


Wenn Sie auf mehrere Dienste zugreifen müssen, um die Verarbeitung einer Anfrage abzuschließen, z. B. bei der Implementierung der Funktion zum Hochladen von Dateien, greifen Sie zunächst auf den Redis-Cache zu, um zu überprüfen, ob der Benutzer angemeldet ist, und empfangen Sie dann den Text in der HTTP-Nachricht und speichern Sie es auf der Festplatte. Und schließlich: Was würden Sie tun, wenn Sie den Dateipfad und andere Informationen in die MySQL-Datenbank schreiben würden?
Zuerst können Sie die Blockierungs-API verwenden, um Synchronisationscode zu schreiben und ihn einfach Schritt für Schritt zu serialisieren, aber derzeit kann ein Thread natürlich nur eine Anfrage gleichzeitig verarbeiten. Wir wissen, dass die Anzahl der Threads begrenzt ist, was es unmöglich macht, Zehntausende gleichzeitiger Verbindungen herzustellen. Übermäßiger Thread-Wechsel nimmt auch CPU-Zeit in Anspruch und reduziert dadurch die Anzahl der Anfragen, die pro Sekunde verarbeitet werden können.
Um eine hohe Parallelität zu erreichen, können Sie ein asynchrones Framework wählen, nicht blockierende APIs verwenden, um die Geschäftslogik in mehrere Rückruffunktionen aufzuteilen, und durch Multiplexen eine hohe Parallelität erreichen. Zu diesem Zeitpunkt muss der Geschäftscode jedoch zu viel auf Parallelitätsdetails achten und viele Zwischenzustände beibehalten. Sobald ein Fehler in der Codelogik auftritt, gerät er in die Rückrufhölle.
Wenn Sie dies tun, ist nicht nur die Fehlerrate sehr hoch, sondern auch die Entwicklungsgeschwindigkeit des Projekts wird verlangsamt, und es besteht das Risiko, das Produkt rechtzeitig auf den Markt zu bringen. Wenn Sie die Entwicklungseffizienz berücksichtigen und gleichzeitig eine hohe Parallelität gewährleisten möchten, sind Coroutinen die beste Wahl. Es kann Code synchron schreiben und gleichzeitig einen asynchronen Betriebsmechanismus beibehalten. Dadurch wird nicht nur eine hohe Parallelität erreicht, sondern auch der Entwicklungszyklus verkürzt. Dies ist die zukünftige Entwicklungsrichtung von Hochleistungsdiensten.
Hier müssen wir darauf hinweisen, dass die Methode „Coroutine“ in Bezug auf die Parallelität nicht besser ist als die Methode „Nicht blockierend + Rückruf“. Der Grund, warum wir uns für Coroutine entscheiden, liegt darin, dass ihr Programmiermodell einfacher ist, ähnlich wie bei For Durch die Synchronisierung können wir asynchronen Code synchron schreiben. Die Methode „Nicht blockierend + Rückruf“ ist ein großartiger Test für die Programmierkenntnisse. Sobald ein Fehler auftritt, ist es schwierig, das Problem zu lokalisieren, und es kann leicht zu Problemen wie Rückrufhölle und Stapelriss kommen.
Sie werden also feststellen, dass sich die Technologie zur Lösung von Problemen mit hoher Parallelität geändert hat, von Multiprozess und Multithreading zu Asynchronität und Coroutine. In verschiedenen Szenarien lösen sie alle Probleme auf unterschiedliche Weise. Werfen wir einen Blick darauf, wie sich Lösungen mit hoher Parallelität entwickelt haben, welche Probleme Coroutinen lösen und wie sie angewendet werden sollten.
Wir wissen, dass ein Host über begrenzte Ressourcen, eine CPU, eine Festplatte und eine Netzwerkkarte verfügt. Wie kann er Hunderte von Anfragen gleichzeitig bedienen? Der Multiprozessmodus war die ursprüngliche Lösung. Der Kernel unterteilt die CPU-Ausführungszeit in viele Zeitscheiben (Zeitscheiben). Beispielsweise kann eine Sekunde in 100 Zeitscheiben zu je 10 Millisekunden unterteilt werden. Normalerweise benötigt jeder Prozess mehrere Zeitscheiben, um ihn abzuschließen eine Bitte.
Auf diese Weise kann die CPU beispielsweise aus Mikroperspektive in diesen 10 Millisekunden nur einen Prozess ausführen, aus Makroperspektive werden jedoch 100 Zeitscheiben in 1 Sekunde ausgeführt, also die Anforderungen im Prozess, zu denen jeder Zeitscheibe gehört ebenfalls zur Ausführung. Dadurch wird eine gleichzeitige Ausführung von Anforderungen erreicht.
Der Speicherplatz jedes Prozesses ist jedoch unabhängig, sodass die Verwendung mehrerer Prozesse zur Erzielung von Parallelität zwei Nachteile hat: Erstens sind die Verwaltungskosten des Kernels hoch und zweitens können Daten nicht einfach über den Speicher synchronisiert werden, was sehr unpraktisch ist . Als Ergebnis erschien der Multithread-Modus. Der Multithread-Modus löste diese beiden Probleme durch die gemeinsame Nutzung des Speicheradressraums.
Obwohl ein gemeinsam genutzter Adressraum problemlos Objekte gemeinsam nutzen kann, führt dies auch zu einem Problem: Wenn ein Thread einen Fehler macht, stürzen alle Threads im Prozess gleichzeitig ab. Aus diesem Grund bestehen Dienste wie Nginx, die Wert auf Stabilität legen, auf der Verwendung des Multiprozessmodus.
Tatsächlich ist es jedoch schwierig, eine hohe Parallelität zu erreichen, unabhängig davon, ob es auf Multiprozess oder Multithreading basiert, hauptsächlich aus den folgenden zwei Gründen.
In der folgenden Abbildung wird die Festplatten-E/A als Beispiel verwendet, um die Umschaltmethode zwischen zwei Threads mithilfe der Blockierungsmethode zum Lesen der Festplatte in mehreren Threads zu beschreiben.
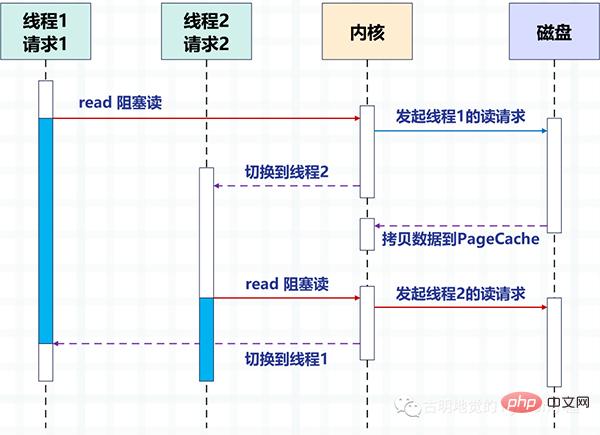
Durch Multithreading verarbeitet ein Thread eine Anfrage, um Parallelität zu erreichen. Es ist jedoch offensichtlich, dass die Anzahl der Threads, die das Betriebssystem erstellen kann, begrenzt ist, denn je mehr Threads, desto mehr Ressourcen werden belegt, und auch die Kosten für den Wechsel zwischen Threads sind relativ hoch, da dabei zwischen Kernelmodus und Benutzermodus gewechselt werden muss Modus.
Dann stellt sich die Frage: Wie können wir eine hohe Parallelität erreichen? Die Antwort lautet: „Überlassen Sie einfach die vom Kernel in der obigen Abbildung implementierte Anforderungswechselarbeit dem Benutzermoduscode.“ Asynchrone Programmierung implementiert die Anforderungsumschaltung über den Code der Anwendungsschicht und reduziert so die Umstellungskosten und den Speicherbedarf.
Die Asynchronisierung basiert auf dem E/A-Multiplexmechanismus, beispielsweise dem Epoll von Linux. Gleichzeitig muss die Blockierungsmethode in eine nicht blockierende Methode geändert werden, um den durch Kernel-Switching verursachten enormen Verbrauch zu vermeiden. Hochleistungsdienste wie Nginx und Redis sind auf Asynchronisierung angewiesen, um Millionen von Ebenen der Parallelität zu erreichen.
Die folgende Abbildung beschreibt, wie die Anforderung umgeschaltet wird, nachdem das nicht blockierende Lesen asynchroner E/A mit dem asynchronen Framework kombiniert wurde.
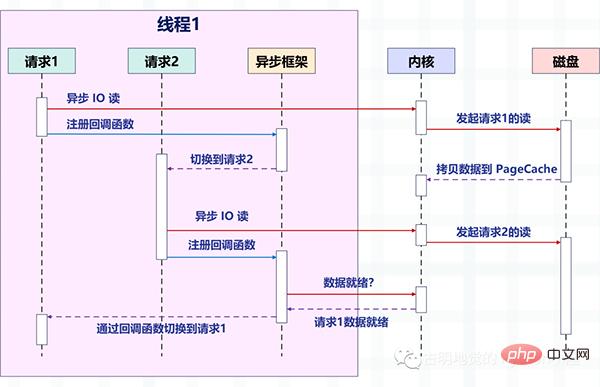
Achten Sie auf die Änderungen im Bild, aber jetzt verarbeitet ein Thread mehrere Anfragen. Dies ist die zuvor erwähnte Methode „Nicht blockierend + Rückruf“. Es basiert auf dem vom Betriebssystem bereitgestellten E/A-Multiplexing, z. B. Epoll von Linux und Kqueue von BSD.
Die Lese- und Schreibvorgänge entsprechen zu diesem Zeitpunkt einem Ereignis, und für jedes Ereignis wird eine entsprechende Rückruffunktion registriert. Dann wird der Thread nicht blockiert (da die Lese- und Schreibvorgänge zu diesem Zeitpunkt nicht blockieren), sondern kann andere Dinge tun. Diese Ereignisse werden dann von Epoll einheitlich verwaltet.
Sobald das Ereignis eintritt (wenn es lesbar und beschreibbar ist), benachrichtigt Epoll den Thread und der Thread führt dann die für das Ereignis registrierte Rückruffunktion aus.
Zum besseren Verständnis nehmen wir Redis als Beispiel, um nicht blockierendes IO und IO-Multiplexing einzuführen.
127.0.0.1:6379> get name "satori"
Zuerst können wir den Befehl get verwenden, um den Wert zu erhalten, der einem Schlüssel entspricht. Dann ist die Frage, was mit dem Redis-Server oben passiert ist.
Der Server muss zuerst auf die Anfrage des Clients hören (binden/listen), dann eine Verbindung mit dem Client herstellen, wenn sie eintrifft (akzeptieren), die Anfrage des Clients vom Socket lesen (recv) und die Anfrage analysieren (parsen). Der hier analysierte Anforderungstyp ist get, der Schlüssel ist „name“, und dann wird der entsprechende Wert gemäß dem Schlüssel abgerufen und schließlich an den Client zurückgegeben, dh Daten werden in den Socket geschrieben (senden).
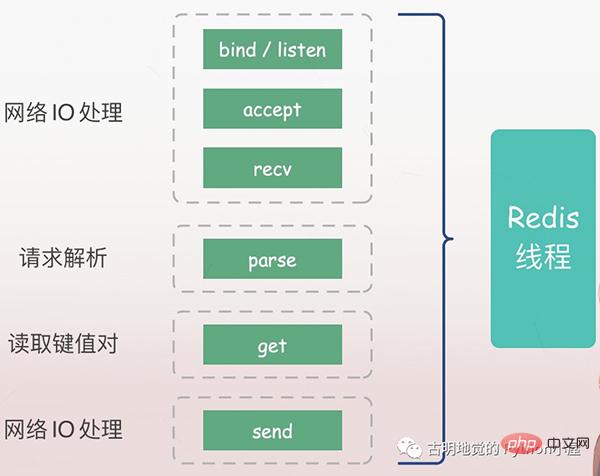
Alle oben genannten Vorgänge werden nacheinander vom Redis-Hauptthread ausgeführt, es gibt jedoch potenzielle Blockierungspunkte, nämlich Accept und Recv.
Wenn es E/A blockiert und Redis eine Verbindungsanforderung von einem Client erkennt, aber keine erfolgreiche Verbindung herstellen kann, wird der Hauptthread immer in der Akzeptanzfunktion blockiert, was dazu führt, dass andere Clients keine Verbindungen mit Redis herstellen können. Wenn Redis Daten vom Client über Recv liest und die Daten nicht angekommen sind, wird der Redis-Hauptthread im Recv-Schritt immer blockiert, sodass die Effizienz von Redis gering ist.
Aber Redis wird dies natürlich nicht zulassen, da es sich bei den oben genannten Situationen um blockierende IO handelt und Redis nicht blockierendes IO verwendet, was bedeutet, dass der Socket in den nicht blockierenden Modus versetzt wird. Im Socket-Modell gibt der Aufruf der socket()-Methode zunächst den aktiven Socket zurück; der Aufruf der bind()-Methode zum Binden der IP und des Ports und der anschließende Aufruf der listen()-Methode, um den aktiven Socket in einen Listening-Socket umzuwandeln; Schließlich ruft der Listening-Socket die Methode „accept()“ auf, um auf das Eintreffen der Client-Verbindung zu warten. Wenn die Verbindung mit dem Client hergestellt ist, gibt er den verbundenen Socket zurück und verwendet dann den verbundenen Socket zum Empfangen und Senden von Daten der Kunde.
Aber beachten Sie: Wir haben gesagt, dass im Schritt listen() der aktive Socket in einen Listening-Socket umgewandelt wird und der Typ des Listening-Sockets zu diesem Zeitpunkt blockiert. Der blockierende Typ des Listening-Sockets ist der Aufruf ()-Methode: Wenn kein Client zum Herstellen einer Verbindung vorhanden ist, wird diese immer blockiert und der Hauptthread kann zu diesem Zeitpunkt keine anderen Dinge tun. Daher können Sie es beim Listening () auf „Nicht blockierend“ einstellen, wenn keine Client-Verbindungsanforderung eintrifft, sondern direkt zurückkehrt und dies tut andere Dinge.
In ähnlicher Weise können wir beim Erstellen eines verbundenen Sockets auch dessen Typ auf „Nicht blockierend“ festlegen, da sich ein verbundener Socket vom blockierenden Typ auch beim Aufrufen von send() / recv() in einem blockierenden Zustand befindet, z. B. wenn Der Client sendet niemals Daten, der verbundene Socket wird im rev()-Schritt immer blockiert. Wenn es sich um einen nicht blockierenden Typ eines verbundenen Sockets handelt, ist es nicht erforderlich, sich im Blockierungszustand zu befinden, wenn recv () aufgerufen wird, aber keine Daten empfangen werden. Sie können auch direkt zurückkehren, um andere Dinge zu tun.
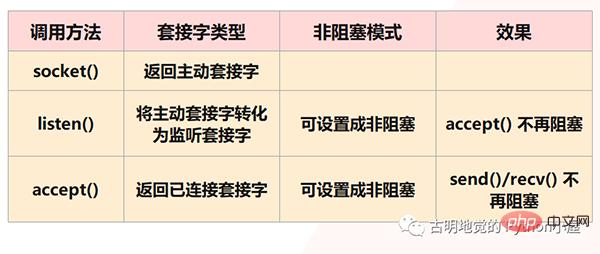
Aber zwei Punkte sind zu beachten:
1) Obwohl Accept() nicht blockiert ist, wird dort der Redis-Hauptthread verwendet Es gibt keine Client-Verbindung. Sie können andere Dinge tun, aber wenn ein Client später eine Verbindung herstellt, woher weiß Redis das? Daher muss ein Mechanismus vorhanden sein, der weiterhin auf nachfolgende Verbindungsanforderungen am Listening-Socket warten und Redis benachrichtigen kann, wenn die Anforderung eintrifft.
2) send() / recv() wird nicht mehr blockiert. Der Lese- und Schreibvorgang wird nicht mehr blockiert. Die Lese- und Schreibmethoden werden sofort abgeschlossen und zurückgegeben Ich werde die Methode verwenden, die lesen kann. Die Strategie, so viel wie möglich zu lesen und so viel wie möglich zu schreiben, um E/A-Vorgänge auszuführen, entspricht offensichtlich eher unserem Streben nach Leistung. Dies wird jedoch auch ein Problem darstellen, das heißt, wenn wir einen Lesevorgang durchführen, ist es möglich, dass nur ein Teil der Daten gelesen wurde und die restlichen Daten nicht vom Client gesendet wurden lesbar? Das Gleiche gilt für das Schreiben von Daten. Wann können die verbleibenden Daten geschrieben werden, wenn der Puffer voll ist und unsere Daten noch nicht geschrieben wurden? Daher muss es auch einen Mechanismus geben, der den verbundenen Socket weiterhin überwachen kann, während der Redis-Hauptthread andere Dinge erledigt, und Redis benachrichtigen kann, wenn Daten zum Lesen und Schreiben vorhanden sind.
Dadurch kann sichergestellt werden, dass der Redis-Thread nicht wie im Basis-IO-Modell am Blockierungspunkt wartet und auch nicht in der Lage ist, die tatsächlich ankommende Client-Verbindungsanfrage und die lesbaren und beschreibbaren Daten zu verarbeiten oben Der erwähnte Mechanismus ist IO-Multiplexing.
Der I/O-Multiplexing-Mechanismus bezieht sich auf einen Thread, der mehrere IO-Streams verarbeitet. Dies ist der Select/Poll/, den wir oft von Epoll hören. Wir werden nicht über die Unterschiede zwischen diesen drei sprechen. Sie machen alle das Gleiche, aber es gibt Unterschiede in der Leistung und den Implementierungsprinzipien. select wird von allen Systemen unterstützt, während epoll nur von Linux unterstützt wird.
Einfach ausgedrückt: Wenn Redis nur einen einzelnen Thread ausführt, ermöglicht dieser Mechanismus die gleichzeitige Existenz mehrerer Listening-Sockets und verbundener Sockets im Kernel. Der Kernel überwacht immer Verbindungsanfragen oder Datenanfragen auf diesen Sockets. Sobald eine Anfrage eintrifft, wird sie zur Verarbeitung an den Redis-Thread übergeben, wodurch der Effekt erzielt wird, dass ein Redis-Thread mehrere E/A-Streams verarbeitet.
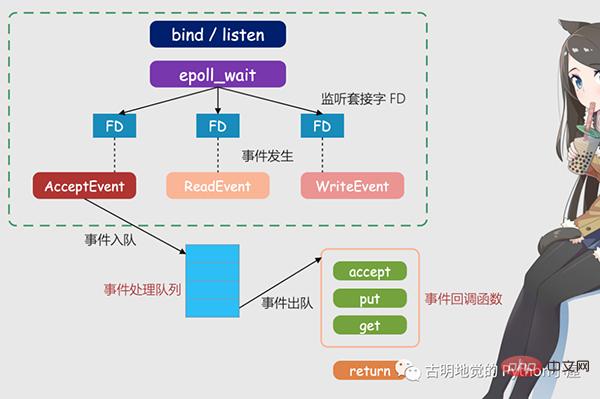
Das obige Bild ist ein Redis-IO-Modell, das auf Multiplexing basiert. Der FD im Bild ist ein Socket, der ein Listening-Socket sein kann, oder es kann ein verbundener Socket sein, und Redis verwendet den Epoll-Mechanismus, damit der Kernel diese Sockets überwachen kann. Zu diesem Zeitpunkt wird der Redis-Thread oder der Hauptthread nicht an einem bestimmten Socket blockiert, was bedeutet, dass er bei der Verarbeitung einer bestimmten Clientanforderung nicht blockiert wird. Daher kann Redis gleichzeitig eine Verbindung zu mehreren Clients herstellen und Anforderungen verarbeiten, wodurch die Parallelität verbessert wird.
Aber um den Redis-Thread zu benachrichtigen, wenn eine Anfrage eintrifft, stellt Epoll einen ereignisbasierten Rückrufmechanismus bereit, dh das Aufrufen der entsprechenden Verarbeitungsfunktion für das Auftreten verschiedener Ereignisse.
Wie funktioniert also der Rückrufmechanismus? Am Beispiel der obigen Abbildung löst Epoll zunächst das entsprechende Ereignis aus, sobald es erkennt, dass eine Anfrage auf FD eintrifft. Diese Ereignisse werden in eine Warteschlange gestellt und der Redis-Hauptthread verarbeitet die Ereigniswarteschlange kontinuierlich. Auf diese Weise muss Redis nicht ständig abfragen, ob eine Anforderung vorliegt, wodurch eine Verschwendung von Ressourcen vermieden wird.
Wenn Redis gleichzeitig Ereignisse in der Ereigniswarteschlange verarbeitet, ruft es die entsprechende Verarbeitungsfunktion auf, die ereignisbasierte Rückrufe implementiert. Da Redis die Ereigniswarteschlange verarbeitet hat, kann es zeitnah auf Clientanfragen reagieren und die Antwortleistung von Redis verbessern.
Nehmen wir als Beispiel die eigentliche Verbindungsanforderung und Datenleseanforderung und erklären sie noch einmal. Verbindungsanfragen und Datenleseanfragen entsprechen Akzeptanzereignissen bzw. Leseereignissen. Redis-Register akzeptieren bzw. erhalten Rückruffunktionen für diese beiden Ereignisse. Wenn der Linux-Kernel eine Verbindungsanfrage oder Datenleseanfrage überwacht, löst er das Akzeptanzereignis bzw. Leseereignis aus , benachrichtigen Sie dann den Hauptthread und rufen Sie die registrierte Akzeptanzfunktion oder Get-Funktion zurück.
Genau wie ein Patient, der ins Krankenhaus geht, um einen Arzt aufzusuchen, muss jeder Patient (ähnlich einer Anfrage) gesichtet, gemessen, registriert usw. werden, bevor der Arzt tatsächlich eine Diagnose stellen kann. Wenn alle diese Aufgaben von Ärzten erledigt werden, ist ihre Arbeitseffizienz sehr gering. Daher hat das Krankenhaus eine Triage-Station eingerichtet, die diese Vordiagnoseaufgaben immer übernimmt (ähnlich der Linux-Kernel-Listening-Anfrage) und sie dann zur eigentlichen Diagnose an den Arzt weiterleitet (entspricht dem Hauptthread von Redis) kann sehr effizient sein.
这里需要再补充一下:我们上面提到的异步 IO 不是真正意义上的异步 IO,而是基于 IO 多路复用实现的异步化。但 IO 多路复用本质上是同步 IO,只是它可以同时监听多个文件描述符,一旦某个描述符的读写操作就绪,就能够通知应用程序进行相应的读写操作。至于真正意义的异步 IO,操作系统也是支持的,但支持的不太理想,所以现在使用的都是 IO 多用复用,并代指异步 IO。
必须要承认的是,编写这种异步化代码能够带来很高的性能收益,Redis、Nginx 已经证明了这一点。
但是这种编程模式,在实际工作中很容易出错,因为所有阻塞函数,都需要通过非阻塞的系统调用加上回调注册的方式拆分成两个函数。说白了就是我们的逻辑不能够直接执行,必须把它们放在一个单独的函数里面,然后这个函数以回调的方式注册给 IO 多路复用。
这种编程模式违反了软件工程的内聚性原则,函数之间同步数据也更复杂。特别是条件分支众多、涉及大量系统调用时,异步化的改造工作会非常困难,尽管它的性能很高。
下面我们用 Python 编写一段代码,实际体验一下这种编程模式,看看它复杂在哪里。
from urllib.parse import urlparse
import socket
from io import BytesIO
# selectors 里面提供了多种"多路复用器"
# 除了 select、poll、epoll 之外
# 还有 kqueue,这个是针对 BSD 平台的
try:
from selectors import (
SelectSelector,
PollSelector,
EpollSelector,
KqueueSelector
)
except ImportError:
pass
# 由于种类比较多,所以提供了DefaultSelector
# 会根据当前的系统种类,自动选择一个合适的多路复用器
from selectors import (
DefaultSelector,
EVENT_READ,# 读事件
EVENT_WRITE,# 写事件
)
class RequestHandler:
"""
向指定的 url 发请求
获取返回的内容
"""
selector = DefaultSelector()
tasks = {"unfinished": 0}
def __init__(self, url):
"""
:param url: http://localhost:9999/v1/index
"""
self.tasks["unfinished"] += 1
url = urlparse(url)
# 根据 url 解析出 域名、端口、查询路径
self.netloc = url.netloc# 域名:端口
self.path = url.path or "/"# 查询路径
# 创建 socket
self.client = socket.socket()
# 设置成非阻塞
self.client.setblocking(False)
# 用于接收数据的缓存
self.buffer = BytesIO()
def get_result(self):
"""
发送请求,进行下载
:return:
"""
# 连接到指定的服务器
# 如果没有 : 说明只有域名没有端口
# 那么默认访问 80 端口
if ":" not in self.netloc:
host, port = self.netloc, 80
else:
host, port = self.netloc.split(":")
# 由于 socket 非阻塞,所以连接可能尚未建立好
try:
self.client.connect((host, int(port)))
except BlockingIOError:
pass
# 我们上面是建立连接,连接建立好就该发请求了
# 但是连接什么时候建立好我们并不知道,只能交给操作系统
# 所以我们需要通过 register 给 socket 注册一个回调函数
# 参数一:socket 的文件描述符
# 参数二:事件
# 参数三:当事件发生时执行的回调函数
self.selector.register(self.client.fileno(),
EVENT_WRITE,
self.send)
# 表示当 self.client 这个 socket 满足可写时
# 就去执行 self.send
# 翻译过来就是连接建立好了,就去发请求
# 可以看到,一个阻塞调用,我们必须拆成两个函数去写
def send(self, key):
"""
连接建立好之后,执行的回调函数
回调需要接收一个参数,这是一个 namedtuple
内部有如下字段:'fileobj', 'fd', 'events', 'data'
key.fd 就是 socket 的文件描述符
key.data 就是给 socket 绑定的回调
:param key:
:return:
"""
payload = (f"GET {self.path} HTTP/1.1rn"
f"Host: {self.netloc}rn"
"Connection: closernrn")
# 执行此函数,说明事件已经触发
# 我们要将绑定的回调函数取消
self.selector.unregister(key.fd)
# 发送请求
self.client.send(payload.encode("utf-8"))
# 请求发送之后就要接收了,但是啥时候能接收呢?
# 还是要交给操作系统,所以仍然需要注册回调
self.selector.register(self.client.fileno(),
EVENT_READ,
self.recv)
# 表示当 self.client 这个 socket 满足可读时
# 就去执行 self.recv
# 翻译过来就是数据返回了,就去接收数据
def recv(self, key):
"""
数据返回时执行的回调函数
:param key:
:return:
"""
# 接收数据,但是只收了 1024 个字节
# 如果实际返回的数据超过了 1024 个字节怎么办?
data = self.client.recv(1024)
# 很简单,只要数据没收完,那么数据到来时就会可读
# 那么会再次调用此函数,直到数据接收完为止
# 注意:此时是非阻塞的,数据有多少就收多少
# 没有接收的数据,会等到下一次再接收
# 所以这里不能写 while True
if data:
# 如果有数据,那么写入到 buffer 中
self.buffer.write(data)
else:
# 否则说明数据读完了,那么将注册的回调取消
self.selector.unregister(key.fd)
# 此时就拿到了所有的数据
all_data = self.buffer.getvalue()
# 按照 rnrn 进行分隔得到列表
# 第一个元素是响应头,第二个元素是响应体
result = all_data.split(b"rnrn")[1]
print(f"result: {result.decode('utf-8')}")
self.client.close()
self.tasks["unfinished"] -= 1
@classmethod
def run_until_complete(cls):
# 基于 IO 多路复用创建事件循环
# 驱动内核不断轮询 socket,检测事件是否发生
# 当事件发生时,调用相应的回调函数
while cls.tasks["unfinished"]:
# 轮询,返回事件已经就绪的 socket
ready = cls.selector.select()
# 这个 key 就是回调里面的 key
for key, mask in ready:
# 拿到回调函数并调用,这一步需要我们手动完成
callback = key.data
callback(key)
# 因此当事件发生时,调用绑定的回调,就是这么实现的
# 整个过程就是给 socket 绑定一个事件 + 回调
# 事件循环不停地轮询检测,一旦事件发生就会告知我们
# 但是调用回调不是内核自动完成的,而是由我们手动完成的
# "非阻塞 + 回调 + 基于 IO 多路复用的事件循环"
# 所有框架基本都是这个套路一个简单的 url 获取,居然要写这么多代码,而它的好处就是性能高,因为不用把时间浪费在建立连接、等待数据上面。只要有事件发生,就会执行相应的回调,极大地提高了 CPU 利用率。而且这是单线程,也没有线程切换带来的开销。
那么下面测试一下吧。
import time
start = time.perf_counter()
for _ in range(10):
# 这里面只是注册了回调,但还没有真正执行
RequestHandler(url="https://localhost:9999/index").get_result()
# 创建事件循环,驱动执行
RequestHandler.run_until_complete()
end = time.perf_counter()
print(f"总耗时: {end - start}")我用 FastAPI 编写了一个服务,为了更好地看到现象,服务里面刻意 sleep 了 1 秒。然后发送十次请求,看看效果如何。
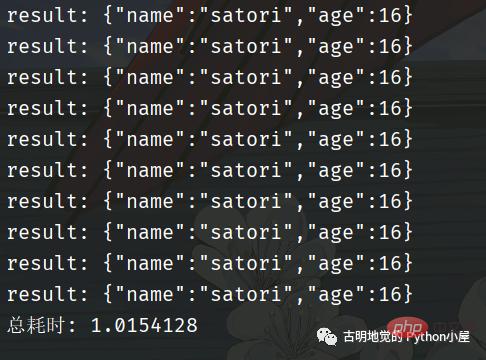
总共耗时 1 秒钟,我们再采用同步的方式进行编写,看看效果如何。
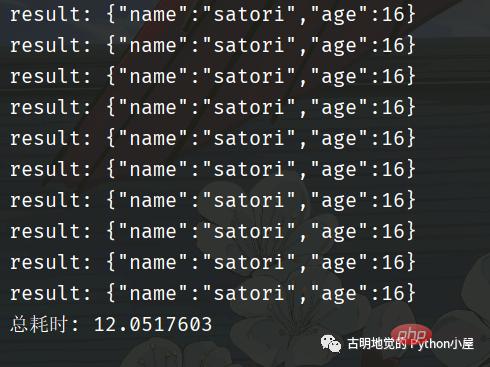
可以看到回调的这种写法性能非常高,但是它和我们传统的同步代码的写法大相径庭。如果是同步代码,那么会先建立连接、然后发送数据、再接收数据,这显然更符合我们人类的思维,逻辑自上而下,非常自然。
但是回调的方式,就让人很不适应,我们在建立完连接之后,不能直接发送数据,必须将发送数据的逻辑放在一个单独的函数(方法)中,然后再将这个函数以回调的方式注册进去。
同理,在发送完数据之后,也不能立刻接收。同样要将接收数据的逻辑放在一个单独的函数中,然后再以回调的方式注册进去。
所以好端端的自上而下的逻辑,因为回调而被分割的四分五裂,这种代码在编写和维护的时候是非常痛苦的。
比如回调可能会层层嵌套,容易陷入回调地狱,如果某一个回调执行出错了怎么办?代码的可读性差导致不好排查,即便排查到了也难处理。
另外,如果多个回调需要共享一个变量该怎么办?因为回调是通过事件循环调用的,在注册回调的时候很难把变量传过去。简单的做法是把该变量设置为全局变量,或者说多个回调都是某个类的成员函数,然后把共享的变量作为一个属性绑定在 self 上面。但当逻辑复杂时,就很容易导致全局变量满天飞的问题。
所以这种模式就使得开发人员在编写业务逻辑的同时,还要关注并发细节。
因此使用回调的方式编写异步化代码,虽然并发量能上去,但是对开发者很不友好;而使用同步的方式编写同步代码,虽然很容易理解,可并发量却又上不去。那么问题来了,有没有一种办法,能够让我们在享受异步化带来的高并发的同时,又能以同步的方式去编写代码呢?也就是我们能不能以同步的方式去编写异步化的代码呢?
答案是可以的,使用「协程」便可以办到。协程在异步化之上包了一层外衣,兼顾了开发效率与运行效率。
协程与异步编程相似的地方在于,它们必须使用非阻塞的系统调用与内核交互,把切换请求的权力牢牢掌握在用户态的代码中。但不同的地方在于,协程把异步化中的两段函数,封装为一个阻塞的协程函数。
这个函数执行时,会使调用它的协程无感知地放弃执行权,由协程框架切换到其他就绪的协程继续执行。当这个函数的结果满足后,协程框架再选择合适的时机,切换回它所在的协程继续执行。我们还是以读取磁盘文件为例,看一张协程的示意图:
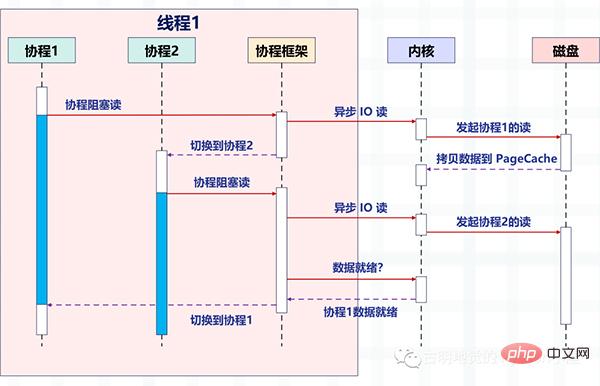
看起来非常棒,所以异步化是通过回调函数来完成请求切换的,业务逻辑与并发实现关联在一起,很容易出错。而协程不需要什么「回调函数」,它允许用户调用「阻塞的」协程方法,用同步编程方式写业务逻辑。
再回到之前的那个 socket 发请求的例子,我们用协程的方式重写一遍,看看它和基于回调的异步化编程有什么区别?
import time
from urllib.parse import urlparse
import asyncio
async def download(url):
url = urlparse(url)
# 域名:端口
netloc = url.netloc
if ":" not in netloc:
host, port = netloc, 80
else:
host, port = netloc.split(":")
path = url.path or "/"
# 创建连接
reader, writer = await asyncio.open_connection(host, port)
# 发送数据
payload = (f"GET {path} HTTP/1.1rn"
f"Host: {netloc}rn"
"Connection: closernrn")
writer.write(payload.encode("utf-8"))
await writer.drain()
# 接收数据
result = (await reader.read()).split(b"rnrn")[1]
writer.close()
print(f"result: {result.decode('utf-8')}")
# 以上就是发送请求相关的逻辑
# 我们看到代码是自上而下的,没有涉及到任何的回调
# 完全就像写同步代码一样
async def main():
# 发送 10 个请求
await asyncio.gather(
*[download("http://localhost:9999/index")
for _ in range(10)]
)
start = time.perf_counter()
# 同样需要创建基于 IO 多路复用的事件循环
# 协程会被丢进事件循环中,依靠事件循环驱动执行
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
end = time.perf_counter()
print(f"总耗时: {end - start}")代码逻辑很好理解,和我们平时编写的同步代码没有太大的区别,那么它的效率如何呢?
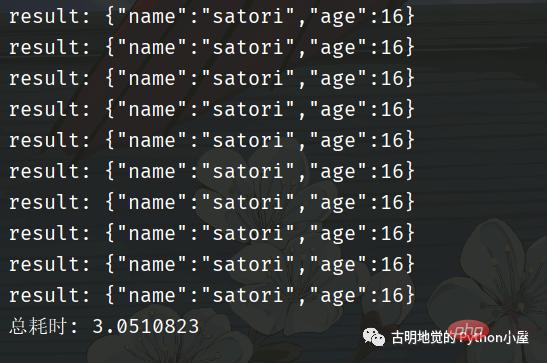
我们看到用了 3 秒钟,比同步的方式快,但是比异步化的方式要慢。因为一开始就说过,协程并不比异步化的方式快,但我们之所以选择它,是因为它的编程模型更简单,能够让我们以同步的方式编写异步的代码。如果是基于回调方式的异步化,虽然性能很高(比如 Redis、Nginx),但对开发者是一个挑战。
回到上面那个协程的例子中,我们一共发了 10 个请求,并在可能阻塞的地方加上了 await。意思就是,在执行某个协程 await 后面的代码时如果阻塞了,那么该协程会主动将执行权交给事件循环,然后事件循环再选择其它的协程执行。并且协程本质上也是个单线程,虽然协程可以有多个,但是背后的线程只有一个。
那么问题来了,协程的切换是如何完成的呢?
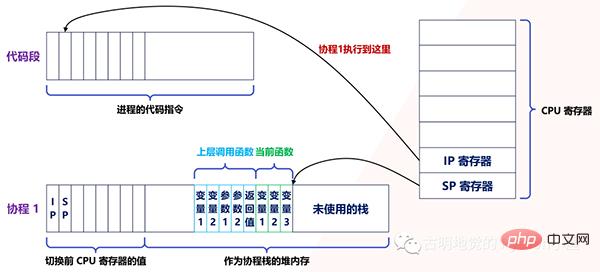
实际上,用户态的代码切换协程,与内核切换线程的原理是一样的。内核通过管理 CPU 的寄存器来切换线程,我们以最重要的栈寄存器和指令寄存器为例,看看协程切换时如何切换程序指令与内存。
每个线程有独立的栈,而栈既保留了变量的值,也保留了函数的调用关系、参数和返回值,CPU 中的栈寄存器 SP 指向了当前线程的栈,而指令寄存器 IP 保存着下一条要执行的指令地址。
因此,从线程 1 切换到线程 2 时,首先要把 SP、IP 寄存器的值为线程 1 保存下来,再从内存中找出线程 2 上一次切换前保存好的寄存器的值,并写入 CPU 的寄存器,这样就完成了线程切换(其他寄存器也需要管理、替换,原理与此相同,不再赘述)。
协程的切换与此相同,只是把内核的工作转移到协程框架来实现而已,下图是协程切换前的状态:
当遇到阻塞时会进行协程切换,从协程 1 切换到协程 2 后的状态如下图所示:
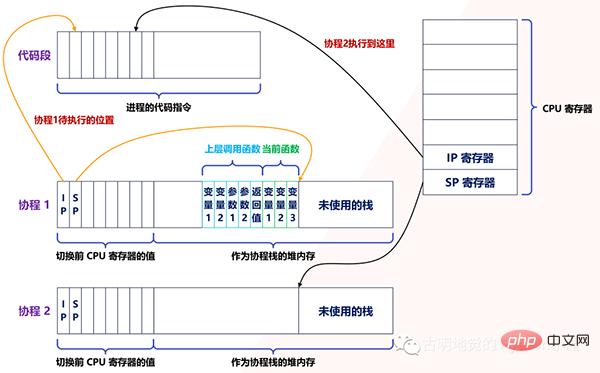
创建协程时,会从进程的堆中分配一段内存作为协程的栈。线程的栈有 8MB,而协程栈的大小通常只有几十 KB。而且,C 库内存池也不会为协程预分配内存,它感知不到协程的存在。这样,更低的内存占用空间为高并发提供了保证,毕竟十万并发请求,就意味着 10 万个协程。
另外栈缩小后,就尽量不要使用递归函数,也不能在栈中申请过多的内存,这是实现高并发必须付出的代价。当然啦,如果能像 Go 一样,协程栈可以自由伸缩的话,就不用担心了。
由此可见,协程就是用户态的线程。然而,为了保证所有切换都在用户态进行,协程必须重新封装所有的阻塞系统调用,否则一旦协程触发了线程切换,会导致这个线程进入休眠状态,进而其上的所有协程都得不到执行。
Zum Beispiel versetzt die normale Sleep-Funktion den aktuellen Thread in den Ruhezustand und der Kernel weckt den Thread. Nach der Coroutine-Transformation sorgt Sleep nur dafür, dass die aktuelle Coroutine in den Ruhezustand versetzt wird, und das Coroutine-Framework weckt die Coroutine nach einer bestimmten Zeit Zeit, also können wir in Python nicht time.sleep in die Coroutine schreiben, sondern sollten asyncio.sleep schreiben. Als weiteres Beispiel werden Mutex-Sperren zwischen Threads mithilfe von Semaphoren implementiert, und Semaphoren können auch dazu führen, dass Threads in den Ruhezustand versetzt werden. Nachdem Mutex-Sperren in Coroutinen umgewandelt wurden, koordiniert und synchronisiert das Framework auch die Ausführung jeder Coroutine.
Die hohe Leistung von Coroutinen basiert also auf der Tatsache, dass der Wechsel durch Benutzermoduscode abgeschlossen werden muss. Dies erfordert, dass das Coroutine-Ökosystem vollständig ist und gemeinsame Komponenten so weit wie möglich abdeckt.
Nehmen wir Python als Beispiel. Ich sehe oft Leute, die Anfragen asynchron schreiben. Das ist falsch. Der zugrunde liegende Aufruf von „requests.get“ ist ein synchron blockierter Socket, der dazu führt, dass der Thread blockiert. Sobald der Thread blockiert ist, werden alle Coroutinen blockiert, was einer Serialisierung entspricht. Es macht also keinen Sinn, es in async def einzufügen. Der richtige Weg ist die Verwendung von aiohttp oder httpx. Wenn Sie Coroutinen verwenden möchten, müssen Sie daher die zugrunde liegenden Systemaufrufe neu kapseln. Wenn es keine andere Möglichkeit gibt, werfen Sie sie zur Ausführung in den Thread-Pool.
Ein weiteres Beispiel ist das von MySQL offiziell bereitgestellte Client-SDK. Es verwendet blockierende Sockets für den Netzwerkzugriff, wodurch Threads in den Ruhezustand versetzt werden. Sie müssen nicht blockierende Sockets verwenden, um das SDK in Coroutine-Funktionen umzuwandeln, bevor sie in Coroutinen verwendet werden können.
Natürlich können nicht alle Funktionen mit Coroutinen transformiert werden, wie zum Beispiel das asynchrone IO-Lesen von Festplatten. Obwohl es nicht blockierend ist, kann es PageCache nicht verwenden, was den Systemdurchsatz verringert. Wenn Sie zwischengespeicherte E/A zum Lesen von Dateien verwenden, kann es zu einer Blockierung kommen, wenn PageCache nicht erreicht wird. Wenn Sie zu diesem Zeitpunkt höhere Leistungsanforderungen haben, müssen Sie Threads mit Coroutinen kombinieren, potenziell blockierende Vorgänge zur Ausführung in den Thread-Pool werfen und über das Producer/Consumer-Modell mit Coroutinen arbeiten.
Tatsächlich müssen angesichts von Multi-Core-Systemen auch Coroutinen und Threads zusammenarbeiten. Da der Träger von Coroutinen Threads sind und ein Thread jeweils nur eine CPU nutzen kann, können die CPU-Ressourcen vollständig genutzt werden, indem mehr Threads geöffnet und alle Coroutinen auf diese Threads verteilt werden. Wenn Sie Erfahrung mit der Go-Sprache haben, sollten Sie diese sehr gut kennen.
Damit die Coroutine mehr CPU-Zeit erhält, können Sie außerdem die Priorität des Threads festlegen. Unter Linux können Sie beispielsweise die Priorität des Threads auf -20 festlegen, um jedes Mal eine längere Zeit zu erhalten . Stück. Darüber hinaus hat der CPU-Cache auch Auswirkungen auf die Programmleistung. Um den Anteil von CPU-Cache-Ausfällen zu reduzieren, können Threads auch an eine CPU gebunden werden, um die Wahrscheinlichkeit zu erhöhen, dass sie bei der Ausführung der Coroutine auf den CPU-Cache treffen.
Obwohl hier gesagt wurde, dass das Coroutine-Framework Coroutinen plant, werden Sie feststellen, dass viele Coroutine-Bibliotheken nur grundlegende Methoden wie das Erstellen, Anhalten und Fortsetzen der Ausführung bereitstellen. Es gibt kein Coroutine-Framework, und der Geschäftscode muss vorhanden sein Coroutinen selbst geplant. Dies liegt daran, dass diese allgemeinen Coroutinen-Bibliotheken (z. B. Asyncio) nicht speziell für Server konzipiert sind. Der Aufbau einer Client-Netzwerkverbindung auf dem Server kann die Erstellung von Coroutinen vorantreiben und mit dem Ende der Anfrage enden.
Wenn die Betriebsbedingungen der Coroutine nicht erfüllt sind, unterbricht das Multiplexing-Framework sie und wählt basierend auf der Prioritätsrichtlinie eine andere Coroutine zur Ausführung aus. Wenn Sie Coroutinen verwenden, um Dienste mit hoher Parallelität auf der Serverseite zu implementieren, wählen Sie daher nicht nur eine Coroutine-Bibliothek, sondern finden auch ein Coroutine-Framework (wie Tornado), das IO-Multiplexing aus seinem Ökosystem kombiniert, was die Entwicklung beschleunigen kann.
Im Großen und Ganzen handelt es sich bei Coroutinen um ein leichtes Parallelitätsmodell, das auf relativ hohem Niveau ist. Aber im engeren Sinne besteht eine Coroutine darin, eine Funktion aufzurufen, die angehalten und umgeschaltet werden kann. Was wir beispielsweise mit async def definieren, ist eine Coroutine-Funktion, die im Wesentlichen eine Funktion ist. Wenn wir die Coroutine-Funktion aufrufen, erhalten wir eine Coroutine.
Werfen Sie die Coroutine in die Ereignisschleife, und die Ereignisschleife steuert die Ausführung. Sobald sie blockiert ist, wird das Ausführungsrecht aktiv an die Ereignisschleife übergeben, und die Ereignisschleife steuert die Ausführung anderer Coroutinen. Es gibt also nur einen Thread von Anfang bis Ende und die Coroutine wird lediglich im Benutzermodus simuliert, indem auf die Struktur des Threads Bezug genommen wird.
Wenn also eine normale Funktion aufgerufen wird, wird die gesamte interne Codelogik ausgeführt, bis alles abgeschlossen ist. Wenn eine Coroutine-Funktion aufgerufen wird und eine interne Blockierung auftritt, wird auf andere Coroutinen umgeschaltet.
Aber es gibt eine wichtige Voraussetzung, um wechseln zu können, wenn eine Coroutine blockiert ist: Diese Blockierung darf keine Systemaufrufe wie time.sleep, synchrone Sockets usw. beinhalten. Dies alles erfordert die Beteiligung des Kernels, und sobald der Kernel teilnimmt, ist die verursachte Blockierung nicht nur so einfach wie das Blockieren einer bestimmten Coroutine (das Betriebssystem kennt die Coroutine nicht), sondern führt auch dazu, dass der Thread blockiert wird. Sobald ein Thread blockiert ist, werden alle Coroutinen darüber blockiert. Da Coroutinen Threads als Träger verwenden, muss die eigentliche Ausführung Threads sein. Wenn jede Coroutine den Thread blockiert, ist dies nicht gleichbedeutend mit einer Zeichenfolge.
Wenn Sie also Coroutinen verwenden möchten, müssen Sie die blockierten Systemaufrufe neu kapseln:
@app.get(r"/index1") async def index1(): time.sleep(30) return "index1" @app.get(r"/index2") async def index2(): return "index2"
这是一个基于 FastAPI 编写的服务,我们只看视图函数。如果我们先访问 /index1,然后访问 /index2,那么必须等到 30 秒之后,/index2 才会响应。因为这是一个单线程,/index1 里面的 time.sleep 会触发系统调用,使得整个线程都进入阻塞,线程一旦阻塞了,所有的协程就都别想执行了。
如果将上面的例子改一下:
@app.get(r"/index1") async def index(): await asyncio.sleep(30) return "index1" @app.get(r"/index2") async def index(): return "index2"
访问 /index1 依旧会进行 30 秒的休眠,但此时再访问 /index2 的话则是立刻返回。原因是 asyncio.sleep(30) 重新封装了阻塞的系统调用,此时的休眠是在用户态完成的,没有经过内核。换句话说,此时只会导致协程休眠,不会导致线程休眠,那么当访问 /index2 的时候,对应的协程会立刻执行,然后返回结果。
同理我们在发网络请求的时候,也不能使用 requests.get,因为它会导致线程阻塞。当然,还有一些数据库的驱动,例如 pymysql, psycopg2 等等,这些阻塞的都是线程。为此,在开发协程项目时,我们应该使用 aiohttp, asyncmy, asyncpg 等等。
为什么早期 Python 的协程都没有人用,原因就是协程想要运行,必须基于协程库 asyncio,但问题是 asyncio 只支持发送 TCP 请求(对于协程库而言足够了)。如果你想通过网络连接到某个组件(比如数据库、Redis),只能手动发 TCP 请求,而且这些组件对发送的数据还有格式要求,返回的数据也要手动解析,可以想象这是多么麻烦的事情。
如果想解决这一点,那么必须基于 asyncio 重新封装一个 SDK。所以同步 SDK 和协程 SDK 最大的区别就是,一个是基于同步阻塞的 socket,一个是基于 asyncio。比如 redis 和 aioredis,连接的都是 Redis,只是在 TCP 层面发送数据的方式不同,至于其它方面则是类似的。
而早期,还没有出现这些协程 SDK,自己封装的话又是一个庞大的工程,所以 Python 的协程用起来就很艰难,因为达不到期望的效果。不像 Go 在语言层面上就支持协程,一个 go 关键字就搞定了。而且 Python 里面一处异步、处处异步,如果某处的阻塞切换不了,那么协程也就没有意义了。
但现在 Python 已经进化到 3.10 了,协程相关的生态也越来越完善,感谢这些开源的作者们。发送网络请求、连接数据库、编写 web 服务等等,都有协程化的 SDK 和框架,现在完全可以开发以协程为主导的项目了。
本次我们从高并发的应用场景入手,分析了协程出现的背景和实现原理,以及它的应用范围。你会发现,协程融合了多线程与异步化编程的优点,既保证了开发效率,也提升了运行效率。有限的硬件资源下,多线程通过微观上时间片的切换,实现了同时服务上百个用户的能力。多线程的开发成本虽然低,但内存消耗大,切换次数过多,无法实现高并发。
异步编程方式通过非阻塞系统调用和多路复用,把原本属于内核的请求切换能力,放在用户态的代码中执行。这样,不仅减少了每个请求的内存消耗,也降低了切换请求的成本,最终实现了高并发。然而,异步编程违反了代码的内聚性,还需要业务代码关注并发细节,开发成本很高。
协程参考内核通过 CPU 寄存器切换线程的方法,在用户态代码中实现了协程的切换,既降低了切换请求的成本,也使得协程中的业务代码不用关注自己何时被挂起,何时被执行。相比异步编程中要维护一堆数据结构表示中间状态,协程直接用代码表示状态,大大提升了开发效率。但是在协程中调用的所有 API,都需要做非阻塞的协程化改造。优秀的协程生态下,常用服务都有对应的协程 SDK,方便业务代码使用。开发高并发服务时,与 IO 多路复用结合的协程框架可以与这些 SDK 配合,自动挂起、切换协程,进一步提升开发效率。
最后,协程并不是完全与线程无关。因为线程可以帮助协程充分使用多核 CPU 的计算力(Python 除外),而且遇到无法协程化、会导致内核切换的阻塞函数,或者计算太密集从而长时间占用 CPU 的任务,还是要放在独立的线程中,以防止它影响别的协程执行。
Wenn Sie also Coroutinen verwenden, ist es am besten, einen Thread-Pool zu verwenden. Wenn einige Blockierungen durch den Kernel gehen müssen und nicht koroutineisiert werden können, werfen Sie sie in den Thread-Pool und schließen Sie den Wechsel auf Thread-Ebene ab. Obwohl das Starten mehrerer Threads Ressourcen beansprucht und das Umschalten von Threads einen Overhead mit sich bringt, ist dies unvermeidbar, und wir können unsere Hoffnung natürlich nur auf Threads setzen, die zu CPU-lastig sind. intensiv, Sie können es auch in den Thread-Pool werfen. Einige Leute sind vielleicht neugierig: Wenn Sie mehrere Kerne verwenden können, ist es sinnvoll, sie in den Thread-Pool zu werfen, aber Pythons Multithreading kann nicht mehrere Kerne verwenden. Warum tun Sie das? Der Grund ist einfach. Wenn nur ein einzelner Thread vorhanden ist, belegt eine solche CPU-intensive Aufgabe lange Zeit CPU-Ressourcen, was dazu führt, dass andere Aufgaben nicht ausgeführt werden. Wenn Multithreading aktiviert ist, führt die GIL zu einem Thread-Wechsel, obwohl immer noch nur ein Kern vorhanden ist, sodass keine Situation wie „Der König von Chu hat eine schlanke Taille und der Harem ist verhungert“ auftritt Die CPU kann gleichmäßig verteilt werden, sodass alle Aufgaben ausgeführt werden können.
Das obige ist der detaillierte Inhalt vonVoller nützlicher Informationen! Eine umfassende Einführung in die Implementierung von Pythons Coroutinen! Wenn du es verstehst, bist du großartig!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



