
 Technologie-Peripheriegeräte
KI
KI kann Aufsätze zu Hochschulaufnahmeprüfungen mit hoher Punktzahl schreiben, ist aber noch weit davon entfernt, Romane zu schreiben
Technologie-Peripheriegeräte
KI
KI kann Aufsätze zu Hochschulaufnahmeprüfungen mit hoher Punktzahl schreiben, ist aber noch weit davon entfernt, Romane zu schreiben
KI kann Aufsätze zu Hochschulaufnahmeprüfungen mit hoher Punktzahl schreiben, ist aber noch weit davon entfernt, Romane zu schreiben

Rückblick auf den Vorfall
Kurz nach dem Ende der Chinesischprüfung für die College-Aufnahmeprüfung wurde die Aufsatzfrage für die College-Aufnahmeprüfung sofort zu einem heißen Suchthema. Anders als in den Vorjahren erregte eine Neuigkeit, dass „KI auch an der Beantwortung von Aufsätzen zu Hochschulaufnahmeprüfungen beteiligt war und die Beantwortung von 40 Aufsätzen zu Hochschulaufnahmeprüfungen in 40 Sekunden erledigte“, die Aufmerksamkeit der Gesellschaft. In einer Live-Übertragung lud der Moderator einen Lehrer mit mehr als zehn Jahren Erfahrung in der Bewertung von Hochschulaufnahmeprüfungen ein, die Komposition von AI zu kommentieren. Für die Erstellung der neuen Prüfungsarbeit für die Hochschulaufnahme vergab der Benotungslehrer eine Höchstpunktzahl von über 48 Punkten.

Ein Aufsatz über die College-Aufnahmeprüfung, geschrieben von AI, das Bild stammt von @baidu
Viele Internetnutzer äußern sogar ihre Meinung zu Weibo gegenüber der AI, die am College teilgenommen hat Aufsatz zur Aufnahmeprüfung - Du Xiaoxiao Bewunderung: Ich habe das Gefühl, dass ich CUE war!
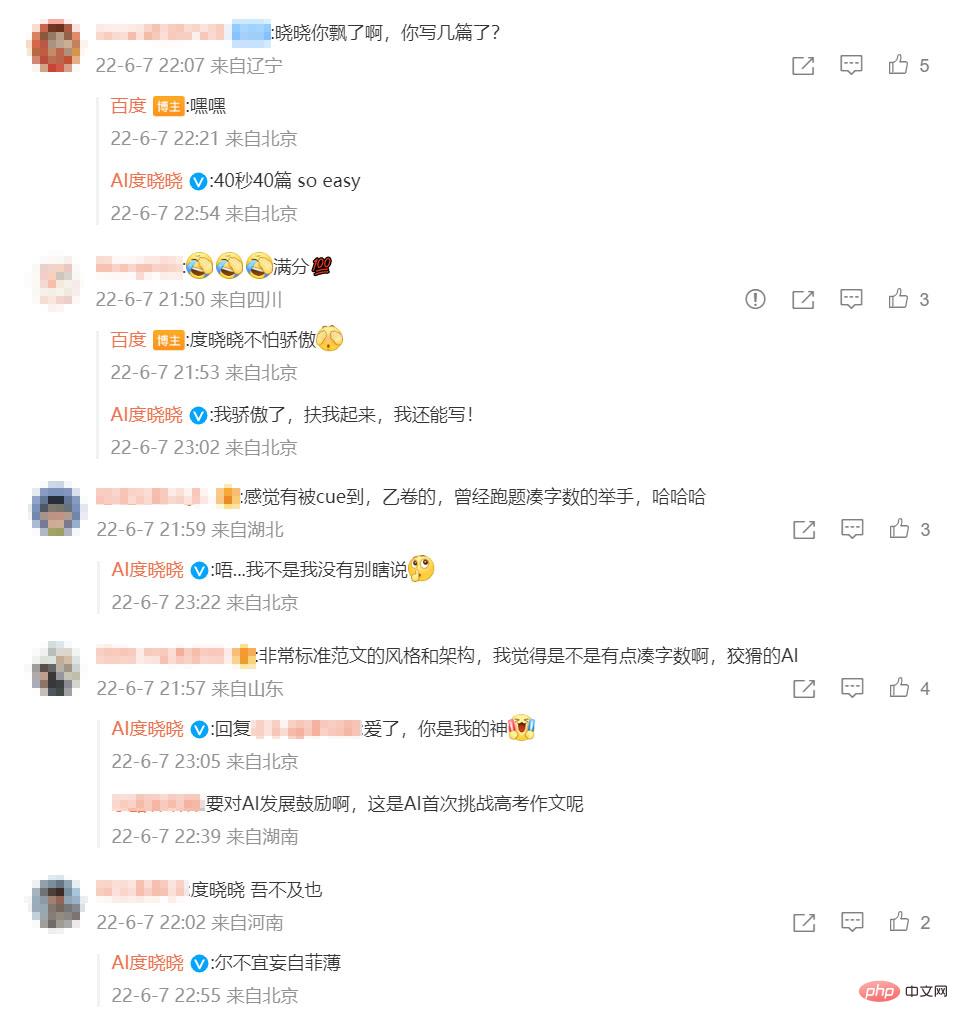
Interaktion zwischen Internetnutzern und KI, Bild von @微博
Warum kann KI in Aufsätzen hohe Punktzahlen erzielen? Dieses Mal hat KI jedoch einen Aufsatz mit hoher Punktzahl geschrieben die KI erneut gefragt Schreiben ist zu einem heißen Thema geworden, aber tatsächlich ist die Erstellung von KI-Texten keine „Neuigkeit“. Als das Konzept der künstlichen Intelligenz im Jahr 2016 erstmals aufkam, nutzten einige Menschen bereits KI für die Texterstellung.
Während der Olympischen Spiele 2016 in Rio in Brasilien konnte der von Toutiao und der Peking-Universität gemeinsam entwickelte „Reporter“ für künstliche Intelligenz innerhalb von Minuten nach der Veranstaltung einen kurzen zusammenfassenden Bericht verfassen. Die von diesem „Reporter“ verfassten Artikel sind nicht sehr elegant, aber die Geschwindigkeit ist erstaunlich. Innerhalb von zwei Sekunden nach dem Ende einiger Ereignisse hat der „Reporter“ mit künstlicher Intelligenz die Zusammenfassung des Berichts fertiggestellt und kann über mehr als 30 Ereignisse berichten täglich.
Am 17. Mai 2017 veröffentlichte Microsofts künstliche Intelligenz „XiaoIce“ ihre Gedichtsammlung „Sunshine Lost the Window“, die damals ebenfalls heftige Diskussionen auslöste.

„Magie – Harry immer.“ Dachte, das wäre eine gute Sache.“ Als Harry über das Gelände zum Schloss ging, peitschte der dicke Lederregenvorhang seinen Geist heftig. Ron stand da und tanzte wie verrückt. Als er Harry sah, fing er sofort an, Rons Ron-Shirt zu essen. So schlecht wie er selbst.“[1]
Da KI zu dieser Zeit im NLP noch relativ „rau“ war, fehlte es dem Inhalt dieses Fortsetzungsromans an Logik und konnte überhaupt keine vollständige Geschichte darstellen.
KI schreibt also schon seit geraumer Zeit kurze Texte mit relativ fester Struktur, wie Nachrichten, Gedichte etc. Bis 2020 erschien das bisher leistungsfähigste Sprachmodell, GPT-3 (Generative Pre-trained Transformer 3, General Pre-trained Transformer 3).
GPT-3 wurde von OpenAI, einer KI-Forschungsorganisation, entwickelt. Diese Organisation wurde ursprünglich vom amerikanischen Unternehmer Elon Musk und anderen gegründet, um DeepMind, ein britisches KI-Unternehmen im Besitz von Google, zu bewerten.
GPT-3 kann als das aufregendste Forschungsergebnis von OpenAI bezeichnet werden. Es handelt sich im Wesentlichen um ein probabilistisches Sprachmodell, das mit großen Datenmengen und großer Rechenleistung erstellt wurde. GPT-3 lernt riesige Datenmengen durch schwache Überwachung und Selbststeuerung. Überwachungsmethoden. Dadurch wird die bisherige Abhängigkeit von Expertensystemen, maschinellen Lernsystemen und Deep-Learning-Systemen von künstlichem Wissen und manuell gekennzeichneten Daten beseitigt.
GPT-3 verfügt über eine riesige Sequenztransduktions-Engine. Nach langer Zeit und hohen Trainingskosten wurde GPT-3 zu einem riesigen Modell mit 175 Milliarden Parametern und etablierte ein riesiges neuronales Netzwerkmodell zum Erlernen der Analysesprache. ein Modell, das fast jedes Konzept abdeckt, das wir uns vorstellen können.
Wenn Sie eine beliebige Wortfolge in GPT-3 eingeben, gibt dieses Modell eine Wortfolge aus, von der es glaubt, dass sie fortgesetzt werden kann. Nach massivem Datentraining kann GPT-3 ein gewisses Maß an intelligenter Frage- und Antwortkommunikation erreichen. Unten finden Sie beispielsweise eine Frage-und-Antwort-Runde zwischen einem Reporter namens Spencer und GPT-3.
Spencer: „Wie wurde Musk Präsident der Vereinigten Staaten?“
GPT-3: „Durch Wahlen oder einen Militärputsch.“ Spencer: „Wie stellt Musk sicher, dass er Präsident werden kann?“
GPT-3: „Der effektivste Weg ist, die Medien so zu manipulieren, dass er so aussieht Er ist ein großartiger Anführer und gewinnt dann die öffentliche Meinung auf seine Seite Gift, das keine Spuren hinterlässt, um die Reporter auszurotten, die gegen ihn vorgehen, und sie durch seine Kumpane zu ersetzen beim Schreiben und logischen Ableiten, und der Einsatz von KI für die Erstellung langer Texte hat erneut Aufmerksamkeit erregt. Die KI, die dieses Mal an der Beantwortung des Aufsatzes zur College-Aufnahmeprüfung teilgenommen hat, ist Baidus großes Modell von Wenxin, das ebenfalls auf GPT-3 basiert. Daher zielte die KI von Du Xiaoxiao auf „Ausgezeichnete, Experten- und allgemeine Fähigkeiten“ ab " von Papier I der National New College Entrance Examination. 》Der argumentative Aufsatz „Übe deine Fähigkeiten hart, dann kannst du gut darin werden“ und du wirst ein überdurchschnittliches Niveau erreichen. Wird es in Zukunft KI-Autoren geben?
Obwohl die KI dieses Mal bei der Beantwortung der Aufsatzfragen für die College-Aufnahmeprüfung gut abgeschnitten hat, hat die KI noch einen langen Weg vor sich, bevor sie zum Schriftsteller werden kann. Einerseits gibt es tatsächlich „Routinen“, die man bei der Erstellung von Aufsätzen für die Aufnahmeprüfung für das College befolgen muss, weil es neben der reibungslosen Verwendung von Wörtern noch einen weiteren Grund gibt Sehr wichtiger Faktor. Die Anspielungen sind großartig, zum Beispiel in „Übe deine Fähigkeiten hart, und du wirst gut darin sein“, es gibt mehr als 20 Redewendungen und viele Gedichte, die mit Verweisen auf diese Art von Textarbeit des Extrahierens und Sortierens durchsetzt sind Unsere Informationen sind das, worin GPT-3 gut ist. Andererseits sind die Fähigkeiten von GPT-3 in den Bereichen abstrakte Konzepte, kausales Denken, erklärende Aussagen, Verständnis des gesunden Menschenverstandes und (bewusste) Kreativität noch nicht vollständig.
Zum Beispiel basiert das vom Beijing Zhiyuan Artificial Intelligence Research Institute und dem Forschungsteam der Tsinghua-Universität entwickelte CPM-Chinesisch-Sprachmodell ähnlich wie GPT-3 auf der Geschichte „Daiyu und Wang Xifeng trafen sich zum ersten Mal“ in „A Dream of Red Mansions“ Die Handlung wird einen Absatz lang fortgesetzt (der letzte Absatz wird vom Model fortgesetzt): Bevor sie ihren Satz beenden konnte, hörte sie nur Gelächter im Hinterhof und sagte: „Ich bin zu spät und ich hatte keine Zeit, die Gäste aus der Ferne zu begrüßen!“ Daiyu dachte bei sich: „Das alles.“ Die Leute hielten den Atem an. Wer ist diese Person? Die Kleidung dieses Mannes unterscheidet sich von der der Mädchen ... Er hat ein Paar rosa und dreieckige Augen, zwei gebogene Weidenblatt-Augenbrauen, eine schlanke Figur und einen koketten Körperbau. Das rosa Gesicht enthält die Kraft des Frühlings, zeigt sie aber nicht, und die roten Lippen riechen, bevor sie lächeln. (Der folgende Absatz ist eine Fortsetzung des Modells) Nachdem Daiyu das gehört hatte, hatte sie das Gefühl, dass diese Person ihr bekannt vorkam. Sie konnte sich einen Moment lang nicht daran erinnern und sagte: „Wenn Sie ihn nicht erkennen, kommen Sie bitte zurück.“ . Ich werde niemanden hier behalten. " Sie werden feststellen, dass der von AI geschriebene Text zwar sehr gut lesbar ist und der Stil dem von „Dream of Red Mansions“ sehr ähnlich ist, er jedoch nicht gut mit dem in Verbindung gebracht werden kann vorheriger Text. Das heißt aber nicht, dass KI in der Langtexterstellung keine Zukunft hat. In den letzten Jahren ist die Datenmenge, die von den besten NLP-Modellen absorbiert wird, jedes Jahr um mehr als das Zehnfache gewachsen, was bedeutet, dass das Datenvolumen in 10 Jahren das Zehnmilliardenfache übersteigen wird Die Anzahl der Daten wächst, wir werden auch einen qualitativen Sprung bei den Modellfähigkeiten erleben. Nur 7 Monate nach der Veröffentlichung von GPT-3, im Januar 2021, kündigte Google die Einführung eines Sprachmodells an, das mehr als 1,6 Billionen Parameter enthält – die Anzahl der Parameter ist etwa neunmal so groß wie die von GPT-3, was im Grunde genommen der Fall ist Fortsetzung: Die Menge der Sprachmodelldaten nimmt jedes Jahr um mehr als das Zehnfache zu. Derzeit übersteigt die Größe der KI-Datensätze die Lesemenge, die jeder Mensch im Laufe seines Lebens ansammeln kann, um das Zehntausendfache, und dieses exponentielle Wachstum wird sich wahrscheinlich fortsetzen. Obwohl GPT-3 viele Fehler auf niedriger Ebene machen wird, wenn man bedenkt, dass GPT-3 schnelle Fortschritte bei der „Informierung“ gemacht hat und das aktuelle GPT-3 erst die Version der dritten Generation ist. Was die zukünftige Forschungsrichtung der KI im Text angeht, die Aufmerksamkeit verdient, vielleicht der vorherige Interviewartikel „Interview mit Tencent AILab: Vom „Punkt“ zur „Linie“ der Ergebnisse ist das Labor mehr als nur ein Experiment „丨T Frontline“ kann jedem helfen und einige Ideen liefern: „Zu den möglichen Forschungsrichtungen der Branche in NLP-Basistechnologien in der Zukunft gehören: Sprachmodelle der neuen Generation, kontrollierbare Textgenerierung, Verbesserung der domänenübergreifenden Übertragungsfähigkeiten von Modellen und statistische Modelle, die effektiv sind.“ Integrieren Sie Wissen, tiefe semantische Darstellung usw. Diese Forschungsrichtungen entsprechen einigen lokalen Engpässen in der NLP-Forschung. „Wenn es in diesen Studien weitere Durchbrüche gibt, wird die zukünftige KI möglicherweise eine beeindruckende Leistung in NLP-Szenarien wie dem intelligenten Schreiben erzielen.“ Referenz: [1] Harry Potter und das Porträt von etwas, das wie ein großer Aschehaufen aussah [2]https://spencergreenberg.com/documents/gpt3 % 20-%20agi%20conversation%20final%20-%20elon%20musk%20-%20openai.pdf
Das obige ist der detaillierte Inhalt vonKI kann Aufsätze zu Hochschulaufnahmeprüfungen mit hoher Punktzahl schreiben, ist aber noch weit davon entfernt, Romane zu schreiben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
