
 Backend-Entwicklung
Python-Tutorial
So verwenden Sie Jieba für Worthäufigkeitsstatistiken und Schlüsselwortextraktion in Python
Backend-Entwicklung
Python-Tutorial
So verwenden Sie Jieba für Worthäufigkeitsstatistiken und Schlüsselwortextraktion in Python
So verwenden Sie Jieba für Worthäufigkeitsstatistiken und Schlüsselwortextraktion in Python

1 Worthäufigkeitsstatistik
1.1 Einfache Worthäufigkeitsstatistik
1. Importieren Sie die jieba-Bibliothek und definieren Sie Text jieba库并定义文本
import jieba text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。"
2.对文本进行分词
words = jieba.cut(text)
这一步会将文本分成若干个词语,并返回一个生成器对象words,可以使用for循环遍历所有的词语。
3. 统计词频
word_count = {}
for word in words:
if len(word) > 1:
word_count[word] = word_count.get(word, 0) + 1这一步通过遍历所有的词语,统计每个词语出现的次数,并保存到一个字典word_count中。在统计词频时,可以通过去除停用词等方式进行优化,这里只是简单地过滤了长度小于2的词语。
4. 结果输出
for word, count in word_count.items():
print(word, count)
1.2 加入停用词
为了更准确地统计词频,我们可以在词频统计中加入停用词,以去除一些常见但无实际意义的词语。具体步骤如下:
定义停用词列表
import jieba # 停用词列表 stopwords = ['是', '一种', '等']
对文本进行分词,并过滤停用词
text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。" words = jieba.cut(text) words_filtered = [word for word in words if word not in stopwords and len(word) > 1]
统计词频并输出结果
word_count = {}
for word in words_filtered:
word_count[word] = word_count.get(word, 0) + 1
for word, count in word_count.items():
print(word, count)加入停用词后,输出的结果是:

可以看到,被停用的一种这个词并没有显示出来。
2 关键词提取
2.1 关键词提取原理
与对词语进行单纯计数的词频统计不同,jieba提取关键字的原理是基于TF-IDF(Term Frequency-Inverse Document Frequency)算法。TF-IDF算法是一种常用的文本特征提取方法,可以衡量一个词语在文本中的重要程度。
具体来说,TF-IDF算法包含两个部分:
Term Frequency(词频):指一个词在文本中出现的次数,通常用一个简单的统计值表示,例如词频、二元词频等。词频反映了一个词在文本中的重要程度,但是忽略了这个词在整个语料库中的普遍程度。
Inverse Document Frequency(逆文档频率):指一个词在所有文档中出现的频率的倒数,用于衡量一个词的普遍程度。逆文档频率越大,表示一个词越普遍,重要程度越低;逆文档频率越小,表示一个词越独特,重要程度越高。
TF-IDF算法通过综合考虑词频和逆文档频率,计算出每个词在文本中的重要程度,从而提取关键字。在jieba中,关键字提取的具体实现包括以下步骤:
对文本进行分词,得到分词结果。
统计每个词在文本中出现的次数,计算出词频。
统计每个词在所有文档中出现的次数,计算出逆文档频率。
综合考虑词频和逆文档频率,计算出每个词在文本中的TF-IDF值。
对TF-IDF值进行排序,选取得分最高的若干个词作为关键字。
举个例子:
F(Term Frequency)指的是某个单词在一篇文档中出现的频率。计算公式如下:
T F = ( 单词在文档中出现的次数 ) / ( 文档中的总单词数 )
例如,在一篇包含100个单词的文档中,某个单词出现了10次,则该单词的TF为
10 / 100 = 0.1
IDF(Inverse Document Frequency)指的是在文档集合中出现某个单词的文档数的倒数。计算公式如下:
I D F = l o g ( 文档集合中的文档总数 / 包含该单词的文档数 )
例如,在一个包含1000篇文档的文档集合中,某个单词在100篇文档中出现过,则该单词的IDF为 l o g ( 1000 / 100 ) = 1.0
TFIDF是将TF和IDF相乘得到的结果,计算公式如下:
T F I D F = T F ∗ I D F
需要注意的是,TF-IDF算法只考虑了词语在文本中的出现情况,而忽略了词语之间的关联性。因此,在一些特定的应用场景中,需要使用其他的文本特征提取方法,例如词向量、主题模型等。
2.2 关键词提取代码
import jieba.analyse
# 待提取关键字的文本
text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。"
# 使用jieba提取关键字
keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=True)
# 输出关键字和对应的权重
for keyword, weight in keywords:
print(keyword, weight)在这个示例中,我们首先导入了jieba.analyse模块,然后定义了一个待提取关键字的文本text。接着,我们使用jieba.analyse.extract_tags()函数提取关键字,其中topK参数表示需要提取的关键字个数,withWeightrrreee #🎜🎜 #2. Wortsegmentierung des Textes
rrreee
words zurück, für das Sie verwenden können Alle Wörter durchlaufen. 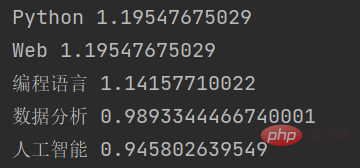 3. Worthäufigkeit zählen
3. Worthäufigkeit zählen
word_count Code> Mitte. Beim Zählen der Worthäufigkeiten kann eine Optimierung durch Entfernen von Stoppwörtern erfolgen. Dabei werden Wörter mit einer Länge kleiner als 2 einfach gefiltert. #🎜🎜##🎜🎜#4. Ergebnisausgabe#🎜🎜#rrreee#🎜🎜#<img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/887/227/168302796823258.png" class="lazy" alt="So verwenden Sie Jieba in Python für Worthäufigkeitsstatistiken und Schlüsselwortextraktion">#🎜🎜##🎜🎜#1.2 Stoppwörter hinzufügen#🎜🎜##🎜🎜#Um die Worthäufigkeit genauer zu zählen, können wir dies tun Stoppwörter zur Worthäufigkeit hinzufügen Stoppwörter werden zur Statistik hinzugefügt, um einige häufige, aber bedeutungslose Wörter zu entfernen. Die spezifischen Schritte sind wie folgt: #🎜🎜##🎜🎜#Definieren Sie die Stoppwortliste #🎜🎜#rrreee#🎜🎜# Segmentieren Sie den Text und filtern Sie die Stoppwörter #🎜🎜#rrreee#🎜🎜# Zählen Sie die Worthäufigkeit und geben Sie die Ergebnisse aus #🎜🎜#rrreee#🎜🎜#Nach dem Hinzufügen von Stoppwörtern lautet das Ausgabeergebnis: #🎜🎜##🎜🎜#<img src="https://img.php.cn/upload/article/%20000/887%20/227/168302796888659.png" alt="So verwenden Sie Jieba für Worthäufigkeitsstatistiken und Schlüsselwortextraktion in Python">#🎜🎜##🎜🎜#Sie können sehen, dass der deaktivierte <code>Typist > Das Wort wird nicht angezeigt. #🎜🎜##🎜🎜#2 Schlüsselwortextraktion#🎜🎜##🎜🎜#2.1 Schlüsselwortextraktionsprinzip#🎜🎜##🎜🎜#Im Gegensatz zu Worthäufigkeitsstatistiken, die einfach Wörter zählen, basiert Jiebas Prinzip der Schlüsselwortextraktion darauf der TF-IDF-Algorithmus (Term Frequency-Inverse Document Frequency). Der TF-IDF-Algorithmus ist eine häufig verwendete Methode zur Extraktion von Textmerkmalen, mit der die Bedeutung eines Wortes im Text gemessen werden kann. #🎜🎜##🎜🎜# Konkret besteht der TF-IDF-Algorithmus aus zwei Teilen: #🎜🎜#- #🎜🎜#Term Frequency (Begriffshäufigkeit): Bezieht sich auf gibt an, wie oft ein Wort in einem Text vorkommt, normalerweise dargestellt durch einen einfachen statistischen Wert, wie z. B. Worthäufigkeit, Bigramm-Worthäufigkeit usw. Die Worthäufigkeit spiegelt die Bedeutung eines Wortes im Text wider, ignoriert jedoch die Verbreitung des Wortes im gesamten Korpus. #🎜🎜#
- #🎜🎜#Inverse Dokumenthäufigkeit: bezieht sich auf den Kehrwert der Häufigkeit, mit der ein Wort in allen Dokumenten vorkommt, und wird verwendet, um die Häufigkeit eines Wortes zu messen. Je größer die inverse Dokumenthäufigkeit, desto häufiger ist ein Wort und je geringer die inverse Dokumenthäufigkeit, desto eindeutiger ist das Wort und desto höher die Bedeutung. #🎜🎜#
- #🎜🎜# Führen Sie eine Wortsegmentierung für den Text durch und erhalten Sie die Wortsegmentierungsergebnisse. #🎜🎜#
- #🎜🎜# Zählen Sie, wie oft jedes Wort im Text vorkommt und berechnen Sie die Worthäufigkeit. #🎜🎜#
- #🎜🎜# Zählen Sie, wie oft jedes Wort in allen Dokumenten vorkommt, und berechnen Sie die umgekehrte Dokumenthäufigkeit. #🎜🎜#
- #🎜🎜# Berechnen Sie unter Berücksichtigung der Worthäufigkeit und der inversen Dokumenthäufigkeit den TF-IDF-Wert jedes Wortes im Text. #🎜🎜#
- #🎜🎜# Sortieren Sie die TF-IDF-Werte und wählen Sie die Wörter mit den höchsten Punktzahlen als Schlüsselwörter aus. #🎜🎜#
#🎜🎜#Zum Beispiel: #🎜🎜#F (Term Frequency) bezieht sich auf das Vorkommen eines bestimmten Wortes in einer Dokumenthäufigkeit des Auftretens. Die Berechnungsformel lautet wie folgt: #🎜🎜#T F = (die Häufigkeit, mit der ein Wort im Dokument vorkommt) / (die Gesamtzahl der Wörter im Dokument) #🎜🎜#Beispiel: In einem Dokument mit 100 Wörtern: Kommt ein bestimmtes Wort zehnmal vor, dann beträgt die TF des Wortes #🎜🎜#10 / 100 = 0,1 #🎜🎜#IDF (Inverse Document Frequency) bezieht sich auf den Kehrwert der Anzahl der Dokumente, in denen ein bestimmtes Wort vorkommt Dokumentensammlung. Die Berechnungsformel lautet wie folgt: #🎜🎜#I D F = l o g (Gesamtzahl der Dokumente in der Dokumentensammlung / Anzahl der Dokumente, die das Wort enthalten) #🎜🎜#In einer Dokumentensammlung mit 1.000 Dokumenten erscheint beispielsweise ein bestimmtes Wort in 100 Dokumenten erscheint in , dann ist die IDF des Wortes log ( 1000 / 100 ) = 1,0 🎜##🎜🎜#Es ist zu beachten, dass der TF-IDF-Algorithmus nur das Vorkommen von Wörtern im Text berücksichtigt und ignoriert die Korrelation zwischen Wörtern. Daher müssen in einigen spezifischen Anwendungsszenarien andere Methoden zur Extraktion von Textmerkmalen verwendet werden, z. B. Wortvektoren, Themenmodelle usw. #🎜🎜##🎜🎜#2.2 Schlüsselwortextraktionscode#🎜🎜#rrreee#🎜🎜#In diesem Beispiel haben wir zuerst das Modul
jieba.analyse importiert und dann einen zu extrahierenden Schlüssel definiert Text des Wortes text. Als nächstes verwenden wir die Funktion jieba.analyse.extract_tags(), um Schlüsselwörter zu extrahieren, wobei der Parameter topK die Anzahl der zu extrahierenden Schlüsselwörter angibt, withWeight code> Der Parameter gibt an, ob der Gewichtungswert des Schlüsselworts zurückgegeben werden soll. Schließlich durchlaufen wir die Schlüsselwortliste und geben jedes Schlüsselwort und seinen entsprechenden Gewichtungswert aus. #🎜🎜#Das Ausgabeergebnis dieser Funktion ist: #🎜🎜##🎜🎜##🎜🎜##🎜🎜#<p>Wie Sie sehen können, hat Jieba basierend auf dem TF-IDF-Algorithmus mehrere Schlüsselwörter im Eingabetext extrahiert und den Gewichtungswert jedes Schlüsselworts zurückgegeben. </p>Das obige ist der detaillierte Inhalt vonSo verwenden Sie Jieba für Worthäufigkeitsstatistiken und Schlüsselwortextraktion in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
Im VS -Code können Sie das Programm im Terminal in den folgenden Schritten ausführen: Erstellen Sie den Code und öffnen Sie das integrierte Terminal, um sicherzustellen, dass das Codeverzeichnis mit dem Terminal Working -Verzeichnis übereinstimmt. Wählen Sie den Befehl aus, den Befehl ausführen, gemäß der Programmiersprache (z. B. Pythons Python your_file_name.py), um zu überprüfen, ob er erfolgreich ausgeführt wird, und Fehler auflösen. Verwenden Sie den Debugger, um die Debugging -Effizienz zu verbessern.
 Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
VS -Code kann zum Schreiben von Python verwendet werden und bietet viele Funktionen, die es zu einem idealen Werkzeug für die Entwicklung von Python -Anwendungen machen. Sie ermöglichen es Benutzern: Installation von Python -Erweiterungen, um Funktionen wie Code -Abschluss, Syntax -Hervorhebung und Debugging zu erhalten. Verwenden Sie den Debugger, um Code Schritt für Schritt zu verfolgen, Fehler zu finden und zu beheben. Integrieren Sie Git für die Versionskontrolle. Verwenden Sie Tools für die Codeformatierung, um die Codekonsistenz aufrechtzuerhalten. Verwenden Sie das Lining -Tool, um potenzielle Probleme im Voraus zu erkennen.
 Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python: Automatisierung, Skript- und Aufgabenverwaltung
Apr 16, 2025 am 12:14 AM
Python zeichnet sich in Automatisierung, Skript und Aufgabenverwaltung aus. 1) Automatisierung: Die Sicherungssicherung wird durch Standardbibliotheken wie OS und Shutil realisiert. 2) Skriptschreiben: Verwenden Sie die PSUTIL -Bibliothek, um die Systemressourcen zu überwachen. 3) Aufgabenverwaltung: Verwenden Sie die Zeitplanbibliothek, um Aufgaben zu planen. Die Benutzerfreundlichkeit von Python und die Unterstützung der reichhaltigen Bibliothek machen es zum bevorzugten Werkzeug in diesen Bereichen.
 Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
VS -Code kann unter Windows 8 ausgeführt werden, aber die Erfahrung ist möglicherweise nicht großartig. Stellen Sie zunächst sicher, dass das System auf den neuesten Patch aktualisiert wurde, und laden Sie dann das VS -Code -Installationspaket herunter, das der Systemarchitektur entspricht und sie wie aufgefordert installiert. Beachten Sie nach der Installation, dass einige Erweiterungen möglicherweise mit Windows 8 nicht kompatibel sind und nach alternativen Erweiterungen suchen oder neuere Windows -Systeme in einer virtuellen Maschine verwenden müssen. Installieren Sie die erforderlichen Erweiterungen, um zu überprüfen, ob sie ordnungsgemäß funktionieren. Obwohl VS -Code unter Windows 8 möglich ist, wird empfohlen, auf ein neueres Windows -System zu upgraden, um eine bessere Entwicklungserfahrung und Sicherheit zu erzielen.
 Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
VS -Code -Erweiterungen stellen böswillige Risiken dar, wie das Verstecken von böswilligem Code, das Ausbeutetieren von Schwachstellen und das Masturbieren als legitime Erweiterungen. Zu den Methoden zur Identifizierung böswilliger Erweiterungen gehören: Überprüfung von Verlegern, Lesen von Kommentaren, Überprüfung von Code und Installation mit Vorsicht. Zu den Sicherheitsmaßnahmen gehören auch: Sicherheitsbewusstsein, gute Gewohnheiten, regelmäßige Updates und Antivirensoftware.
