
 Technologie-Peripheriegeräte
KI
Technische Weiterentwicklung des Echtzeit-Großmodells für Weibo-Empfehlung
Technologie-Peripheriegeräte
KI
Technische Weiterentwicklung des Echtzeit-Großmodells für Weibo-Empfehlung
Technische Weiterentwicklung des Echtzeit-Großmodells für Weibo-Empfehlung

1. Überprüfung der technischen Roadmap 1. Geschäftsszenarien und -merkmale Startseite Für alle Inhalte der Tab-Spalte haben Informationsflussprodukte im Allgemeinen einen höheren Anteil an Verkehr im ersten Tab.

② Ein Informationsfluss, der durch Herunterschieben der Hot-Suche eingegeben wird. einschließlich auf dieser Seite. Andere Informationsfluss-Registerkarten, wie Videokanäle usw.;
③ Suchen oder klicken Sie auf empfohlene Videos in der gesamten APP, um die immersive Videoszene aufzurufen.
Unser Unternehmen weist die folgenden Merkmale auf:
(1) Zunächst einmal aus der Perspektive der Empfehlungsumsetzung:
① Es gibt viele Geschäftsszenarien.
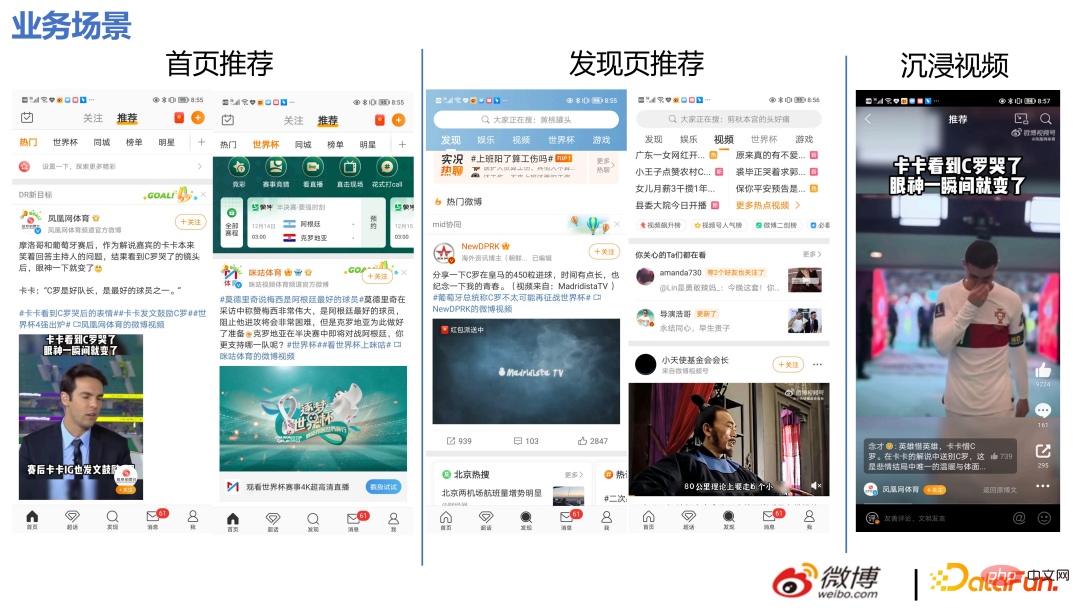 ② Benutzer können auf der Weibo-Benutzeroberfläche auf den Inhalt klicken, um ihn anzusehen, oder ihn innerhalb des Streams nutzen, z Persönliche Seite des Bloggers, klicken Sie, um die Textseite aufzurufen, klicken Sie auf Bilder, klicken Sie auf Videos, leiten Sie Kommentare und Likes weiter usw.
② Benutzer können auf der Weibo-Benutzeroberfläche auf den Inhalt klicken, um ihn anzusehen, oder ihn innerhalb des Streams nutzen, z Persönliche Seite des Bloggers, klicken Sie, um die Textseite aufzurufen, klicken Sie auf Bilder, klicken Sie auf Videos, leiten Sie Kommentare und Likes weiter usw.
③ Es gibt viele Arten von Materialien, die verbreitet werden können, z. B. lange Bilder, Bilder (ein Bild oder mehrere Bilder), Videos (horizontale oder vertikale Videos), Artikel usw., die auf der verteilt werden können Homepage.
(2) Aus Sicht der Produktpositionierung:
① Service-Hotspots: Vor und nach dem Ausbruch der Hotspots sind die Verkehrsveränderungen bei Weibo besonders groß. Benutzer können problemlos heiße Inhalte konsumieren Empfehlungen, ein Unternehmen, das nach empfohlenen Produkten fragt.
② Beziehungen aufbauen: Ich hoffe, im empfohlenen Weibo einige soziale Beziehungen aufzubauen.
2. Technologieauswahl
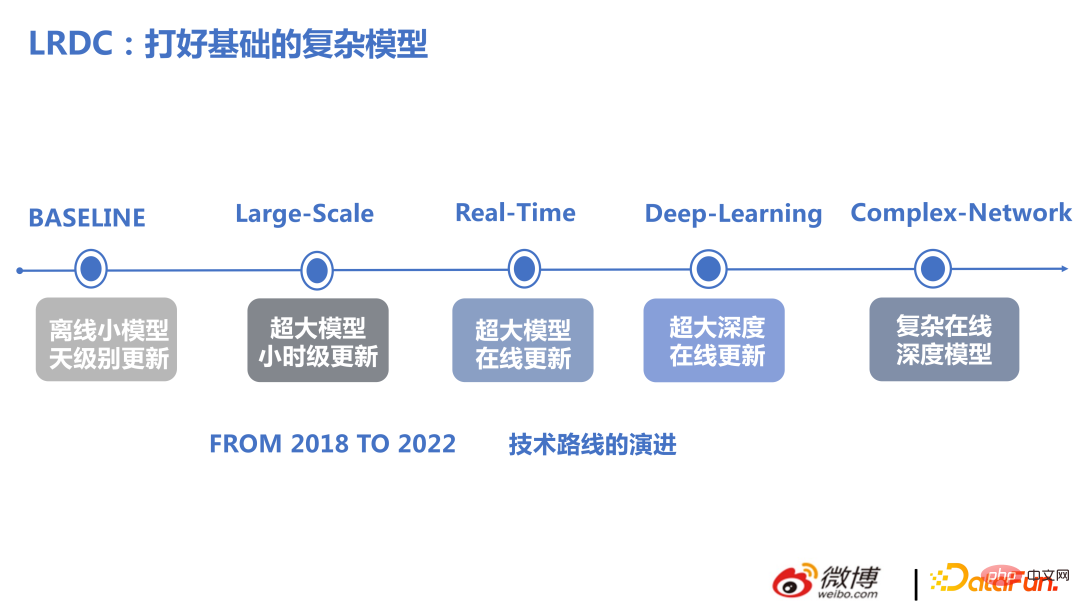
Das Bild unten zeigt unseren technologischen Fortschritt in den letzten Jahren.
Im aktuellen Empfehlungsrahmen sind Hunderte Milliarden Funktionen und Billionen Parameter Standard. Im Gegensatz zu NLP und CV weisen Modelle, die in diesen beiden Richtungen zu groß sind, eine hohe Komplexität des Netzwerks selbst, eine gute Sparsamkeit in empfohlenen Szenarien, eine relativ große Modellgröße auf, und beim Training wird häufig Datenparallelität verwendet, und nicht jeder Benutzer muss alle Modelle bedienen Parameter.
Die technische Entwicklung dieses Teams von 2018 bis 2022 erfolgt hauptsächlich in zwei Aspekten: groß angelegt und in Echtzeit. Erstellen Sie auf dieser Basis komplexe Strukturen, um mit halbem Aufwand das doppelte Ergebnis zu erzielen.
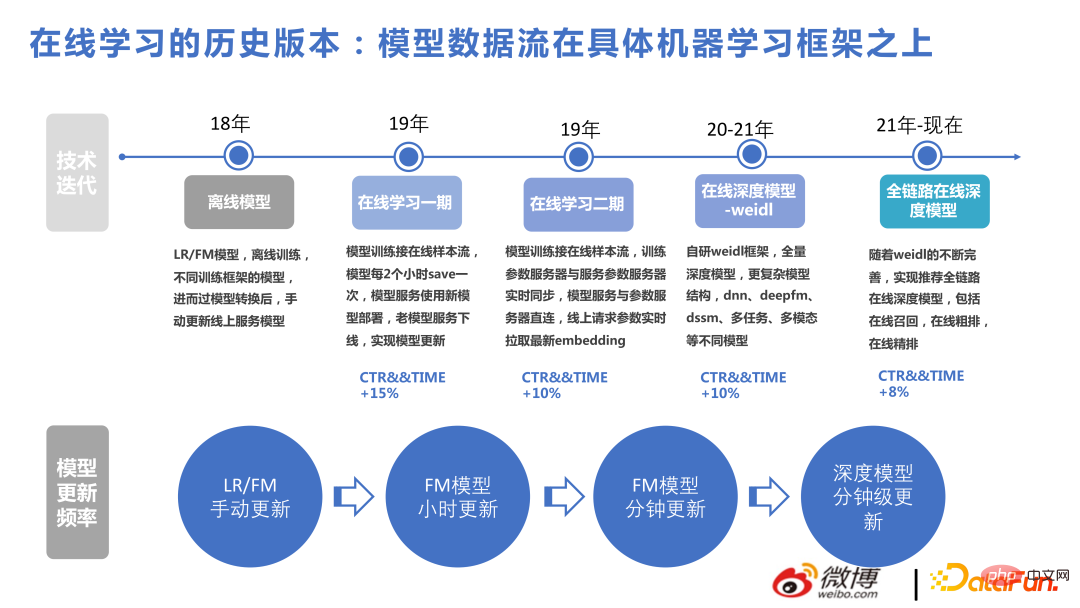
Hier eine kurze Einführung in unsere Weidl Online-Lernplattform.
Der Hauptprozess besteht darin: Beispiele für das Benutzerverhalten zusammenzufügen, das Modell zum Lernen bereitzustellen und es dann den Benutzern zur Rückmeldung zu empfehlen. Um eine bessere Flexibilität zu erreichen, wird das allgemeine Designprinzip der Datenflusspriorität übernommen. Unabhängig davon, welche Methode zum Trainieren von KERNEL verwendet wird, besteht weiterhin der Echtzeit-Aktualisierungsteil zwischen Offline-Modellspeicher und Online-PS. Unabhängig davon, ob es sich um handgeschriebenes LR oder FM, ein Tensorflow- oder ein DeepRec-Trainingsmodell handelt, ist es möglich, dass der entsprechende Modellspeicher ein Satz von Datenströmen ist, die wir selbst erstellt haben, und das Modellformat wird ebenfalls von uns selbst erstellt, wodurch sichergestellt wird, dass mehrere Daten vorhanden sind Backends können heruntergeladen werden. Das Modelltraining kann in weniger als einer Minute online aktualisiert werden und die neuen Parameter können beim nächsten Benutzeraufruf verwendet werden. Nach diesem Designprinzip kann das Backend einfach gewechselt werden.
Weidl ist die von Weibo selbst entwickelte Plattform für maschinelles Lernen. Sie können den Bridge-Modus auch ohne ihn verwenden. Es ist auch praktisch, ihn durch selbst entwickelte Operatoren zu ersetzen. Wenn wir beispielsweise zuvor Tensorflow verwendet haben, haben wir einige Speicherzuweisungen und Operatoroptimierungen für tf durchgeführt. Wir werden in der zweiten Hälfte des Jahres 2022 auf DeepRec umsteigen. Nachdem wir mehr über DeepRec erfahren haben, werden wir feststellen, dass einige der vorherigen Leistungsoptimierungspunkte basierend auf tf ähneln denen von DeepRec.
Die folgende Abbildung listet einige der Versionen auf, die unser Team im Laufe der Jahre erstellt hat, um jedem das Verständnis für den Beitrag jedes technischen Punkts in unserem Unternehmen zu erleichtern. Die erste besteht darin, FM-basierte Modelle zur Lösung in großem Maßstab zu verwenden Echtzeit-Empfehlungsprobleme, gefolgt von Erstellt eine komplexe Struktur basierend auf der Tiefe. Den Ergebnissen zufolge hat die bisherige Verwendung nicht-tiefer Modelle zur Lösung von Online-Echtzeitproblemen ebenfalls große Vorteile gebracht.
Informationsflussempfehlung unterscheidet sich von Produktempfehlung und ist im Grunde eine groß angelegte Echtzeit-Tiefenstruktur. Auch in diesem Bereich gibt es einige Schwierigkeiten und Unterschiede. Beispielsweise sind Echtzeitfunktionen keine Alternative zu Echtzeitmodellen. Darüber hinaus bringt das Online-Lernen einige Iterationsprobleme mit sich Aber bevor absolute Erfolge erzielt werden können, kann es mit der Zeit überwunden werden.
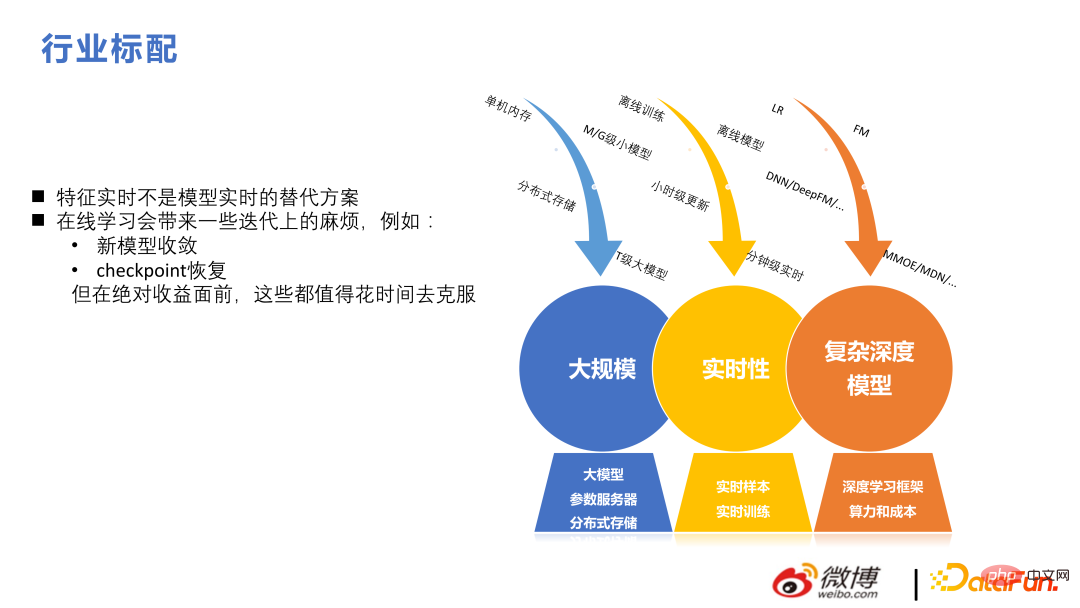
2. Aktuelle Technologieiteration großer Modelle
In diesem Kapitel wird das Geschäftsiterationsmodell unter den Aspekten Ziele, Struktur und Eigenschaften vorgestellt.
1. Multi-Objective-Fusion
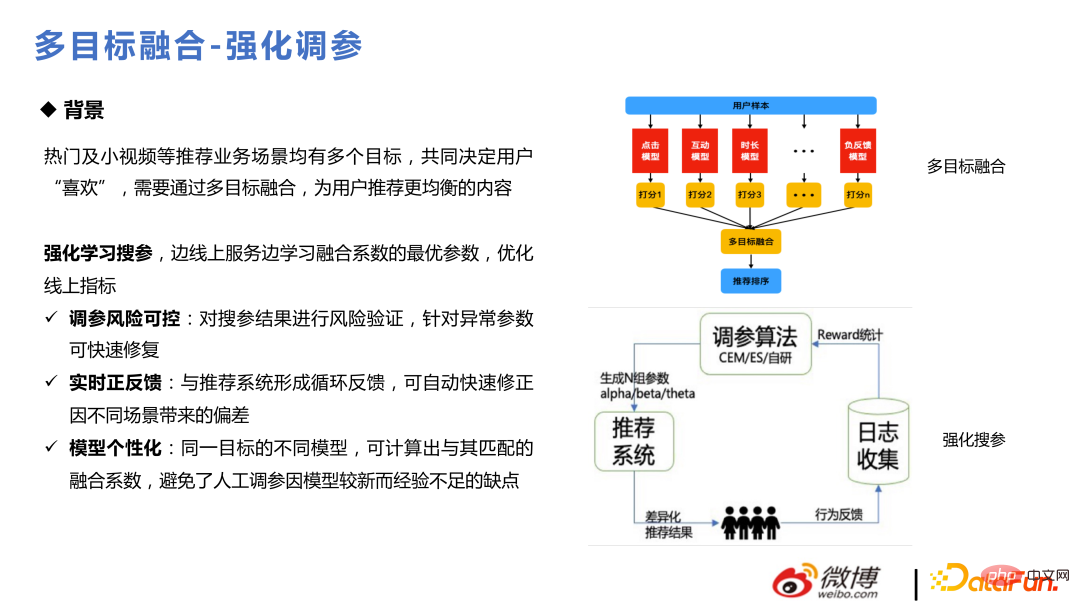
Es gibt viele Benutzeroperationen in der Weibo-Szene, die ihre Liebe zu Artikeln durch viele Verhaltensweisen ausdrücken, wie z. B. Klickinteraktion, Dauer, Dropdown usw Das Ziel muss angegangen werden. Modellierung und Schätzung sowie schließlich die Gesamtfusion und das Ranking sind für das Empfehlungsgeschäft sehr wichtig. Als es zum ersten Mal durchgeführt wurde, wurde es durch statische Fusion und Offline-Parametersuche durchgeführt. Später wurde es durch die Reinforcement-Learning-Methode in eine dynamische Parametersuche umgewandelt. Danach wurden einige Optimierungen der Fusionsformel durchgeführt und später verbessert, um einige auszugeben Fusion punktet durch das Modell.

Die Kernmethode zur Stärkung der Parameteranpassung besteht darin, den Online-Verkehr in einige kleine Verkehrspools aufzuteilen und einige aktuelle Online-Parameter zu verwenden, um zu sehen, wie Benutzer darauf reagieren Diese Parameter sammeln Feedback und iterieren. Der Kernteil ist die Berechnung der Belohnung, die CEM und ES verwendet. Später wurde ein selbst entwickelter Algorithmus zur Anpassung an die eigenen Geschäftsanforderungen verwendet. Da sich das Online-Lernen sehr schnell ändert, entstehen große Probleme, wenn sich die Parameter nicht entsprechend ändern können. Beispielsweise ändert sich die Vorliebe aller für Videoinhalte von Freitagabend auf Samstagmorgen und von Sonntagabend auf Montagmorgen Fusionsparameter müssen Änderungen in den Benutzerpräferenzen für etwas widerspiegeln.
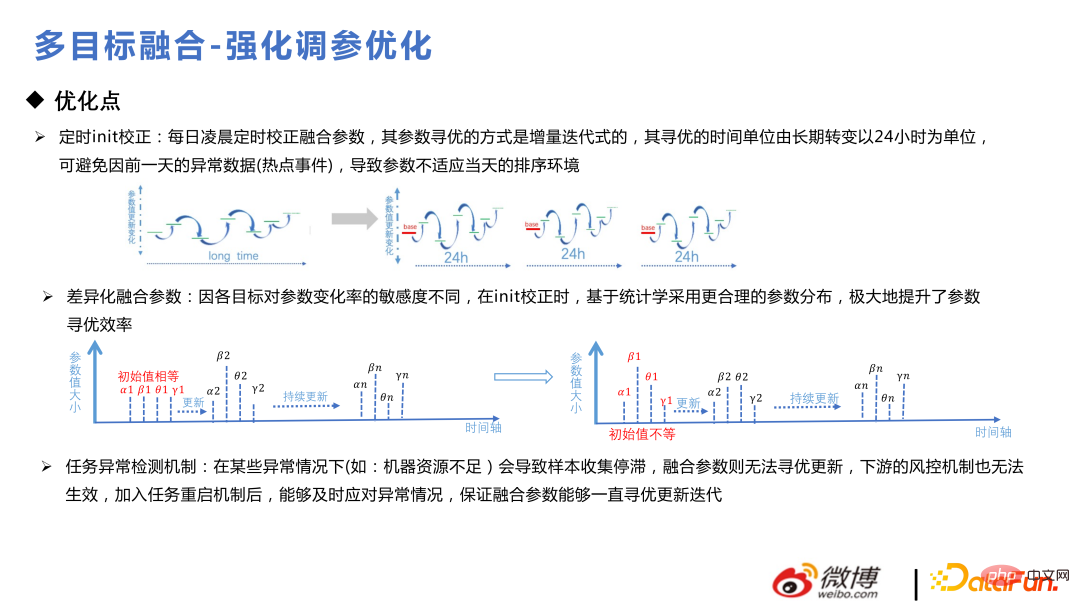
Im Folgenden sind einige kleine Tricks zur Modelloptimierung aufgeführt. Es ist besser, jeden Tag eine regelmäßige Init-Korrektur durchzuführen, da es sonst zu einem voreingenommeneren Zweig kommen kann. Bei der Initialisierung von Parametern müssen sie die vorherige Verteilung befolgen, zuerst eine vorherige Analyse durchführen und dann einen Anomalieerkennungsmechanismus hinzufügen, um sicherzustellen, dass die Fusionsparameter konsistent und iterativ aktualisiert werden können.
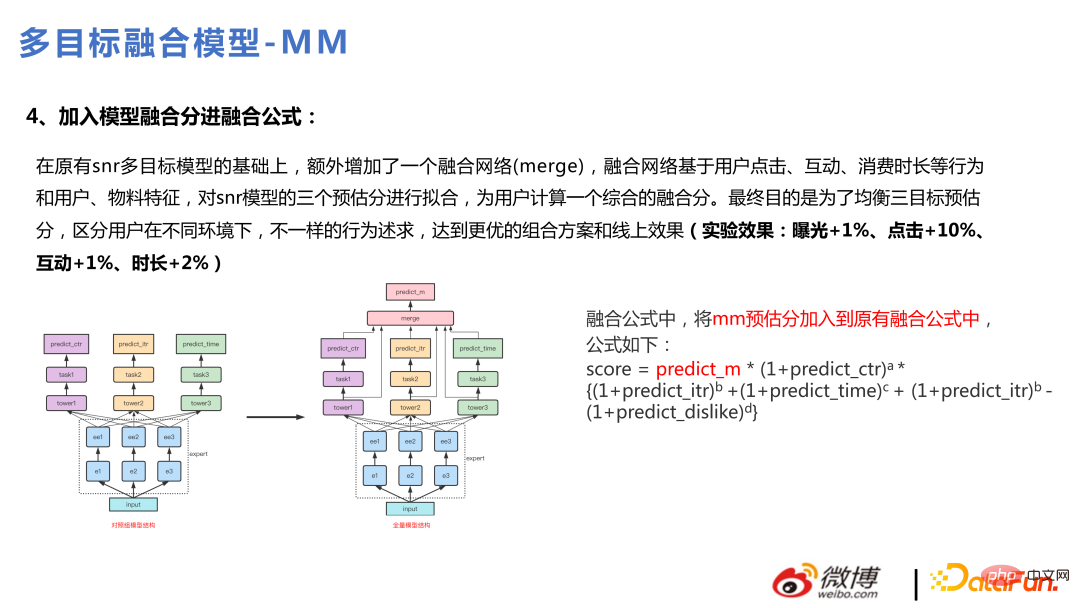
Die Fusionsformel verwendet Addition bei Für die Fusion gab es damals noch nicht so viele Geschäftsziele. Später, als die Anzahl der Ziele zunahm, stellte sich heraus, dass die additive Fusion nicht geeignet war, das Hinzufügen weiterer Ziele zu unterstützen, und die Bedeutung jedes einzelnen Unterziels schwächen würde Daher wurde später die multiplikative Fusionsformel verwendet. Der Effekt wird in ppt angezeigt:

#🎜🎜 # Nach dem Upgrade der Vollversion auf Multitasking ist diese Version für die Zielfusion über das Modell optimiert. Durch die Modellfusion können viele nichtlineare Dinge besser erfasst werden und haben eine bessere Ausdruckskraft. Auf diese Weise kann auch eine personalisierte Fusion erreicht werden, und die zusammengeführten Dinge werden für jeden Benutzer unterschiedlich sein.
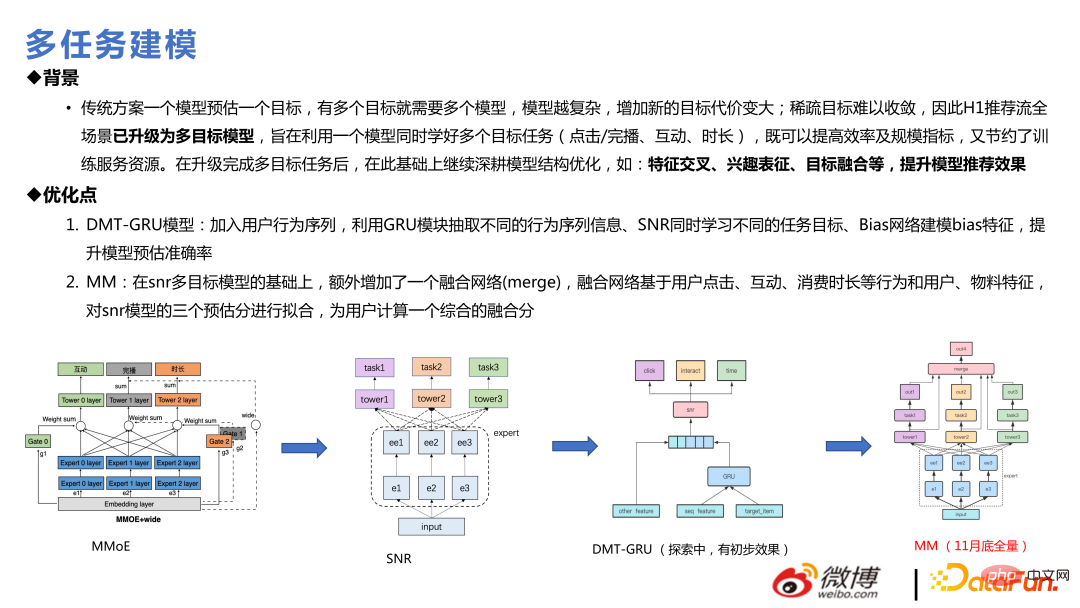
2. Multitasking #🎜 🎜 #Multitasking ist ein Konzept, das seit 2019 und 2020 populär geworden ist. Empfehlungssysteme müssen sich oft auf mehrere Ziele gleichzeitig konzentrieren: In unserem Geschäftsszenario gibt es beispielsweise sieben Ziele: Klick, Dauer, Interaktion, Abschlussübertragung, negatives Feedback, Aufrufen der Startseite, Herunterziehen zum Aktualisieren usw. Das Trainieren eines Modells für jedes Ziel verbraucht mehr Ressourcen und ist umständlich. Darüber hinaus sind einige Ziele spärlich und andere relativ dicht. Wenn die Modelle separat erstellt werden, sind diese spärlichen Ziele im Allgemeinen nicht leicht zu lernen. Gemeinsames Lernen kann das Problem des spärlichen Ziellernens lösen.

Die empfohlene Einführung in die Multitask-Modellierung beginnt im Allgemeinen mit MMOE und geht weiter SNR, dann zu DMT und schließlich zum vollständigen MM, bei dem es sich tatsächlich um eine Optimierung des SNR wie bei konvergenten Netzwerken handelt. Vor dem Multitasking müssen folgende Schlüsselfragen gelöst werden: Gibt es Konflikte zwischen den Verlusten zwischen mehreren Zielen und ob es zu einem Wackeleffekt untereinander kommt? usw. In der Praxis zeigen sowohl PCGrad- als auch UWL-Methoden ihre Auswirkungen in Testdaten. Wenn sie jedoch auf eine Produktionsumgebung ausgeweitet werden und das Online-Lernen und -Training fortgesetzt wird, lassen die Auswirkungen dieser Methoden erfahrungsgemäß schneller nach Es ist nicht unmöglich, einige Werte in der gesamten Online-Praktikumsumgebung festzulegen. Es ist nicht sicher, ob dies mit dem Online-Lernen oder der Stichprobengröße zusammenhängt. Der Effekt, MMOE allein zu betreiben, ist ebenfalls relativ gut. Auf der linken Seite sind einige tatsächliche Gewinnpunkte im Geschäft aufgeführt. Das Folgende beginnt mit MMOE Some technologische Entwicklung. Der erste Schritt zum Multitasking sind einfache harte Verbindungen, gefolgt von MMOE, dann SNR oder PLE. Dies sind in den letzten Jahren relativ ausgereifte Methoden in der Branche. Dieses Team verwendet SNR und führt zwei Optimierungen durch. In der unteren Hälfte der Abbildung unten ist ganz links der Ansatz des SNR-Standardpapiers dargestellt. Wir haben die Transformation innerhalb des Experten vereinfacht. Gleichzeitig wird es exklusive Experten und gemeinsame Experten geben. Hier werden einige Analysen durchgeführt, die auf den tatsächlichen Werten und geschätzten Abweichungen der Datenrückschlüsse basieren, die in einigen tatsächlichen Unternehmen zurückgeführt werden, und es werden einige unabhängige Experten erstellt.
3. Multiszenen-Technologie
Wir sind für viele empfohlene Szenarien verantwortlich, daher ist es selbstverständlich, über die Verwendung nachzudenken einige Multi-Szenario-Technologien. Multitasking bedeutet, dass einige Ziele relativ spärlich sind. Die Konvergenz kleiner Szenen ist aufgrund des unzureichenden Datenvolumens nicht so gut, während die Konvergenz großer Szenen besser ist Da zwei Szenen ungefähr gleich groß sind, wird es eine Lücke in der Mitte geben. Einige von ihnen beinhalten einen Wissenstransfer, der dem Unternehmen zugute kommt. Dies ist ebenfalls ein aktueller Trend und weist viele technische Ähnlichkeiten mit Multitasking auf. Basierend auf jedem Multitask-Modell können Multi-Szenen-Modelle erstellt werden. Was in der folgenden Abbildung hinzugefügt wird, ist die Slot-Gate-Ebene, die unterschiedliche Funktionen für verschiedene Szenen durch Slot-Gate ausdrückt . . Die Ausgabe über Slot-Gate kann in drei Teile unterteilt werden: Verbindung zum Expertennetzwerk, Verbindung zur Zielaufgabe oder Verbindung zu Funktionen.
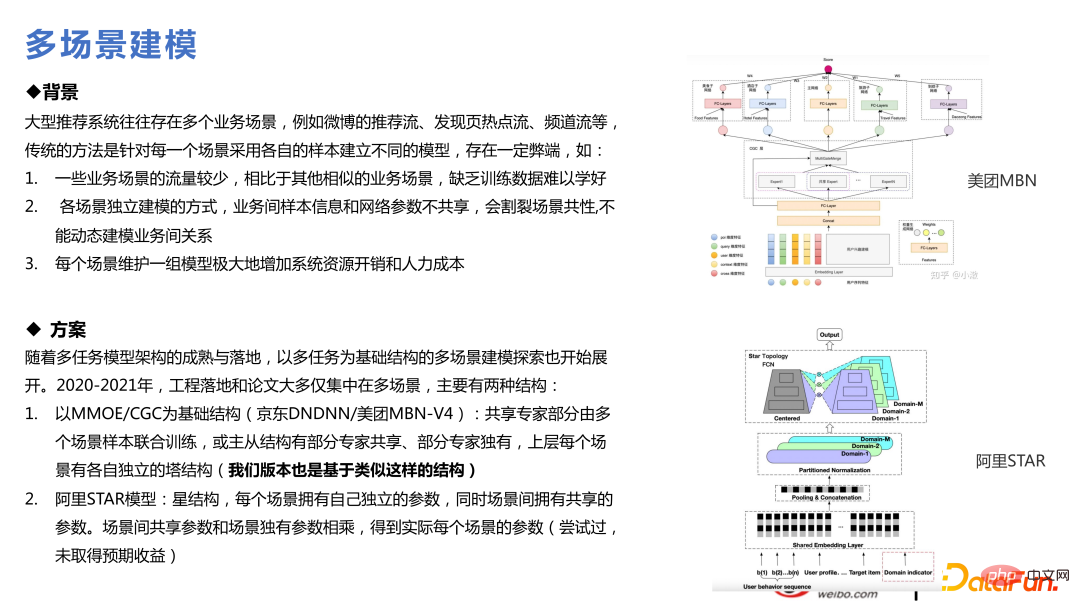
Die Gesamtstruktur ähnelt SNR, mit drei Zieltürmen: Klick, Interaktion und Dauer. Darunter sind diese drei Zieltürme in sechs Ziele für zwei beliebte und beliebte Szenen unterteilt. Darüber hinaus wird die Embeding-Transformationsschicht hinzugefügt. Im Gegensatz zu Slot-Gate dient Slot-Gate dazu, die Bedeutung von Features zu ermitteln, während die Embeding-Transformationsschicht die Unterschiede im Einbettungsraum in verschiedenen Szenarien berücksichtigt, um eine Einbettungszuordnung durchzuführen. Einige Features haben in den beiden Szenen unterschiedliche Abmessungen und werden durch die Embedding-Transformationsebene transformiert.
4. Interessenvertretung
#🎜 🎜#Interessenvertretung ist eine Technologie, die in den letzten Jahren häufig erwähnt wurde, von Alibabas DIN bis hin zu SIM und DMT, sie hat sich zum Mainstream der Benutzerverhaltenssequenzmodellierung in der Branche entwickelt .
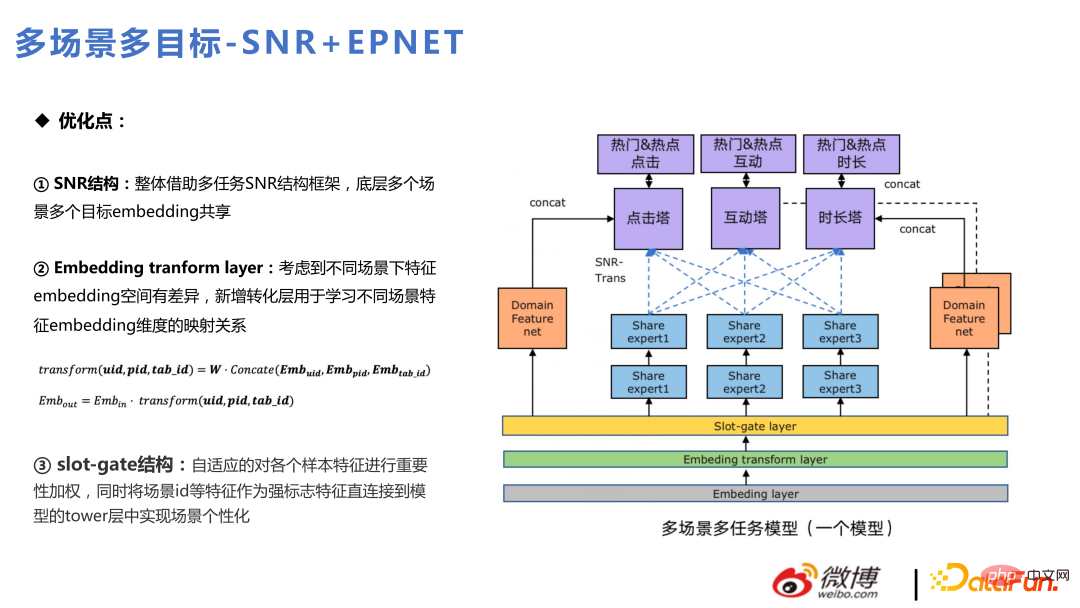
Die am Anfang verwendete DIN , Konstruieren Sie mehrere Verhaltenssequenzen für unterschiedliche Verhaltensweisen. Der Aufmerksamkeitsmechanismus wurde eingeführt, um verschiedenen Materialien im Verhalten unterschiedliche Gewichte zuzuweisen, und die lokale Aktivierungseinheit wurde verwendet, um die Gewichtsverteilung der Benutzersequenz und der aktuell sortierten Kandidatenmaterialien zu lernen, um eine beliebte Feinranking-Lösung zu realisieren und bestimmte Geschäfte zu erzielen Vorteile.
Der Kern von DMT besteht darin, Transformer für Multitasking zu verwenden. Dieses Team verwendet ein vereinfachtes DMT-Modell und entfernt das Bias-Modul mit SNR und erzielen Sie bestimmte Geschäftsergebnisse, nachdem Sie online gegangen sind.
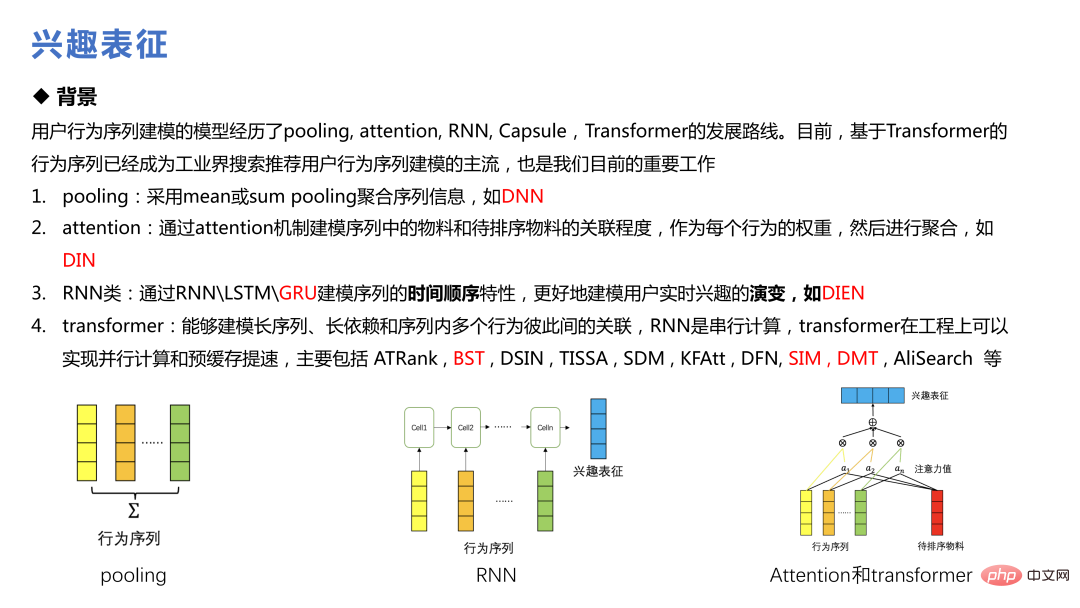
Multi-DIN dient dazu, mehrere Sequenzen zu erweitern und die Kandidatenmaterialien zu kombinieren , Tag, Autorid usw. werden als Abfragen verwendet, und die Aufmerksamkeit wird auf jede Sequenz separat gerichtet. Nach Erhalt der Interessendarstellung werden andere Funktionen in das Multitask-Ranking-Modell integriert.
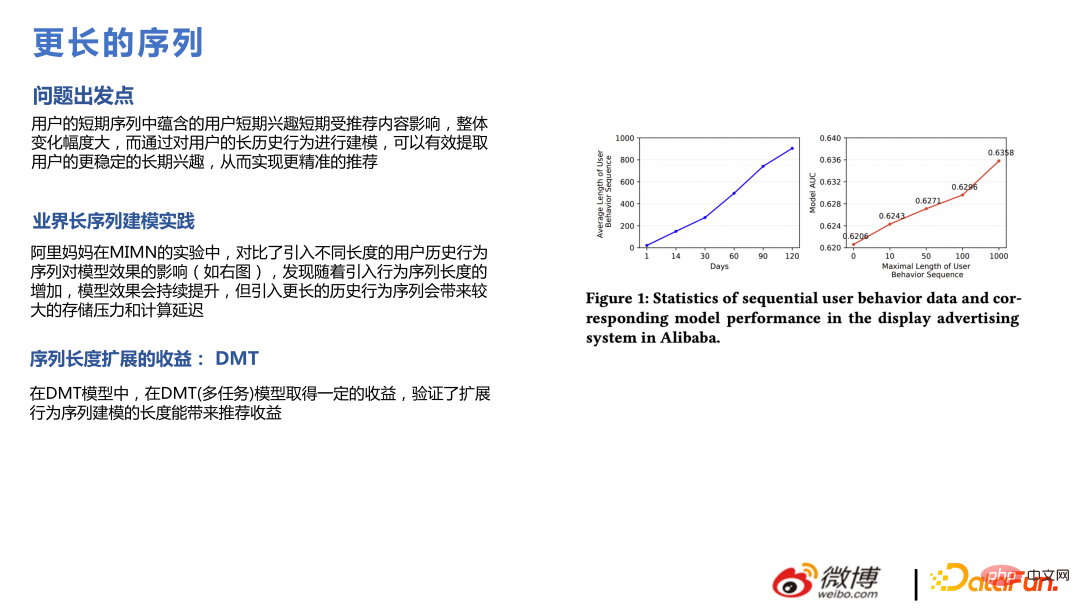
Gleichzeitig haben wir auch Experimente durchgeführt und festgestellt, dass die Reihenfolge B. durch Erweitern von Klicks, Dauer, Interaktionssequenzen usw., von 20 auf 50 für jede Sequenz. Der Effekt ist besser, was mit der Schlussfolgerung im Papier übereinstimmt, aber längere Sequenzen erfordern mehr Rechenleistungskosten. 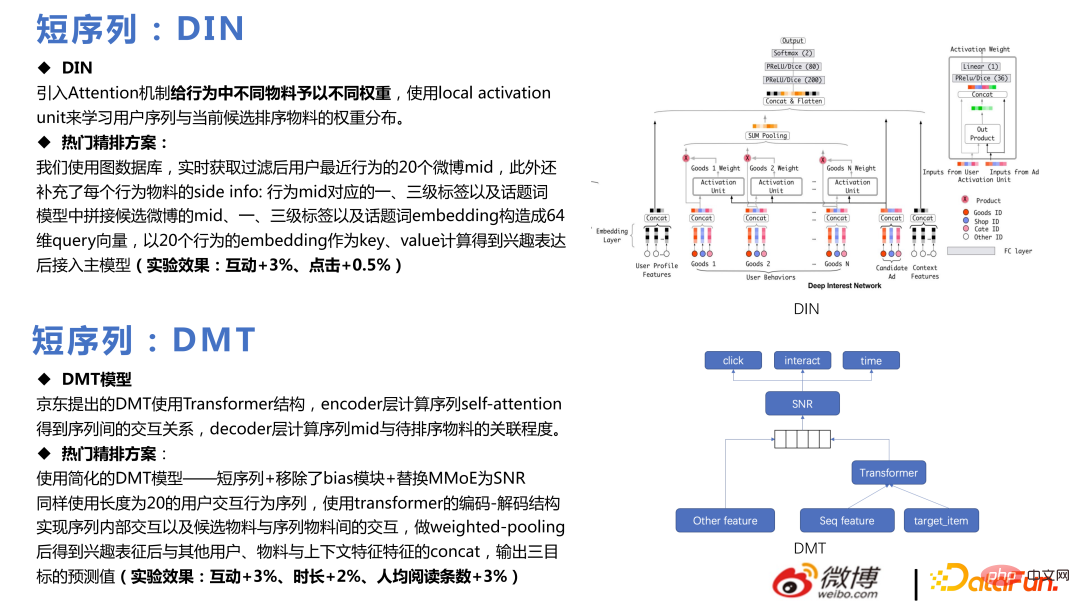
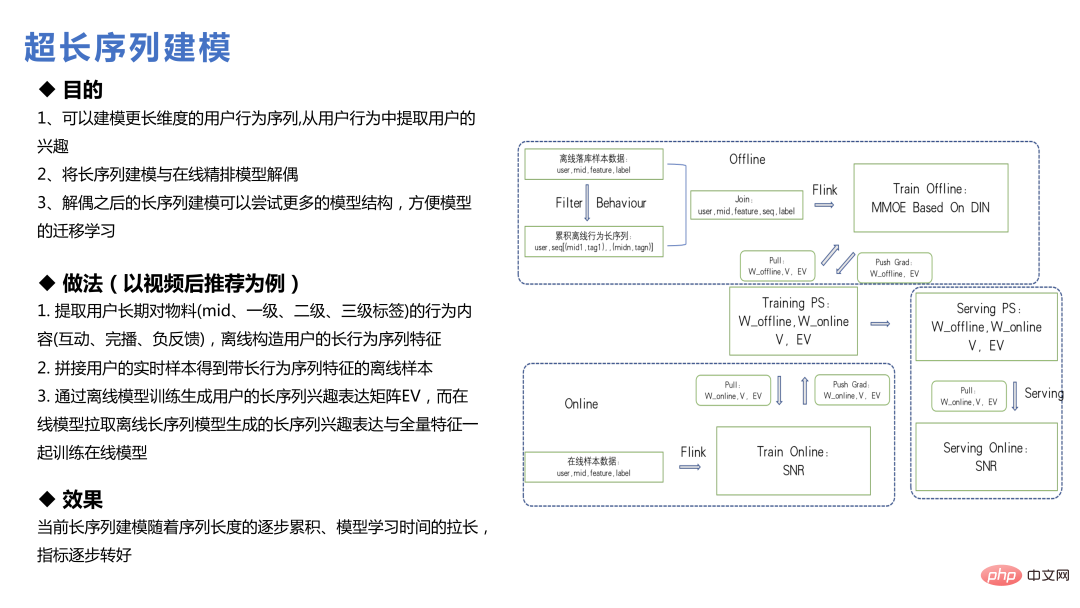
Die Modellierung des Benutzerlebenszyklus mit extrem langer Sequenz unterscheidet sich von der vorherigen Modellierung der langen Sequenz. Sie ruft die Daten nicht durch Anfordern von Funktionen ab, sondern erstellt die Funktionen der langen Verhaltenssequenz des Benutzers offline oder durch eine Suche Methode, finden Sie die entsprechenden Merkmale und generieren Sie dann die Einbettung; oder modellieren Sie das Hauptmodell und das Ultra-Long-Sequenz-Modell separat und bilden Sie schließlich die Einbettung und senden Sie sie an das Hauptmodell.
Im Weibo-Geschäft ist der Wert ultralanger Sequenzen nicht so groß, da sich der Fokus aller im Internet schnell ändert. Beispielsweise verschwinden heiß gesuchte Dinge nach ein oder zwei Tagen allmählich Sieben Tage im Informationsfluss Es werden relativ wenige Dinge vorher verteilt. Daher schwächt eine zu lange Benutzerverhaltenssequenz den geschätzten Benutzerpräferenzwert für das Element in gewissem Maße. Für Nutzer mit geringer Frequenz oder wiederkehrenden Nutzern ist diese Schlussfolgerung jedoch in gewissem Maße anders.
5. Funktionen
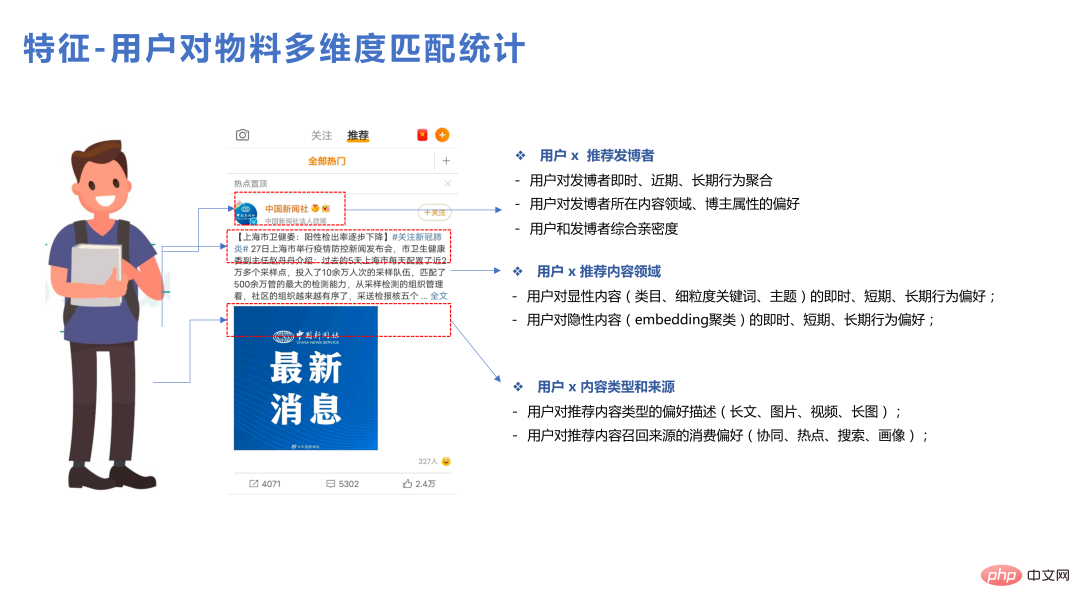
Die Verwendung sehr großer Modelle führt auch auf Funktionsebene zu einigen Problemen. Beispielsweise geht man theoretisch davon aus, dass einige Funktionen für das Modell hilfreich sind, aber die Wirkung nach dem Hinzufügen kann die Erwartungen nicht erfüllen. Dies ist auch die Realität, mit der das Empfehlungsgeschäft konfrontiert ist. Da der Maßstab des Modells sehr groß ist, wurden dem Modell viele Informationen zur ID-Klasse hinzugefügt, was einigen Benutzerpräferenzen bereits einen guten Ausdruck verliehen hat. Das Hinzufügen einiger statistischer Funktionen ist derzeit möglicherweise nicht so einfach zu verwenden. Lassen Sie uns über dieses Team sprechen Funktionen, die in der Praxis relativ einfach zu verwenden sind.
Zuallererst ist der Matching-Feature-Effekt relativ gut. Benutzer können einige detailliertere statistische Daten für ein einzelnes Material, einen einzelnen Inhaltstyp und einen einzelnen Blogger erstellen, was einige Vorteile bringen kann.
Darüber hinaus sind multimodale Funktionen auch wertvoller, da das gesamte Empfehlungsmodell auf dem Benutzerverhalten basiert. Es gibt einige seltene und unpopuläre Elemente, deren Benutzerverhalten im gesamten System unzureichend ist Dieses Mal kann die Einführung von mehr Vorkenntnissen mehr Vorteile bringen. Multimodalität führt durch die Einführung von NLP und anderen Technologien eine Reihe von Semantiken ein, die sowohl für Niederfrequenz- als auch für Kaltstarts hilfreich sind.
Dieses Team hat zwei Arten von Methoden entwickelt, um multimodale Funktionen einzuführen: Die erste Art besteht darin, multimodale Einbettungen in das Empfehlungsmodell zu integrieren, die Gradienten dieser zugrunde liegenden Einbettungen einzufrieren und sie dann auf das obere MLP zu aktualisieren Die andere besteht darin, multimodale Einbettungen in das Empfehlungsmodell zu integrieren. Eine Methode besteht darin, vor der Eingabe des Empfehlungsmodells die Cluster-IDs in das empfohlene Modell einzufügen. Dies ist eine einfachere Möglichkeit, Informationen einzuführen zum Empfehlungsmodell, es gehen aber auch einige multimodale konkrete semantische Informationen verloren.
Die beiden oben genannten Methoden wurden in unserem Unternehmen häufig ausprobiert. Die erste Methode erhöht die Komplexität des Modells und erfordert viel räumliche Transformation, das Finden von Merkmalsbedeutung usw., kann jedoch gute Ergebnisse bringen Die zweite Methode verwendet Cluster-IDs zum Lernen, die Komplexität liegt außerhalb des Modells, der Online-Dienst ist relativ einfach, der Effekt kann etwa 90 % erreichen und einige statistische Funktionen können auch mit den Cluster-IDs durchgeführt werden. Die Kombination funktioniert gut.
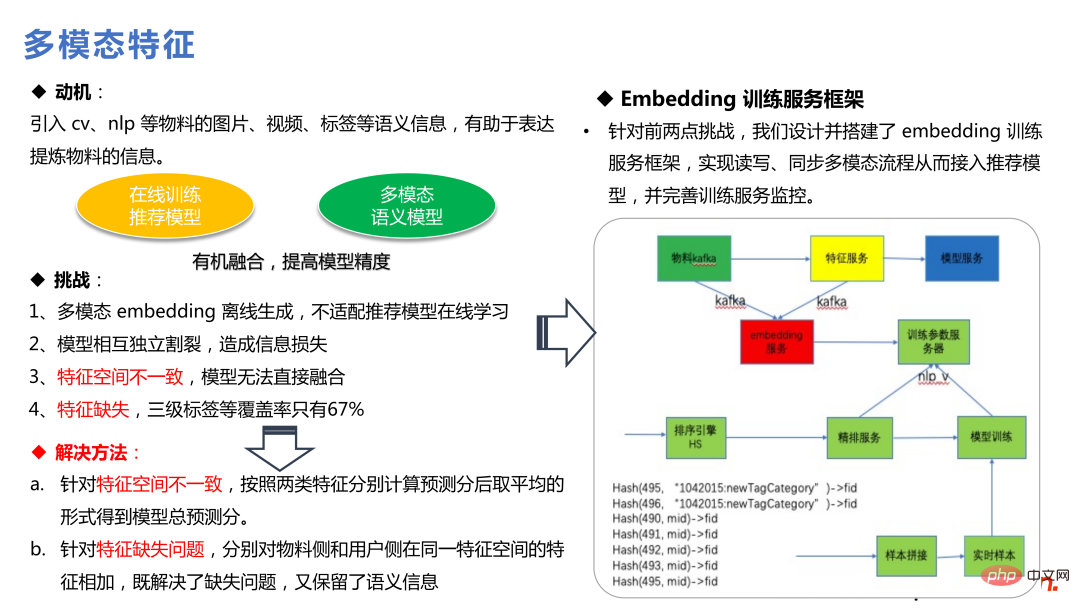
Nach dem Hinzufügen multimodaler Funktionen besteht der größte Vorteil in hochwertigen Materialien mit geringer Belichtung, die das Kaltstartproblem lösen können. Die Empfehlung von Materialien mit relativ geringer Exposition, die das Modell nicht vollständig erlernen kann, wird stark auf multimodale Gremien angewiesen sein, um mehr Informationen bereitzustellen, was auch für die Unternehmensökologie von positivem Wert ist.

Die Motivation für Co-Action ist: Vergebliches Ausprobieren von DeepFM, Wide Deep und anderen Feature-Cross-Methoden. Es wird vermutet, dass das Cross-Feature im Widerspruch zur teilweisen gemeinsamen Einbettung von DNN steht. Gemeinsames Handeln ist gleichbedeutend mit dem Hinzufügen von Lagerraum und der Schaffung von separatem Lagerraum für Crossover. Dadurch wird der Ausdrucksraum vergrößert und es werden auch gute Gewinne im Unternehmen erzielt.

3. Konsistenz des Link-Ausdrucks
In diesem Teil geht es um grobes Sortieren und Abrufen. Für das Empfehlungsgeschäft ist die Logik das gleiche Problem, obwohl die Rechenleistung die Feinsortierung von Millionen von Kandidatensätzen nicht unterstützen kann und diese in Rückruf, Grobsortierung und Feinsortierung unterteilt sind. Wie in der Abbildung unten gezeigt, wird die Grobsortierung beispielsweise abgeschnitten, und der endgültige Inhalt für die Feinsortierung beträgt nur etwa 1.000. Wenn sich die Ausdrücke der Grobsortierung und der Feinsortierung während des Abschneidevorgangs erheblich unterscheiden, erfolgt die Feinsortierung Die Punktzahl wird in Zukunft wahrscheinlich höher sein. Der Inhalt ist gekürzt. Die Merkmale und Modellstrukturen der Feinsortierung und der Grobsortierung ähneln im Allgemeinen dem Rückrufrahmen, bei dem es sich um eine ungefähre Struktur des Vektorabrufs handelt, und es kommt zu natürlichen Ausdrucksunterschieden bei der Feinsortierung Modell erscheinen. Wenn die Konsistenz verbessert werden kann, werden auch die Geschäftsindikatoren steigen, da beide Parteien die gleichen sich ändernden Trends erfassen können.
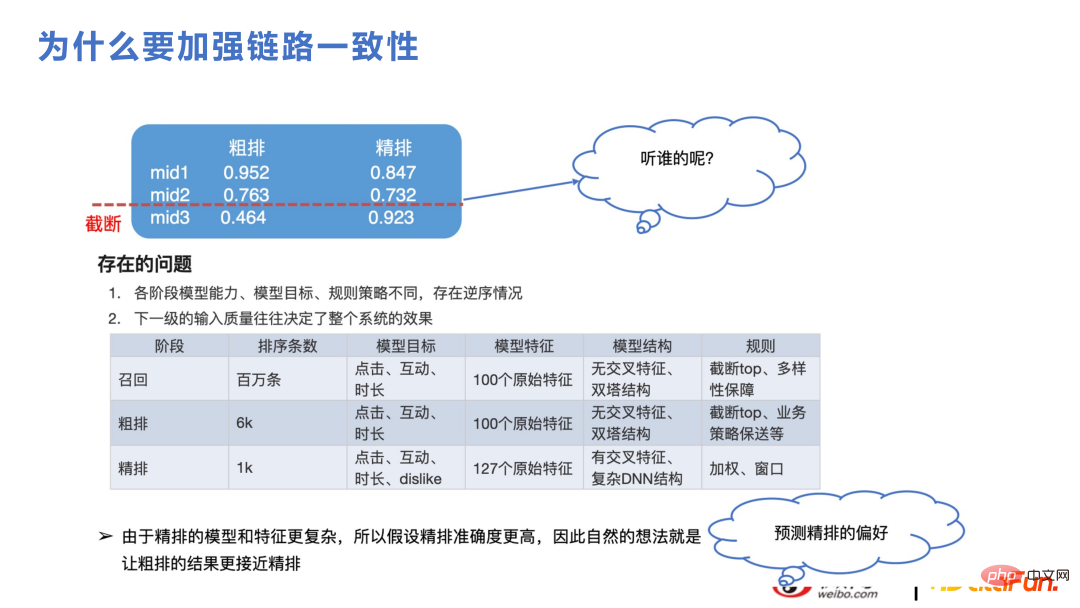
Die folgende Abbildung zeigt den technischen Kontext im groben Konsistenziterationsprozess. Oben ist die technische Linie von Twin Towers und unten ist die technische Linie von DNN. Da die Merkmale der Twin Towers relativ spät interagieren, wurden viele Möglichkeiten für die Überschneidung der Merkmale der Twin Towers hinzugefügt. Allerdings ist die Obergrenze der Vektorabrufmethode etwas zu niedrig, sodass es ab 2022 einen DNN-Zweig für die Grobsortierung geben wird, was einen größeren Druck auf die technische Architektur wie Feature-Screening, Netzwerkbereinigung und Leistungsoptimierung ausüben wird usw. und Die Anzahl der gleichzeitig bewerteten Elemente wird ebenfalls verringert als zuvor, aber die Bewertungen sind besser, sodass eine geringere Anzahl von Elementen akzeptabel ist.
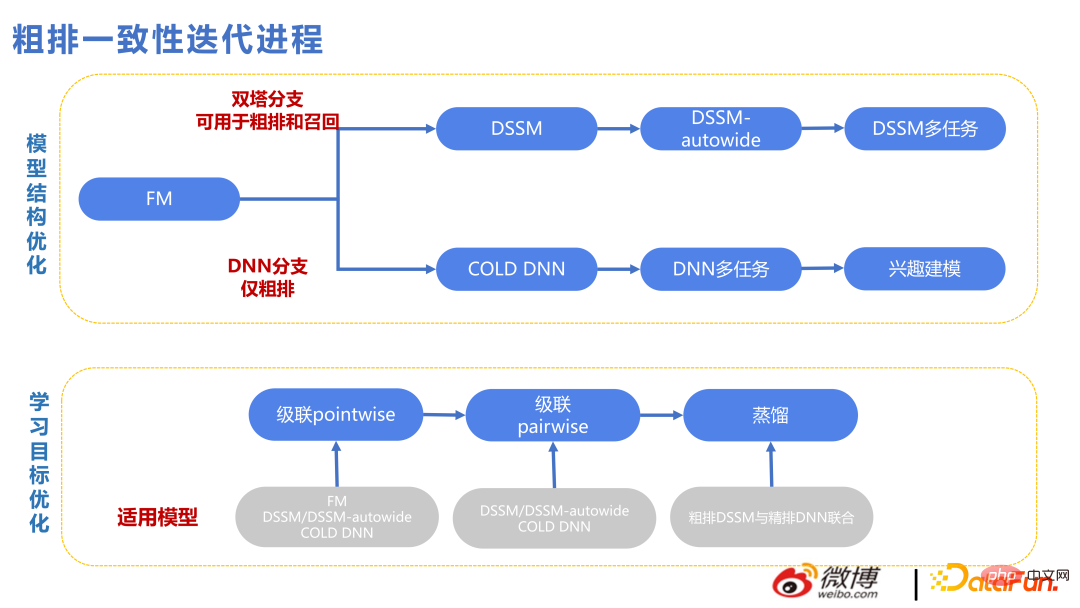
DSSM-autowide ist ein Crossover ähnlich wie Deep-FM auf Basis von Twin Towers, das jedoch für das nächste Projekt mit einer neuen Crossover-Methode zu einer Steigerung der Geschäftsindikatoren geführt hat. Es wird keine Verbesserung geben.
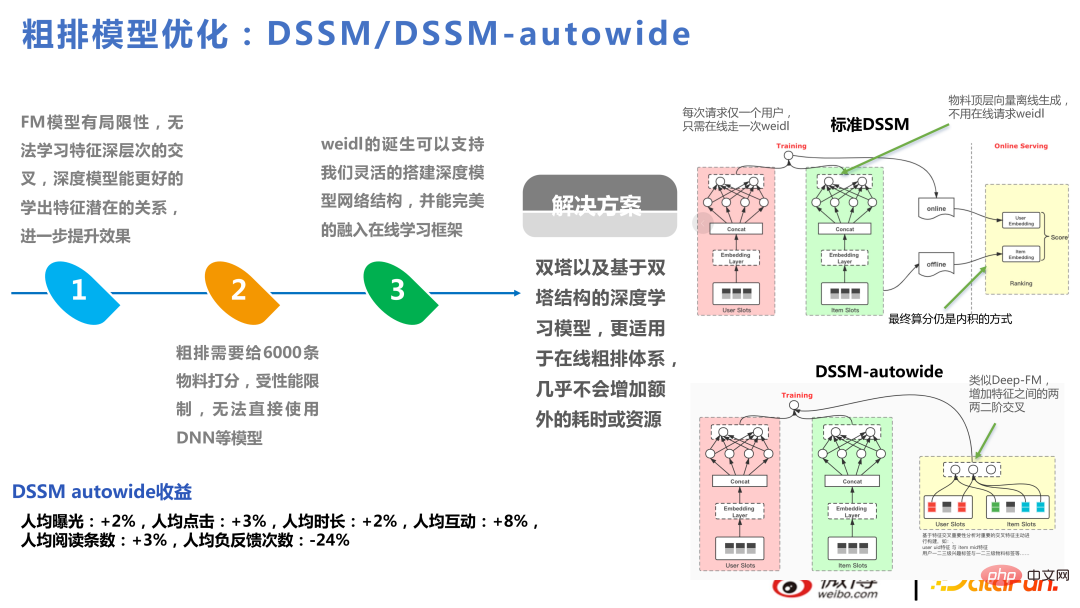
Daher sind wir der Meinung, dass die Vorteile, die sich aus den Zwillingstürmen ergeben können, relativ begrenzt sind. Wir haben auch ein grobes Multitasking-Modell basierend auf den Zwillingstürmen ausprobiert, konnten das Problem mit den Zwillingstürmen jedoch immer noch nicht umgehen.
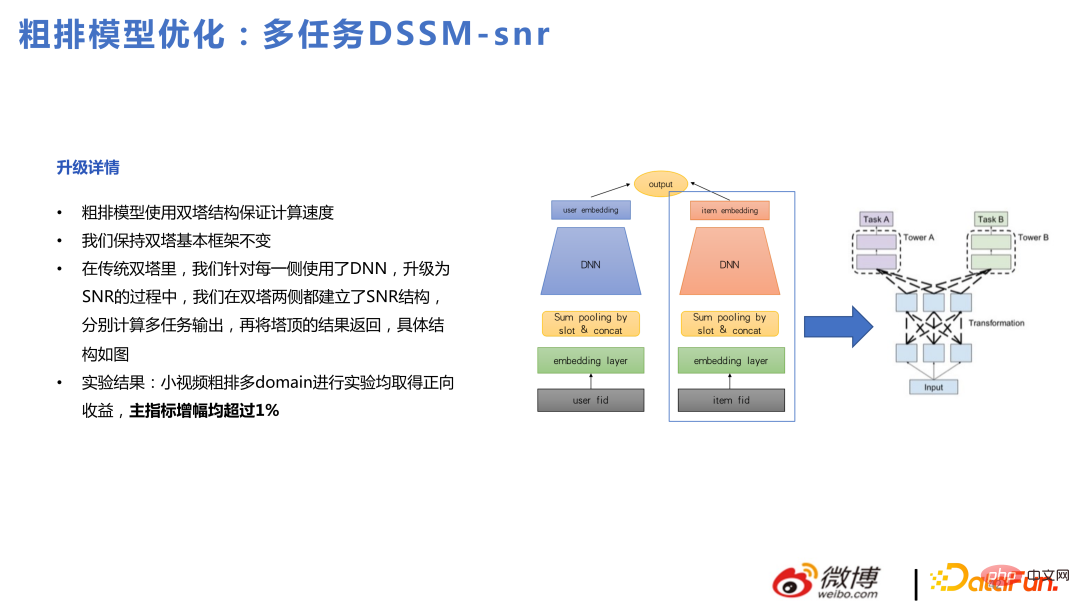
Basierend auf den oben genannten Problemen optimierte unser -Team das Grobsortiermodell und verwendete DNN- und Kaskadenmodelle, um eine Stapelarchitektur zu erstellen.
Das Kaskadenmodell kann zuerst mit Twin Towers gefiltert und dann zur Grobsortierung gefiltert und auf das DNN-Modell gekürzt werden, was einer Grobsortierung und einer Feinsortierung innerhalb der Grobsortierung entspricht. Nach der Umstellung auf ein DNN-Modell kann es komplexere Strukturen unterstützen und sich schneller an veränderte Benutzerinteressen anpassen.
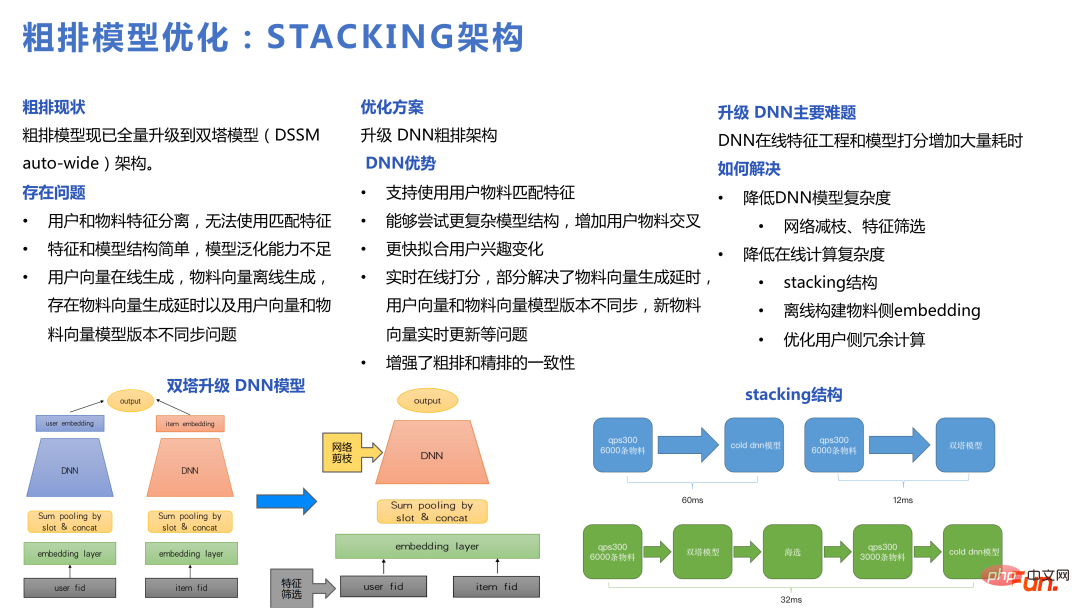
Die Kaskade spielt im Framework eine wichtigere Rolle. Ohne das Kaskadenmodell ist es schwierig, aus einer relativ großen Kandidatenmenge eine kleine Auswahl für die grobe Verwendung von DNN zu treffen. Das Wichtigste in der Kaskade ist, wie das Beispiel aufgebaut wird. Sie können die Abbildung unten sehen. Aus der Millionen-Level-Materialbibliothek rufen wir Tausende von Materialien zur Grob- und Feinsortierung innerhalb von 1.000 ab, und die Anzahl der Benutzeraktionen lag im einstelligen Bereich Bibliothek für den Benutzer. Bei der Kaskadenausführung besteht der Kernpunkt darin, dass jeder Teil abgetastet werden muss, um einige schwierige Paare und relativ einfache Paare zu bilden, um aus dem Kaskadenmodell zu lernen.
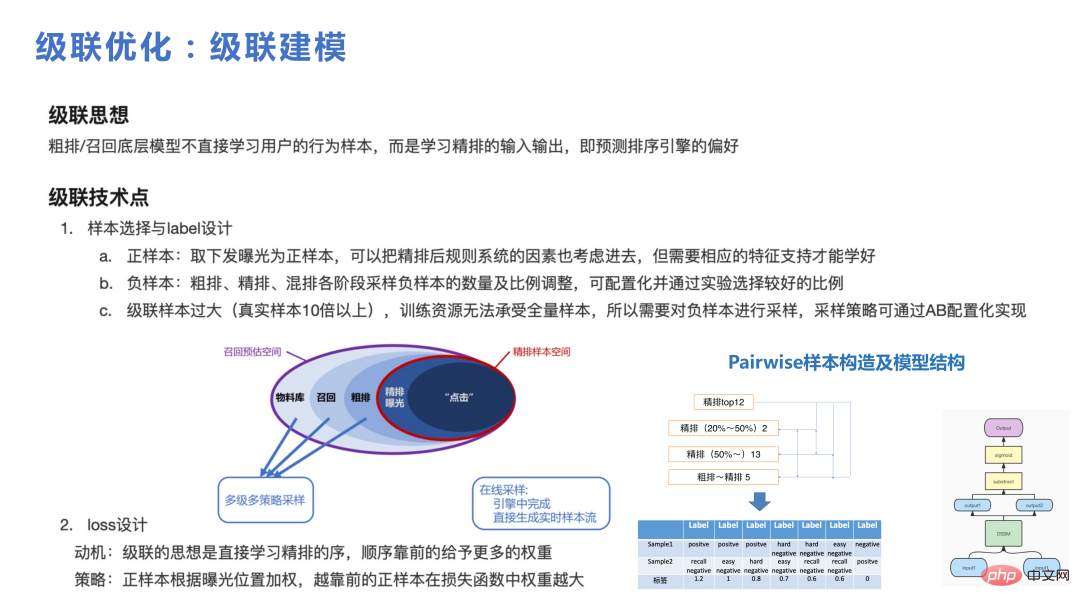
Die folgende Abbildung zeigt die Vorteile der Kaskadenoptimierung und der globalen Negativabtastung, die hier nicht im Detail vorgestellt werden.
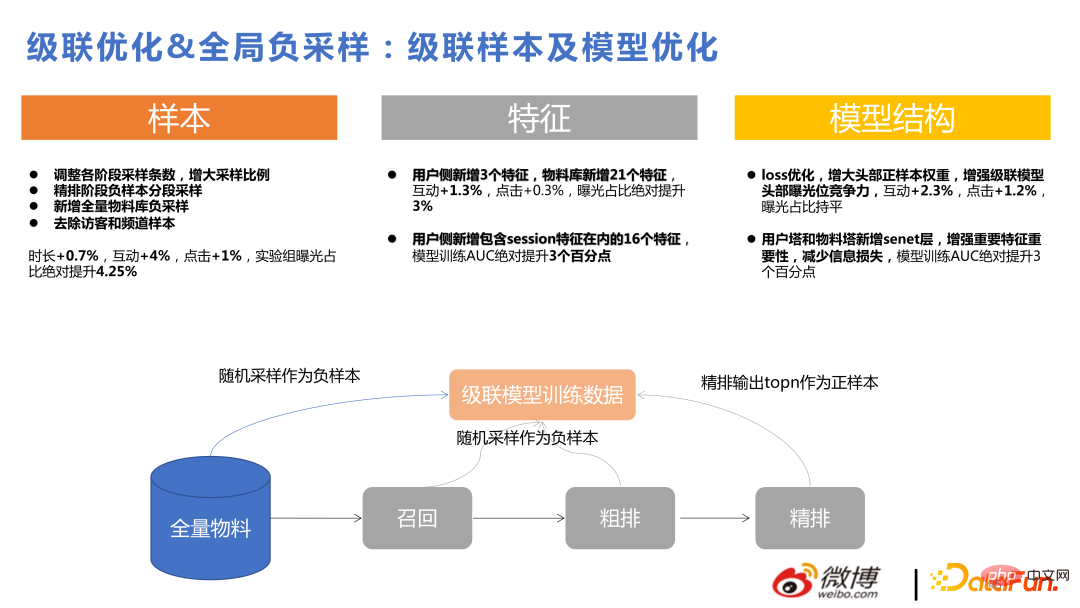
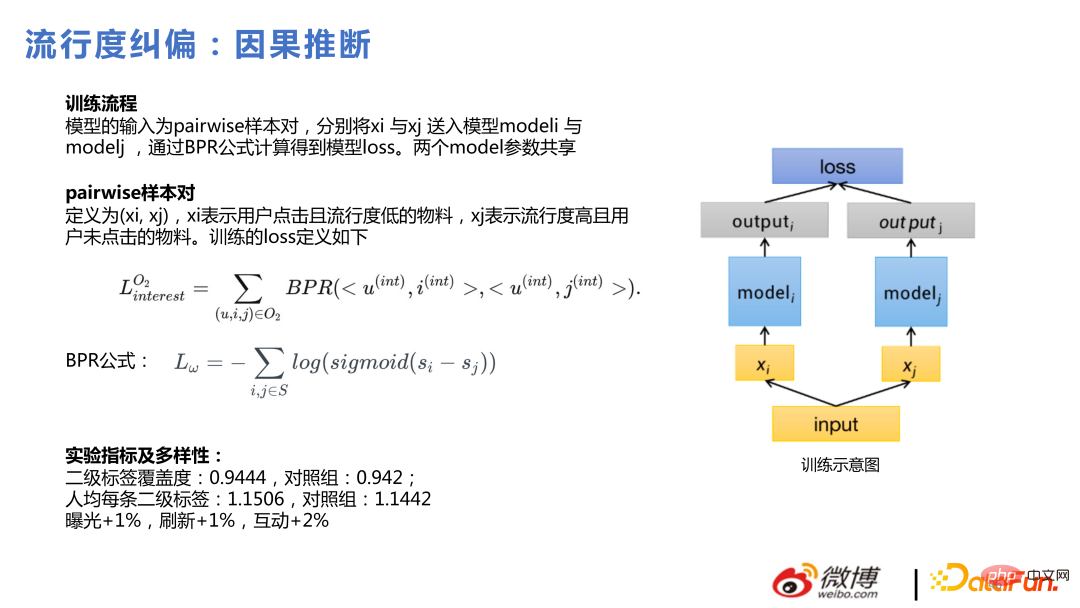
Als nächstes stellen wir die jüngste beliebte kausale Schlussfolgerung vor.
Die Motivation für uns, kausale Schlussfolgerungen zu verwenden, besteht darin, den Benutzern Dinge zu vermitteln, die jedem gefallen, der Klickeffekt der Benutzer ist gut, aber die Benutzer selbst haben auch einige relativ Nischeninteressen, also pushen Diese Nutzer bevorzugen auch Nischenmaterialien. Diese beiden Dinge sind für Benutzer gleich, aber je mehr Nischendinge eingeführt werden können, desto einfacher ist es, diese Art von Problem durch das Modell zu lösen .
Die spezifische Methode besteht darin, paarweise Stichprobenpaare zu gruppieren und die Bayes'sche Methode zu verwenden, um das Verlustmodell für Materialien zu trainieren, die von Benutzern angeklickt werden und eine geringe Popularität aufweisen, sowie für Materialien, die sehr beliebt sind, aber von Benutzern nicht angeklickt werden .
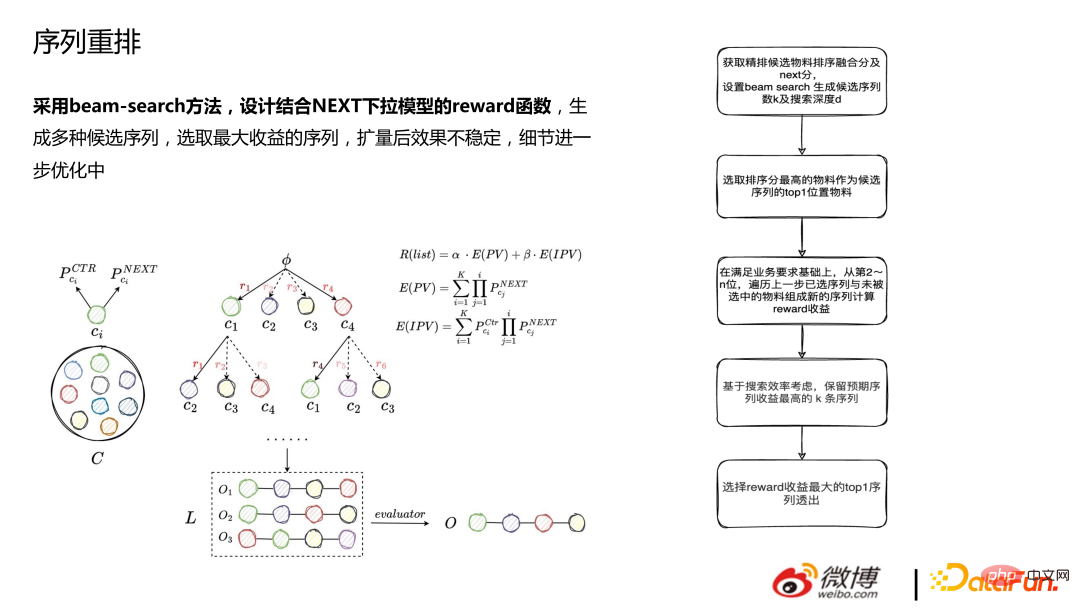
In unserer Praxis ist es einfacher, kausale Schlussfolgerungen zu ziehen, wenn sie in der Grobsortierungs- und Rückrufphase durchgeführt werden, als in der Feinsortierungsphase. Der Grund dafür ist, dass das Feinranking bereits über gute Personalisierungsfähigkeiten verfügt. Auch wenn Grobranking und Rückruf DNNs verwenden, besteht immer noch eine Lücke in der Personalisierungsfähigkeit des gesamten Modells Die Personalisierungsfähigkeit ist relativ gering. Der Effekt der Verwendung kausaler Schlussfolgerungen an Orten mit starken Personalisierungsfähigkeiten ist definitiv offensichtlicher als an Orten mit starken Personalisierungsfähigkeiten. IV. Weitere technische Punkte Modell zum Generieren verschiedener Kandidatensequenzen: Wählen Sie die Sequenz mit dem größten Gewinn aus. Der Effekt ist nach der Erweiterung instabil und die Details werden weiter optimiert.
2. Diagrammtechnologie
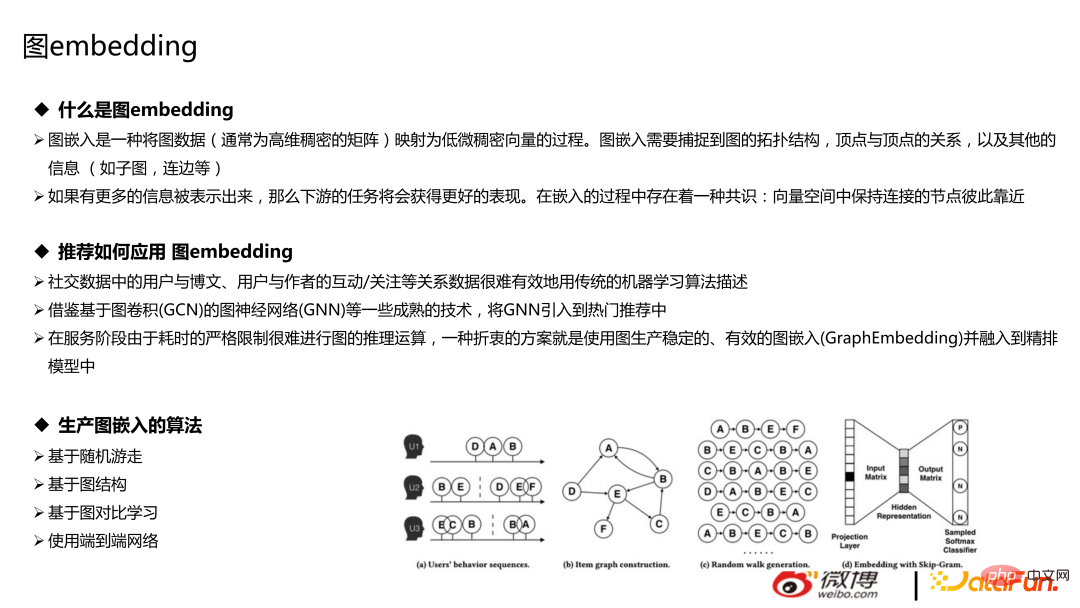
Die Diagrammtechnologie besteht hauptsächlich aus zwei Teilen: Diagrammdatenbank und Diagrammeinbettung. Für Empfehlungen ist es bequemer und kostengünstiger, eine Diagrammdatenbank zu verwenden. Das Einbetten von Graphen bezieht sich auf den Prozess des zufälligen Gehens von Knoten der Walking-Klasse, bei dem Diagrammdaten (normalerweise hochdimensionale dichte Matrizen) in niedrigdimensionale dichte Vektoren abgebildet werden. Beim Einbetten von Diagrammen müssen die topologische Struktur des Diagramms, die Beziehung zwischen Scheitelpunkten und andere Informationen (z. B. Unterdiagramme, Kanten usw.) erfasst werden, die hier nicht vorgestellt werden.
 Algorithmen basierend auf Random Walk, Graphstruktur, Graphvergleichslernen und anderen Algorithmen können verwendet werden, um die Interaktion/Aufmerksamkeit zwischen Benutzern und Blogbeiträgen, Benutzern und Autoren abzurufen. Die gängige Methode besteht darin, Bilder, Text, Benutzer usw. einzubetten und dem Modell Funktionen hinzuzufügen. Es gibt auch einige innovativere Versuche, wie den direkten Aufbau eines End-to-End-Netzwerks und die Verwendung von GNN für Empfehlungen.
Algorithmen basierend auf Random Walk, Graphstruktur, Graphvergleichslernen und anderen Algorithmen können verwendet werden, um die Interaktion/Aufmerksamkeit zwischen Benutzern und Blogbeiträgen, Benutzern und Autoren abzurufen. Die gängige Methode besteht darin, Bilder, Text, Benutzer usw. einzubetten und dem Modell Funktionen hinzuzufügen. Es gibt auch einige innovativere Versuche, wie den direkten Aufbau eines End-to-End-Netzwerks und die Verwendung von GNN für Empfehlungen.
Das Bild unten ist das aktuelle End-to-End-Modell. Wir probieren es noch aus und es ist nicht die Hauptverkehrsversion online.
Das Bild unten basiert auf dem Diagrammnetzwerk zum Generieren der Einbettung, und das Bild rechts zeigt die Ähnlichkeit, die basierend auf der Domäne des Kontos berechnet wird. Für Weibo ist es vorteilhaft, die Einbettung anhand der Aufmerksamkeitsbeziehung zu berechnen.
5. Frage- und Antwortsitzung
F1: Es gibt viele Elemente im empfohlenen Informationsfluss, aber Sie blättern nur, ohne zu klicken. Durch die Verweildauer des Artikels auf der Listenseite?
A1: Ja, wenn es um das Informationsflussgeschäft geht, ist die Dauer ein wichtigerer Optimierungsindikator. Es ist heute nicht einfach, direkt zu optimieren, wie lange Benutzer insgesamt auf der APP bleiben, wenn Indikatoren zur Laufzeitoptimierung verwendet werden. Optimierter ist jedoch die Verweildauer von Benutzern bei Elementen. Wenn die Dauer nicht als Optimierungsziel betrachtet wird, ist es einfacher, viele Inhalte mit oberflächlichem Konsum zu fördern.
F2: Kommt es zu Konsistenzproblemen bei der Echtzeitaktualisierung des Modells, wenn während des Trainings ein Failover auftritt? Wie gehe ich mit Modellkonsistenzproblemen um?
A2: Wenn es sich beim empfohlenen Lernen und Training um eine CPU handelt, erfolgt die Erfassung in der Regel nicht in einer globalen Runde zusammensetzen und auf ps aktualisieren und dann die nächste Runde starten. Aufgrund von Leistungsproblemen werden die Leute dies grundsätzlich nicht tun. Unabhängig davon, ob es sich um Echtzeit- oder Online-Lernen handelt, kann keine starke Konsistenz erreicht werden.
Wenn während Ihres Trainings ein Failover auftritt und Streaming-Training verwendet wird, wird es im Datenstrom aufgezeichnet, z. B. Kafka oder Flink, um aufzuzeichnen, wo Ihr aktueller Plan trainiert wird, auf Ihrem PS auch Aufzeichnungen Ihres letzten Trainings, was der Gesamtdifferenz ähnelt.
F3: Wird die Verwendung einer feinen Sortierreihenfolge für den Rückruf die Iterationsgrenze des Rückrufmodells senken?
A3: Die Obergrenze der Iteration kann als Rückrufobergrenze verstanden werden. Dann darf die Rückrufobergrenze definitiv nicht überschritten werden. Wenn die Rechenleistung jetzt beispielsweise unendlich ist, ist das in Ordnung Sortierung wird zur Produktion von 5 Millionen Materialien eingesetzt. Ist dies die beste Art, das Geschäft abzuwickeln? Wenn die Investition in den Rückruf nicht so groß ist, versuchen Sie, die besten Teile für den Experten herauszufinden. Lassen Sie ihn beispielsweise die Top 15 aus den 6.000 im Rückruf und die Top 15 aus den 5 Millionen auswählen, was relativ nahe beieinander liegt . Das Rückrufmodul leistet einen besseren Job. Wenn jeder dies versteht, wird das Erinnern an die Reihenfolge der Feinsortierung die Online-Iteration nicht reduzieren, sondern sich der Obergrenze nähern. Allerdings ist dies auch unsere Meinung. Abhängig von Ihrer eigenen Geschäftsausrichtung ist die Schlussfolgerung möglicherweise nicht allgemeingültig.
Das obige ist der detaillierte Inhalt vonTechnische Weiterentwicklung des Echtzeit-Großmodells für Weibo-Empfehlung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Am 30. Mai kündigte Tencent ein umfassendes Upgrade seines Hunyuan-Modells an. Die auf dem Hunyuan-Modell basierende App „Tencent Yuanbao“ wurde offiziell eingeführt und kann in den App-Stores von Apple und Android heruntergeladen werden. Im Vergleich zur Hunyuan-Applet-Version in der vorherigen Testphase bietet Tencent Yuanbao Kernfunktionen wie KI-Suche, KI-Zusammenfassung und KI-Schreiben für Arbeitseffizienzszenarien. Yuanbaos Gameplay ist außerdem umfangreicher und bietet mehrere Funktionen für KI-Anwendungen , und neue Spielmethoden wie das Erstellen persönlicher Agenten werden hinzugefügt. „Tencent strebt nicht danach, der Erste zu sein, der große Modelle herstellt.“ Liu Yuhong, Vizepräsident von Tencent Cloud und Leiter des großen Modells von Tencent Hunyuan, sagte: „Im vergangenen Jahr haben wir die Fähigkeiten des großen Modells von Tencent Hunyuan weiter gefördert.“ . In die reichhaltige und umfangreiche polnische Technologie in Geschäftsszenarien eintauchen und gleichzeitig Einblicke in die tatsächlichen Bedürfnisse der Benutzer gewinnen
 Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Tan Dai, Präsident von Volcano Engine, sagte, dass Unternehmen, die große Modelle gut implementieren wollen, vor drei zentralen Herausforderungen stehen: Modelleffekt, Inferenzkosten und Implementierungsschwierigkeiten: Sie müssen über eine gute Basisunterstützung für große Modelle verfügen, um komplexe Probleme zu lösen, und das müssen sie auch Dank der kostengünstigen Inferenzdienste können große Modelle weit verbreitet verwendet werden, und es werden mehr Tools, Plattformen und Anwendungen benötigt, um Unternehmen bei der Implementierung von Szenarien zu unterstützen. ——Tan Dai, Präsident von Huoshan Engine 01. Das große Sitzsackmodell feiert sein Debüt und wird häufig genutzt. Das Polieren des Modelleffekts ist die größte Herausforderung für die Implementierung von KI. Tan Dai wies darauf hin, dass ein gutes Modell nur durch ausgiebigen Gebrauch poliert werden kann. Derzeit verarbeitet das Doubao-Modell täglich 120 Milliarden Text-Tokens und generiert 30 Millionen Bilder. Um Unternehmen bei der Umsetzung groß angelegter Modellszenarien zu unterstützen, wird das von ByteDance unabhängig entwickelte Beanbao-Großmodell durch den Vulkan gestartet
 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
1. Einführung in den Hintergrund Lassen Sie uns zunächst die Entwicklungsgeschichte von Yunwen Technology vorstellen. Yunwen Technology Company ... 2023 ist die Zeit, in der große Modelle vorherrschen. Viele Unternehmen glauben, dass die Bedeutung von Diagrammen nach großen Modellen stark abgenommen hat und die zuvor untersuchten voreingestellten Informationssysteme nicht mehr wichtig sind. Mit der Förderung von RAG und der Verbreitung von Data Governance haben wir jedoch festgestellt, dass eine effizientere Datenverwaltung und qualitativ hochwertige Daten wichtige Voraussetzungen für die Verbesserung der Wirksamkeit privatisierter Großmodelle sind. Deshalb beginnen immer mehr Unternehmen, darauf zu achten zu wissenskonstruktionsbezogenen Inhalten. Dies fördert auch den Aufbau und die Verarbeitung von Wissen auf einer höheren Ebene, wo es viele Techniken und Methoden gibt, die erforscht werden können. Es ist ersichtlich, dass das Aufkommen einer neuen Technologie nicht alle alten Technologien besiegt, sondern auch neue und alte Technologien integrieren kann.
 Xiaomi Byte schließt sich zusammen! Ein großes Modell von Xiao Ais Zugang zu Doubao: bereits auf Mobiltelefonen und SU7 installiert
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte schließt sich zusammen! Ein großes Modell von Xiao Ais Zugang zu Doubao: bereits auf Mobiltelefonen und SU7 installiert
Jun 13, 2024 pm 05:11 PM
Laut Nachrichten vom 13. Juni hat Xiaomis Assistent für künstliche Intelligenz „Xiao Ai“ laut Bytes öffentlichem Bericht „Volcano Engine“ eine Zusammenarbeit mit Volcano Engine erzielt. Die beiden Parteien werden ein intelligenteres interaktives KI-Erlebnis auf der Grundlage des großen Beanbao-Modells erzielen . Berichten zufolge kann das von ByteDance erstellte groß angelegte Beanbao-Modell bis zu 120 Milliarden Text-Tokens effizient verarbeiten und täglich 30 Millionen Inhalte generieren. Xiaomi nutzte das große Doubao-Modell, um die Lern- und Denkfähigkeiten seines eigenen Modells zu verbessern und einen neuen „Xiao Ai Classmate“ zu schaffen, der nicht nur die Benutzerbedürfnisse genauer erfasst, sondern auch eine schnellere Reaktionsgeschwindigkeit und umfassendere Inhaltsdienste bietet. Wenn ein Benutzer beispielsweise nach einem komplexen wissenschaftlichen Konzept fragt, &ldq
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
