
 Technologie-Peripheriegeräte
KI
Effizientes und realistisches Stadtrendering in extrem großem Maßstab: Kombination von NeRF und Feature-Grid-Technologie
Technologie-Peripheriegeräte
KI
Effizientes und realistisches Stadtrendering in extrem großem Maßstab: Kombination von NeRF und Feature-Grid-Technologie
Effizientes und realistisches Stadtrendering in extrem großem Maßstab: Kombination von NeRF und Feature-Grid-Technologie

Das rein MLP-basierte Neural Radiation Field (NeRF) leidet aufgrund der begrenzten Modellkapazität häufig unter einer unzureichenden Anpassung bei der Darstellung von Unschärfen in großen Szenen. Kürzlich haben einige Forscher vorgeschlagen, die Szene geografisch aufzuteilen und mehrere Sub-NeRFs zu verwenden, um jeden Bereich separat zu modellieren. Das dadurch verursachte Problem besteht jedoch darin, dass die Trainingskosten mit der schrittweisen Erweiterung der Szene linear mit der Anzahl der Sub-NeRFs werden. expandieren.
Eine andere Lösung ist die Verwendung einer Voxel-Feature-Rasterdarstellung, die recheneffizient ist und sich mit zunehmender Rasterauflösung auf natürliche Weise auf große Szenen skalieren lässt. Allerdings erzielen Feature-Netze aufgrund weniger Einschränkungen oft nur suboptimale Lösungen, was zu einigen Rauschartefakten beim Rendern führt, insbesondere in Bereichen mit komplexer Geometrie und Texturen.
In diesem Artikel schlagen Forscher der Chinesischen Universität Hongkong, des Shanghai Artificial Intelligence Laboratory und anderer Institutionen einen neuen Rahmen vor, um eine hochauflösende Darstellung städtischer (Ubran-)Szenen unter Berücksichtigung der Recheneffizienz zu erreichen für CVPR 2023. Die Studie verwendet eine kompakte, mehrfach auflösende Boden-Feature-Plane-Darstellung, um die Szene grob zu erfassen, und ergänzt sie mit positionscodierten Eingaben über ein NeRF-Zweignetzwerk, um sie auf gemeinsam erlernte Weise zu rendern. Dieser Ansatz vereint die Vorteile der beiden Ansätze: Unter der Führung der Feature-Grid-Darstellung reicht ein leicht gewichtetes NeRF aus, um eine realistische neue Perspektive mit Details darzustellen, die gemeinsam optimierte Boden-Feature-Ebene kann weiter verfeinert werden, um eine genauere und genauere Darstellung zu erzielen Detaillierter kompakter Funktionsraum, Ausgabe natürlicherer Rendering-Ergebnisse.

- Papieradresse: https://arxiv.org/pdf/2303.14001.pdf
- Projekthomepage: https://city-super.github.io/ gridnerf/
Das Bild unten zeigt Beispielergebnisse der Forschungsmethode in der realen Ubran-Szene und bietet den Menschen ein immersives Stadt-Roaming-Erlebnis:

Einführung in die Methode
Um Implizite neuronale Funktionen effektiv nutzen Um die Rekonstruktion großräumiger städtischer Szenen darzustellen, schlägt diese Studie eine Dual-Branche-Modellarchitektur vor, die eine einheitliche Szenendarstellung verwendet, die explizite Voxelgitter-basierte und implizite basierte NeRF-Methoden integriert ergänzen sich gegenseitig.
Die Zielszene wird zunächst in der Vortrainingsphase mithilfe eines Feature-Mesh modelliert, um die Geometrie und das Erscheinungsbild der Szene grob zu erfassen. Anschließend wird ein grobes Merkmalsgitter verwendet, um 1) die NeRF-Punktabtastung so zu steuern, dass sie um die Szenenoberfläche konzentriert ist, und 2) die Positionskodierung von NeRF mit zusätzlichen Merkmalen über die Szenengeometrie und das Erscheinungsbild an den abgetasteten Orten zu versorgen. Mit einer solchen Führung kann NeRF effizienter feinere Details in einem stark komprimierten Abtastraum erfassen. Da darüber hinaus grobe Geometrie- und Aussehensinformationen explizit für NeRF bereitgestellt werden, reicht ein leichter MLP aus, um die Zuordnung von globalen Koordinaten zu Volumendichte- und Farbwerten zu erlernen. In einer zweiten gemeinsamen Lernphase wird das grobe Merkmalsnetz über Gradienten aus dem NeRF-Zweig weiter optimiert und normalisiert, was bei alleiniger Anwendung zu genaueren und natürlicheren Rendering-Ergebnissen führt.
Der Kern dieser Forschung ist eine neue Doppelzweigstruktur, nämlich der Grid-Zweig und der NeRF-Zweig. 1) Die Forscher erfassten zunächst die Pyramidenszene der Merkmalsebene in der Vortrainingsphase, tasteten die Strahlpunkte grob durch einen flachen MLP-Renderer (Gitterzweig) ab und sagten ihre Strahlungswerte durch volumenintegriertes MSE auf dem Pixel vorher Farbverlustüberwachung. Dieser Schritt generiert einen informationsreichen Satz von Dichte-/Erscheinungsmerkmalsebenen mit mehreren Auflösungen. 2) Als nächstes treten die Forscher in die gemeinsame Lernphase ein und führen eine verfeinerte Stichprobe durch. Die Forscher nutzten das erlernte Merkmalsraster, um die NeRF-Zweigstichprobe so zu steuern, dass sie sich auf Szenenoberflächen konzentrierte. Die Gittereigenschaften der Abtastpunkte werden durch bilineare Interpolation auf der Merkmalsebene abgeleitet. Diese Merkmale werden dann mit der Positionskodierung verkettet und in den NeRF-Zweig eingespeist, um volumetrische Dichte und Farbe vorherzusagen. Beachten Sie, dass während des gemeinsamen Trainings die Ausgabe des Rasterzweigs weiterhin mithilfe von Ground-Truth-Bildern sowie feinen Rendering-Ergebnissen aus dem NeRF-Zweig überwacht wird.
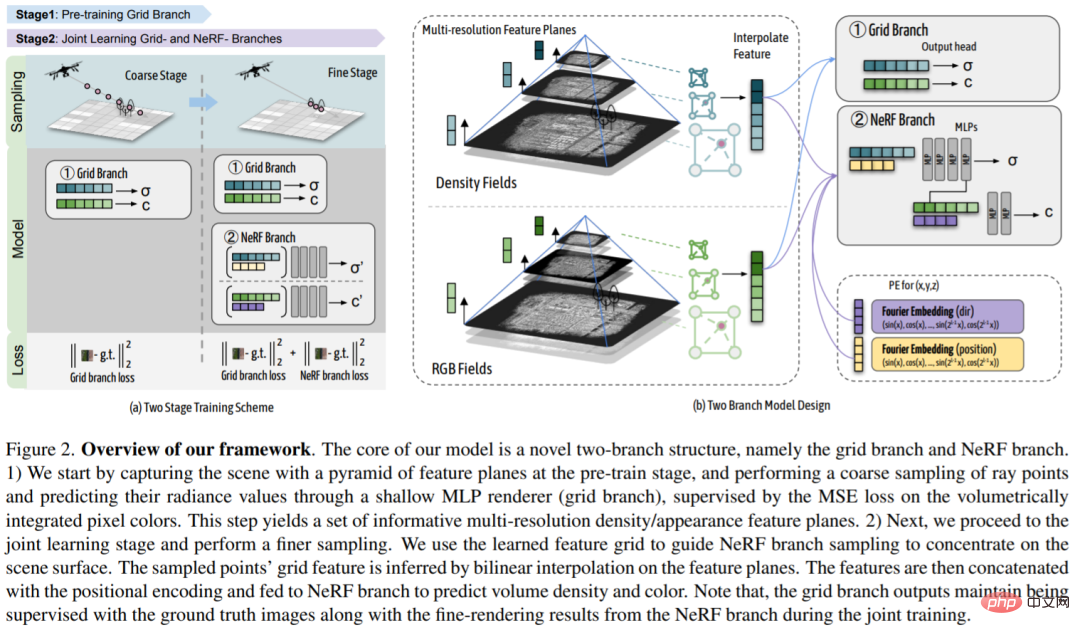
Zielszenario: In dieser Arbeit verwendet die Studie ein neuartiges gittergeführtes neuronales Strahlungsfeld, um eine groß angelegte Darstellung städtischer Szenen durchzuführen. Die linke Seite des Bildes unten zeigt ein Beispiel einer großen städtischen Szene, die sich über eine 2,7 km² große Bodenfläche erstreckt und mit über 5.000 Drohnenbildern aufgenommen wurde. Studien haben gezeigt, dass NeRF-basierte Methoden verschwommene und übermäßig geglättete Ergebnisse liefern und über eine begrenzte Modellkapazität verfügen, während eigengitterbasierte Methoden bei der Anpassung an große Szenen mit hochauflösenden Eigengittern tendenziell verrauschte Artefakte zeigen. Das in dieser Studie vorgeschlagene Dual-Branche-Modell kombiniert die Vorteile beider Methoden und erreicht durch erhebliche Verbesserungen gegenüber bestehenden Methoden eine realistische Darstellung neuartiger Ansichten. Beide Zweige erzielen erhebliche Verbesserungen gegenüber ihren jeweiligen Basislinien.

Experiment
Die Forscher berichteten über die Leistung der Basislinie und die Methode des Forschers in der Abbildung und Tabelle unten. Sowohl qualitativ als auch quantitativ. Hinsichtlich der visuellen Qualität und aller Kennzahlen sind deutliche Verbesserungen zu beobachten. Der Ansatz der Forscher offenbart schärfere Geometrien und feinere Details als rein MLP-basierte Methoden (NeRF und Mega-NeRF). Insbesondere aufgrund der begrenzten Kapazität und der spektralen Ausrichtung von NeRF ist es immer nicht in der Lage, schnelle Änderungen in Geometrie und Farbe zu simulieren, wie zum Beispiel Vegetation und Streifen auf einem Spielplatz. Obwohl die geografische Aufteilung der Szene in kleine Regionen, wie in der Mega-NeRF-Basislinie gezeigt, etwas hilft, scheinen die präsentierten Ergebnisse immer noch zu glatt zu sein. Im Gegenteil, basierend auf dem erlernten Merkmalsgitter wird der Abtastraum von NeRF in der Nähe der Szenenoberfläche effektiv und stark komprimiert. Dichte- und Erscheinungsmerkmale, die von der Bodenmerkmalsebene abgetastet werden, stellen explizit den Inhalt der Szene dar, wie in Abbildung 3 dargestellt. Obwohl weniger genau, liefert es bereits informative lokale Geometrie und Textur und unterstützt die Positionskodierung von NeRF, um fehlende Szenendetails zu erfassen.

Tabelle 1 unten zeigt die quantitativen Ergebnisse:
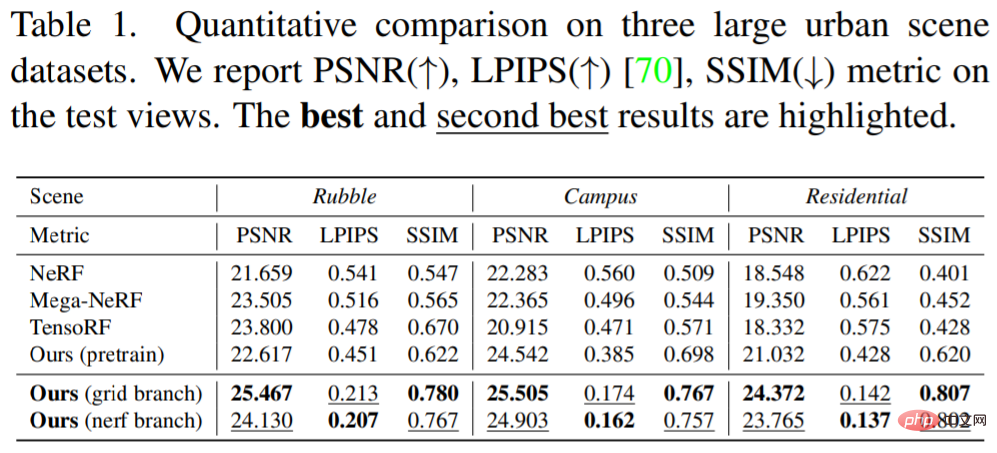
Abbildung 6 Eine schnelle Verbesserung der Wiedergabetreue ist zu beobachten:

Erfahren Sie mehr für Den Inhalt entnehmen Sie bitte dem Originalpapier.
Das obige ist der detaillierte Inhalt vonEffizientes und realistisches Stadtrendering in extrem großem Maßstab: Kombination von NeRF und Feature-Grid-Technologie. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Die Rolle und praktische Anwendung von Pfeilsymbolen in PHP
Mar 22, 2024 am 11:30 AM
Die Rolle und praktische Anwendung von Pfeilsymbolen in PHP
Mar 22, 2024 am 11:30 AM
Die Rolle und praktische Anwendung von Pfeilsymbolen in PHP In PHP wird das Pfeilsymbol (->) normalerweise verwendet, um auf die Eigenschaften und Methoden von Objekten zuzugreifen. Objekte sind eines der Grundkonzepte der objektorientierten Programmierung (OOP) in PHP. In der tatsächlichen Entwicklung spielen Pfeilsymbole eine wichtige Rolle bei der Bedienung von Objekten. In diesem Artikel werden die Rolle und die praktische Anwendung von Pfeilsymbolen vorgestellt und spezifische Codebeispiele bereitgestellt, um den Lesern ein besseres Verständnis zu erleichtern. 1. Die Rolle des Pfeilsymbols für den Zugriff auf die Eigenschaften eines Objekts. Das Pfeilsymbol kann für den Zugriff auf die Eigenschaften eines Objekts verwendet werden. Wenn wir ein Paar instanziieren
 So machen Sie das Löschen vom Startbildschirm im iPhone rückgängig
Apr 17, 2024 pm 07:37 PM
So machen Sie das Löschen vom Startbildschirm im iPhone rückgängig
Apr 17, 2024 pm 07:37 PM
Sie haben etwas Wichtiges von Ihrem Startbildschirm gelöscht und versuchen, es wiederherzustellen? Es gibt verschiedene Möglichkeiten, App-Symbole wieder auf dem Bildschirm anzuzeigen. Wir haben alle Methoden besprochen, die Sie anwenden können, um das App-Symbol wieder auf dem Startbildschirm anzuzeigen. So machen Sie das Entfernen vom Startbildschirm auf dem iPhone rückgängig. Wie bereits erwähnt, gibt es mehrere Möglichkeiten, diese Änderung auf dem iPhone wiederherzustellen. Methode 1 – App-Symbol in der App-Bibliothek ersetzen Sie können ein App-Symbol direkt aus der App-Bibliothek auf Ihrem Startbildschirm platzieren. Schritt 1 – Wischen Sie seitwärts, um alle Apps in der App-Bibliothek zu finden. Schritt 2 – Suchen Sie das App-Symbol, das Sie zuvor gelöscht haben. Schritt 3 – Ziehen Sie einfach das App-Symbol aus der Hauptbibliothek an die richtige Stelle auf dem Startbildschirm. Dies ist das Anwendungsdiagramm
 Vom Anfänger bis zum Experten: Entdecken Sie verschiedene Anwendungsszenarien des Linux-Befehls tee
Mar 20, 2024 am 10:00 AM
Vom Anfänger bis zum Experten: Entdecken Sie verschiedene Anwendungsszenarien des Linux-Befehls tee
Mar 20, 2024 am 10:00 AM
Der Linuxtee-Befehl ist ein sehr nützliches Befehlszeilentool, das Ausgaben in eine Datei schreiben oder an einen anderen Befehl senden kann, ohne die vorhandene Ausgabe zu beeinträchtigen. In diesem Artikel werden wir die verschiedenen Anwendungsszenarien des Linuxtee-Befehls eingehend untersuchen, vom Anfänger bis zum Experten. 1. Grundlegende Verwendung Werfen wir zunächst einen Blick auf die grundlegende Verwendung des Tee-Befehls. Die Syntax des Tee-Befehls lautet wie folgt: tee[OPTION]...[DATEI]...Dieser Befehl liest Daten aus der Standardeingabe und speichert sie dort
 Entdecken Sie die Vorteile und Anwendungsszenarien der Go-Sprache
Mar 27, 2024 pm 03:48 PM
Entdecken Sie die Vorteile und Anwendungsszenarien der Go-Sprache
Mar 27, 2024 pm 03:48 PM
Die Go-Sprache ist eine Open-Source-Programmiersprache, die von Google entwickelt und erstmals 2007 veröffentlicht wurde. Sie ist als einfache, leicht zu erlernende, effiziente Sprache mit hoher Parallelität konzipiert und wird von immer mehr Entwicklern bevorzugt. In diesem Artikel werden die Vorteile der Go-Sprache untersucht, einige für die Go-Sprache geeignete Anwendungsszenarien vorgestellt und spezifische Codebeispiele gegeben. Vorteile: Starke Parallelität: Die Go-Sprache verfügt über eine integrierte Unterstützung für leichtgewichtige Threads-Goroutinen, mit denen die gleichzeitige Programmierung problemlos implementiert werden kann. Goroutine kann mit dem Schlüsselwort go gestartet werden
 Die breite Anwendung von Linux im Bereich Cloud Computing
Mar 20, 2024 pm 04:51 PM
Die breite Anwendung von Linux im Bereich Cloud Computing
Mar 20, 2024 pm 04:51 PM
Die breite Anwendung von Linux im Bereich Cloud Computing Mit der kontinuierlichen Weiterentwicklung und Popularisierung der Cloud-Computing-Technologie spielt Linux als Open-Source-Betriebssystem eine wichtige Rolle im Bereich Cloud Computing. Aufgrund seiner Stabilität, Sicherheit und Flexibilität werden Linux-Systeme häufig in verschiedenen Cloud-Computing-Plattformen und -Diensten eingesetzt und bieten eine solide Grundlage für die Entwicklung der Cloud-Computing-Technologie. In diesem Artikel werden die vielfältigen Einsatzmöglichkeiten von Linux im Bereich Cloud Computing vorgestellt und konkrete Codebeispiele gegeben. 1. Anwendungsvirtualisierungstechnologie von Linux in der Virtualisierungstechnologie der Cloud-Computing-Plattform
 Googles neue Forschung zur verkörperten Intelligenz: RT-H, das besser als RT-2 ist, ist da
Mar 11, 2024 pm 01:10 PM
Googles neue Forschung zur verkörperten Intelligenz: RT-H, das besser als RT-2 ist, ist da
Mar 11, 2024 pm 01:10 PM
Da große Sprachmodelle wie GPT-4 zunehmend in die Robotik integriert werden, hält künstliche Intelligenz allmählich Einzug in die reale Welt. Daher hat auch die Forschung im Zusammenhang mit der verkörperten Intelligenz immer mehr Aufmerksamkeit auf sich gezogen. Bei vielen Forschungsprojekten stand Googles „RT“-Roboterserie schon immer an vorderster Front, und dieser Trend hat sich in letzter Zeit beschleunigt (Einzelheiten siehe „Große Modelle rekonstruieren Roboter, wie Google Deepmind verkörperte Intelligenz in der Zukunft definiert“). Im Juli letzten Jahres brachte Google DeepMind RT-2 auf den Markt, das weltweit erste Modell, das Roboter für die Interaktion mit visueller Sprache und Aktion (VLA) steuern kann. Allein durch das Erteilen von Anweisungen im Gespräch kann RT-2 Swift auf einer großen Anzahl von Bildern identifizieren und ihr eine Dose Cola liefern. Jetzt,
 Verstehen Sie den Mechanismus und die Anwendung der Golang-Stack-Verwaltung
Mar 13, 2024 am 11:21 AM
Verstehen Sie den Mechanismus und die Anwendung der Golang-Stack-Verwaltung
Mar 13, 2024 am 11:21 AM
Golang ist eine von Google entwickelte Open-Source-Programmiersprache, die über viele einzigartige Funktionen in der gleichzeitigen Programmierung und Speicherverwaltung verfügt. Unter diesen ist der Stapelverwaltungsmechanismus von Golang ein wichtiges Merkmal. Dieser Artikel konzentriert sich auf den Mechanismus und die Anwendung der Stapelverwaltung von Golang und gibt spezifische Codebeispiele. 1. Stapelverwaltung in Golang In Golang hat jede Goroutine ihren eigenen Stapel. Der Stapel wird zum Speichern von Informationen wie Parametern, lokalen Variablen und Funktionsrückgabeadressen von Funktionsaufrufen verwendet.
 MySQL-Zeitstempel verstehen: Funktionen, Features und Anwendungsszenarien
Mar 15, 2024 pm 04:36 PM
MySQL-Zeitstempel verstehen: Funktionen, Features und Anwendungsszenarien
Mar 15, 2024 pm 04:36 PM
Der MySQL-Zeitstempel ist ein sehr wichtiger Datentyp, der Datum, Uhrzeit oder Datum plus Uhrzeit speichern kann. Im eigentlichen Entwicklungsprozess kann die rationelle Verwendung von Zeitstempeln die Effizienz von Datenbankoperationen verbessern und zeitbezogene Abfragen und Berechnungen erleichtern. In diesem Artikel werden die Funktionen, Features und Anwendungsszenarien von MySQL-Zeitstempeln erläutert und anhand spezifischer Codebeispiele erläutert. 1. Funktionen und Eigenschaften von MySQL-Zeitstempeln In MySQL gibt es zwei Arten von Zeitstempeln, einer ist TIMESTAMP
