
 Technologie-Peripheriegeräte
KI
Wie können große visuelle Modelle verwendet werden, um Training und Inferenz zu beschleunigen?
Technologie-Peripheriegeräte
KI
Wie können große visuelle Modelle verwendet werden, um Training und Inferenz zu beschleunigen?
Wie können große visuelle Modelle verwendet werden, um Training und Inferenz zu beschleunigen?

Hallo zusammen, ich bin Tao Li vom NVIDIA GPU-Computing-Expertenteam. Ich freue mich sehr, heute die Gelegenheit zu haben, das Modelltraining und die Inferenzoptimierung von Swin Transformer, einem großen visuellen Modell, mit Ihnen zu teilen Yu und ich haben einiges getan. Einige dieser Methoden und Strategien können in anderen Modelltrainings- und Inferenzoptimierungen verwendet werden, um den Modelldurchsatz zu verbessern, die GPU-Nutzungseffizienz zu verbessern und die Modelliteration zu beschleunigen.
Ich werde die Optimierung des Trainingsteils des Swin Transformer-Modells im Detail vorstellen. Die Arbeit am Inferenzoptimierungsteil wird von meinen Kollegen ausführlich vorgestellt.
Hier ist der Katalog, den wir haben Heute geteilt, hauptsächlich in vier Teile unterteilt. Da es für ein bestimmtes Modell optimiert ist, werden wir zunächst das Swin Transformer-Modell kurz vorstellen. Anschließend werde ich das Profiling-Tool, also das nsight-System, kombinieren, um den Trainingsprozess zu analysieren und zu optimieren. Im Inferenzteil werden meine Kollegen Strategien und Methoden zur Inferenzoptimierung vorstellen, einschließlich einer detaillierteren Optimierung auf CUDA-Ebene. Abschließend finden Sie hier eine Zusammenfassung der heutigen Optimierungsinhalte.

Der erste Teil ist die Einführung von Swin Transformer.
1. Einführung in Swin Transformer
Anhand des Namens des Modells können wir erkennen, dass es sich um ein auf Transformer basierendes Modell handelt.
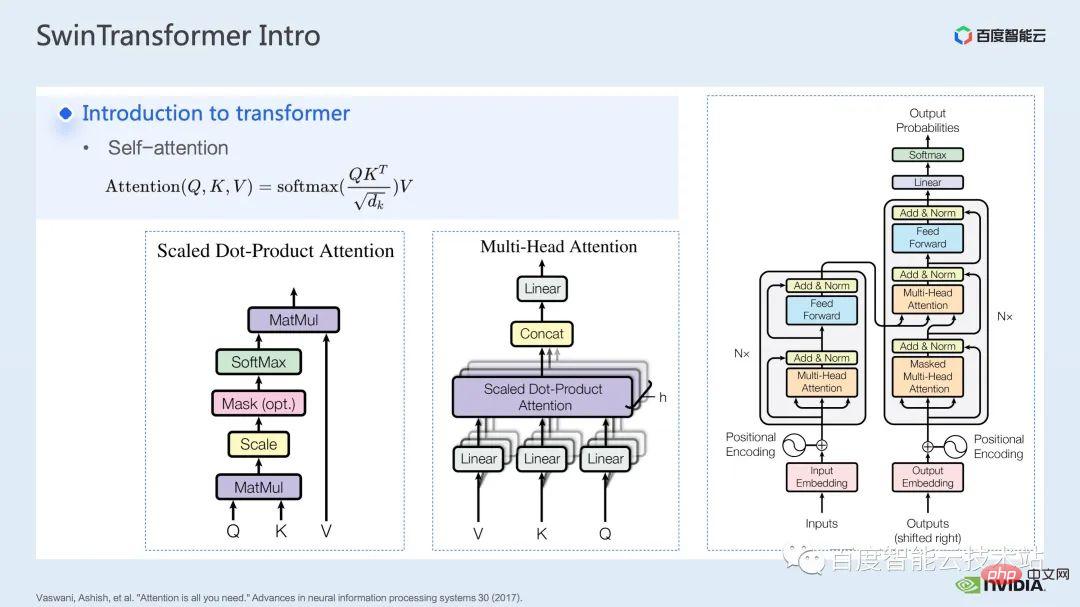
Nachdem das Transformer-Modell im Artikel „Aufmerksamkeit ist alles, was Sie brauchen“ vorgeschlagen wurde, hat es bei vielen Aufgaben im Bereich der Verarbeitung natürlicher Sprache glänzt.
Der Kern des Transformer-Modells ist der sogenannte Aufmerksamkeitsmechanismus, der Aufmerksamkeitsmechanismus. Für das Aufmerksamkeitsmodul sind die üblichen Eingaben Abfrage-, Schlüssel- und Werttensoren. Durch die Abfrage- und Schlüsselfunktion sowie die Berechnung von Softmax kann das Aufmerksamkeitsergebnis, das normalerweise als Aufmerksamkeitskarte bezeichnet wird, erhalten werden. Basierend auf dem Wert in der Aufmerksamkeitskarte kann das Modell lernen, welchen Bereichen im Wert mehr Aufmerksamkeit geschenkt werden muss. oder Es wird gesagt, dass das Modell lernen kann, welche Werte für unsere Aufgabe eine große Hilfe sind. Dies ist das grundlegendste Einzelkopf-Aufmerksamkeitsmodell.
Durch die Erhöhung der Anzahl solcher Einzelkopf-Aufmerksamkeitsmodule können wir ein gemeinsames Mehrkopf-Aufmerksamkeitsmodul bilden. Gängige Encoder und Decoder basieren auf solchen Mehrkopf-Aufmerksamkeitsmodulen.
Viele Modelle beinhalten normalerweise zwei Aufmerksamkeitsmodule, Selbstaufmerksamkeit und Kreuzaufmerksamkeit, oder einen Stapel aus einem oder mehreren Modulen. Beispielsweise besteht das berühmte BERT aus mehreren Encodermodulen. Das beliebte Diffusionsmodell umfasst normalerweise sowohl Selbstaufmerksamkeit als auch Kreuzaufmerksamkeit.
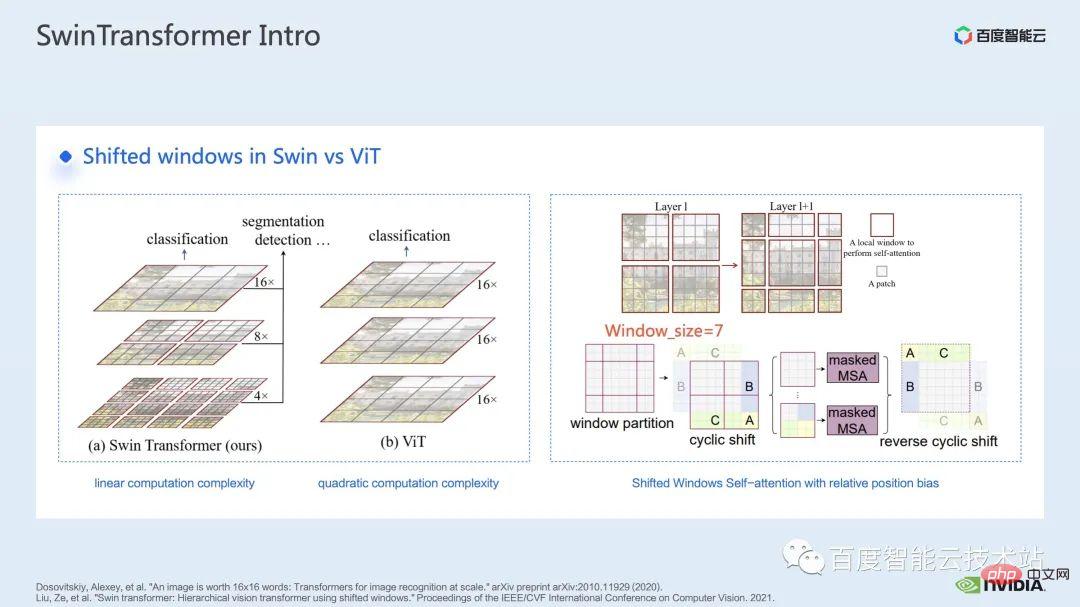
Vor Swin Transformer wandte Vision Transformer (ViT) erstmals Transformatoren im Bereich Computer Vision an. Die Modellstruktur von ViT ist auf der linken Seite der Abbildung dargestellt. ViT unterteilt ein Bild in eine Reihe von Patches. Jeder Patch entspricht einem Token bei der Verarbeitung natürlicher Sprache und codiert diese Reihe von Patches dann über einen Transformer. basierten Encoder und erhalten schließlich Funktionen, die für Aufgaben wie die Klassifizierung verwendet werden können.
Bei Swin Transformer wird das Konzept der Fensteraufmerksamkeit eingeführt. Im Gegensatz zu ViT, das auf das gesamte Bild achtet, teilt Swin Transformer das Bild zunächst in mehrere Fenster auf und achtet dann nur auf die darin enthaltenen Patches das Fenster, wodurch der Rechenaufwand reduziert wird.
Um das durch Fenster verursachte Grenzproblem auszugleichen, führt Swin Transformer außerdem die Fensterverschiebungsoperation ein. Gleichzeitig wird auch eine relative Positionsverzerrung eingeführt, damit das Modell über umfassendere Positionsinformationen verfügt. Tatsächlich sind die Fensteraufmerksamkeit und die Fensterverschiebung hier der Ursprung des Namens Swin in Swin Transformer.
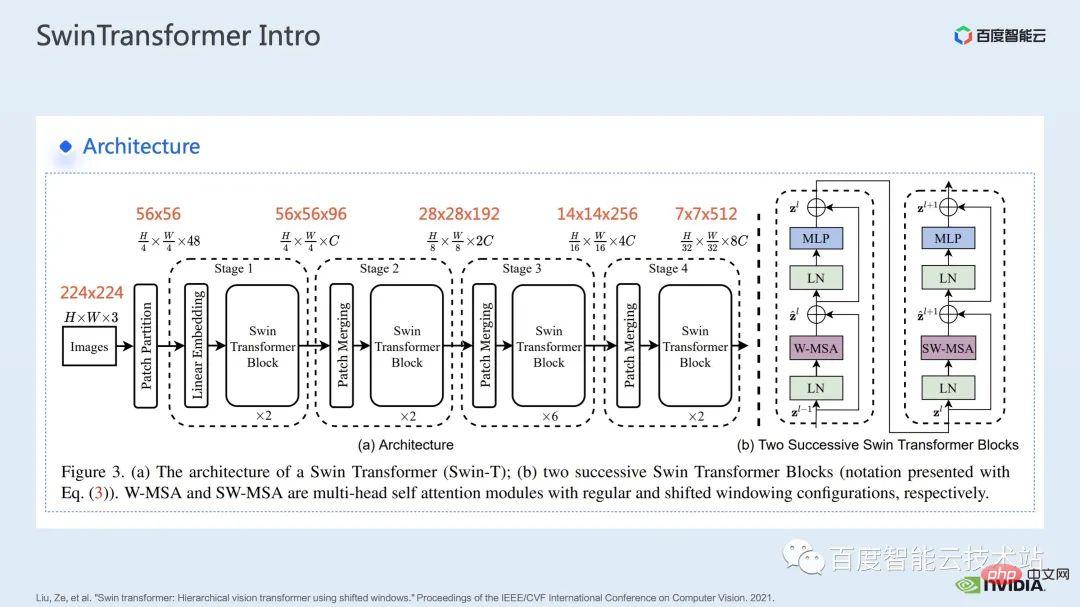
Hier ist die Netzwerkstruktur von Swin Transformer angegeben. Die allgemeine Netzwerkstruktur ist der von traditionellem CNN wie ResNet sehr ähnlich.
Sie können sehen, dass die gesamte Netzwerkstruktur in mehrere Phasen unterteilt ist und in der Mitte der verschiedenen Phasen ein entsprechender Downsampling-Prozess stattfindet. Die Auflösung jeder Stufe ist unterschiedlich und bildet somit eine Auflösungspyramide, wodurch auch die Rechenkomplexität jeder Stufe schrittweise verringert wird.
Dann wird es in jeder Stufe mehrere Transformatorblöcke geben. In jedem Transformatorblock wird das oben erwähnte Fensteraufmerksamkeitsmodul verwendet.
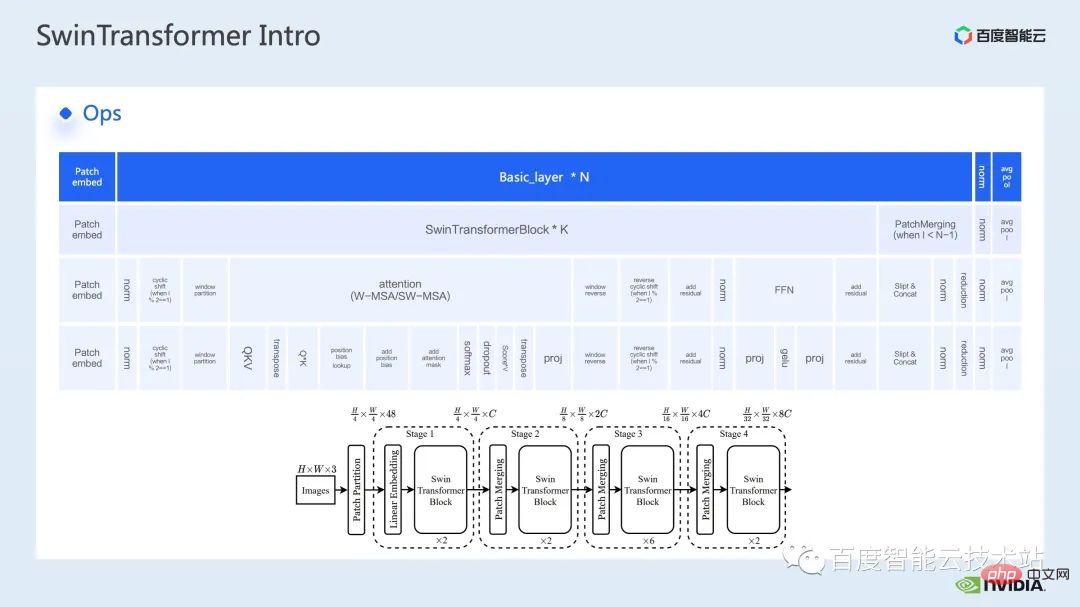
Als nächstes dekonstruieren wir Swin Transformer aus der Perspektive spezifischer Vorgänge.
Sie können sehen, dass ein Transformatorblock aus drei Teilen besteht. Der erste Teil sind die fensterbezogenen Operationen Fensterverschiebung/Partition/Umkehr, der zweite Teil ist die Aufmerksamkeitsberechnung und der dritte Teil ist die FFN-Berechnung ; und Die Aufmerksamkeits- und FFN-Teile können weiter in mehrere Operationen unterteilt werden, und schließlich können wir das gesamte Modell in eine Kombination aus Dutzenden von Operationen unterteilen.
Eine solche Betreiberaufteilung ist für uns sehr wichtig, um Leistungsanalysen durchzuführen, Leistungsengpässe zu lokalisieren und Beschleunigungsoptimierungen durchzuführen.
Das Obige ist die Einleitung zum ersten Teil. Als nächstes stellen wir einige der Optimierungsarbeiten vor, die wir im Training durchgeführt haben. Insbesondere kombinieren wir das Profiling-Tool, also das Nsight-System, um den gesamten Trainingsprozess zu analysieren und zu optimieren. 2. Optimierung des Swin Transformer-Trainings Bei Swin Transformer haben wir festgestellt, dass der Overhead der Kommunikation zwischen Karten relativ gering ist und die Gesamtgeschwindigkeit nahezu linear zunimmt. Daher legen wir hier Wert auf die Analyse der Rechenengpässe auf einer einzelnen GPU Optimierung.
nsight-System ist ein Leistungsanalysetool auf Systemebene. Mit diesem Tool können wir leicht die GPU-Auslastung jedes Moduls des Modells erkennen und feststellen, ob es mögliche Leistungsengpässe und Optimierungen wie Datenwartezeiten usw. gibt. Der Platz kann uns dabei helfen, die Belastung zwischen CPU und GPU sinnvoll zu planen.
nsight-System kann den Aufruf- und Ausführungsstatus von Kernelfunktionen erfassen, die von CUDA und einigen GPU-Computing-Bibliotheken wie cublas, cudnn, tensorRT usw. aufgerufen werden, und kann Benutzern das Hinzufügen einiger Markierungen zum Zählen des Bereichs erleichtern Markierungen, die dem Betrieb der GPU entsprechen.
Ein standardmäßiger Modelloptimierungsprozess ist in der Abbildung unten dargestellt. Wir profilieren das Modell, erhalten den Leistungsanalysebericht, ermitteln Leistungsoptimierungspunkte und führen dann eine gezielte Leistungsoptimierung durch.
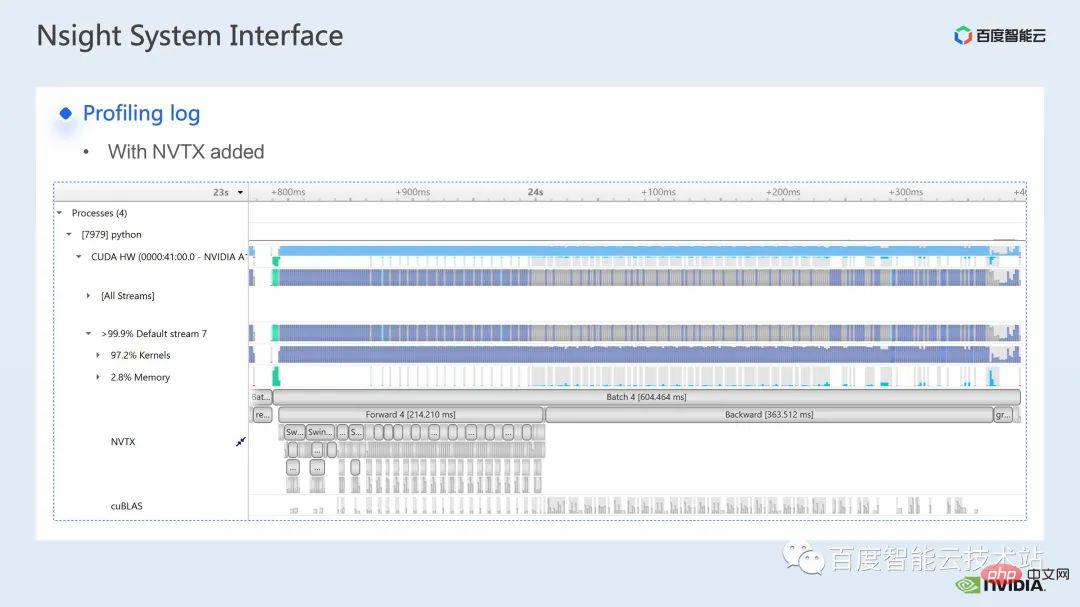
Hier ist eine Schnittstelle des nsight-Systems, die den Kernel-Start darstellt, der hier der Laufzeitteil ist. Für bestimmte Kernel-Funktionen können wir den Zeitanteil im gesamten Prozess sehen, sowie Informationen, etwa ob die GPU im Leerlauf ist. Nach dem Hinzufügen des NVTX-Tags können wir die Zeit sehen, die das Modell benötigt, um sich vorwärts und rückwärts zu bewegen.
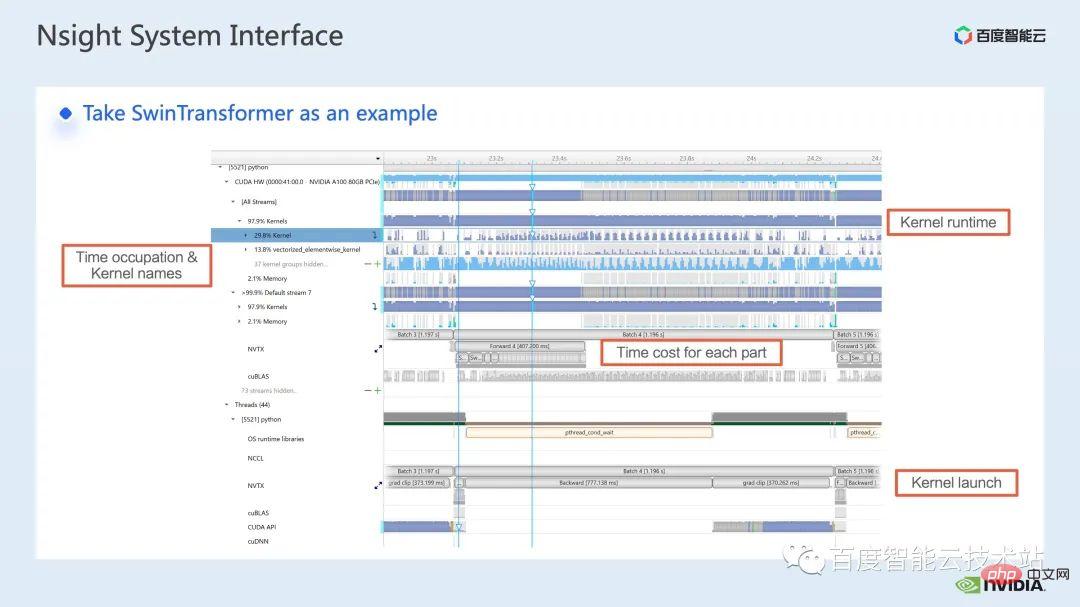
Wenn wir im vorderen Teil hineinzoomen, können wir auch deutlich die spezifische Zeit sehen, die für die Berechnung jedes SwinTransformer-Blocks erforderlich ist.
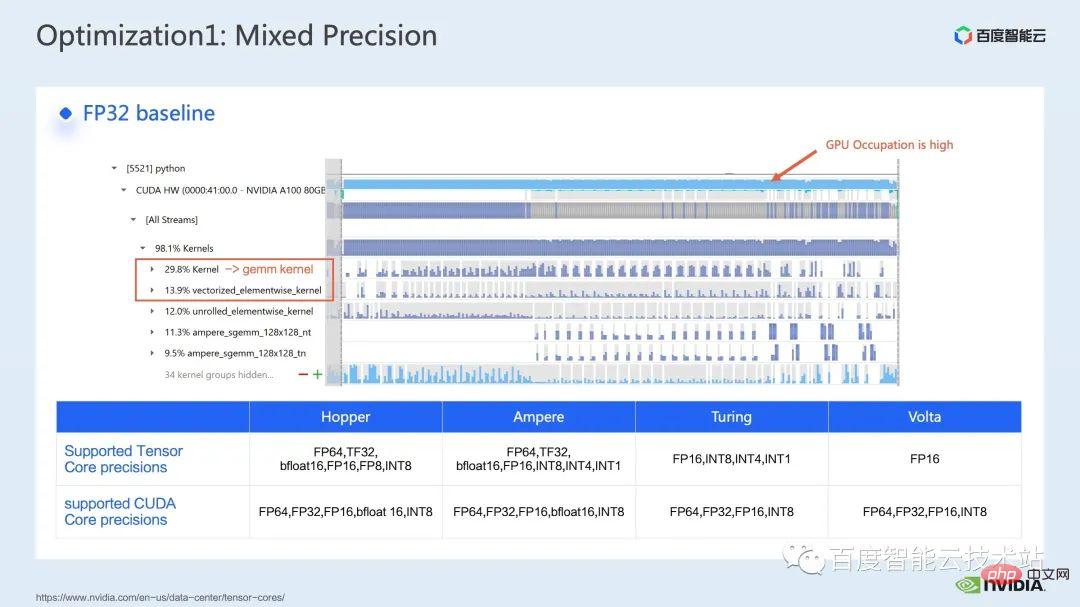
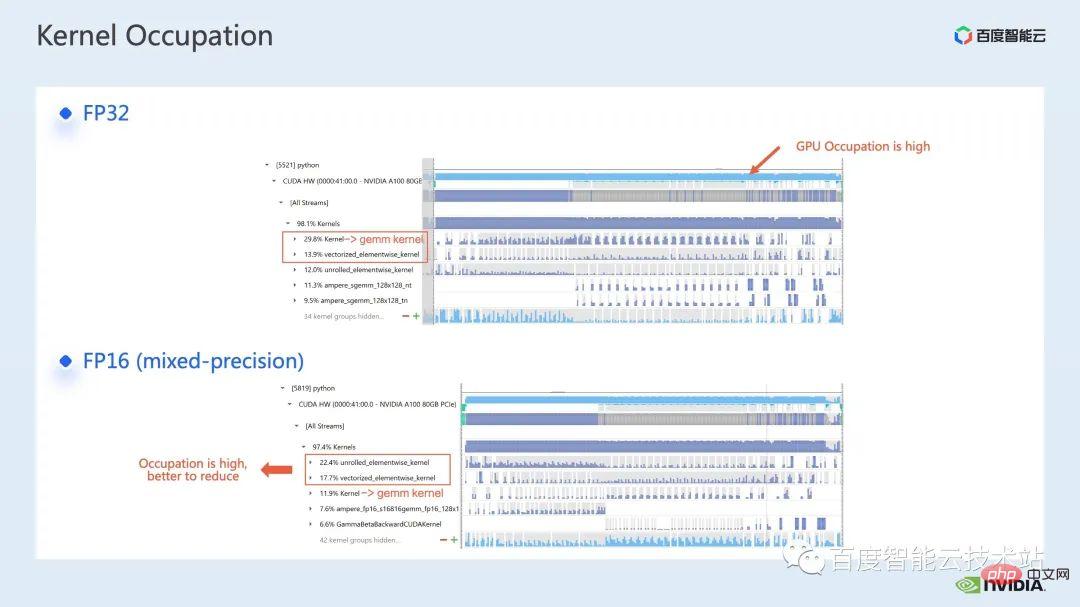
Wir betrachten zunächst die Leistung der gesamten Basislinie mithilfe des nsight-Systemleistungsanalysetools. Das Bild unten zeigt, dass die GPU-Auslastung sehr hoch ist Einer davon ist der Matrixmultiplikationskern.
Für die Matrixmultiplikation besteht eine unserer Optimierungsmethoden darin, den Tensorkern zur Beschleunigung voll auszunutzen.
Wir wissen, dass die GPU von NVIDIA über Hardwareressourcen wie den Cuda-Kern und den Tensor-Kern verfügt, ein Modul, das speziell zur Beschleunigung der Matrixmultiplikation entwickelt wurde. Wir können die direkte Verwendung des tf32-Tensorkerns oder die Verwendung des fp16-Tensorkerns in gemischter Präzision in Betracht ziehen. Sie sollten wissen, dass der Durchsatz der Matrixmultiplikation des Tensorkerns mit fp16 höher ist als der von tf32 und die Matrixmultiplikation mit reinem fp32 auch einen hohen Beschleunigungseffekt hat.
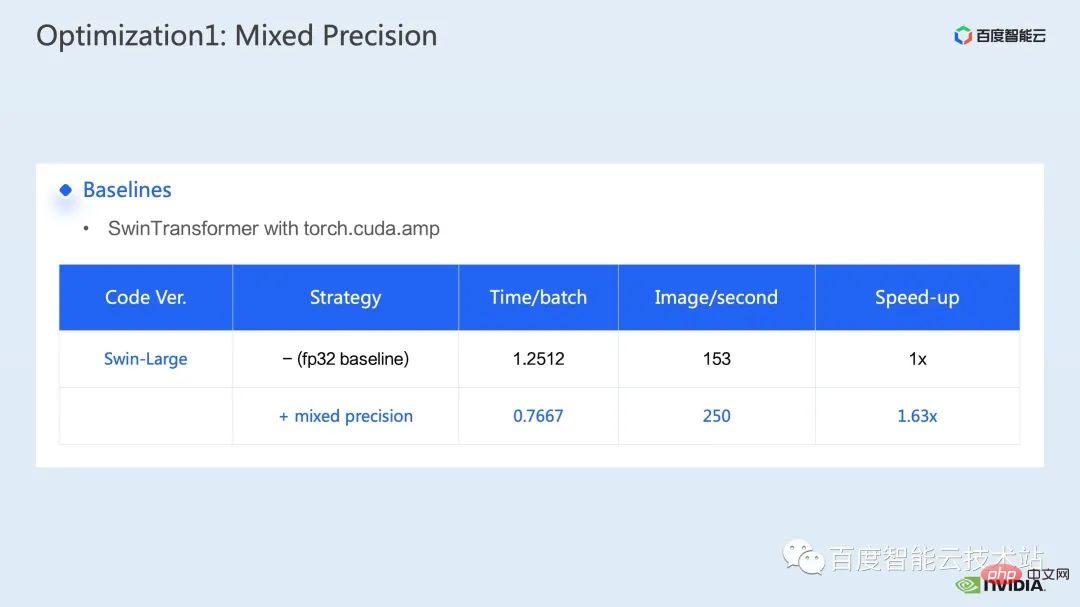
Hier verwenden wir eine gemischte Präzisionslösung. Durch die Verwendung des Mixed-Precision-Modus von Torch.cuda.amp können wir eine 1,63-fache Durchsatzverbesserung erreichen.
In den Profilierungsergebnissen ist auch deutlich zu erkennen, dass die Matrixmultiplikation, die ursprünglich den höchsten Anteil ausmachte, optimiert wurde und ihr Anteil in der gesamten Zeitleiste auf 11,9 % gesunken ist. Bisher sind die Kernel mit einem relativ hohen Anteil elementweise Kernel.
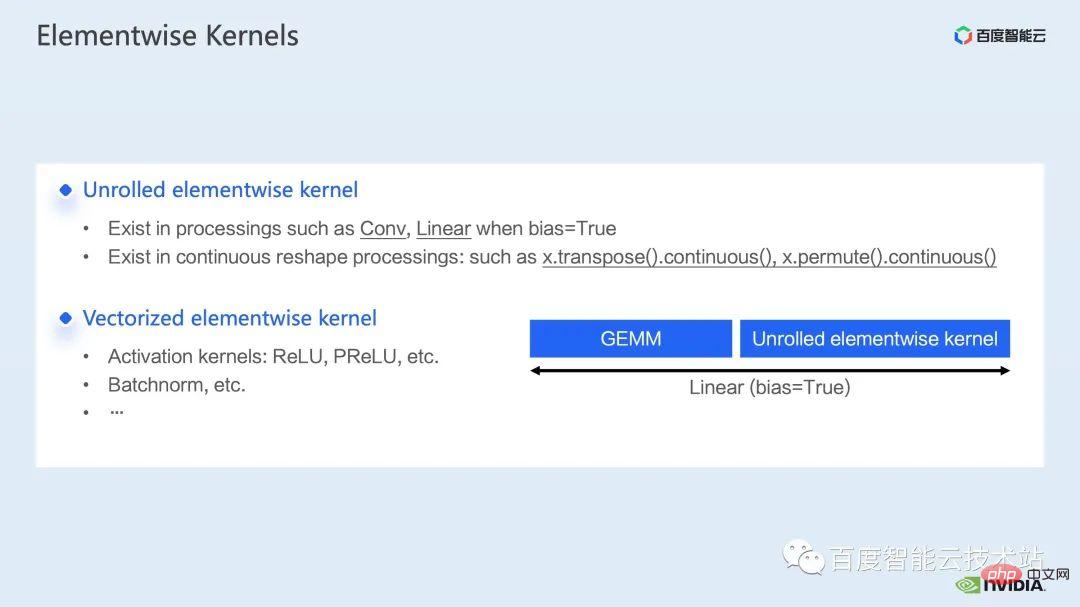
Für den elementweisen Kernel müssen wir zunächst verstehen, wo der elementweise Kernel verwendet wird.
Elementweiser Kernel, der gebräuchlichere entrollte elementweise Kernel und der vektorisierte elementweise Kernel. Unter diesen ist der elementweise entrollte Kernel weit verbreitet in einigen voreingenommenen Faltungen oder linearen Schichten sowie in einigen Operationen, die die Datenkontinuität im Speicher sicherstellen.
Der vektorisierte elementweise Kernel erscheint häufig bei der Berechnung einiger Aktivierungsfunktionen, wie z. B. ReLU. Wenn Sie hier die große Anzahl elementweiser Kernel reduzieren möchten, besteht ein gängiger Ansatz darin, eine Operatorfusion durchzuführen. Bei der Matrixmultiplikation können wir beispielsweise diesen Teil des Zeitaufwands reduzieren, indem wir die elementweise Operation mit dem Operator der Matrixmultiplikation fusionieren.
Im Allgemeinen kann uns die Operatorfusion zwei Vorteile bringen:
Einer besteht darin, die Kosten für den Kernel-Start zu senken, wie in der Abbildung unten gezeigt, zwei Cuda-Kernel. Die Ausführung erfordert zwei Starts , was zu einer Lücke zwischen den Kerneln führen und die GPU inaktiv machen kann. Wenn wir zwei Cuda-Kernel zu einem Cuda-Kernel zusammenführen, sparen wir einerseits einen Start und können gleichzeitig die Entstehung von Lücken vermeiden.
Ein weiterer Vorteil besteht darin, dass der globale Speicherzugriff reduziert wird, da der globale Speicherzugriff sehr zeitaufwändig ist und die Übertragung von Ergebnissen zwischen zwei unabhängigen Cuda-Kerneln eine globale Speicherfusion in einen Kernel erfordert. Wir können Ergebnisse in Register oder gemeinsam genutzten Speicher übertragen. Dadurch wird ein globales Schreiben und Lesen im Speicher vermieden und die Leistung verbessert.

Für die Operatorfusion besteht unser erster Schritt darin, die vorgefertigte Apex-Bibliothek zu verwenden, um die Operationen in Layernorm und Adam zu fusionieren. Es ist ersichtlich, dass wir durch einfaches Ersetzen von Anweisungen die fusionierte Layernorm aktivieren können von Apex und verschmolzenem Adam, wodurch die Beschleunigung von 1,63x auf 2,11x erhöht wird.

Aus dem Profiling-Protokoll können wir auch ersehen, dass nach der Operatorfusion der Anteil des elementweisen Kernels in dieser Zeitleiste stark reduziert wurde und die Matrixmultiplikation wieder zum Kernel mit dem größten Zeitanteil geworden ist .
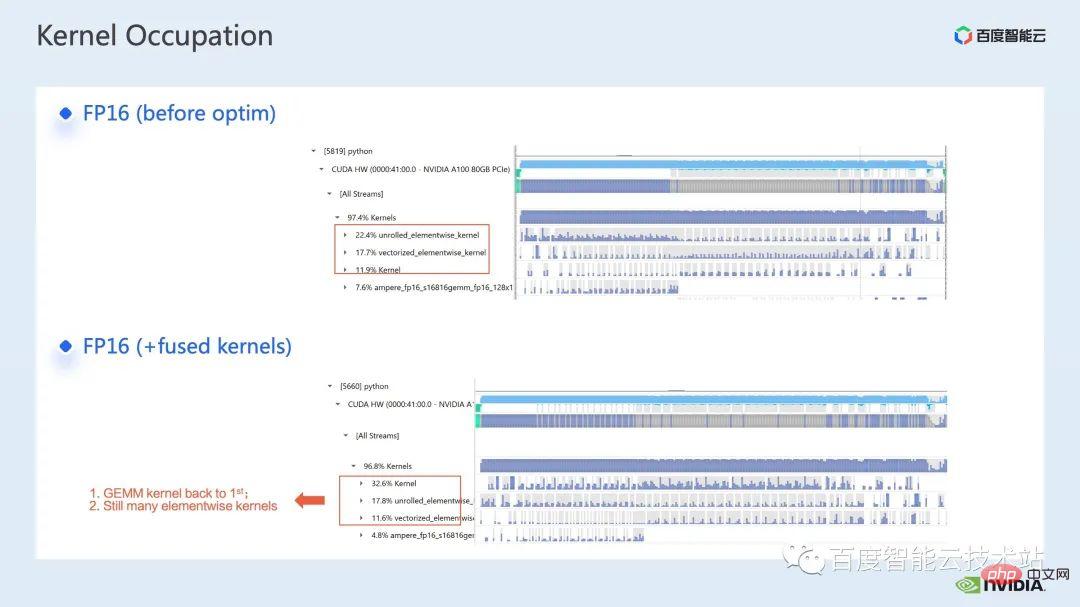
Zusätzlich zur Nutzung der vorhandenen Apex-Bibliothek haben wir auch manuelle Fusionsoperatoren entwickelt.
Durch Beobachtung der Zeitleiste und Verständnis des Modells haben wir festgestellt, dass es in Swin Transformer einzigartige fensterbezogene Vorgänge gibt, wie z. B. Fensterpartition/-verschiebung/-zusammenführung usw. Eine Fensterverschiebung erfordert hier den Aufruf von zwei Kerneln und Der elementweise Kernel wird aufgerufen, nachdem die Verschiebung abgeschlossen ist. Wenn ein solcher Vorgang außerdem vor dem Aufmerksamkeitsmodul ausgeführt werden muss, erfolgt danach ein entsprechender umgekehrter Vorgang. Hier macht allein der durch Window Shift aufgerufene roll_cuda_kernel 4,6 % der gesamten Timeline aus.
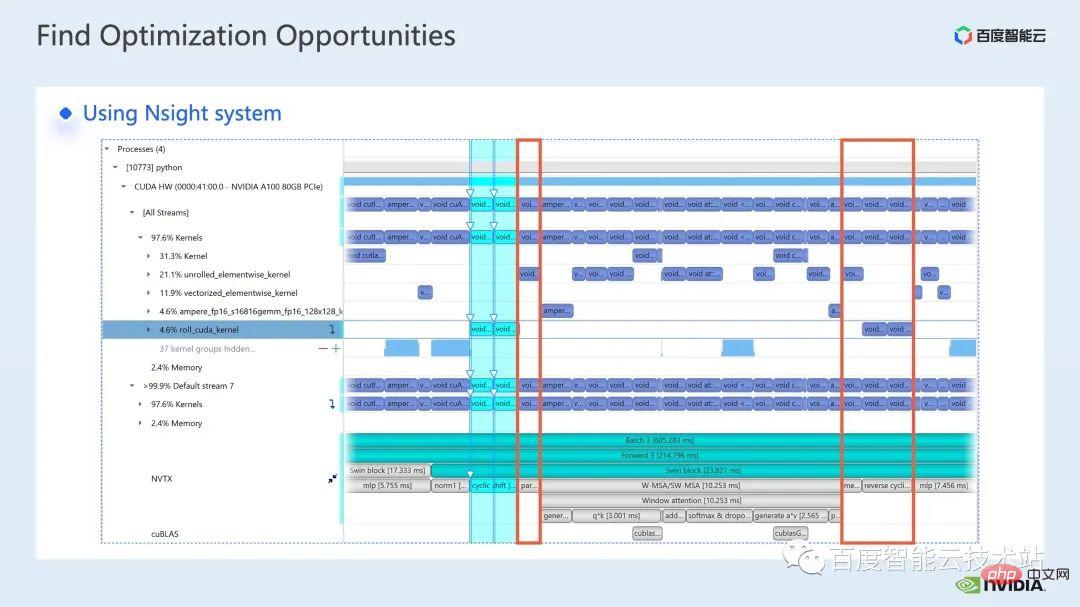
Die gerade erwähnten Vorgänge teilen eigentlich nur die Daten auf, das heißt, die entsprechenden Daten werden in ein Fenster unterteilt. Der entsprechende Originalcode ist in der folgenden Abbildung dargestellt.

Wir haben festgestellt, dass es sich bei diesem Teil der Operation eigentlich nur um eine Indexzuordnung handelt, und haben daher den Fusionsoperator für diesen Teil entwickelt. Während des Entwicklungsprozesses müssen wir die entsprechenden Kenntnisse der CUDA-Programmierung beherrschen und relevante Codes für die Vorwärtsberechnung und Rückwärtsberechnung von Operatoren schreiben.
Wie man benutzerdefinierte Operatoren in Pytorch einführt, wird im offiziellen Tutorial gegeben. Wir können dem Tutorial folgen, um CUDA-Code zu schreiben, und nach der Kompilierung können wir das Originalmodell als Modul einführen. Es ist ersichtlich, dass wir durch die Einführung unseres maßgeschneiderten Fusionsoperators die Geschwindigkeit weiter auf das 2,19-fache steigern können.

Das nächste, was wir zeigen, ist unsere Fusionsarbeit im MHA-Teil.
Mha-Teil ist ein großes Modul im Transformatormodell, daher kann seine Optimierung oft zu größeren Beschleunigungseffekten führen. Wie aus der Abbildung ersichtlich ist, beträgt der Anteil der Operationen im MHA-Teil vor der Operatorfusion 37,69 %, was viele elementweise Kernel umfasst. Wenn wir verwandte Vorgänge schneller in einem separaten Kernel zusammenfassen können, kann die Beschleunigung weiter verbessert werden.
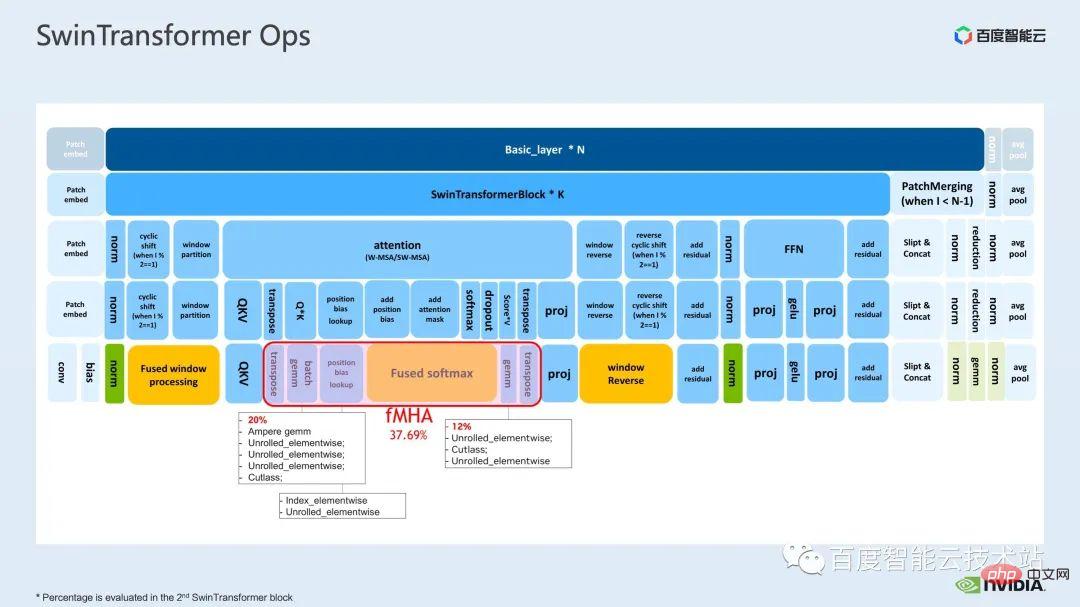
Für Swin Transformer werden zusätzlich zu Abfrage, Schlüssel und Wert auch Maske und Bias in Form eines Tensors übergeben. Mehrere Originalkerne können dies tun integriert werden. Den Berechnungen des fMHA-Moduls zufolge hat dieses Modul einige in Swin Transformer vorkommende Formen erheblich verbessert.

Nachdem wir das fMHA-Modul im Modell verwendet haben, können wir das weiter verbessern Beschleunigungsverhältnis 2,85 mal. Das Obige ist der Trainingsbeschleunigungseffekt, den wir auf einer einzelnen Karte erzielt haben. Schauen wir uns die Trainingssituation mit 8 Karten auf einer einzelnen Maschine an. Wir können sehen, dass wir durch die obige Optimierung den Trainingsdurchsatz von 1612 auf 3733 erhöhen können. Erreichen einer Beschleunigung von 2,32-fach.

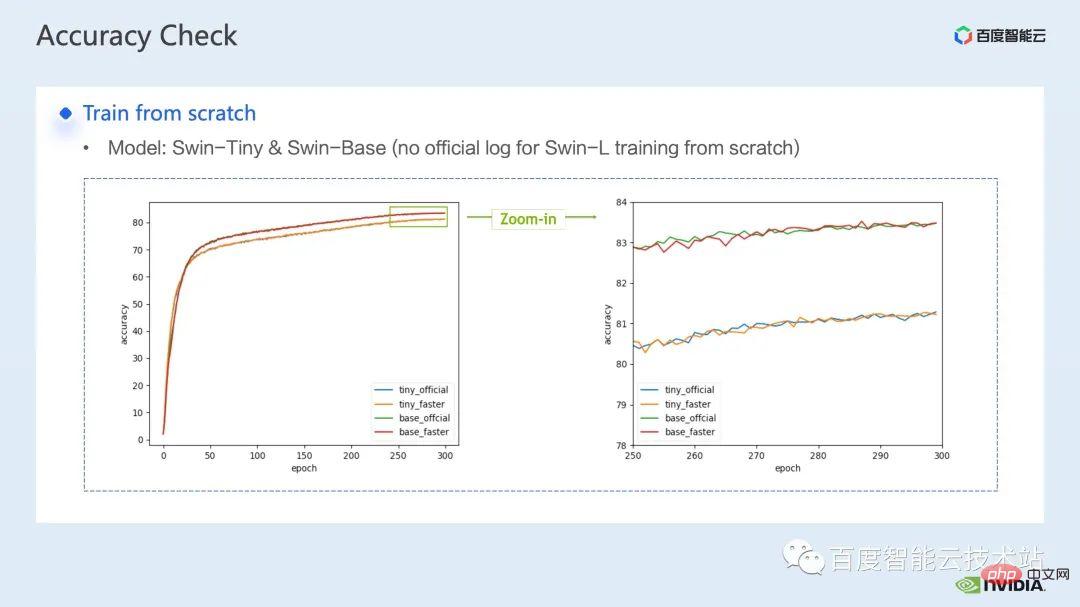
Zur Trainingsoptimierung hoffen wir, dass je höher das Beschleunigungsverhältnis, desto höher die Beschleunigungsrate besser Dementsprechend hoffen wir auch, dass die Leistung nach der Beschleunigung mit der Leistung vor der Beschleunigung übereinstimmen kann.
Nach der Überlagerung der oben genannten verschiedenen Beschleunigungsschemata ist ersichtlich, dass die Konvergenz des Modells mit der ursprünglichen Grundlinie übereinstimmt Konvergenz und Genauigkeitskonsistenz des Modells wurden auf Swin-Tiny, Swin-Base und Swin-Large überprüft.
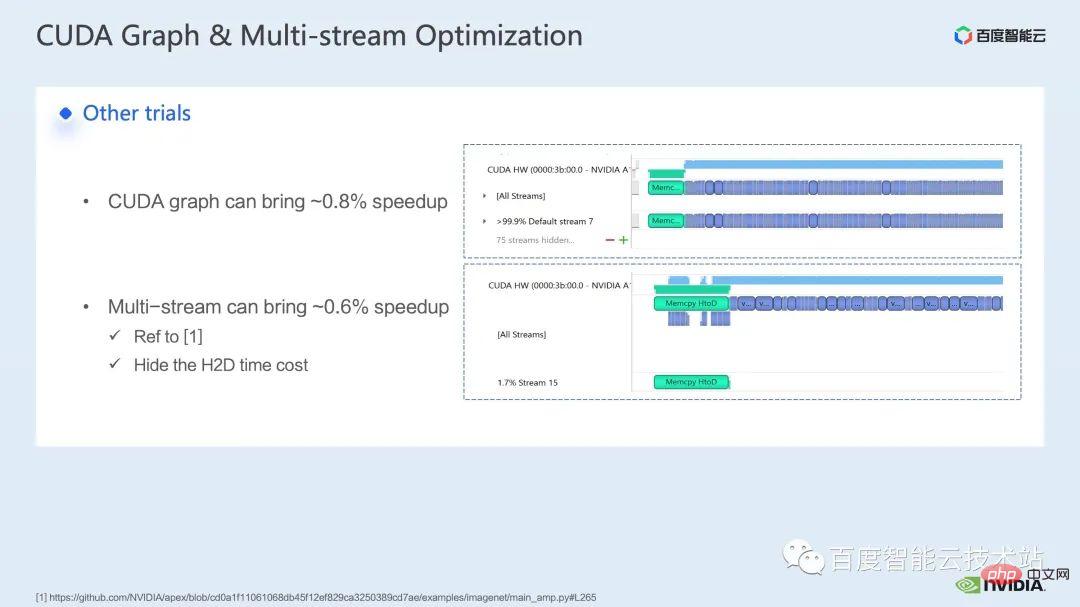
In Bezug auf den Trainingsteil umfassen einige andere Beschleunigungsstrategien CUDA Graph, Multi -Stream usw. können die Leistung von Swin Transformer weiter verbessern. In anderen Aspekten führen wir derzeit die Lösung mit gemischter Präzision ein. Dabei handelt es sich um die Strategie, die vom offiziellen Swin Transformer-Repo übernommen wird ) Kann einen schnelleren Beschleunigungseffekt erzielen.
Obwohl Swin im Vergleich zum ursprünglichen verteilten Training keine hohen Kommunikationsanforderungen für das Training großer Modelle mit mehreren Knoten hat, Durch die Verwendung sinnvoller Strategien zum Verbergen des Kommunikationsaufwands können beim Training mit mehreren Karten weitere Vorteile erzielt werden.
Als nächstes möchte ich meine Kollegen bitten, unsere Argumentationsbeschleunigung vorzustellen Pläne und Wirkungen.
3. Swin Transformer Inferenzoptimierung
Hallo zusammen, ich bin Chen Yu vom GPU-Computing-Expertenteam. Vielen Dank für Tao Lis Einführung zur Trainingsbeschleunigung. Als nächstes möchte ich die Beschleunigung bei Inferenz vorstellen.
Wie beim Training ist die Beschleunigung der Inferenz untrennbar mit der Operator-Fusion-Lösung verbunden. Im Vergleich zum Training bietet die Operatorfusion jedoch eine bessere Flexibilität bei der Inferenz, was sich hauptsächlich in zwei Punkten widerspiegelt: #Die Operatorfusion bei der Inferenz muss die umgekehrte Richtung nicht berücksichtigen, sodass der Kernelentwicklungsprozess keine Einsparungen berücksichtigen muss die zur Berechnung des Gradienten erforderlichen Zwischenergebnisse; kann wiederholt verwendet werden, berechnet sie im Voraus, behält die Ergebnisse bei und ruft sie bei jeder Inferenz direkt auf, um wiederholte Berechnungen zu vermeiden.
- Auf der Inferenzseite können wir viele Operatorfusionen durchführen, was wir in Transformer verwenden Einige gängige Operatorfusionsmuster im Modell und die zum Implementieren verwandter Muster erforderlichen Werkzeuge.
-
Zunächst listen wir Matrixmultiplikation und Faltung getrennt auf, da es eine große Klasse von Operatorfusionen gibt, die sich um sie drehen. Für die Fusion im Zusammenhang mit der Matrixmultiplikation können wir die Verwendung von drei Bibliotheken in Betracht ziehen: cublas, cutlass und cudnn For Für die Faltung können wir cudnn oder cutlass verwenden. Für die Operatorfusion der Matrixmultiplikation fassen wir sie im Transformer-Modell als gemm + elementweise Operation zusammen, wie z. B. gemm + Bias, gemm + Bias + Aktivierungsfunktion usw. Für diese Art der Operatorfusion können wir einen direkten Aufruf in Betracht ziehen Cublas oder Entermesser, um dies zu erreichen.
Wenn die Op-Operationen nach unserem Gemm komplexer sind, wie z. B. Layernorm, Transpose usw., können wir darüber hinaus in Betracht ziehen, Gemm und Bias zu trennen und Bias dann in die nächste Operation zu integrieren, damit dies möglich ist Es ist einfacher, Cublas aufzurufen, um eine einfache Matrixmultiplikation zu implementieren. Natürlich erfordert das Muster der Integration von Bias mit der nächsten Operation im Allgemeinen, dass wir den Cuda-Kernel von Hand schreiben.
Schließlich gibt es einige spezifische Vorgänge, bei denen wir sie auch durch handschriftlichen Cuda-Kernel zusammenführen müssen, z. B. Layernorm + Shift + Fensterpartition.
Da die Operator-Fusion erfordert, dass wir den Cuda-Kernel geschickter entwerfen, empfehlen wir im Allgemeinen, die gesamte Pipeline mit dem Nsight-Systemleistungsanalysetool zu analysieren und der Operator-Fusion-Optimierung für Hotspot-Module Vorrang einzuräumen, um Leistung und Arbeitslastgleichgewicht zu erreichen.

Unter den vielen Optimierungen der Operatorfusion haben wir zwei Operatoren mit offensichtlichen Beschleunigungseffekten zur Einführung ausgewählt.
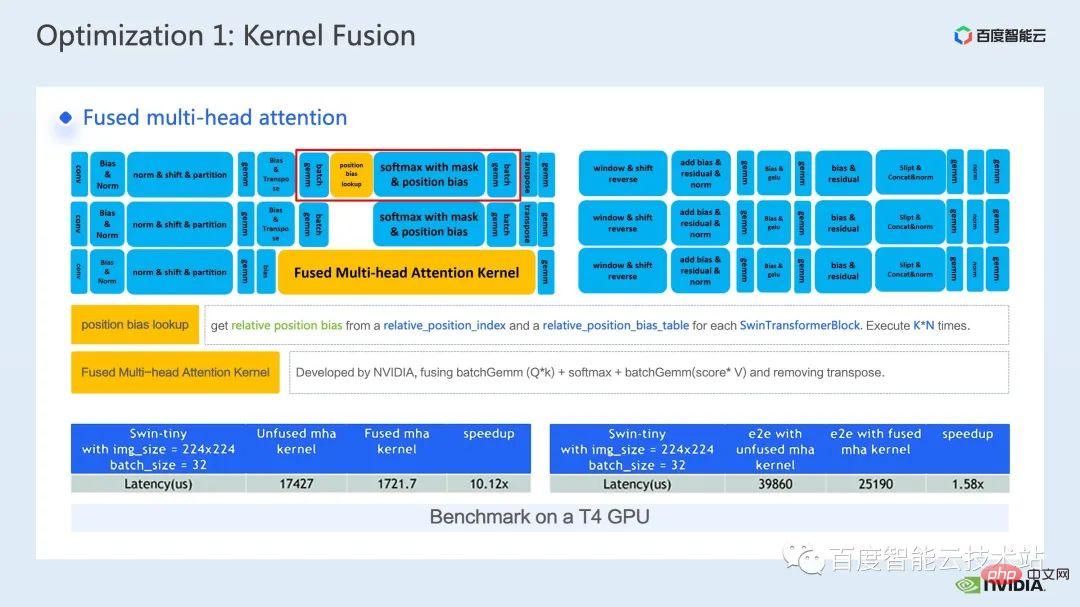
Die erste ist die Operatorfusion des MHA-Teils. Wir erweitern die Positionsbias-Suchoperation auf den Vorverarbeitungsteil, um zu vermeiden, dass wir jedes Mal eine Suche durchführen.
Dann integrieren wir Batch-Gemm, Softmax und Batch-Gemm in einen unabhängigen fMHA-Kernel. Gleichzeitig integrieren wir transponierte Vorgänge in fMHA-Kernel-E/A-Vorgänge und vermeiden diese durch bestimmte Datenlese- und -schreibmuster . Explizite Transponierungsoperationen.
Es ist ersichtlich, dass dieser Teil nach der Fusion eine 10-fache Beschleunigung erreicht hat und die End-to-End-Beschleunigung ebenfalls das 1,58-fache erreicht hat.
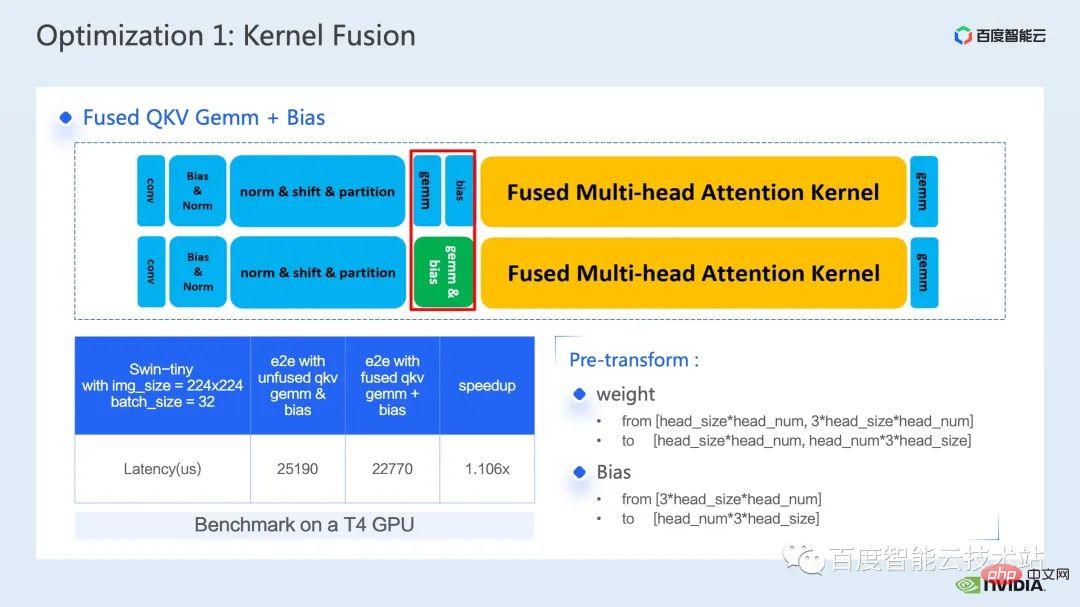
Eine weitere Operatorfusion, die ich vorstellen möchte, ist die Fusion von QKV gemm + Bias.
Die Fusion von Gemm und Bias ist eine sehr verbreitete Fusionsmethode. Um mit dem zuvor erwähnten fMHA-Kernel zusammenzuarbeiten, müssen wir das Gewicht und den Bias im Voraus formatieren.
Der Grund, warum ich mich hier für die Einführung dieser Operatorfusion entscheide, liegt genau darin, dass diese Vorabtransformation die Flexibilität der Operatorfusion in der Argumentation widerspiegelt, wie wir bereits erwähnt haben, und wir über das Modell nachdenken können. Der Prozess nimmt einige Änderungen vor, die dies tun hat keinen Einfluss auf die Genauigkeit, um bessere Operator-Fusionsmuster und bessere Beschleunigungseffekte zu erzielen.
Durch die Integration von QKV gemm+bias können wir schließlich eine End-to-End-Beschleunigung um das 1,1-fache erreichen.
Die nächste Optimierungsmethode ist das Matrixmultiplikationsauffüllen.
Bei der Berechnung von Swin Transformer stoßen wir manchmal auf eine Matrixmultiplikation mit einer ungeraden Hauptdimension. Zu diesem Zeitpunkt ist es für unseren Matrixmultiplikationskern nicht förderlich, vektorisiertes Lesen und Schreiben durchzuführen, was die Betriebseffizienz des Kernels verringert Wenn wir in Betracht ziehen können, die Hauptdimension der an der Operation beteiligten Matrix aufzufüllen, sodass sie ein Vielfaches von 8 wird. Auf diese Weise kann der Matrixmultiplikationskern vektorisiertes Lesen mit Ausrichtung = 8 durchführen und 8 Elemente gleichzeitig lesen und schreiben . Schreiben Sie, um die Leistung zu verbessern.
Wie in der folgenden Tabelle gezeigt, sank die Latenz der Matrixmultiplikation von 60,54us auf 40,38us, nachdem wir n von 49 auf 56 aufgefüllt hatten, wodurch eine 1,5-fache Beschleunigung erreicht wurde.
Die nächste Optimierungsmethode ist die Verwendung von Datentypen wie half2 oder char4.
Der folgende Code ist ein Beispiel für die Half2-Optimierung. Er implementiert eine einfache Operatorfusionsoperation zum Hinzufügen von Bias und Residuen. Sie können sehen, dass wir durch die Verwendung des Datentyps half2 im Vergleich zur Datenklasse half2 reduzieren können die Latenz von 20,96us auf 10,78us, eine Beschleunigung um das 1,94-fache.
Was sind also die allgemeinen Vorteile der Verwendung des Datentyps half2? Es gibt drei Hauptpunkte:
Der erste Vorteil besteht darin, dass vektorisiertes Lesen und Schreiben die Bandbreitennutzungseffizienz des Speichers verbessern und die Anzahl der Speicherzugriffsanweisungen reduzieren kann, wie auf der rechten Seite der Abbildung unten gezeigt Durch die Verwendung von half2 werden die Speicherzugriffsanweisungen reduziert. Gleichzeitig wurde auch die SOL des Speichers erheblich verbessert. Der zweite Vorteil besteht darin, dass in Kombination mit den proprietären mathematischen Anweisungen mit hohem Durchsatz von half2 die Die Latenz des Kernels kann reduziert werden. Beide Punkte wurden in diesem Beispielprogramm berücksichtigt.
Der dritte Vorteil besteht darin, dass bei der Entwicklung reduktionsbezogener Kernel die Verwendung des Datentyps half2 bedeutet, dass ein Cuda-Thread zwei Elemente gleichzeitig verarbeitet effektiv reduzieren Die Anzahl der inaktiven Threads kann auch die Latenz der Thread-Synchronisierung verringern.
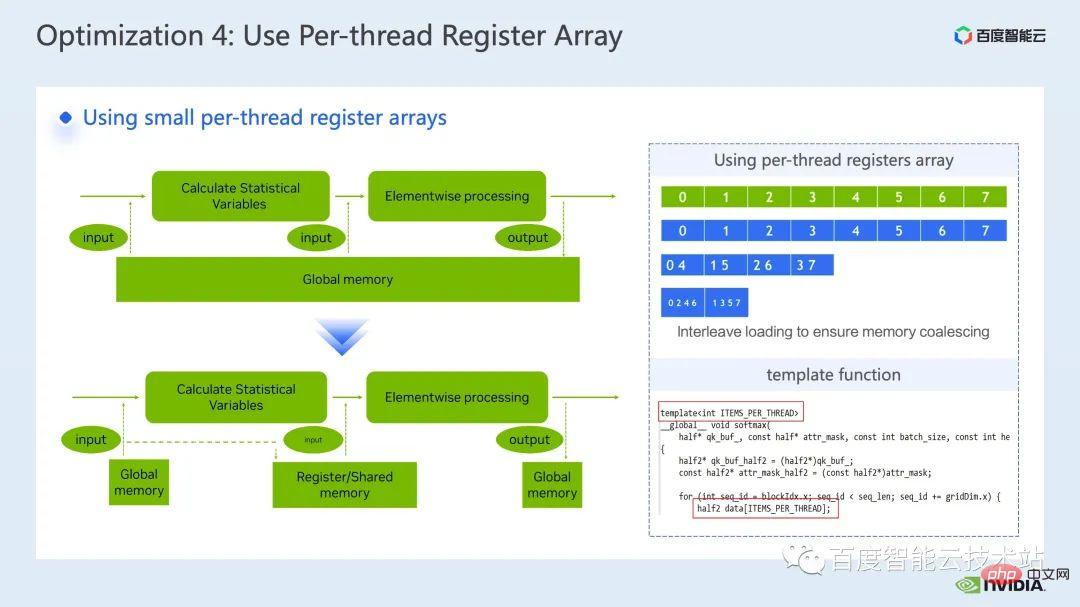
Die nächste Optimierungsmethode besteht darin, Registerarrays geschickt zu nutzen.
Wenn wir gängige Operatoren von Transformer-Modellen wie Layernorm oder Softmax optimieren, müssen wir häufig dieselben Eingabedaten mehrmals in einem Kernel verwenden. Anstatt also jedes Mal aus dem globalen Speicher zu lesen, können wir Arrays registrieren Wird zum Zwischenspeichern von Daten verwendet, um wiederholte Lesevorgänge im globalen Speicher zu vermeiden.
Da Register exklusiv für jeden Cuda-Thread gelten, müssen wir beim Entwerfen des Kernels die Anzahl der Elemente festlegen, die jeder Cuda-Thread im Voraus zwischenspeichern muss, um ein Registerarray entsprechender Größe zu öffnen. und Bei der Zuweisung der für jeden Cuda-Thread verantwortlichen Elemente müssen wir sicherstellen, dass wir einen kombinierten Zugriff erreichen können, wie oben rechts in der Abbildung unten gezeigt. Wenn wir 8 Threads haben, kann Thread 0 Element 0 verarbeiten 4 Threads Ja, Thread Nr. 0 verarbeitet die Elemente Nr. 0 und Nr. 4 usw.
Wir empfehlen im Allgemeinen die Verwendung von Vorlagenfunktionen, um die Registerarraygröße jedes CUDA-Threads über Vorlagenparameter zu steuern.
Außerdem müssen wir bei Verwendung eines Registerarrays sicherstellen, dass unsere Indizes Konstanten sind. Wenn eine Schleifenvariable als Subskript verwendet wird, sollten wir versuchen, sicherzustellen, dass eine Schleifenerweiterung durchgeführt werden kann , um zu verhindern, dass der Compiler die Daten mit hoher Latenz im lokalen Speicher ablegt, wie in der Abbildung unten gezeigt, fügen wir Einschränkungen in die Schleifenbedingungen ein, die im NCU-Bericht sichtbar sind, um die Verwendung des lokalen Speichers zu vermeiden.
Die letzte Optimierungsmethode, die ich vorstellen möchte, ist die INT8-Quantisierung.
INT8-Quantisierung ist eine sehr wichtige Beschleunigungsmethode für die Inferenzbeschleunigung. Bei Transformer-basierten Modellen kann die INT8-Quantisierung den Speicherverbrauch reduzieren und gleichzeitig eine bessere Leistung bringen.
Für Swin können Sie durch die Kombination eines geeigneten PTQ- oder QAT-Quantisierungsschemas eine gute Beschleunigung erreichen und gleichzeitig die Quantisierungsgenauigkeit sicherstellen. Im Allgemeinen führen wir eine int8-Quantisierung durch, hauptsächlich um die Matrixmultiplikation oder -faltung zu quantisieren. Bei der int8-Matrixmultiplikation quantisieren wir beispielsweise zuerst die ursprüngliche FP32- oder FP16-Eingabe und gewichten sie in INT8 und führen dann eine INT8-Matrixmultiplikation durch und akkumulieren sie zu INT32-Daten Was das betrifft, würden wir hier eine inverse Quantisierungsoperation durchführen und das Ergebnis von FP32 oder FP16 erhalten.
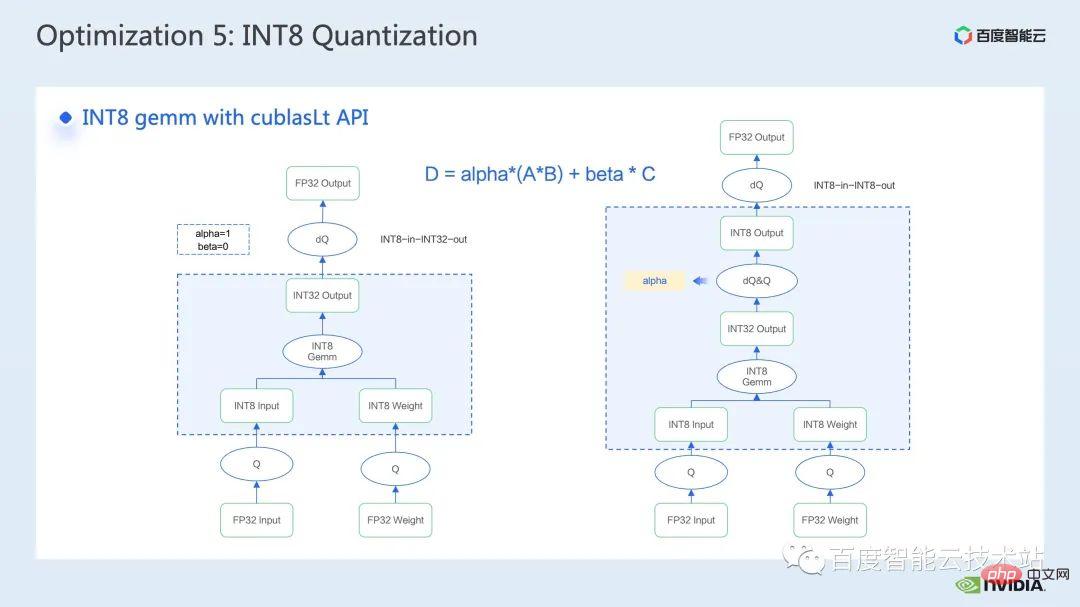
Das gebräuchlichere Tool zum Aufrufen der INT8-Matrixmultiplikation ist cublasLt. Um eine bessere Leistung zu erzielen, müssen wir einige Funktionen der cublasLt-API genau verstehen.
cublasLt Für die int8-Matrixmultiplikation stehen zwei Ausgabetypen zur Verfügung, die wie auf der linken Seite der Abbildung unten gezeigt als INT32 oder wie auf der rechten Seite der Abbildung unten als INT8 ausgegeben werden , wie in der blauen Box in der Abbildung gezeigt. Rechenoperation von cublasLt.
Sie können sehen, dass die INT8-Ausgabe im Vergleich zur INT32-Ausgabe ein zusätzliches Paar inverser Quantisierungs- und Quantisierungsoperationen aufweist, was jedoch aufgrund der INT8-Ausgabe beim Schreiben zu mehr Genauigkeit führt Speicher ist die Menge der ausgegebenen Daten 3/4 geringer als die von INT32 und die Leistung ist besser, sodass ein Kompromiss zwischen Genauigkeit und Leistung besteht.
Für Swin Transformer haben wir also festgestellt, dass die Ausgabe in INT8 in Verbindung mit QAT die Genauigkeit unter der Voraussetzung gewährleistet, dass ein gutes Beschleunigungsverhältnis erreicht wird, da wir die INT8-Ausgabelösung übernommen haben.
Außerdem müssen Sie bei der INT8-Matrixmultiplikation in cublasLt auch das Layout der Daten berücksichtigen, ein IMMA-spezifisches Layout, das einige komplexere Formate beinhaltet. Darüber hinaus unterstützt dieses Layout nur NT-gemm, und das andere ist ein herkömmliches Column-First-Layout, das TN-gemm in diesem Layout unterstützt.
Im Allgemeinen ist die Verwendung eines spaltenorientierten Layouts für die Entwicklung des gesamten Pipeline-Codes förderlicher, da wir bei Verwendung eines IMMA-spezifischen Layouts möglicherweise viele zusätzliche Vorgänge benötigen, um mit diesem Layout kompatibel zu sein sowie Upstream und Downstream Der Kernel muss auch mit diesem speziellen Layout kompatibel sein. Allerdings bietet das IMMA-spezifische Layout möglicherweise eine bessere Leistung bei der Matrixmultiplikation einiger Größen. Wenn wir also versuchen möchten, int8-Argumentation aufzubauen, wird empfohlen, zunächst einige Benchmarks durchzuführen, um die Leistung und die Entwicklungsfreundlichkeit besser zu verstehen .
In FasterTransformer verwenden wir IMMA-spezifisches Layout. Als nächstes nehmen wir das IMMA-spezifische Layout als Beispiel, um kurz den grundlegenden Konstruktionsprozess der cublasLt int8-Matrixmultiplikation sowie einige Entwicklungstechniken vorzustellen.
cublasLt int8 Der grundlegende Konstruktionsprozess der Matrixmultiplikation kann in 5 Schritte unterteilt werden:
- Zuerst müssen wir Handles und Multiplikationsdeskriptoren erstellen. Als nächstes erstellen wir einen Matrixdeskriptor für jede Matrix 🎜#Da unsere Eingabe im Allgemeinen ein reguläres Layout ist, müssen wir die herkömmliche Layoutmatrix in ein IMMA-spezifisches Layout umwandeln. 🎜🎜#
- und führen Sie dann eine int8-Matrixmultiplikation durch. Nachdem wir das Ergebnis erhalten haben, können wir erwägen, dieses Ergebnis weiterhin für nachgelagerte Multiplikationsberechnungen zu verwenden, um den Aufwand für die Konvertierung in das reguläre Layout zu vermeiden 🎜 #Nur das Ergebnis der letzten Matrixmultiplikation, wir müssen das reguläre Layout für die Ausgabe konvertieren.
- Das Obige stellt den Bauprozess unter dem IMMA-spezifischen Layout vor. Sie können sehen, dass es viele Einschränkungen gibt. Um die Auswirkungen dieser Einschränkungen auf die Leistung zu vermeiden, haben wir die folgenden Techniken in Faster Transformer übernommen:
- First IMMA - Das spezifische Layout stellt spezifische Größenanforderungen für die Matrix. Um zu vermeiden, dass während des Inferenzprozesses zusätzlicher Speicherplatz zugewiesen werden muss, weisen wir im Voraus Puffer zu, die der IMMA-spezifischen Layoutgröße entsprechen ## 🎜🎜# Da das Gewicht dann einmal verarbeitet und wiederverwendet werden kann, führen wir im Voraus eine Layouttransformation des Gewichts durch (entspricht der B-Matrix bei der Multiplikation), um wiederholte Änderungen zu vermeiden Gewicht während des Inferenzprozesses; 🎜🎜#
- Der dritte Trick besteht darin, dass wir für A und C, die einer speziellen Layouttransformation unterzogen werden müssen, das kombinieren Die Transformation mit der Upstream- oder Downstream-Operatorfusion wird durchgeführt, um diesen Teil des Overheads zu verbergen. Bei einigen Quantisierungs- und inversen Quantisierungsoperationen werden wir auch die Operatorfusion verwenden, um die Latenz zu verbergen.
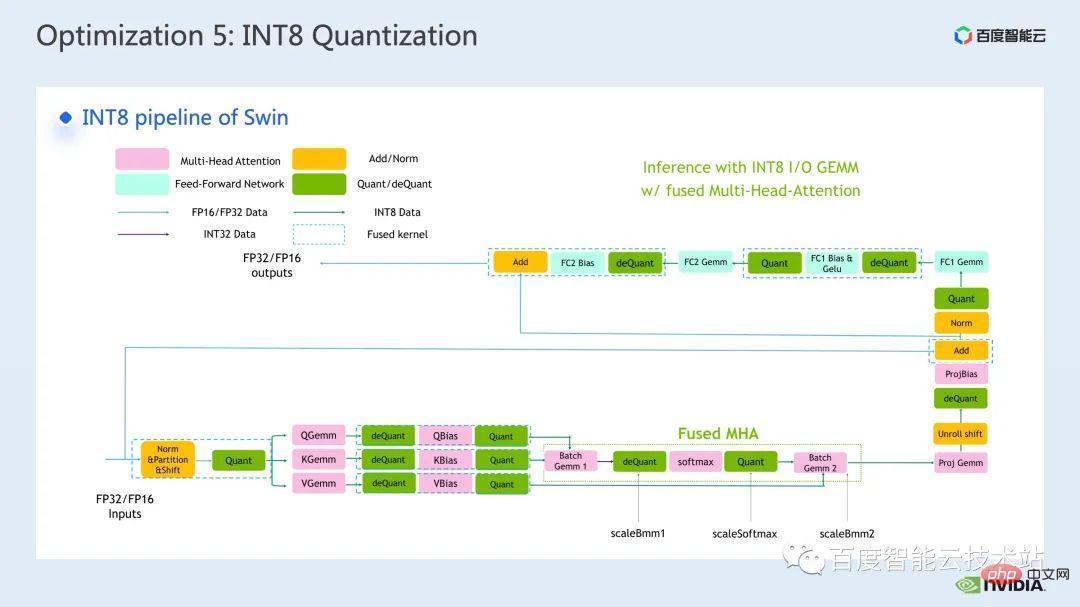
- Die folgenden sind diejenigen, die wir in Faster Transformer verwenden Schematische Darstellung des INT8-Prozesses Es ist ersichtlich, dass vor und nach jeder int8-Matrixmultiplikation entsprechende Quantisierungs- und Dequantisierungsknoten eingefügt werden. Wir behalten immer noch den ursprünglichen FP32- oder FP16-Datentyp bei, natürlich kann seine E/A int8 sein, was eine bessere E/A-Leistung als FP16 oder FP32 bietet.
- Was hier gezeigt wird, ist die Genauigkeit der Swin Transformer int8-Quantisierung durch QAT Wir können garantieren, dass der Genauigkeitsverlust innerhalb von 5 Promille liegt.
- In der PTQ-Spalte können wir sehen, dass Swin-Large einen schwerwiegenden Punktverlust aufweist, was im Allgemeinen schwerwiegenden Punktverlustproblemen entspricht . Wir können alle darüber nachdenken, einige Quantisierungsknoten zu reduzieren, um die Quantisierungsgenauigkeit zu verbessern. Dies kann natürlich zu einer Abschwächung des Beschleunigungseffekts führen.
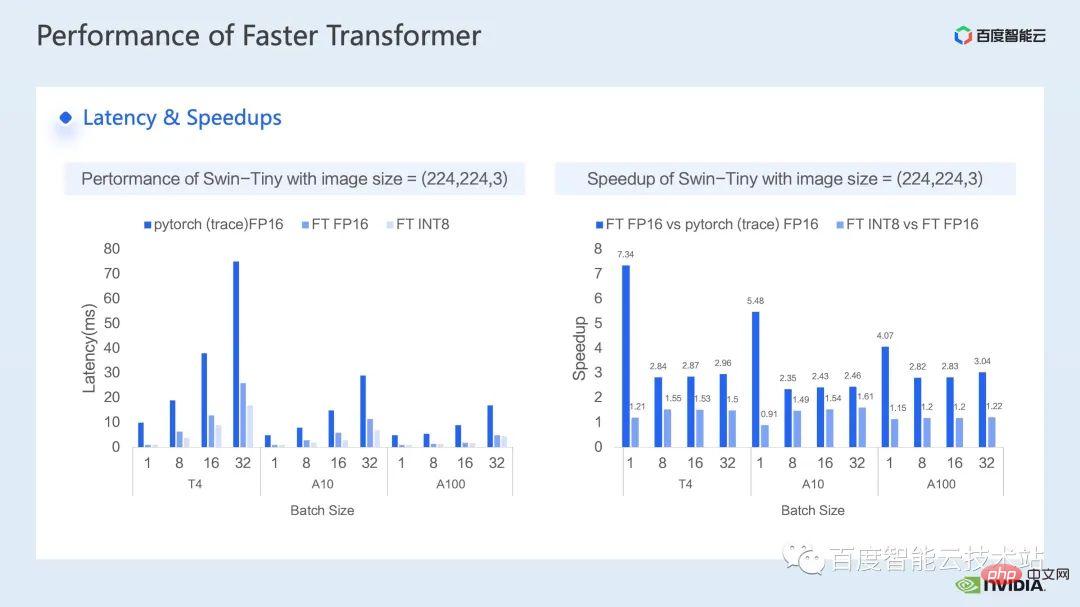
Als nächstes kommt der Beschleunigungseffekt, den wir auf der Inferenzseite erzielt haben verschiedener GPU-Modelle T4, A10 und A100 wurde mit dem von Pytorch FP16 verglichen.
Die linke Seite der folgenden Abbildung zeigt den Latenzvergleich zwischen Optimierung und Pytorch, und die rechte Abbildung zeigt das Beschleunigungsverhältnis zwischen FP16 und Pytorch nach der Optimierung sowie das Beschleunigungsverhältnis zwischen der INT8-Optimierung und FP16-Optimierung. Es ist ersichtlich, dass wir durch Optimierung eine Beschleunigung von 2,82x bis 7,34x im Vergleich zu Pytorch in Bezug auf die FP16-Genauigkeit erreichen können. In Kombination mit der INT8-Quantisierung können wir auf dieser Basis eine weitere Beschleunigung von 1,2x bis 1,5x erreichen.
4. Zusammenfassung der Swin Transformer-Optimierung
In diesem Beitrag haben wir abschließend vorgestellt, wie man Leistungsengpässe mithilfe des nsight-Systemleistungsanalysetools findet Ziel Leistungsengpässe, eine Reihe von Techniken zur Beschleunigung der Trainingsinferenz werden eingeführt, darunter 1. Training mit gemischter Präzision/Inferenz mit geringer Präzision, 2. Operatorfusion, 3. Cuda-Kernel-Optimierungstechniken: wie Matrix-Null-Padding, vektorisiertes Lesen und Schreiben und Clever Verwendung von Registern, Arrays usw., 4. Ein Teil der Vorverarbeitung wird zur Inferenzoptimierung verwendet, um unseren Berechnungsprozess zu verbessern. Wir haben auch einige Anwendungen von Multi-Stream und Cuda-Graph eingeführt.
In Kombination mit der obigen Optimierung haben wir das Swin-Large-Modell als Beispiel verwendet, um ein Beschleunigungsverhältnis von 2,85x für a zu erreichen Das Beschleunigungsverhältnis von 8 Karten beträgt 2,32x; am Beispiel des Swin-tiny-Modells wird unter FP16-Genauigkeit ein Beschleunigungsverhältnis von 2,82x bis 7,34x erreicht Es wird ein Beschleunigungsverhältnis von 1,2x ~ 1,5x erreicht.
Die oben genannten Beschleunigungsmethoden für das Training und die Inferenz großer visueller Modelle wurden veröffentlicht auf Baidu Es ist in der AIAK-Beschleunigungsfunktion der heterogenen Computerplattform Baige AI implementiert. Jeder ist willkommen, es zu verwenden.








Das obige ist der detaillierte Inhalt vonWie können große visuelle Modelle verwendet werden, um Training und Inferenz zu beschleunigen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1655
1655
 14
1414
52
1307
25
1253
29
1227
24
14
1414
52
1307
25
1253
29
1227
24

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Projektlink vorne geschrieben: https://nianticlabs.github.io/mickey/ Anhand zweier Bilder kann die Kameraposition zwischen ihnen geschätzt werden, indem die Korrespondenz zwischen den Bildern hergestellt wird. Normalerweise handelt es sich bei diesen Entsprechungen um 2D-zu-2D-Entsprechungen, und unsere geschätzten Posen sind maßstabsunabhängig. Einige Anwendungen, wie z. B. Instant Augmented Reality jederzeit und überall, erfordern eine Posenschätzung von Skalenmetriken und sind daher auf externe Tiefenschätzer angewiesen, um die Skalierung wiederherzustellen. In diesem Artikel wird MicKey vorgeschlagen, ein Keypoint-Matching-Prozess, mit dem metrische Korrespondenzen im 3D-Kameraraum vorhergesagt werden können. Durch das Erlernen des 3D-Koordinatenabgleichs zwischen Bildern können wir auf metrische Relativwerte schließen
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
