
 Technologie-Peripheriegeräte
KI
A100 implementiert eine 3D-Rekonstruktionsmethode ohne 3D-Faltung und benötigt für jede Frame-Rekonstruktion nur 70 ms
Technologie-Peripheriegeräte
KI
A100 implementiert eine 3D-Rekonstruktionsmethode ohne 3D-Faltung und benötigt für jede Frame-Rekonstruktion nur 70 ms
A100 implementiert eine 3D-Rekonstruktionsmethode ohne 3D-Faltung und benötigt für jede Frame-Rekonstruktion nur 70 ms

Die Rekonstruktion von 3D-Innenszenen aus Posenbildern gliedert sich normalerweise in zwei Phasen: Schätzung der Bildtiefe, gefolgt von Tiefenzusammenführung und Oberflächenrekonstruktion. Kürzlich haben mehrere Studien eine Reihe von Methoden vorgeschlagen, die die Rekonstruktion direkt im endgültigen volumetrischen 3D-Merkmalsraum durchführen. Obwohl diese Methoden beeindruckende Rekonstruktionsergebnisse erzielt haben, basieren sie auf teuren 3D-Faltungsschichten, was ihre Anwendung in ressourcenbeschränkten Umgebungen einschränkt.
Jetzt versuchen Forscher von Institutionen wie Niantic und UCL, traditionelle Methoden wiederzuverwenden und sich auf eine qualitativ hochwertige Multi-View-Tiefenvorhersage zu konzentrieren, um schließlich mithilfe einfacher und handelsüblicher Tiefenfusionsmethoden eine hochpräzise 3D-Rekonstruktion zu erreichen .

- Papieradresse: https://nianticlabs.github.io/simplerecon/resources/SimpleRecon.pdf
- GitHub-Adresse: https://github.com /nianticlabs/simplerecon Sorgfältig entworfenes 2D-CNN. Die vorgeschlagene Methode SimpleRecon erzielt deutlich führende Ergebnisse bei der Tiefenschätzung und ermöglicht eine Online-Echtzeit-Rekonstruktion mit geringem Speicherbedarf.
- Wie in der Abbildung unten gezeigt, ist die Rekonstruktionsgeschwindigkeit von SimpleRecon sehr hoch und dauert nur etwa 70 ms pro Frame. Die Vergleichsergebnisse zwischen
SimpleRecon und anderen Methoden lauten wie folgt:
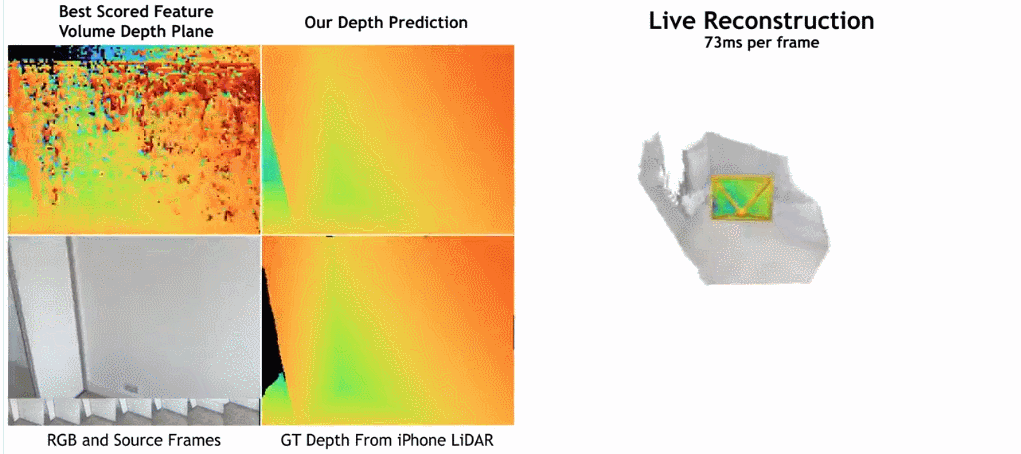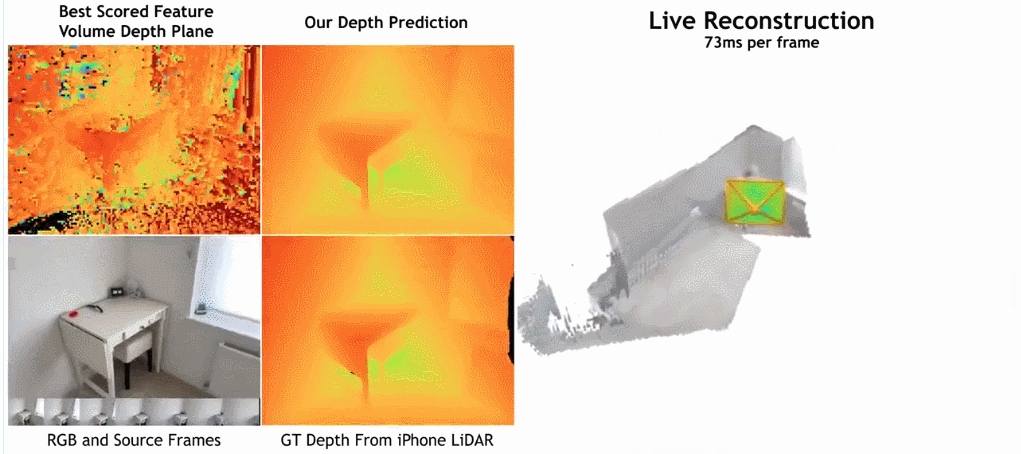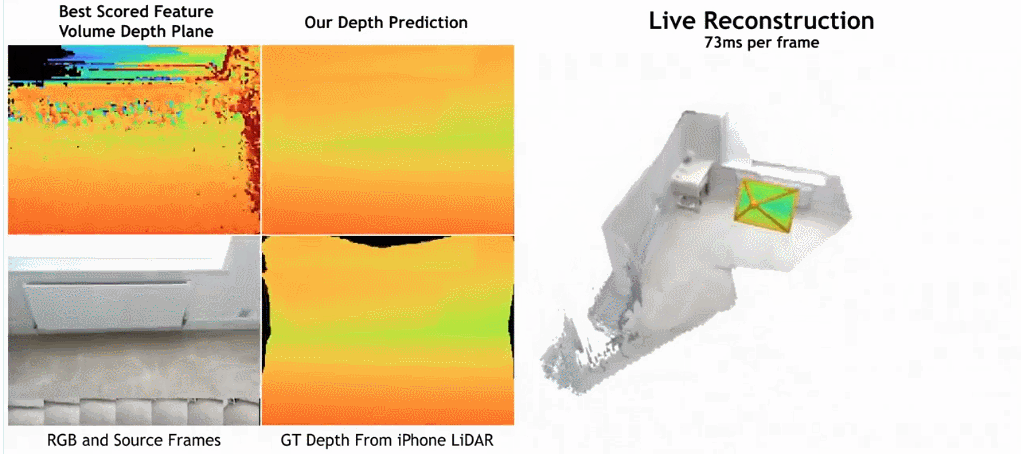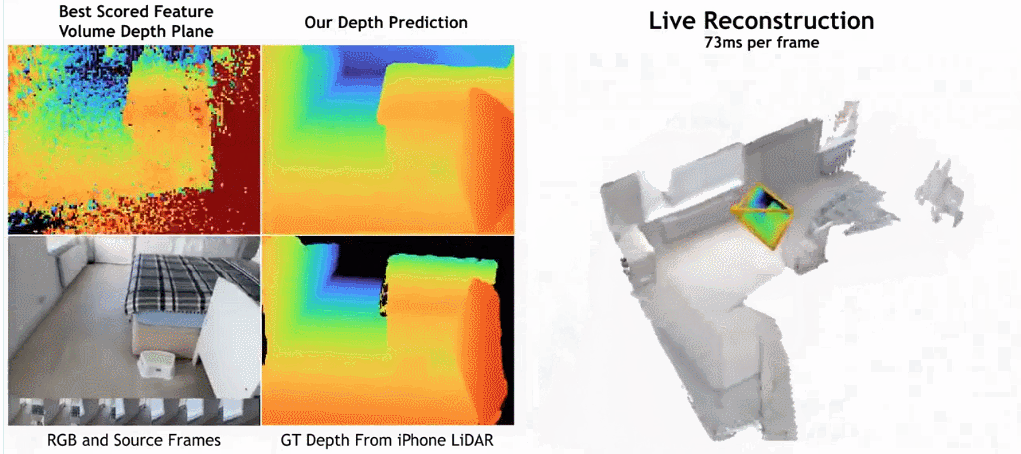 Methode
Methode
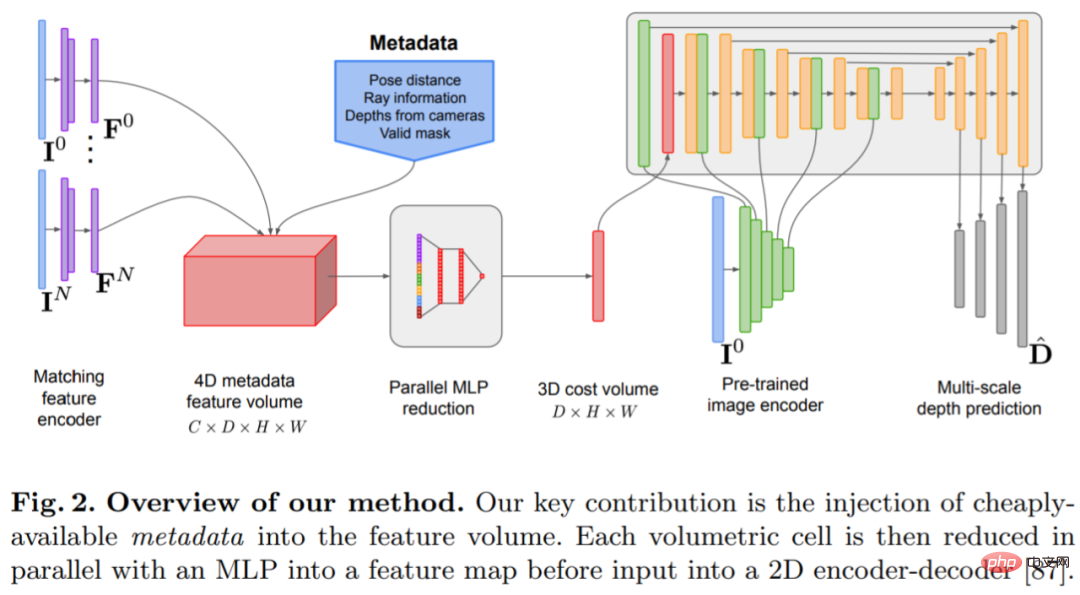
Das Tiefenschätzungsmodell befindet sich am Schnittpunkt von monokularer Tiefenschätzung und planarem Scanning MVS. Der Forscher nutzt das Kostenvolumen (Kostenvolumen), um die Encoder-Decoder-Architektur für die Tiefenvorhersage zu erhöhen, wie in Abbildung 2 dargestellt. Der Bildencoder extrahiert passende Merkmale aus den Referenz- und Quellbildern als Eingabe für das Kostenvolumen. Zur Verarbeitung der Ausgabe des Kostenvolumens wird ein 2D-Faltungs-Encoder-Decoder-Netzwerk verwendet, das durch Merkmale auf Bildebene ergänzt wird, die von einem separaten vorab trainierten Bildencoder extrahiert werden.

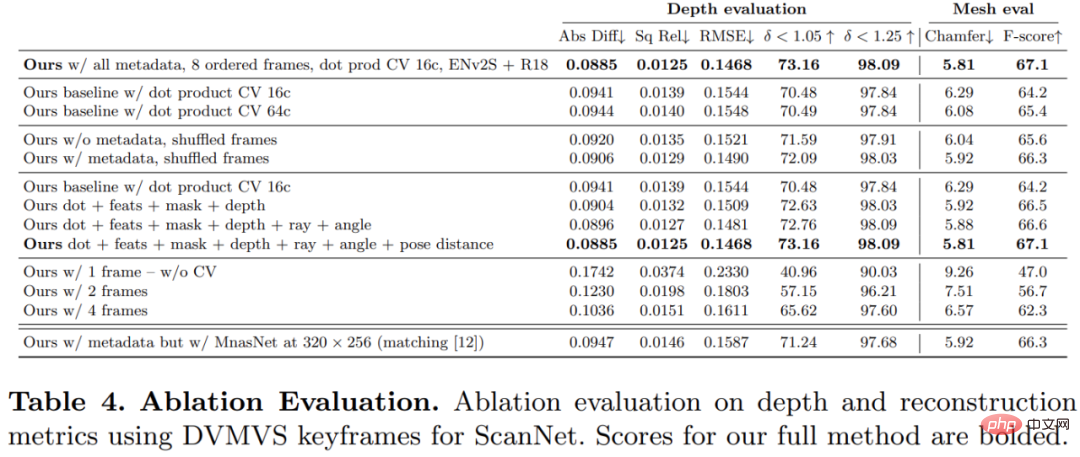
 Der Schlüssel zu dieser Forschung besteht darin, vorhandene Metadaten zusammen mit typischen Tiefenbildfunktionen in das Kostenvolumen einzufügen, um dem Netzwerk den Zugriff auf nützliche Informationen wie Geometrie und relative Kamerapositionsinformationen zu ermöglichen. Abbildung 3 zeigt den Aufbau des Feature-Volumes im Detail. Durch die Integration dieser bisher unerschlossenen Informationen ist unser Modell in der Lage, frühere Methoden in der Tiefenvorhersage deutlich zu übertreffen, ohne teure 4D-Kostenvolumina, komplexe zeitliche Fusion und Gaußsche Prozesse.
Der Schlüssel zu dieser Forschung besteht darin, vorhandene Metadaten zusammen mit typischen Tiefenbildfunktionen in das Kostenvolumen einzufügen, um dem Netzwerk den Zugriff auf nützliche Informationen wie Geometrie und relative Kamerapositionsinformationen zu ermöglichen. Abbildung 3 zeigt den Aufbau des Feature-Volumes im Detail. Durch die Integration dieser bisher unerschlossenen Informationen ist unser Modell in der Lage, frühere Methoden in der Tiefenvorhersage deutlich zu übertreffen, ohne teure 4D-Kostenvolumina, komplexe zeitliche Fusion und Gaußsche Prozesse.
Die Studie wurde mit PyTorch implementiert und verwendete EfficientNetV2 S als Rückgrat, das über einen UNet++-ähnlichen Decoder verfügt. Darüber hinaus wurden auch die ersten beiden Blöcke von ResNet18 für die Matching-Feature-Extraktion verwendet, und der Optimierer war AdamW, dessen Fertigstellung auf zwei 40-GB-A100-GPUs 36 Stunden dauerte.
Das Netzwerk wird basierend auf der 2D-Faltungs-Encoder-Decoder-Architektur implementiert. Untersuchungen haben ergeben, dass es beim Aufbau eines solchen Netzwerks einige wichtige Entwurfsentscheidungen gibt, die die Genauigkeit der Tiefenvorhersage erheblich verbessern können, darunter vor allem:
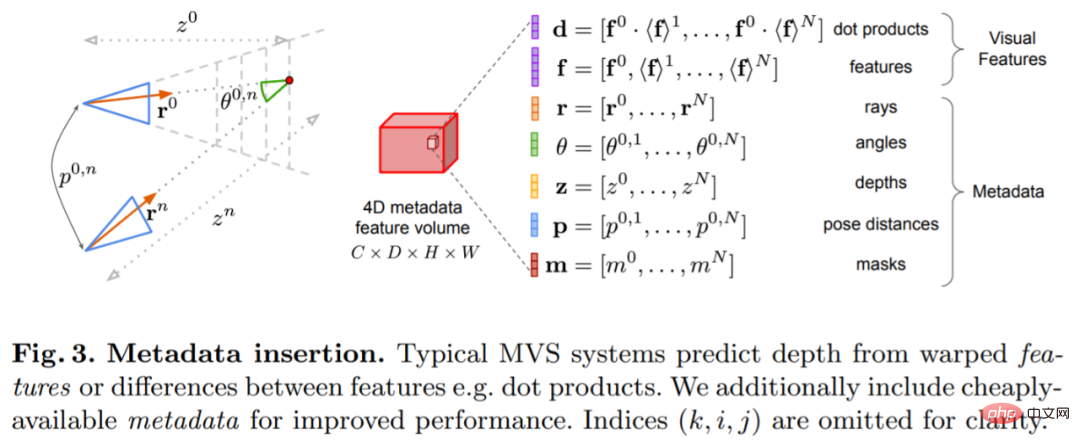
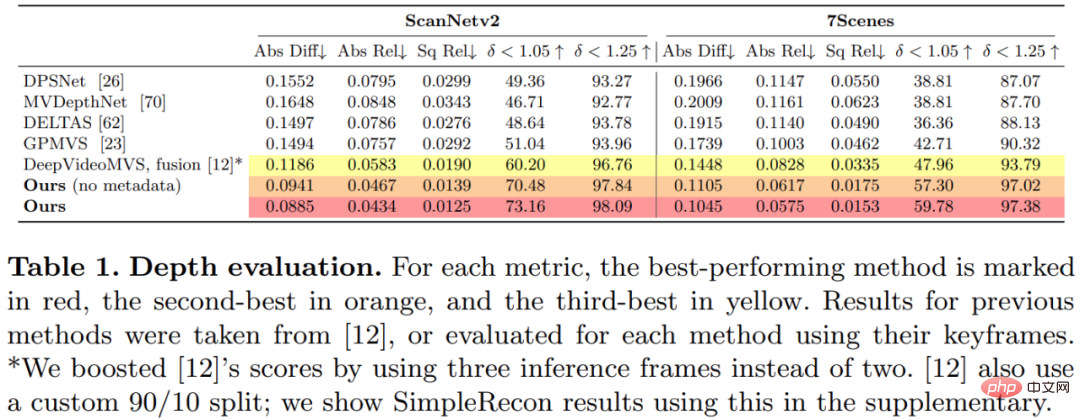
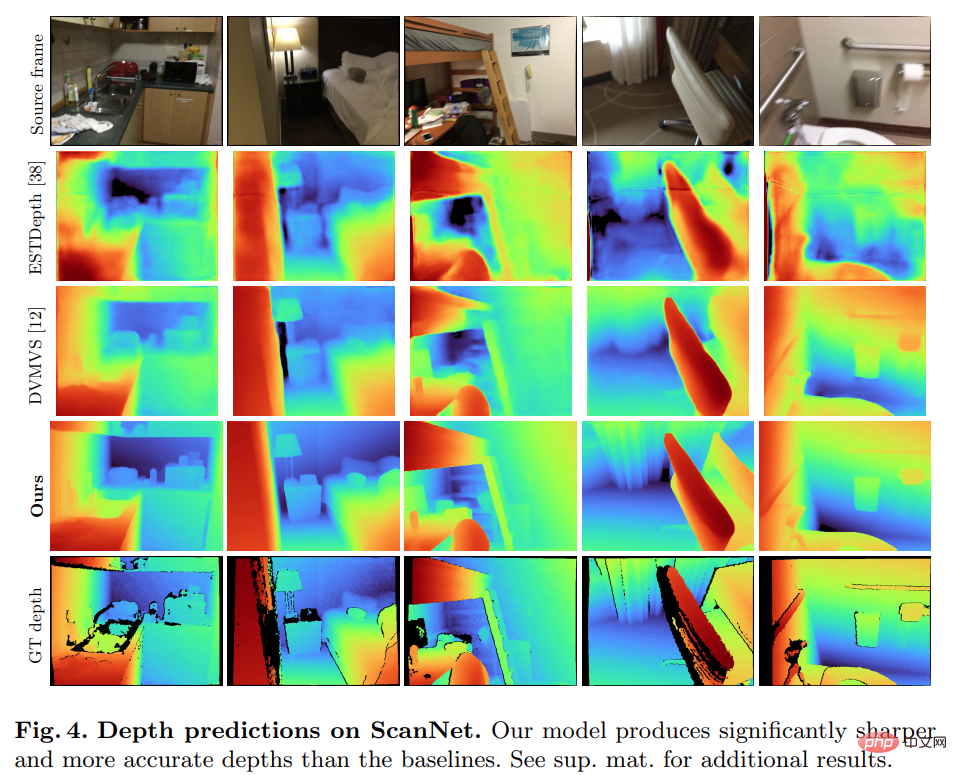
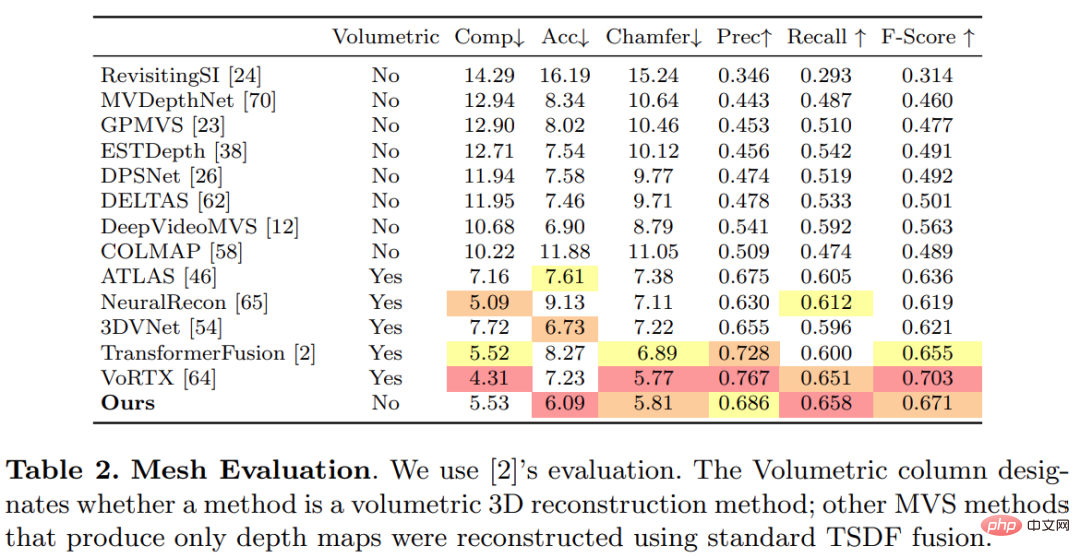
Bild-Encoder und Feature-Matching-Encoder: Frühere Untersuchungen haben gezeigt, dass der Bild-Encoder für die Tiefenschätzung sowohl bei der monokularen als auch bei der Multi-View-Schätzung sehr wichtig ist. DeepVideoMVS verwendet beispielsweise MnasNet als Bildencoder, der eine relativ geringe Latenz aufweist. Die Studie empfiehlt die Verwendung eines kleinen, aber leistungsstärkeren EfficientNetv2 S-Encoders, der die Genauigkeit der Tiefenschätzung deutlich verbessert, allerdings auf Kosten einer höheren Anzahl von Parametern und einer Reduzierung der Ausführungsgeschwindigkeit um 10 %. Verschmelzung von Bildmerkmalen mit mehreren Maßstäben in einem Kostenvolumen-Encoder: Bei 2D-CNN-basiertem Tiefenstereo und Multi-View-Stereo werden Bildmerkmale normalerweise mit der Kostenvolumenausgabe in einem einzigen Maßstab kombiniert. Kürzlich schlägt DeepVideoMVS vor, Deep-Image-Features in mehreren Maßstäben zusammenzufügen und bei allen Auflösungen Sprungverbindungen zwischen Bild-Encodern und Kostenvolumen-Encodern hinzuzufügen. Dies ist hilfreich für LSTM-basierte Fusionsnetzwerke und die Studie ergab, dass es auch für deren Architektur wichtig ist. Diese Studie trainierte und evaluierte die vorgeschlagene Methode anhand des 3D-Szenenrekonstruktionsdatensatzes ScanNetv2. In der folgenden Tabelle 1 werden die von Eigen et al. (2014) vorgeschlagenen Metriken verwendet, um die Tiefenvorhersageleistung mehrerer Netzwerkmodelle zu bewerten. Überraschenderweise verwendet das in dieser Studie vorgeschlagene Modell keine 3D-Faltung, übertrifft aber alle Basismodelle hinsichtlich der Tiefenvorhersageindikatoren. Darüber hinaus schneiden Basismodelle, die keine Metadatenkodierung verwenden, auch besser ab als frühere Methoden, was darauf hindeutet, dass ein gut entworfenes und trainiertes 2D-Netzwerk für eine qualitativ hochwertige Tiefenschätzung ausreicht. Die Abbildungen 4 und 5 unten zeigen qualitative Ergebnisse für Tiefe und Normal. Diese Studie verwendete das von TransformerFusion entwickelte Standardprotokoll für die 3D-Rekonstruktionsbewertung. Die Ergebnisse sind in Tabelle 2 unten aufgeführt. Für Online- und interaktive 3D-Rekonstruktionsanwendungen ist die Reduzierung der Sensorlatenz von entscheidender Bedeutung. Tabelle 3 unten zeigt die Ensemble-Rechenzeit pro Frame für jedes Modell bei einem neuen RGB-Frame. Um die Wirksamkeit jeder Komponente der in dieser Studie vorgeschlagenen Methode zu überprüfen, führte der Forscher ein Ablationsexperiment durch. Die Ergebnisse sind in Tabelle 4 unten aufgeführt. Interessierte Leser können den Originaltext des Artikels lesen, um weitere Forschungsdetails zu erfahren. Experimente


Das obige ist der detaillierte Inhalt vonA100 implementiert eine 3D-Rekonstruktionsmethode ohne 3D-Faltung und benötigt für jede Frame-Rekonstruktion nur 70 ms. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

![WLAN-Erweiterungsmodul ist gestoppt [Fix]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) WLAN-Erweiterungsmodul ist gestoppt [Fix]
Feb 19, 2024 pm 02:18 PM
WLAN-Erweiterungsmodul ist gestoppt [Fix]
Feb 19, 2024 pm 02:18 PM
Wenn es ein Problem mit dem WLAN-Erweiterungsmodul Ihres Windows-Computers gibt, kann dies dazu führen, dass Sie nicht mehr mit dem Internet verbunden sind. Diese Situation ist oft frustrierend, aber glücklicherweise enthält dieser Artikel einige einfache Vorschläge, die Ihnen helfen können, dieses Problem zu lösen und Ihre drahtlose Verbindung wieder ordnungsgemäß funktionieren zu lassen. Behebung, dass das WLAN-Erweiterbarkeitsmodul nicht mehr funktioniert Wenn das WLAN-Erweiterbarkeitsmodul auf Ihrem Windows-Computer nicht mehr funktioniert, befolgen Sie diese Vorschläge, um das Problem zu beheben: Führen Sie die Netzwerk- und Internet-Fehlerbehebung aus, um drahtlose Netzwerkverbindungen zu deaktivieren und wieder zu aktivieren. Starten Sie den WLAN-Autokonfigurationsdienst neu. Ändern Sie die Energieoptionen. Ändern Erweiterte Energieeinstellungen Netzwerkadaptertreiber neu installieren Einige Netzwerkbefehle ausführen Schauen wir uns das nun im Detail an
 So beheben Sie einen Win11-DNS-Serverfehler
Jan 10, 2024 pm 09:02 PM
So beheben Sie einen Win11-DNS-Serverfehler
Jan 10, 2024 pm 09:02 PM
Um auf das Internet zuzugreifen, müssen wir beim Herstellen einer Verbindung zum Internet das richtige DNS verwenden. Wenn wir die falschen DNS-Einstellungen verwenden, wird auf die gleiche Weise ein DNS-Serverfehler angezeigt. Zu diesem Zeitpunkt können wir versuchen, das Problem zu lösen, indem wir in den Netzwerkeinstellungen auswählen, ob DNS automatisch abgerufen werden soll Lösungen. So beheben Sie den Win11-Netzwerk-DNS-Serverfehler. Methode 1: DNS zurücksetzen 1. Klicken Sie zunächst in der Taskleiste auf „Start“, suchen Sie die Symbolschaltfläche „Einstellungen“ und klicken Sie darauf. 2. Klicken Sie dann in der linken Spalte auf den Optionsbefehl „Netzwerk & Internet“. 3. Suchen Sie dann rechts die Option „Ethernet“ und klicken Sie zur Eingabe. 4. Klicken Sie anschließend in der DNS-Serverzuweisung auf „Bearbeiten“ und stellen Sie schließlich DNS auf „Automatisch (D.)“ ein
 Beheben Sie „fehlgeschlagene Netzwerkfehler'-Downloads auf Chrome, Google Drive und Fotos!
Oct 27, 2023 pm 11:13 PM
Beheben Sie „fehlgeschlagene Netzwerkfehler'-Downloads auf Chrome, Google Drive und Fotos!
Oct 27, 2023 pm 11:13 PM
Was ist das Problem „Download aufgrund eines Netzwerkfehlers fehlgeschlagen“? Bevor wir uns mit den Lösungen befassen, wollen wir zunächst verstehen, was das Problem „Netzwerkfehler-Download fehlgeschlagen“ bedeutet. Dieser Fehler tritt normalerweise auf, wenn die Netzwerkverbindung während des Downloads unterbrochen wird. Dies kann verschiedene Gründe haben, wie z. B. eine schwache Internetverbindung, Netzwerküberlastung oder Serverprobleme. Wenn dieser Fehler auftritt, wird der Download gestoppt und eine Fehlermeldung angezeigt. Wie kann ein fehlgeschlagener Download mit Netzwerkfehler behoben werden? Die Meldung „Netzwerkfehler beim Herunterladen fehlgeschlagen“ kann beim Zugriff auf oder beim Herunterladen erforderlicher Dateien zu einem Hindernis werden. Unabhängig davon, ob Sie Browser wie Chrome oder Plattformen wie Google Drive und Google Fotos verwenden, wird dieser Fehler auftreten und Unannehmlichkeiten verursachen. Nachfolgend finden Sie Punkte, die Ihnen bei der Navigation und Lösung dieses Problems helfen sollen
 Fix: WD My Cloud wird unter Windows 11 nicht im Netzwerk angezeigt
Oct 02, 2023 pm 11:21 PM
Fix: WD My Cloud wird unter Windows 11 nicht im Netzwerk angezeigt
Oct 02, 2023 pm 11:21 PM
Wenn WDMyCloud unter Windows 11 nicht im Netzwerk angezeigt wird, kann dies ein großes Problem sein, insbesondere wenn Sie Backups oder andere wichtige Dateien darin speichern. Dies kann ein großes Problem für Benutzer sein, die häufig auf Netzwerkspeicher zugreifen müssen. In der heutigen Anleitung zeigen wir Ihnen daher, wie Sie dieses Problem dauerhaft beheben können. Warum wird WDMyCloud nicht im Windows 11-Netzwerk angezeigt? Ihr MyCloud-Gerät, Ihr Netzwerkadapter oder Ihre Internetverbindung sind nicht richtig konfiguriert. Die SMB-Funktion ist nicht auf dem Computer installiert. Dieses Problem kann manchmal durch einen vorübergehenden Fehler in Winsock verursacht werden. Was soll ich tun, wenn meine Cloud nicht im Netzwerk angezeigt wird? Bevor wir mit der Behebung des Problems beginnen, können Sie einige Vorprüfungen durchführen:
 Was soll ich tun, wenn die Erde in der unteren rechten Ecke von Windows 10 angezeigt wird, wenn ich nicht auf das Internet zugreifen kann? Verschiedene Lösungen für das Problem, dass die Erde in Win10 nicht auf das Internet zugreifen kann
Feb 29, 2024 am 09:52 AM
Was soll ich tun, wenn die Erde in der unteren rechten Ecke von Windows 10 angezeigt wird, wenn ich nicht auf das Internet zugreifen kann? Verschiedene Lösungen für das Problem, dass die Erde in Win10 nicht auf das Internet zugreifen kann
Feb 29, 2024 am 09:52 AM
In diesem Artikel wird die Lösung für das Problem vorgestellt, dass das Globussymbol im Win10-Systemnetzwerk angezeigt wird, aber nicht auf das Internet zugreifen kann. Der Artikel enthält detaillierte Schritte, die den Lesern helfen sollen, das Problem des Win10-Netzwerks zu lösen, das zeigt, dass die Erde keinen Zugriff auf das Internet hat. Methode 1: Direkt neu starten. Überprüfen Sie zunächst, ob das Netzwerkkabel nicht richtig eingesteckt ist und ob das Breitband im Rückstand ist. In diesem Fall müssen Sie den Router oder das optische Modem neu starten. Wenn auf dem Computer keine wichtigen Dinge erledigt werden, können Sie den Computer direkt neu starten. Die meisten kleineren Probleme können durch einen Neustart des Computers schnell behoben werden. Wenn festgestellt wird, dass die Breitbandanbindung nicht im Rückstand ist und das Netzwerk normal ist, ist das eine andere Sache. Methode 2: 1. Drücken Sie die [Win]-Taste oder klicken Sie auf [Startmenü] in der unteren linken Ecke. Klicken Sie im sich öffnenden Menüelement auf das Zahnradsymbol über dem Netzschalter.
 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Überprüfen Sie die Netzwerkverbindung: lol kann keine Verbindung zum Server herstellen
Feb 19, 2024 pm 12:10 PM
Überprüfen Sie die Netzwerkverbindung: lol kann keine Verbindung zum Server herstellen
Feb 19, 2024 pm 12:10 PM
LOL kann keine Verbindung zum Server herstellen. Bitte überprüfen Sie das Netzwerk. In den letzten Jahren sind Online-Spiele für viele Menschen zu einer täglichen Unterhaltungsaktivität geworden. Unter ihnen ist League of Legends (LOL) ein sehr beliebtes Multiplayer-Onlinespiel, das die Teilnahme und das Interesse von Hunderten Millionen Spielern auf sich zieht. Wenn wir jedoch LOL spielen, stoßen wir manchmal auf die Fehlermeldung „Verbindung zum Server nicht möglich, bitte überprüfen Sie das Netzwerk“, was den Spielern zweifellos einige Probleme bereitet. Als nächstes werden wir die Ursachen und Lösungen dieses Fehlers besprechen. Zunächst besteht möglicherweise das Problem, dass LOL keine Verbindung zum Server herstellen kann
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
