

Geben Sie eine Referenzspalte an, führen Sie basierend auf dieser Spalte andere Spalten zusammen.
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '002', '003'],
'num4': [80, 86, 79]})
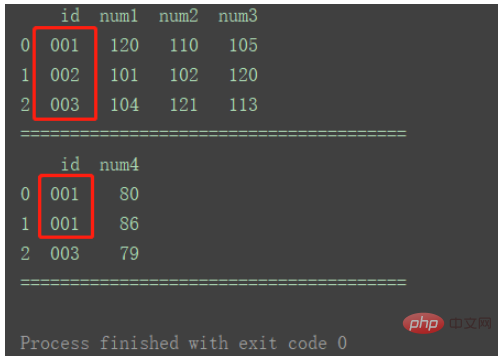
print(df1)
print("=======================================")
print(df2)
print("=======================================")
df_merge = pd.merge(df1, df2, on='id')
print(df_merge)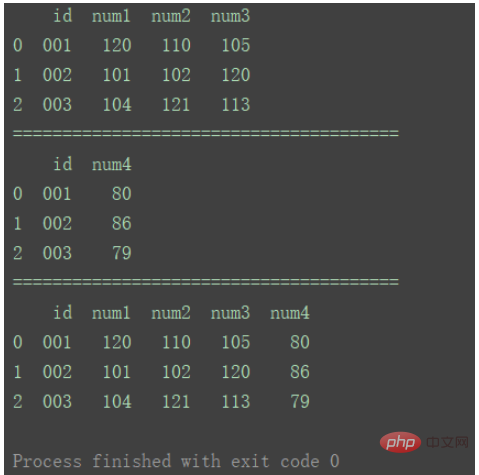
Um diese Zusammenführung zu erreichen, können Sie auch nach Index zusammenführen, also basierend auf der Indexspalte. Setzen Sie einfach sowohl left_index als auch right_index auf True
. (Sowohl left_index als auch right_index sind standardmäßig auf False eingestellt. left_index bedeutet, dass die linke Tabelle auf dem Index der Daten der linken Tabelle basiert, und right_index bedeutet, dass die rechte Tabelle auf dem Index der Daten der rechten Tabelle basiert.)
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '002', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
df_merge = pd.merge(df1, df2, left_index=True, right_index=True)
print(df_merge)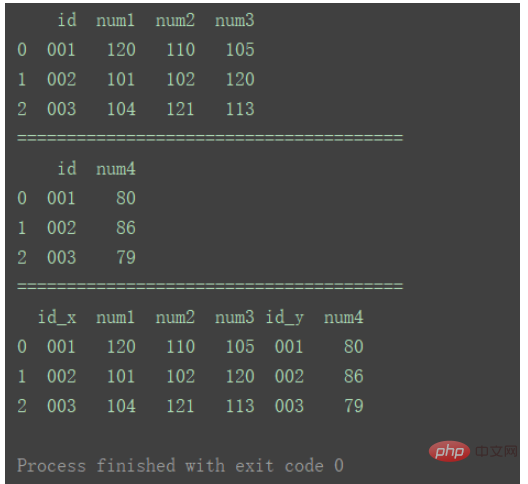
Im Vergleich zu Methode ① besteht der Unterschied darin, dass, wie in der Abbildung gezeigt, in den mit Methode 2 zusammengeführten Daten doppelte Spalten vorhanden sind.
pd.merge(right,how=‘inner’, on=“None“, left_on=“None“, right_on=“None“, left_index=False, right_index=False)
| Parameter | Beschreibung |
|---|---|
| Linke Tabelle, zusammengeführtes Objekt, Datenrahmen oder Serie | |
| Rechte Tabelle, zusammengeführtes Objekt, Datenrahmen oder Serie | |
| Merge-Methode, Es kann links (linke Zusammenführung), rechts (rechts zusammengeführt), außen (äußere Zusammenführung), innen (innere Zusammenführung) sein Der Name der linken Tabelle ist rechts Die Spalte basiert auf dem Index, der Standardwert ist False, Nein | |
| Unter diesen können left_index und right_index nicht gleichzeitig mit on angegeben werden. | Merge-Methode links rechts außen innen |
| Daten vorbereiten‘ | Einen Datensatz neu vorbereiten: |
| inner (Standard) | |
| Verwenden Sie die Schnittmenge von aus beiden Datensätzen | |
| outer |
df_merge = pd.merge(df1, df2, on='id', how="outer")
print(df_merge)
Mit den Schlüsseln von links. dataset
df_merge = pd.merge(df1, df2, on='id', how='left') print(df_merge)
richtig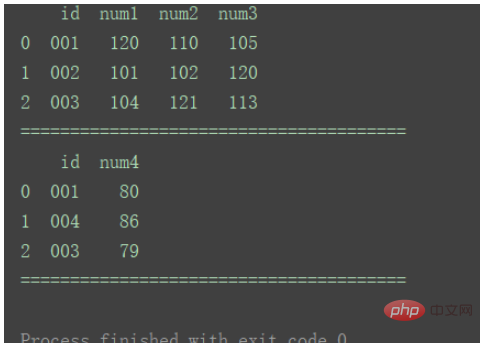
df_merge = pd.merge(df1, df2, on='id', how='right') print(df_merge)
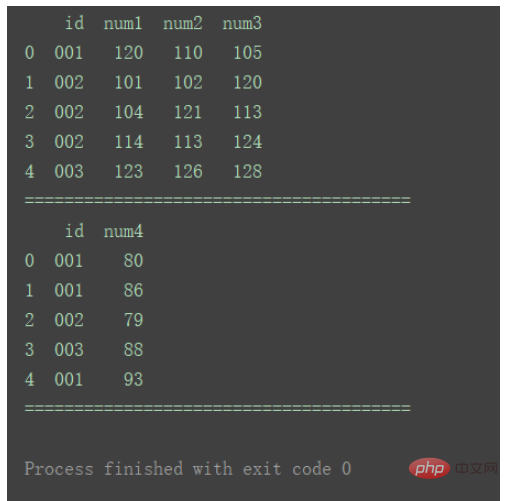
2. Viele-zu-eins-Zusammenführungimport pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '001', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
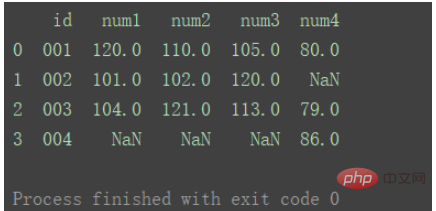
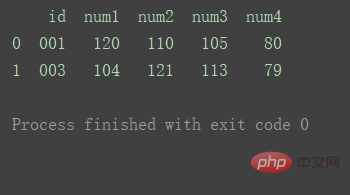 Wie in der Abbildung gezeigt, gibt es in df2 doppelte ID1-Daten.
Wie in der Abbildung gezeigt, gibt es in df2 doppelte ID1-Daten.
Mergedf_merge = pd.merge(df1, df2, on='id')
print(df_merge)
verwendet weiterhin die Schnittmenge der Schlüssel aus den beiden Datensätzen gemäß der standardmäßigen Inner-Methode. Und Zeilen mit doppelten Schlüsseln werden im zusammengeführten Ergebnis als mehrere Zeilen wiedergegeben.
 3. Viele-zu-viele-Zusammenführung
3. Viele-zu-viele-Zusammenführung
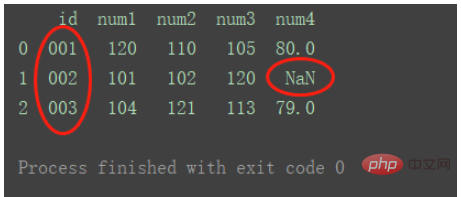
Zum Beispiel gibt es sowohl in Diagramm 1 als auch in Tabelle 2 mehrere Zeilen mit doppelten IDs.
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '002', '002', '003'],
'num1': [120, 101, 104, 114, 123],
'num2': [110, 102, 121, 113, 126],
'num3': [105, 120, 113, 124, 128]})
df2 = pd.DataFrame({'id': ['001', '001', '002', '003', '001'],
'num4': [80, 86, 79, 88, 93]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")df_merge = pd.merge(df1, df2, on='id') print(df_merge)
 concat()
concat()pd.concat(objs, axis=0, join=‘outer’,ignore_index:bool=False,keys=None,levels=None,names=None , verify_integrity:bool=False,sort:bool=False,copy:bool=True)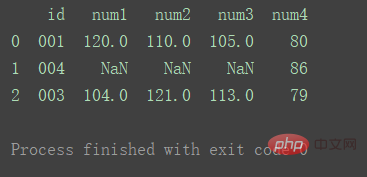
 Parameter
Parameter
Beschreibung
objs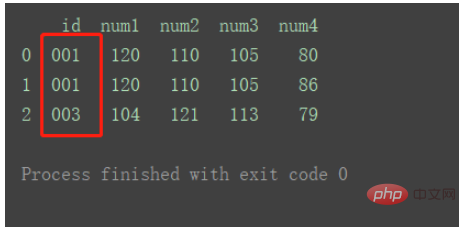
join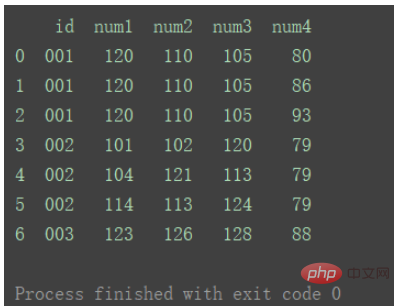
Der Standardwert ist „False“, was darauf hinweist, dass der Index beibehalten (nicht ignoriert) wird. Auf „True“ setzen, um den Index zu ignorieren.ignore_index
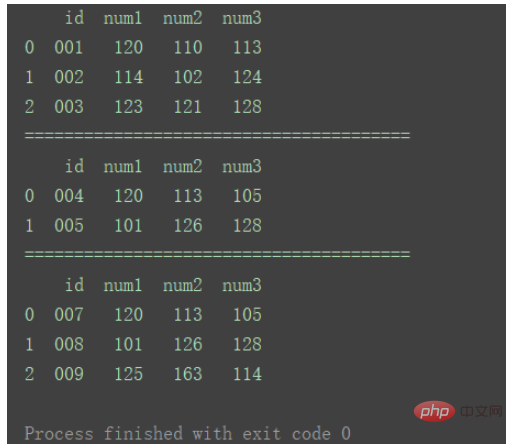
其他重要参数通过实例说明。 1.相同字段的表首位相连首先准备三组DataFrame数据: import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 114, 123],
'num2': [110, 102, 121],
'num3': [113, 124, 128]})
df2 = pd.DataFrame({'id': ['004', '005'],
'num1': [120, 101],
'num2': [113, 126],
'num3': [105, 128]})
df3 = pd.DataFrame({'id': ['007', '008', '009'],
'num1': [120, 101, 125],
'num2': [113, 126, 163],
'num3': [105, 128, 114]})
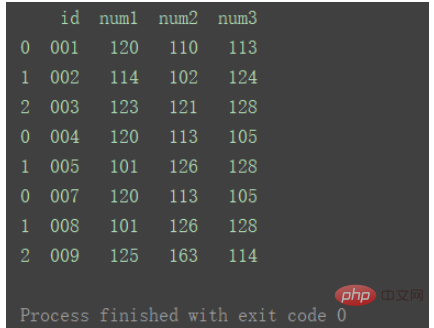
print(df1)
print("=======================================")
print(df2)
print("=======================================")
print(df3)Nach dem Login kopieren
合并 dfs = [df1, df2, df3] result = pd.concat(dfs) print(result) Nach dem Login kopieren
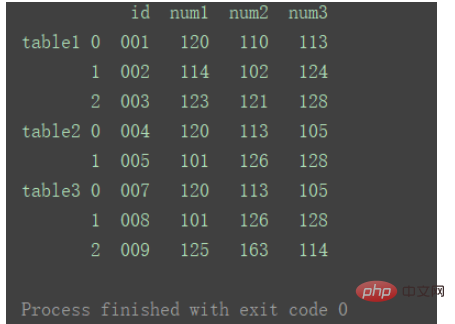
如果想要在合并后,标记一下数据都来自于哪张表或者数据的某类别,则也可以给concat加上 参数keys 。 result = pd.concat(dfs, keys=['table1', 'table2', 'table3']) print(result) Nach dem Login kopieren
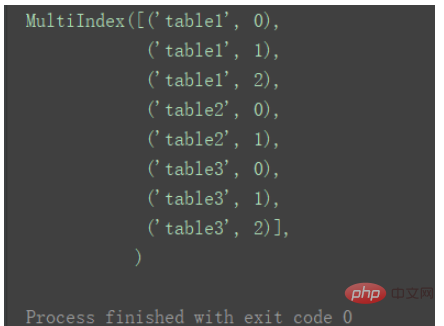
此时,添加的keys与原来的index组成元组,共同成为新的index。 print(result.index) Nach dem Login kopieren
2.横向表合并(行对齐)准备两组DataFrame数据: import pandas as pd
df1 = pd.DataFrame({'num1': [120, 114, 123],
'num2': [110, 102, 121],
'num3': [113, 124, 128]}, index=['001', '002', '003'])
df2 = pd.DataFrame({'num3': [117, 120, 101, 126],
'num5': [113, 125, 126, 133],
'num6': [105, 130, 128, 128]}, index=['002', '003', '004', '005'])
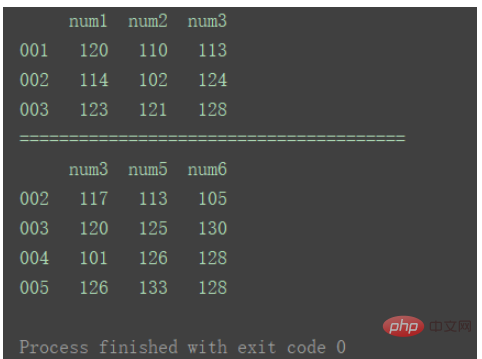
print(df1)
print("=======================================")
print(df2)Nach dem Login kopieren
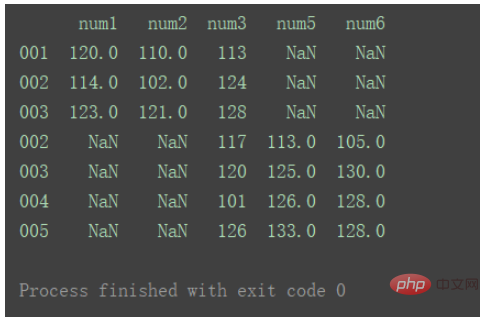
当axis为默认值0时: result = pd.concat([df1, df2]) print(result) Nach dem Login kopieren
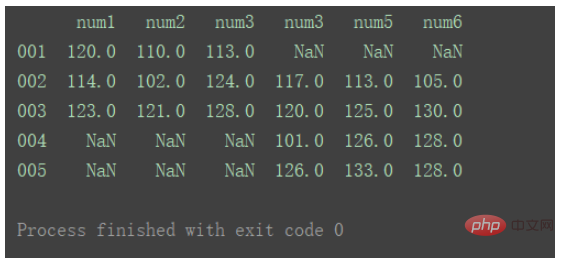
横向合并需要将axis设置为1 : result = pd.concat([df1, df2], axis=1) print(result) Nach dem Login kopieren
对比以上输出差异。
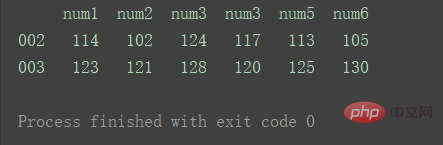
3.交叉合并result = pd.concat([df1, df2], axis=1, join='inner') print(result) Nach dem Login kopieren
Das obige ist der detaillierte Inhalt vonWie füge ich Daten mit DataFrame in Python zusammen und verbinde sie?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Vorheriger Artikel:Methoden und Schritte zur Implementierung der Gesichtserkennung mit Python
Nächster Artikel:Wie implementiert man einen Mechanismus zur Ausnahmebehandlung in automatisierten Python-Tests?
Erklärung dieser Website
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn
Neueste Artikel des Autors
Aktuelle Ausgaben
python – Gibt es relevante Foren oder Bücher zur Python-Webentwicklung?
Aus 1970-01-01 08:00:00
0
0
0
python3.x - Java ruft Python auf, der Python-Code stoppt automatisch und der Grund kann nicht gefunden werden
Aus 1970-01-01 08:00:00
0
0
0
verwandte Themen
Mehr>
Beliebte Empfehlungen
Beliebte Tutorials
Mehr>
Neueste Downloads
Mehr>
|
|---|
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



