

ChatGPT von OpenAI ist in der Lage, eine Vielzahl menschlicher Anweisungen zu verstehen und verschiedene Sprachaufgaben gut zu bewältigen. Dies ist dank einer neuartigen Methode zur Feinabstimmung groß angelegter Sprachmodelle namens RLHF (Aligned Human Feedback via Reinforcement Learning) möglich.
Die RLHF-Methode erschließt die Fähigkeit von Sprachmodellen, menschlichen Anweisungen zu folgen, wodurch die Fähigkeiten von Sprachmodellen mit menschlichen Bedürfnissen und Werten in Einklang gebracht werden.
Derzeit verwendet die Forschungsarbeit von RLHF hauptsächlich den PPO-Algorithmus zur Optimierung von Sprachmodellen. Der PPO-Algorithmus enthält jedoch viele Hyperparameter und erfordert die Zusammenarbeit mehrerer unabhängiger Modelle während des Iterationsprozesses des Algorithmus, sodass falsche Implementierungsdetails zu schlechten Trainingsergebnissen führen können.
Gleichzeitig sind Lernalgorithmen zur Verstärkung aus Sicht der menschlichen Ausrichtung nicht erforderlich.

Papieradresse: https://arxiv.org/abs/2304.05302v1
Projektadresse: https://github.com/GanjinZero/RRHF
Zu diesem Zweck schlugen Autoren der Alibaba Damo Academy und der Tsinghua University eine Methode namens Ranking-based Human Preference Alignment – RRHF – vor.
RRHF Es ist kein Verstärkungslernen erforderlich und die von verschiedenen Sprachmodellen generierten Antworten können genutzt werden, einschließlich ChatGPT, GPT-4 oder aktuellen Trainingsmodellen. RRHF funktioniert, indem es Antworten bewertet und die Antworten durch einen Ranking-Verlust an menschliche Vorlieben anpasst.
Im Gegensatz zu PPO kann der Trainingsprozess von RRHF die Ergebnisse menschlicher Experten oder GPT-4 als Vergleich verwenden. Das trainierte RRHF-Modell kann sowohl als generatives Sprachmodell als auch als Belohnungsmodell verwendet werden.
Der CEO von Playgound AI sagte, dass dies der interessanteste Artikel der letzten Zeit sei
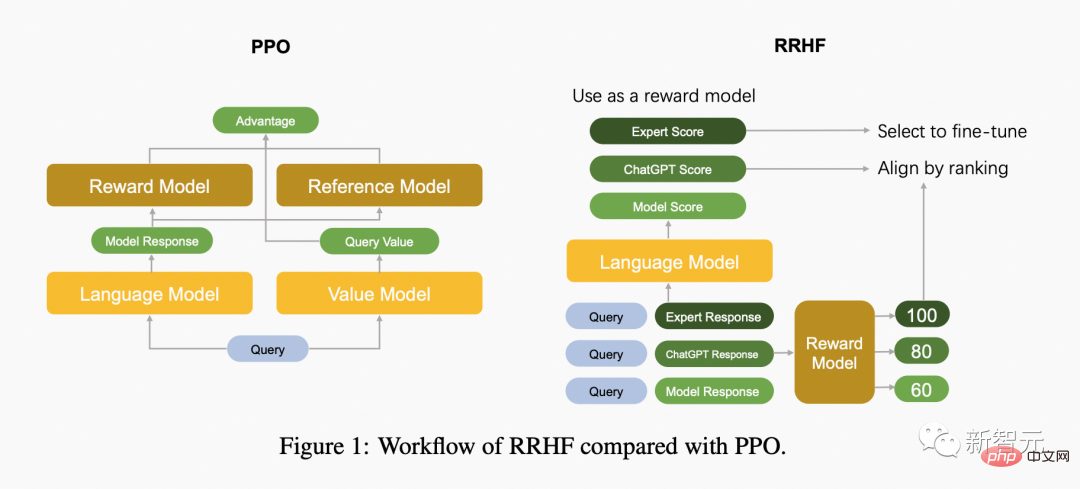
Die folgende Abbildung vergleicht den Unterschied zwischen dem PPO-Algorithmus und dem RRHF-Algorithmus.
RRHF erhält zunächst k Antworten über verschiedene Methoden für die Eingabeabfrage und verwendet dann das Belohnungsmodell, um diese k Antworten jeweils zu bewerten. Jede Antwort wird mit logarithmischer Wahrscheinlichkeit bewertet:
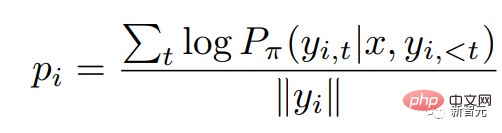
Dabei ist die Wahrscheinlichkeitsverteilung des autoregressiven Sprachmodells.
Wir hoffen, Antworten mit hohen Punktzahlen aus dem Belohnungsmodell eine größere Wahrscheinlichkeit zu geben, das heißt, wir hoffen, die Belohnungspunktzahl zu erreichen. Wir optimieren dieses Ziel durch Ranking-Verlust:
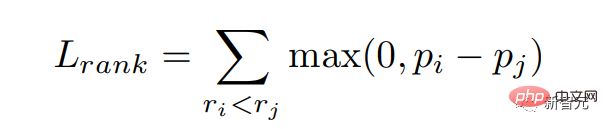
Darüber hinaus geben wir dem Modell auch das Ziel, direkt die Antwort mit der höchsten Punktzahl zu lernen:
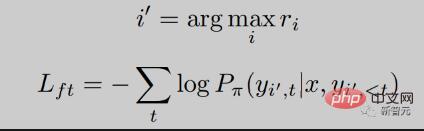
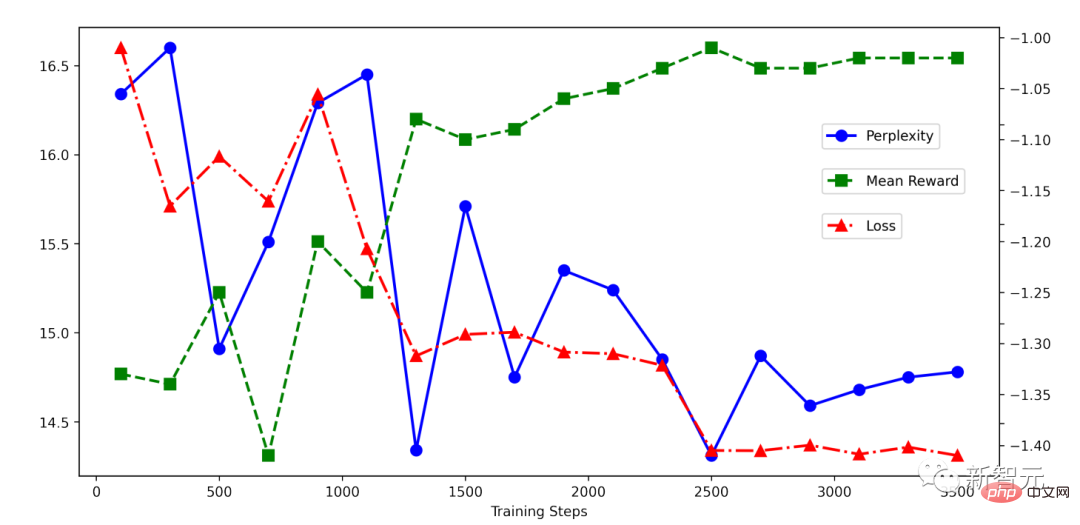
Sie können sehen, dass die RRHF Der Trainingsprozess ist sehr einfach. Es ist ersichtlich, dass der Rückgang während des RRHF-Trainings sehr stabil ist und der Belohnungswert mit abnehmendem Verlust stetig zunimmt.
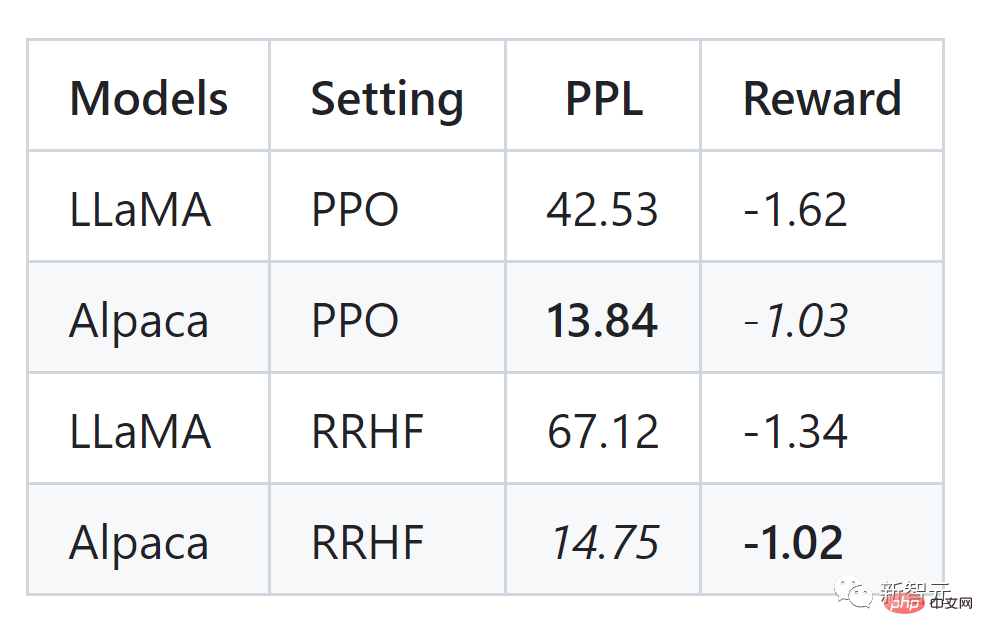
Der Autor des Artikels führte Experimente mit dem HH-Datensatz durch und kann auch mit PPO vergleichbare Ergebnisse sehen:
Der RRHF-Algorithmus kann die Ausgabewahrscheinlichkeit des Sprachmodells effektiv mit der des Menschen abgleichen Präferenzen Ausrichtung, seine Trainingsidee ist sehr einfach und das trainierte Modell weist mehrere Merkmale auf:
RRHF-Methode verwendet chatGPT oder GPT-4 von OpenAI als Bewertungsmodell und die Ausgabe von ChatGPT, Alpaca und anderen Modellen als Trainingsbeispiele, um zwei neue Sprachmodelle zu entwickeln, nämlich Wombat-7B und Wombat-7B -GPT4 . Die Trainingszeit liegt zwischen 2 und 4 Stunden und ist sehr gering.
Wombat kann als neues Open-Source-Pre-Training-Modell im Vergleich zu LLaMA, Alpaca usw. besser auf menschliche Vorlieben eingehen. Die Autoren fanden experimentell heraus, dass Wombat-7B über komplexe Fähigkeiten wie Rollenspiele und die Durchführung von kontrafaktischem Denken verfügt.
Wenn Sie Wombat bitten, die Zukunftstechnologie aus dem Jahr 3000 vorzustellen, wird Wombat wie folgt antworten (übersetzt aus dem Englischen):
Ich hoffe, dass unsere Zukunft immer besser wird, wie Wombat es vorhersagt.

Referenz:
https://github.com/GanjinZero/RRHF
Das obige ist der detaillierte Inhalt vonKann Menschen ohne RLHF ausrichten, Leistung vergleichbar mit ChatGPT! Chinesisches Team schlägt Wombat-Modell vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Kontextmenü
Kontextmenü
 So fügen Sie ein Video in HTML ein
So fügen Sie ein Video in HTML ein
 Der Unterschied zwischen Java und Java
Der Unterschied zwischen Java und Java
 Win10-Systemfestplatte zu 100 % belegt
Win10-Systemfestplatte zu 100 % belegt
 In welcher Sprache kann vscode geschrieben werden?
In welcher Sprache kann vscode geschrieben werden?
 Die PHPStudy-Datenbank kann die Lösung nicht starten
Die PHPStudy-Datenbank kann die Lösung nicht starten
 Linux-Befehl zum Ändern des Dateinamens
Linux-Befehl zum Ändern des Dateinamens
 In Word gibt es eine zusätzliche leere Seite, die ich nicht löschen kann.
In Word gibt es eine zusätzliche leere Seite, die ich nicht löschen kann.
 Wie hoch sind die Sternebewertungen mobiler Nutzer?
Wie hoch sind die Sternebewertungen mobiler Nutzer?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



