
3. Code-Implementierung" >
pip install pyinstaller
3. Code-Implementierung
 Backend-Entwicklung
Python-Tutorial
Zu stark! Python entwickelt Desktop-Gadgets und lässt den Code die sich wiederholende Arbeit für uns erledigen!
Backend-Entwicklung
Python-Tutorial
Zu stark! Python entwickelt Desktop-Gadgets und lässt den Code die sich wiederholende Arbeit für uns erledigen!
Zu stark! Python entwickelt Desktop-Gadgets und lässt den Code die sich wiederholende Arbeit für uns erledigen!


Die ursprüngliche Absicht, diesen Artikel zu schreiben, entstand aus einer Frage eines Freundes zum Thema „Wie generiert man automatisch eine Pivot-Tabelle mit Python basierend auf der Datenquelle?“ Hinter diesem Problem steckt eine sehr gute Lösungsidee. Lassen Sie den Code die Arbeit für uns erledigen. Erledigen Sie sich wiederholende Arbeiten und reduzieren Sie dadurch die Arbeitsbelastung und die Fehlerquote.
Die von Python entwickelten Gadgets packen Python-Programme tatsächlich in exe, die nach der Freigabe verwendet werden können. Auch wenn die Python-Umgebung nicht auf dem Computer installiert ist, kann sie zur Verbesserung der Arbeitseffizienz und zur Minimierung von Überstunden verwendet werden. ?? zwei Teile Python generiert Pivot-Tabelle und Desktop-GUI-Verknüpfungsdesign
Pakete Python-Programm zum Generieren einer ausführbaren Exe-Datei 
Lösen Sie das Problem, dass die Exe-Datei möglicherweise zu groß ist: Installieren Sie eine virtuelle Umgebung
- 1
- Machen Sie die Arbeit zu einem sich wiederholenden Vorgang. Verwenden Sie die drei Felder Lieferantenname, Monat und Lagermenge, um das gewünschte Pivot-Tabellenformat zu generieren.
-
2. Installieren Sie abhängige Bibliotheken von Drittanbietern. -
Hier verwenden wir tkinter, die Python-eigene GUI-Bibliothek, die nach der Installation verwendet werden kann. pip install tkinter
Nach dem Login kopierenVerwenden Sie pyinsatller, um das Programm in exe zu packen. Der Vorteil besteht darin, dass Sie den gepackten exe-Code nicht direkt an die andere Partei senden können sehr freundlich für diese kleine und leichte Funktion.
pip install pyinstaller
Nach dem Login kopieren
3. Code-Implementierung
pip install pyinstaller
Excel-Datei zum Generieren von Pivot-Tabellen und Filterdaten, Dateiname: excel_to_pivot.py
import pandas as pd
import numpy as np
class ExcelToPivot(object):
def __init__(self, filename, file_path):
self.file_name = filename
self.file_path = file_path
"""
excel自动转透视表功能
返回透视结果
"""
def excel_Pivot(self):
print(self.file_path)
data = pd.read_excel(self.file_path)
data_pivot_table = pd.pivot_table(data, index=['供应商名称', '月份'], values=["入库金额"], aggfunc=np.sum)
return data_pivot_table
"""
按条件筛选,并保存
"""
def select_data(self, name, month):
data_pivot_table = self.excel_Pivot()
data_new = data_pivot_table.query('供应商名称 == ["{}"] & 月份 == {}'.format(name, month))
data_new.to_excel('{}.xlsx'.format(str(self.file_name).split('.')[0]))
return '筛选完成!'
if __name__ == '__main__':
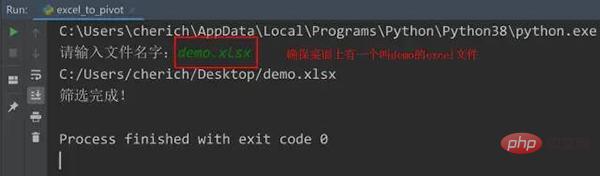
filename = input("请输入文件名字:")
path = 'C:/Users/cherich/Desktop/' + filename
pross = ExcelToPivot(filename, path)
print(pross.select_data("C", 4))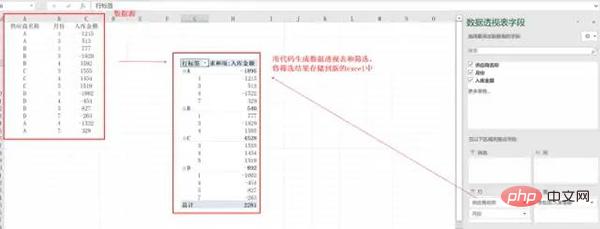
Design-Desktop-Fensterfunktion, Dateiname: operation.py
from tkinter import Tk, Entry, Button, mainloop
import tkinter.filedialog
import excel_to_pivot
from tkinter import messagebox
from tkinter import ttk
def Upload():
global filename, data_pivot_table
try:
filename = tkinter.filedialog.askopenfilename(title='选择文件')
pross = excel_to_pivot.ExcelToPivot(str(filename).split('/')[-1], filename)
data_pivot_table = pross.excel_Pivot()
messagebox.showinfo('Info', '转换成功!')
except Exception as e:
print(e)
messagebox.showinfo('Info', '转换失败!')
def select(name, month):
try:
print('供应商名称 == ["{}"] & 月份 == {}'.format(name, month))
data_new = data_pivot_table.query('供应商名称 == ["{}"] & 月份 == {}'.format(name, month))
data_new.to_excel('{}.xlsx'.format(str(filename).split('.')[0]))
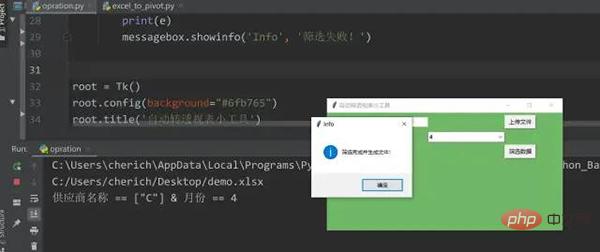
messagebox.showinfo('Info', '筛选完成并生成文件!')
root.destroy()
except Exception as e:
print(e)
messagebox.showinfo('Info', '筛选失败!')
root = Tk()
root.config(background="#6fb765")
root.title('自动转透视表小工具')
root.geometry('500x250')
e1 = Entry(root, width=30)
e1.grid(row=2, column=0)
btn1 = Button(root, text=' 上传文件 ', command=Upload).grid(row=2, column=10, pady=5)
box1 = ttk.Combobox(root)
# 使用 grid() 来控制控件的位置
box1.grid(row=5, sticky="NW")
# 设置下拉菜单中的值
box1['value'] = ('A', 'B', 'C', 'D', '供应商')
# 通过 current() 设置下拉菜单选项的默认值
box1.current(4)
box2 = ttk.Combobox(root)
box2.grid(row=5, column=1, sticky="NW")
box2['value'] = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, '月份')
box2.current(12)
# 编写回调函数,绑定执行事件
def func(event):
global b1, b2
b1 = box1.get()
b2 = box2.get()
# 绑定下拉菜单事件
box1.bind("<<ComboboxSelected>>", func)
box2.bind("<<ComboboxSelected>>", func)
btn2 = Button(root, text=' 筛选数据 ', command=lambda: select(b1, b2)).grid(row=30, column=10, pady=5)
mainloop()Nach dem Login kopieren
from tkinter import Tk, Entry, Button, mainloop
import tkinter.filedialog
import excel_to_pivot
from tkinter import messagebox
from tkinter import ttk
def Upload():
global filename, data_pivot_table
try:
filename = tkinter.filedialog.askopenfilename(title='选择文件')
pross = excel_to_pivot.ExcelToPivot(str(filename).split('/')[-1], filename)
data_pivot_table = pross.excel_Pivot()
messagebox.showinfo('Info', '转换成功!')
except Exception as e:
print(e)
messagebox.showinfo('Info', '转换失败!')
def select(name, month):
try:
print('供应商名称 == ["{}"] & 月份 == {}'.format(name, month))
data_new = data_pivot_table.query('供应商名称 == ["{}"] & 月份 == {}'.format(name, month))
data_new.to_excel('{}.xlsx'.format(str(filename).split('.')[0]))
messagebox.showinfo('Info', '筛选完成并生成文件!')
root.destroy()
except Exception as e:
print(e)
messagebox.showinfo('Info', '筛选失败!')
root = Tk()
root.config(background="#6fb765")
root.title('自动转透视表小工具')
root.geometry('500x250')
e1 = Entry(root, width=30)
e1.grid(row=2, column=0)
btn1 = Button(root, text=' 上传文件 ', command=Upload).grid(row=2, column=10, pady=5)
box1 = ttk.Combobox(root)
# 使用 grid() 来控制控件的位置
box1.grid(row=5, sticky="NW")
# 设置下拉菜单中的值
box1['value'] = ('A', 'B', 'C', 'D', '供应商')
# 通过 current() 设置下拉菜单选项的默认值
box1.current(4)
box2 = ttk.Combobox(root)
box2.grid(row=5, column=1, sticky="NW")
box2['value'] = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, '月份')
box2.current(12)
# 编写回调函数,绑定执行事件
def func(event):
global b1, b2
b1 = box1.get()
b2 = box2.get()
# 绑定下拉菜单事件
box1.bind("<<ComboboxSelected>>", func)
box2.bind("<<ComboboxSelected>>", func)
btn2 = Button(root, text=' 筛选数据 ', command=lambda: select(b1, b2)).grid(row=30, column=10, pady=5)
mainloop()
4. Packen Sie das Python-Programm, um exe zu generieren
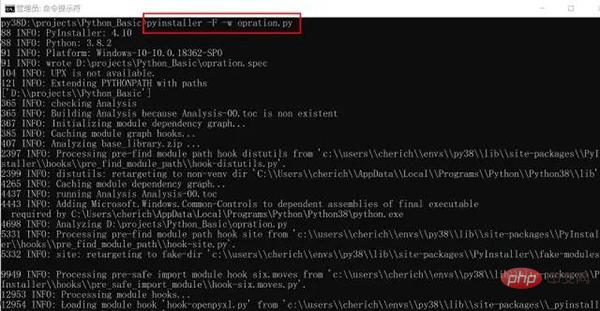
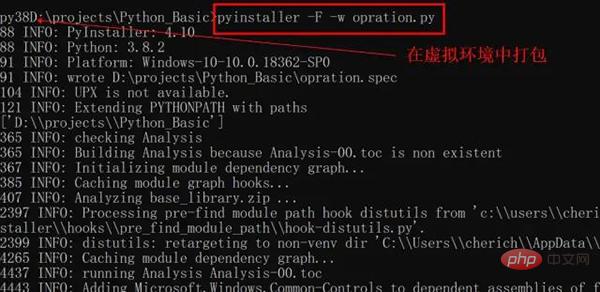
Öffnen Sie das DOS-Fenster und wechseln Sie in das Verzeichnis, in dem sich die beiden py-Dateien befinden. Achten Sie darauf, dass der Pfad keine chinesischen Zeichen enthält.
pyinsatller -F -w opration.py
 -i Der Anwendung ein Symbol hinzufügen
-i Der Anwendung ein Symbol hinzufügen
-F Gibt an, dass nach dem Packen nur eine exe-Formatdatei generiert wird
-D –onedir Erstellen Sie ein Verzeichnis, das exe-Dateien enthält, aber von vielen Dateien abhängt (Standardoption)
-c –console, –nowindowed Konsole verwenden, keine Schnittstelle (Standard)
 -w –windowed, –noconsole Fenster verwenden, nein console
-w –windowed, –noconsole Fenster verwenden, nein console
-p Suchpfad hinzufügen
5. Lösen Sie das Problem, dass die exe-Datei möglicherweise zu groß ist.
Einige Partner haben vor nicht allzu langer Zeit die Python-Umgebung installiert, und dieses Problem, dass die Datei zu groß ist, besteht möglicherweise nicht. Ich habe zum Beispiel viele Abhängigkeitspakete von Python und Anaconda auf meinem Computer installiert. Das Packen dauert sehr lange und bleibt während der Ausführung hängen ist schnell und kann in Sekundenschnelle ausgeführt werden. Die Lösung besteht darin, eine virtuelle Python-Umgebung unter einem Windows-System zu installieren. Die folgenden Vorgänge können nur ausgeführt werden, wenn Python auf dem Computer installiert wurde.
找到 Python 所在路径,如果忘记了,可以在电脑左下角搜索【编辑系统环境变量】——【用户变量】——【PATH】中找到
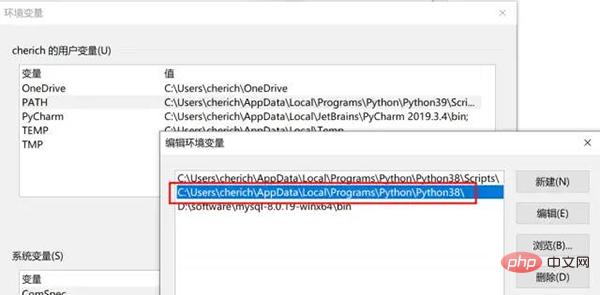
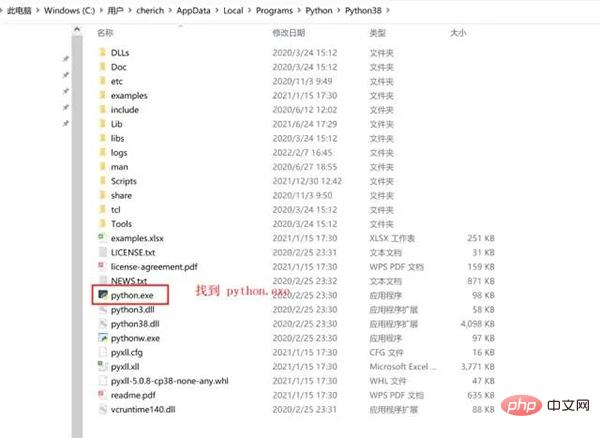
配置虚拟环境
虚拟环境可以理解为是 Python 解释器的一个副本,在这个环境你可以安装私有包,而且不会影响系统中安装的全局 Python 解释器。虚拟环境非常有用,可以在系统的 Python 解释器中避免包的混乱和版本的冲突。
重要是不同虚拟环境可以搭建不同的 Python 版本,创建时候选择,我们这里需要一个相对 "干净" 的 Python 环境,没有安装过多依赖包,避免 exe 打包文件过大,所以用到虚拟环境。
安装虚拟环境依赖包
pip install virtualenv pip install virtualenvwrapper-win
创建虚拟环境命令
mkvirtualenv -p="C:UserscherichAppDataLocalProgramsPythonPython38python.exe" py38
进入虚拟环境,可以看到只有几个默认的 Python 库
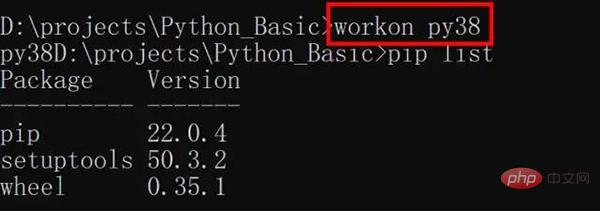
这时可以测试一下代码,是否缺少相关依赖,比如我这个缺少 Pandas,openpyxl,依次按照 pip install 包名安装即可,非常重要的点:pyinstaller 必须重新安装,文件才会缩小。
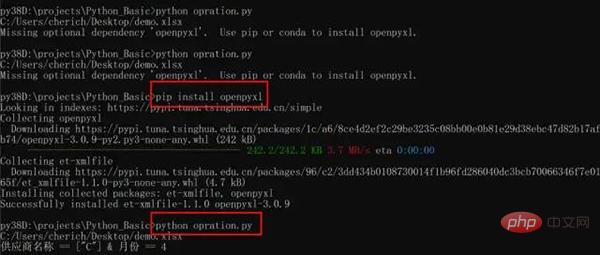
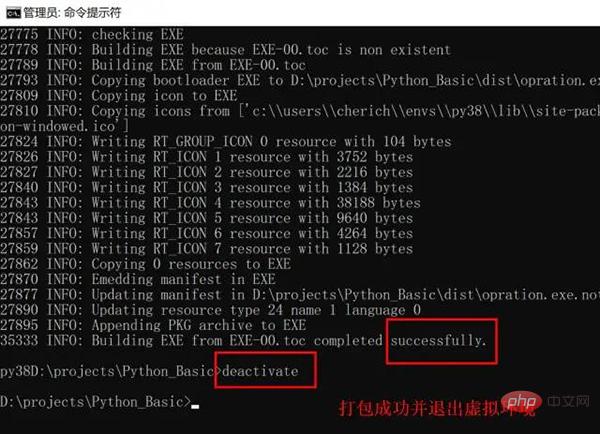
上述操作完成后,打包就可以了,最后退出虚拟环境即可。
退出虚拟环境
deactivate
Das obige ist der detaillierte Inhalt vonZu stark! Python entwickelt Desktop-Gadgets und lässt den Code die sich wiederholende Arbeit für uns erledigen!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Das Erstellen einer Oracle -Datenbank ist nicht einfach, Sie müssen den zugrunde liegenden Mechanismus verstehen. 1. Sie müssen die Konzepte von Datenbank und Oracle DBMS verstehen. 2. Beherrschen Sie die Kernkonzepte wie SID, CDB (Containerdatenbank), PDB (Pluggable -Datenbank); 3.. Verwenden Sie SQL*Plus, um CDB zu erstellen und dann PDB zu erstellen. Sie müssen Parameter wie Größe, Anzahl der Datendateien und Pfade angeben. 4. Erweiterte Anwendungen müssen den Zeichensatz, den Speicher und andere Parameter anpassen und die Leistungsstimmung durchführen. 5. Achten Sie auf Speicherplatz, Berechtigungen und Parametereinstellungen und überwachen und optimieren Sie die Datenbankleistung kontinuierlich. Nur indem Sie es geschickt beherrschen, müssen Sie die Erstellung und Verwaltung von Oracle -Datenbanken wirklich verstehen.
 So sehen Sie sich die Oracle -Datenbank an, wie Sie die Oracle -Datenbank anzeigen
Apr 11, 2025 pm 02:48 PM
So sehen Sie sich die Oracle -Datenbank an, wie Sie die Oracle -Datenbank anzeigen
Apr 11, 2025 pm 02:48 PM
Um Oracle -Datenbanken anzuzeigen, können Sie SQL*Plus (mithilfe von SELECT -Befehlen), SQL Developer (Graphy Interface) oder Systemansicht (Anzeige interner Informationen der Datenbank) verwenden. Die grundlegenden Schritte umfassen eine Verbindung zur Datenbank, das Filtern von Daten mithilfe von Auswahlanweisungen und Optimierung von Abfragen für die Leistung. Darüber hinaus enthält die Systemansicht detaillierte Informationen zur Datenbank, mit denen die Überwachung und Fehlerbehebung beibehalten werden kann. Durch Übung und kontinuierliches Lernen können Sie das Geheimnis der Oracle -Datenbank tief erforschen.
 So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
Um eine Oracle -Datenbank zu erstellen, besteht die gemeinsame Methode darin, das dbca -grafische Tool zu verwenden. Die Schritte sind wie folgt: 1. Verwenden Sie das DBCA -Tool, um den DBNAME festzulegen, um den Datenbanknamen anzugeben. 2. Setzen Sie Syspassword und SystemPassword auf starke Passwörter. 3.. Setzen Sie Charaktere und NationalCharacterset auf AL32UTF8; 4. Setzen Sie MemorySize und tablespacesize, um sie entsprechend den tatsächlichen Bedürfnissen anzupassen. 5. Geben Sie den Logfile -Pfad an. Erweiterte Methoden werden manuell mit SQL -Befehlen erstellt, sind jedoch komplexer und anfällig für Fehler. Achten Sie auf die Kennwortstärke, die Auswahl der Zeichensatz, die Größe und den Speicher von Tabellenräumen
 So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
Der Kern von Oracle SQL -Anweisungen ist ausgewählt, einfügen, aktualisiert und löschen sowie die flexible Anwendung verschiedener Klauseln. Es ist wichtig, den Ausführungsmechanismus hinter der Aussage wie die Indexoptimierung zu verstehen. Zu den erweiterten Verwendungen gehören Unterabfragen, Verbindungsabfragen, Analysefunktionen und PL/SQL. Häufige Fehler sind Syntaxfehler, Leistungsprobleme und Datenkonsistenzprobleme. Best Practices für Leistungsoptimierung umfassen die Verwendung geeigneter Indizes, die Vermeidung von Auswahl *, optimieren Sie, wo Klauseln und gebundene Variablen verwenden. Das Beherrschen von Oracle SQL erfordert Übung, einschließlich des Schreibens von Code, Debuggen, Denken und Verständnis der zugrunde liegenden Mechanismen.
 So melden Sie sich in der Oracle -Datenbank an
Apr 11, 2025 pm 02:39 PM
So melden Sie sich in der Oracle -Datenbank an
Apr 11, 2025 pm 02:39 PM
Die Oracle -Datenbankanmeldung umfasst nicht nur Benutzername und Kennwort, sondern auch Verbindungszeichenfolgen (einschließlich Serverinformationen und Anmeldeinformationen) und Authentifizierungsmethoden. Es unterstützt SQL*Plus- und Programmiersprachanschlüsse und bietet Authentifizierungsoptionen wie Benutzername und Passwort, Kerberos und LDAP. Zu den häufigen Fehlern gehören Verbindungszeichenfolgenfehler und ungültige Benutzername/Passwörter, während sich Best Practices auf Verbindungspooling, parametrisierte Abfragen, Indizierung und Sicherheitsanmeldeinformationen konzentrieren.
 Welche Arten von Dateien bestehen aus Oracle -Datenbanken?
Apr 11, 2025 pm 03:03 PM
Welche Arten von Dateien bestehen aus Oracle -Datenbanken?
Apr 11, 2025 pm 03:03 PM
Die Struktur der Oracle -Datenbankdatei umfasst: Datendatei: Speichern tatsächlicher Daten. Steuerdatei: Datenbankstrukturinformationen aufzeichnen. Protokolldateien neu wieder aufnehmen: Aktenübertragungsvorgänge aufzeichnen, um die Datenkonsistenz sicherzustellen. Parameterdatei: Enthält Datenbank, die über Parameter ausgeführt werden, um die Leistung zu optimieren. Archivprotokolldatei: Backup -Wiederherstellung der Protokolldatei für die Katastrophenwiederherstellung.
 Python vs. C: Anwendungen und Anwendungsfälle verglichen
Apr 12, 2025 am 12:01 AM
Python vs. C: Anwendungen und Anwendungsfälle verglichen
Apr 12, 2025 am 12:01 AM
Python eignet sich für Datenwissenschafts-, Webentwicklungs- und Automatisierungsaufgaben, während C für Systemprogrammierung, Spieleentwicklung und eingebettete Systeme geeignet ist. Python ist bekannt für seine Einfachheit und sein starkes Ökosystem, während C für seine hohen Leistung und die zugrunde liegenden Kontrollfunktionen bekannt ist.
 So löschen Sie die Oracle -Datenbank Oracle Database Löschenmethode
Apr 11, 2025 pm 02:45 PM
So löschen Sie die Oracle -Datenbank Oracle Database Löschenmethode
Apr 11, 2025 pm 02:45 PM
Die Löschung der Oracle -Datenbank muss basierend auf dem Löschobjekt (der gesamten Datenbankinstanz oder einer einzigen Datenbank/Objekt) und Berechtigungen bewertet werden. Es gibt viele Möglichkeiten, es zu löschen: DROP -Datenbankbefehl: Einfaches, aber hohes Risiko, und es muss die Klausel mit Datenfaktoren enthalten. Manuell Löschen von Datenbankdateien: Extrem riskant, es wird nur empfohlen, dass Experten sie verwenden, wenn es eine vollständige Sicherung gibt. Verwenden Sie RMAN zum Löschen: sicher und zuverlässig, empfohlen. Die Abhängigkeiten müssen vor dem Löschen behandelt werden, und häufige Fehler wie Berechtigungen und Dateibeschäftigung sollten mit Vorsicht behandelt werden. Geeignete Sicherungsstrategien und angemessene Datenbankarchitektur können den Löschprozess optimieren.
