
 Technologie-Peripheriegeräte
KI
Verbessern Sie die KI-End-to-End-Leistung durch maßgeschneiderte Operator-Fusion
Technologie-Peripheriegeräte
KI
Verbessern Sie die KI-End-to-End-Leistung durch maßgeschneiderte Operator-Fusion
Verbessern Sie die KI-End-to-End-Leistung durch maßgeschneiderte Operator-Fusion

Die Diagrammoptimierung spielt eine wichtige Rolle bei der Reduzierung des Zeit- und Ressourcenaufwands für das Training und die Inferenz von KI-Modellen. Eine wichtige Funktion der Graphoptimierung besteht darin, Operatoren zu fusionieren, die im Modell fusioniert werden können, wodurch die Recheneffizienz durch Reduzierung der Speichernutzung und Datenübertragung im Speicher mit niedriger Geschwindigkeit verbessert wird. Es ist jedoch sehr schwierig, eine Back-End-Lösung zu implementieren, die verschiedene Operatorfusionen bereitstellen kann, was dazu führt, dass die Operatorfusionen, die von KI-Modellen auf tatsächlicher Hardware verwendet werden können, nur sehr begrenzt sind.
Die Composable Kernel (CK)-Bibliothek zielt darauf ab, eine Reihe von Back-End-Lösungen für die Operatorfusion auf AMD-GPUs bereitzustellen. CK verwendet die universelle Programmiersprache HIP C++ und ist vollständig Open Source. Zu seinen Designkonzepten gehören:
- Hohe Leistung und hohe Produktivität: Der Kern von CK ist eine Reihe sorgfältig entworfener, hochoptimierter und wiederverwendbarer Basismodule. Alle Operatoren in der CK-Bibliothek werden durch die Kombination dieser Grundmodule implementiert. Die Wiederverwendung dieser Basismodule verkürzt den Entwicklungszyklus von Back-End-Algorithmen erheblich und gewährleistet gleichzeitig eine hohe Leistung.
- Beherrschen Sie aktuelle KI-Probleme und passen Sie sich schnell an zukünftige KI-Probleme an: CK zielt darauf ab, einen vollständigen Satz von KI-Operator-Backend-Lösungen bereitzustellen, die eine komplexe Operatorfusion ermöglichen, da dadurch das gesamte Backend mit CK implementiert werden kann, ohne sich darauf verlassen zu müssen auf externen Operatorbibliotheken. Die wiederverwendbaren Basismodule von CK reichen aus, um verschiedene Operatoren und deren Fusion zu implementieren, die von gängigen KI-Modellen (maschinelles Sehen, Verarbeitung natürlicher Sprache usw.) benötigt werden. Wenn neue KI-Modelle neue Operatoren erfordern, stellt CK auch die erforderlichen Basismodule bereit.
- Ein einfaches, aber leistungsstarkes Tool für KI-Systemexperten: CK Alle Operatoren werden mithilfe von HIP C++-Vorlagen implementiert. KI-Systemexperten können die Eigenschaften dieser Operatoren über Instanziierungsvorlagen anpassen, z. B. Datentyp, Metaoperationstyp, Tensorspeicherformat usw. Dies erfordert in der Regel nur wenige Codezeilen.
- Freundliche HIP-C++-Schnittstelle: Entwickler von HPC-Algorithmen haben die Grenzen der KI-Rechnerbeschleunigung erweitert. Ein wichtiges Designkonzept von CK besteht darin, es HPC-Algorithmusentwicklern zu erleichtern, zur KI-Beschleunigung beizutragen. Daher werden alle Kernmodule von CK in HIP C++ statt in Intermediate Representation (IR) implementiert. Entwickler von HPC-Algorithmen können Algorithmen direkt in der Form schreiben, mit der sie mit dem Schreiben von C++-Code vertraut sind, ohne einen Compiler-Pass für einen bestimmten Algorithmus schreiben zu müssen, wie es bei IR-basierten Operatorbibliotheken der Fall ist. Dadurch kann die Iterationsgeschwindigkeit des Algorithmus erheblich verbessert werden.
- Portabilität: Die heutige Grafikoptimierung mit CK als Backend kann auf alle zukünftigen AMD-GPUs portiert werden und wird schließlich auf AMD-CPUs portiert [2].
- CK-Quellcode: https://github.com/ROCmSoftwarePlatform/composable_kernel
Core Concepts
CK stellt zwei Konzepte vor, um die Produktivität von Backend-Entwicklern zu verbessern:
1 Die Einführung der „Tensor-Koordinatentransformation“ reduziert die Komplexität beim Schreiben von KI-Operatoren. Diese Forschung leistete Pionierarbeit bei der Definition einer Reihe wiederverwendbarer Basismodule für die Tensorkoordinatentransformation und nutzte sie, um komplexe KI-Operatoren (wie Faltung, Gruppennormalisierungsreduzierung, Depth2Space usw.) auf mathematisch strenge Weise in die grundlegendste KI umzuwandeln Operatoren (GEMM, 2D-Reduktion, Tensortransfer usw.). Diese Technologie ermöglicht die direkte Verwendung von Algorithmen, die für grundlegende KI-Operatoren geschrieben wurden, auf allen entsprechenden komplexen KI-Operatoren, ohne dass der Algorithmus neu geschrieben werden muss.
2. Kachelbasiertes Programmierparadigma: Die Entwicklung des Back-End-Algorithmus für die Operatorfusion kann als erstes Zerlegen jedes Pre-Fusion-Operators (unabhängiger Operator) in viele „kleine Teile“ von Datenoperationen angesehen werden „Operationen werden dann zu fusionierten Operatoren zusammengefasst. Jede solche „Kleinblock“-Operation entspricht einem ursprünglichen unabhängigen Operator, aber die verarbeiteten Daten sind nur ein Teil (Kachel) des ursprünglichen Tensors, daher wird eine solche „Kleinblock“-Operation als Kachel-Tensoroperator bezeichnet. Die CK-Bibliothek enthält eine Reihe hochoptimierter Implementierungen des Tile-Tensor-Operators, und alle KI-unabhängigen Operatoren und Fusionsoperatoren in CK werden mit ihnen implementiert. Derzeit umfassen diese Tile-Tensor-Operatoren Tile GEMM, Tile Reduction und Tile Tensor Transfer. Jeder Tile-Tensor-Operator verfügt über Implementierungen für GPU-Thread-Blöcke, Warps und Threads.
Tensorkoordinatentransformation und Kacheltensoroperator bilden zusammen das wiederverwendbare Grundmodul von CK.
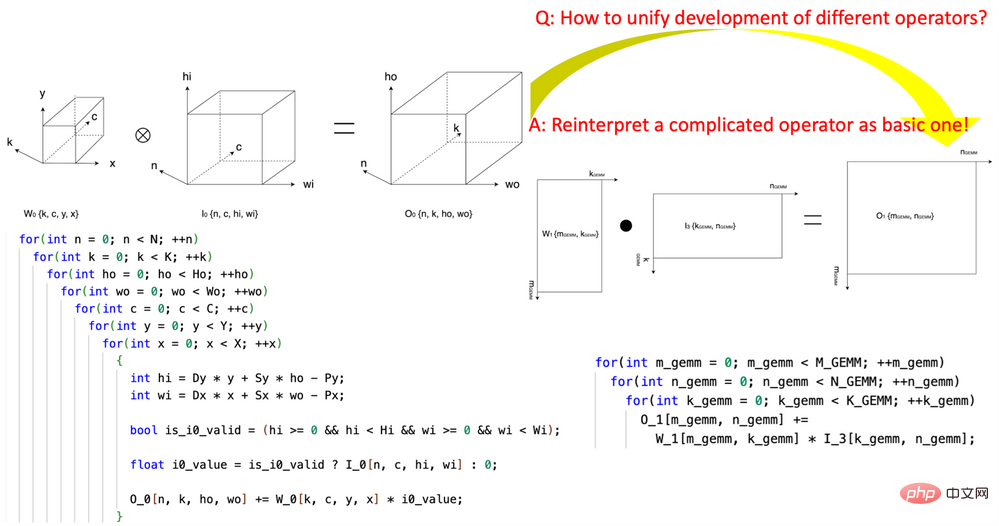
Abbildung 1, Verwendung des Tensor-Koordinatentransformations-Basismoduls von CK, um den Faltungsoperator in einen GEMM-Operator auszudrücken
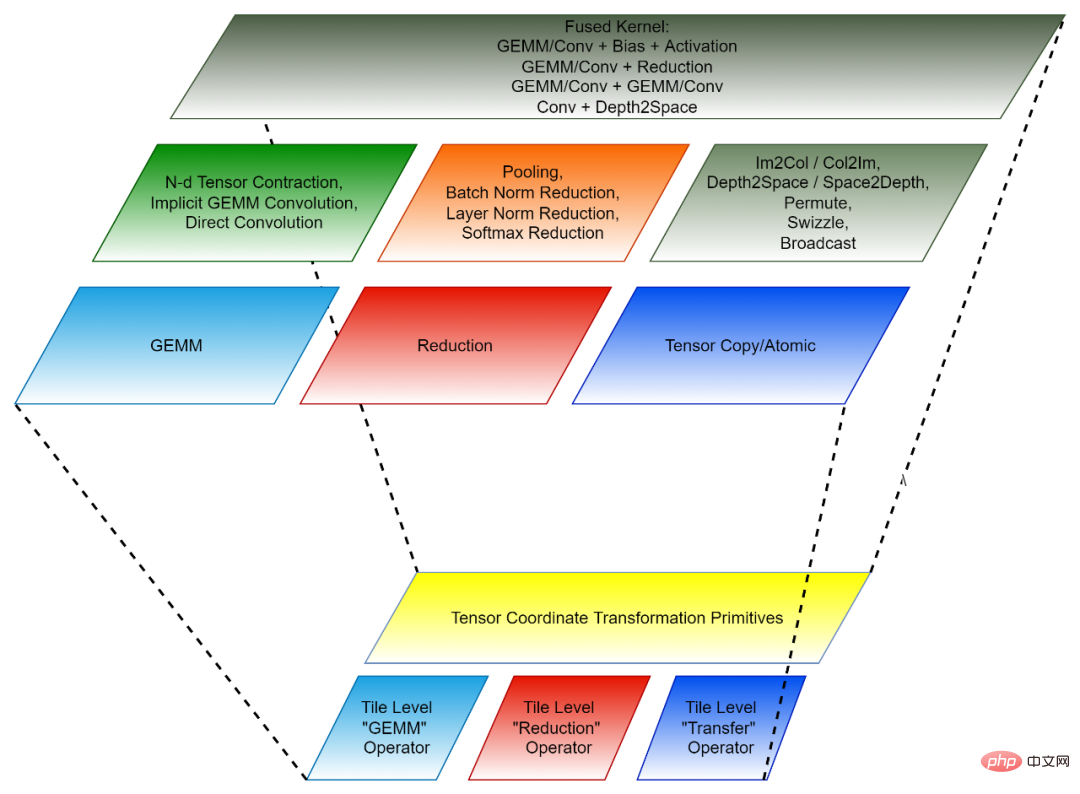
Abbildung 2, die Zusammensetzung von CK (unten: wiederverwendbar). Modul der Invoker- und Client-API [3]. Jede Ebene entspricht verschiedenen Entwicklern.
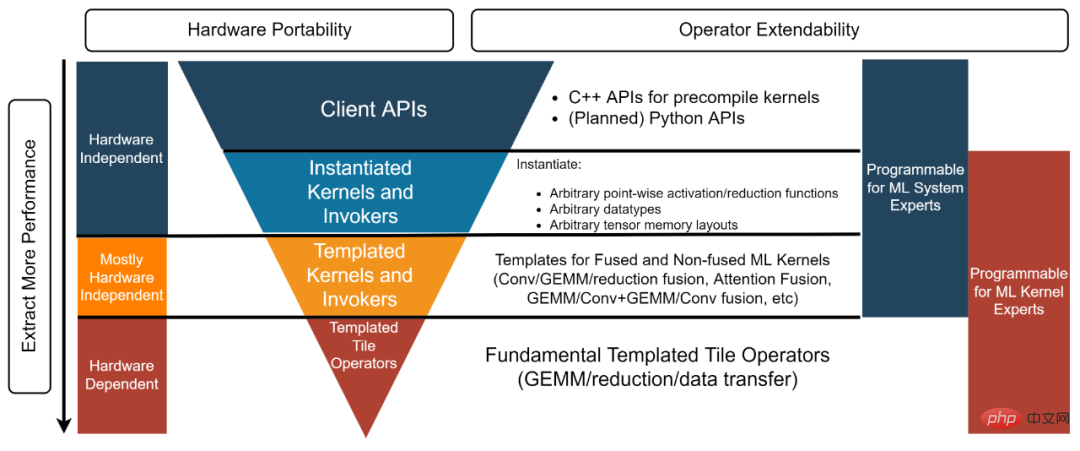
KI-Systemexperte: „Ich brauche eine Back-End-Lösung, die leistungsstarke unabhängige und zusammengeführte Operatoren bereitstellt, die ich direkt nutzen kann.“ Die in diesem Beispiel [4] verwendete Client-API sowie der instanziierte Kernel und Invoker stellen vorinstanziierte und kompilierte Objekte bereit, um den Anforderungen dieses Entwicklertyps gerecht zu werden.
Experte für KI-Systeme: „Ich erledige hochmoderne Graphoptimierungsarbeiten für ein Open-Source-KI-Framework. Ich benötige eine Backend-Lösung, die einen leistungsstarken Kernel für alle für die Graphoptimierung erforderlichen Fusionsoperatoren bereitstellen kann.“ Gleichzeitig muss ich diese Kernel anpassen, sodass eine Black-Box-Lösung wie „Nimm es oder lass es“ meinen Anforderungen nicht entspricht. Die Ebenen „Templated Kernel“ und „Invoker“ erfüllen diese Art von Entwickler. In diesem Beispiel [5] können Entwickler beispielsweise die Templated Kernel- und Invoker-Ebene verwenden, um den erforderlichen FP16 GEMM + Add + Add + FastGeLU-Kernel zu instanziieren.
- HPC-Algorithmus-Experte: „Mein Team entwickelt leistungsstarke Back-End-Algorithmen für die KI-Modelle, die innerhalb des Unternehmens ständig iterieren. Wir haben HPC-Algorithmus-Experten im Team, hoffen aber dennoch auf eine Wiederverwendung und Verbesserung.“ die von Hardware-Anbietern bereitgestellten Algorithmen, um unsere Produktivität zu steigern und die Portierung unseres Codes auf zukünftige Hardware-Architekturen zu ermöglichen. Die Ebene „Templated Tile Operator“ kann dieser Art von Entwicklern helfen. In diesem Code [6] verwendet der Entwickler beispielsweise den Templated Tile Operator, um die GEMM-Optimierungspipeline zu implementieren. Abbildung 3, vierschichtige Struktur der CK-Bibliothek AMD- und KI-Inferenzsystem für Nvidia-GPUs. AITemplate verwendet CK als Backend auf AMD-GPUs und nutzt dabei den Templated Kernel und die Invoker-Schicht von CK.
- AITemplate + CK erreicht modernste Inferenzleistung bei mehreren wichtigen KI-Modellen auf AMD Instinct™ MI250. Die Definition der fortschrittlichsten Fusionsoperatoren in CK basiert auf der Vision des AITemplate-Teams. Viele Fusionsoperator-Algorithmen werden auch gemeinsam von den CK- und AITemplate-Teams entworfen.
- Dieser Artikel vergleicht die Leistung mehrerer End-to-End-Modelle auf AMD Instinct MI250 und ähnlichen Produkten [8]. Alle Leistungsdaten des AMD Instinct MI250 AI-Modells in diesem Artikel werden mit AITemplate[9] + CK[10] ermittelt.
ResNet-50Das Bild unten zeigt AIT + CK auf AMD Instinct MI250 mit TensorRT v8.5.0.12 auf A100-PCIe-40GB und A100-DGX-80GB [11 】 ( TRT) Leistungsvergleich. Die Ergebnisse zeigen, dass AIT + CK auf AMD Instinct MI250 eine 1,08-fache Beschleunigung im Vergleich zu TRT auf A100-PCIe-40GB erreichte.
BERT
Eine auf CK basierende Batch-GEMM + Softmax + GEMM-Fusionsoperatorvorlage, die die Übertragung von Zwischenergebnissen zwischen der GPU-Recheneinheit (Recheneinheit) und HBM vollständig eliminieren kann. Durch die Verwendung dieser Fusionsoperatorvorlage sind viele Probleme in der Aufmerksamkeitsschicht, die ursprünglich bandbreitengebunden waren, zu rechnerischen Engpässen (rechengebunden) geworden, wodurch die Rechenleistung der GPU besser genutzt werden kann. Diese CK-Implementierung ist stark von FlashAttention [12] inspiriert und reduziert mehr Datenverarbeitung als die ursprüngliche FlashAttention-Implementierung.
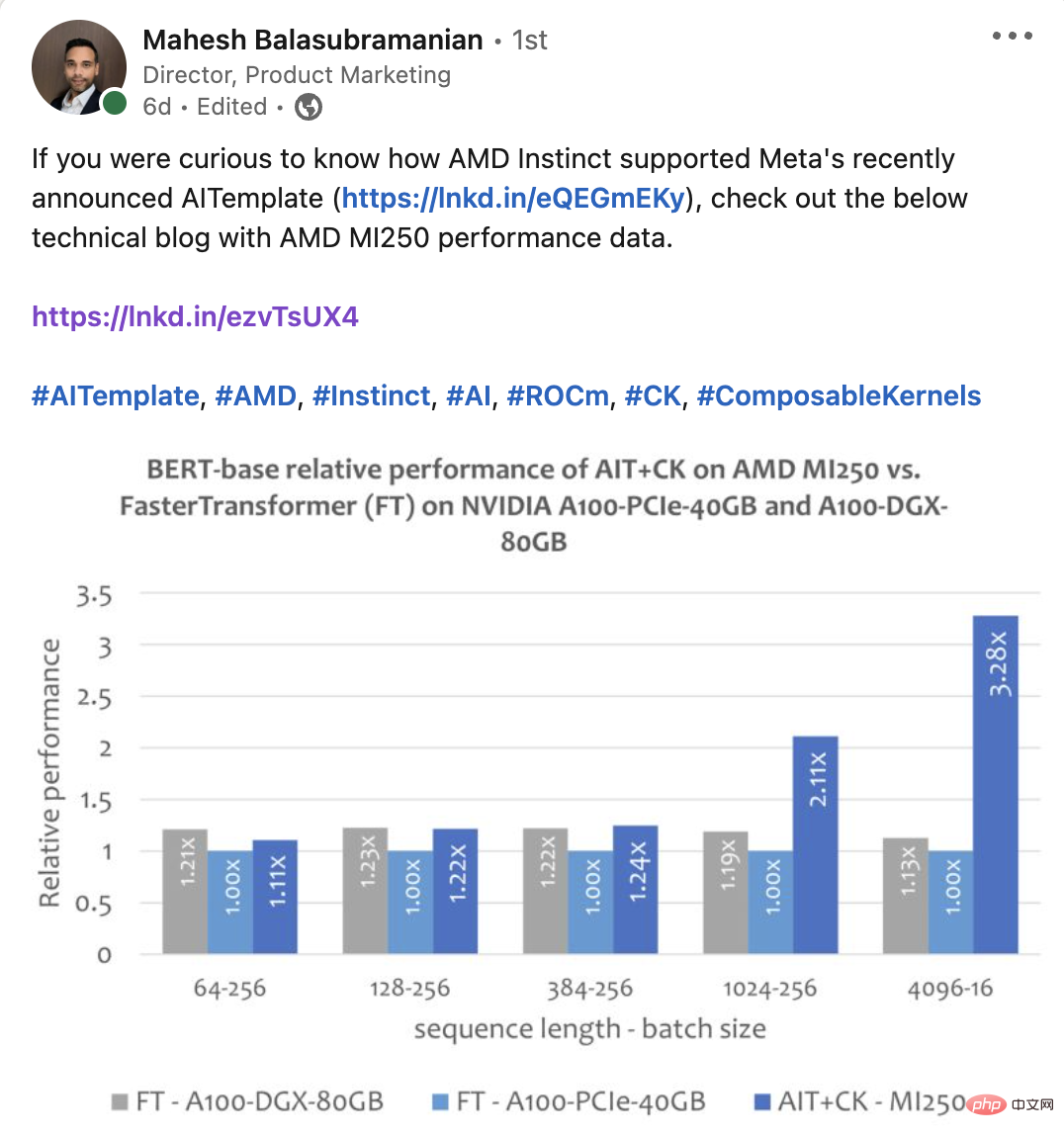
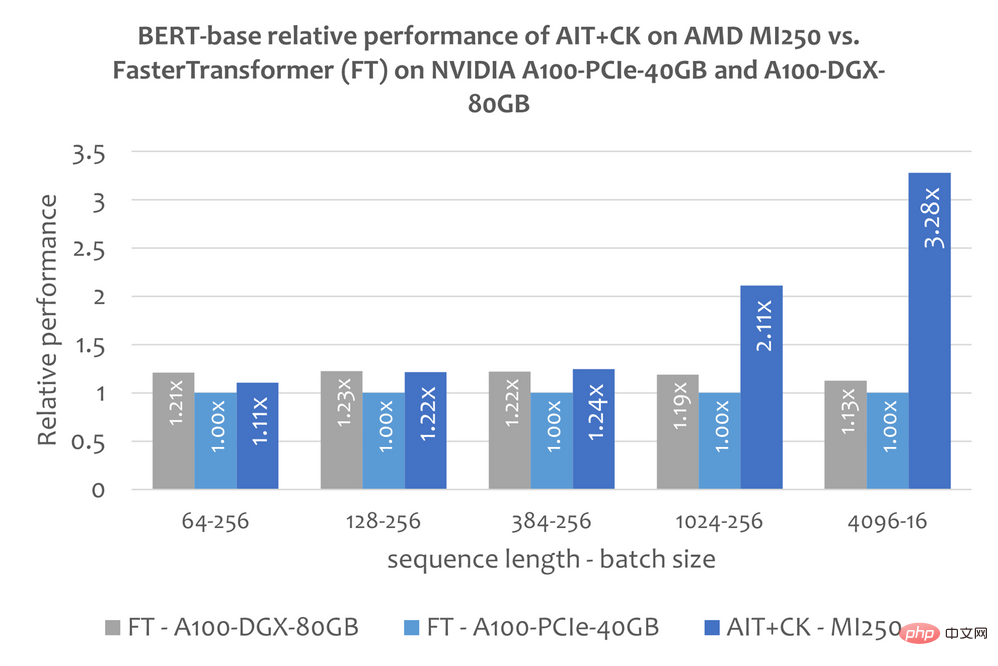
Das Bild unten zeigt das Bert Base-Modell (ohne Gehäuse) von AIT + CK auf AMD Instinct MI250 und FasterTransformer v5.1.1 Bugfix [13] (FT) auf A100-PCIe-40GB und A100-DGX-80GB Leistungsvergleich . FT führt bei Batch 32 auf A100-PCIe-40GB und A100-DGX-80GB zu einem Überlauf des GPU-Speichers, wenn die Sequenz 4096 ist. Wenn die Sequenz 4096 ist, werden in diesem Artikel daher nur die Ergebnisse von Batch 16 angezeigt. Die Ergebnisse zeigen, dass AIT + CK auf AMD Instinct MI250 eine 3,28-fache FT-Beschleunigung im Vergleich zu FT auf A100-PCIe-40GB und eine 2,91-fache FT-Beschleunigung im Vergleich zu A100-DGX-80GB erreicht.
Vision Transformer (VIT)
Das Bild unten zeigt AIT + CK auf AMD Instinct MI250 mit TensorRT v8.5.0.12 auf A100-PCIe-40GB und A100-DGX-80GB Leistungsvergleich von Vision Transformer Base (224x224 Bild) von (TRT). Die Ergebnisse zeigen, dass AIT + CK auf AMD Instinct MI250 eine 1,8-fache Beschleunigung im Vergleich zu TRT auf A100-PCIe-40GB und eine 1,4-fache Beschleunigung im Vergleich zu TRT auf A100-DGX-80GB erreicht.
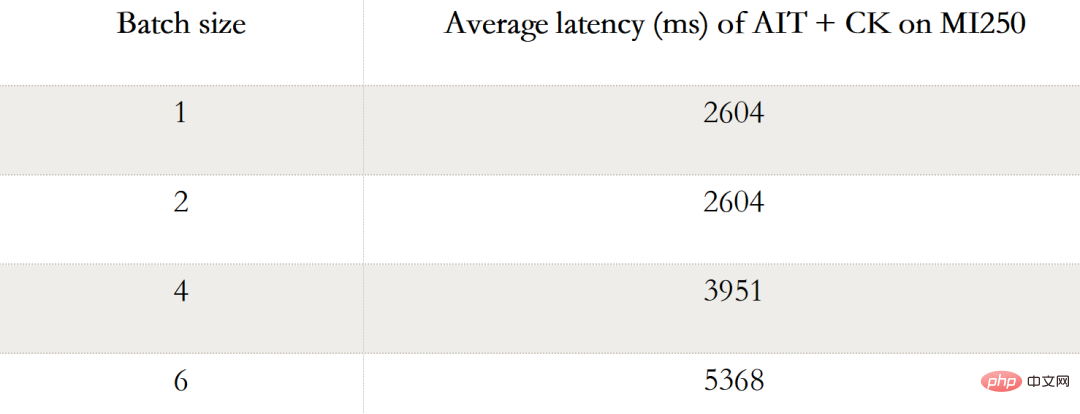
... 4, 6 ) Leistungsdaten. Wenn Batch 1 ist, wird nur ein GCD auf dem MI250 verwendet, während in Batch 2, 4 und 6 beide GCDs verwendet werden. 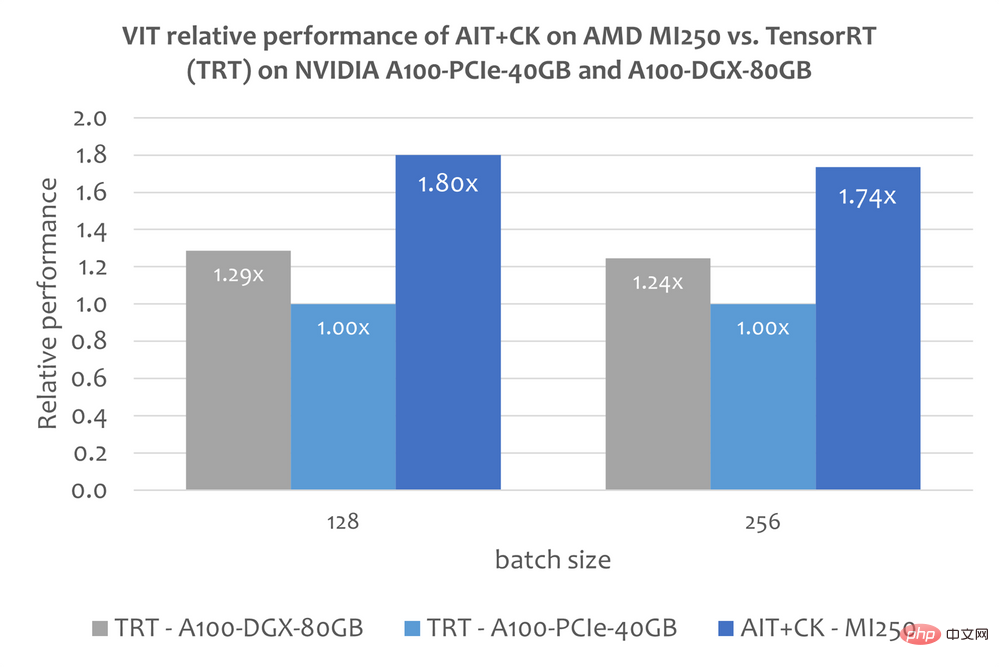
UNet in Stable Diffusion
Dieser Artikel enthält jedoch keine öffentlichen Informationen über die Verwendung von TensorRT zum Ausführen des Stable Diffusion-End-to-End-Modells. In diesem Artikel „Machen Sie die stabile Diffusion mit TensorRT um 25 % schneller“ [14] wird jedoch erläutert, wie Sie TensorRT verwenden, um das UNet-Modell in Stable Diffusion zu beschleunigen. UNet ist der wichtigste und zeitaufwändigste Teil der stabilen Diffusion, daher spiegelt die Leistung von UNet in etwa die Leistung der stabilen Diffusion wider.
Die folgende Grafik zeigt den Leistungsvergleich von AIT + CK auf AMD Instinct MI250 mit UNet auf A100-PCIe-40GB und A100-DGX-80GB mit TensorRT v8.5.0.12 (TRT). Die Ergebnisse zeigen, dass AIT + CK auf dem AMD Instinct MI250 eine 2,45-fache Beschleunigung im Vergleich zum TRT auf dem A100-PCIe-40GB und eine 2,03-fache Beschleunigung im Vergleich zum TRT auf dem A100-DGX-80GB erreicht.
Weitere Informationen: Ersteller: AMD Instinct™ Jing Zhang ist SMTS Software Development Engineer bei AMD. Ihre Beiträge geben ihre eigene Meinung wieder und geben möglicherweise nicht die Positionen, Strategien oder Meinungen von AMD wieder solche verlinkten Seiten und es ist keine Billigung impliziert
2.CK für CPU befindet sich in der frühen Entwicklungsphase.
#🎜🎜 #3.C++-APIs vorerst, Python-APIs sind in Planung.
4.Beispiel für CK „Client API“ für GEMM + Add + Add + FastGeLU-Fused-Operator. https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491...
#🎜🎜 #5.Beispiel für CK „Templated Kernel and Invoker“ von GEMM + Add + Add + FastGeLU-Sicherungsoperator. https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491...#🎜🎜 #
6.Beispiel für die Verwendung von CK-Grundelementen „Templated Tile Operator“ zum Schreiben einer GEMM-Pipeline. https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491...#🎜🎜 #
7.Metas AITemplate GitHub-Repository. https://github.com/facebookincubator/AITemplate8.MI200-71: Testen Durchgeführt von AMD MLSE 10.23.22 mit AITemplate (https://github.com/ROCmSoftwarePlatform/AITemplate, Commit f940d9b) + Composable Kernel https://github.com/ROCmSoftwarePlatform/composable_kernel, Commit 40942b9) mit ROCm™5.3 auf 2x AMD EPYC 7713 64-Core-Prozessorserver mit 4x AMD Instinct MI250 OAM (128 GB HBM2e) 560-W-GPU mit AMD Infinity Fabric™-Technologie im Vergleich zu TensorRT v8.5.0.12 und FasterTransformer (v5.1.1 Bugfix) mit CUDA® 11.8 auf 2x AMD EPYC 7742 64-Core-Prozessorserver mit 4x Nvidia A100-PCIe-40GB (250W) GPU und TensorRT v8.5.0.12 und FasterTransformer (v5.1.1 Bugfix) mit CUDA® 11.8 läuft auf 2xAMD EPYC 7742 64-Core-Prozessorserver mit 8x NVIDIA A100 SXM 80GB (400W) GPU. Serverhersteller können Konfigurationen variieren, was zu unterschiedlichen Ergebnissen führt. Die Leistung kann aufgrund von Faktoren wie der Verwendung der neuesten Treiber und Optimierungen variieren. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#9.https: //github.com/rocmsoftwareplatform/aitemplate/tree/f940d9b7ac8b976fba127e2c269dc5b368f30e 🎜🎜#
10.https://github.com/ROCmSoftwarePlatform/composable_kernel/tree/40942b909801dd 721769834fc61ad201b5795.. .
11.TensorRT GitHub-Repository. https://github.com/NVIDIA/TensorRT
12.FlashAchtung: Schnell und Speicher -Effiziente exakte Aufmerksamkeit mit IO-Bewusstsein. https://arxiv.org/abs/2205.14135
13.FasterTransformer GitHub-Repository. https://github.com/NVIDIA/FasterTransformer
14. Stabile Diffusion um 25 % erhöhen schneller mit TensorRT. https://www.photoroom.com/tech/stable-diffusion-25-percent-faster-and-save-seconds/
#🎜 🎜#15.Während ihrer Zeit bei AMD
Das obige ist der detaillierte Inhalt vonVerbessern Sie die KI-End-to-End-Leistung durch maßgeschneiderte Operator-Fusion. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Zehn empfohlene Open-Source-Tools für kostenlose Textanmerkungen
Mar 26, 2024 pm 08:20 PM
Zehn empfohlene Open-Source-Tools für kostenlose Textanmerkungen
Mar 26, 2024 pm 08:20 PM
Bei der Textanmerkung handelt es sich um die Arbeit mit entsprechenden Beschriftungen oder Tags für bestimmte Inhalte im Text. Sein Hauptzweck besteht darin, zusätzliche Informationen zum Text für eine tiefere Analyse und Verarbeitung bereitzustellen, insbesondere im Bereich der künstlichen Intelligenz. Textanmerkungen sind für überwachte maschinelle Lernaufgaben in Anwendungen der künstlichen Intelligenz von entscheidender Bedeutung. Es wird zum Trainieren von KI-Modellen verwendet, um Textinformationen in natürlicher Sprache genauer zu verstehen und die Leistung von Aufgaben wie Textklassifizierung, Stimmungsanalyse und Sprachübersetzung zu verbessern. Durch Textanmerkungen können wir KI-Modellen beibringen, Entitäten im Text zu erkennen, den Kontext zu verstehen und genaue Vorhersagen zu treffen, wenn neue ähnliche Daten auftauchen. In diesem Artikel werden hauptsächlich einige bessere Open-Source-Textanmerkungstools empfohlen. 1.LabelStudiohttps://github.com/Hu
 15 empfohlene kostenlose Open-Source-Bildanmerkungstools
Mar 28, 2024 pm 01:21 PM
15 empfohlene kostenlose Open-Source-Bildanmerkungstools
Mar 28, 2024 pm 01:21 PM
Bei der Bildanmerkung handelt es sich um das Verknüpfen von Beschriftungen oder beschreibenden Informationen mit Bildern, um dem Bildinhalt eine tiefere Bedeutung und Erklärung zu verleihen. Dieser Prozess ist entscheidend für maschinelles Lernen, das dabei hilft, Sehmodelle zu trainieren, um einzelne Elemente in Bildern genauer zu identifizieren. Durch das Hinzufügen von Anmerkungen zu Bildern kann der Computer die Semantik und den Kontext hinter den Bildern verstehen und so den Bildinhalt besser verstehen und analysieren. Die Bildanmerkung hat ein breites Anwendungsspektrum und deckt viele Bereiche ab, z. B. Computer Vision, Verarbeitung natürlicher Sprache und Diagramm-Vision-Modelle. Sie verfügt über ein breites Anwendungsspektrum, z. B. zur Unterstützung von Fahrzeugen bei der Identifizierung von Hindernissen auf der Straße und bei der Erkennung und Diagnose von Krankheiten durch medizinische Bilderkennung. In diesem Artikel werden hauptsächlich einige bessere Open-Source- und kostenlose Bildanmerkungstools empfohlen. 1.Makesens
 So deaktivieren Sie den gemeinsam genutzten Win10GPU-Speicher
Jan 12, 2024 am 09:45 AM
So deaktivieren Sie den gemeinsam genutzten Win10GPU-Speicher
Jan 12, 2024 am 09:45 AM
Freunde, die sich mit Computern auskennen, müssen wissen, dass GPUs über einen gemeinsamen Speicher verfügen, und viele Freunde befürchten, dass der gemeinsame Speicher den Speicher verringert und den Computer ausschaltet. Hier erfahren Sie, wie Sie ihn ausschalten sehen. Deaktivieren Sie den gemeinsam genutzten Speicher von win10gpu: Hinweis: Der gemeinsam genutzte Speicher der GPU kann nicht deaktiviert werden, aber sein Wert kann auf den Mindestwert gesetzt werden. 1. Drücken Sie beim Booten die Entf-Taste, um das BIOS aufzurufen. Es gibt viele Registerkarten oben in der BIOS-Oberfläche, darunter „Main“, „Erweitert“ und andere Einstellungen " Möglichkeit. Suchen Sie die SouthBridge-Einstellungsoption in der Benutzeroberfläche unten und klicken Sie zum Aufrufen auf die Eingabetaste.
 Muss ich die GPU-Hardwarebeschleunigung aktivieren?
Feb 26, 2024 pm 08:45 PM
Muss ich die GPU-Hardwarebeschleunigung aktivieren?
Feb 26, 2024 pm 08:45 PM
Ist es notwendig, die hardwarebeschleunigte GPU zu aktivieren? Bei der kontinuierlichen Weiterentwicklung und Weiterentwicklung der Technologie spielt die GPU (Graphics Processing Unit) als Kernkomponente der Computergrafikverarbeitung eine entscheidende Rolle. Einige Benutzer haben jedoch möglicherweise Fragen dazu, ob die Hardwarebeschleunigung aktiviert werden muss. In diesem Artikel werden die Notwendigkeit der Hardwarebeschleunigung für die GPU und die Auswirkungen der Aktivierung der Hardwarebeschleunigung auf die Computerleistung und das Benutzererlebnis erörtert. Zunächst müssen wir verstehen, wie hardwarebeschleunigte GPUs funktionieren. GPU ist spezialisiert
 Laut News wird AMD die neue Laptop-GPU RX 7700M/7800M auf den Markt bringen
Jan 06, 2024 pm 11:30 PM
Laut News wird AMD die neue Laptop-GPU RX 7700M/7800M auf den Markt bringen
Jan 06, 2024 pm 11:30 PM
Laut Nachrichten dieser Website vom 2. Januar wird AMD laut TechPowerUp bald Notebook-Grafikkarten auf Basis der Navi32-GPU auf den Markt bringen. Die spezifischen Modelle könnten RX7700M und RX7800M sein. Derzeit hat AMD eine Reihe von Notebook-GPUs der RX7000-Serie auf den Markt gebracht, darunter die High-End-Serie RX7900M (72 CU) und die Mainstream-Serie RX7600M/7600MXT (28/32 CU) sowie die RX7600S/7700S-Serie (28/32 CU). Navi32GPU verfügt über 60 CU. AMD schafft es möglicherweise in die Modelle RX7700M und RX7800M oder ein RX7900S-Modell mit geringem Stromverbrauch. AMD wird dies voraussichtlich tun
 Das Grafikkarten-Erweiterungsdock Beelink EX verspricht keinen GPU-Leistungsverlust
Aug 11, 2024 pm 09:55 PM
Das Grafikkarten-Erweiterungsdock Beelink EX verspricht keinen GPU-Leistungsverlust
Aug 11, 2024 pm 09:55 PM
Eines der herausragenden Merkmale des kürzlich eingeführten Beelink GTi 14 ist, dass der Mini-PC über einen versteckten PCIe x8-Steckplatz an der Unterseite verfügt. Bei der Markteinführung gab das Unternehmen an, dass dies den Anschluss einer externen Grafikkarte an das System erleichtern würde. Beelink hat n
 Empfohlen: Ausgezeichnetes JS-Open-Source-Projekt zur Gesichtserkennung und -erkennung
Apr 03, 2024 am 11:55 AM
Empfohlen: Ausgezeichnetes JS-Open-Source-Projekt zur Gesichtserkennung und -erkennung
Apr 03, 2024 am 11:55 AM
Die Technologie zur Gesichtserkennung und -erkennung ist bereits eine relativ ausgereifte und weit verbreitete Technologie. Derzeit ist JS die am weitesten verbreitete Internetanwendungssprache. Die Implementierung der Gesichtserkennung und -erkennung im Web-Frontend hat im Vergleich zur Back-End-Gesichtserkennung Vor- und Nachteile. Zu den Vorteilen gehören die Reduzierung der Netzwerkinteraktion und die Echtzeiterkennung, was die Wartezeit des Benutzers erheblich verkürzt und das Benutzererlebnis verbessert. Die Nachteile sind: Es ist durch die Größe des Modells begrenzt und auch die Genauigkeit ist begrenzt. Wie implementiert man mit js die Gesichtserkennung im Web? Um die Gesichtserkennung im Web zu implementieren, müssen Sie mit verwandten Programmiersprachen und -technologien wie JavaScript, HTML, CSS, WebRTC usw. vertraut sein. Gleichzeitig müssen Sie auch relevante Technologien für Computer Vision und künstliche Intelligenz beherrschen. Dies ist aufgrund des Designs der Webseite erwähnenswert
 AMD FSR 3.1 eingeführt: Frame-Generierungsfunktion funktioniert auch auf Nvidia GeForce RTX- und Intel Arc-GPUs
Jun 29, 2024 am 06:57 AM
AMD FSR 3.1 eingeführt: Frame-Generierungsfunktion funktioniert auch auf Nvidia GeForce RTX- und Intel Arc-GPUs
Jun 29, 2024 am 06:57 AM
AMD löst sein ursprüngliches Versprechen vom 24. März ein und bringt FSR 3.1 im zweiten Quartal dieses Jahres auf den Markt. Was die Version 3.1 wirklich auszeichnet, ist die Entkopplung der Frame-Generierung von der Upscaling-Seite. Dadurch können Nvidia- und Intel-GPU-Besitzer den FSR 3 anwenden.
