
 Technologie-Peripheriegeräte
KI
Durch die Umkehrfunktion steigt das Re-ID-Modell von 88,54 % auf 0,15 %.
Technologie-Peripheriegeräte
KI
Durch die Umkehrfunktion steigt das Re-ID-Modell von 88,54 % auf 0,15 %.
Durch die Umkehrfunktion steigt das Re-ID-Modell von 88,54 % auf 0,15 %.

Die erste Version dieses Artikels wurde im Mai 2018 verfasst und kürzlich im Dezember 2022 veröffentlicht. Ich habe in den letzten vier Jahren viel Unterstützung und Verständnis von meinen Vorgesetzten erhalten.
(Ich hoffe auch, dass diese Erfahrung den Studenten, die Arbeiten einreichen, etwas Mut macht. Wenn Sie die Arbeit gut schreiben, werden Sie auf jeden Fall gewinnen, geben Sie nicht so schnell auf!)
Die frühe Version von arXiv ist: Abfrageangriff über Funktion in entgegengesetzter Richtung: Auf dem Weg zu einem robusten Bildabruf
 Papier-Backup-Link: https://zdzheng.xyz/files/IJCV_Retrieval_Robustness_CameraReady.pdf
Papier-Backup-Link: https://zdzheng.xyz/files/IJCV_Retrieval_Robustness_CameraReady.pdf
Code: https://github.com/layumi/U_turn
Autor: Zhedong Zheng, Liang Zheng, Yi Yang und Fei Wu Mehrskaliger Abfrageangriff/Black-Box-Angriff / Verteidigen Sie Experimente aus drei verschiedenen Blickwinkeln.
Fügen Sie neue Methoden und neuere Visualisierungsmethoden für Food256, Market-1501, CUB, Oxford, Paris und andere Datensätze hinzu.
Die PCB-Struktur in Reid und WiderResNet in Cifar10 angegriffen.Tatsächliche Fälle
Im tatsächlichen Gebrauch. Nehmen wir zum Beispiel an, wir wollen das Bildabrufsystem von Google oder Baidu angreifen, um große Schlagzeilen zu machen (Nebel). Wir können ein Bild eines Hundes herunterladen, die Merkmale mithilfe des Imagenet-Modells (oder anderer Modelle, vorzugsweise eines Modells in der Nähe des Retrievalsystems) berechnen und das gegnerische Rauschen plus berechnen, indem wir die Merkmale umdrehen (die Methode in diesem Artikel). Zurück zum Hund. Nutzen Sie dann nach dem Angriff die Bildsuchfunktion für den Hund. Sie sehen, dass das System von Baidu und Google keine hundebezogenen Inhalte zurückgeben kann. Obwohl wir Menschen immer noch erkennen können, dass es sich hier um ein Bild eines Hundes handelt.
- P.S.: Ich habe auch versucht, Google anzugreifen, um nach Bildern zu suchen. Die Leute können immer noch erkennen, dass es sich um ein Bild eines Hundes handelt, aber Google gibt oft „Mosaik“-bezogene Bilder zurück. Ich schätze, dass Google nicht alle Deep-Features verwendet oder sich stark vom Imagenet-Modell unterscheidet. Daher tendiert es nach einem Angriff oft dazu, „Mosaik“ anstelle anderer Entitätskategorien (Flugzeuge und dergleichen) zu verwenden. Natürlich kann Mosaik bis zu einem gewissen Grad als Erfolg gewertet werden!
- Was
- 1. Die ursprüngliche Absicht dieses Artikels ist eigentlich sehr einfach. Das vorhandene Reid-Modell oder Landschaftsabrufmodell hat eine Rückrufrate von mehr als 95 % erreicht. Können wir also einen Angriffsweg entwickeln? Abruf? Modell? Lassen Sie uns einerseits den Hintergrund des REID-Modells untersuchen. Andererseits dient der Angriff der besseren Verteidigung.
- 2. Der Unterschied zwischen dem Abrufmodell und dem herkömmlichen Klassifizierungsmodell besteht darin, dass das Abrufmodell extrahierte Merkmale verwendet, um die Ergebnisse zu vergleichen (Sortierung), was sich deutlich vom herkömmlichen Klassifizierungsmodell unterscheidet, wie in der folgenden Tabelle dargestellt.
- 3. Ein weiteres Merkmal von Retrieval-Problemen ist die offene Menge, was bedeutet, dass die Kategorien beim Testen während des Trainings oft nicht sichtbar sind. Wenn Sie mit dem Jungtierdatensatz vertraut sind, gibt es unter der Abrufeinstellung mehr als 100 Vogelarten im Trainingssatz und mehr als 100 Vogelarten im Testsatz. Diese beiden 100 Arten überschneiden sich nicht Typen. Matching und Ranking basieren ausschließlich auf extrahierten visuellen Merkmalen. Daher eignen sich einige Klassifizierungsangriffsmethoden nicht für Angriffe auf das Abrufmodell, da der auf der Kategorievorhersage basierende Gradient während des Angriffs häufig ungenau ist.
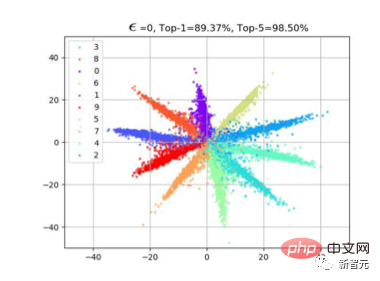
1. Eine natürliche Idee sind Angriffseigenschaften. Wie kann man also Funktionen angreifen? Basierend auf unseren früheren Beobachtungen zum Kreuzentropieverlust (siehe Artikel „Großmargiger Softmax-Verlust“). Wenn wir Klassifizierungsverlust verwenden, weist Merkmal f häufig eine radiale Verteilung auf. Dies liegt daran, dass beim Lernen die Cos-Ähnlichkeit zwischen dem Merkmal und dem Gewicht W der letzten Klassifizierungsschicht berechnet wird. Wie in der folgenden Abbildung gezeigt, werden Stichproben derselben Klasse nach dem Erlernen des Modells in der Nähe von W dieser Klasse verteilt, sodass f*W den Maximalwert erreichen kann. Wie
2 Also haben wir uns eine sehr einfache Methode ausgedacht, nämlich die Funktionen umzudrehen. Wie in der folgenden Abbildung dargestellt, gibt es tatsächlich zwei gängige Klassifizierungsangriffsmethoden, die auch gemeinsam visualisiert werden können. Beispielsweise dient (a) dazu, die Kategorie mit der höchsten Klassifizierungswahrscheinlichkeit (z. B. Fast Gradient) zu unterdrücken, indem -Wmax angegeben wird, sodass es eine Ausbreitungsrichtung des roten Gradienten entlang des inversen Wmax gibt, während es in (b) eine andere gibt Eine Möglichkeit, die am wenigsten wahrscheinliche Kategorie zu unterdrücken, wird nach oben gezogen (z. B. am wenigsten wahrscheinlich), sodass der rote Farbverlauf entlang von Wmin verläuft.
3. Diese beiden Klassifizierungsangriffsmethoden sind bei herkömmlichen Klassifizierungsproblemen natürlich sehr direkt und effektiv. Da es sich bei den Testsätzen im Retrieval-Problem jedoch ausschließlich um unsichtbare Kategorien (unsichtbare Vogelarten) handelt, passt die Verteilung von natürlichem f nicht genau zu Wmax oder Wmin. Daher ist unsere Strategie sehr einfach. Da wir f haben, können wir es einfach Verschieben Sie f nach -f, wie in Abbildung (c) gezeigt.
Auf diese Weise werden in der Feature-Matching-Phase die ursprünglichen hochrangigen Ergebnisse idealerweise am niedrigsten eingestuft, wenn sie als Cos-Ähnlichkeit mit -f berechnet werden, von nahe 1 bis nahe -1.
Wir haben den Effekt unserer Angriffs-Retrieval-Sortierung erreicht.
4. Eine kleine Erweiterung. Bei Abrufproblemen verwenden wir häufig auch Multiskalen zur Abfrageerweiterung. Daher haben wir auch untersucht, wie der Angriffseffekt in diesem Fall aufrechterhalten werden kann. (Die Hauptschwierigkeit besteht darin, dass der Größenänderungsvorgang einige kleine, aber kritische Schwankungen glätten kann.)
Tatsächlich ist unsere Methode, damit umzugehen, ebenfalls sehr einfach. Genau wie beim Modellensemble mitteln wir die kontradiktorischen Gradienten mehrerer Skalen zu einem Ensemble.
Experiment
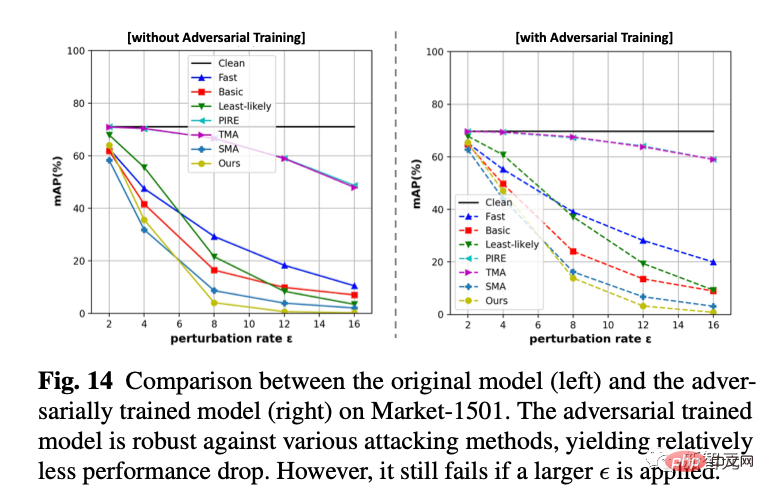
1. Unter drei Datensätzen und drei Indikatoren haben wir die Jitter-Amplitude, das Epsilon der Abszisse, festgelegt und verglichen, welche Methode dazu führen kann, dass das Abrufmodell bei derselben Jitter-Amplitude mehr Fehler macht. Unsere Methode besteht darin, dass die gelben Linien alle unten liegen, was bedeutet, dass der Angriffseffekt besser ist.
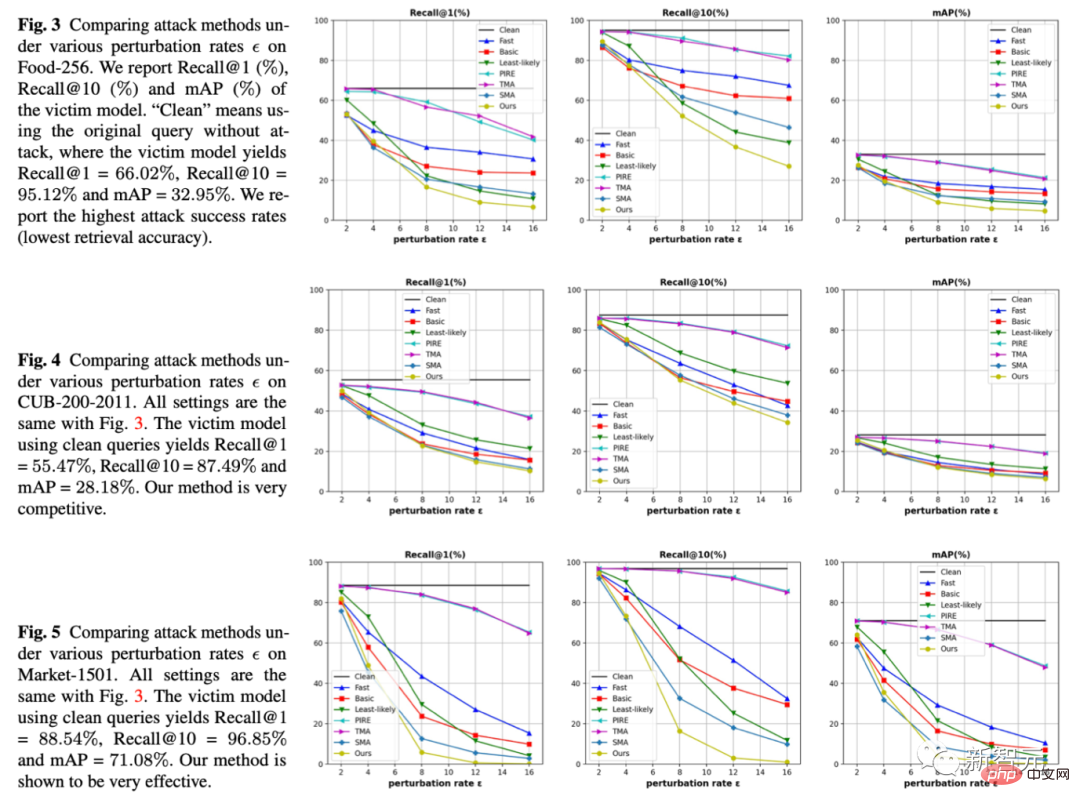
2 Gleichzeitig liefern wir auch quantitative experimentelle Ergebnisse zu 5 Datensätzen (Lebensmittel, CUB, Markt, Oxford, Paris)
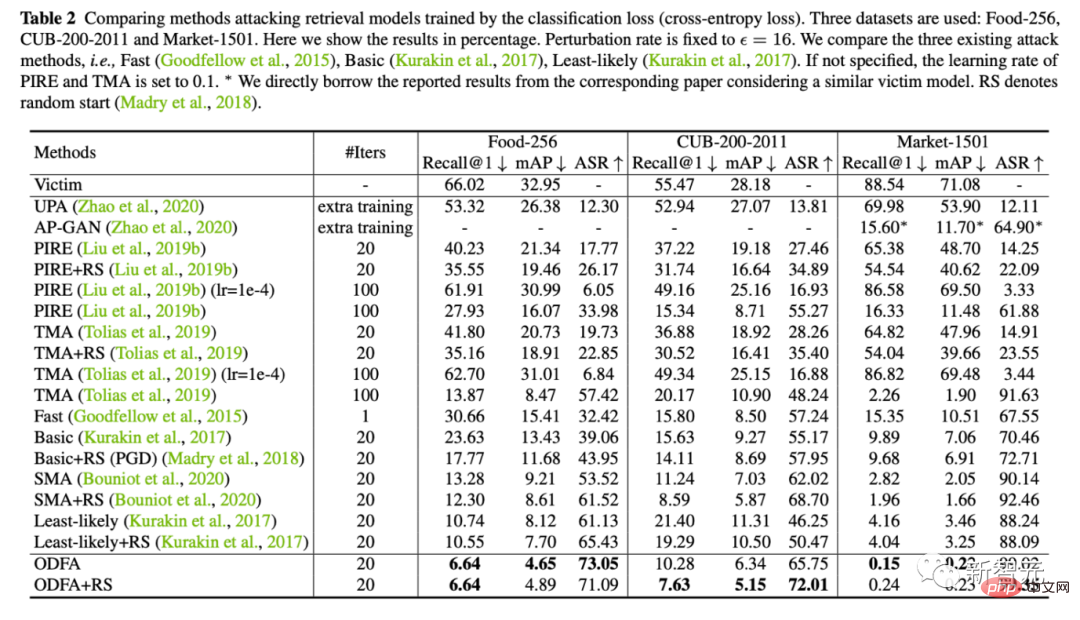
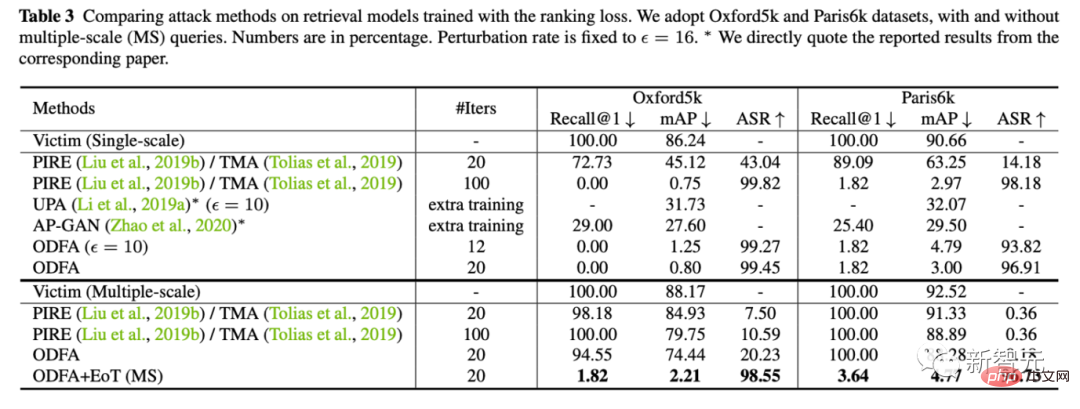
3 Um den Modellmechanismus zu demonstrieren, haben wir auch versucht, das Klassifizierungsmodell auf Cifar10 anzugreifen.
Sie können sehen, dass unsere Strategie, die letzte Funktionsebene zu ändern, auch eine starke Unterdrückungskraft gegenüber den Top 5 hat. Da für die Top-1-Kandidaten keine Kandidatenkategorie herangezogen wird, ist sie etwas niedriger als die am wenigsten wahrscheinliche, aber sie ist fast gleich.
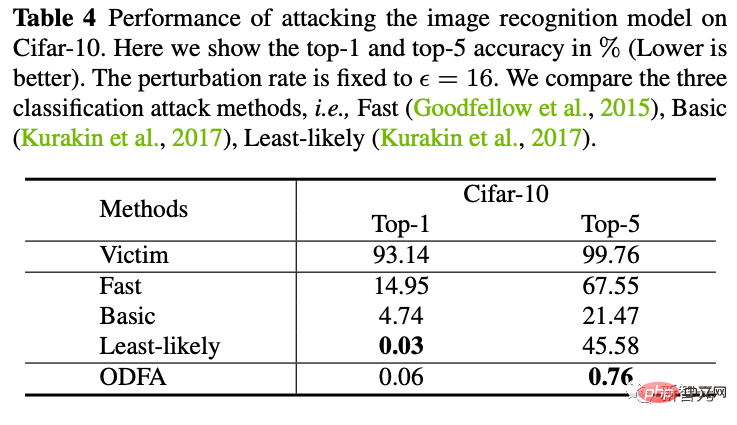
4. Black-Box-Angriff
Wir haben auch versucht, das von ResNet50 generierte Angriffsbeispiel zu verwenden, um ein Black-Box-DenseNet-Modell anzugreifen (die Parameter dieses Modells stehen uns nicht zur Verfügung). Es zeigt sich, dass auch bessere Migrationsangriffsfähigkeiten erreicht werden können.
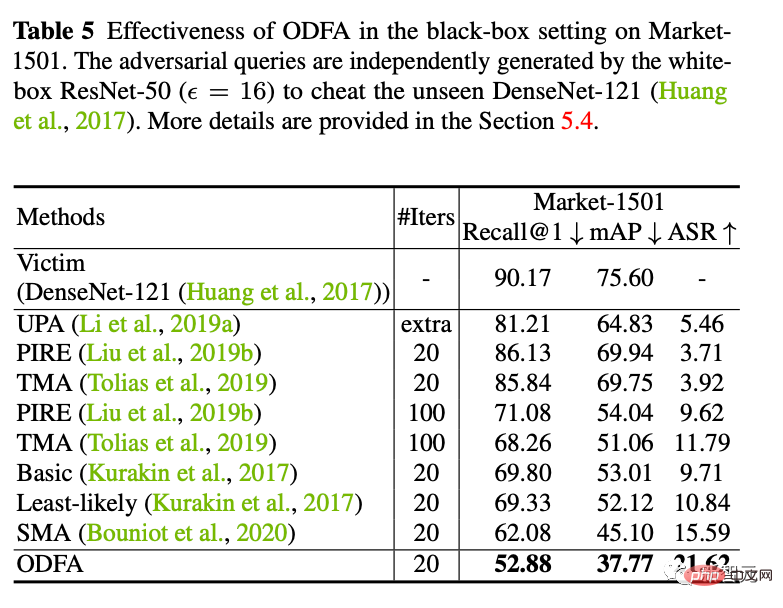
5. Gegenverteidigung
Wir nutzen Online-Gegnertraining, um ein Verteidigungsmodell zu trainieren. Wir haben festgestellt, dass es immer noch ineffektiv ist, wenn es neue White-Box-Angriffe akzeptiert, aber bei kleinen Schwankungen (weniger Punkteverlust) stabiler ist als ein völlig wehrloses Modell.
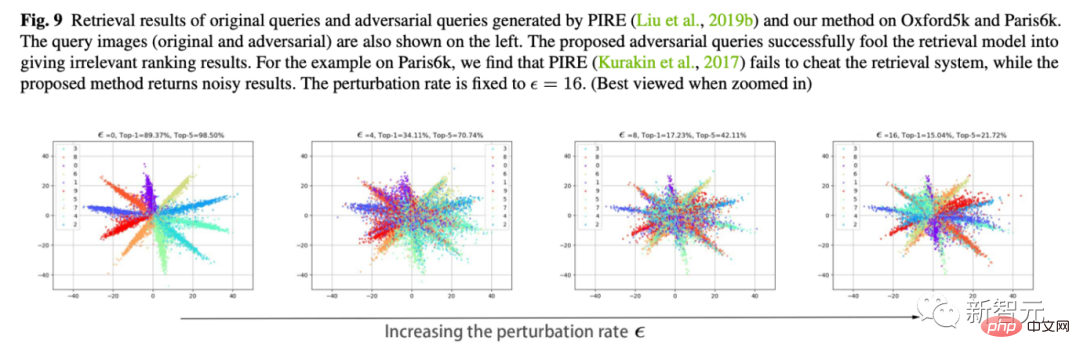
6. Visualisierung von Feature-Bewegungen
Das ist auch mein Lieblingsexperiment. Wir verwenden Cifar10, um die Dimension der letzten Klassifizierungsschicht auf 2 zu ändern und die Änderungen in den Merkmalen der Klassifizierungsschicht darzustellen.
Wie in der Abbildung unten gezeigt, können wir mit zunehmender Jitter-Amplitude Epsilon sehen, dass sich die Eigenschaften der Probe langsam „umkehren“. Beispielsweise sind die meisten orangefarbenen Merkmale auf die gegenüberliegende Seite verschoben.
Das obige ist der detaillierte Inhalt vonDurch die Umkehrfunktion steigt das Re-ID-Modell von 88,54 % auf 0,15 %.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Mar 18, 2024 am 09:20 AM
Mar 18, 2024 am 09:20 AM
Heute möchte ich eine aktuelle Forschungsarbeit der University of Connecticut vorstellen, die eine Methode zum Abgleichen von Zeitreihendaten mit großen NLP-Modellen (Natural Language Processing) im latenten Raum vorschlägt, um die Leistung von Zeitreihenprognosen zu verbessern. Der Schlüssel zu dieser Methode besteht darin, latente räumliche Hinweise (Eingabeaufforderungen) zu verwenden, um die Genauigkeit von Zeitreihenvorhersagen zu verbessern. Titel des Papiers: S2IP-LLM: SemanticSpaceInformedPromptLearningwithLLMforTimeSeriesForecasting Download-Adresse: https://arxiv.org/pdf/2403.05798v1.pdf 1. Hintergrundmodell für große Probleme
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
