
 Technologie-Peripheriegeräte
KI
Eine Textzeile erzeugt eine dynamische 3D-Szene: Metas „One-Step'-Modell ist ziemlich leistungsfähig
Technologie-Peripheriegeräte
KI
Eine Textzeile erzeugt eine dynamische 3D-Szene: Metas „One-Step'-Modell ist ziemlich leistungsfähig
Eine Textzeile erzeugt eine dynamische 3D-Szene: Metas „One-Step'-Modell ist ziemlich leistungsfähig

Einfach eine Textzeile eingeben, um eine dynamische 3D-Szene zu generieren?
Ja, einige Forscher haben es bereits getan. Es ist ersichtlich, dass der aktuelle Generationseffekt noch in den Kinderschuhen steckt und nur einige einfache Objekte generieren kann. Diese „einstufige“ Methode erregte jedoch immer noch die Aufmerksamkeit einer großen Anzahl von Forschern: 🎜# In einem aktuellen Artikel schlugen Forscher von Meta erstmals MAV3D (Make-A-Video3D) vor, eine Methode, die aus Textbeschreibungen dreidimensionale dynamische Szenen generieren kann.

Papierlink: https:/ / /arxiv.org/abs/2301.11280

- Projektlink: https://make-a-video3d.github.io/ # 🎜🎜# Konkret nutzt diese Methode 4D Dynamic Neural Radiation Field (NeRF), um text-to-video (T2V) diffusionsbasiert abzufragen Modell zur Optimierung der Konsistenz von Szenenerscheinung, Dichte und Bewegung. Die durch den bereitgestellten Text erzeugte dynamische Videoausgabe kann aus jedem Kamerawinkel oder Winkel betrachtet und in jede 3D-Umgebung synthetisiert werden.
- MAV3D benötigt keine 3D- oder 4D-Daten, das T2V-Modell wird nur auf Text-Bild-Paare und unbeschriftete Videos trainiert. Werfen wir einen Blick auf die Wirkung der Generierung dynamischer 4D-Szenen aus Text durch MAV3D: 🎜🎜#
Darüber hinaus kann auch direkt vom Bild in 4D gewechselt werden, der Effekt ist wie folgt:
#🎜 Die Forscher haben die Wirksamkeit der Methode durch umfassende quantitative und qualitative Experimente nachgewiesen und auch die zuvor ermittelte interne Basislinie wurde verbessert. Es wird berichtet, dass dies die erste Methode ist, dynamische 3D-Szenen basierend auf Textbeschreibungen zu generieren.
 Methode
Methode
Das Ziel dieser Forschung ist die Entwicklung einer Methode, die dynamische 3D-Szenendarstellungen aus Beschreibungen in natürlicher Sprache generieren kann. Dies ist äußerst anspruchsvoll, da weder Text- oder 3D-Paare noch dynamische 3D-Szenendaten für das Training vorhanden sind. Aus diesem Grund haben wir uns entschieden, uns auf ein vorab trainiertes Text-zu-Video-Diffusionsmodell (T2V) als Szene zu verlassen, das gelernt hat, das realistische Erscheinungsbild und die Bewegung der Szene durch Training an großformatigen Bildern, Texten usw. zu modellieren Videodaten.
Auf einer höheren Ebene kann die Studie bei gegebener Textaufforderung p eine 4D-Darstellung anpassen, die das Erscheinungsbild der mit der Aufforderung übereinstimmenden Szene zu jedem Zeitpunkt in Raum und Zeit simuliert. Ohne gepaarte Trainingsdaten kann die Studie die Ausgabe von 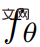 nicht direkt überwachen; bei gegebener Sequenz von Kamerapositionen
nicht direkt überwachen; bei gegebener Sequenz von Kamerapositionen 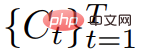 ist es jedoch möglich, daraus zu rendern
ist es jedoch möglich, daraus zu rendern 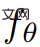 Nehmen Sie eine Bildfolge auf
Nehmen Sie eine Bildfolge auf 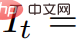
 und stapeln Sie sie zu einem Video V. Der Text-Prompt p und das Video V werden dann an das eingefrorene und vorab trainierte T2V-Diffusionsmodell übergeben, das die Authentizität und Prompt-Ausrichtung des Videos bewertet und mithilfe von SDS (Score Distillation Sampling) die Aktualisierungsrichtung des Szenenparameters θ berechnet.
und stapeln Sie sie zu einem Video V. Der Text-Prompt p und das Video V werden dann an das eingefrorene und vorab trainierte T2V-Diffusionsmodell übergeben, das die Authentizität und Prompt-Ausrichtung des Videos bewertet und mithilfe von SDS (Score Distillation Sampling) die Aktualisierungsrichtung des Szenenparameters θ berechnet.
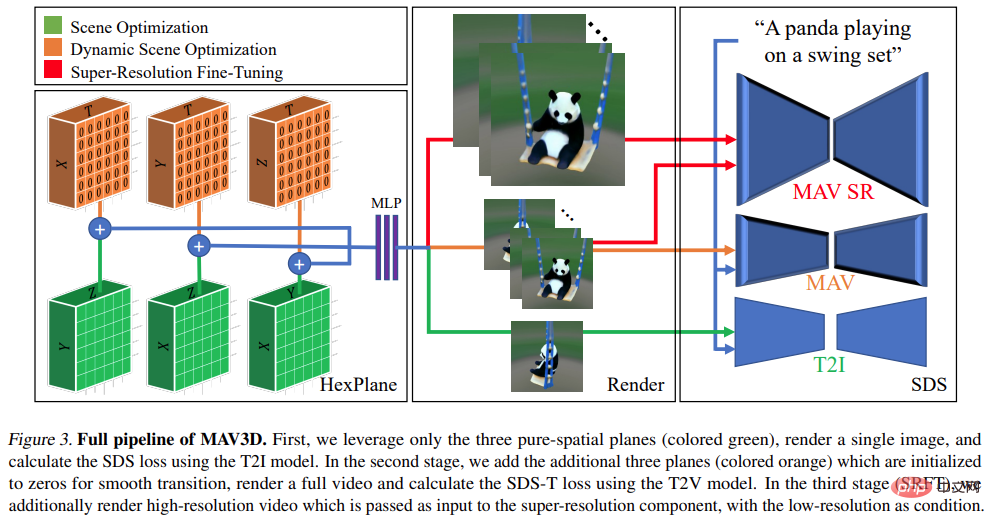
Die obige Pipeline kann als Erweiterung von DreamFusion gezählt werden, indem sie dem Szenenmodell eine zeitliche Dimension hinzufügt und zur Überwachung ein T2V-Modell anstelle eines Text-to-Image (T2I)-Modells verwendet. Um eine qualitativ hochwertige Text-zu-4D-Generierung zu erreichen, sind jedoch weitere Innovationen erforderlich:
- Erstens sind neue 4D-Darstellungen erforderlich, die eine flexible Szenenbewegungsmodellierung ermöglichen.
- Zweitens: Ein mehrstufiges statisches bis dynamisches Optimierungsschema wird benötigt, um die Videoqualität zu verbessern und die Modellkonvergenz zu verbessern.
- Drittens muss Super-Resolution Fine-Tuning (SRFT) verwendet werden, um die Modellauflösung zu verbessern.
Spezifische Anweisungen finden Sie in der Abbildung unten:
Experiment
In dem Experiment bewerteten die Forscher die Fähigkeit von MAV3D, dynamische Szenen aus Textbeschreibungen zu generieren. Zunächst bewerteten die Forscher die Wirksamkeit der Methode bei der Text-To-4D-Aufgabe. Es wird berichtet, dass MAV3D die erste Lösung für diese Aufgabe ist, daher wurden im Rahmen der Forschung drei alternative Methoden als Basis entwickelt. Zweitens evaluieren wir vereinfachte Versionen der T2V- und Text-To-3D-Teilaufgabenmodelle und vergleichen sie mit bestehenden Basislinien in der Literatur. Drittens rechtfertigen umfassende Ablationsstudien das Methodendesign. Viertens beschreiben Experimente den Prozess der Konvertierung von dynamischem NeRF in dynamische Netze, wodurch das Modell letztendlich auf Bild-zu-4D-Aufgaben erweitert wird.
Metriken
Die Studie wertet die generierten Videos mit CLIP R-Precision aus, das die Konsistenz zwischen Text und generierten Szenen misst. Die gemeldete Metrik ist die Genauigkeit des Abrufens der Eingabeaufforderung aus dem gerenderten Frame. Wir haben die ViT-B/32-Variante von CLIP verwendet und Frames in verschiedenen Ansichten und Zeitschritten extrahiert und außerdem vier qualitative Metriken verwendet, indem wir menschliche Bewerter nach ihren Präferenzen für zwei generierte Videos gefragt haben: (i) Videoqualität ( ii) Treue zu Textaufforderungen; (iii) Ausmaß der Aktivität; (iv) Realismus der Bewegung. Wir haben alle bei der Textaufforderungssegmentierung verwendeten Basislinien und Ablationen ausgewertet.
Abbildung 1 und 2 sind Beispiele. Detailliertere Visualisierungen finden Sie unter make-a-video3d.github.io.

Ergebnis# 🎜🎜#
Tabelle 1 zeigt den Vergleich mit der Basislinie (R – Genauigkeit und menschliche Präferenz). Menschliche Bewertungen werden als Prozentsatz der Stimmen dargestellt, die die Basismehrheit im Vergleich zum Modell in einer bestimmten Umgebung befürworten.
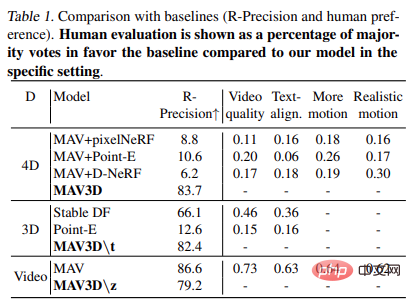
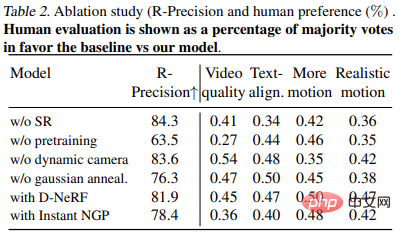
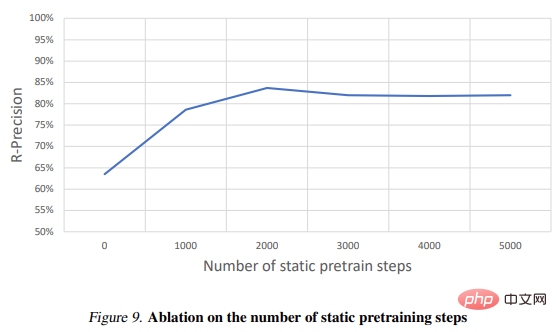
Tabelle 2 zeigt die Ergebnisse des Ablationsexperiments: # 🎜🎜#
Echtzeit-Rendering#🎜 🎜## 🎜🎜# Anwendungen wie Virtual Reality und Spiele, die herkömmliche Grafik-Engines verwenden, erfordern Standardformate wie Texturnetze. HexPlane-Modelle können wie unten gezeigt einfach in animierte Netze umgewandelt werden. Zunächst wird mithilfe des Marching-Cube-Algorithmus ein einfaches Netz aus dem zu jedem Zeitpunkt t erzeugten Opazitätsfeld extrahiert, gefolgt von der Netzextraktion (aus Effizienzgründen) und der Entfernung kleiner, verrauschter verbundener Komponenten. Der XATLAS-Algorithmus wird verwendet, um Netzscheitelpunkte einem Texturatlas zuzuordnen, wobei die Textur mithilfe der HexPlane-Farbe initialisiert wird, die in einer kleinen Kugel gemittelt wird, die an jedem Scheitelpunkt zentriert ist. Abschließend werden die Texturen weiter optimiert, um besser zu einigen Beispielframes zu passen, die von HexPlane mithilfe differenzierbarer Netze gerendert wurden. Dadurch wird eine Sammlung von Texturnetzen erstellt, die in jeder handelsüblichen 3D-Engine wiedergegeben werden können.
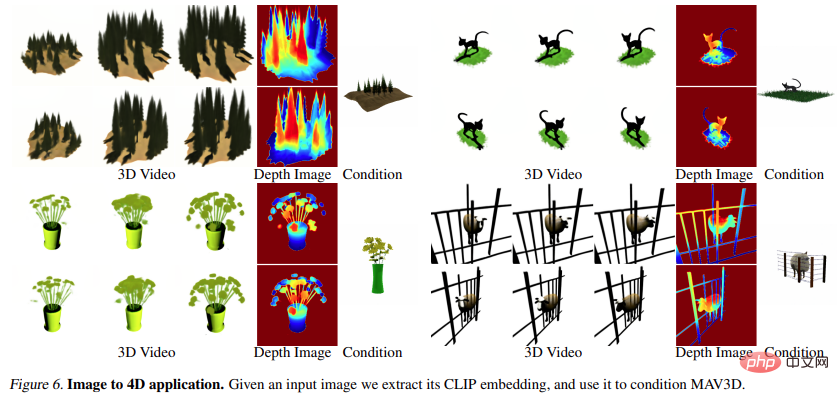
Bild zu 4D
Abbildung 6 und Abbildung 10 zeigen dies Die Methode ist in der Lage, aus einem gegebenen Eingabebild Tiefe und Bewegung zu erzeugen und so 4D-Assets zu generieren.
# 🎜 🎜#


Weitere Forschungsdetails finden Sie im Original Papier.

Das obige ist der detaillierte Inhalt vonEine Textzeile erzeugt eine dynamische 3D-Szene: Metas „One-Step'-Modell ist ziemlich leistungsfähig. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Diese Woche gab FigureAI, ein Robotikunternehmen, an dem OpenAI, Microsoft, Bezos und Nvidia beteiligt sind, bekannt, dass es fast 700 Millionen US-Dollar an Finanzmitteln erhalten hat und plant, im nächsten Jahr einen humanoiden Roboter zu entwickeln, der selbstständig gehen kann. Und Teslas Optimus Prime hat immer wieder gute Nachrichten erhalten. Niemand zweifelt daran, dass dieses Jahr das Jahr sein wird, in dem humanoide Roboter explodieren. SanctuaryAI, ein in Kanada ansässiges Robotikunternehmen, hat kürzlich einen neuen humanoiden Roboter auf den Markt gebracht: Phoenix. Beamte behaupten, dass es viele Aufgaben autonom und mit der gleichen Geschwindigkeit wie Menschen erledigen kann. Pheonix, der weltweit erste Roboter, der Aufgaben autonom in menschlicher Geschwindigkeit erledigen kann, kann jedes Objekt sanft greifen, bewegen und elegant auf der linken und rechten Seite platzieren. Es kann Objekte autonom identifizieren
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
