
 Technologie-Peripheriegeräte
KI
US-Medien enthüllen großen Datensatz zum Modelltraining: Einige Inhalte sind etwas „schmutzig'
Technologie-Peripheriegeräte
KI
US-Medien enthüllen großen Datensatz zum Modelltraining: Einige Inhalte sind etwas „schmutzig'
US-Medien enthüllen großen Datensatz zum Modelltraining: Einige Inhalte sind etwas „schmutzig'


Neuigkeiten vom 20. April: Chatbots mit künstlicher Intelligenz sind in den letzten vier Monaten immer beliebter geworden. Ihre Fähigkeit, eine Vielzahl von Aufgaben zu erledigen, wie zum Beispiel das Verfassen komplexer wissenschaftlicher Arbeiten und das Führen intensiver Gespräche, ist beeindruckend.
Chatbots denken nicht wie Menschen, sie wissen nicht einmal, wovon sie reden. Sie können menschliche Sprache nachahmen, weil die künstliche Intelligenz, die sie antreibt, riesige Textmengen absorbiert hat, von denen ein Großteil aus dem Internet stammt.
Diese Texte sind die Hauptinformationsquelle der KI über die Welt während ihres Aufbaus und können einen tiefgreifenden Einfluss darauf haben, wie die KI reagiert. Wenn künstliche Intelligenz bei der gerichtlichen Prüfung hervorragende Ergebnisse erzielt, liegt das möglicherweise daran, dass ihre Trainingsdaten Tausende von LSAT-Informationen (Law School Admission Test, American Law School Admission Test) enthalten.
Tech-Unternehmen machen immer ein Geheimnis darüber, welche Informationen sie der künstlichen Intelligenz zur Verfügung stellen. Deshalb machte sich die Washington Post daran, einen dieser wichtigen Datensätze zu analysieren und die Arten proprietärer, persönlicher und oft anstößiger Websites aufzudecken, die zum Trainieren von KI verwendet werden.
Um den internen Aufbau von Trainingsdaten für künstliche Intelligenz zu untersuchen, arbeitete die Washington Post mit Forschern des Allen Institute for Artificial Intelligence zusammen, um den C4-Datensatz von Google zu analysieren. Dieser Datensatz ist eine riesige Momentaufnahme von mehr als 15 Millionen Websites, deren Inhalte zum Trainieren vieler hochkarätiger englischsprachiger KIs wie Googles T5 und Facebooks LLaMA verwendet werden. OpenAI gab nicht bekannt, welche Art von Datensatz sie zum Trainieren des Modells verwendet haben, das den Chatbot ChatGPT unterstützt.
In dieser Umfrage verwendeten Forscher Daten des Webanalyseunternehmens Similarweb, um Websites zu klassifizieren. Etwa ein Drittel dieser Websites konnte nicht klassifiziert werden und wurde ausgeschlossen, vor allem weil sie nicht mehr im Internet vorhanden sind. Anschließend ordneten die Forscher die verbleibenden 10 Millionen Websites anhand der Anzahl der „Tokens“ ein, die auf jeder Website im Datensatz auftauchten. Ein Token ist eine kleine Textverarbeitungsinformation, normalerweise ein Wort oder eine Phrase, die zum Trainieren von KI-Modellen verwendet wird.
Von Wikipedia bis WoWhead
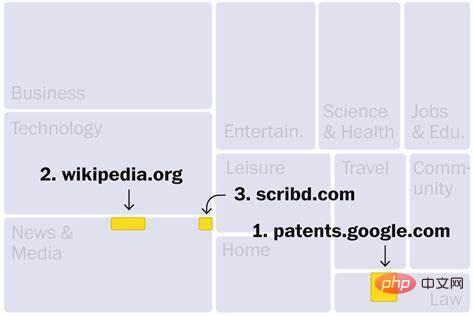
Websites im C4-Datensatz stammen hauptsächlich aus Branchen wie Nachrichten, Unterhaltung, Softwareentwicklung, Medizin und Inhaltserstellung. Dies könnte erklären, warum diese Bereiche durch eine neue Welle künstlicher Intelligenz bedroht sein könnten. Die drei wichtigsten Websites sind: Die erste ist Google Patent Search, die weltweit veröffentlichte Patenttexte enthält, und die dritte ist Scribd, eine digitale Bibliothek, die nur kostenpflichtige Abonnements akzeptiert. Zu den weiteren hochrangigen Websites gehört außerdem der Raubkopien-E-Book-Marktplatz Library (Nr. 190), der vom US-Justizministerium wegen illegaler Aktivitäten geschlossen wurde. Darüber hinaus enthält der Datensatz mindestens 27 Websites, die von der US-Regierung als Märkte für Raubkopien und gefälschte Produkte identifiziert wurden.
Es werden auch einige Top-Seiten vorgestellt, wie zum Beispiel wowhead (Nr. 181), ein Forum für World of Warcraft-Spieler, und throveglobal (Nr. 181), eine von Arianna Huffington gegründete Seite zur Bekämpfung von Burnout 175 Bits. Darüber hinaus gibt es mindestens 10 Websites, die Müllcontainer verkaufen, darunter dumpsteroid (Nr. 183), aber es scheint nicht mehr zugänglich zu sein.
Während die meisten Websites sicher sind, gibt es bei einigen schwerwiegende Datenschutzprobleme. Beispielsweise waren zwei Websites in der Top-100-Liste privat gehostete Kopien staatlicher Wählerregistrierungsdatenbanken. Während Wählerdaten öffentlich sind, können diese Modelle diese persönlichen Informationen auf unbekannte Weise nutzen.
Industrielle und kommerzielle Websites nehmen die größte Kategorie ein (16 % der Kategorie-Tokens). Ganz oben auf der Liste steht The Motley Fool (Nr. 13), das Anlageberatung anbietet. Als nächstes folgt Kickstarter (Nr. 25), eine Website, die es Benutzern ermöglicht, kreative Projekte per Crowdfunding zu finanzieren. Patreon, das auf Platz 2.398 weiter unten liegt, hilft Kreativen dabei, monatliche Gebühren von Abonnenten für exklusive Inhalte zu erheben.
Kickstarter und Patreon ermöglichen jedoch möglicherweise, dass künstliche Intelligenz auf die Ideen und Marketingtexte von Künstlern zugreift, und es gibt Bedenken, dass KI diese Werke kopieren könnte, wenn sie Benutzern Vorschläge macht. Künstler, die derzeit keine Entschädigung erhalten, wenn ihre Arbeit in KI-Trainingsdaten einbezogen wird, haben Verletzungsklagen gegen die Text-zu-Bild-Generatoren Stable Diffusion, MidJourney und DeviantArt eingereicht.
Laut dieser Analyse der Washington Post könnten weitere rechtliche Herausforderungen auf uns zukommen: Das Urheberrechtssymbol (das als geistiges Eigentum registrierte Werke anzeigt) kommt im C4-Datensatz mehr als 200 Millionen Mal vor.
Technische Websites sind die zweitgrößte Kategorie und machen 15 % der Kategorie-Tokens aus. Dazu gehören viele Plattformen, die Menschen beim Erstellen von Websites unterstützen, wie zum Beispiel Google Sites (Nr. 85), dessen Seiten alles von einem Judo-Club in Reading, England, bis zu einem Kindergarten in New Jersey abdecken.
Der C4-Datensatz enthält außerdem mehr als 500.000 persönliche Blogs, was 3,8 % der klassifizierten Inhalte ausmacht. Die Veröffentlichungsplattform Medium belegt den 46. Platz und ist die fünftgrößte Technologie-Website mit Zehntausenden Blogs unter ihrem Domainnamen. Darüber hinaus gibt es Blogs, die auf Plattformen wie WordPress, Tumblr, Blogpot und Live Journal geschrieben wurden.
Diese Blogs gibt es in vielen Formen, von beruflich bis privat, wie zum Beispiel ein Blog mit dem Titel „Grumpy Rumblings“, gemeinsam verfasst von zwei anonymen Akademikern, von denen einer kürzlich darüber schrieb, wie sich der Verlust des Arbeitsplatzes ihres Partners auf die Steuererklärung des Paares auswirkte. Darüber hinaus gibt es im C4-Datensatz einige Top-Blogs, die sich auf Live-Action-Rollenspiele konzentrieren.
Der Inhalt sozialer Netzwerke wie Facebook und Twitter (die als Kern des modernen Webs gelten) ist für das Crawling gesperrt, was bedeutet, dass die meisten Datensätze, die zum Trainieren künstlicher Intelligenz verwendet werden, nicht darauf zugreifen können. Tech-Giganten wie Facebook und Google sitzen auf riesigen Mengen an Gesprächsdaten, wissen aber noch nicht, wie sie persönliche Benutzerinformationen nutzen können, um Modelle der künstlichen Intelligenz für den internen Gebrauch oder den Verkauf als Produkte zu trainieren.
Nachrichten- und Medienseiten belegen in allen Kategorien den dritten Platz, während die Hälfte der Top-Ten-Seiten Nachrichtenagenturen sind: Die Website der New York Times belegt den vierten Platz, die Website der Los Angeles Times den sechsten und die Website des Guardian den dritten und siebten Platz Die Website „Forbes“ belegte den achten Platz, die Website „Huffington Post“ den neunten und die Website „Washington Post“ den 11. Platz. Ebenso wie Künstler und YouTuber haben mehrere Nachrichtenorganisationen Technologieunternehmen dafür kritisiert, dass sie ihre Inhalte ohne Genehmigung oder Vergütung nutzen.
Gleichzeitig stellte die „Washington Post“ auch fest, dass mehrere Medien in der unabhängigen Glaubwürdigkeitsbewertung von NewsGuard schlecht abgeschnitten haben: etwa Russlands RT (65.) und die rechtsextreme Nachrichten-Website Breitbart (159.) sowie die Anti-Einwanderungs-Website vdare ( Nr. 993) mit Verbindungen zur weißen Vorherrschaft.
Chatbots verbreiten nachweislich Fehlinformationen. Nicht vertrauenswürdige Trainingsdaten können dazu führen, dass sie Voreingenommenheit verbreiten und Fehlinformationen verbreiten, ohne dass Benutzer sie auf ihre ursprüngliche Quelle zurückführen können.
Community-Websites machen etwa 5 % der klassifizierten Inhalte aus, hauptsächlich religiöse Websites.
Welche Fische fehlen im Filter?
Wie die meisten Unternehmen filtert und überprüft Google die Daten, bevor es sie an die KI weiterleitet. Das Unternehmen entfernt nicht nur bedeutungslosen und sich wiederholenden Text, sondern verwendet auch eine Open-Source-Liste mit „schlechten Wörtern“, die 402 englische Begriffe und ein Emoji enthält. Unternehmen verwenden häufig hochwertige Datensätze zur Feinabstimmung von Modellen, um Inhalte zu blockieren, die Benutzer nicht sehen möchten.
Während Listen wie diese dazu dienen sollen, zu verhindern, dass Models während des Trainings rassistischen Beleidigungen und unangemessenen Inhalten ausgesetzt werden, bleibt vieles unbemerkt. Die Washington Post fand Hunderte pornografische Websites und mehr als 72.000 Beispiele für „Nazi“ auf der Liste der verbotenen Wörter.
Unterdessen stellte die Washington Post fest, dass die Filter einige beunruhigende Inhalte nicht entfernen konnten, darunter Websites von weißen Rassisten, Anti-Trans-Websites und ein anonymes Message Board, das dafür bekannt ist, Belästigungskampagnen gegen Einzelpersonen auf 4chan zu organisieren. Die Studie deckte auch Websites auf, die Verschwörungstheorien verbreiten.
Wird Ihre Website zum Training von KI verwendet?
Web Scraping hört sich vielleicht so an, als würde man das gesamte Internet kopieren, aber es handelt sich tatsächlich nur um das Sammeln von Schnappschüssen, einer Auswahl von Webseiten zu einem bestimmten Zeitpunkt. Der C4-Datensatz wurde ursprünglich im April 2019 von der gemeinnützigen Organisation CommonCrawl für das Crawlen von Webinhalten erstellt und ist eine beliebte Ressource für das Training von Modellen für künstliche Intelligenz. Laut CommonCrawl versucht die Organisation, die wichtigsten und seriösesten Websites zu priorisieren, unternimmt jedoch keinen Versuch, lizenzierte oder urheberrechtlich geschützte Inhalte zu vermeiden.
Die Washington Post ist der Ansicht, dass es von entscheidender Bedeutung ist, den vollständigen Dateninhalt in Modellen der künstlichen Intelligenz darzustellen, die das Potenzial haben, viele Aspekte des modernen Lebens der Menschen zu verwalten. Allerdings enthalten viele Websites in diesem Datensatz äußerst anstößige Sprache, und selbst wenn das Modell darauf trainiert ist, diese Wörter zu maskieren, können dennoch anstößige Inhalte vorhanden sein.
Experten sagen, dass der C4-Datensatz zwar groß ist, große Sprachmodelle jedoch möglicherweise noch größere Datensätze verwenden. Beispielsweise veröffentlichte OpenAI im Jahr 2020 GPT-3-Trainingsdaten, die das 40-fache der Menge an Web-Scraping-Daten in C4 enthalten. Die Trainingsdaten von GPT-3 umfassen die gesamte englische Wikipedia, eine Sammlung kostenloser Romane unveröffentlichter Autoren, die häufig von großen Technologieunternehmen verwendet werden, und eine Zusammenstellung verlinkter Texte, die von Reddit-Benutzern hoch bewertet werden.
Experten sagen, dass viele Unternehmen den Inhalt ihrer Schulungsdaten nicht einmal protokollieren (auch nicht intern), aus Angst, personenbezogene Daten, urheberrechtlich geschütztes Material und andere Daten herauszufinden, die ohne Zustimmung gestohlen wurden. Während Unternehmen die Herausforderung hervorheben, zu erklären, wie Chatbots Entscheidungen treffen, ist dies ein Bereich, in dem Führungskräfte transparente Antworten geben müssen.
Das obige ist der detaillierte Inhalt vonUS-Medien enthüllen großen Datensatz zum Modelltraining: Einige Inhalte sind etwas „schmutzig'. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
Laut Nachrichten dieser Website vom 1. August hat SK Hynix heute (1. August) einen Blogbeitrag veröffentlicht, in dem es ankündigt, dass es am Global Semiconductor Memory Summit FMS2024 teilnehmen wird, der vom 6. bis 8. August in Santa Clara, Kalifornien, USA, stattfindet viele neue Technologien Generation Produkt. Einführung des Future Memory and Storage Summit (FutureMemoryandStorage), früher Flash Memory Summit (FlashMemorySummit), hauptsächlich für NAND-Anbieter, im Zusammenhang mit der zunehmenden Aufmerksamkeit für die Technologie der künstlichen Intelligenz wurde dieses Jahr in Future Memory and Storage Summit (FutureMemoryandStorage) umbenannt Laden Sie DRAM- und Speicheranbieter und viele weitere Akteure ein. Neues Produkt SK Hynix wurde letztes Jahr auf den Markt gebracht
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
