

Toolformer interpretieren

Große Sprachmodelle (LLM) haben unglaubliche Vorteile bei der Lösung neuer Aufgaben mit begrenzten Textdaten gezeigt. Trotzdem weisen sie jedoch in anderer Hinsicht Einschränkungen auf, wie zum Beispiel:
- Mangelnder Zugang zu aktuellen Informationen
- Tendenz, über Fakten zu fantasieren
- Schwierigkeiten mit Sprachen mit geringen Ressourcen
- Mangelnde Mathematik Fähigkeiten für präzise Berechnungen
- Ungenauigkeit im zeitlichen Verlauf Verstehen
Wie kann man große Modelle verwenden, um mehr Probleme zu lösen? Im Artikel „Interpretation von TaskMatrix.AI“ ist TaskMatrix.AI eine Kombination aus Toolformer und chatGPT, die das Basismodell mit Millionen von APIs verbindet, um Aufgaben zu erledigen. Was ist also ein Toolformer?
Toolformer ist ein neues Open-Source-Meta-Modell, das Probleme lösen kann, die die Verwendung von APIs erfordern, wie z. B. Taschenrechner, Wikipedia-Suchen, Wörterbuchsuche usw. Toolformer erkennt, dass ein Werkzeug verwendet werden muss, bestimmt, welches Werkzeug verwendet werden soll und wie das Werkzeug verwendet werden soll. Die Anwendungsfälle für Toolformers könnten endlos sein, von der Bereitstellung sofortiger Suchergebnisse für jede Frage bis hin zu kontextbezogenen Informationen, wie z. B. den besten Restaurants der Stadt.
1. Was ist Toolformer?
Was ist Toolformer? Kurz gesagt, Toolformer ist ein Sprachmodell, das sich selbst den Umgang mit Werkzeugen beibringen kann.
Toolformer basiert auf einem vorab trainierten GPT-J-Modell mit 6,7 Milliarden Parametern, trainiert mit selbstüberwachten Lernmethoden. Dieser Ansatz umfasst das Sampling und Filtern von API-Aufrufen, um vorhandene Textdatensätze zu erweitern.
Toolformer hofft, die Aufgabe des LLM-Selbstlernens im Umgang mit Werkzeugen durch die folgenden zwei Anforderungen zu erfüllen:
- Der Umgang mit Werkzeugen sollte auf selbstüberwachte Weise erlernt werden, ohne dass eine große Anzahl manueller Anmerkungen erforderlich ist.
- LM soll seine Allgemeingültigkeit nicht verlieren und selbst entscheiden können, wann und wie welches Tool eingesetzt wird.
Die folgende Abbildung zeigt die Vorhersagen von Toolformer (z. B. in Datenbeispiele eingebettete API-Aufrufe):

2. Die Architektur und der Implementierungsansatz von Toolformer
Eine Kernfunktion in ChatGPT ist kontextbasiertes Lernen (In-Context). Lernen) bezieht sich auf eine maschinelle Lernmethode, bei der das Modell aus Beispielen lernt, die in einem bestimmten Kontext oder einer bestimmten Umgebung präsentiert werden. Das Ziel des kontextuellen Lernens besteht darin, die Fähigkeit des Modells zu verbessern, eine Sprache zu verstehen und zu generieren, die für einen bestimmten Kontext oder eine bestimmte Situation geeignet ist. Bei Aufgaben zur Verarbeitung natürlicher Sprache (NLP) können Sprachmodelle trainiert werden, um Antworten auf bestimmte Aufforderungen oder Fragen zu generieren. Wie nutzt Toolformer also die Vorteile von In-Context Learning?
Toolformer ist ein großes Sprachmodell, das die Verwendung verschiedener Tools durch API-Aufrufe ermöglicht. Die Eingabe und Ausgabe jedes API-Aufrufs muss als Text-/Konversationssequenz formatiert werden, um einen natürlichen Ablauf innerhalb der Sitzung zu gewährleisten.

Wie Sie auf dem Bild oben sehen können, nutzt Toolformer zunächst die kontextbezogenen Lernfunktionen des Modells, um eine große Anzahl potenzieller API-Aufrufe abzutasten.
Führen Sie diese API-Aufrufe aus und prüfen Sie, ob die erhaltene Antwort bei der Vorhersage zukünftiger Token helfen und als Filter verwendet werden kann. Nach der Filterung werden API-Aufrufe an verschiedene Tools in die Rohdatenbeispiele eingebettet, was zu einem erweiterten Datensatz führt, an dem das Modell feinabgestimmt wird.
Konkret zeigt das Bild oben ein Modell, das diese Aufgabe mithilfe eines Frage- und Antworttools erfüllt:
- Der LM-Datensatz enthält Beispieltext: Geben Sie die Eingabeaufforderung „Pittsburgh ist auch als The Steel City bekannt“ für „Pittsburgh ist auch bekannt“ ein als".
- Um die richtige Antwort zu finden, muss das Modell einen API-Aufruf durchführen und diesen korrekt ausführen.
- Sampling einiger API-Aufrufe, insbesondere „Unter welchem anderen Namen ist Pittsburgh bekannt?“ und „In welchem Land liegt Pittsburgh?“
- Die entsprechenden Antworten lauten „Steel City“ und „United States“. Da die erste Antwort besser ist, wird sie mit dem API-Aufruf in einen neuen LM-Datensatz aufgenommen: „Pittsburgh ist auch bekannt als [QA(„Welcher andere Name ist Pittsburgh bekannt?“) –> Steel City], die Steel City“ .
- Dies enthält erwartete API-Aufrufe und -Antworten. Wiederholen Sie diesen Schritt, um mit verschiedenen Tools (z. B. API-Aufrufen) neue LM-Datensätze zu generieren.
Also kommentiert LM große Datenmengen mit in den Text eingebetteten API-Aufrufen und verwendet diese API-Aufrufe dann, um LM so zu optimieren, dass nützliche API-Aufrufe durchgeführt werden. So funktioniert selbstüberwachtes Training und zu den Vorteilen dieses Ansatzes gehören:
- Weniger manuelle Anmerkungen erforderlich.
- Durch das Einbetten von API-Aufrufen in Text kann LM mehrere externe Tools verwenden, um mehr Inhalte hinzuzufügen.
Toolformer lernt dann, vorherzusagen, welches Werkzeug für welche Aufgabe verwendet wird.
2.1 Stichprobe von API-Aufrufen
Die folgende Abbildung zeigt, dass Toolformer und verwendet, um den Anfang und das Ende von API-Aufrufen bei gegebener Benutzereingabe darzustellen. Das Schreiben einer Eingabeaufforderung für jede API ermutigt den Toolformer, das Beispiel mit dem entsprechenden API-Aufruf zu kommentieren.

Toolformer weist jedem Token eine Wahrscheinlichkeit als mögliche Fortsetzung der gegebenen Sequenz zu. Diese Methode tastet bis zu k Kandidatenpositionen für einen API-Aufruf ab, indem sie die vom ToolFormer zugewiesene Wahrscheinlichkeit berechnet, den API-Aufruf an jeder Position in der Sequenz zu initiieren. Positionen mit einer Wahrscheinlichkeit, die über einem bestimmten Schwellenwert liegt, werden beibehalten. Für jede Position werden bis zu m API-Aufrufe durch Abtasten vom Toolformer mithilfe einer Sequenz abgerufen, der der API-Aufruf vorangestellt ist und an die die Sequenz-Endmarkierung angehängt ist.
2.2 Ausführung von API-Aufrufen
Die Ausführung von API-Aufrufen hängt vollständig vom Client ab, der den Aufruf ausführt. Der Client kann eine andere Art von Anwendung sein, von einem anderen neuronalen Netzwerk über ein Python-Skript bis hin zu einem Retrieval-System, das in einem großen Korpus sucht. Es ist wichtig zu beachten, dass die API bei einem Aufruf des Clients eine einzelne Textsequenz als Antwort zurückgibt. Diese Antwort enthält detaillierte Informationen zum Anruf, einschließlich des Erfolgs- oder Fehlerstatus des Anrufs, der Ausführungszeit und mehr.
Um genaue Ergebnisse zu erhalten, sollte der Kunde daher sicherstellen, dass die richtigen Eingabeparameter bereitgestellt werden. Wenn die Eingabeparameter falsch sind, gibt die API möglicherweise falsche Ergebnisse zurück, die für den Benutzer möglicherweise nicht akzeptabel sind. Darüber hinaus sollten Clients sicherstellen, dass die Verbindung zur API stabil ist, um Verbindungsunterbrechungen oder andere Netzwerkprobleme während Anrufen zu vermeiden.
2.3 API-Aufrufe filtern
Während des Filtervorgangs berechnet Toolformer den gewichteten Kreuzentropieverlust von Toolformer durch das Token nach dem API-Aufruf.
Vergleichen Sie dann zwei verschiedene Verlustberechnungen:
(i) Eine ist ein API-Aufruf mit dem Ergebnis als Eingabe für den Toolformer
(ii) Eine ist kein API-Aufruf oder API-Aufruf, aber es wird kein Ergebnis zurückgegeben.
Ein API-Aufruf gilt als nützlich, wenn die für den API-Aufruf bereitgestellten Eingaben und Ausgaben es dem Toolformer erleichtern, zukünftige Token vorherzusagen. Wenden Sie einen Filterschwellenwert an, um nur API-Aufrufe beizubehalten, bei denen die Differenz zwischen den beiden Verlusten größer oder gleich dem Schwellenwert ist.
2.4 Feinabstimmung des Modells
Abschließend führt Toolformer die verbleibenden API-Aufrufe mit der ursprünglichen Eingabe zusammen und erstellt einen neuen API-Aufruf, um den Datensatz zu erweitern. Mit anderen Worten: Der erweiterte Datensatz enthält denselben Text wie der ursprüngliche Datensatz, wobei nur die API-Aufrufe eingefügt sind.
Dann verwenden Sie den neuen Datensatz zur Feinabstimmung von ToolFormer unter Verwendung standardmäßiger Sprachmodellierungsziele. Dadurch wird sichergestellt, dass bei der Feinabstimmung des Modells am erweiterten Datensatz derselbe Inhalt angezeigt wird wie bei der Feinabstimmung am Originaldatensatz. Durch die Feinabstimmung der erweiterten Daten kann das Sprachmodell anhand seines eigenen Feedbacks verstehen, wann und wie API-Aufrufe verwendet werden sollen, indem es API-Aufrufe an präzisen Positionen einfügt und Hilfsmodelle verwendet, um zukünftige Token-Eingaben vorherzusagen.
2.5 Inferenz
Während der Inferenz wird der Dekodierungsprozess unterbrochen, wenn das Sprachmodell das „→“-Token erzeugt, das die nächste erwartete Antwort auf den API-Aufruf anzeigt. Rufen Sie dann die entsprechende API auf, um die Antwort abzurufen, und fahren Sie mit der Dekodierung fort, nachdem Sie die Antwort und das Token eingefügt haben.
An diesem Punkt müssen wir sicherstellen, dass die Antwort, die wir erhalten, mit der vom vorherigen Token erwarteten Antwort übereinstimmt. Wenn es nicht übereinstimmt, müssen wir den API-Aufruf anpassen, um die richtige Antwort zu erhalten. Bevor wir mit der Dekodierung fortfahren, müssen wir auch einige Datenverarbeitungen durchführen, um uns auf den nächsten Schritt des Inferenzprozesses vorzubereiten. Zu diesen Datenprozessen gehören die Analyse von Antworten, das Verständnis des Kontexts und die Auswahl von Inferenzpfaden. Daher müssen Sie während des Inferenzprozesses nicht nur die API aufrufen, um eine Antwort zu erhalten, sondern auch eine Reihe von Datenverarbeitungen und -analysen durchführen, um die Richtigkeit und Konsistenz des Inferenzprozesses sicherzustellen.
2.6 API-Tools
Jedes API-Tool, das in Toolformer verwendet werden kann, muss die folgenden zwei Bedingungen erfüllen:
- Eingabe/Ausgabe muss als Textsequenz dargestellt werden.
- Es sind Demos verfügbar, die zeigen, wie diese Tools verwendet werden.
Die erste Implementierung von Toolformer unterstützt fünf API-Tools:
- Q&A: Dies ist ein weiterer LM, der einfache sachliche Fragen beantwortet.
- Rechner: Unterstützt derzeit nur 4 Grundrechenarten und das Runden auf zwei Dezimalstellen.
- Wiki-Suche: Eine Suchmaschine, die aus Wikipedia ausgeschnittene Kurztexte zurückgibt.
- Maschinelles Übersetzungssystem: Ein LM, das Phrasen in jeder Sprache ins Englische übersetzen kann.
- Kalender: API-Aufruf an den Kalender, der das aktuelle Datum zurückgibt, ohne Eingaben zu akzeptieren.
Die folgende Abbildung zeigt die Eingabe- und Ausgabebeispiele aller verwendeten APIs:

3. Anwendungsbeispiele
Toolformer bietet eine hervorragende Leistung bei Aufgaben wie LAMA, mathematischen Datensätzen, Problemlösung und Zeitdatensätzen Im Vergleich zum Basismodell und GPT-3 ist die Leistung bei der Beantwortung mehrsprachiger Fragen jedoch nicht so gut wie bei anderen Modellen. Toolformer verwendet API-Aufrufe, um Aufgaben auszuführen, z. B. die LAMA-API, die Rechner-API und die Wikipedia-Suchtool-API.
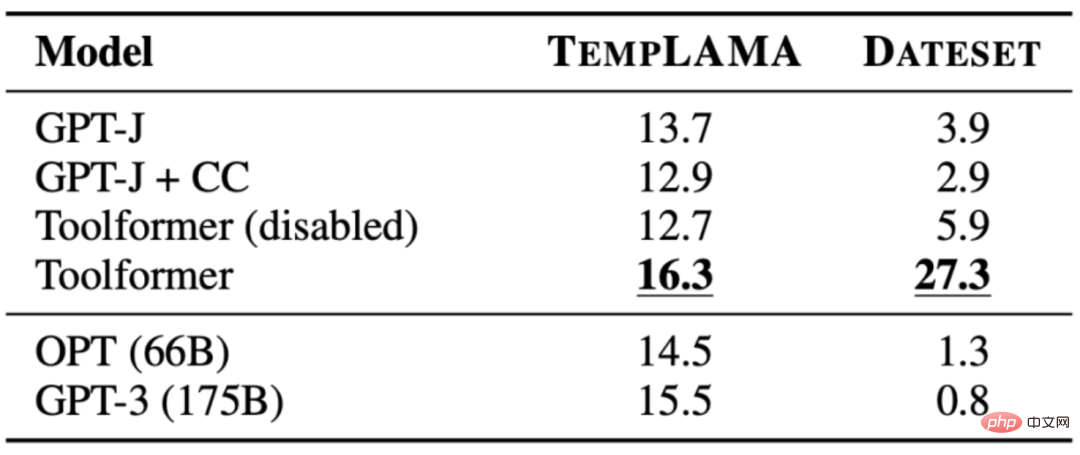
3.1 LAMA
Die Aufgabe besteht darin, eine Aussage zu vervollständigen, der es an Fakten mangelt. Toolformer übertrifft Basismodelle und sogar größere Modelle wie GPT-3. Die folgende Tabelle zeigt die durch LAMA-API-Aufrufe erhaltenen Ergebnisse:
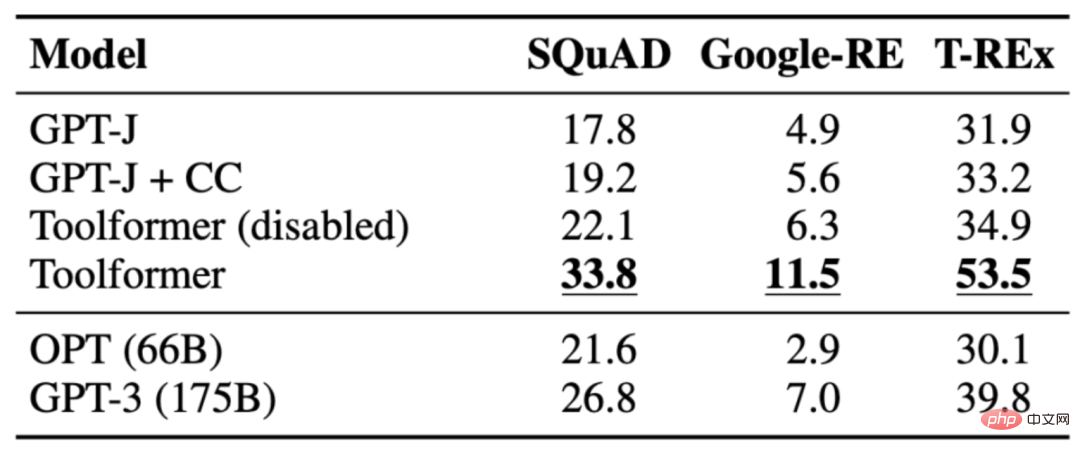
3.2 Mathe-Datensatz
Die Aufgabe besteht darin, die mathematischen Denkfähigkeiten von Toolformer anhand verschiedener Basismodelle zu bewerten. Toolformer schneidet besser ab als die anderen Modelle, wahrscheinlich aufgrund der Feinabstimmung der API-Aufrufbeispiele. Wenn es Modellen ermöglicht wird, API-Aufrufe durchzuführen, verbessert sich die Leistung bei allen Aufgaben erheblich und übertrifft größere Modelle wie OPT und GPT-3. In fast allen Fällen entschied sich das Modell, das Taschenrechner-Tool um Hilfe zu bitten.
Die folgende Tabelle zeigt die durch den Rechner-API-Aufruf erhaltenen Ergebnisse:
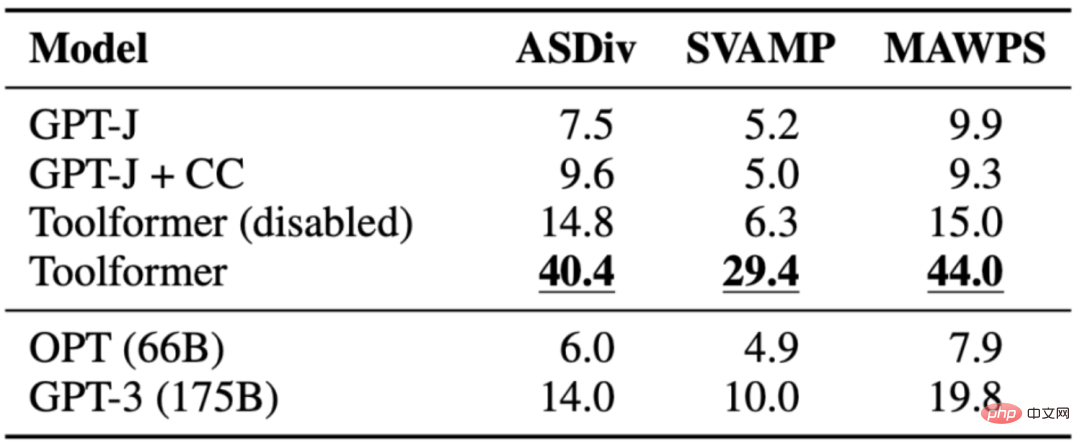
3.3 Frage Antwort
Die Aufgabe besteht darin, die Frage zu beantworten. Die Leistung von Toolformer ist besser als das Basismodell derselben Größe, aber besser als GPT-3(175B). Toolformer nutzt für die meisten Beispiele in dieser Aufgabe die Suchfunktionen von Wikipedia. Die folgende Tabelle zeigt die Ergebnisse, die durch den API-Aufruf des Wikipedia-Suchtools erhalten wurden:
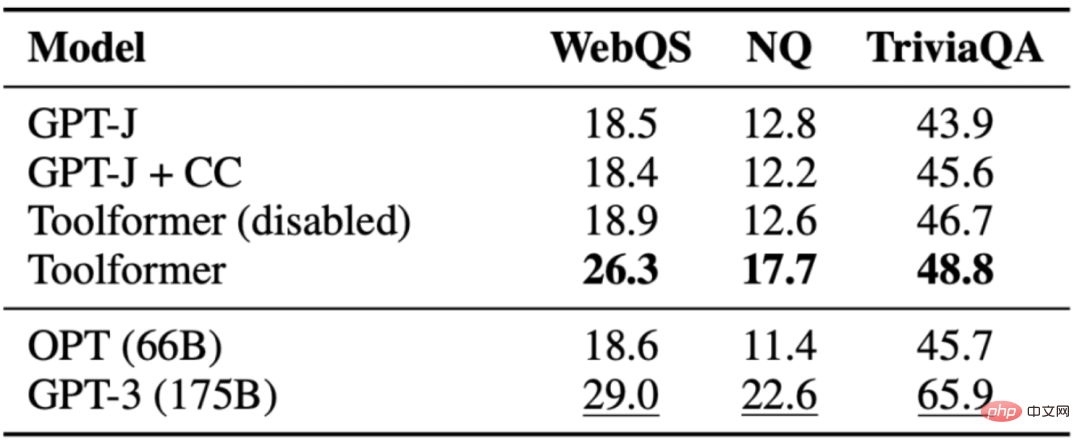
3.4 Mehrsprachige Fragebeantwortung
Der Frage-Antwort-Datensatz wird für den mehrsprachigen Frage-Antwort-Benchmark MLQA verwendet, der englische Kontextabsätze und Arabisch enthält. Deutsch, Spanisch, Hindi, Vietnamesisch oder vereinfachtes Chinesisch. Toolformer ist hier nicht der leistungsstärkste, was wahrscheinlich daran liegt, dass CCNet nicht alle Sprachen optimiert.
Die folgende Tabelle zeigt die Ergebnisse, die durch den API-Aufruf des Wikipedia-Suchtools erhalten wurden:
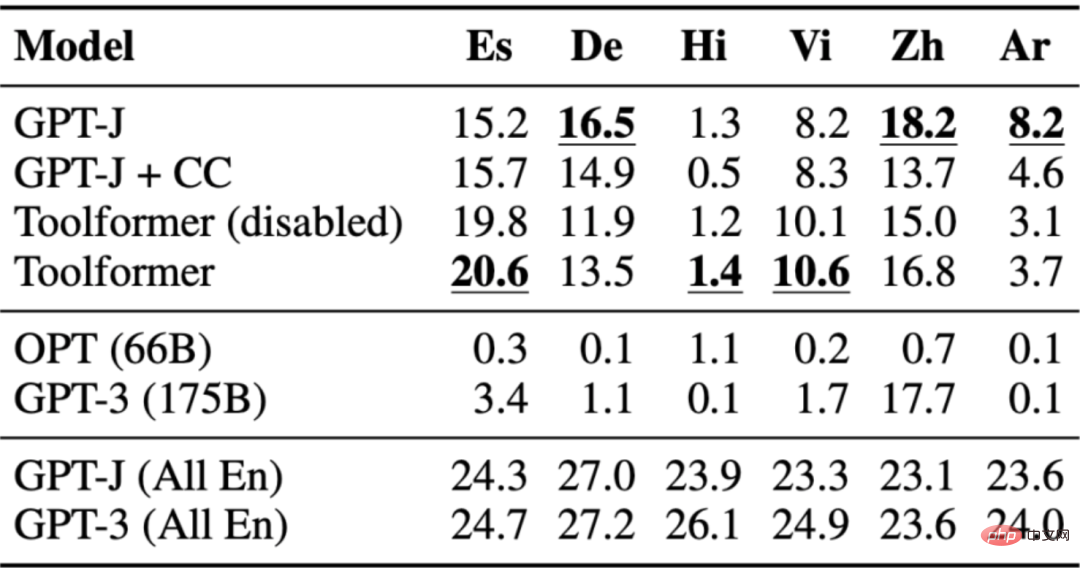
3.5 Zeitdatensatz
Die Aufgabe besteht darin, zu verstehen, wo das aktuelle Datum für die Beantwortung der Frage entscheidend ist. Toolformer konnte die Basisversion übertreffen, nutzte das Kalendertool jedoch offensichtlich nicht zu 100 % aus. Stattdessen wird eine Wikipedia-Suche verwendet. Die folgende Tabelle zeigt die durch den API-Aufruf des Wikipedia-Suchtools erhaltenen Ergebnisse:
4 Einschränkungen von ToolFormer
Toolformer weist immer noch einige Einschränkungen auf, z. B. die Unfähigkeit, mehrere Tools gleichzeitig zu verwenden zu viele zurückgegebene Ergebnisse zu verarbeiten, Empfindlichkeit gegenüber Eingabeformulierungen, die zu Ineffizienz führt, Nichtberücksichtigung der Nutzungskosten, die zu hohen Rechenkosten führen können, und andere Probleme. Die Details sind wie folgt:
- Da die API-Aufrufe für jedes Tool unabhängig generiert werden, kann Toolformer nicht mehrere Tools in einem Prozess verwenden.
- Insbesondere für Tools, die möglicherweise Hunderte verschiedener Ergebnisse liefern (z. B. Suchmaschinen), kann Toolformer nicht interaktiv verwendet werden.
- Mit Toolformer trainierte Modelle reagieren sehr empfindlich auf den genauen Wortlaut der Eingabe. Dieser Ansatz ist für einige Tools ineffizient und erfordert eine umfangreiche Dokumentation, um eine kleine Anzahl nützlicher API-Aufrufe zu generieren.
- Bei der Entscheidung, jedes Tool zu verwenden, werden die Kosten für die Verwendung nicht berücksichtigt, was zu höheren Rechenkosten führen kann.
5. Zusammenfassung
Toolformer ist ein umfangreiches Sprachmodell, das In-Context Learning verwendet, um das Modellverständnis zu verbessern und eine für einen bestimmten Kontext geeignete Sprache zu generieren Situation. Fähigkeit. Es verwendet API-Aufrufe, um große Datenmengen mit Anmerkungen zu versehen, und verwendet diese API-Aufrufe dann, um das Modell zu optimieren, um nützliche API-Aufrufe durchzuführen. Toolformer lernt vorherzusagen, welches Werkzeug für welche Aufgabe verwendet wird. Toolformer weist jedoch immer noch einige Einschränkungen auf, z. B. die Unfähigkeit, mehrere Tools in einem Prozess zu verwenden, und die Unfähigkeit, Tools interaktiv zu verwenden, die möglicherweise Hunderte verschiedener Ergebnisse liefern.
【Referenzen und verwandte Lektüre】
- Toolformer: Sprachmodelle können sich selbst den Umgang mit Werkzeugen beibringen, https://arxiv.org/pdf/2302.04761
- Metas Toolformer nutzt APIs, um GPT-3 bei Zero-Shot-NLP-Aufgaben zu übertreffen, https://www.infoq.com/news/2023/04/meta-toolformer/ # 🎜 🎜#Toolformer: Sprachmodelle können sich selbst den Umgang mit Werkzeugen beibringen (2023), https://kikaben.com/toolformer-2023/
- Breaking Down Toolformer, https://www.shaped.ai / blog/breaking-down-toolformer
- Toolformer: Meta nimmt erneut am ChatGPT-Rennen mit einem neuen Modell unter Verwendung von Wikipedia teil, https://thechainsaw.com/business/meta-toolformer-ai/#🎜 🎜 #
- Das Toolformer-Sprachmodell verwendet externe Tools selbst #
Das obige ist der detaillierte Inhalt vonToolformer interpretieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
