

Erhalten Sie die Ajax-Anfrage und analysieren Sie die erforderlichen Felder in JSON
Speichern Sie die Daten in Excel
#🎜🎜 #Speichern Sie die Daten zur bequemen Analyse in MySQL in fünf Städten#🎜 🎜#2. Seitenstruktur
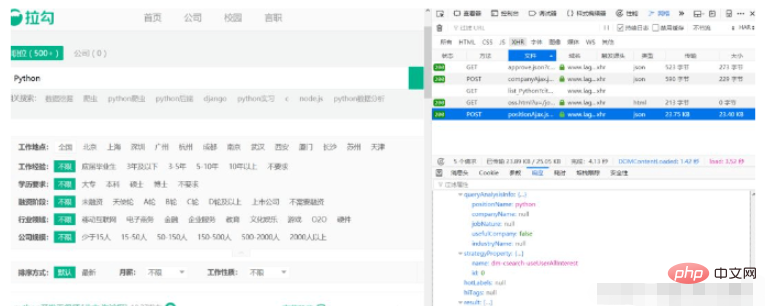 Wir klicken auf die Registerkarte „Parameter“ wie folgt:
Wir klicken auf die Registerkarte „Parameter“ wie folgt:
Es wurde festgestellt, dass drei Formulardaten übermittelt wurden, und Es ist offensichtlich, dass kd das Schlüsselwort ist, nach dem wir gesucht haben, pn ist die aktuelle Seitenzahl. Stellen Sie einfach die Standardeinstellung ein, machen Sie sich darüber keine Sorgen. Jetzt müssen Sie nur noch eine Anfrage zum Herunterladen von 30 Seiten mit Daten erstellen.
4. Erstellen Sie eine Anfrage und analysieren Sie die Daten
data = {'first': 'true', 'pn': page, 'kd': lang_name}und verwenden dann Anfragen, um die URL-Adresse anzufordern. Die analysierten JSON-Daten sind fertig. Da Lagou strenge Einschränkungen für Crawler hat, müssen wir alle Header-Felder im Browser hinzufügen und das Crawler-Intervall später auf 10 bis 20 Sekunden einstellen, damit die Daten normal abgerufen werden können.
import requests
def get_json(url, page, lang_name):
headers = {
'Host': 'www.lagou.com',
'Connection': 'keep-alive',
'Content-Length': '23',
'Origin': 'https://www.lagou.com',
'X-Anit-Forge-Code': '0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'X-Anit-Forge-Token': 'None',
'Referer': 'https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7'
}
data = {'first': 'false', 'pn': page, 'kd': lang_name}
json = requests.post(url, data, headers=headers).json()
list_con = json['content']['positionResult']['result']
info_list = []
for i in list_con:
info = []
info.append(i.get('companyShortName', '无'))
info.append(i.get('companyFullName', '无'))
info.append(i.get('industryField', '无'))
info.append(i.get('companySize', '无'))
info.append(i.get('salary', '无'))
info.append(i.get('city', '无'))
info.append(i.get('education', '无'))
info_list.append(info)
return info_list4. Alle Daten abrufen
def main():
lang_name = 'python'
wb = Workbook()
conn = get_conn()
for i in ['北京', '上海', '广州', '深圳', '杭州']:
page = 1
ws1 = wb.active
ws1.title = lang_name
url = 'https://www.lagou.com/jobs/positionAjax.json?city={}&needAddtionalResult=false'.format(i)
while page < 31:
info = get_json(url, page, lang_name)
page += 1
import time
a = random.randint(10, 20)
time.sleep(a)
for row in info:
insert(conn, tuple(row))
ws1.append(row)
conn.close()
wb.save('{}职位信息.xlsx'.format(lang_name))
if __name__ == '__main__':
main()Das obige ist der detaillierte Inhalt vonSo verwenden Sie Python zum Implementieren von Jobanalyseberichten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



