

So verwenden Sie den Java-Crawler zum stapelweisen Crawlen von Bildern

Crawling-Ideen
Der Erwerb dieser Art von Bild ist eigentlich das Herunterladen der Datei (HttpClient). Da es aber nicht nur darum geht, ein Bild zu bekommen, gibt es auch einen Seitenparsing-Prozess (Jsoup).
Jsoup: Analysieren Sie die HTML-Seite und erhalten Sie den Link zum Bild.
HttpClient: Fordern Sie den Link des Bildes an und speichern Sie das Bild lokal.
Spezifische Schritte
Betreten Sie zunächst die Homepage-Analyse. Es gibt hauptsächlich die folgenden Kategorien (nicht alle Kategorien hier, aber diese reichen aus, dies dient nur zum Lernen Es ist nur Technologie. Unser Ziel ist es, Bilder in jeder Kategorie zu erhalten.
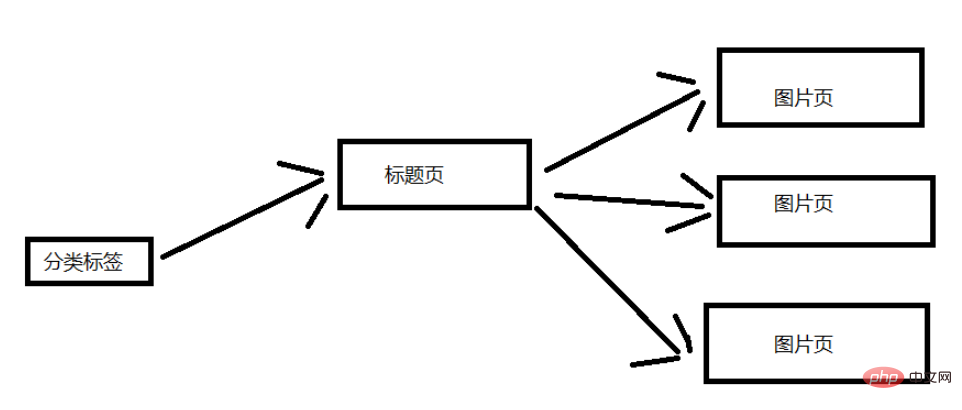
Lassen Sie uns die Struktur der Website analysieren. Ich werde es hier einfach halten. Das Bild unten zeigt den allgemeinen Aufbau. Hier ist zur Veranschaulichung ein Klassifizierungsetikett ausgewählt. Eine Kategorie-Tag-Seite enthält mehrere Titelseiten und jede Titelseite enthält mehrere Bildseiten. (Entspricht Dutzenden von Bildern auf der Titelseite)
Spezifischer Code
Projektabhängiges JAR-Paket importieren Koordinaten Oder laden Sie direkt das entsprechende JAR-Paket herunter und importieren Sie das Projekt.
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.6</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>Entitätsklasse Bild- und Werkzeugklasse HeaderUtil
Entitätsklasse: Kapseln Sie die Eigenschaften in ein Objekt, was den Aufruf erleichtert.
package com.picture;
public class Picture {
private String title;
private String url;
public Picture(String title, String url) {
this.title = title;
this.url = url;
}
public String getTitle() {
return this.title;
}
public String getUrl() {
return this.url;
}
}Tool-Kategorie: Ständig wechselndes UA (ich weiß nicht, ob es nützlich ist, aber ich verwende meine eigene IP, daher ist es wahrscheinlich von geringem Nutzen)
package com.picture;
public class HeaderUtil {
public static String[] headers = {
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11",
"Opera/9.25 (Windows NT 5.1; U; en)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12",
"Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9",
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
};
}Kategorie herunterladen# 🎜🎜#
Multi-Threading ist wirklich zu schnell. Außerdem habe ich nur eine IP und es ist keine Proxy-IP verfügbar (ich weiß nicht viel darüber). schnell.package com.picture;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.Random;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import com.m3u8.HttpClientUtil;
public class SinglePictureDownloader {
private String referer;
private CloseableHttpClient httpClient;
private Picture picture;
private String filePath;
public SinglePictureDownloader(Picture picture, String referer, String filePath) {
this.httpClient = HttpClientUtil.getHttpClient();
this.picture = picture;
this.referer = referer;
this.filePath = filePath;
}
public void download() {
HttpGet get = new HttpGet(picture.getUrl());
Random rand = new Random();
//设置请求头
get.setHeader("User-Agent", HeaderUtil.headers[rand.nextInt(HeaderUtil.headers.length)]);
get.setHeader("referer", referer);
System.out.println(referer);
HttpEntity entity = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
File picFile = new File(filePath, picture.getTitle());
try (OutputStream out = new BufferedOutputStream(new FileOutputStream(picFile))) {
entity.writeTo(out);
System.out.println("下载完毕:" + picFile.getAbsolutePath());
}
}
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
//关闭实体,关于 httpClient 的关闭资源,有点不太了解。
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}Dies ist eine Toolklasse zum Erhalten von HttpClient-Verbindungen, um den Leistungsverbrauch durch häufiges Erstellen von Verbindungen zu vermeiden. (Aber da ich hier einen einzelnen Thread zum Crawlen verwende, ist dies nicht sehr nützlich. Ich kann zum Crawlen nur eine HttpClient-Verbindung verwenden. Dies liegt daran, dass ich am Anfang mehrere Threads zum Crawlen verwendet habe. , aber das war es nachdem im Grunde ein paar Bilder abgerufen wurden, wurde es in einen Single-Thread-Crawler geändert, sodass der Verbindungspool übrig blieb.)
package com.m3u8;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
public class HttpClientUtil {
private static final int TIME_OUT = 10 * 1000;
private static PoolingHttpClientConnectionManager pcm; //HttpClient 连接池管理类
private static RequestConfig requestConfig;
static {
requestConfig = RequestConfig.custom()
.setConnectionRequestTimeout(TIME_OUT)
.setConnectTimeout(TIME_OUT)
.setSocketTimeout(TIME_OUT).build();
pcm = new PoolingHttpClientConnectionManager();
pcm.setMaxTotal(50);
pcm.setDefaultMaxPerRoute(10); //这里可能用不到这个东西。
}
public static CloseableHttpClient getHttpClient() {
return HttpClients.custom()
.setConnectionManager(pcm)
.setDefaultRequestConfig(requestConfig)
.build();
}
}package com.picture;
import java.io.File;
import java.io.IOException;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import com.m3u8.HttpClientUtil;
/**
* 首先从顶部分类标题开始,依次爬取每一个标题(小分页),每一个标题(大分页。)
* */
public class PictureSpider {
private CloseableHttpClient httpClient;
private String referer;
private String rootPath;
private String filePath;
public PictureSpider() {
httpClient = HttpClientUtil.getHttpClient();
}
/**
* 开始爬虫爬取!
*
* 从爬虫队列的第一条开始,依次爬取每一条url。
*
* 分页爬取:爬10页
* 每个url属于一个分类,每个分类一个文件夹
* */
public void start(List<String> urlList) {
urlList.stream().forEach(url->{
this.referer = url;
String dirName = url.substring(22, url.length()-1); //根据标题名字去创建目录
//创建分类目录
File path = new File("D:/DragonFile/DBC/mzt/", dirName); //硬编码路径,需要用户自己指定一个
if (!path.exists()) {
path.mkdir();
rootPath = path.toString();
}
for (int i = 1; i <= 10; i++) { //分页获取图片数据,简单获取几页就行了
this.page(url + "page/"+ 1);
}
});
}
/**
* 标题分页获取链接
* */
public void page(String url) {
System.out.println("url:" + url);
String html = this.getHtml(url); //获取页面数据
Map<String, String> picMap = this.extractTitleUrl(html); //抽取图片的url
if (picMap == null) {
return ;
}
//获取标题对应的图片页面数据
this.getPictureHtml(picMap);
}
private String getHtml(String url) {
String html = null;
HttpGet get = new HttpGet(url);
get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36");
get.setHeader("referer", url);
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
HttpEntity entity = response.getEntity();
if (entity != null) {
html = EntityUtils.toString(entity, "UTf-8"); //关闭实体?
}
}
else {
System.out.println(statusCode);
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return html;
}
private Map<String, String> extractTitleUrl(String html) {
if (html == null) {
return null;
}
Document doc = Jsoup.parse(html, "UTF-8");
Elements pictures = doc.select("ul#pins > li");
//不知为何,无法直接获取 a[0],我不太懂这方面的知识。
//那我就多处理一步,这里先放下。
Elements pictureA = pictures.stream()
.map(pic->pic.getElementsByTag("a").first())
.collect(Collectors.toCollection(Elements::new));
return pictureA.stream().collect(Collectors.toMap(
pic->pic.getElementsByTag("img").first().attr("alt"),
pic->pic.attr("href")));
}
/**
* 进入每一个标题的链接,再次分页获取图片的链接
* */
private void getPictureHtml(Map<String, String> picMap) {
//进入标题页,在标题页中再次分页下载。
picMap.forEach((title, url)->{
//分页下载一个系列的图片,每个系列一个文件夹。
File dir = new File(rootPath, title.trim());
if (!dir.exists()) {
dir.mkdir();
filePath = dir.toString(); //这个 filePath 是每一个系列图片的文件夹
}
for (int i = 1; i <= 60; i++) {
String html = this.getHtml(url + "/" + i);
if (html == null) {
//每个系列的图片一般没有那么多,
//如果返回的页面数据为 null,那就退出这个系列的下载。
return ;
}
Picture picture = this.extractPictureUrl(html);
System.out.println("开始下载");
//多线程实在是太快了(快并不是好事,我改成单线程爬取吧)
SinglePictureDownloader downloader = new SinglePictureDownloader(picture, referer, filePath);
downloader.download();
try {
Thread.sleep(1500); //不要爬的太快了,这里只是学习爬虫的知识。不要扰乱别人的正常服务。
System.out.println("爬取完一张图片,休息1.5秒。");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
/**
* 获取每一页图片的标题和链接
* */
private Picture extractPictureUrl(String html) {
Document doc = Jsoup.parse(html, "UTF-8");
//获取标题作为文件名
String title = doc.getElementsByTag("h3")
.first()
.text();
//获取图片的链接(img 标签的 src 属性)
String url = doc.getElementsByAttributeValue("class", "main-image")
.first()
.getElementsByTag("img")
.attr("src");
//获取图片的文件扩展名
title = title + url.substring(url.lastIndexOf("."));
return new Picture(title, url);
}
}BootStrap
Hier gibt es eine Crawler-Warteschlange, aber ich habe noch nicht einmal die erste zu Ende gecrawlt. Das liegt daran, dass ich einen Rechenfehler gemacht und zwei Größenordnungen weniger gezählt habe. Die Funktionalität des Programms ist jedoch korrekt.
package com.picture;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* 爬虫启动类
* */
public class BootStrap {
public static void main(String[] args) {
//反爬措施:UA、refer 简单绕过就行了。
//refer https://www.mzitu.com
//使用数组做一个爬虫队列
String[] urls = new String[] {
"https://www.mzitu.com/xinggan/",
"https://www.mzitu.com/zipai/"
};
// 添加初始队列,启动爬虫
List<String> urlList = new ArrayList<>(Arrays.asList(urls));
PictureSpider spider = new PictureSpider();
spider.start(urlList);
}
}Crawling-Ergebnisse

 Notizen
Notizen
Hier liegt ein Rechenfehler vor, der Code lautet wie folgt:
for (int i = 1; i <= 10; i++) { //分页获取图片数据,简单获取几页就行了
this.page(url + "page/"+ 1);
}Dieses Programm dient nur zum Lernen. Ich habe das Download-Intervall für jedes Bild auf 1,5 Sekunden eingestellt und es handelt sich um ein Single-Thread-Programm, sodass die Geschwindigkeit sehr langsam erscheint. Aber das macht nichts, solange das Programm korrekt funktioniert, wird niemand wirklich warten, bis das Bild heruntergeladen ist.
Es wird geschätzt, dass es lange dauert: 64800*1,5s = 97200s = 27h. Dies ist nur eine grobe Schätzung und berücksichtigt keine anderen Laufzeiten von das Programm, aber andere Zeiten können grundsätzlich ignoriert werden.
Das obige ist der detaillierte Inhalt vonSo verwenden Sie den Java-Crawler zum stapelweisen Crawlen von Bildern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur perfekten Zahl in Java. Hier besprechen wir die Definition, Wie prüft man die perfekte Zahl in Java?, Beispiele mit Code-Implementierung.
 Zufallszahlengenerator in Java
Aug 30, 2024 pm 04:27 PM
Zufallszahlengenerator in Java
Aug 30, 2024 pm 04:27 PM
Leitfaden zum Zufallszahlengenerator in Java. Hier besprechen wir Funktionen in Java anhand von Beispielen und zwei verschiedene Generatoren anhand ihrer Beispiele.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden für Weka in Java. Hier besprechen wir die Einführung, die Verwendung von Weka Java, die Art der Plattform und die Vorteile anhand von Beispielen.
 Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur Smith-Zahl in Java. Hier besprechen wir die Definition: Wie überprüft man die Smith-Nummer in Java? Beispiel mit Code-Implementierung.
 Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
In diesem Artikel haben wir die am häufigsten gestellten Fragen zu Java Spring-Interviews mit ihren detaillierten Antworten zusammengestellt. Damit Sie das Interview knacken können.
 Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Java 8 führt die Stream -API ein und bietet eine leistungsstarke und ausdrucksstarke Möglichkeit, Datensammlungen zu verarbeiten. Eine häufige Frage bei der Verwendung von Stream lautet jedoch: Wie kann man von einem Foreach -Betrieb brechen oder zurückkehren? Herkömmliche Schleifen ermöglichen eine frühzeitige Unterbrechung oder Rückkehr, aber die Stream's foreach -Methode unterstützt diese Methode nicht direkt. In diesem Artikel werden die Gründe erläutert und alternative Methoden zur Implementierung vorzeitiger Beendigung in Strahlverarbeitungssystemen erforscht. Weitere Lektüre: Java Stream API -Verbesserungen Stream foreach verstehen Die Foreach -Methode ist ein Terminalbetrieb, der einen Vorgang für jedes Element im Stream ausführt. Seine Designabsicht ist
 Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Anleitung zum TimeStamp to Date in Java. Hier diskutieren wir auch die Einführung und wie man Zeitstempel in Java in ein Datum konvertiert, zusammen mit Beispielen.
 Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Java ist eine beliebte Programmiersprache, die sowohl von Anfängern als auch von erfahrenen Entwicklern erlernt werden kann. Dieses Tutorial beginnt mit grundlegenden Konzepten und geht dann weiter zu fortgeschrittenen Themen. Nach der Installation des Java Development Kit können Sie das Programmieren üben, indem Sie ein einfaches „Hello, World!“-Programm erstellen. Nachdem Sie den Code verstanden haben, verwenden Sie die Eingabeaufforderung, um das Programm zu kompilieren und auszuführen. Auf der Konsole wird „Hello, World!“ ausgegeben. Mit dem Erlernen von Java beginnt Ihre Programmierreise, und wenn Sie Ihre Kenntnisse vertiefen, können Sie komplexere Anwendungen erstellen.
