
 Backend-Entwicklung
Python-Tutorial
Pandas und PySpark bündeln ihre Kräfte, um sowohl Funktionalität als auch Geschwindigkeit zu erreichen!
Backend-Entwicklung
Python-Tutorial
Pandas und PySpark bündeln ihre Kräfte, um sowohl Funktionalität als auch Geschwindigkeit zu erreichen!
Pandas und PySpark bündeln ihre Kräfte, um sowohl Funktionalität als auch Geschwindigkeit zu erreichen!

Datenwissenschaftler oder Datenpraktiker, die Python für die Datenverarbeitung verwenden, sind mit dem Datenwissenschaftspaket Pandas vertraut, und es gibt auch starke Pandas-Benutzer wie Yun Duojun. Die meisten der ersten Codezeilen, die zu Beginn des Projekts geschrieben wurden, sind importiert Pandas als PD. Man kann sagen, dass Pandas ein Idiot für die Datenverarbeitung sind! Und seine Mängel sind auch sehr offensichtlich. Pandas können nur auf einer einzigen Maschine verarbeitet werden und können nicht linear mit der Datenmenge skaliert werden. Wenn Pandas beispielsweise versucht, einen Datensatz zu lesen, der größer ist als der verfügbare Speicher einer Maschine, schlägt dies aufgrund unzureichenden Speichers fehl.
Darüber hinaus verarbeitet Pandas große Datenmengen sehr langsam. Obwohl es andere Bibliotheken wie Dask oder Vaex gibt, um die Datenverarbeitungsgeschwindigkeit zu optimieren und zu verbessern, ist dies ein Kinderspiel gegenüber dem Spark-Framework für die Verarbeitung großer Datenmengen.
Glücklicherweise ist in der neuen Spark 3.2-Version eine neue Pandas-API erschienen, die die meisten Pandas-Funktionen in PySpark integriert. Über die Pandas-Schnittstelle können Sie Spark verwenden, da die Pandas-API auf Spark Spark im Hintergrund verwendet kann den Effekt einer starken Zusammenarbeit erzielen, die als sehr kraftvoll und sehr praktisch bezeichnet werden kann.
Alles begann beim Spark + AI Summit 2019. Koalas ist ein Open-Source-Projekt, das Pandas zusätzlich zu Spark verwendet. Zu Beginn deckte es nur einen kleinen Teil der Funktionalität von Pandas ab, doch nach und nach wurde es immer größer. Jetzt wurde Koalas in der neuen Spark 3.2-Version in PySpark integriert.
Spark integriert jetzt die Pandas-API, sodass Sie Pandas auf Spark ausführen können. Wir müssen nur eine Codezeile ändern:
import pyspark.pandas as ps
Daraus können wir viele Vorteile ziehen:
- Wenn wir mit der Verwendung von Python und Pandas, aber nicht mit Spark vertraut sind, können wir den komplizierten Lernprozess weglassen und PySpark verwenden sofort.
- Eine Codebasis kann für alles verwendet werden: kleine und große Datenmengen, einzelne und verteilte Maschinen.
- Sie können Pandas-Code schneller auf dem verteilten Spark-Framework ausführen.
Besonders hervorzuheben ist der letzte Punkt.
Einerseits kann verteiltes Rechnen auf Code in Pandas angewendet werden. Und mit der Spark-Engine wird Ihr Code sogar auf einer einzelnen Maschine schneller! Die folgende Grafik zeigt den Leistungsvergleich zwischen der Ausführung von Spark auf einer Maschine mit 96 vCPUs und 384 GiBs Arbeitsspeicher und dem alleinigen Aufruf von Pandas zur Analyse eines 130 GB großen CSV-Datensatzes.
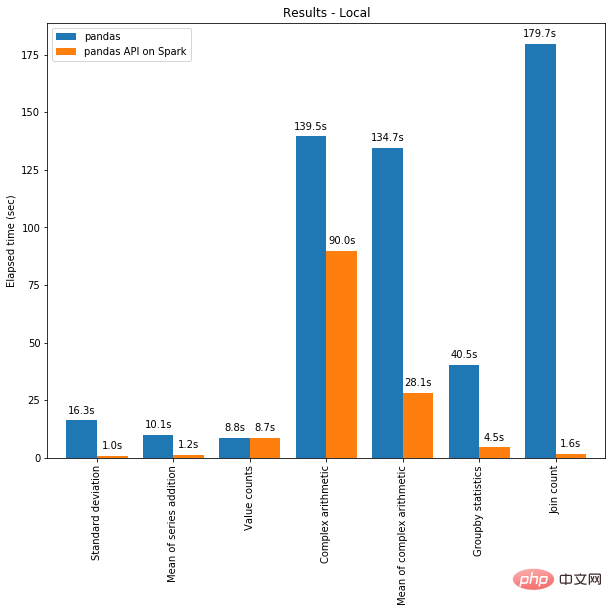
Multi-Threading und Spark SQL Catalyst Optimizer helfen beide, die Leistung zu optimieren. Beispielsweise ist der Join-Count-Vorgang bei vollständiger Codegenerierung viermal schneller: 5,9 Sekunden ohne Codegenerierung und 1,6 Sekunden mit Codegenerierung.
Spark hat besonders große Vorteile bei Verkettungsvorgängen. Der Catalyst-Abfrageoptimierer erkennt Filter, um Daten intelligent zu filtern, und kann festplattenbasierte Verknüpfungen anwenden, wohingegen Pandas es vorzieht, bei jedem Schritt alle Daten in den Speicher zu laden.
Sie können es kaum erwarten, auszuprobieren, wie Sie mit der Pandas-API auf Spark Code schreiben? Fangen wir jetzt an!
Wechsel zwischen Pandas / Pandas-on-Spark / Spark
Als Erstes müssen Sie wissen, was genau wir verwenden. Wenn Sie Pandas verwenden, verwenden Sie die Klasse pandas.core.frame.DataFrame. Wenn Sie die Pandas-API in Spark verwenden, verwenden Sie pyspark.pandas.frame.DataFrame. Obwohl die beiden ähnlich sind, sind sie nicht gleich. Der Hauptunterschied besteht darin, dass sich Ersteres in einer einzelnen Maschine befindet, während Letzteres verteilt ist.
Es ist möglich, einen Dataframe mit Pandas-on-Spark zu erstellen und ihn in Pandas zu konvertieren und umgekehrt:
# import Pandas-on-Spark import pyspark.pandas as ps # 使用 Pandas-on-Spark 创建一个 DataFrame ps_df = ps.DataFrame(range(10)) # 将 Pandas-on-Spark Dataframe 转换为 Pandas Dataframe pd_df = ps_df.to_pandas() # 将 Pandas Dataframe 转换为 Pandas-on-Spark Dataframe ps_df = ps.from_pandas(pd_df)
Beachten Sie, dass bei Verwendung mehrerer Maschinen beim Konvertieren eines Pandas-on-Spark-Dataframes in einen Pandas-Dataframe Data wird von mehreren Maschinen auf eine Maschine und umgekehrt übertragen (siehe PySpark-Anleitung [1]).
Es ist auch möglich, einen Pandas-on-Spark-Dataframe in einen Spark-DataFrame zu konvertieren und umgekehrt:
# 使用 Pandas-on-Spark 创建一个 DataFrame ps_df = ps.DataFrame(range(10)) # 将 Pandas-on-Spark Dataframe 转换为 Spark Dataframe spark_df = ps_df.to_spark() # 将 Spark Dataframe 转换为 Pandas-on-Spark Dataframe ps_df_new = spark_df.to_pandas_on_spark()
Wie ändert sich der Datentyp?
Die Datentypen sind bei der Verwendung von Pandas-on-Spark und Pandas grundsätzlich gleich. Beim Konvertieren eines Pandas-on-Spark DataFrame in einen Spark DataFrame werden die Datentypen automatisch in den entsprechenden Typ konvertiert (siehe PySpark Guide [2])
Das folgende Beispiel zeigt, wie die Datentypen bei der Konvertierung aus einem PySpark DataFrame konvertiert werden In Pandas-on-Spark DataFrame konvertieren.
>>> sdf = spark.createDataFrame([ ... (1, Decimal(1.0), 1., 1., 1, 1, 1, datetime(2020, 10, 27), "1", True, datetime(2020, 10, 27)), ... ], 'tinyint tinyint, decimal decimal, float float, double double, integer integer, long long, short short, timestamp timestamp, string string, boolean boolean, date date') >>> sdf
DataFrame[tinyint: tinyint, decimal: decimal(10,0), float: float, double: double, integer: int, long: bigint, short: smallint, timestamp: timestamp, string: string, boolean: boolean, date: date]
psdf = sdf.pandas_api() psdf.dtypes
tinyintint8 decimalobject float float32 doublefloat64 integer int32 longint64 short int16 timestampdatetime64[ns] string object booleanbool date object dtype: object
Pandas-on-Spark vs. Spark-Funktionen
DataFrame in Spark und seine am häufigsten verwendeten Funktionen in Pandas-on-Spark. Beachten Sie, dass der einzige Syntaxunterschied zwischen Pandas-on-Spark und Pandas in der Zeile import pyspark.pandas as ps besteht.
当你看完如下内容后,你会发现,即使您不熟悉 Spark,也可以通过 Pandas API 轻松使用。
导入库
# 运行Spark
from pyspark.sql import SparkSession
spark = SparkSession.builder
.appName("Spark")
.getOrCreate()
# 在Spark上运行Pandas
import pyspark.pandas as ps读取数据
以 old dog iris 数据集为例。
# SPARK
sdf = spark.read.options(inferSchema='True',
header='True').csv('iris.csv')
# PANDAS-ON-SPARK
pdf = ps.read_csv('iris.csv')选择
# SPARK
sdf.select("sepal_length","sepal_width").show()
# PANDAS-ON-SPARK
pdf[["sepal_length","sepal_width"]].head()删除列
# SPARK
sdf.drop('sepal_length').show()# PANDAS-ON-SPARK
pdf.drop('sepal_length').head()删除重复项
# SPARK sdf.dropDuplicates(["sepal_length","sepal_width"]).show() # PANDAS-ON-SPARK pdf[["sepal_length", "sepal_width"]].drop_duplicates()
筛选
# SPARK sdf.filter( (sdf.flower_type == "Iris-setosa") & (sdf.petal_length > 1.5) ).show() # PANDAS-ON-SPARK pdf.loc[ (pdf.flower_type == "Iris-setosa") & (pdf.petal_length > 1.5) ].head()
计数
# SPARK sdf.filter(sdf.flower_type == "Iris-virginica").count() # PANDAS-ON-SPARK pdf.loc[pdf.flower_type == "Iris-virginica"].count()
唯一值
# SPARK
sdf.select("flower_type").distinct().show()
# PANDAS-ON-SPARK
pdf["flower_type"].unique()排序
# SPARK
sdf.sort("sepal_length", "sepal_width").show()
# PANDAS-ON-SPARK
pdf.sort_values(["sepal_length", "sepal_width"]).head()分组
# SPARK
sdf.groupBy("flower_type").count().show()
# PANDAS-ON-SPARK
pdf.groupby("flower_type").count()替换
# SPARK
sdf.replace("Iris-setosa", "setosa").show()
# PANDAS-ON-SPARK
pdf.replace("Iris-setosa", "setosa").head()连接
#SPARK sdf.union(sdf) # PANDAS-ON-SPARK pdf.append(pdf)
transform 和 apply 函数应用
有许多 API 允许用户针对 pandas-on-Spark DataFrame 应用函数,例如:
DataFrame.transform() DataFrame.apply() DataFrame.pandas_on_spark.transform_batch() DataFrame.pandas_on_spark.apply_batch() Series.pandas_on_spark.transform_batch()
每个 API 都有不同的用途,并且在内部工作方式不同。
transform 和 apply
DataFrame.transform()和DataFrame.apply()之间的主要区别在于,前者需要返回相同长度的输入,而后者不需要。
# transform
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser):
return pser + 1# 应该总是返回与输入相同的长度。
psdf.transform(pandas_plus)
# apply
psdf = ps.DataFrame({'a': [1,2,3], 'b':[5,6,7]})
def pandas_plus(pser):
return pser[pser % 2 == 1]# 允许任意长度
psdf.apply(pandas_plus)在这种情况下,每个函数采用一个 pandas Series,Spark 上的 pandas API 以分布式方式计算函数,如下所示。
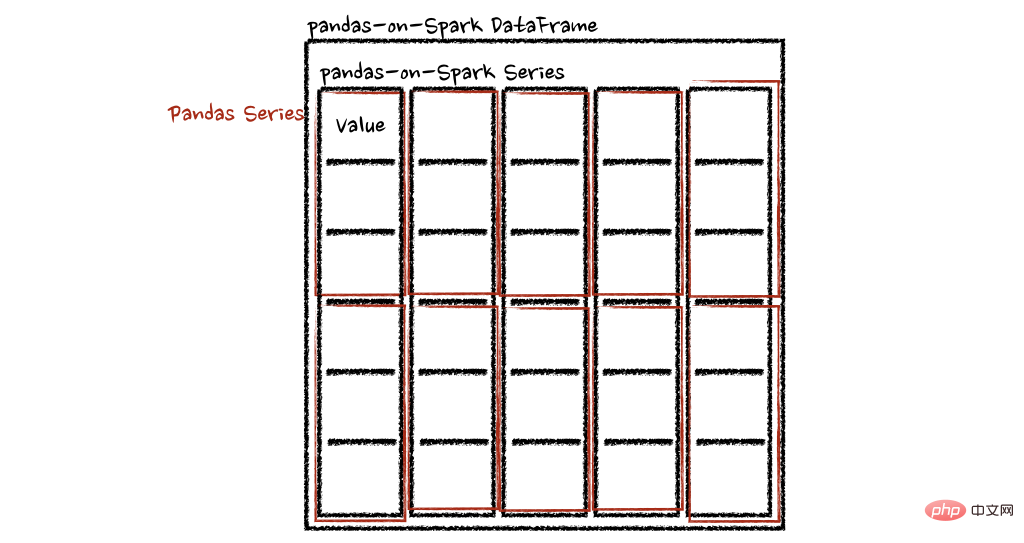
在“列”轴的情况下,该函数将每一行作为一个熊猫系列。
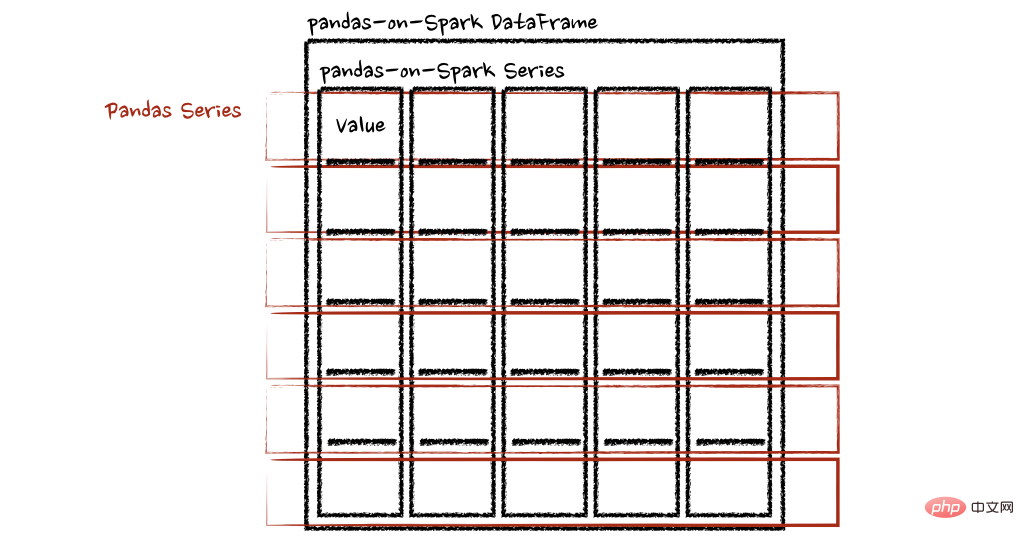
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser):
return sum(pser)# 允许任意长度
psdf.apply(pandas_plus, axis='columns')上面的示例将每一行的总和计算为pands Series
pandas_on_spark.transform_batch和pandas_on_spark.apply_batch
batch 后缀表示 pandas-on-Spark DataFrame 或 Series 中的每个块。API 对 pandas-on-Spark DataFrame 或 Series 进行切片,然后以 pandas DataFrame 或 Series 作为输入和输出应用给定函数。请参阅以下示例:
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf + 1# 应该总是返回与输入相同的长度。
psdf.pandas_on_spark.transform_batch(pandas_plus)
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf[pdf.a > 1]# 允许任意长度
psdf.pandas_on_spark.apply_batch(pandas_plus)两个示例中的函数都将 pandas DataFrame 作为 pandas-on-Spark DataFrame 的一个块,并输出一个 pandas DataFrame。Spark 上的 Pandas API 将 pandas 数据帧组合为 pandas-on-Spark 数据帧。
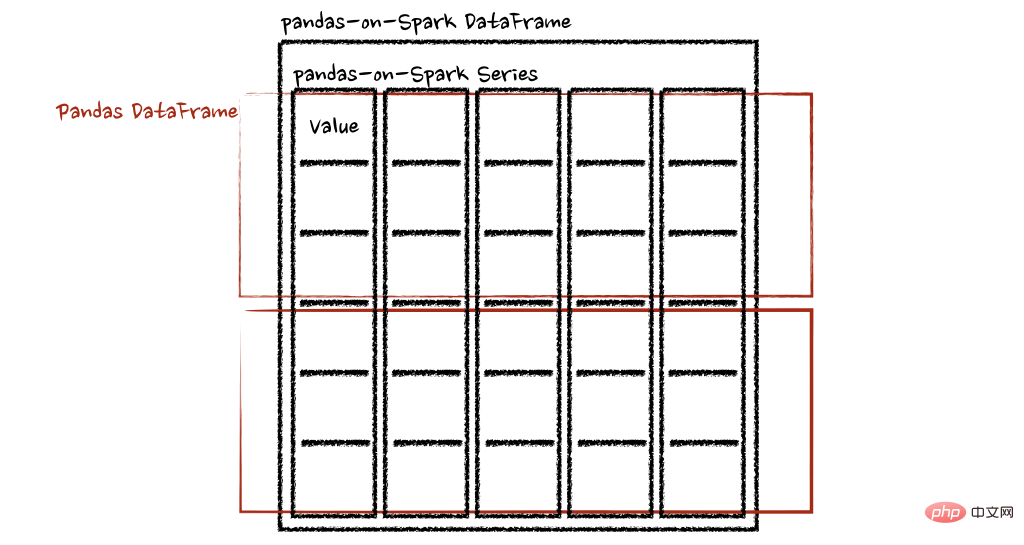
在 Spark 上使用 pandas API的注意事项
避免shuffle
某些操作,例如sort_values在并行或分布式环境中比在单台机器上的内存中更难完成,因为它需要将数据发送到其他节点,并通过网络在多个节点之间交换数据。
避免在单个分区上计算
另一种常见情况是在单个分区上进行计算。目前, DataFrame.rank 等一些 API 使用 PySpark 的 Window 而不指定分区规范。这会将所有数据移动到单个机器中的单个分区中,并可能导致严重的性能下降。对于非常大的数据集,应避免使用此类 API。
不要使用重复的列名
不允许使用重复的列名,因为 Spark SQL 通常不允许这样做。Spark 上的 Pandas API 继承了这种行为。例如,见下文:
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'b':[3, 4]})
psdf.columns = ["a", "a"]Reference 'a' is ambiguous, could be: a, a.;
此外,强烈建议不要使用区分大小写的列名。Spark 上的 Pandas API 默认不允许它。
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})Reference 'a' is ambiguous, could be: a, a.;
但可以在 Spark 配置spark.sql.caseSensitive中打开以启用它,但需要自己承担风险。
from pyspark.sql import SparkSession
builder = SparkSession.builder.appName("pandas-on-spark")
builder = builder.config("spark.sql.caseSensitive", "true")
builder.getOrCreate()
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})
psdfaA 013 124
使用默认索引
pandas-on-Spark 用户面临的一个常见问题是默认索引导致性能下降。当索引未知时,Spark 上的 Pandas API 会附加一个默认索引,例如 Spark DataFrame 直接转换为 pandas-on-Spark DataFrame。
如果计划在生产中处理大数据,请通过将默认索引配置为distributed或distributed-sequence来使其确保为分布式。
有关配置默认索引的更多详细信息,请参阅默认索引类型[3]。
在 Spark 上使用 pandas API
尽管 Spark 上的 pandas API 具有大部分与 pandas 等效的 API,但仍有一些 API 尚未实现或明确不受支持。因此尽可能直接在 Spark 上使用 pandas API。
例如,Spark 上的 pandas API 没有实现__iter__(),阻止用户将所有数据从整个集群收集到客户端(驱动程序)端。不幸的是,许多外部 API,例如 min、max、sum 等 Python 的内置函数,都要求给定参数是可迭代的。对于 pandas,它开箱即用,如下所示:
>>> import pandas as pd >>> max(pd.Series([1, 2, 3])) 3 >>> min(pd.Series([1, 2, 3])) 1 >>> sum(pd.Series([1, 2, 3])) 6
Pandas 数据集存在于单台机器中,自然可以在同一台机器内进行本地迭代。但是,pandas-on-Spark 数据集存在于多台机器上,并且它们是以分布式方式计算的。很难在本地迭代,很可能用户在不知情的情况下将整个数据收集到客户端。因此,最好坚持使用 pandas-on-Spark API。上面的例子可以转换如下:
>>> import pyspark.pandas as ps >>> ps.Series([1, 2, 3]).max() 3 >>> ps.Series([1, 2, 3]).min() 1 >>> ps.Series([1, 2, 3]).sum() 6
pandas 用户的另一个常见模式可能是依赖列表推导式或生成器表达式。但是,它还假设数据集在引擎盖下是本地可迭代的。因此,它可以在 pandas 中无缝运行,如下所示:
import pandas as pd data = [] countries = ['London', 'New York', 'Helsinki'] pser = pd.Series([20., 21., 12.], index=countries) for temperature in pser: assert temperature > 0 if temperature > 1000: temperature = None data.append(temperature ** 2) pd.Series(data, index=countries)
London400.0 New York441.0 Helsinki144.0 dtype: float64
但是,对于 Spark 上的 pandas API,它的工作原理与上述相同。上面的示例也可以更改为直接使用 pandas-on-Spark API,如下所示:
import pyspark.pandas as ps import numpy as np countries = ['London', 'New York', 'Helsinki'] psser = ps.Series([20., 21., 12.], index=countries) def square(temperature) -> np.float64: assert temperature > 0 if temperature > 1000: temperature = None return temperature ** 2 psser.apply(square)
London400.0 New York441.0 Helsinki144.0
减少对不同 DataFrame 的操作
Spark 上的 Pandas API 默认不允许对不同 DataFrame(或 Series)进行操作,以防止昂贵的操作。只要有可能,就应该避免这种操作。
写在最后
到目前为止,我们将能够在 Spark 上使用 Pandas。这将会导致Pandas 速度的大大提高,迁移到 Spark 时学习曲线的减少,以及单机计算和分布式计算在同一代码库中的合并。
参考资料
[1]PySpark 指南: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/pandas_pyspark.html
[2]PySpark 指南: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/types.html
[3]默认索引类型: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/options.html#default-index-type
Das obige ist der detaillierte Inhalt vonPandas und PySpark bündeln ihre Kräfte, um sowohl Funktionalität als auch Geschwindigkeit zu erreichen!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 Lösung häufiger Pandas-Installationsprobleme: Interpretation und Lösungen für Installationsfehler
Feb 19, 2024 am 09:19 AM
Lösung häufiger Pandas-Installationsprobleme: Interpretation und Lösungen für Installationsfehler
Feb 19, 2024 am 09:19 AM
Pandas-Installations-Tutorial: Analyse häufiger Installationsfehler und ihrer Lösungen. Es sind spezifische Codebeispiele erforderlich. Einführung: Pandas ist ein leistungsstarkes Datenanalysetool, das in der Datenbereinigung, Datenverarbeitung und Datenvisualisierung weit verbreitet ist und daher in der Branche hohes Ansehen genießt der Datenwissenschaft. Aufgrund von Umgebungskonfigurations- und Abhängigkeitsproblemen können jedoch bei der Installation von Pandas einige Schwierigkeiten und Fehler auftreten. In diesem Artikel erhalten Sie ein Pandas-Installations-Tutorial und analysieren einige häufige Installationsfehler und deren Lösungen. 1. Pandas installieren
 Python-Pandas-Installationsmethode
Nov 22, 2023 pm 02:33 PM
Python-Pandas-Installationsmethode
Nov 22, 2023 pm 02:33 PM
Python kann Pandas mithilfe von Pip, Conda, aus dem Quellcode und mithilfe des in die IDE integrierten Paketverwaltungstools installieren. Detaillierte Einführung: 1. Verwenden Sie pip und führen Sie den Befehl „pip install pandas“ im Terminal oder in der Eingabeaufforderung aus, um Pandas zu installieren. 2. Verwenden Sie conda und führen Sie den Befehl „conda install pandas“ im Terminal oder in der Eingabeaufforderung aus, um Pandas zu installieren Installation und mehr.
 Lesen Sie CSV-Dateien und führen Sie eine Datenanalyse mit Pandas durch
Jan 09, 2024 am 09:26 AM
Lesen Sie CSV-Dateien und führen Sie eine Datenanalyse mit Pandas durch
Jan 09, 2024 am 09:26 AM
Pandas ist ein leistungsstarkes Datenanalysetool, das verschiedene Arten von Datendateien problemlos lesen und verarbeiten kann. Unter diesen sind CSV-Dateien eines der gebräuchlichsten und am häufigsten verwendeten Datendateiformate. In diesem Artikel wird erläutert, wie Sie mit Pandas CSV-Dateien lesen und Datenanalysen durchführen, und es werden spezifische Codebeispiele bereitgestellt. 1. Importieren Sie die erforderlichen Bibliotheken. Zuerst müssen wir die Pandas-Bibliothek und andere möglicherweise benötigte verwandte Bibliotheken importieren, wie unten gezeigt: importpandasaspd 2. Lesen Sie die CSV-Datei mit Pan
 So installieren Sie Pandas in Python
Dec 04, 2023 pm 02:48 PM
So installieren Sie Pandas in Python
Dec 04, 2023 pm 02:48 PM
Schritte zum Installieren von Pandas in Python: 1. Öffnen Sie das Terminal oder die Eingabeaufforderung. 2. Geben Sie den Befehl „pip install pandas“ ein, um die Pandas-Bibliothek zu installieren. 3. Warten Sie, bis die Installation abgeschlossen ist. Anschließend können Sie die Pandas-Bibliothek importieren und verwenden im Python-Skript; 4. Stellen Sie sicher, dass Sie die entsprechende virtuelle Umgebung aktivieren, bevor Sie Pandas installieren. 5. Wenn Sie eine integrierte Entwicklungsumgebung verwenden, können Sie den Code „Pandas als PD importieren“ hinzufügen Importieren Sie die Pandas-Bibliothek.
 So lesen Sie eine TXT-Datei mit Pandas richtig
Jan 19, 2024 am 08:39 AM
So lesen Sie eine TXT-Datei mit Pandas richtig
Jan 19, 2024 am 08:39 AM
Um Pandas zum korrekten Lesen von TXT-Dateien zu verwenden, sind bestimmte Codebeispiele erforderlich. Pandas ist eine weit verbreitete Python-Datenanalysebibliothek. Sie kann zur Verarbeitung einer Vielzahl von Datentypen verwendet werden, einschließlich CSV-Dateien, Excel-Dateien, SQL-Datenbanken usw. Gleichzeitig können damit auch Textdateien, beispielsweise TXT-Dateien, gelesen werden. Beim Lesen von TXT-Dateien treten jedoch manchmal Probleme auf, z. B. Codierungsprobleme, Trennzeichenprobleme usw. In diesem Artikel erfahren Sie, wie Sie TXT mit Pandas richtig lesen
 Praktische Tipps zum Lesen von TXT-Dateien mit Pandas
Jan 19, 2024 am 09:49 AM
Praktische Tipps zum Lesen von TXT-Dateien mit Pandas
Jan 19, 2024 am 09:49 AM
Praktische Tipps zum Lesen von TXT-Dateien mit Pandas. In der Datenanalyse und Datenverarbeitung sind TXT-Dateien ein gängiges Datenformat. Die Verwendung von Pandas zum Lesen von TXT-Dateien ermöglicht eine schnelle und bequeme Datenverarbeitung. In diesem Artikel werden verschiedene praktische Techniken vorgestellt, die Ihnen dabei helfen, Pandas besser zum Lesen von TXT-Dateien zu verwenden, sowie spezifische Codebeispiele. TXT-Dateien mit Trennzeichen lesen Wenn Sie Pandas zum Lesen von TXT-Dateien mit Trennzeichen verwenden, können Sie read_c verwenden
 Pandas liest problemlos Daten aus der SQL-Datenbank
Jan 09, 2024 pm 10:45 PM
Pandas liest problemlos Daten aus der SQL-Datenbank
Jan 09, 2024 pm 10:45 PM
Datenverarbeitungstool: Pandas liest Daten in SQL-Datenbanken und erfordert spezifische Codebeispiele. Da die Datenmenge weiter wächst und ihre Komplexität zunimmt, ist die Datenverarbeitung zu einem wichtigen Bestandteil der modernen Gesellschaft geworden. Im Datenverarbeitungsprozess ist Pandas für viele Datenanalysten und Wissenschaftler zu einem der bevorzugten Tools geworden. In diesem Artikel wird die Verwendung der Pandas-Bibliothek zum Lesen von Daten aus einer SQL-Datenbank vorgestellt und einige spezifische Codebeispiele bereitgestellt. Pandas ist ein leistungsstarkes Datenverarbeitungs- und Analysetool auf Basis von Python
 Vorstellung der effizienten Datendeduplizierungsmethode in Pandas: Tipps zum schnellen Entfernen doppelter Daten
Jan 24, 2024 am 08:12 AM
Vorstellung der effizienten Datendeduplizierungsmethode in Pandas: Tipps zum schnellen Entfernen doppelter Daten
Jan 24, 2024 am 08:12 AM
Das Geheimnis der Pandas-Deduplizierungsmethode: eine schnelle und effiziente Methode zur Datendeduplizierung, die spezifische Codebeispiele erfordert. Bei der Datenanalyse und -verarbeitung kommt es häufig zu Duplikaten in den Daten. Doppelte Daten können die Analyseergebnisse verfälschen, daher ist die Deduplizierung ein sehr wichtiger Schritt. Pandas, eine leistungsstarke Datenverarbeitungsbibliothek, bietet eine Vielzahl von Methoden zur Datendeduplizierung. In diesem Artikel werden einige häufig verwendete Deduplizierungsmethoden vorgestellt und spezifische Codebeispiele angehängt. Der häufigste Fall der Deduplizierung basierend auf einer einzelnen Spalte basiert darauf, ob der Wert einer bestimmten Spalte dupliziert wird.
