
 Technologie-Peripheriegeräte
KI
Warum ist DeepMind beim GPT-Fest nicht dabei? Es stellte sich heraus, dass ich einem kleinen Roboter das Fußballspielen beibrachte.
Technologie-Peripheriegeräte
KI
Warum ist DeepMind beim GPT-Fest nicht dabei? Es stellte sich heraus, dass ich einem kleinen Roboter das Fußballspielen beibrachte.
Warum ist DeepMind beim GPT-Fest nicht dabei? Es stellte sich heraus, dass ich einem kleinen Roboter das Fußballspielen beibrachte.

Nach Meinung vieler Wissenschaftler ist verkörperte Intelligenz eine vielversprechende Richtung in Richtung AGI, und der Erfolg von ChatGPT ist auch untrennbar mit der auf Verstärkungslernen basierenden RLHF-Technologie verbunden. DeepMind vs. OpenAI, wer kann AGI zuerst erreichen? Die Antwort scheint noch nicht bekannt zu sein.
Wir wissen, dass die Schaffung universeller verkörperter Intelligenz (d. h. Agenten, die in der physischen Welt auf agile, geschickte Weise agieren und wie Tiere oder Menschen verstehen) eine davon ist die langfristigen Ziele von KI-Forschern und Robotik-Experten. Zeitlich gesehen reicht die Entwicklung intelligenter verkörperter Agenten mit komplexen Fortbewegungsfähigkeiten viele Jahre zurück, sowohl in Simulationen als auch in der realen Welt.
Das Tempo des Fortschritts hat sich in den letzten Jahren deutlich beschleunigt, wobei lernbasierte Methoden eine große Rolle spielen. Zum Beispiel hat sich gezeigt, dass Deep Reinforcement Learning in der Lage ist, komplexe Bewegungssteuerungsprobleme simulierter Charaktere zu lösen, einschließlich komplexer, wahrnehmungsgesteuerter Ganzkörpersteuerung oder Multiagentenverhalten. Gleichzeitig wird Deep Reinforcement Learning zunehmend bei physischen Robotern eingesetzt. Insbesondere weit verbreitete hochwertige Vierbeinerroboter sind zu Demonstrationszielen für das Erlernen der Erzeugung einer Reihe robuster Bewegungsverhaltensweisen geworden.
Bewegung in statischen Umgebungen ist jedoch nur ein Teil der vielen Möglichkeiten, wie Tiere und Menschen ihren Körper einsetzen, um mit der Welt zu interagieren, und dieses Bewegungsmuster wurde verwendet in vielen Studien zur Ganzkörperkontrolle und in Arbeiten zur Bewegungsmanipulation, insbesondere für vierbeinige Roboter, nachgewiesen. Beispiele für verwandte Bewegungen sind Klettern, Fußballfähigkeiten wie Dribbeln oder Ballfangen sowie einfache Manöver mit den Beinen.
Unter anderem zeigt es beim Fußball viele Merkmale der menschlichen sensomotorischen Intelligenz. Die Komplexität des Fußballs erfordert eine Vielzahl äußerst agiler und dynamischer Bewegungen, darunter Laufen, Drehen, Ausweichen, Treten, Passen, Fallen und Aufstehen usw. Diese Maßnahmen müssen auf vielfältige Weise kombiniert werden. Die Spieler müssen den Ball, ihre Mitspieler und gegnerischen Spieler vorhersagen und ihre Aktionen an die Spielumgebung anpassen. Diese Vielfalt an Herausforderungen wurde in der Robotik- und KI-Community erkannt und RoboCup war geboren.
Es sollte jedoch beachtet werden, dass die Beweglichkeit, Flexibilität und schnelle Reaktion, die für ein gutes Fußballspiel erforderlich sind, sowie der reibungslose Übergang zwischen diesen Elementen eine große Herausforderung darstellen manuelles Design von Robotern. Kürzlich untersuchte ein neuer Artikel von DeepMind (inzwischen mit dem Google Brain-Team zu Google DeepMind fusioniert) den Einsatz von Deep Reinforcement Learning zum Erlernen agiler Fußballfähigkeiten für zweibeinige Roboter.

Papier Adresse :https://arxiv.org/pdf/2304.13653.pdf
Projekthomepage: https://sites.google.com /view/op3-soccer
In diesem Artikel untersuchen Forscher die Ganzkörpersteuerung und -steuerung kleiner humanoider Roboter in dynamischen Multiagentenumgebungen. Objektinteraktion. Sie betrachteten einen Teilbereich des gesamten Fußballproblems, trainierten einen kostengünstigen humanoiden Miniaturroboter mit 20 steuerbaren Gelenken, um ein 1-gegen-1-Fußballspiel zu spielen, und beobachteten propriozeptive und Spielzustandsmerkmale. Mit der eingebauten Steuerung bewegt sich der Roboter langsam und ungeschickt. Die Forscher verwendeten jedoch tiefes Verstärkungslernen, um dynamische und agile kontextadaptive motorische Fähigkeiten (wie Gehen, Laufen, Drehen und Treten eines Balls und das Wiederaufstehen nach einem Sturz) zu synthetisieren, die der Agent auf natürliche und reibungslose Weise zu komplexen Langstrecken kombinierte -term Verhaltensweisen.
Im Experiment lernte der Agent, die Bewegung des Balls vorherzusagen, ihn zu positionieren, zu blockieren und abprallende Bälle zu verwenden. Agenten erreichen diese Verhaltensweisen in einer Umgebung mit mehreren Agenten dank einer Kombination aus Wiederverwendung von Fähigkeiten, End-to-End-Schulung und einfachen Belohnungen. Die Forscher schulten Agenten in Simulationen und übertrugen sie auf physische Roboter. Sie zeigten, dass die Übertragung von Simulationen in die Realität auch für kostengünstige Roboter möglich ist.
Die Laufgeschwindigkeit des Roboters erhöhte sich um 156 %, die Zeit zum Aufstehen wurde um 63 % verkürzt und die Geschwindigkeit beim Treten des Balls wurde im Vergleich zum Ausgangswert ebenfalls um 24 % erhöht.
Bevor wir uns mit der technischen Interpretation befassen, werfen wir einen Blick auf einige Highlights von Robotern in 1v1-Fußballspielen. Zum Beispiel Schießen:


Elfmeter:

Drehen, dribbeln und treten, alles in einem Durchgang

Blockieren:

Versuchsaufbau
Wenn Sie möchten, dass ein Roboter das Fußballspielen lernt, müssen Sie zunächst einige Grundeinstellungen vornehmen.
In Bezug auf die Umgebung simuliert und trainiert DeepMind den Agenten zunächst in einer maßgeschneiderten Fußballumgebung und migriert dann die Strategie in die entsprechende reale Umgebung, wie in Abbildung 1 dargestellt. Die Umgebung bestand aus einem Fußballfeld von 5 m Länge und 4 m Breite mit zwei Toren mit einer Öffnungsweite von jeweils 0,8 m. Sowohl in simulierten als auch in realen Umgebungen ist das Spielfeld durch Rampen begrenzt, um den Ball im Spiel zu halten. Der eigentliche Spielfeldboden ist mit Gummifliesen bedeckt, um das Risiko einer Beschädigung des Roboters durch einen Sturz zu verringern und die Reibung auf dem Boden zu erhöhen.
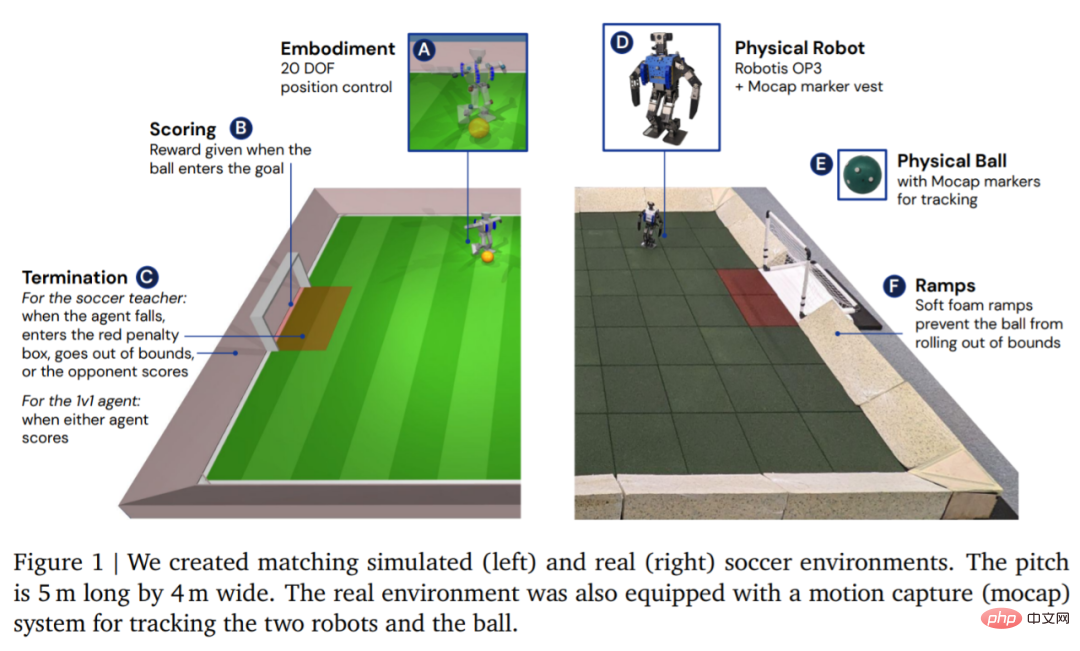
Nachdem die Umgebung eingerichtet ist, besteht der nächste Schritt darin, die Hardware und die Bewegungserfassung einzurichten. DeepMind verwendet einen Robotis OP3-Roboter, der 51 cm groß und 3,5 kg schwer ist und von 20 Servomotoren angetrieben wird. Der Roboter verfügt über keine GPU oder einen anderen dedizierten Beschleuniger, daher laufen alle neuronalen Netzwerkberechnungen auf der CPU. An der Spitze des Roboters sitzt eine Logitech C920-Webcam, die optional einen RGB-Videostream mit 30 Bildern pro Sekunde liefern kann.

Methode
DeepMinds Ziel ist es, einen Agenten zu trainieren, der gehen, einen Ball treten, aufstehen und verteidigen kann und weiß, wie man punktet, und diese Funktionen dann auf einen echten Roboter zu übertragen. DeepMind unterteilt das Training in zwei Phasen, wie in Abbildung 3 dargestellt.
- In der ersten Phase trainiert DeepMind Lehrerstrategien für zwei spezifische Fähigkeiten, darunter das Aufstehen des Agenten vom Boden und das Schießen von Toren.
- In der zweiten Phase wird die Lehrerstrategie aus der ersten Phase verwendet, um den Agenten zu regulieren, während der Agent lernt, effektiv gegen immer mächtigere Gegner zu kämpfen.
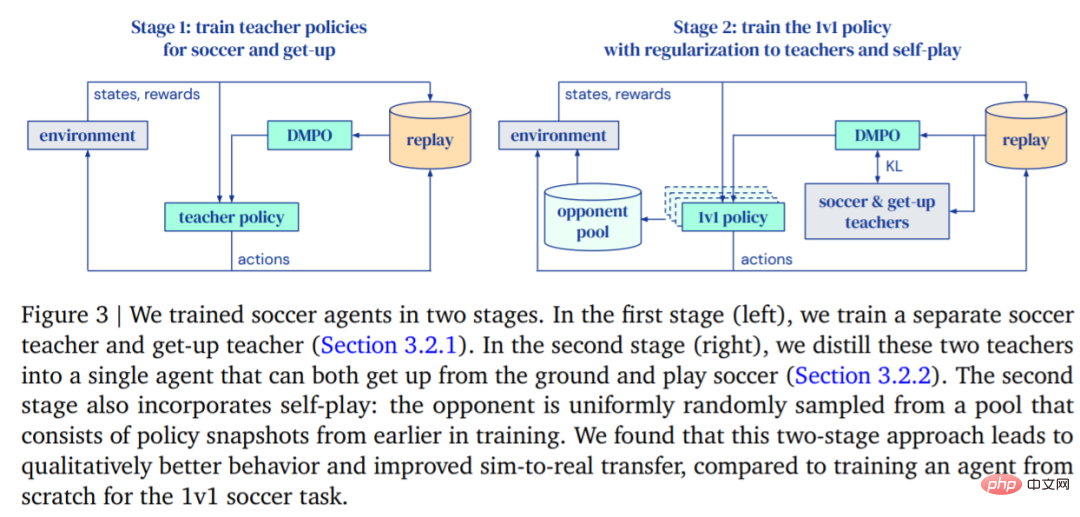
Ausbildung
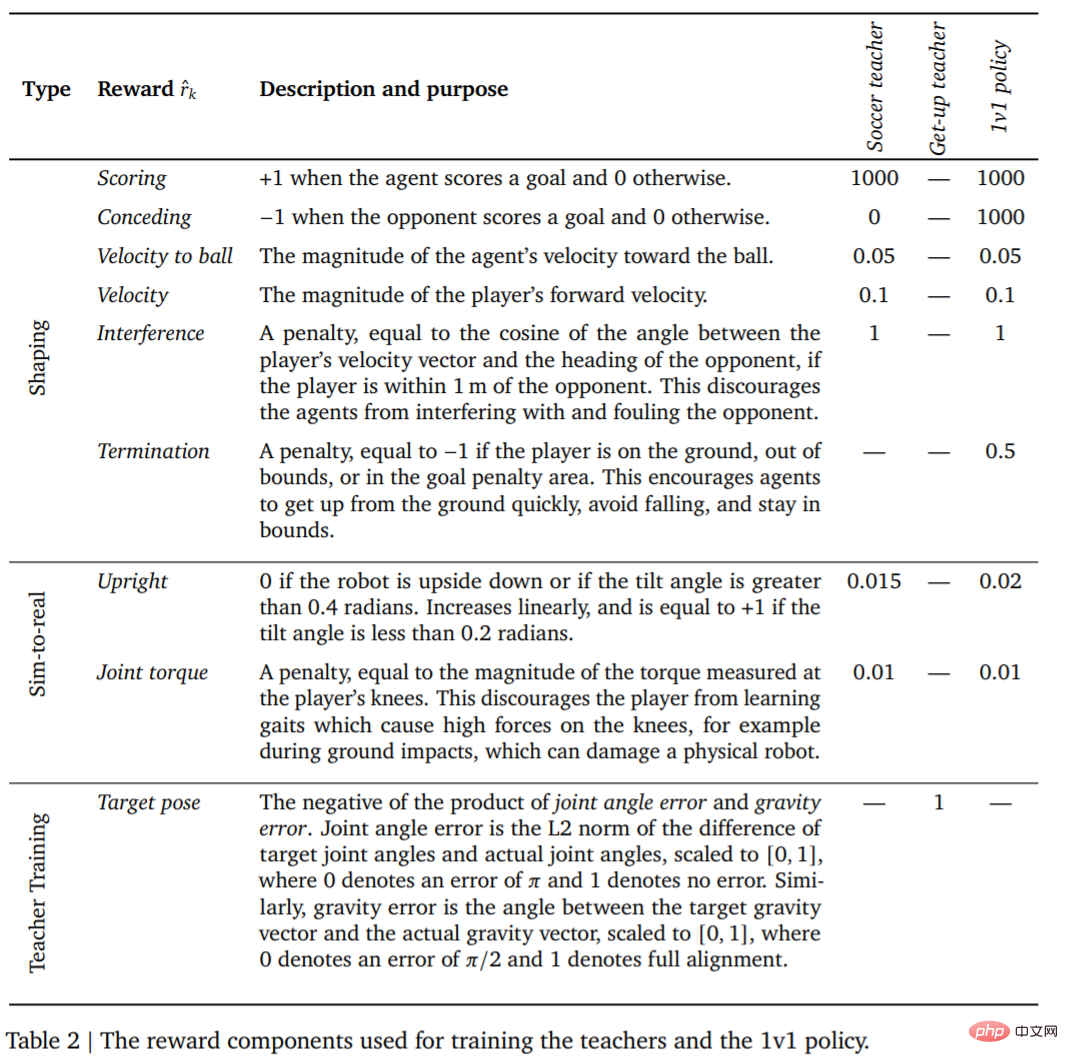
Das erste ist die Lehrerausbildung. Lehrer müssen so umfassend wie möglich in der Zielerreichung geschult werden. Diese Runde (Episoden) endet, wenn der Agent fällt, das Spielfeld verlässt, den Sperrbereich betritt (in Abbildung 1 rot markiert) oder wenn der Gegner ein Tor erzielt. Zu Beginn jeder Runde werden der Agent, die andere Seite und der Ball auf zufällige Positionen und Richtungen auf dem Spielfeld initialisiert. Beide Seiten werden auf die Standardhaltung initialisiert. Der Gegner wird mit einer ungeschulten Richtlinie initialisiert, sodass der Agent in dieser Phase lernt, dem Gegner auszuweichen, es finden jedoch keine weiteren komplexen Interaktionen statt. Darüber hinaus sind in Tabelle 2 die Belohnungen und deren Gewichtungen für jede Trainingsphase aufgeführt.
Der Agent tritt dann gegen immer mächtigere Gegner an und passt sein Verhalten an die Richtlinien des Lehrers an. Auf diese Weise kann der Agent eine Reihe von Fußballfähigkeiten erlernen: Gehen, Treten, Aufstehen, Tore schießen und Verteidigen. Wenn der Agent ins Aus geht oder sich in der Torbox befindet, erhält er bei jedem Zeitschritt eine feste Strafe.
Nachdem der intelligente Agent trainiert wurde, besteht der nächste Schritt darin, die trainierte Trittstrategie ohne Proben auf den echten Roboter zu übertragen. Um die Erfolgsquote des Zero-Shot-Transfers zu verbessern, verringert DeepMind die Lücke zwischen simulierten Agenten und echten Robotern durch einfache Systemidentifikation, verbessert die Robustheit der Strategie durch Domänenrandomisierung und Störung während des Trainings und umfasst die Gestaltung der zu erhaltenden Belohnungsstrategie anderes Verhalten, das dem Roboter zu wahrscheinlich schadet.
Experimente
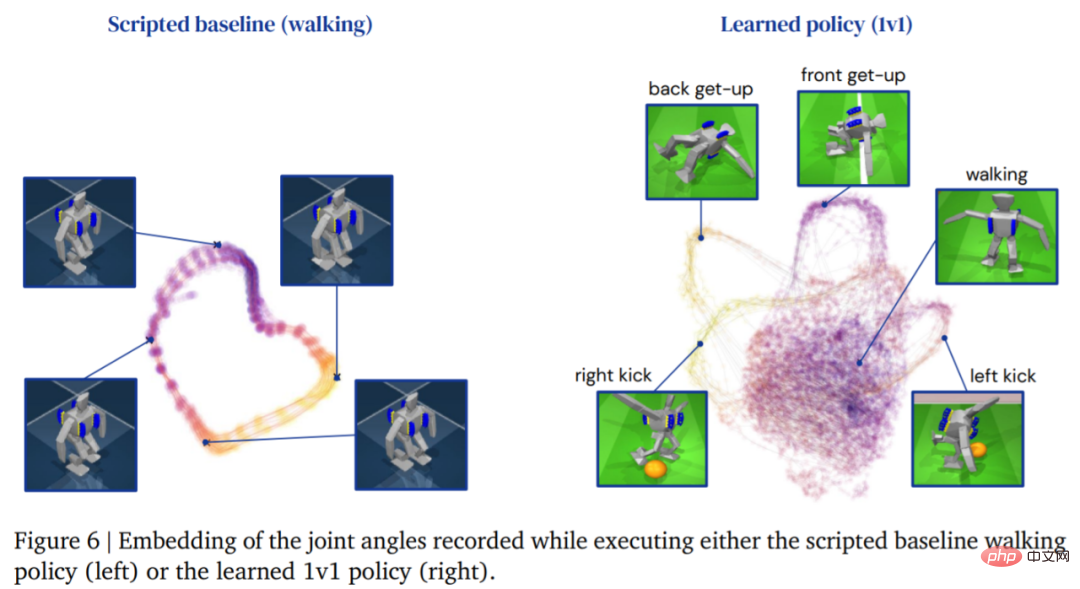
1-gegen-1-Wettbewerb: Der Fußballagent kann mit einer Vielzahl aufkommender Verhaltensweisen umgehen, einschließlich flexibler motorischer Fähigkeiten wie Aufstehen vom Boden, schnelle Erholung nach Stürzen, Laufen und Drehen. Während des Spiels wechselt der Agent fließend zwischen all diesen Fähigkeiten.

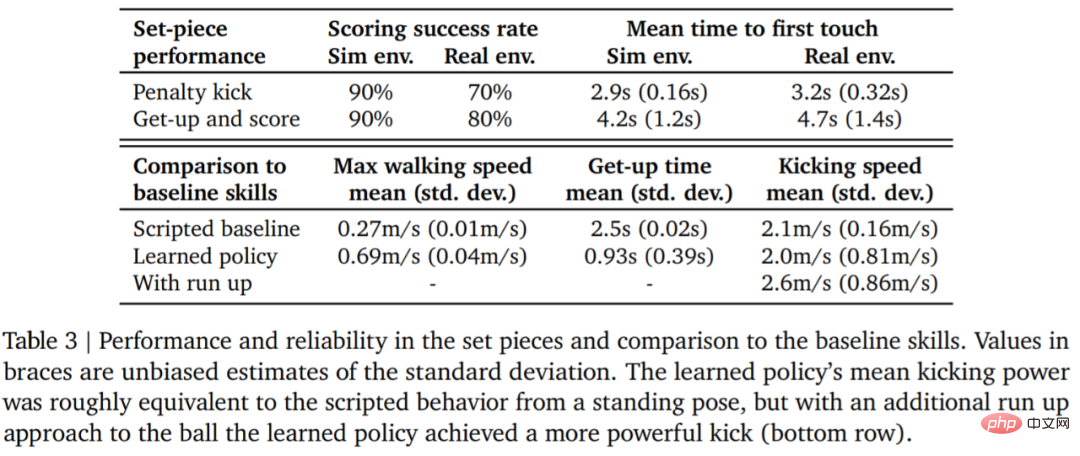
Tabelle 3 unten zeigt die Ergebnisse der quantitativen Analyse. Aus den Ergebnissen geht hervor, dass die Strategie des verstärkenden Lernens besser abschneidet als spezialisierte, künstlich gestaltete Fähigkeiten: Der Agent geht 156 % schneller und benötigt 63 % weniger Zeit zum Aufstehen.
Das Bild unten zeigt die Laufbahn des Agenten, die durch die Lernstrategie generiert wird, ist umfangreicher:
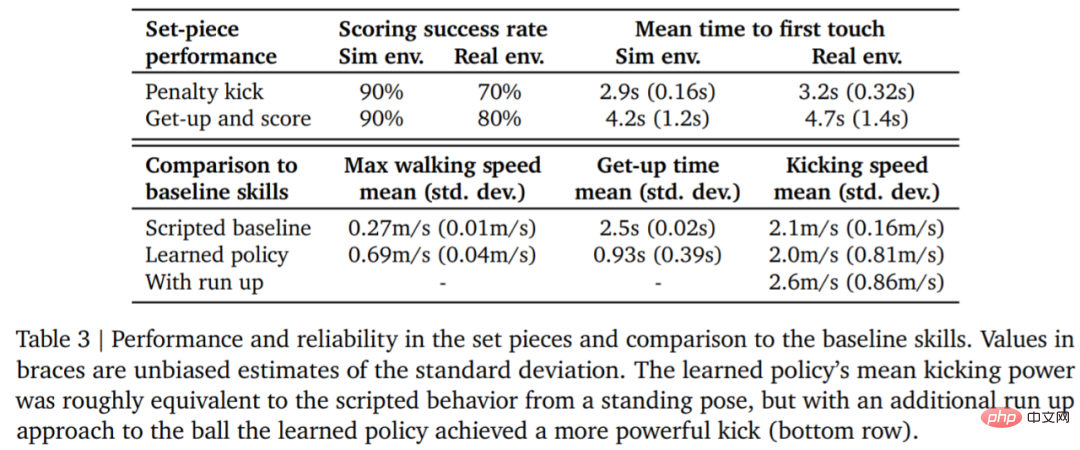
Zur Bewertung die Zuverlässigkeit der Lernstrategie DeepMind entwarf Strafstöße und Standardsituationen mit Sprungschüssen und implementierte sie in simulierten und realen Umgebungen. Die anfängliche Konfiguration ist in Abbildung 7 dargestellt.
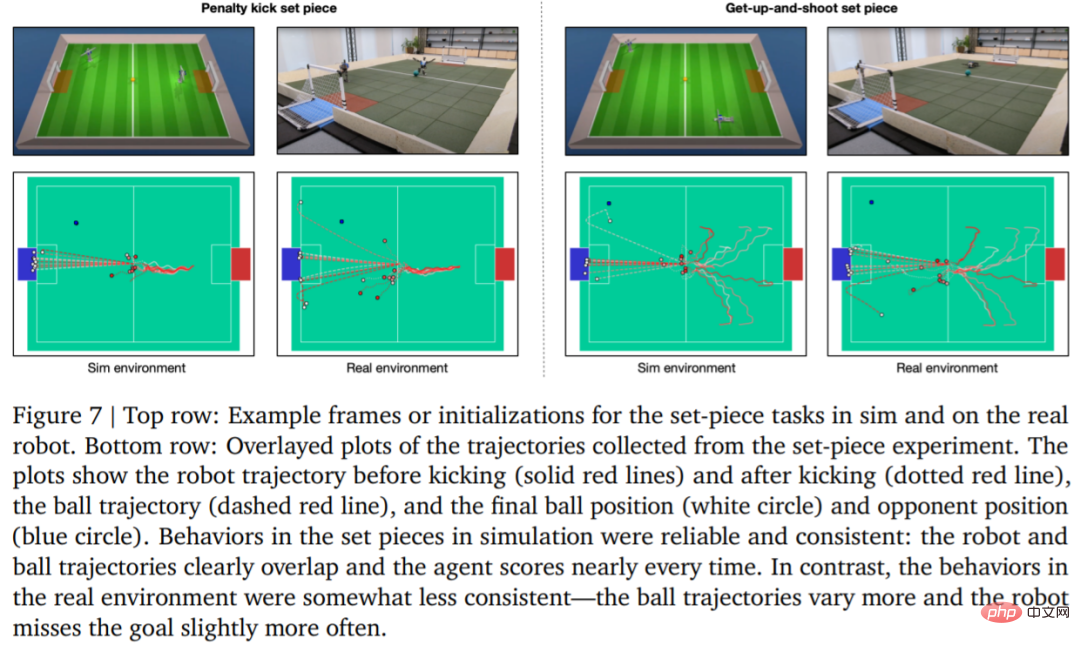
In einer realen Umgebung traf der Roboter 7 von 10 Malen (70 %) bei der Strafstoßaufgabe und 8 von 10 Malen (80 %) bei der Startaufgabe. Im Simulationsexperiment waren die Ergebnisse des Agenten bei diesen beiden Aufgaben konsistenter, was zeigt, dass die Trainingsstrategie des Agenten auf die reale Umgebung (einschließlich realer Roboter, Bälle, Bodenflächen usw.) übertragen wird und die Leistung leicht beeinträchtigt ist Die Verhaltensunterschiede haben zugenommen, aber der Roboter ist immer noch in der Lage, zuverlässig aufzustehen, den Ball zu treten und zu punkten. Die Ergebnisse sind in Abbildung 7 und Tabelle 3 dargestellt.
Das obige ist der detaillierte Inhalt vonWarum ist DeepMind beim GPT-Fest nicht dabei? Es stellte sich heraus, dass ich einem kleinen Roboter das Fußballspielen beibrachte.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
