

Die Image Rescaling (LR)-Aufgabe optimiert gemeinsam Bild-Downsampling- und Upsampling-Vorgänge, indem sie die Bildauflösung reduziert und wiederherstellt, um Speicherplatz oder Übertragungsbandbreite zu sparen. In praktischen Anwendungen wie der mehrstufigen Verteilung von Atlasdiensten werden durch Downsampling erhaltene Bilder mit niedriger Auflösung häufig einer verlustbehafteten Komprimierung unterzogen, und eine verlustbehaftete Komprimierung führt häufig zu einer erheblichen Leistungseinbuße bestehender Algorithmen.
Kürzlich hat ByteDance - Volcano Engine Multimedia Laboratory zum ersten Mal versucht, die Bild-Resampling-Leistung unter verlustbehafteter Komprimierung zu optimieren, und ein asymmetrisches reversibles Resampling-Framework entworfen, basierend auf den beiden Beobachtungen, schlug die Antikomprimierung weiter vor Bild-Resampling-Modell SAIN. Diese Studie entkoppelt einen Satz reversibler Netzwerkmodule in zwei Teile: Resampling und Komprimierungssimulation, verwendet eine gemischte Gaußsche Verteilung, um den gemeinsamen Informationsverlust zu modellieren, der durch Auflösungsverschlechterung und Komprimierungsverzerrung verursacht wird, und kombiniert ihn mit einem differenzierbaren JPEG-Operator für End-to- Endtraining, was die Robustheit gegenüber gängigen Komprimierungsalgorithmen erheblich verbessert.
In der aktuellen Forschung zum Bild-Resampling basiert die SOTA-Methode auf dem invertierbaren Netzwerk, um eine bijektive Funktion (bijektive Funktion) zu erstellen, deren positive Operation hochauflösende (HR) Bilder in niedrig aufgelöste (LR) Bilder umwandelt und eine Reihe versteckter Variablen, die der Standardnormalverteilung gehorchen. Die Umkehroperation tastet die versteckten Variablen zufällig ab und kombiniert sie mit dem LR-Bild zur Upsampling-Wiederherstellung.
Aufgrund der Eigenschaften des reversiblen Netzwerks behalten die Downsampling- und Upsampling-Operatoren ein hohes Maß an Symmetrie bei, was es schwierig macht, das komprimierte LR-Bild durch den ursprünglich erlernten Upsampling-Operator wiederherzustellen. Um die Robustheit gegenüber verlustbehafteter Komprimierung zu verbessern, schlägt diese Forschung ein kompressionsresistentes Bild-Resampling-Modell SAIN (Self-Asymmetric Invertible Network) vor, das auf einem asymmetrischen reversiblen Framework basiert.
Die Kerninnovationen des SAIN-Modells sind wie folgt:
Die Leistung des SAIN-Modells wurde unter JPEG- und WebP-Komprimierung überprüft und seine Leistung bei mehreren öffentlichen Datensätzen liegt deutlich über der des SOTA-Modells. Verwandte Forschung wurde für den AAAI 2023 Oral ausgewählt.

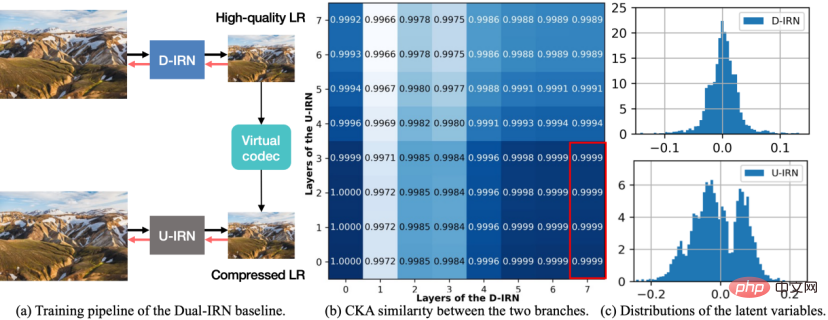
Abbildung 1 Dual-IRN-Modelldiagramm.
Um die Antikomprimierungsleistung zu verbessern, entwarf diese Forschung zunächst ein asymmetrisches reversibles Bild-Resampling-Framework und schlug das Basisschema Dual-IRN-Modell vor. Nach einer eingehenden Analyse der Mängel dieses Schemas erfolgte eine weitere Optimierung durchgeführt Das SAIN-Modell wird vorgeschlagen. Wie in der Abbildung oben gezeigt, enthält das Dual-IRN-Modell zwei Zweige, wobei D-IRN und U-IRN zwei Sätze reversibler Netzwerke sind, die die Bijektion zwischen dem HR-Bild und dem LR-Bild vor bzw. nach der Komprimierung lernen .
Während der Trainingsphase leitet das Dual-IRN-Modell den Gradienten zwischen den beiden Zweigen durch den differenzierbaren JPEG-Operator. In der Testphase verwendet das Modell D-IRN zum Downsampling, um qualitativ hochwertige LR-Bilder zu erhalten. Nach der echten Komprimierung in der realen Umgebung verwendet das Modell dann U-IRN mit Komprimierungserkennung, um die Komprimierungswiederherstellung und das Upsampling abzuschließen.
Ein solches asymmetrisches Framework ermöglicht es den Upsampling- und Downsampling-Operatoren, strikte reversible Beziehungen zu vermeiden. Es löst grundsätzlich das Problem, das durch den Komprimierungsalgorithmus verursacht wird, der die Symmetrie der Upsampling- und Downsampling-Prozesse zerstört. Im Vergleich zu SOTA verbessert sich das symmetrische Schema erheblich die Kompressionswiderstandsleistung.
Anschließend führten die Forscher weitere Analysen des Dual-IRN-Modells durch und beobachteten die folgenden zwei Phänomene:
SAIN-Modelldetails
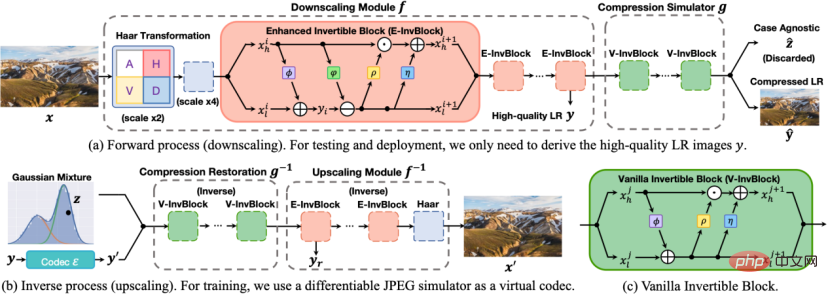
Abbildung 2 SAIN-Modelldiagramm.
Die Architektur des SAIN-Modells ist in der Abbildung oben dargestellt. Die folgenden vier Hauptverbesserungen wurden vorgenommen:
1. Gesamtrahmen . Basierend auf der Ähnlichkeit der Merkmale der mittleren Schicht wird ein Satz reversibler Netzwerkmodule in zwei Teile entkoppelt: Resampling und Komprimierungssimulation, wodurch eine selbstasymmetrische Architektur entsteht, um die Verwendung zweier vollständiger Sätze reversibler Netzwerke zu vermeiden. Verwenden Sie in der Testphase die Vorwärtstransformation
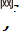
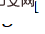
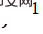
2. Netzwerkstruktur. E-InvBlock wird basierend auf der Annahme vorgeschlagen, dass der Komprimierungsverlust mithilfe von Hochfrequenzinformationen wiederhergestellt werden kann. Dem Modul wird eine additive Transformation hinzugefügt, sodass zwei Sätze von LR-Bildern vor und nach der Komprimierung beim Teilen effizient modelliert werden können eine große Anzahl von Operationen.
3. Modellierung von Informationsverlusten. Basierend auf der wahren Verteilung latenter Variablen wird vorgeschlagen, die lernbare gemischte Gaußsche Verteilung zu verwenden, um den durch Downsampling und verlustbehaftete Komprimierung verursachten gemeinsamen Informationsverlust zu modellieren und die Verteilungsparameter durch Neuparametrisierungstechniken durchgängig zu optimieren.
4. Zielfunktion . Mehrere Verlustfunktionen sollen die Reversibilität des Netzwerks einschränken und die Rekonstruktionsgenauigkeit verbessern. Gleichzeitig werden echte Komprimierungsoperationen in die Verlustfunktion eingeführt, um die Robustheit gegenüber realen Komprimierungsschemata zu verbessern. Experiment- und Effektbewertung
Der Bewertungsdatensatz ist der DIV2K-Verifizierungssatz und die vier Standardtestsätze Set5, Set14, BSD100 und Urban100.Die quantitativen Bewertungsindikatoren sind:
SAIN-Modell immer noch die optimale Leistung beibehält.
In den Vergleichsexperimenten in Tabelle 1 und Abbildung 3 liegen die PSNR- und SSIM-Werte von SAIN für alle Datensätze deutlich vor dem Bild-Resampling von SOTA. Modell. Bei relativ niedrigem QF kommt es bei bestehenden Methoden im Allgemeinen zu starken Leistungseinbußen, während das 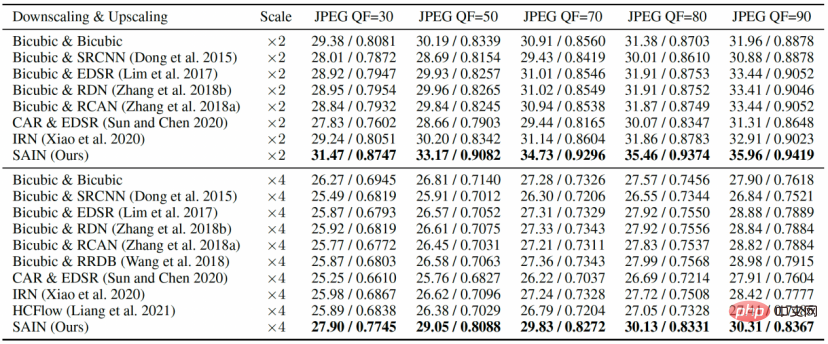
Tabelle 1 Vergleichsexperiment am DIV2K-Datensatz Vergleichen Sie die Rekonstruktionsqualität (PSNR/SSIM) bei verschiedenen JPEG-Komprimierungsqualitäten (QF). Abbildung 3 Vergleichsexperiment: Vergleichen Sie die Rekonstruktionsqualität (PSNR) unter verschiedenen JPEG-QFs an vier Standardtestsätzen.
In den Visualisierungsergebnissen von Abbildung 4 ist deutlich zu erkennen, dass das von SAIN wiederhergestellte HR-Bildmehr ist klar und genau# 🎜🎜#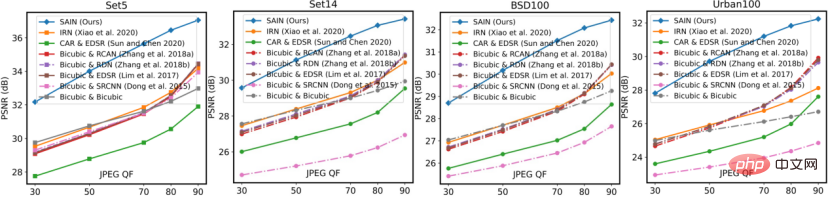 . Abbildung 4 Visualisierung verschiedener Methoden unter JPEG-Komprimierung Vergleich der Ergebnisse (4-fache Vergrößerung).
. Abbildung 4 Visualisierung verschiedener Methoden unter JPEG-Komprimierung Vergleich der Ergebnisse (4-fache Vergrößerung).
In den Ablationsexperimenten in Tabelle 2 verglichen die Forscher auch mehrere andere Kandidaten für ein Training in Kombination mit echter Kompression. Diese Kandidaten sind resistenter gegen Komprimierung als das vollständig symmetrische bestehende Modell (IRN), sind dem SAIN-Modell jedoch hinsichtlich der Anzahl der Parameter und der Genauigkeit immer noch unterlegen.
Tabelle 2 Ablation für den Gesamtrahmen und die Trainingsstrategie Experiment.

Darüber hinaus wurden im Rahmen der Studie auch Ablationsexperimente zu gemischter Gauß-Verteilung, E-InvBlock und Verlustfunktionen durchgeführt, um diesen positiven Beitrag zu den Ergebnissen zu demonstrieren.
Zusammenfassung und Ausblick
Das Volcano Engine Multimedia Laboratory schlug ein Modell vor, das auf einem asymmetrischen reversiblen Framework für das Anti-Komprimierungs-Bild-Resampling basiert: SAIN. Das Modell besteht aus zwei Teilen: Resampling und Komprimierungssimulation. Es verwendet eine gemischte Gaußsche Verteilung, um den durch Auflösungsreduzierung und Komprimierungsverzerrung verursachten gemeinsamen Informationsverlust zu modellieren. Es wird mit einem differenzierbaren JPEG-Operator für ein durchgängiges Training kombiniert -InvBlock wird vorgeschlagen, um das Modell zu verbessern. Die Anpassungsfähigkeit verbessert die Robustheit gegenüber gängigen Komprimierungsalgorithmen erheblich.
Das Volcano Engine Multimedia Laboratory ist ein Forschungsteam von ByteDance, das sich der Erforschung modernster Technologien im Multimediabereich und der Teilnahme an internationalen Standardisierungsarbeiten widmet. Seine zahlreichen innovativen Algorithmen sowie Software- und Hardwarelösungen wurden in vielen Produkten eingesetzt als Douyin und Xigua Video und bietet technische Dienstleistungen für die Unternehmenskunden von Volcano Engine. Seit der Gründung des Labors wurden viele Beiträge für die wichtigsten internationalen Konferenzen und Flaggschiff-Zeitschriften ausgewählt und gewannen mehrere internationale technische Wettbewerbsmeisterschaften, Brancheninnovationspreise und Auszeichnungen für die beste Arbeit.
In Zukunft wird das Forschungsteam die Leistung des Bild-Resampling-Modells unter verlustbehafteter Komprimierung weiter optimieren und komplexere Anwendungsszenarien wie Anti-Komprimierungs-Video-Resampling und Resampling mit beliebiger Vergrößerung weiter untersuchen.
Das obige ist der detaillierte Inhalt vonByte schlägt ein asymmetrisches Bild-Resampling-Modell vor, dessen Anti-Komprimierungsleistung SOTA bei JPEG und WebP übertrifft. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Einführung in das von vscode verwendete Framework
Einführung in das von vscode verwendete Framework
 So stellen Sie Dateien wieder her, die aus dem Papierkorb geleert wurden
So stellen Sie Dateien wieder her, die aus dem Papierkorb geleert wurden
 Was ist der Kern eines Datenbanksystems?
Was ist der Kern eines Datenbanksystems?
 Was tun, wenn die CPU-Auslastung zu hoch ist?
Was tun, wenn die CPU-Auslastung zu hoch ist?
 Verwendung der setproperty-Funktion
Verwendung der setproperty-Funktion
 js regulärer Ausdruck
js regulärer Ausdruck
 So stellen Sie gelöschte Dateien auf dem Computer wieder her
So stellen Sie gelöschte Dateien auf dem Computer wieder her
 Wie viel ist ein Bitcoin in RMB wert?
Wie viel ist ein Bitcoin in RMB wert?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



