

So implementieren Sie ein Prozessorchestrierungs-Framework in Java

Prozessregistrierung
Wir haben bereits erwähnt, dass wir das Registrierungsprozessmodell in Form von YML, Eigenschaften, XML, JSON und Schnittstellen unterstützen müssen, um das widerzuspiegeln. Single-Responsibility-PrinzipWir müssen die Logik des Parsens eines Formats unabhängig verarbeiten. Um das -Prinzip der Erweiterungsentwicklung und des Abschlusses von Modifikationen widerzuspiegeln, definieren wir zunächst eine Reihe von Schnittstellen und übergeben Sie dann die Fabrikmodell-Formel. Stellen Sie die entsprechende Implementierungslogik bereit. Hier ist die Fabrik der Benutzer, der die spezifische Implementierung über die Schnittstelle aufruft, und die Implementierung hier ist der Anbieter, der ebenfalls eine Reihe von # ist. 🎜🎜#Strategiemuster.
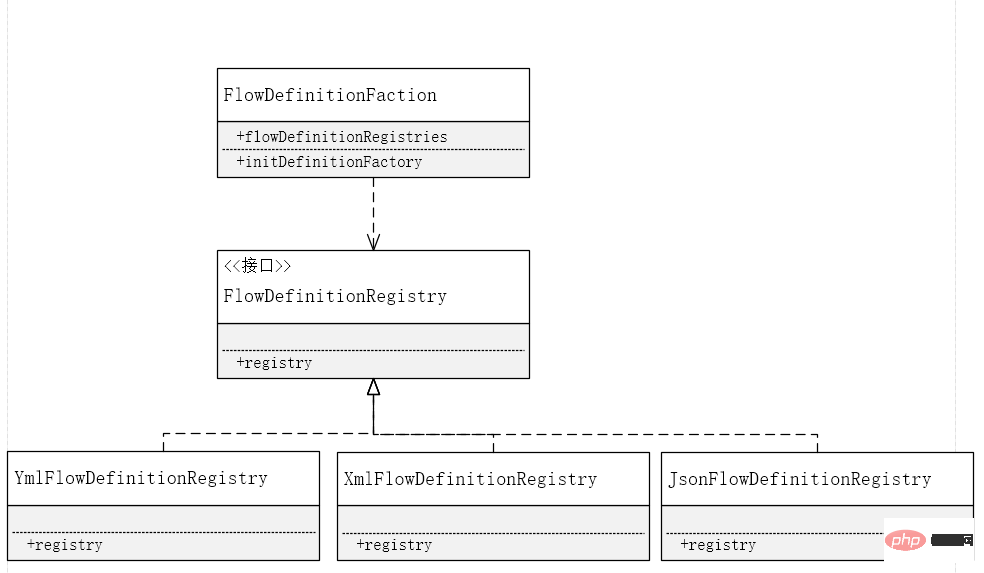
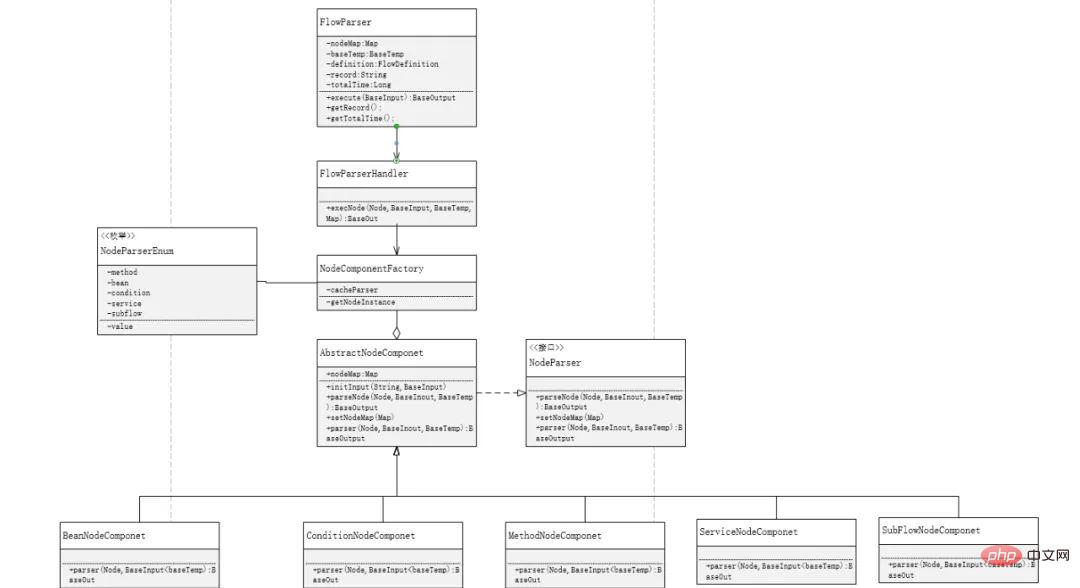
Werksmodus erforderlich ist. , und es muss für die Entwicklung und Änderung externer Erweiterungen geschlossen werden. Um Knoten hinzuzufügen, müssen Sie keine andere Codelogik verwenden. Sie müssen lediglich einen Knotenparser in der Factory-Funktion hinzufügen. Gleichzeitig definieren wir hier eine Kartensammlung zur Verwendung in Das Analyseobjekt wird beim Laden der Factory-Funktion erstellt, anstatt bei jeder Analyse einen Parser zu erstellen, wodurch unnötiger Speicher reduziert wird
Der Code ist wie folgt:<code>public class NodeComponentFactory {<br><br> private final static Map<string> cacheParser = new HashMap();<br><br> static {<br> cacheParser.put(NodeParserEnum.method.name(),new MethodNodeComponent());<br> cacheParser.put(NodeParserEnum.bean.name(),new BeanNodeComponent());<br> cacheParser.put(NodeParserEnum.condition.name(),new ConditionNodeComponent());<br> cacheParser.put(NodeParserEnum.service.name(),new ServiceNodeComponent());<br> cacheParser.put(NodeParserEnum.subflow.name(),new SubFlowNodeComponent());<br> }<br><br> public static NodeParser getNodeInstance(String nodeName){<br> return cacheParser.get(nodeName);<br> }<br>}<br></string></code>Abhängigkeitsinversion Das Designprinzip besteht darin, dass auf das obere Modul über die abhängige Schnittstelle zugegriffen wird. Das nächste Modul erbt die abstrakte Klasse und verwendet auch Strategiemuster, um Schnittstellenaufrufe durchzuführen. Im logischen Implementierungsprozess werden wir feststellen, dass viele Schritte wiederholt werden, z. B. das Initialisieren von Eingabeparametern und das Ausführen von Datensätzen. Wir fügen den gesamten wiederholten Inhalt in abstrakte Klassen ein und verwenden Vorlagenmodus, um dies zu ermöglichen Prozessknoten konzentrieren sich nur auf die Analyseebene.
<code>public abstract class AbstractNodeComponent implements NodeParser{<br><br> public Map<string node> nodeMap;<br><br><br> /**<br> * 初始化参数<br> * @param inputUrl<br> * @param baseInput<br> * @return<br> */<br> public BaseInput initInput(String inputUrl, BaseInput baseInput){<br> BaseInput baseInputTarget = ClassUtil.newInstance(inputUrl, BaseInput.class);<br> BeanUtils.copyProperties(baseInput,baseInputTarget);<br> return baseInputTarget;<br> }<br><br><br> /**<br> * 解析节点信息<br> * @param node 节点信息<br> * @param baseInput 请求参数<br> * @param baseTemp 临时上下文<br> * @return<br> */<br> public BaseOutput parserNode(Node node, BaseInput baseInput, BaseTemp baseTemp){<br> baseTemp.setFlowRecord(baseTemp.getFlowRecord().append(FlowConstants.NODEKEY+FlowConstants.NODE+FlowConstants.COLON+node.getId()));<br> BaseOutput baseOutput = parser(node, baseInput, baseTemp);<br> return baseOutput;<br> };<br><br> @Override<br> public void setNodeMap(Map<string node> nodeMap) {<br> this.nodeMap = nodeMap;<br> }<br><br> @Override<br> public abstract BaseOutput parser(Node node, BaseInput baseInput, BaseTemp baseTemp);<br><br>}</string></string></code>Prinzip der Einzelverantwortung widerzuspiegeln. Nur durch eine sehr feine Aufteilung der Ausführungsfunktionen können sie in jedem Prozess der Prozessausführung flexibel kombiniert werden , Sie können mehrere Komponenten sehen. Die erste ist der Eingang zur einheitlichen Ausführung des Prozesses. Es gibt zwei Orte, an denen sie verwendet wird, die erste ist die Schnittstelle für externe Aufrufe, die zweite ist der Einstiegspunkt für untergeordnete. Die zweite Komponente ist die einheitliche Ladeverwaltungskomponente, die oben erwähnte Factory-Klasse. Der Parser wird verwendet, um die Operationen verschiedener Knotentypen während des Entwurfsprozesses zu implementieren Prozesse, Management und Knoten müssen bekannt sein, um die Kopplung zu reduzieren. Nur so können verschiedene Komponenten flexibel zusammengestellt werden.
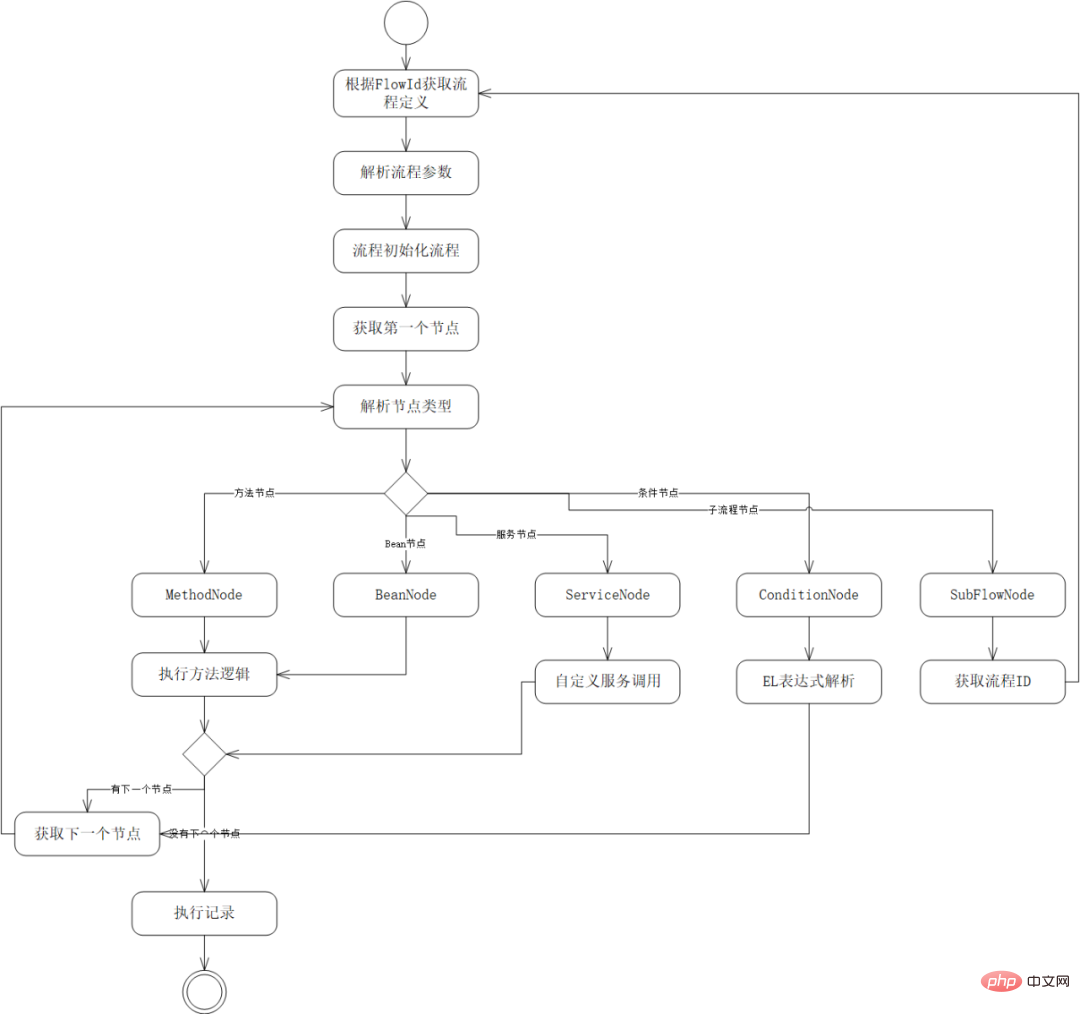
Das obige ist der detaillierte Inhalt vonSo implementieren Sie ein Prozessorchestrierungs-Framework in Java. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1659
1659
 14
1416
52
1310
25
1259
29
1233
24
14
1416
52
1310
25
1259
29
1233
24

 Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Java 8 führt die Stream -API ein und bietet eine leistungsstarke und ausdrucksstarke Möglichkeit, Datensammlungen zu verarbeiten. Eine häufige Frage bei der Verwendung von Stream lautet jedoch: Wie kann man von einem Foreach -Betrieb brechen oder zurückkehren? Herkömmliche Schleifen ermöglichen eine frühzeitige Unterbrechung oder Rückkehr, aber die Stream's foreach -Methode unterstützt diese Methode nicht direkt. In diesem Artikel werden die Gründe erläutert und alternative Methoden zur Implementierung vorzeitiger Beendigung in Strahlverarbeitungssystemen erforscht. Weitere Lektüre: Java Stream API -Verbesserungen Stream foreach verstehen Die Foreach -Methode ist ein Terminalbetrieb, der einen Vorgang für jedes Element im Stream ausführt. Seine Designabsicht ist
 PHP: Eine Schlüsselsprache für die Webentwicklung
Apr 13, 2025 am 12:08 AM
PHP: Eine Schlüsselsprache für die Webentwicklung
Apr 13, 2025 am 12:08 AM
PHP ist eine Skriptsprache, die auf der Serverseite weit verbreitet ist und insbesondere für die Webentwicklung geeignet ist. 1.PHP kann HTML einbetten, HTTP -Anforderungen und Antworten verarbeiten und eine Vielzahl von Datenbanken unterstützt. 2.PHP wird verwendet, um dynamische Webinhalte, Prozessformdaten, Zugriffsdatenbanken usw. mit starker Community -Unterstützung und Open -Source -Ressourcen zu generieren. 3. PHP ist eine interpretierte Sprache, und der Ausführungsprozess umfasst lexikalische Analyse, grammatikalische Analyse, Zusammenstellung und Ausführung. 4.PHP kann mit MySQL für erweiterte Anwendungen wie Benutzerregistrierungssysteme kombiniert werden. 5. Beim Debuggen von PHP können Sie Funktionen wie error_reporting () und var_dump () verwenden. 6. Optimieren Sie den PHP-Code, um Caching-Mechanismen zu verwenden, Datenbankabfragen zu optimieren und integrierte Funktionen zu verwenden. 7
 PHP vs. Python: Verständnis der Unterschiede
Apr 11, 2025 am 12:15 AM
PHP vs. Python: Verständnis der Unterschiede
Apr 11, 2025 am 12:15 AM
PHP und Python haben jeweils ihre eigenen Vorteile, und die Wahl sollte auf Projektanforderungen beruhen. 1.PHP eignet sich für die Webentwicklung mit einfacher Syntax und hoher Ausführungseffizienz. 2. Python eignet sich für Datenwissenschaft und maschinelles Lernen mit präziser Syntax und reichhaltigen Bibliotheken.
 Php gegen andere Sprachen: Ein Vergleich
Apr 13, 2025 am 12:19 AM
Php gegen andere Sprachen: Ein Vergleich
Apr 13, 2025 am 12:19 AM
PHP eignet sich für die Webentwicklung, insbesondere für die schnelle Entwicklung und Verarbeitung dynamischer Inhalte, ist jedoch nicht gut in Anwendungen auf Datenwissenschaft und Unternehmensebene. Im Vergleich zu Python hat PHP mehr Vorteile in der Webentwicklung, ist aber nicht so gut wie Python im Bereich der Datenwissenschaft. Im Vergleich zu Java wird PHP in Anwendungen auf Unternehmensebene schlechter, ist jedoch flexibler in der Webentwicklung. Im Vergleich zu JavaScript ist PHP in der Back-End-Entwicklung präziser, ist jedoch in der Front-End-Entwicklung nicht so gut wie JavaScript.
 PHP vs. Python: Kernmerkmale und Funktionen
Apr 13, 2025 am 12:16 AM
PHP vs. Python: Kernmerkmale und Funktionen
Apr 13, 2025 am 12:16 AM
PHP und Python haben jeweils ihre eigenen Vorteile und eignen sich für verschiedene Szenarien. 1.PHP ist für die Webentwicklung geeignet und bietet integrierte Webserver und reichhaltige Funktionsbibliotheken. 2. Python eignet sich für Datenwissenschaft und maschinelles Lernen mit prägnanter Syntax und einer leistungsstarken Standardbibliothek. Bei der Auswahl sollte anhand der Projektanforderungen festgelegt werden.
 Java -Programm, um das Kapselvolumen zu finden
Feb 07, 2025 am 11:37 AM
Java -Programm, um das Kapselvolumen zu finden
Feb 07, 2025 am 11:37 AM
Kapseln sind dreidimensionale geometrische Figuren, die aus einem Zylinder und einer Hemisphäre an beiden Enden bestehen. Das Volumen der Kapsel kann berechnet werden, indem das Volumen des Zylinders und das Volumen der Hemisphäre an beiden Enden hinzugefügt werden. In diesem Tutorial wird erörtert, wie das Volumen einer bestimmten Kapsel in Java mit verschiedenen Methoden berechnet wird. Kapselvolumenformel Die Formel für das Kapselvolumen lautet wie folgt: Kapselvolumen = zylindrisches Volumenvolumen Zwei Hemisphäre Volumen In, R: Der Radius der Hemisphäre. H: Die Höhe des Zylinders (ohne die Hemisphäre). Beispiel 1 eingeben Radius = 5 Einheiten Höhe = 10 Einheiten Ausgabe Volumen = 1570,8 Kubikeinheiten erklären Berechnen Sie das Volumen mithilfe der Formel: Volumen = π × R2 × H (4
 Auswirkungen von PHP: Webentwicklung und darüber hinaus
Apr 18, 2025 am 12:10 AM
Auswirkungen von PHP: Webentwicklung und darüber hinaus
Apr 18, 2025 am 12:10 AM
PhPhas significantantyPactedWebDevelopmentAndendendsbeyondit.1) iTpowersMAjorPlatforms-LikewordpressandExcelsInDatabaseInteractions.2) php'SadaptabilityAllowStoscaleForLargeApplicationsfraMe-Linien-Linien-Linien-Linienkripte
 PHP: Die Grundlage vieler Websites
Apr 13, 2025 am 12:07 AM
PHP: Die Grundlage vieler Websites
Apr 13, 2025 am 12:07 AM
Die Gründe, warum PHP für viele Websites der bevorzugte Technologie -Stack ist, umfassen die Benutzerfreundlichkeit, die starke Unterstützung der Community und die weit verbreitete Verwendung. 1) Einfach zu erlernen und zu bedienen, geeignet für Anfänger. 2) eine riesige Entwicklergemeinschaft und eine reichhaltige Ressourcen haben. 3) in WordPress, Drupal und anderen Plattformen häufig verwendet. 4) Integrieren Sie eng in Webserver, um die Entwicklung der Entwicklung zu vereinfachen.
