
 Technologie-Peripheriegeräte
KI
HKUST & MSRA Research: Was die Bild-zu-Bild-Konvertierung betrifft, ist die Feinabstimmung alles, was Sie brauchen
Technologie-Peripheriegeräte
KI
HKUST & MSRA Research: Was die Bild-zu-Bild-Konvertierung betrifft, ist die Feinabstimmung alles, was Sie brauchen
HKUST & MSRA Research: Was die Bild-zu-Bild-Konvertierung betrifft, ist die Feinabstimmung alles, was Sie brauchen


Viele Content-Produktionsprojekte erfordern die Umwandlung einfacher Skizzen in realistische Bilder, was eine Bild-zu-Bild-Übersetzung beinhaltet, bei der tiefe generative Modelle verwendet werden, um bedingte Verteilungen natürlicher Bilder anhand einer Eingabe zu erlernen .
Das Grundkonzept der Bild-zu-Bild-Konvertierung besteht darin, vorab trainierte neuronale Netze zu nutzen, um natürliche Bildmannigfaltigkeiten zu erfassen. Die Bildtransformation ähnelt dem Durchqueren der Mannigfaltigkeit und dem Auffinden möglicher semantischer Eingabepunkte. Das System trainiert das synthetische Netzwerk vorab mithilfe vieler Bilder, um eine zuverlässige Ausgabe aller Stichproben seines latenten Raums zu liefern. Durch das vorab trainierte synthetische Netzwerk passt das nachgelagerte Training die Benutzereingaben an die latente Darstellung des Modells an.
Im Laufe der Jahre haben wir gesehen, dass viele aufgabenspezifische Methoden das SOTA-Niveau erreichen, aber aktuelle Lösungen haben immer noch Schwierigkeiten, hochauflösende Bilder für den realen Einsatz zu erstellen.

In einem aktuellen Artikel glauben Forscher der Hong Kong University of Science and Technology und Microsoft Research Asia, dass für die Bild-zu-Bild-Konvertierung vorab Training Es ist alles, was Sie brauchen. Bisherige Methoden erfordern einen speziellen Architekturentwurf und das Training eines einzelnen Transformationsmodells von Grund auf, was es schwierig macht, komplexe Szenen mit hoher Qualität zu generieren, insbesondere wenn gepaarte Trainingsdaten nicht ausreichen.
Daher behandeln die Forscher jedes Bild-zu-Bild-Übersetzungsproblem als nachgelagerte Aufgabe und führen ein einfaches allgemeines Framework ein, das ein vorab trainiertes Diffusionsmodell verwendet, um sich an verschiedene Bild-zu-Bild-Übersetzungen anzupassen. Konvertieren. Sie nannten das vorgeschlagene vorab trainierte Bild-zu-Bild-Übersetzungsmodell PITI (vortrainingsbasierte Bild-zu-Bild-Übersetzung). Darüber hinaus schlugen die Forscher auch vor, kontradiktorisches Training zu verwenden, um die Textursynthese im Diffusionsmodelltraining zu verbessern, und es mit normalisierter geführter Probenahme zu kombinieren, um die Generierungsqualität zu verbessern.
Abschließend führten die Forscher umfangreiche empirische Vergleiche zu verschiedenen Aufgaben mit anspruchsvollen Benchmarks wie ADE20K, COCO-Stuff und DIODE durch und zeigten, dass PITI-synthetisierte Bilder einen beispiellosen Realismus und eine beispiellose Wiedergabetreue aufweisen.

- Papierlink: https://arxiv.org/pdf/2205.12952.pdf
- Projektheimat Seite:https://tengfei-wang.github.io/PITI/index.html
GAN ist tot, das Diffusionsmodell lebt weiter
Der Autor hat kein spezifisches GAN verwendet, das leistungsstärkste GAN auf diesem Gebiet, sondern verwendet stattdessen ein Diffusionsmodell, um eine Vielzahl von Bildern zu synthetisieren. Zweitens sollte es Bilder aus zwei Arten latenter Codes generieren: einem, der die visuelle Semantik beschreibt, und einem anderen, der sich an Bildschwankungen anpasst. Semantische, niedrigdimensionale latente Daten sind für nachgelagerte Aufgaben von entscheidender Bedeutung. Andernfalls wäre es unmöglich, den modalen Input in einen komplexen latenten Raum umzuwandeln. Vor diesem Hintergrund verwendeten sie GLIDE, ein datengesteuertes Modell, das verschiedene Bilder generieren kann, als vorab trainierten generativen Prior. Da GLIDE latenten Text verwendet, ermöglicht es einen semantischen latenten Raum.
Diffusions- und Score-basierte Methoden demonstrieren die Generierungsqualität über Benchmarks hinweg. Im klassenbedingten ImageNet konkurrieren diese Modelle hinsichtlich der visuellen Qualität und der Stichprobenvielfalt mit GAN-basierten Methoden. Kürzlich haben Diffusionsmodelle, die mit großen Text-Bild-Paarungen trainiert wurden, überraschende Fähigkeiten gezeigt. Ein gut trainiertes Diffusionsmodell kann eine allgemeine generative Vorstufe für die Synthese liefern.
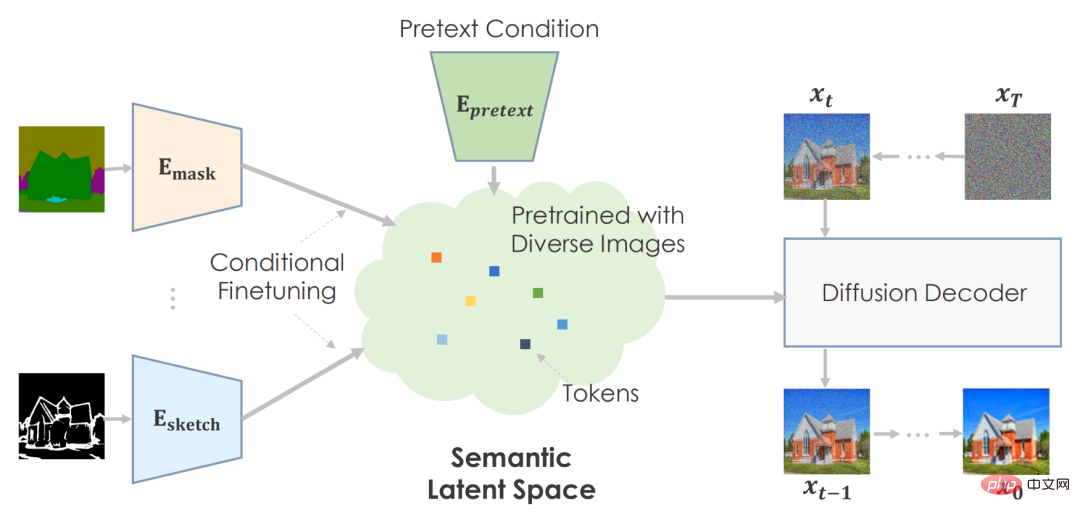
Framework
Der Autor kann die Vorwandaufgabe verwenden, um eine große Datenmenge vorab zu trainieren und eine sehr effektive zu entwickeln Aussagekräftige latente Räume zur Vorhersage von Bildstatistiken.
Für nachgelagerte Aufgaben optimieren sie den semantischen Raum bedingt, um aufgabenspezifische Umgebungen abzubilden. Die Maschine erstellt glaubwürdige Bilder basierend auf vorab trainierten Informationen.
Der Autor empfiehlt, semantische Eingaben zu verwenden, um das Diffusionsmodell vorab zu trainieren. Sie verwenden textkonditioniertes, bildtrainiertes GLIDE-Modell. Das Transformer-Netzwerk codiert Texteingaben und gibt Token für das Diffusionsmodell aus. Wie geplant ist es sinnvoll, den Text in den Raum einzubetten.

Das Bild oben ist das Werk des Autors. Vorab trainierte Modelle verbessern die Bildqualität und -vielfalt im Vergleich zu völlig neuen Techniken. Da der COCO-Datensatz über zahlreiche Kategorien und Kombinationen verfügt, kann der grundlegende Ansatz keine schönen Ergebnisse mit einer überzeugenden Architektur liefern. Ihre Methode kann für schwierige Szenen reichhaltige Details mit präziser Semantik erzeugen. Bilder veranschaulichen die Vielseitigkeit ihres Ansatzes.
Experimente und Auswirkungen
Tabelle 1 zeigt, dass die Leistung der in dieser Studie vorgeschlagenen Methode immer besser ist als die anderer Modelle. Im Vergleich zum führenden OASIS erzielt PITI erhebliche Verbesserungen im FID bei der Maske-zu-Bild-Synthese. Darüber hinaus zeigt die Methode auch eine gute Leistung bei Skizze-zu-Bild- und Geometrie-zu-Bild-Syntheseaufgaben.
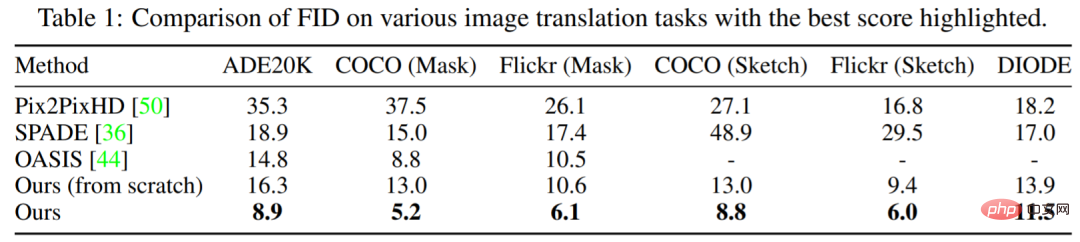
Abbildung 3 zeigt die Visualisierungsergebnisse dieser Studie zu verschiedenen Aufgaben. Experimente zeigen, dass das vorab trainierte Modell im Vergleich zur Trainingsmethode von Grund auf die Qualität und Vielfalt der generierten Bilder deutlich verbessert. Die in dieser Studie verwendeten Methoden können selbst bei anspruchsvollen Generierungsaufgaben lebendige Details und korrekte Semantik erzeugen.

Diese Studie führte auch eine Benutzerstudie zur Masken-zu-Bild-Synthese bei COCO-Stuff auf Amazon Mechanical Turk mit 3000 Stimmen von 20 Teilnehmern durch. Den Teilnehmern wurden jeweils zwei Bilder vorgelegt und sie wurden gebeten, darüber abzustimmen, welches realistischer war. Wie in Tabelle 2 gezeigt, übertrifft die vorgeschlagene Methode das Modell von Grund auf und andere Basislinien bei weitem.

Die bedingte Bildsynthese erstellt hochwertige Bilder, die den Bedingungen entsprechen. Die Bereiche Computer Vision und Grafik nutzen es, um Informationen zu erstellen und zu manipulieren. Umfangreiches Vortraining verbessert die Bildklassifizierung, Objekterkennung und semantische Segmentierung. Unbekannt ist, ob eine groß angelegte Vorschulung für allgemeine Erzeugungsaufgaben von Vorteil ist.
Energieverbrauch und CO2-Emissionen sind zentrale Themen beim Image-Pre-Training. Das Vortraining ist energieintensiv, aber nur einmal erforderlich. Durch die bedingte Feinabstimmung können nachgelagerte Aufgaben dasselbe vorab trainierte Modell verwenden. Durch das Vortraining können generative Modelle mit weniger Trainingsdaten trainiert werden, wodurch die Bildsynthese verbessert wird, wenn die Daten aufgrund von Datenschutzproblemen oder hohen Annotationskosten begrenzt sind.
Das obige ist der detaillierte Inhalt vonHKUST & MSRA Research: Was die Bild-zu-Bild-Konvertierung betrifft, ist die Feinabstimmung alles, was Sie brauchen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
