

Übersetzer |. Li Rui
Rezensent |. In letzter Zeit haben viele Menschen in ihrem Freundeskreis einen rücksichtslosen Charakter gefunden, der sowohl geliebt als auch gefürchtet wird, so sehr, dass StackOverflow ihn eilig aus den Regalen entfernen musste.
Vor kurzem veröffentlichte OpenAI die Chat-KI ChatGPT. In nur wenigen Tagen erreichte die Anzahl der Benutzer eine Million und der Server war sogar mit registrierten Benutzern überfüllt.
Wie funktioniert diese Art von Artefakt, über das Internetnutzer „jenseits der Google-Suche“ staunen? Ist es zuverlässig?
1. Event-Rezension
Wie bei den meisten LLM-Versionen (Large Language Model) stieß auch die Veröffentlichung von ChatGPT auf einige Kontroversen. Nur wenige Stunden nach seiner Veröffentlichung sorgte das neue Sprachmodell auf Twitter für Aufsehen, da Benutzer Screenshots der beeindruckenden Erfolge oder katastrophalen Misserfolge von ChatGPT hochluden.
Aus der breiten Perspektive großer Sprachmodelle betrachtet spiegelt ChatGPT jedoch die kurze, aber reiche Geschichte des Fachgebiets wider und zeigt, wie viel Fortschritt in nur wenigen Jahren erzielt wurde und welche grundlegenden Probleme noch gelöst werden müssen.
2. Der Traum vom unbeaufsichtigten Lernen
Dies hat sich mit der Einführung der Transformer-Architektur, einer Schlüsselkomponente großer Sprachmodelle, geändert. Transformer-Modelle können mit großen Korpora unbeschrifteten Textes trainiert werden. Sie maskieren nach dem Zufallsprinzip Teile des Textes und versuchen, die fehlenden Teile vorherzusagen. Durch wiederholtes Ausführen dieser Operation passt der Transformer seine Parameter an, um die Beziehung zwischen verschiedenen Wörtern in der großen Sequenz darzustellen.
Dies hat sich als sehr effektive und skalierbare Strategie erwiesen. Sehr große Trainingskorpora können gesammelt werden, ohne dass eine menschliche Kennzeichnung erforderlich ist, was die Erstellung und das Training immer größerer Transformer-Modelle ermöglicht. Untersuchungen und Experimente zeigen, dass Transformer-Modelle und Large Language Models (LLMs) mit zunehmender Größe längere kohärente Textsequenzen erzeugen können. Large Language Models (LLMs) weisen auch umfangreiche Notfallfähigkeiten auf.
3. Regressionsüberwachtes Lernen?
Durch die Vergrößerung des Modells und seines Trainingskorpus konnten Wissenschaftler die Häufigkeit offensichtlicher Fehler in großen Sprachmodellen reduzieren. Aber das grundlegende Problem verschwindet nicht, selbst die größten großen Sprachmodelle (LLMs) können mit sehr wenig Druck dumme Fehler machen.
Wenn große Sprachmodelle (LLMs) nur in wissenschaftlichen Forschungslabors verwendet würden, um die Leistung bei Benchmarks zu verfolgen, wäre dies möglicherweise kein großes Problem. Da jedoch das Interesse an der Verwendung großer Sprachmodelle (LLMs) in realen Anwendungen zunimmt, wird es immer wichtiger, diese und andere Probleme anzugehen. Ingenieure müssen sicherstellen, dass ihre Modelle für maschinelles Lernen unter unterschiedlichen Bedingungen robust bleiben und die Bedürfnisse und Anforderungen der Benutzer erfüllen.
Um dieses Problem zu lösen, nutzt OpenAI die Reinforcement Learning from Human Feedback (RLHF)-Technologie, die zuvor zur Optimierung von Reinforcement-Learning-Modellen entwickelt wurde. Anstatt ein Reinforcement-Learning-Modell zufällig seine Umgebung und sein Verhalten erkunden zu lassen, nutzt Reinforcement Learning with Human Feedback (RLHF) gelegentliches Feedback eines menschlichen Vorgesetzten, um den Agenten in die richtige Richtung zu leiten. Der Vorteil von Reinforcement Learning with Human Feedback (RLHF) besteht darin, dass es die Ausbildung von Reinforcement Learning Agents mit minimalem menschlichem Feedback verbessert.
OpenAI wendete später Reinforcement Learning with Human Feedback (RLHF) auf InstructGPT an, eine Familie großer Sprachmodelle (LLM), die darauf ausgelegt sind, Anweisungen in Benutzeraufforderungen besser zu verstehen und darauf zu reagieren. InstructGPT ist ein GPT-3-Modell, das auf Grundlage menschlichen Feedbacks optimiert wird.
Das ist offensichtlich ein Kompromiss. Menschliche Anmerkungen können zu einem Engpass im skalierbaren Trainingsprozess werden. Aber indem OpenAI das richtige Gleichgewicht zwischen unbeaufsichtigtem und überwachtem Lernen findet, kann es wichtige Vorteile erzielen, darunter eine bessere Reaktion auf Anweisungen, eine Reduzierung schädlicher Ausgaben und eine Ressourcenoptimierung. Den Forschungsergebnissen von OpenAI zufolge übertrifft das InstructionGPT mit 1,3 Milliarden Parametern im Allgemeinen das GPT-3-Modell mit 175 Milliarden Parametern bei der Befolgung von Anweisungen.
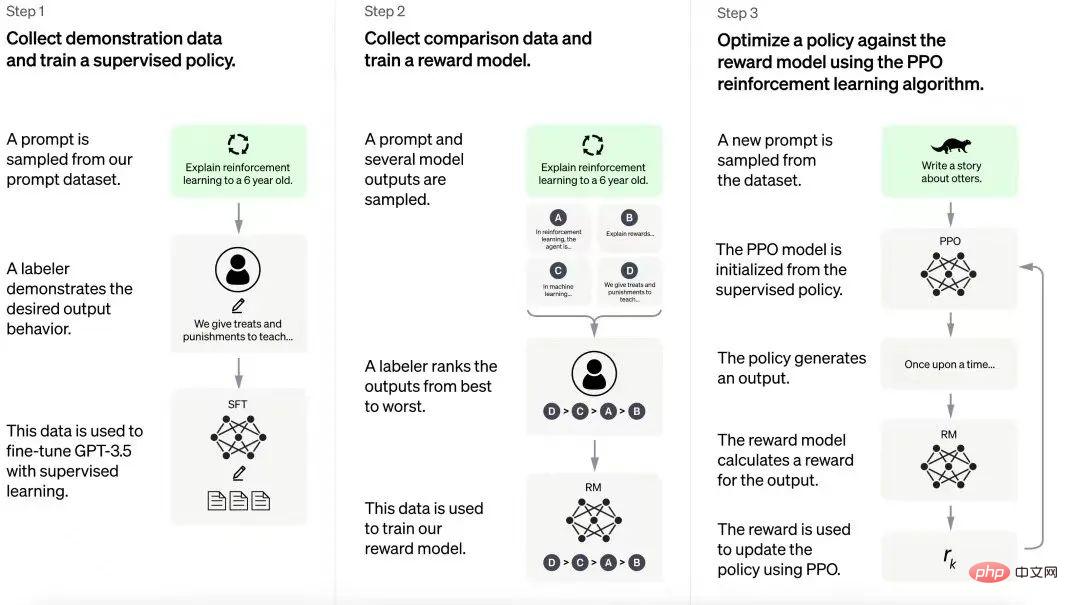 ChatGPT-Trainingsprozess
ChatGPT-Trainingsprozess
ChatGPT basiert auf den Erfahrungen aus dem InstructGPT-Modell. Der menschliche Annotator erstellt eine Reihe von Beispielkonversationen, die Benutzeraufforderungen und Modellantworten enthalten. Diese Daten werden zur Feinabstimmung des GPT-3.5-Modells verwendet, auf dem ChatGPT basiert. Im nächsten Schritt erhält das verfeinerte Modell neue Anregungen und mehrere Antworten. Kommentatoren ordnen diese Antworten. Die aus diesen Interaktionen generierten Daten werden dann zum Trainieren von Belohnungsmodellen verwendet, was zur weiteren Feinabstimmung großer Sprachmodelle (LLMs) in Reinforcement-Learning-Pipelines beiträgt.
OpenAI hat nicht die vollständigen Details des Reinforcement-Learning-Prozesses bekannt gegeben, aber die Leute sind daran interessiert, die „nicht skalierbaren Kosten“ dieses Prozesses zu erfahren, das heißt, wie viel Arbeitskraft erforderlich ist.
Allerdings ist das Modell auch anfällig für Fehler, die denen großer Sprachmodelle (LLMs) ähneln, wie z. B. das Zitieren nicht existierender Arbeiten und Bücher, Missverständnisse der intuitiven Physik und Versagen bei der Kompositionalität.
Die Menschen sind von diesen Misserfolgen nicht überrascht. ChatGPT wirkt nicht magisch und sollte unter den gleichen Problemen leiden wie sein Vorgänger. Doch wo und in welchem Umfang kann man ihm in realen Anwendungen vertrauen? Offensichtlich gibt es hier etwas Wertvolles, wie man in Codex und GitHubCopilot sehen kann, dass Large Language Models (LLMs) sehr effektiv genutzt werden können.
Was darüber entscheidet, ob ChatGPT hier nützlich ist, ist die Art der Tools und der damit implementierte Schutz. ChatGPT könnte beispielsweise eine sehr gute Plattform für die Erstellung von Chatbots für Unternehmen werden, etwa als digitale Begleiter für Codierung und Grafikdesign. Erstens: Wenn es dem Beispiel von InstructGPT folgt, sollten Sie in der Lage sein, die Leistung komplexer Modelle mit weniger Parametern zu erreichen, was es kostengünstig machen würde. Wenn OpenAI außerdem Tools bereitstellt, die es Unternehmen ermöglichen, ihre eigene Feinabstimmung des Reinforcement Learning mit menschlichem Feedback (RLHF) zu implementieren, kann es für bestimmte Anwendungen weiter optimiert werden, was in den meisten Fällen nützlicher sein wird als Chatbots über irgendetwas. Wenn Anwendungsentwickler schließlich über die Tools verfügen, mit denen sie ChatGPT in Anwendungsszenarien integrieren und seine Ein- und Ausgaben bestimmten Anwendungsereignissen und -aktionen zuordnen können, können sie die richtigen Leitplanken festlegen, um zu verhindern, dass Modelle instabile Funktionen übernehmen.
Im Grunde hat OpenAI ein leistungsstarkes Tool für künstliche Intelligenz geschaffen, das jedoch offensichtliche Mängel aufweist. Jetzt muss das richtige Ökosystem an Entwicklungstools geschaffen werden, um sicherzustellen, dass Produktteams die Leistungsfähigkeit von ChatGPT nutzen können. GPT-3 öffnet den Weg für viele unvorhersehbare Anwendungen, daher wird es interessant sein zu wissen, was ChatGPT bereithält.
Originallink: https://bdtechtalks.com/2022/12/05/openai-chatgpt/
Das obige ist der detaillierte Inhalt vonDie Zahl der Benutzer hat in 5 Tagen die Marke von einer Million überschritten. Was ist das Geheimnis hinter ChatGPT?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 ChatGPT-Registrierung
ChatGPT-Registrierung
 Inländische kostenlose ChatGPT-Enzyklopädie
Inländische kostenlose ChatGPT-Enzyklopädie
 So installieren Sie ChatGPT auf einem Mobiltelefon
So installieren Sie ChatGPT auf einem Mobiltelefon
 Kann Chatgpt in China verwendet werden?
Kann Chatgpt in China verwendet werden?
 Ist Linux ein eingebettetes System?
Ist Linux ein eingebettetes System?
 Python-Entwicklungstools
Python-Entwicklungstools
 So beantragen Sie die Registrierung einer E-Mail-Adresse
So beantragen Sie die Registrierung einer E-Mail-Adresse
 Einführung in Standard-Tags in PHP
Einführung in Standard-Tags in PHP








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



