
 Technologie-Peripheriegeräte
KI
Meta veröffentlicht Open-Source-Multifunktions-Großmodelle, um der visuellen Vereinheitlichung einen Schritt näher zu kommen
Technologie-Peripheriegeräte
KI
Meta veröffentlicht Open-Source-Multifunktions-Großmodelle, um der visuellen Vereinheitlichung einen Schritt näher zu kommen
Meta veröffentlicht Open-Source-Multifunktions-Großmodelle, um der visuellen Vereinheitlichung einen Schritt näher zu kommen

Nach dem Open-Source-SAM-Modell, das „alles teilt“, geht Meta immer weiter auf dem Weg zum „visuellen Basismodell“.
Dieses Mal haben sie eine Reihe von Modellen namens DINOv2 als Open Source bereitgestellt. Diese Modelle können leistungsstarke visuelle Darstellungen erzeugen, die ohne Feinabstimmung für nachgelagerte Aufgaben wie Klassifizierung, Segmentierung, Bildabruf und Tiefenschätzung verwendet werden können.
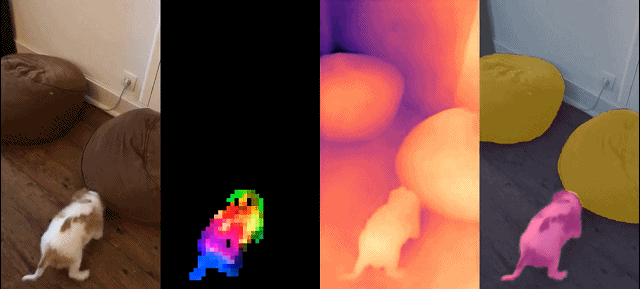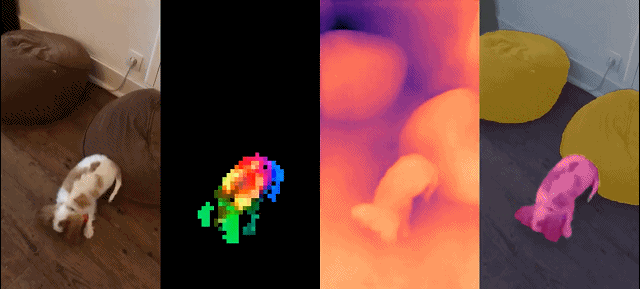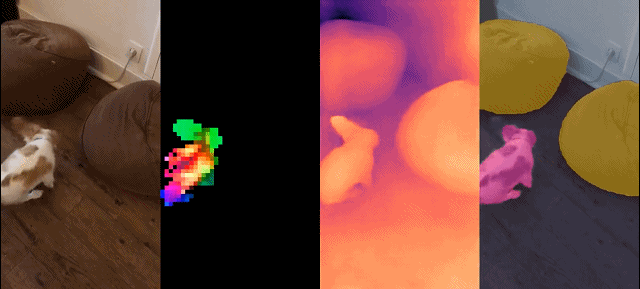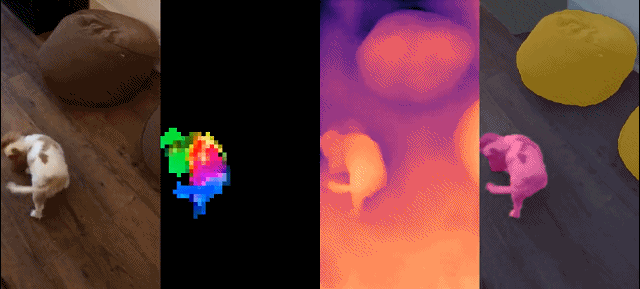
Dieser Satz von Modellen hat die folgenden Eigenschaften: #
- Nutzen Sie selbstüberwachtes Training, ohne dass eine große Menge an gekennzeichneten Daten erforderlich ist;
- # 🎜🎜##🎜 🎜# kann ohne Feinabstimmung als Rückgrat für fast alle Lebenslaufaufgaben verwendet werden, z. B. Bildklassifizierung, Segmentierung, Bildabruf und Tiefenschätzung; aus Bildern, ohne auf Textbeschreibungen angewiesen zu sein, kann das Modell lokale Informationen besser verstehen; # #🎜 🎜# Eine vorab trainierte Version von DINOv2 ist bereits verfügbar und ist bei einer Reihe von Aufgaben mit CLIP und OpenCLIP vergleichbar.
- Papierlink: https://arxiv.org /pdf/2304.07193.pdf
- Projektlink: https://dinov2.metademolab.com/

- Das Erlernen nicht aufgabenspezifischer vorab trainierter Darstellungen ist zu einem Standard in der Verarbeitung natürlicher Sprache geworden. Sie können diese Funktionen „wie sie sind“ verwenden (keine Feinabstimmung erforderlich) und sie erzielen bei nachgelagerten Aufgaben eine deutlich bessere Leistung als aufgabenspezifische Modelle. Dieser Erfolg ist auf das Vortraining großer Rohtextmengen unter Verwendung von Hilfszielen wie Sprachmodellierung oder Wortvektoren zurückzuführen, die keiner Aufsicht bedürfen. Da dieser Paradigmenwechsel im Bereich NLP stattfindet, wird erwartet, dass ähnliche „grundlegende“ Modelle in der Computer Vision entstehen werden. Diese Modelle sollten visuelle Funktionen generieren, die bei jeder Aufgabe „out of the box“ funktionieren, sei es auf Bildebene (z. B. Bildklassifizierung) oder Pixelebene (z. B. Segmentierung).
- Diese Grundmodelle konzentrieren sich stark auf das textgesteuerte Vortraining, das heißt, sie verwenden eine Form der Textüberwachung, um das Trainieren von Funktionen zu leiten. Diese Form des textgesteuerten Vortrainings schränkt die Informationen über das Bild ein, die gespeichert werden können, da die Bildunterschrift die umfangreichen Informationen im Bild nur annähernd wiedergibt und feinere, komplexe Informationen auf Pixelebene bei dieser Überwachung möglicherweise nicht entdeckt werden. Darüber hinaus erfordern diese Bildencoder bereits ausgerichtete Text-Bild-Korpora und bieten nicht die Flexibilität ihrer Text-Gegenstücke, d. h. sie können nicht allein aus Rohdaten lernen.
Eine Alternative zum textgesteuerten Vortraining ist selbstüberwachtes Lernen, bei dem Funktionen ausschließlich aus Bildern gelernt werden. Diese Methoden sind konzeptionell näher an Front-End-Aufgaben wie der Sprachmodellierung und können Informationen auf Bild- und Pixelebene erfassen. Trotz ihres Potenzials zum Erlernen allgemeiner Funktionen wurden die meisten Verbesserungen beim selbstüberwachten Lernen jedoch im Kontext des Vortrainings mit dem kleinen, verfeinerten Datensatz ImageNet1k erzielt. Einige Forscher haben einige Anstrengungen unternommen, diese Methoden über ImageNet-1k hinaus zu erweitern, sie konzentrierten sich jedoch auf ungefilterte Datensätze, was häufig zu einer erheblichen Verschlechterung der Leistungsqualität führte. Dies liegt an der mangelnden Kontrolle über die Datenqualität und -vielfalt, die für die Erzielung guter Ergebnisse von entscheidender Bedeutung sind.
In dieser Arbeit untersuchen Forscher, ob selbstüberwachtes Lernen möglich ist, um allgemeine visuelle Merkmale zu erlernen, wenn es vorab auf einer großen Menge verfeinerter Daten trainiert wird. Sie überdenken bestehende diskriminierende selbstüberwachte Methoden, die Funktionen auf Bild- und Patchebene lernen, wie z. B. iBOT, und überdenken einige ihrer Designentscheidungen anhand größerer Datensätze. Die meisten unserer technischen Beiträge sind darauf zugeschnitten, diskriminierendes selbstüberwachtes Lernen bei der Skalierung von Modell- und Datengrößen zu stabilisieren und zu beschleunigen. Diese Verbesserungen machten ihre Methode ungefähr doppelt so schnell und benötigten 1/3 weniger Speicher als ähnliche diskriminierende selbstüberwachte Methoden, sodass sie von längerem Training und größeren Batchgrößen profitieren konnten.
In Bezug auf die Daten vor dem Training haben sie eine automatisierte Pipeline erstellt, um den Datensatz aus einer großen Sammlung ungefilterter Bilder zu filtern und neu auszugleichen. Dies ist von Pipelines inspiriert, die in NLP verwendet werden, wo Datenähnlichkeit anstelle externer Metadaten verwendet wird und keine manuelle Annotation erforderlich ist. Eine große Schwierigkeit bei der Verarbeitung von Bildern besteht darin, Konzepte neu auszubalancieren und eine Überanpassung in einigen vorherrschenden Modi zu vermeiden. In dieser Arbeit kann die naive Clustering-Methode dieses Problem gut lösen, und die Forscher sammelten einen kleinen, aber vielfältigen Korpus bestehend aus 142 Millionen Bildern, um ihre Methode zu validieren.
Schließlich stellen die Forscher verschiedene vorab trainierte Vision-Modelle namens DINOv2 bereit, die auf ihren Daten mithilfe verschiedener Visual Transformer (ViT)-Architekturen trainiert werden. Sie haben alle Modelle und Codes veröffentlicht, um DINOv2 auf beliebigen Daten neu zu trainieren. Bei der Erweiterung validierten sie die Qualität von DINOv2 anhand verschiedener Computer-Vision-Benchmarks auf Bild- und Pixelebene, wie in Abbildung 2 dargestellt. Wir kommen zu dem Schluss, dass selbstüberwachtes Vortraining allein ein guter Kandidat für das Erlernen übertragbarer eingefrorener Funktionen ist, vergleichbar mit den besten öffentlich verfügbaren, schwach überwachten Modellen.
Datenverarbeitung
Die Forscher stellten ihren verfeinerten LVD-142M-Datensatz zusammen, indem sie Bilder aus einer großen Menge ungefilterter Daten abgerufen haben, die den Bildern in mehreren verfeinerten Datensätzen nahe kamen. In ihrem Artikel beschreiben sie die Hauptkomponenten der Datenpipeline, einschließlich kuratierter/ungefilterter Datenquellen, Schritte zur Bilddeduplizierung und Abrufsysteme. Die gesamte Pipeline benötigt keine Metadaten oder Text und verarbeitet Bilder direkt, wie in Abbildung 3 dargestellt. Für weitere Einzelheiten zur Modellmethodik wird der Leser auf Anhang A verwiesen.
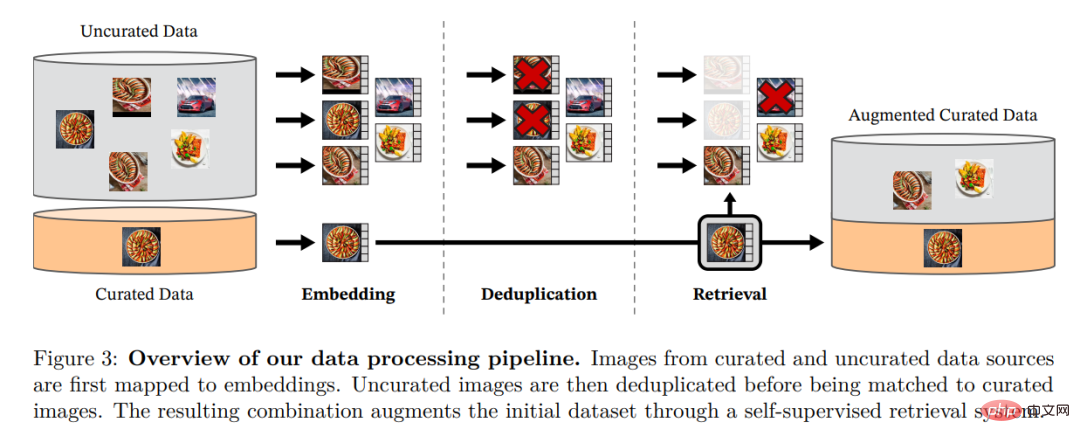
Abbildung 3: Übersicht über die Datenverarbeitungspipeline. Bilder aus verfeinerten und nicht verfeinerten Datenquellen werden zunächst Einbettungen zugeordnet. Das nicht verfeinerte Bild wird dann dedupliziert, bevor es mit dem Standardbild abgeglichen wird. Die resultierende Kombination bereichert den ursprünglichen Datensatz durch ein selbstüberwachtes Abrufsystem weiter.
Diskriminatives selbstüberwachtes Vortraining
Die Forscher lernten ihre Merkmale durch einen diskriminierenden selbstüberwachten Ansatz, der als eine Kombination aus DINO- und iBOT-Verlusten betrachtet werden kann, die sich auf SwAV konzentrieren. Sie fügten außerdem einen Regularisierer zur Verbreitung von Funktionen und eine kurze hochauflösende Trainingsphase hinzu.
Effiziente Implementierung
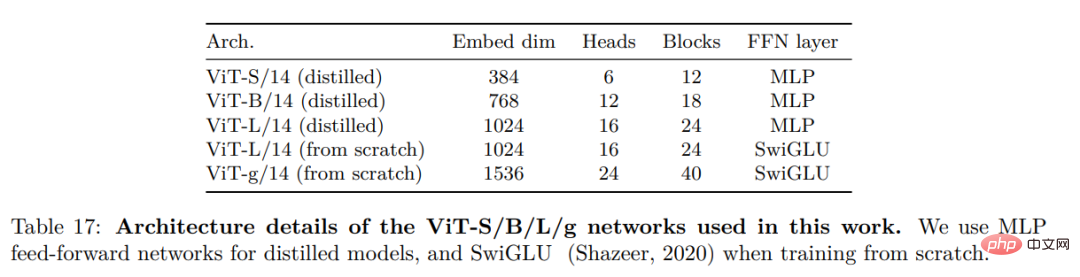
Sie erwogen mehrere Verbesserungen, um das Modell in größerem Maßstab zu trainieren. Das Modell wird auf einer A100-GPU mit PyTorch 2.0 trainiert, und der Code kann auch mit einem vorab trainierten Modell zur Merkmalsextraktion verwendet werden. Einzelheiten zum Modell finden Sie in Anhang Tabelle 17. Auf derselben Hardware nutzt der DINOv2-Code nur 1/3 des Speichers und läuft 2-mal schneller als die iBOT-Implementierung.
Experimentelle Ergebnisse
In diesem Abschnitt stellen die Forscher die empirische Bewertung des neuen Modells für eine Reihe von Bildverständnisaufgaben vor. Sie bewerteten globale und lokale Bilddarstellungen, einschließlich Erkennung auf Kategorie- und Instanzebene, semantische Segmentierung, monokulare Tiefenvorhersage und Aktionserkennung.
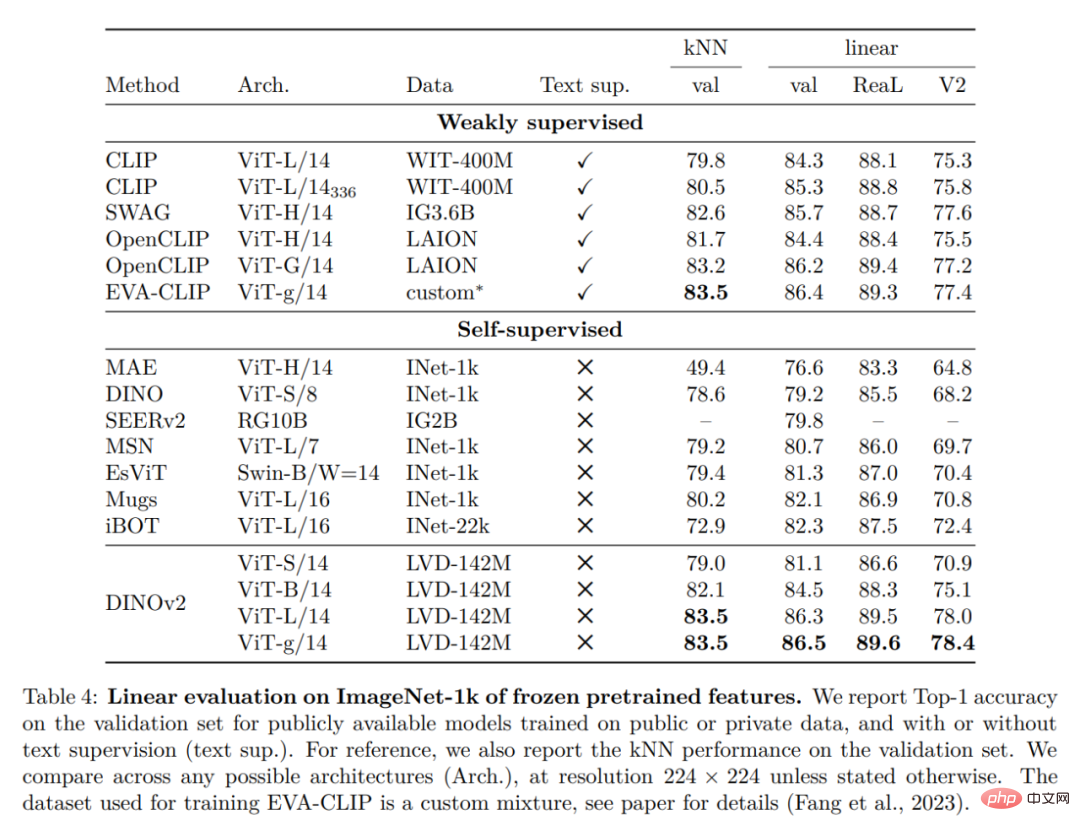
ImageNet-Klassifizierung
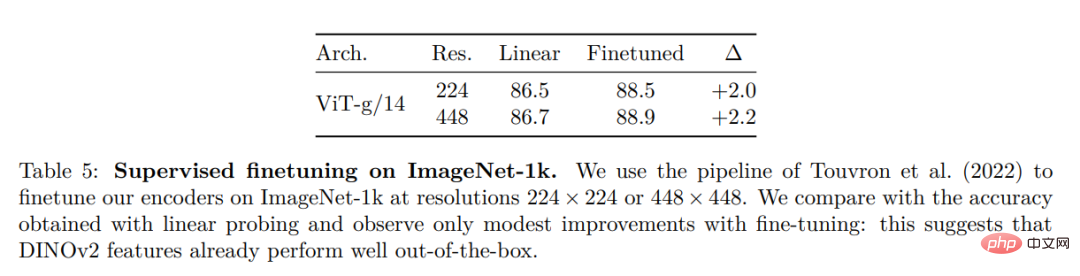
Instanzerkennung
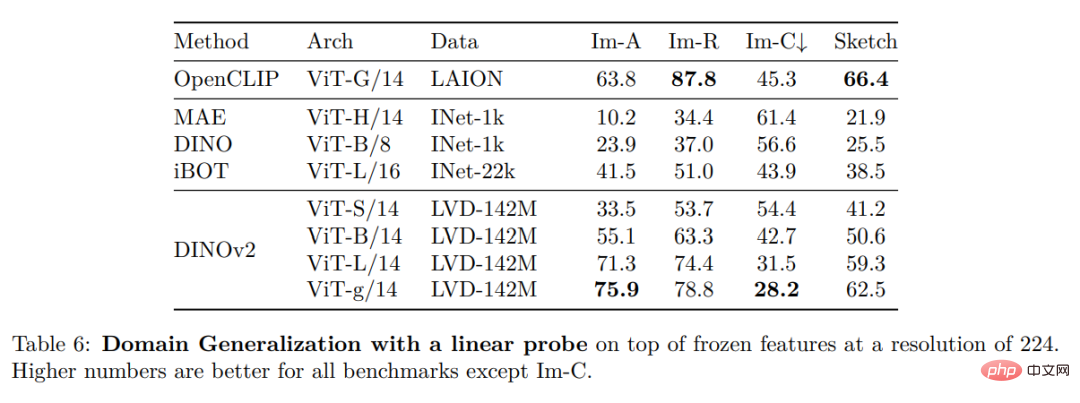
Dichte Erkennung Aufgabe: qualitative Ergebnisse:
Das obige ist der detaillierte Inhalt vonMeta veröffentlicht Open-Source-Multifunktions-Großmodelle, um der visuellen Vereinheitlichung einen Schritt näher zu kommen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So schließen Sie die Horrorkorridor-Mission in Goat Simulator 3 ab
Feb 25, 2024 pm 03:40 PM
So schließen Sie die Horrorkorridor-Mission in Goat Simulator 3 ab
Feb 25, 2024 pm 03:40 PM
Der Terrorkorridor ist eine Mission in Goat Simulator 3. Wie können Sie die detaillierten Räumungsmethoden und entsprechenden Prozesse meistern und die entsprechenden Herausforderungen dieser Mission meistern? Leitfaden zum Erlernen verwandter Informationen. Goat Simulator 3 Terror Corridor Guide 1. Zuerst müssen die Spieler zum Silent Hill in der oberen linken Ecke der Karte gehen. 2. Hier sehen Sie ein Haus mit der Aufschrift „RESTSTOP“ auf dem Dach. Um dieses Haus zu betreten, müssen die Spieler die Ziege bedienen. 3. Nachdem wir den Raum betreten haben, gehen wir zunächst geradeaus und biegen dann rechts ab. Hier befindet sich am Ende eine Tür, von hier aus gehen wir direkt hinein. 4. Nach dem Betreten müssen wir auch zuerst vorwärts gehen und dann rechts abbiegen. Wenn wir hier die Tür erreichen, müssen wir umkehren und sie finden.
 So bestehen Sie die Imperial Tomb-Mission im Goat Simulator 3
Mar 11, 2024 pm 01:10 PM
So bestehen Sie die Imperial Tomb-Mission im Goat Simulator 3
Mar 11, 2024 pm 01:10 PM
Goat Simulator 3 ist ein Spiel mit klassischem Simulationsspiel, das es den Spielern ermöglicht, den Spaß einer Gelegenheits-Action-Simulation in vollen Zügen zu genießen. Das Spiel hat auch viele spannende Spezialaufgaben. Unter anderem erfordert die Goat Simulator 3 Imperial Tomb-Aufgabe, dass die Spieler den Glockenturm finden. Einige Spieler sind sich nicht sicher, wie sie die drei Uhren gleichzeitig bedienen sollen. Hier ist die Anleitung zur Tomb of the Tomb-Mission in Goat Simulator 3. Die Anleitung zur Tomb of the Tomb-Mission in Goat Simulator 3 besteht darin, die Glocken zu läuten in Ordnung. Detaillierte Schritterweiterung 1. Zuerst müssen die Spieler die Karte öffnen und zum Wuqiu-Friedhof gehen. 2. Gehen Sie dann hinauf zum Glockenturm. Dort befinden sich drei Glocken. 3. Folgen Sie dann 222312312 in der Reihenfolge vom größten zum kleinsten, um sich mit dem wütenden Klopfen vertraut zu machen. 4. Nachdem Sie das Klopfen abgeschlossen haben, können Sie die Mission abschließen und die Tür öffnen, um das Lichtschwert zu erhalten.
 Fix: Fehler „Operator verweigert Anforderung' im Windows-Taskplaner
Aug 01, 2023 pm 08:43 PM
Fix: Fehler „Operator verweigert Anforderung' im Windows-Taskplaner
Aug 01, 2023 pm 08:43 PM
Um Aufgaben zu automatisieren und mehrere Systeme zu verwalten, ist Missionsplanungssoftware ein wertvolles Werkzeug in Ihrem Arsenal, insbesondere als Systemadministrator. Der Windows-Taskplaner erledigt seine Aufgabe perfekt, aber in letzter Zeit berichten viele Leute über Fehler, bei denen der Operator eine Anforderung abgelehnt hat. Dieses Problem besteht in allen Iterationen des Betriebssystems, und obwohl ausführlich darüber berichtet und behandelt wurde, gibt es keine wirksame Lösung. Lesen Sie weiter, um herauszufinden, was für andere Menschen tatsächlich funktionieren könnte! Welche Anfrage im Taskplaner 0x800710e0 wurde vom Bediener oder Administrator abgelehnt? Der Taskplaner ermöglicht die Automatisierung verschiedener Aufgaben und Anwendungen ohne Benutzereingaben. Sie können damit bestimmte Anwendungen planen und organisieren, automatische Benachrichtigungen konfigurieren, bei der Zustellung von Nachrichten helfen und vieles mehr. Es
 So führen Sie die Steve-Rettungsmission im Goat Simulator 3 durch
Feb 25, 2024 pm 03:34 PM
So führen Sie die Steve-Rettungsmission im Goat Simulator 3 durch
Feb 25, 2024 pm 03:34 PM
Steve zu retten ist eine einzigartige Aufgabe in Goat Simulator 3. Was genau muss getan werden, um sie abzuschließen? Diese Aufgabe ist relativ einfach, aber wir müssen aufpassen, dass wir die Bedeutung von Steve nicht falsch verstehen Simulator 3-Aufgabenstrategien können Ihnen dabei helfen, verwandte Aufgaben besser zu erledigen. Goat Simulator 3 Rescue Steve Mission Strategie 1. Kommen Sie zuerst zur heißen Quelle in der unteren rechten Ecke der Karte. 2. Nachdem Sie an der heißen Quelle angekommen sind, können Sie die Aufgabe auslösen, Steve zu retten. 3. Beachten Sie, dass es in der heißen Quelle einen Mann gibt, der zwar Steve heißt, aber nicht das Ziel dieser Mission ist. 4. Finden Sie in dieser heißen Quelle einen Fisch namens Steve und bringen Sie ihn an Land, um diese Aufgabe abzuschließen.
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 Wo finde ich Douyin-Fangruppenaufgaben? Wird der Douyin-Fanclub an Niveau verlieren?
Mar 07, 2024 pm 05:25 PM
Wo finde ich Douyin-Fangruppenaufgaben? Wird der Douyin-Fanclub an Niveau verlieren?
Mar 07, 2024 pm 05:25 PM
Als eine der derzeit beliebtesten Social-Media-Plattformen hat TikTok eine große Anzahl von Nutzern zur Teilnahme angezogen. Auf Douyin gibt es viele Fangruppenaufgaben, die Benutzer erledigen können, um bestimmte Belohnungen und Vorteile zu erhalten. Wo finde ich die Aufgaben des Douyin-Fanclubs? 1. Wo kann ich die Aufgaben des Douyin-Fanclubs einsehen? Um die Aufgaben einer Douyin-Fangruppe zu finden, müssen Sie die persönliche Homepage von Douyin besuchen. Auf der Startseite sehen Sie eine Option namens „Fanclub“. Klicken Sie auf diese Option und Sie können die Fangruppen, denen Sie beigetreten sind, und die damit verbundenen Aufgaben durchsuchen. In der Spalte „Fanclub-Aufgaben“ sehen Sie verschiedene Arten von Aufgaben, wie z. B. Likes, Kommentare, Teilen, Weiterleiten usw. Für jede Aufgabe gibt es entsprechende Belohnungen und Anforderungen. Im Allgemeinen erhalten Sie nach Abschluss der Aufgabe eine bestimmte Menge an Goldmünzen oder Erfahrungspunkten.
 Was ist NeRF? Ist die NeRF-basierte 3D-Rekonstruktion voxelbasiert?
Oct 16, 2023 am 11:33 AM
Was ist NeRF? Ist die NeRF-basierte 3D-Rekonstruktion voxelbasiert?
Oct 16, 2023 am 11:33 AM
1 Einleitung Neural Radiation Fields (NeRF) sind ein relativ neues Paradigma im Bereich Deep Learning und Computer Vision. Diese Technologie wurde im ECCV2020-Papier „NeRF: Representing Scenes as Neural Radiation Fields for View Synthesis“ (das mit dem Best Paper Award ausgezeichnet wurde) vorgestellt und erfreut sich seitdem mit bisher fast 800 Zitaten äußerster Beliebtheit [1]. Der Ansatz markiert einen grundlegenden Wandel in der traditionellen Art und Weise, wie maschinelles Lernen 3D-Daten verarbeitet. Darstellung neuronaler Strahlungsfelder und differenzierbarer Rendering-Prozess: Zusammengesetzte Bilder durch Abtasten von 5D-Koordinaten (Position und Blickrichtung) entlang der Kamerastrahlen, Eingabe dieser Positionen in ein MLP, um mithilfe volumetrischer Rendering-Techniken Bilder zu erzeugen; ; Die Rendering-Funktion ist differenzierbar und kann daher übergeben werden
 So stoppen Sie Prozessaktualisierungen im Task-Manager und beenden Aufgaben einfacher in Windows 11
Aug 20, 2023 am 11:05 AM
So stoppen Sie Prozessaktualisierungen im Task-Manager und beenden Aufgaben einfacher in Windows 11
Aug 20, 2023 am 11:05 AM
So unterbrechen Sie Task-Manager-Prozessaktualisierungen in Windows 11 und Windows 10. Drücken Sie STRG+Fenstertaste+Entf, um den Task-Manager zu öffnen. Standardmäßig öffnet der Task-Manager das Fenster „Prozesse“. Wie Sie hier sehen können, sind alle Apps endlos in Bewegung und es kann schwierig sein, auf sie zu zeigen, wenn Sie sie auswählen möchten. Drücken Sie also die STRG-Taste und halten Sie sie gedrückt. Dadurch wird der Task-Manager angehalten. Sie können weiterhin Apps auswählen und sogar nach unten scrollen, müssen jedoch jederzeit die STRG-Taste gedrückt halten.
