
 Technologie-Peripheriegeräte
KI
AltDiffusion-m18, ein vielseitiges Tool zum Generieren mehrsprachiger Texte und Bilder
Technologie-Peripheriegeräte
KI
AltDiffusion-m18, ein vielseitiges Tool zum Generieren mehrsprachiger Texte und Bilder
AltDiffusion-m18, ein vielseitiges Tool zum Generieren mehrsprachiger Texte und Bilder

Derzeit ist die Auswahl an nicht-englischen Text- und Bildgenerierungsmodellen begrenzt und Benutzer müssen die Eingabeaufforderung häufig ins Englische übersetzen, bevor sie das Modell eingeben. Dies führt nicht nur zu einer zusätzlichen betrieblichen Belastung, sondern auch sprachliche und kulturelle Fehler im Übersetzungsprozess beeinträchtigen die Genauigkeit der generierten Bilder.
Das FlagAI-Team des Zhiyuan Research Institute hat eine effiziente Trainingsmethode entwickelt, bei der ein mehrsprachiges Vortrainingsmodell in Kombination mit Stable Diffusion verwendet wurde, um ein mehrsprachiges Text- und Bildgenerierungsmodell zu trainieren – AltDiffusion-m18, das Text und unterstützt Bildgenerierung in 18 Sprachen.
Einschließlich Chinesisch, Englisch, Japanisch, Thailändisch, Koreanisch, Hindi, Ukrainisch, Arabisch, Türkisch, Vietnamesisch, Polnisch, Niederländisch, Portugiesisch, Italienisch, Spanisch, Deutsch, Französisch, Russisch.
Huggingface: https://huggingface.co/BAAI/AltDiffusion-m18
GitHub: https://github.com/FlagAI-Open/FlagAI/blob/master/examples/AltDiffusion-m18
AltDiffusion-m18 in Die objektive Bewertung des FID-, IS- und CLIP-Scores in Englisch hat einen stabilen Diffusionseffekt von 95 bis 99 % erreicht und das optimale Niveau in Chinesisch und Japanisch erreicht. Gleichzeitig wurden die Lücken in den Text- und Bildgenerierungsmodellen von geschlossen die restlichen 15 Sprachen, was den Anforderungen von in hohem Maße gerecht wird. In der Branche besteht eine starke Nachfrage nach mehrsprachiger Text- und Grafikerstellung. Besonderer Dank geht an das Stable Diffusion Research Team für die Beratung bei dieser Arbeit.
Darüber hinaus wurde der AltDiffusion-m18-bezogene innovative Technologiebericht „AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities“ von Findings of ACL 2023 akzeptiert. Technische Highlights 4 AltCLIP für den mehrsprachigen Turm und mit mehrsprachigen Daten in neun Sprachen verfeinert, wodurch die ursprüngliche, nur auf Englisch verfügbare Stable Diffusion auf die Unterstützung von neun verschiedenen Sprachen erweitert wird.
AltCLIP: https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltCLIP-m18
Und AltDiffusion-m18 wird basierend auf Stable Diffusion v2.1 trainiert. Der neue Sprachturm von Stable Diffusion v2.1 ist die invertierte zweite Schicht von OpenCLIP. Daher verwendet der neue AltCLIP die invertierte zweite Schicht von OpenCLIP als Destillationsziel für die Neuschulung und verwendet basierend auf m9 nur die CrossAttention-Schicht K Die Feinabstimmung wird zu einer zweistufigen Trainingsmethode erweitert, wie in der folgenden Abbildung dargestellt:
– Phase 1: Zu Beginn des Experiments von m9 wurde festgestellt, dass die Feinabstimmung der K- und V-Matrizen erlernen hauptsächlich die Konzeptausrichtung von Text und Bildern. Daher werden in der ersten Stufe des m18-Trainings weiterhin die Daten von 18 Sprachen verwendet, um die K- und V-Matrizen zu optimieren. Darüber hinaus haben Experimente gezeigt, dass die Reduzierung der Auflösung eines Bildes von 512*512 auf 256*256 nicht zum Verlust der semantischen Informationen des Bildes führt. Daher wird in der ersten Phase des Erlernens der Text-Bild-Konzeptausrichtung die Auflösung 256*256 für das Training verwendet, was das Training beschleunigt. - Die zweite Stufe: Um die Qualität der generierten Bilder weiter zu verbessern, verwenden Sie die Auflösung von 512*512, um die vollständigen Parameter von Unet in den Daten von 18 Sprachen zu trainieren. Darüber hinaus werden 10 % des Textes für das bedingungslose Training verworfen, um eine klassifiziererfreie Leitfolgerung zu ermöglichen. - Darüber hinaus wird eine klassifikatorfreie geführte Trainingstechnik eingesetzt, um die Generierungsqualität weiter zu verbessern. Die neuesten Bewertungsergebnisse zeigen, dass AltCLIP-m18 CLIP übertrifft und das optimale Niveau bei chinesischen und englischen Zero-Shot-(Zero-Sample-)Abrufaufgaben erreicht Version, unterstützt 9 Sprachen) erreicht das optimale Niveau mit AltCLIP-m18 ⬇️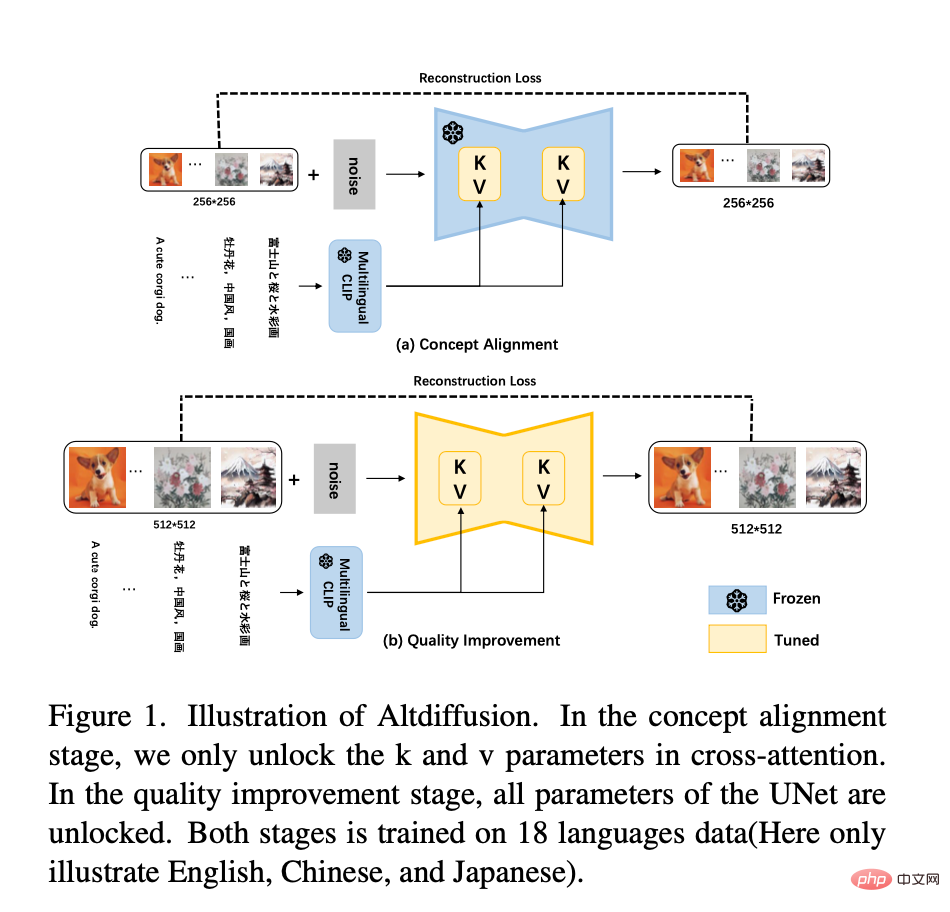
Mit der Unterstützung des neuen AltCLIP hat AltDiffusion-m18 95 bis 99 % des ursprünglichen stabilen Diffusionseffekts in der englischen FID-, IS- und CLIP-Score-Bewertung erreicht und die besten Ergebnisse in 17 Sprachen erzielt, darunter Chinesisch und Japanisch. Erweiterte Leistung, detaillierte Daten werden in der folgenden Tabelle angezeigt:
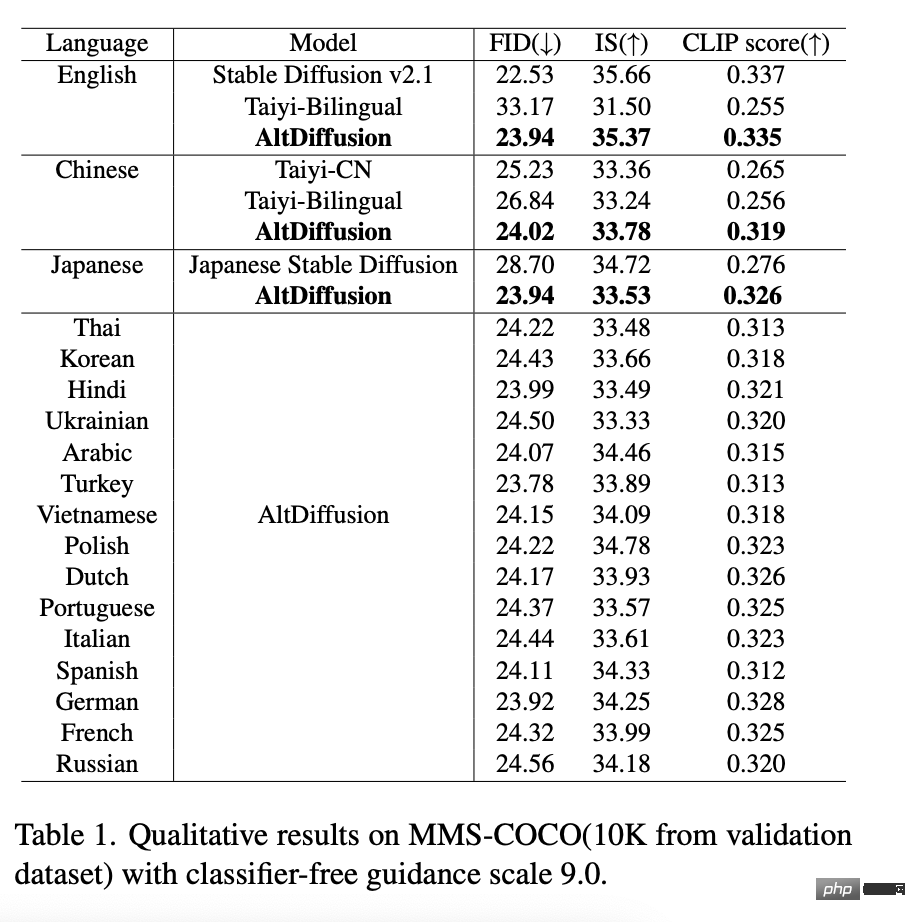
In Englisch, Chinesisch, Japanisch wird AltDiffusion-m18 mit anderen Modellgenerationen verglichen Ergebnisse, Der Effekt ist überlegen und die Details sind genauer:

AltDiffusion-m18 in (a) oben kann Ergebnisse erzeugen, die in hohem Maße mit dem übereinstimmen Original Stable Diffusion, und im Prompt ist es besser zu verstehen als andere inländische zweisprachige Chinesisch-Englisch-Modelle, zum Beispiel: „Ein ausgestopfter Bär“, „Ein Schwarz-Weiß-Foto“, „Katze“ und andere Konzepte, die in anderen Sprachen nicht generiert werden konnten Inländische zweisprachige Modelle Chinesisch-Englisch können erfolgreich in AltDiffusion generiert werden. Das gleiche Phänomen tritt im Chinesischen und Japanischen auf.
Das „schwarze Sofa, Holzboden“ in (b) oben wird nur von AltDiffusion-m18 korrekt generiert.
Die „Bären“ in (c) oben, Japanese Stable Diffusion generiert fälschlicherweise „Menschen“, AltDiffusion-m18 kann jedoch korrekt „Bären“ generieren.
Darüber hinaus entwickelte das Zhiyuan FlagEval-Team das Bewertungstool ImageEval für das Text- und Bildgenerierungsmodell. Nach der Evaluierung übertrifft die Genauigkeit von AltDiffusion-m18 in den Dimensionen Entitätsobjekt und Entitätsmenge die von inländischen Peer-Modellen um 11 % bzw. 10 % (Hinweis: Die ImageEval-Bewertungsmethode und die Ergebnisse werden in naher Zukunft öffentlich veröffentlicht, also bleiben Sie abgestimmt).
3 Der Retter kleiner Sprachtexte und Bilder, der ein Referenzsystem für mehrsprachige Text- und Bildgenerierungsmodelle bereitstellt
AltDiffusion-m18 Gelernt von Mehrsprachige Daten Die Voreingenommenheit in verschiedenen Sprachen hilft Benutzern, die Sprachübersetzungsschwelle zu überschreiten und kulturelle Übersetzungen zu umgehen, wodurch der Verlust kultureller Informationen hinter der Sprache verringert wird. Wie in der Abbildung unten gezeigt, ist die Gesichtskontur des kleinen Jungen, die durch Eingabeaufforderungen in chinesischer und japanischer Sprache generiert wird, eher „asiatischer Stil“, während die Gesichtskontur des kleinen Jungen, die durch Eingabeaufforderungen in englischer und anderer europäischer Sprache generiert wird, eher „europäischer und amerikanischer Stil“ ist.

Interessanter ist, dass auch die Details der Bilder, die durch Tieraufforderungen in verschiedenen Sprachen generiert werden, unterschiedlich sind. Wie in der folgenden Abbildung gezeigt, sind die in verschiedenen Sprachen generierten Bilder insgesamt zwar sehr konsistent, es gibt jedoch geringfügige Unterschiede im Hintergrund des Bildes und in den Details der Gesichtszüge von Corgi.

Im Allgemeinen bietet AltDiffusion-m18 einen grundlegenden Referenzrahmen für mehrsprachige Text- und Bildgenerierungsmodelle. Benutzer, deren Muttersprachen Spanisch, Deutsch und Französisch sind, können den Spaß von AIGC genießen, ohne die Eingabeaufforderungen in ihrem Kopf ins Englische übersetzen zu müssen. KI-Trainingsexperten können basierend auf AltDiffusion-m18 auch durch die Kombination von DreamBooth, ControlNet und LoRA eine weitere Optimierung durchführen oder Korpus-Feinabstimmungen in anderen Sprachen verwenden, um bessere Effekte bei der Text- und Bildgenerierung zu erzielen.
Gleichzeitig stellt FlagAI (github.com/FlagAI-Open/FlagAI), ein One-Stop-Open-Source-Projekt für große Modellalgorithmen, Modelle und Tools, auch Trainingsinferenztools und APIs für bereit Jeder kann AltDiffusion-m18 schnell herunterladen und verwenden.
Das obige ist der detaillierte Inhalt vonAltDiffusion-m18, ein vielseitiges Tool zum Generieren mehrsprachiger Texte und Bilder. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Empfohlen: Ausgezeichnetes JS-Open-Source-Projekt zur Gesichtserkennung und -erkennung
Apr 03, 2024 am 11:55 AM
Empfohlen: Ausgezeichnetes JS-Open-Source-Projekt zur Gesichtserkennung und -erkennung
Apr 03, 2024 am 11:55 AM
Die Technologie zur Gesichtserkennung und -erkennung ist bereits eine relativ ausgereifte und weit verbreitete Technologie. Derzeit ist JS die am weitesten verbreitete Internetanwendungssprache. Die Implementierung der Gesichtserkennung und -erkennung im Web-Frontend hat im Vergleich zur Back-End-Gesichtserkennung Vor- und Nachteile. Zu den Vorteilen gehören die Reduzierung der Netzwerkinteraktion und die Echtzeiterkennung, was die Wartezeit des Benutzers erheblich verkürzt und das Benutzererlebnis verbessert. Die Nachteile sind: Es ist durch die Größe des Modells begrenzt und auch die Genauigkeit ist begrenzt. Wie implementiert man mit js die Gesichtserkennung im Web? Um die Gesichtserkennung im Web zu implementieren, müssen Sie mit verwandten Programmiersprachen und -technologien wie JavaScript, HTML, CSS, WebRTC usw. vertraut sein. Gleichzeitig müssen Sie auch relevante Technologien für Computer Vision und künstliche Intelligenz beherrschen. Dies ist aufgrund des Designs der Webseite erwähnenswert
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Neues SOTA für multimodale Dokumentverständnisfunktionen! Das Alibaba mPLUG-Team hat die neueste Open-Source-Arbeit mPLUG-DocOwl1.5 veröffentlicht, die eine Reihe von Lösungen zur Bewältigung der vier großen Herausforderungen der hochauflösenden Bildtexterkennung, des allgemeinen Verständnisses der Dokumentstruktur, der Befolgung von Anweisungen und der Einführung externen Wissens vorschlägt. Schauen wir uns ohne weitere Umschweife zunächst die Auswirkungen an. Ein-Klick-Erkennung und Konvertierung von Diagrammen mit komplexen Strukturen in das Markdown-Format: Es stehen Diagramme verschiedener Stile zur Verfügung: Auch eine detailliertere Texterkennung und -positionierung ist einfach zu handhaben: Auch ausführliche Erläuterungen zum Dokumentverständnis können gegeben werden: Sie wissen schon, „Document Understanding“. " ist derzeit ein wichtiges Szenario für die Implementierung großer Sprachmodelle. Es gibt viele Produkte auf dem Markt, die das Lesen von Dokumenten unterstützen. Einige von ihnen verwenden hauptsächlich OCR-Systeme zur Texterkennung und arbeiten mit LLM zur Textverarbeitung zusammen.
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
