechende Audiofunktionen und Stilkennungen als Bedingungen für Rhythmusbewusstsein und Identitätsstil hinzugefügt.
Das Modell verwendet die KL-Divergenz, um die Verteilung der erzeugten Bewegung zu messen; es verwendet den mittleren quadratischen Verlust und den gegnerischen Verlust, um die Qualität der Erzeugung sicherzustellen.
3D-fähige Gesichtsdarstellung
bei der Generierung echter Drei- Nach den dimensionalen Bewegungskoeffizienten renderten die Forscher das endgültige Video mithilfe eines sorgfältig entwickelten 3D-Bildanimators.
Die kürzlich vorgeschlagene Bildanimationsmethode face-vid2vid kann implizit 3D-Informationen aus einem einzelnen Bild lernen, diese Methode erfordert jedoch ein echtes Video als aktionstreibendes Signal Das in diesem Artikel vorgeschlagene Rendering kann durch 3DMM-Koeffizienten gesteuert werden.
Forscher schlagen MappingNet vor, um die Beziehung zwischen expliziten 3DMM-Bewegungskoeffizienten (Kopfhaltung und Ausdruck) und impliziten unbeaufsichtigten 3D-Schlüsselpunkten zu lernen.
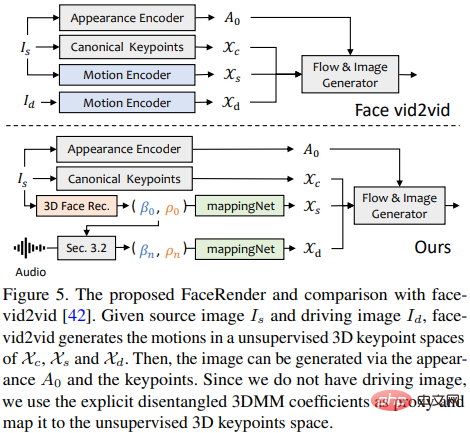
mappingNet besteht aus mehreren eindimensionalen Faltungsschichten und verwendet den Zeitkoeffizienten des Zeitfensters zur Glättung Der Unterschied besteht wie bei der PIRenderer-Verarbeitung darin, dass die Forscher herausgefunden haben, dass die gesichtsausgerichteten Bewegungskoeffizienten in PIRenderer die Natürlichkeit der von audiogesteuerten Videos erzeugten Bewegungen stark beeinflussen, sodass MappingNet nur die Koeffizienten von Gesichtsausdrücken und Kopfhaltungen verwendet.
Die Trainingsphase besteht aus zwei Schritten: Befolgen Sie zunächst das Originalpapier und trainieren Sie face-vid2vid auf selbstüberwachte Weise. Anschließend wird der Appearance-Encoder, der kanonische Schlüsselpunktschätzer, eingefroren und Nach allen Parametern des Bildgenerators wird MappingNet zur Feinabstimmung auf die 3DMM-Koeffizienten des Ground-Truth-Videos in rekonstruierter Weise trainiert.
Verwendet L1-Verlust für überwachtes Training im Bereich unbeaufsichtigter Schlüsselpunkte und liefert das endgültig generierte Video gemäß seiner ursprünglichen Implementierung.
Experimentelle Ergebnisse
Um die Überlegenheit dieser Methode zu beweisen, wählten die Forscher Frechet Inception Distance (FID) und Cumulative Probability Blur Detection (CPBD)-Index zur Bewertung der Bildqualität, wobei FID hauptsächlich die Authentizität der generierten Frames und CPBD die Klarheit der generierten Frames bewertet.
Um den Grad der Identitätserhaltung zu bewerten, wird ArcFace verwendet, um die Identitätseinbettung des Bildes zu extrahieren und anschließend die Kosinusähnlichkeit der Identitätseinbettung (CSIM) zu berechnen zwischen dem Quellbild und dem generierten Frame.
Um die Lippensynchronisation und die Mundform zu bewerten, bewerteten die Forscher den Wahrnehmungsunterschied der Mundform zu Wav2Lip, einschließlich Distanzwert (LSE-D) und Konfidenzwert (LSE- C).
Bei der Auswertung der Kopfbewegung wird die Diversität der generierten Kopfbewegungen anhand der Standardabweichung der von Hopenet aus den generierten Frames extrahierten Kopfbewegungsmerkmalseinbettungen berechnet. Berechnen Sie den Beat Align Score, um die Konsistenz von Audio und erzeugten Kopfbewegungen zu bewerten.
Unter den Vergleichsmethoden wurden mehrere fortschrittlichste Methoden zur Generierung sprechender Avatare ausgewählt, darunter MakeItTalk, Audio2Head und Methoden zur Audio-to-Expression-Generierung (Wav2Lip, PC-AVS). , bewertet anhand öffentlicher Prüfpunktgewichte.
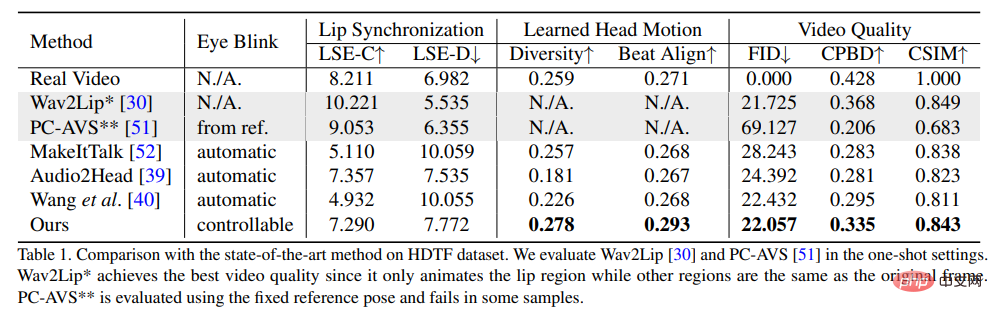
Aus den experimentellen Ergebnissen ist ersichtlich, dass die in der vorgeschlagene Methode Der Artikel kann zeigen, dass dies zu einer insgesamt besseren Videoqualität und einer besseren Kopfhaltungsvielfalt führt und gleichzeitig hinsichtlich der Lippensynchronisationsmetriken eine vergleichbare Leistung wie andere Methoden zur Generierung vollständig sprechender Köpfe zeigt.
Die Forscher glauben, dass diese Lippensynchronisationsmetriken so empfindlich auf Audio reagieren, dass unnatürliche Lippenbewegungen möglicherweise bessere Ergebnisse erzielen, aber der Artikel legt nahe, dass die Methode ähnliche Ergebnisse wie bei echten Videos erzielte , was auch die Vorteile dieser Methode zeigt.

Wie aus den visuellen Ergebnissen verschiedener Methoden hervorgeht, ist die visuelle Qualität dieser Methode sehr ähnlich zum ursprünglichen Zielvideo und ist auch den erwarteten unterschiedlichen Kopfhaltungen sehr ähnlich.
Im Vergleich zu anderen Methoden erzeugt Wav2Lip unscharfe Halbgesichter; PC-AVS und Audio2Head haben Schwierigkeiten, die Identität des Quellbildes beizubehalten; Gesicht; MakeItTalk und Audio2Head erzeugen aufgrund der 2D-Verzerrung verzerrte Gesichtsvideos.
Das obige ist der detaillierte Inhalt vonBilder + Audios verwandeln sich in Sekundenschnelle in Videos! Der Open-Source-SadTalker der Xi'an Jiaotong University: übernatürliche Kopf- und Lippenbewegungen, zweisprachig in Chinesisch und Englisch und kann auch singen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Wie stelle ich die Audiobalance in Win11 ein? (Win11 passt die Lautstärke des linken und rechten Kanals an)
Feb 11, 2024 pm 05:57 PM
Wie stelle ich die Audiobalance in Win11 ein? (Win11 passt die Lautstärke des linken und rechten Kanals an)
Feb 11, 2024 pm 05:57 PM
Wenn beim Musikhören oder Ansehen von Filmen auf einem Win11-Computer die Lautsprecher oder Kopfhörer unausgewogen klingen, können Benutzer den Balancepegel manuell entsprechend ihren Bedürfnissen anpassen. Wie passen wir uns an? Als Reaktion auf dieses Problem hat der Herausgeber ein detailliertes Bedienungs-Tutorial mitgebracht, in der Hoffnung, allen zu helfen. Wie gleicht man den linken und rechten Audiokanal in Windows 11 aus? Methode 1: Tippen Sie in der App „Einstellungen“ auf die Taste und klicken Sie auf „Einstellungen“. Klicken Sie unter Windows auf „System“ und wählen Sie „Sound“ aus. Wählen Sie weitere Toneinstellungen aus. Klicken Sie auf Ihre Lautsprecher/Kopfhörer und wählen Sie Eigenschaften. Navigieren Sie zur Registerkarte „Ebenen“ und klicken Sie auf „Balance“. Stellen Sie sicher, dass „links“ und
 Einführungserlebnis der Bose Soundbar Ultra: Heimkino direkt nach dem Auspacken?
Feb 06, 2024 pm 05:30 PM
Einführungserlebnis der Bose Soundbar Ultra: Heimkino direkt nach dem Auspacken?
Feb 06, 2024 pm 05:30 PM
Solange ich mich erinnern kann, habe ich zu Hause ein Paar große Standlautsprecher gehabt. Ich bin der Meinung gewesen, dass ein Fernseher nur dann als Fernseher bezeichnet werden kann, wenn er mit einem kompletten Soundsystem ausgestattet ist. Aber als ich anfing zu arbeiten, konnte ich mir professionelles Home-Audio nicht leisten. Nachdem ich mich erkundigt und die Produktpositionierung verstanden hatte, stellte ich fest, dass die Soundbar-Kategorie für mich sehr gut geeignet ist. Sie erfüllt meine Bedürfnisse in Bezug auf Klangqualität, Größe und Preis. Deshalb habe ich mich für die Soundbar entschieden. Nach sorgfältiger Auswahl habe ich mich für dieses Panorama-Soundbar-Produkt entschieden, das Anfang 2024 von Bose auf den Markt gebracht wurde: den Bose Home-Entertainment-Lautsprecher Ultra. (Fotoquelle: Fotografiert von Lei Technology) Wenn wir den „originalen“ Dolby Atmos-Effekt erleben wollen, müssen wir im Allgemeinen eine gemessene und kalibrierte Surround-Sound-Decke zu Hause installieren.
 Wie kann das Problem des automatischen Speicherns von Bildern beim Veröffentlichen auf Xiaohongshu gelöst werden? Wo ist das beim Posten automatisch gespeicherte Bild?
Mar 22, 2024 am 08:06 AM
Wie kann das Problem des automatischen Speicherns von Bildern beim Veröffentlichen auf Xiaohongshu gelöst werden? Wo ist das beim Posten automatisch gespeicherte Bild?
Mar 22, 2024 am 08:06 AM
Durch die kontinuierliche Entwicklung der sozialen Medien ist Xiaohongshu zu einer Plattform für immer mehr junge Menschen geworden, auf der sie ihr Leben teilen und schöne Dinge entdecken können. Viele Benutzer haben beim Posten von Bildern Probleme mit der automatischen Speicherung. Wie kann man dieses Problem lösen? 1. Wie kann das Problem des automatischen Speicherns von Bildern beim Veröffentlichen auf Xiaohongshu gelöst werden? 1. Cache leeren Zuerst können wir versuchen, die Cache-Daten von Xiaohongshu zu löschen. Die Schritte sind wie folgt: (1) Öffnen Sie Xiaohongshu und klicken Sie auf die Schaltfläche „Mein“ in der unteren rechten Ecke. (2) Suchen Sie auf der persönlichen Center-Seite nach „Einstellungen“ und klicken Sie darauf. (3) Scrollen Sie nach unten und suchen Sie nach „; Option „Cache löschen“. Klicken Sie auf „OK“. Nachdem Sie den Cache geleert haben, geben Sie Xiaohongshu erneut ein und versuchen Sie, Bilder zu posten, um zu sehen, ob das Problem mit dem automatischen Speichern behoben ist. 2. Aktualisieren Sie die Xiaohongshu-Version, um sicherzustellen, dass Ihr Xiaohongshu
 Wie poste ich Bilder in TikTok-Kommentaren? Wo ist der Zugang zu den Bildern im Kommentarbereich?
Mar 21, 2024 pm 09:12 PM
Wie poste ich Bilder in TikTok-Kommentaren? Wo ist der Zugang zu den Bildern im Kommentarbereich?
Mar 21, 2024 pm 09:12 PM
Mit der Beliebtheit von Douyin-Kurzvideos sind die Benutzerinteraktionen im Kommentarbereich bunter geworden. Einige Benutzer möchten Bilder in Kommentaren teilen, um ihre Meinung oder Gefühle besser auszudrücken. Wie postet man also Bilder in TikTok-Kommentaren? Dieser Artikel beantwortet diese Frage ausführlich und gibt Ihnen einige entsprechende Tipps und Vorsichtsmaßnahmen. 1. Wie poste ich Bilder in Douyin-Kommentaren? 1. Öffnen Sie Douyin: Zuerst müssen Sie die Douyin-App öffnen und sich bei Ihrem Konto anmelden. 2. Suchen Sie den Kommentarbereich: Suchen Sie beim Durchsuchen oder Posten eines kurzen Videos die Stelle, an der Sie einen Kommentar abgeben möchten, und klicken Sie auf die Schaltfläche „Kommentieren“. 3. Geben Sie Ihren Kommentarinhalt ein: Geben Sie Ihren Kommentarinhalt in den Kommentarbereich ein. 4. Wählen Sie, ob Sie ein Bild senden möchten: In der Benutzeroberfläche zur Eingabe von Kommentarinhalten sehen Sie eine Schaltfläche „Bild“ oder eine Schaltfläche „+“. Klicken Sie darauf
 6 Möglichkeiten, Bilder auf dem iPhone schärfer zu machen
Mar 04, 2024 pm 06:25 PM
6 Möglichkeiten, Bilder auf dem iPhone schärfer zu machen
Mar 04, 2024 pm 06:25 PM
Die neuesten iPhones von Apple halten Erinnerungen mit gestochen scharfen Details, Sättigung und Helligkeit fest. Manchmal kann es jedoch zu Problemen kommen, die dazu führen können, dass das Bild weniger klar aussieht. Während der Autofokus bei iPhone-Kameras große Fortschritte gemacht hat und es Ihnen ermöglicht, schnell Fotos aufzunehmen, kann die Kamera in bestimmten Situationen versehentlich auf das falsche Motiv fokussieren, wodurch das Foto in unerwünschten Bereichen unscharf wird. Wenn Ihre Fotos auf Ihrem iPhone unscharf wirken oder es ihnen insgesamt an Schärfe mangelt, soll Ihnen der folgende Beitrag dabei helfen, sie schärfer zu machen. So machen Sie Bilder auf dem iPhone klarer [6 Methoden] Sie können versuchen, Ihre Fotos mit der nativen Foto-App zu bereinigen. Wenn Sie mehr Funktionen und Optionen wünschen
 7 Möglichkeiten, die Toneinstellungen unter Windows 11 zurückzusetzen
Nov 08, 2023 pm 05:17 PM
7 Möglichkeiten, die Toneinstellungen unter Windows 11 zurückzusetzen
Nov 08, 2023 pm 05:17 PM
Obwohl Windows in der Lage ist, den Ton auf Ihrem Computer zu verwalten, möchten Sie möglicherweise dennoch eingreifen und Ihre Toneinstellungen zurücksetzen, falls Sie auf Audioprobleme oder Störungen stoßen. Mit den ästhetischen Änderungen, die Microsoft in Windows 11 vorgenommen hat, ist es jedoch schwieriger geworden, diese Einstellungen genau festzulegen. Sehen wir uns also an, wie Sie diese Einstellungen unter Windows 11 finden und verwalten oder sie zurücksetzen können, falls Probleme auftreten. So setzen Sie die Toneinstellungen in Windows 11 auf 7 einfache Arten zurück. Hier finden Sie sieben Möglichkeiten, die Toneinstellungen in Windows 11 zurückzusetzen, je nachdem, mit welchem Problem Sie konfrontiert sind. Fangen wir an. Methode 1: Ton- und Lautstärkeeinstellungen der App zurücksetzen Drücken Sie die Taste auf Ihrer Tastatur, um die Einstellungen-App zu öffnen. Klicken Sie jetzt
 So lassen Sie PPT-Bilder einzeln erscheinen
Mar 25, 2024 pm 04:00 PM
So lassen Sie PPT-Bilder einzeln erscheinen
Mar 25, 2024 pm 04:00 PM
In PowerPoint ist es eine gängige Technik, Bilder einzeln anzuzeigen, was durch das Festlegen von Animationseffekten erreicht werden kann. In dieser Anleitung werden die Schritte zur Implementierung dieser Technik detailliert beschrieben, einschließlich der grundlegenden Einrichtung, des Einfügens von Bildern, des Hinzufügens von Animationen sowie des Anpassens der Reihenfolge und des Timings der Animationen. Darüber hinaus stehen erweiterte Einstellungen und Anpassungen zur Verfügung, z. B. die Verwendung von Triggern, das Anpassen von Animationsgeschwindigkeit und -reihenfolge sowie die Vorschau von Animationseffekten. Durch Befolgen dieser Schritte und Tipps können Benutzer ganz einfach Bilder so einrichten, dass sie in PowerPoint nacheinander angezeigt werden, wodurch die visuelle Wirkung der Präsentation verbessert und die Aufmerksamkeit des Publikums erregt wird.
 So konvertieren Sie PDF-Dokumente mit Foxit PDF Reader in JPG-Bilder. - So konvertieren Sie PDF-Dokumente mit Foxit PDF Reader in JPG-Bilder
Mar 04, 2024 pm 05:49 PM
So konvertieren Sie PDF-Dokumente mit Foxit PDF Reader in JPG-Bilder. - So konvertieren Sie PDF-Dokumente mit Foxit PDF Reader in JPG-Bilder
Mar 04, 2024 pm 05:49 PM
Verwenden Sie auch die Foxit PDF Reader-Software? Wissen Sie, wie Foxit PDF Reader PDF-Dokumente in JPG-Bilder konvertiert? Für diejenigen, die sich für die Konvertierungsmethode interessieren jpg-Bilder, kommen Sie bitte vorbei und schauen Sie sich unten um. Starten Sie zunächst Foxit PDF Reader, suchen Sie dann in der oberen Symbolleiste nach „Funktionen“ und wählen Sie dann die Funktion „PDF an andere“ aus. Öffnen Sie als Nächstes eine Webseite namens „Foxit PDF Online Conversion“. Klicken Sie auf die Schaltfläche „Anmelden“ oben rechts auf der Seite, um sich anzumelden, und aktivieren Sie dann die Funktion „PDF zu Bild“. Klicken Sie dann auf die Schaltfläche „Hochladen“ und fügen Sie die PDF-Datei hinzu, die Sie in ein Bild konvertieren möchten. Klicken Sie nach dem Hinzufügen auf „Konvertierung starten“.
