

Zusammenfassung von acht Zeitreihenklassifizierungsmethoden

Die Klassifizierung von Zeitreihen ist eine der häufigsten Aufgaben, bei denen maschinelle und Deep-Learning-Modelle angewendet werden. In diesem Artikel werden 8 Arten von Zeitreihenklassifizierungsmethoden behandelt. Dies reicht von einfachen distanz- oder margenbasierten Methoden bis hin zu Methoden, die tiefe neuronale Netze nutzen. Dieser Artikel soll als Referenzartikel für alle Zeitreihenklassifizierungsalgorithmen dienen.
Zeitreihendefinition
Bevor wir verschiedene Arten von Zeitreihenklassifizierungsmethoden (TS) behandeln, vereinheitlichen wir zunächst das Konzept der Zeitreihen. TS kann als univariate oder multivariate TS klassifiziert werden.
- Ein univariater TS ist eine geordnete Menge (normalerweise) reeller Werte.
- Multivariate TS ist eine Menge univariater TS. Jeder Zeitstempel ist ein Vektor oder Array realer Werte.
Ein Datensatz einzelner oder multivariater TS enthält normalerweise einen geordneten Satz einzelner oder multivariater TS. Darüber hinaus enthalten Datensätze normalerweise einen durch eine einzelne Kodierung repräsentierten Label-Vektor, dessen Länge die Labels verschiedener Klassen repräsentiert.
Das Ziel der TS-Klassifizierung wird durch das Training eines beliebigen Klassifizierungsmodells anhand eines bestimmten Datensatzes definiert, damit das Modell die Wahrscheinlichkeitsverteilung des bereitgestellten Datensatzes lernen kann. Das heißt, das Modell sollte lernen, Klassenbezeichnungen korrekt zuzuweisen, wenn ein TS gegeben wird.
Entfernungsbasierte Methoden
Entfernungs- oder nächster Nachbar-basierte TS-Klassifizierungsmethoden verwenden verschiedene entfernungsbasierte Metriken, um die gegebenen Daten zu klassifizieren. Es handelt sich um eine überwachte Lerntechnik, bei der das Vorhersageergebnis eines neuen TS von den Labelinformationen der bekannten Zeitreihe abhängt, der es am ähnlichsten ist.
Eine Distanzmetrik ist eine Funktion, die den Abstand zwischen zwei oder mehr Zeitreihen beschreibt und maßgebend ist. Typische Entfernungsmaße sind:
- p-Norm (z. B. Manhattan-Entfernung, euklidische Entfernung usw.)
- Dynamic Time Warping (DTW)
Nach der Entscheidung über die Metrik wird normalerweise der KNN-Algorithmus (k-Nearest Neighbor) verwendet angewendet, wobei der Algorithmus den Abstand zwischen dem neuen TS und allen TSs im Trainingsdatensatz misst. Nachdem Sie alle Entfernungen berechnet haben, wählen Sie die k nächstgelegenen aus. Abschließend wird der neue TS der Klasse zugeordnet, zu der die Mehrheit der k nächsten Nachbarn gehören.
Während die beliebtesten Normen definitiv p-Normen sind, insbesondere die euklidische Distanz, haben sie zwei Hauptnachteile, die sie für TS-Klassifizierungsaufgaben weniger geeignet machen. Da die Norm nur für zwei TS gleicher Länge definiert ist, ist es in der Praxis nicht immer möglich, Folgen gleicher Länge zu erhalten. Die Norm vergleicht nur zwei TS-Werte zu jedem Zeitpunkt unabhängig voneinander, die meisten TS-Werte sind jedoch miteinander korreliert.
Und DTW kann die beiden Einschränkungen der p-Norm lösen. Das klassische DTW minimiert den Abstand zwischen zwei Zeitreihenpunkten, deren Zeitstempel unterschiedlich sein können. Dies bedeutet, dass leicht verschobene oder verzerrte TS immer noch als ähnlich angesehen werden. Die folgende Abbildung veranschaulicht den Unterschied zwischen p-normbasierten Metriken und der Funktionsweise von DTW.
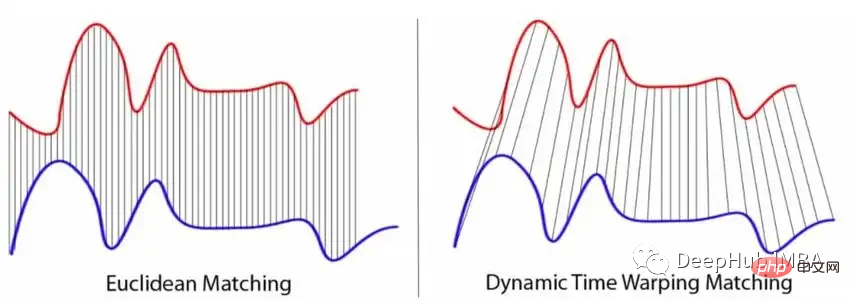
In Kombination mit KNN wird DTW als Basisalgorithmus für verschiedene Benchmark-Bewertungen der TS-Klassifizierung verwendet.
KNN kann auch mithilfe einer Entscheidungsbaummethode implementiert werden. Der Nachbarwaldalgorithmus modelliert beispielsweise einen Wald aus Entscheidungsbäumen, der Distanzmaße zur Partitionierung von TS-Daten verwendet.
Intervall- und frequenzbasierte Methoden
Intervallbasierte Methoden teilen den TS normalerweise in mehrere verschiedene Intervalle auf. Jede Teilsequenz wird dann verwendet, um einen separaten Klassifikator für maschinelles Lernen (ML) zu trainieren. Es wird eine Reihe von Klassifikatoren generiert, wobei jeder Klassifikator auf sein eigenes Intervall einwirkt. Die Berechnung der häufigsten Klasse unter separat klassifizierten Teilreihen ergibt die endgültige Bezeichnung für die gesamte Zeitreihe.
Time Series Forest
Der bekannteste Vertreter des intervallbasierten Modells ist der Time Series Forest. Ein TSF ist eine Sammlung von Entscheidungsbäumen, die auf zufälligen Teilsequenzen des anfänglichen TS basieren. Jeder Baum ist für die Zuordnung einer Klasse zu einem Bereich verantwortlich.
Dies erfolgt durch die Berechnung zusammenfassender Merkmale (normalerweise Mittelwert, Standardabweichung und Steigung), um für jedes Intervall einen Merkmalsvektor zu erstellen. Entscheidungsbäume werden dann auf der Grundlage der berechneten Merkmale trainiert und Vorhersagen werden durch Mehrheitsabstimmung aller Bäume erhalten. Der Abstimmungsprozess ist notwendig, da jeder Baum nur eine bestimmte Teilsequenz des anfänglichen TS auswertet.
Neben TSF gibt es noch weitere intervallbasierte Modelle. Varianten von TSF nutzen zusätzliche Merkmale wie Median, Interquartilbereich, Minimal- und Maximalwerte der Unterreihen. Im Vergleich zum klassischen TSF-Algorithmus gibt es einen recht komplexen Algorithmus namens Random Interval Spectral Ensemble (RISE)-Algorithmus. Der
RISE
RISE-Algorithmus unterscheidet sich vom klassischen TS-Wald in zwei Aspekten.
- Jeder Baum verwendet ein einzelnes TS-Intervall
- Es wird trainiert, indem Spektralmerkmale verwendet werden, die aus dem TS extrahiert wurden (anstatt zusammenfassende Statistiken wie Mittelwert, Steigung usw. zu verwenden).
Bei der RISE-Technik bauen alle Entscheidungsbäume auf ein anderer Satz von Fourier-, Autokorrelations-, autoregressiven und partiellen Autokorrelationsmerkmalen. Der Algorithmus funktioniert wie folgt:
Wählen Sie die ersten zufälligen Intervalle von TS aus und berechnen Sie die oben genannten Merkmale für diese Intervalle. Anschließend wird durch Kombinieren der extrahierten Features ein neuer Trainingssatz erstellt. Darauf aufbauend wird ein Entscheidungsbaumklassifikator trainiert. Diese Schritte werden schließlich mit unterschiedlichen Konfigurationen wiederholt, um ein Ensemblemodell zu erstellen, bei dem es sich um eine zufällige Gesamtstruktur eines einzelnen Entscheidungsbaumklassifikators handelt.
Wörterbuchbasierte Methode
Der wörterbuchbasierte Algorithmus ist eine andere Art von TS-Klassifikator, der auf der Struktur des Wörterbuchs basiert. Sie decken eine Vielzahl verschiedener Klassifikatoren ab und können teilweise in Kombination mit den oben genannten Klassifikatoren verwendet werden. B OSS
Randomized BOSS
- WEASEL
- Diese Art von Methode wandelt TS normalerweise zunächst in eine Symbolsequenz um und extrahiert daraus „WÖRTER“ über ein Schiebefenster. Die endgültige Klassifizierung erfolgt dann durch die Bestimmung der Verteilung der „WÖRTER“, was üblicherweise durch Zählen und Sortieren der „WÖRTER“ erfolgt. Die Theorie hinter diesem Ansatz ist, dass Zeitreihen ähnlich sind, das heißt, sie gehören zur gleichen Klasse, wenn sie ähnliche „WÖRTER“ enthalten. Der Hauptprozess wörterbuchbasierter Klassifikatoren ist normalerweise derselbe.
- Führen Sie ein Schiebefenster mit einer bestimmten Länge auf dem TS aus.
- Konvertieren Sie jede Teilsequenz in „WÖRTER“ (mit einer bestimmten Länge und einem festen Satz von Buchstaben).
- Erstellen Sie diese Histogramme.
- Hier sind die beliebtesten ones Liste wörterbuchbasierter Klassifikatoren:
- Die gebräuchlichste Technik zum Erstellen von Wörtern aus Zahlen (hier rohe TS) heißt Symbolic Aggregation Approximation (SAX). Der TS wird zunächst in verschiedene Blöcke unterteilt, jeder Block wird dann normalisiert, d. h. er hat einen Mittelwert von 0 und eine Standardabweichung von 1. Normalerweise ist die Länge eines Wortes länger als die Anzahl der realen Werte in der Teilfolge. Daher wird das Binning weiter auf jeden Block angewendet. Anschließend wird der durchschnittliche tatsächliche Wert für jede Klasse berechnet und einem Buchstaben zugeordnet. Beispielsweise wird allen Werten unter -1 der Buchstabe „a“ zugewiesen, allen Werten über –1 und unter 1 der Buchstabe „b“ und allen Werten über 1 der Buchstabe „c“. Das Bild unten veranschaulicht diesen Vorgang.
- Hier enthält jedes Segment 30 Werte, die in 6er-Gruppen unterteilt sind, und jeder Gruppe werden drei mögliche Buchstaben zugewiesen, um ein Wort mit fünf Buchstaben zu bilden. Die Häufigkeit des Vorkommens jedes Wortes wird abschließend zusammengefasst und zur Klassifizierung verwendet, indem es in den Algorithmus für den nächsten Nachbarn eingefügt wird.
Symbolische Fourier-Approximation
Im Gegensatz zur Idee des obigen BOP-Algorithmus, bei dem der ursprüngliche TS in Buchstaben und dann in Wörter diskretisiert wird, kann ein ähnlicher Ansatz auf die Fourier-Koeffizienten des TS angewendet werden.
Der bekannteste Algorithmus ist die Symbolische Fourier-Approximation (SFA), die in zwei Teile unterteilt werden kann.
Berechnen Sie die diskrete Fourier-Transformation von TS und behalten Sie dabei eine Teilmenge der berechneten Koeffizienten bei.
Überwacht: Die univariate Merkmalsauswahl wird verwendet, um höherrangige Koeffizienten basierend auf Statistiken (z. B. F-Statistik oder χ2-Statistik) auszuwählen.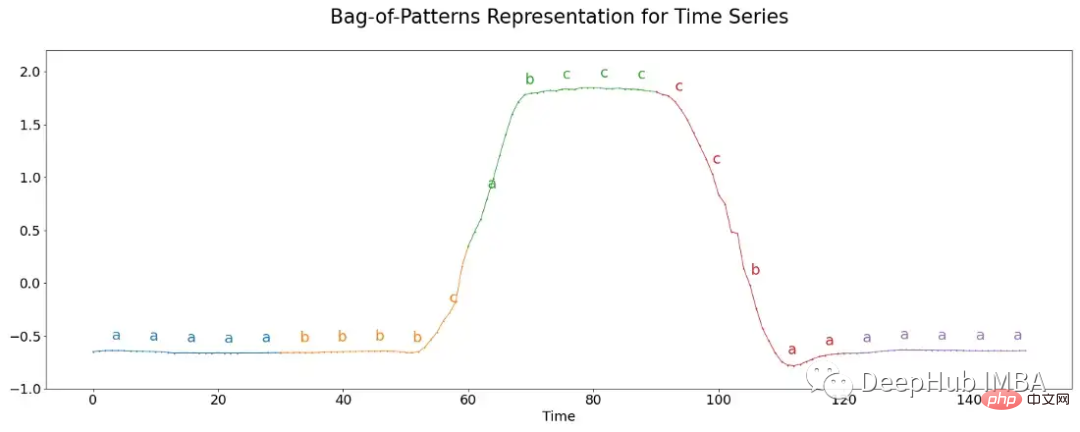 Unüberwacht: Nimmt normalerweise eine Teilmenge des ersten Koeffizienten, die den Trend von TS darstellt
Unüberwacht: Nimmt normalerweise eine Teilmenge des ersten Koeffizienten, die den Trend von TS darstellt
Überwachung: Berechnen Sie Binning-Kanten so, dass das Verunreinigungskriterium der Instanzentropie minimiert wird.
Unüberwacht: Berechnen Sie die Klassenkanten basierend auf den Extremwerten der Fourier-Koeffizienten (die Klassen sind einheitlich) oder basierend auf deren Quantilen (die gleiche Anzahl von Koeffizienten in jeder Klasse)
Basierend auf der Voreinstellung oben Verarbeitung: Zur weiteren Verarbeitung der Informationen können verschiedene Algorithmen verwendet werden, um Vorhersagen für TS zu erhalten.- BOSS
- Bag-of-SFA-Symbols (BOSS)-Algorithmus funktioniert wie folgt:
Extrahiert Teilsequenzen von TS durch einen Schiebefenstermechanismus.
- Wende SFA-Transformation auf jedes Fragment an und gebe einen geordneten Satz von Wörtern zurück.
- berechne die Häufigkeit jedes Wortes, wodurch ein Histogramm von TS-Wörtern
- erstellt wird, die durch die Anwendung von Algorithmen wie KNN in Kombination mit einer benutzerdefinierten BOSS-Metrik (kleine Änderungen im euklidischen Abstand) klassifiziert werden.
- BOSS im Vektorraum
- Der Algorithmus „BOSS im Vektorraum“ (BOSSVS) ist eine Variante der individuellen BOSS-Methode unter Verwendung des Vektorraummodells, das ein Histogramm für jede Klasse berechnet und die Termfrequenz-inverse Dokumenthäufigkeit (TF-IDF) berechnet ) Matrix. Die Klassifizierung wird dann erhalten, indem die Klasse mit der höchsten Kosinusähnlichkeit zwischen dem TF-IDF-Vektor jeder Klasse und dem Histogramm des TS selbst ermittelt wird.
- Es können Shapelets erhalten werden, die nicht im Trainingssatz enthalten sind, aber für Kategorien stark diskriminierend sind.
- Der Algorithmus muss nicht auf dem gesamten Datensatz ausgeführt werden, was die Trainingszeit erheblich verkürzen kann
- Multi-Layer Perceptron
- Fully Convolutional NN (CNN)
- Echo -State Networks (basierend auf wiederkehrenden NNs)
- Encoder
- Multi-Scale Deep CNN
- Time CNN
Contractable BOSS
Der Contractable BOSS (cBOSS)-Algorithmus ist rechnerisch viel schneller als die klassische BOSS-Methode.
Eine Beschleunigung wird dadurch erreicht, dass nicht eine Rastersuche für den gesamten Parameterraum, sondern für zufällig ausgewählte Stichproben daraus durchgeführt wird. cBOSS verwendet eine Teilstichprobe der Daten für jeden Basisklassifikator. cBOSS verbessert die Speichereffizienz, indem es nur eine feste Anzahl der besten Basisklassifikatoren berücksichtigt und nicht alle Klassifikatoren über einem bestimmten Leistungsschwellenwert.
Randomized BOSS
Die nächste Variante des BOSS-Algorithmus ist Randomized BOSS (RBOSS). Diese Methode fügt einen stochastischen Prozess bei der Auswahl der Schiebefensterlänge hinzu und aggregiert geschickt die Vorhersagen einzelner BOSS-Klassifikatoren. Dies ähnelt der cBOSS-Variante und reduziert die Rechenzeit bei gleichzeitiger Beibehaltung der Grundleistung.
WEASE
Der TS Classifier Extraction (WEASEL)-Algorithmus kann die Leistung der Standard-BOSS-Methode verbessern, indem er Schiebefenster unterschiedlicher Länge in der SFA-Transformation verwendet. Ähnlich wie andere BOSS-Varianten verwendet es Fenstergrößen unterschiedlicher Länge, um TS in Merkmalsvektoren umzuwandeln, die dann von einem KNN-Klassifikator ausgewertet werden.
WEASEL verwendet eine spezielle Methode zur Merkmalsableitung, bei der nur nicht überlappende Teilsequenzen jedes Schiebefensters verwendet werden, indem ein χ2-Test angewendet und die relevantesten Merkmale herausgefiltert werden.
Kombinieren Sie WEASEL mit Multivariate Unsupervised Symbols (WEASEL+MUSE), um multivariate Features aus TS zu extrahieren und zu filtern, indem Sie Kontextinformationen in jedes Feature kodieren.
Shapelet-basierte Methode
Die Shapelet-basierte Methode nutzt die Idee von Teilsequenzen der anfänglichen Zeitreihe (d. h. Shapelets). Shapelets werden ausgewählt, um sie als Repräsentanten von Klassen zu verwenden, was bedeutet, dass Shapelets die Hauptmerkmale einer Klasse enthalten, die zur Unterscheidung verschiedener Klassen verwendet werden können. Im optimalen Fall können sie lokale Ähnlichkeiten zwischen TS innerhalb derselben Klasse erkennen.
Die Abbildung unten zeigt ein Beispiel für ein Shapelet. Es ist nur eine Teilsequenz des gesamten TS.
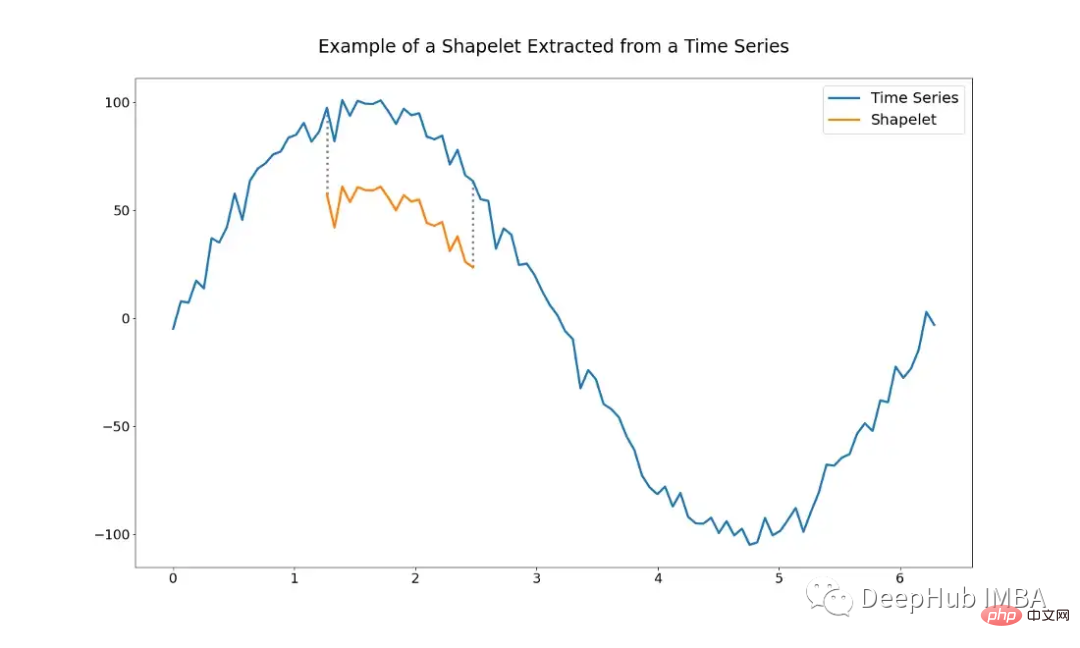
Die Verwendung von Shapelets-basierten Algorithmen erfordert das Problem, zu bestimmen, welche Shapelets verwendet werden sollen. Es ist möglich, von Hand einen Satz Shapelets auszuwählen, dies kann jedoch sehr schwierig sein. Shapelets können mithilfe verschiedener Algorithmen auch automatisch ausgewählt werden.
Algorithmus basierend auf der Shapelet-Extraktion
Shapelet Transform ist ein Algorithmus, der auf der Shapelet-Extraktion basiert und von Lines et al. vorgeschlagen wurde. Es ist einer der derzeit am häufigsten verwendeten Algorithmen. Bei einem TS von n reellwertigen Beobachtungen wird ein Shapelet durch eine Teilmenge von TS der Länge l definiert.
Der Mindestabstand zwischen einem Shapelet und dem gesamten TS kann mithilfe des euklidischen Abstands – oder einer anderen Abstandsmetrik – als Abstand zwischen dem Shapelet selbst und allen Shapelets der Länge l ausgehend vom TS gemessen werden.
Dann wählt der Algorithmus die k besten Shapelets aus, deren Längen in einem bestimmten Bereich liegen. Dieser Schritt kann als eine Art univariate Merkmalsextraktion betrachtet werden, wobei jedes Merkmal durch den Abstand zwischen dem Shapelet und allen TS im gegebenen Datensatz definiert wird. Die Shapelets werden dann anhand einiger Statistiken eingestuft. Dabei handelt es sich in der Regel um F-Statistiken oder χ²-Statistiken, die Shapelets nach ihrer Fähigkeit zur Klassenunterscheidung einordnen.
Nach Abschluss der oben genannten Schritte kann jede Art von ML-Algorithmus angewendet werden, um den neuen Datensatz zu klassifizieren. Zum Beispiel knn-basierte Klassifikatoren, Support-Vektor-Maschinen oder Random Forests usw.
Ein weiteres Problem bei der Suche nach idealen Shapelets ist die schreckliche Zeitkomplexität, die mit der Anzahl der Trainingsbeispiele exponentiell zunimmt.
Shapelet-lernbasierter Algorithmus
Shapelet-lernbasierter Algorithmus versucht, die Einschränkungen von Algorithmen zu überwinden, die auf Shapelet-Extraktion basieren. Die Idee besteht darin, eine Reihe von Shapelets zu erlernen, die in der Lage sind, Klassen zu unterscheiden, anstatt sie direkt aus einem bestimmten Datensatz zu extrahieren.
Dies hat zwei Hauptvorteile:
Aber dieser Ansatz weist auch einige Nachteile auf, die durch die Verwendung einer differenzierbaren Minimierungsfunktion und des gewählten Klassifikators verursacht werden.
Um den euklidischen Abstand zu ersetzen, müssen wir uns auf differenzierbare Funktionen verlassen, sodass Shapelets über Gradientenabstiegs- oder Backpropagation-Algorithmen gelernt werden können. Am gebräuchlichsten ist die Funktion LogSumExp, die das Maximum durch Logarithmusbildung der Summe der Exponenten ihrer Argumente sanft annähert. Da die LogSumExp-Funktion nicht streng konvex ist, konvergiert der Optimierungsalgorithmus möglicherweise nicht korrekt, was zu schlechten lokalen Minima führen kann.
Und da der Optimierungsprozess selbst die Hauptkomponente des Algorithmus ist, müssen zur Optimierung mehrere Hyperparameter hinzugefügt werden.
Aber diese Methode ist in der Praxis sehr nützlich und kann einige neue Erkenntnisse über die Daten generieren.
Kernelbasierter Ansatz
Eine leichte Variation des Shapelet-basierten Algorithmus ist der Kernel-basierte Algorithmus. Lernen und verwenden Sie zufällige Faltungskerne (den gebräuchlichsten Computer-Vision-Algorithmus), die Merkmale aus einem bestimmten TS extrahieren.
Der ROCKET-Algorithmus (Random Convolution Kernel Transform) wurde speziell für diesen Zweck entwickelt. . Es verwendet eine große Anzahl von Kerneln, die sich in Länge, Gewicht, Bias, Dilatation und Padding unterscheiden und zufällig aus einer festen Verteilung erstellt werden.
Nach der Auswahl des Kernels benötigen Sie außerdem einen Klassifikator, der die relevantesten Merkmale zur Unterscheidung von Klassen auswählen kann. In der Originalarbeit wurde die Ridge-Regression (eine L2-regulierte Variante der linearen Regression) verwendet, um Vorhersagen zu treffen. Die Verwendung bietet zwei Vorteile: erstens die Recheneffizienz, selbst bei Klassifizierungsproblemen mit mehreren Klassen, und zweitens die Einfachheit der Feinabstimmung einzigartiger Regularisierungshyperparameter mithilfe der Kreuzvalidierung.
Einer der Hauptvorteile der Verwendung von Kernel-basierten Algorithmen oder ROCKET-Algorithmen besteht darin, dass der Rechenaufwand für deren Verwendung recht gering ist.
Merkmalsbasierte Methoden
Merkmalsbasierte Methoden können im Allgemeinen die meisten Algorithmen abdecken, die eine Art Merkmalsextraktion für eine bestimmte Zeitreihe verwenden, und Vorhersagen werden dann von einem Klassifizierungsalgorithmus durchgeführt.
Über Features, von einfachen statistischen Features bis hin zu komplexeren Fourier-basierten Features. Eine große Anzahl solcher Funktionen ist in hctsa (https://github.com/benfulcher/hctsa) zu finden, aber das Ausprobieren und Vergleichen der einzelnen Funktionen kann eine unmögliche Aufgabe sein, insbesondere bei größeren Datensätzen. Daher wurde der typische Algorithmus für Zeitreihenmerkmale (catch22) vorgeschlagen.
catch22-Algorithmus
Diese Methode zielt darauf ab, einen kleinen TS-Funktionssatz abzuleiten, der nicht nur eine starke Klassifizierungsleistung erfordert, sondern auch die Redundanz weiter minimiert. Catch22 hat insgesamt 22 Features aus der hctsa-Bibliothek ausgewählt (die Bibliothek bietet mehr als 4000 Features).
Die Entwickler dieser Methode erhielten 22 Funktionen, indem sie verschiedene Modelle auf 93 verschiedenen Datensätzen trainierten und die leistungsstärksten TS-Funktionen darauf bewerteten, was zu einer kleinen Teilmenge führte, die immer noch eine hervorragende Leistung beibehielt. Der darauf befindliche Klassifikator kann frei gewählt werden, was ihn zu einem weiteren zu optimierenden Hyperparameter macht.
Matrix Profile Classifier
Ein weiterer funktionsbasierter Ansatz ist der Matrix Profile (MP)-Klassifikator, ein MP-basierter interpretierbarer TS-Klassifikator, der interpretierbare Ergebnisse liefern und gleichzeitig die Basisleistung beibehalten kann.
Die Designer extrahierten ein Modell namens Matrix Profile aus einem Shapelet-basierten Klassifikator. Das Modell repräsentiert alle Abstände zwischen einer Teilsequenz eines TS und seinen nächsten Nachbarn. Auf diese Weise kann MP die Merkmale von TS wie Motive und Zwietracht effektiv extrahieren. Motive sind Untersequenzen von TS, die einander sehr ähnlich sind, während Zwietracht Sequenzen beschreibt, die sich voneinander unterscheiden.
Als theoretisches Klassifizierungsmodell kann jedes Modell verwendet werden. Die Entwickler dieser Methode haben sich für Entscheidungsbaumklassifikatoren entschieden.
Zusätzlich zu den beiden genannten Methoden bietet sktime auch einige weitere funktionsbasierte TS-Klassifikatoren.
Model Ensemble
Model Ensemble selbst ist kein unabhängiger Algorithmus, sondern eine Technik, die verschiedene TS-Klassifikatoren kombiniert, um bessere kombinierte Vorhersagen zu erstellen. Modellensembles reduzieren die Varianz durch die Kombination mehrerer Einzelmodelle, ähnlich einem Zufallswald mit einer großen Anzahl von Entscheidungsbäumen. Und die Verwendung verschiedener Arten unterschiedlicher Lernalgorithmen führt zu einem breiteren und vielfältigeren Satz erlernter Merkmale, was wiederum zu einer besseren Klassendiskriminierung führt.
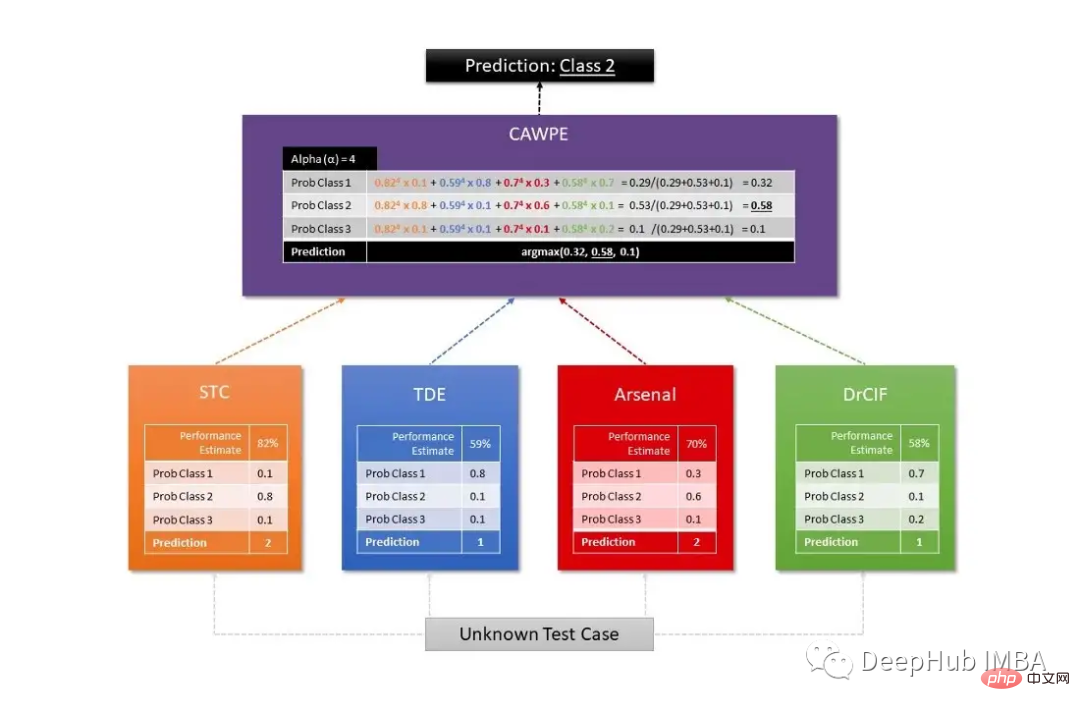
Das beliebteste Modellensemble ist das Hierarchical Vote Collective of Transformation-based Ensembles (HIVE-COTE). Es gibt viele verschiedene Arten ähnlicher Versionen, aber allen gemeinsam ist die Kombination von Informationen aus verschiedenen Klassifikatoren, d. h. Vorhersagen, durch die Verwendung eines gewichteten Durchschnitts für jeden Klassifikator.
Sktime verwendet zwei verschiedene HIVE-COTE-Algorithmen, von denen der erste Wahrscheinlichkeiten pro Schätzer kombiniert, einschließlich eines Shapelet Transform Classifier (STC), eines TS Forest, eines RISE und eines cBOSS. Der zweite wird durch eine Kombination aus STC, Diverse Canonical Interval Forest Classifier (DrCIF, eine Variante von TS Forest), Arsenal (eine Sammlung von ROCKET-Modellen) und TDE (eine Variante des BOSS-Algorithmus) definiert.
Die endgültige Vorhersage wird durch den CAWPE-Algorithmus erhalten, der jedem Klassifikator Gewichte zuweist, die anhand der relativen geschätzten Qualität der im Trainingsdatensatz gefundenen Klassifikatoren ermittelt werden.
Die folgende Abbildung ist ein häufig verwendetes Diagramm zur Visualisierung der Arbeitsstruktur des HIVE-COTE-Algorithmus:
Deep-Learning-basierte Methode
Über den Deep-Learning-basierten Algorithmus können Sie einen langen Artikel zur Erläuterung schreiben es selbst Alle Details für jede Architektur. In diesem Artikel werden jedoch nur einige häufig verwendete Benchmark-Modelle und -Techniken für die TS-Klassifizierung vorgestellt.
Während auf Deep Learning basierende Algorithmen in Bereichen wie Computer Vision und NLP sehr beliebt sind und umfassend untersucht werden, sind sie im Bereich der TS-Klassifizierung weniger verbreitet. Fawaz et al. Eine umfassende Untersuchung aktuell vorhandener Methoden in ihrem Artikel über Deep Learning für die TS-Klassifizierung: Zusammenfassung untersuchte mehr als 60 Modelle neuronaler Netzwerke (NN) mit sechs Architekturen:
Die meisten der oben genannten Modelle wurden ursprünglich für verschiedene Anwendungsfälle entwickelt. Daher muss es für verschiedene Anwendungsfälle getestet werden.
Außerdem wurde 2020 das InceptionTime-Netzwerk ins Leben gerufen. InceptionTime ist ein Ensemble aus fünf Deep-Learning-Modellen, von denen jedes von InceptionTime erstellt wurde, das zuerst von Szegedy et al. vorgeschlagen wurde. Diese ersten Module wenden mehrere Filter unterschiedlicher Länge gleichzeitig auf den TS an und extrahieren gleichzeitig relevante Merkmale und Informationen aus kürzeren und längeren Teilsequenzen des TS. Das folgende Bild zeigt das InceptionTime-Modul.
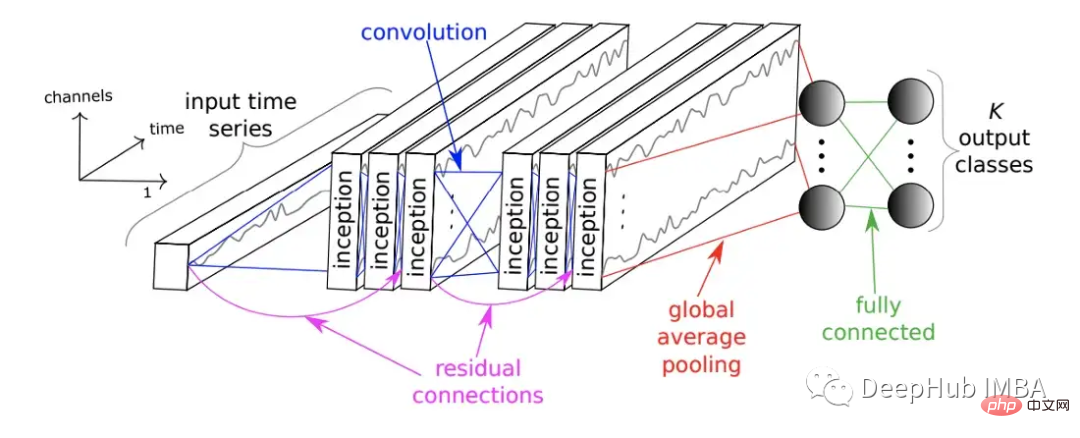
Es besteht aus mehreren Anfangsmodulen, die im Feed-Forward-Verfahren gestapelt und mit den Residuen verbunden sind. Schließlich generieren globale Durchschnittspools und vollständig verbundene neuronale Netze Vorhersageergebnisse.
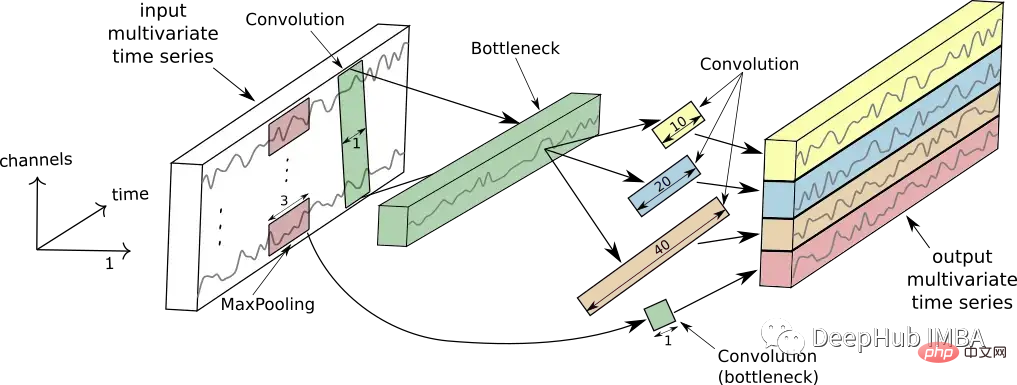
Das Bild unten zeigt die Funktionsweise eines einzelnen Anfangsmoduls.
Zusammenfassung
Die große Liste der in diesem Artikel zusammengefassten Algorithmen, Modelle und Techniken kann nicht nur zum Verständnis des weiten Bereichs der Zeitreihenklassifizierungsmethoden beitragen, ich hoffe auch, dass sie Ihnen hilfreich sein wird
Das obige ist der detaillierte Inhalt vonZusammenfassung von acht Zeitreihenklassifizierungsmethoden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 Wie Debian die Hadoop -Datenverarbeitungsgeschwindigkeit verbessert
Apr 13, 2025 am 11:54 AM
Wie Debian die Hadoop -Datenverarbeitungsgeschwindigkeit verbessert
Apr 13, 2025 am 11:54 AM
In diesem Artikel wird erläutert, wie die Effizienz der Hadoop -Datenverarbeitung auf Debian -Systemen verbessert werden kann. Optimierungsstrategien decken Hardware -Upgrades, Parameteranpassungen des Betriebssystems, Änderungen der Hadoop -Konfiguration und die Verwendung effizienter Algorithmen und Tools ab. 1. Hardware -Ressourcenverstärkung stellt sicher, dass alle Knoten konsistente Hardwarekonfigurationen aufweisen, insbesondere die Aufmerksamkeit auf die Leistung von CPU-, Speicher- und Netzwerkgeräten. Die Auswahl von Hochleistungs-Hardwarekomponenten ist wichtig, um die Gesamtverarbeitungsgeschwindigkeit zu verbessern. 2. Betriebssystem -Tunes -Dateideskriptoren und Netzwerkverbindungen: Ändern Sie die Datei /etc/security/limits.conf, um die Obergrenze der Dateideskriptoren und Netzwerkverbindungen zu erhöhen, die gleichzeitig vom System geöffnet werden dürfen. JVM-Parameteranpassung: Einstellen in der Hadoop-env.sh-Datei einstellen
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 So verwenden Sie NGINX -Protokolle, um die Geschwindigkeit der Website zu verbessern
Apr 13, 2025 am 09:09 AM
So verwenden Sie NGINX -Protokolle, um die Geschwindigkeit der Website zu verbessern
Apr 13, 2025 am 09:09 AM
Die Optimierung der Website-Leistungsoptimierung ist untrennbar mit einer detaillierten Analyse von Zugriffsprotokollen untrennwillig. NGINX -Protokoll zeichnet die detaillierten Informationen von Benutzern auf, die die Website besuchen. Wenn Sie diese Daten geschickt verwenden, können Sie die Geschwindigkeit der Website effektiv verbessern. In diesem Artikel werden mehrere Methoden zur Optimierungsoptimierungsmethoden für Website -Leistungsoptimierung vorgestellt. 1. Benutzerverhaltensanalyse und Optimierung. Durch die Analyse des NGINX-Protokolls können wir ein tiefes Verständnis des Benutzerverhaltens erlangen und gezielte Optimierung basierend auf diesem: Hochfrequenzzugriffs-IP-Identifizierung durchführen: Suchen Sie die IP-Adresse mit der höchsten Zugriffsfrequenz und optimieren Sie die Serverressourcenkonfiguration für diese IP-Adressen, z. B. die Erhöhung der Bandbreite oder die Verbesserung der Antwortgeschwindigkeit des spezifischen Inhalts. Statuscode -Analyse: Analysieren Sie die Häufigkeit verschiedener HTTP -Statuscodes (z. B. 404 Fehler), finden Sie Probleme in der Navigation oder des Inhaltsmanagements auf Website und fahren Sie fort
 So upgraden Sie die Zookeeper -Version auf Debian auf
Apr 13, 2025 am 10:42 AM
So upgraden Sie die Zookeeper -Version auf Debian auf
Apr 13, 2025 am 10:42 AM
Das Upgrade der Zookeeper -Version auf Debian -System kann die folgenden Schritte ausführen: 1. Wenn Sie die vorhandenen Konfiguration und Daten vor einem Upgrade unterstützen, wird dringend empfohlen, die vorhandenen Zookeeper -Konfigurationsdateien und Datenverzeichnisse zu sichern. sudocp-r/var/lib/zookeeper/var/lib/zookeper_backupsudocp/etc/zookeper/conf/zoo.cfg/etc/zookeeper/conf/zookeeper/z
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
 Wie man Pakete recyceln, die nicht mehr verwendet werden
Apr 13, 2025 am 08:51 AM
Wie man Pakete recyceln, die nicht mehr verwendet werden
Apr 13, 2025 am 08:51 AM
In diesem Artikel wird beschrieben, wie nutzlose Softwarepakete und der Speicherplatz im Debian -System freigegeben werden können. Schritt 1: Aktualisieren Sie die Paketliste stellen Sie sicher, dass Ihre Paketliste auf dem neuesten Stand ist: sudoaptupdate Schritt 2: Installierte Pakete anzeigen Verwenden Sie den folgenden Befehl, um alle installierten Pakete anzuzeigen: DPKG-Get-Selections | Grep-VDeinstall-Schritt 3: Identifizieren von redundanten Paketen Verwenden Sie das Handwerks-Tool, um nicht benötigte Pakete zu finden, die nicht mehr benötigt werden. Die Eignung wird Vorschläge bereitstellen, mit denen Sie Pakete sicher löschen können: sudoaptitudesearch '~ pimportant' Dieser Befehl listet die Tags auf
