

Im Jahr 2012 schlugen Hinton et al. in ihrer Arbeit „Verbesserung neuronaler Netze durch Verhinderung der Co-Adaption von Merkmalsdetektoren“ einen Ausstieg vor. Im selben Jahr eröffnete die Entstehung von AlexNet eine neue Ära des Deep Learning. AlexNet nutzt Dropout, um die Überanpassung deutlich zu reduzieren und spielte eine Schlüsselrolle beim Sieg im ILSVRC 2012-Wettbewerb. Es genügt zu sagen, dass sich die Fortschritte, die wir derzeit beim Deep Learning sehen, ohne Schulabbrecher möglicherweise um Jahre verzögert hätten.
Seit der Einführung von Dropout wird es häufig als Regularisierer verwendet, um Überanpassung in neuronalen Netzen zu reduzieren. Dropout deaktiviert jedes Neuron mit der Wahrscheinlichkeit p und verhindert so, dass sich verschiedene Merkmale aneinander anpassen. Nach der Anwendung von Dropout steigt normalerweise der Trainingsverlust, während der Testfehler abnimmt, wodurch die Generalisierungslücke des Modells geschlossen wird. Die Entwicklung des Deep Learning führt weiterhin zur Einführung neuer Technologien und Architekturen, aber es gibt immer noch Abbrecher. Es spielt weiterhin eine Rolle bei den neuesten KI-Errungenschaften wie der AlphaFold-Proteinvorhersage, der DALL-E 2-Bilderzeugung usw. und demonstriert Vielseitigkeit und Wirksamkeit.
Trotz der anhaltenden Beliebtheit von Schulabbrechern ist ihre Intensität (ausgedrückt als Drop-Rate p) im Laufe der Jahre zurückgegangen. Bei der anfänglichen Dropout-Bemühung wurde eine Standard-Drop-Rate von 0,5 verwendet. In den letzten Jahren werden jedoch häufig niedrigere Drop-Raten verwendet, z. B. 0,1. Ähnliche Beispiele finden sich im Training von BERT und ViT. Der Hauptgrund für diesen Trend ist die explosionsartige Zunahme verfügbarer Trainingsdaten, die eine Überanpassung immer schwieriger macht. In Kombination mit anderen Faktoren kann es schnell zu mehr Unteranpassungs- als Überanpassungsproblemen kommen.
Kürzlich haben Forscher von Meta AI, der University of California, Berkeley und anderen Institutionen in einem Artikel mit dem Titel „Dropout Reduces Underfitting“ gezeigt, wie man Dropout zur Lösung von Underfitting-Fragen nutzen kann.
Papieradresse: https://arxiv.org/abs/2303.01500
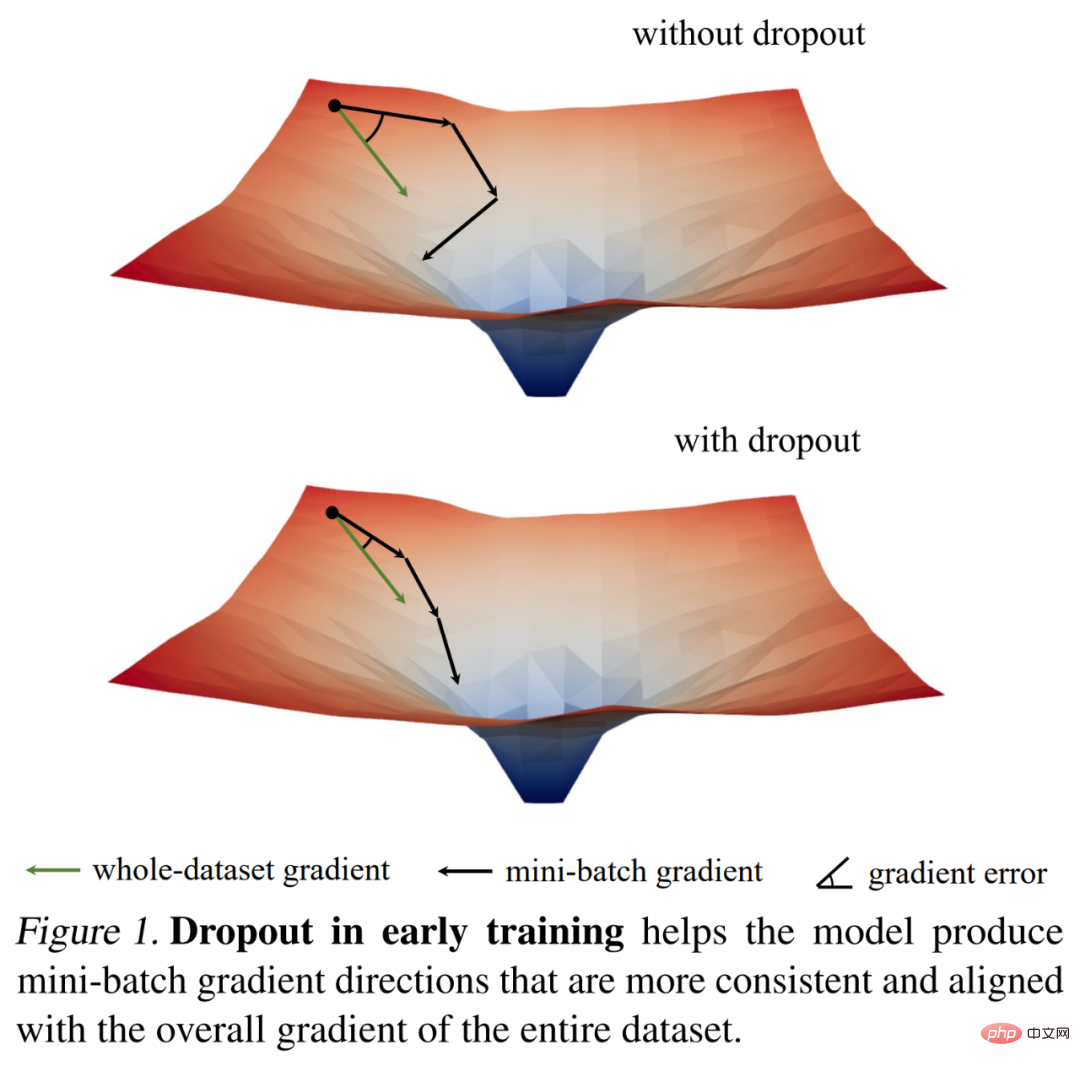
Sie untersuchten zunächst die Trainingsdynamik von Dropouts anhand interessanter Beobachtungen zur Gradientennorm und kamen dann zu einem wichtigen empirischen Ergebnis: In der Anfangsphase des Trainings verringert Dropout die Gradientenvarianz des Mini-Batches und ermöglicht das Modell um konsequenter in die Richtung aktualisiert zu werden. Diese Richtungen stimmen auch besser mit den Gradientenrichtungen im gesamten Datensatz überein, wie in Abbildung 1 unten dargestellt.
Daher kann das Modell den Trainingsverlust des gesamten Trainingssatzes effektiver optimieren, ohne durch einzelne Mini-Batches beeinträchtigt zu werden. Mit anderen Worten: Dropout wirkt dem stochastischen Gradientenabstieg (SGD) entgegen und verhindert eine Überregularisierung, die durch die Zufälligkeit der abgetasteten Mini-Batches zu Beginn des Trainings verursacht wird.
Basierend auf diesem Befund schlugen Forscher einen frühen Abbruch vor. Wird nur zu Beginn der Ausbildung eingesetzt ), um unterfitten Modellen zu helfen, besser zu passen. Ein früher Abbruch reduziert den endgültigen Trainingsverlust im Vergleich zu keinem Abbruch und einem Standardabbruch. Im Gegensatz dazu empfehlen Forscher für Modelle, die bereits Standard-Dropout verwenden, das Entfernen von Dropout in frühen Trainingsepochen, um eine Überanpassung zu reduzieren. Sie nannten diese Methode Late Dropout und zeigten, dass sie die Generalisierungsgenauigkeit großer Modelle verbessern kann. Abbildung 2 unten vergleicht Standard-, Früh- und Spätabbrecher. Forscher verwenden unterschiedliche Modelle zur Bildklassifizierung und nachgelagerten Aufgaben, um Early Dropout und Late Dropout zu bewerten. Die Ergebnisse zeigen, dass beide durchweg bessere Ergebnisse liefern als Standard-Dropout und kein Dropout. Sie hoffen, dass ihre Ergebnisse neue Einblicke in Dropout und Überanpassung liefern und die weitere Entwicklung von Regularisierern für neuronale Netze inspirieren können.
Analyse und Verifizierung

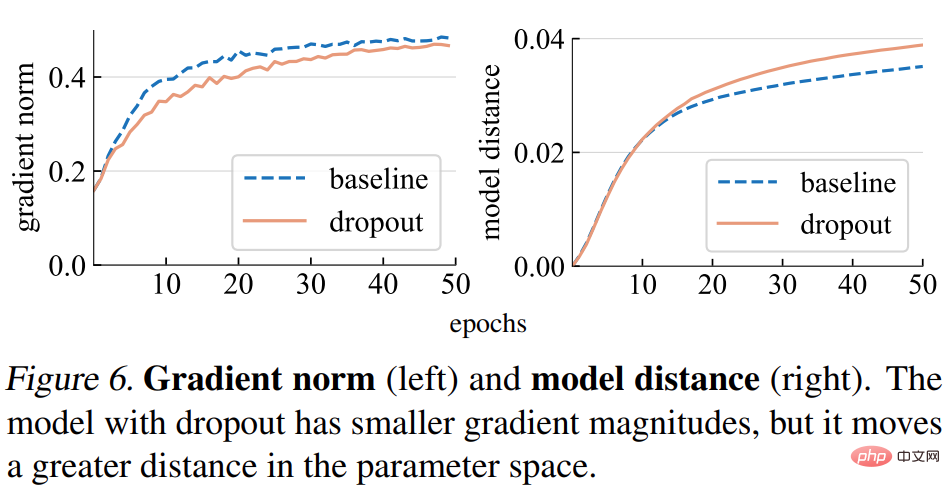
Gradientennorm (Norm). Diese Studie analysiert zunächst den Einfluss von Dropout auf die Stärke des Gradienten g. Wie in Abbildung 6 (links) unten dargestellt, erzeugt das Dropout-Modell Verläufe mit kleineren Normen, was darauf hinweist, dass es bei jeder Verlaufsaktualisierung kleinere Schritte durchführt.
Modellentfernung. Da die Schrittgröße des Gradienten kleiner ist, erwarten wir, dass sich das Dropout-Modell relativ zu seinem Anfangspunkt um eine kleinere Strecke bewegt als das Basismodell. Wie in Abbildung 6 (rechts) unten dargestellt, stellt die Studie den Abstand jedes Modells von seiner zufälligen Initialisierung dar. Überraschenderweise bewegte sich das Dropout-Modell jedoch tatsächlich um eine größere Strecke als das Basismodell, im Gegensatz zu dem, was die Studie ursprünglich aufgrund der Gradientennorm erwartet hatte.
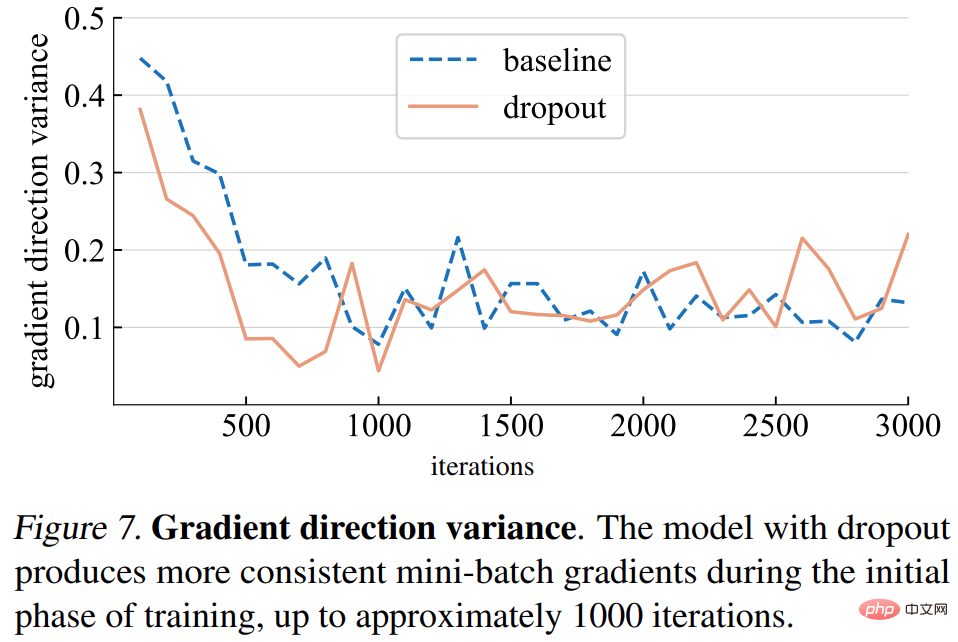
Gradientenrichtungsvarianz. Die Studie stellt zunächst die Hypothese auf, dass Dropout-Modelle konsistentere Gradientenrichtungen über Mini-Batches hinweg erzeugen. Die in Abbildung 7 unten dargestellten Abweichungen stimmen im Allgemeinen mit den Annahmen überein. Bis zu einer bestimmten Anzahl von Iterationen (ca. 1000) schwanken die Gradientenvarianzen sowohl des Dropout-Modells als auch des Basismodells auf einem niedrigen Niveau.
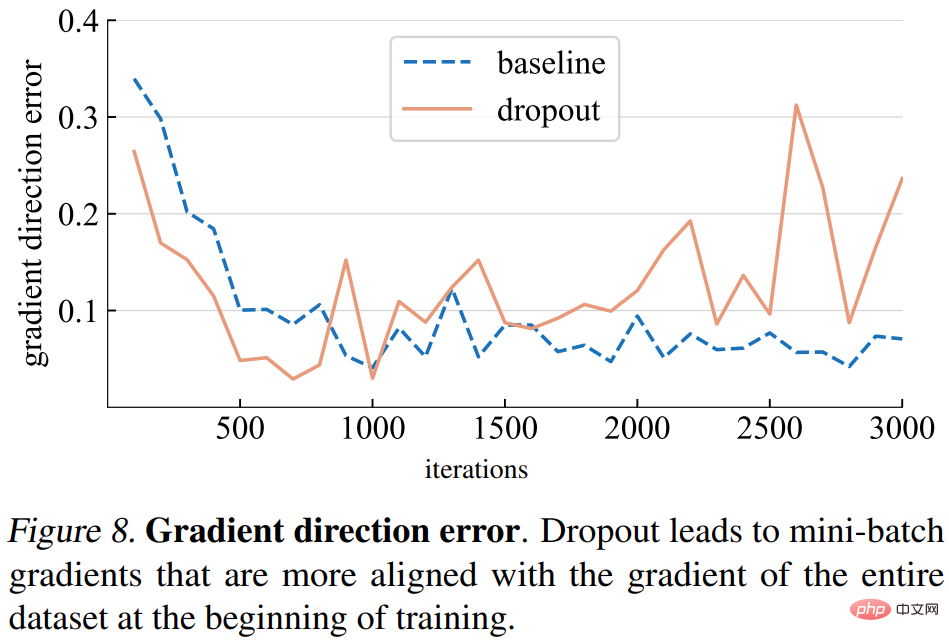
Gradientenrichtungsfehler. Was sollte jedoch die richtige Gradientenrichtung sein? Um die Trainingsdaten anzupassen, besteht das grundlegende Ziel darin, den Verlust des gesamten Trainingssatzes und nicht nur den Verlust eines einzelnen Mini-Batches zu minimieren. Die Studie berechnet den Gradienten eines bestimmten Modells über den gesamten Trainingssatz, wobei Dropout auf den Inferenzmodus eingestellt ist, um den Gradienten des gesamten Modells zu erfassen. Der Gradientenrichtungsfehler ist in Abbildung 8 unten dargestellt.
Basierend auf der obigen Analyse ergab diese Studie, dass die frühzeitige Verwendung von Dropout möglicherweise die Fähigkeit des Modells verbessern kann, die Trainingsdaten anzupassen. Ob eine bessere Anpassung an die Trainingsdaten erforderlich ist, hängt davon ab, ob das Modell eine Unter- oder Überanpassung aufweist, was schwierig genau zu definieren sein kann. In der Studie wurden die folgenden Kriterien verwendet:
Der Zustand des Modells hängt nicht nur von der Modellarchitektur ab, sondern auch vom verwendeten Datensatz und anderen Trainingsparametern.
Dann wurden in der Studie zwei Methoden vorgeschlagen: früher Schulabbrecher und später Schulabbrecher
früher Schulabbrecher. Modelle mit unzureichender Anpassung verwenden standardmäßig kein Dropout. Um die Anpassungsfähigkeit an Trainingsdaten zu verbessern, schlägt diese Studie einen frühen Abbruch vor: Verwenden Sie den Abbruch vor einer bestimmten Iteration und deaktivieren Sie ihn dann während des restlichen Trainingsprozesses. Die Forschungsexperimente zeigen, dass ein früher Abbruch den endgültigen Trainingsverlust reduziert und die Genauigkeit verbessert.
später Schulabbrecher. Standard-Dropout ist bereits in den Trainingseinstellungen für Overfitting-Modelle enthalten. In den frühen Phasen des Trainings kann ein Abbruch unbeabsichtigt zu einer Überanpassung führen, was unerwünscht ist. Um die Überanpassung zu reduzieren, schlägt diese Studie einen späten Dropout vor: Der Dropout wird nicht vor einer bestimmten Iteration verwendet, sondern im Rest des Trainings.
Die in dieser Studie vorgeschlagene Methode ist in Konzept und Umsetzung einfach, wie in Abbildung 2 dargestellt. Die Implementierung erfordert zwei Hyperparameter: 1) die Anzahl der Epochen, die gewartet werden müssen, bevor der Dropout aktiviert oder deaktiviert wird; 2) die Dropout-Rate p, die der Standard-Dropout-Rate ähnelt; Diese Studie zeigt, dass diese beiden Hyperparameter die Robustheit der vorgeschlagenen Methode gewährleisten können.
Die Forscher führten eine empirische Auswertung des ImageNet-1K-Klassifizierungsdatensatzes mit 1000 Klassen und 1,2 Millionen Trainingsbildern durch und berichteten über eine erstklassige Validierungsgenauigkeit.
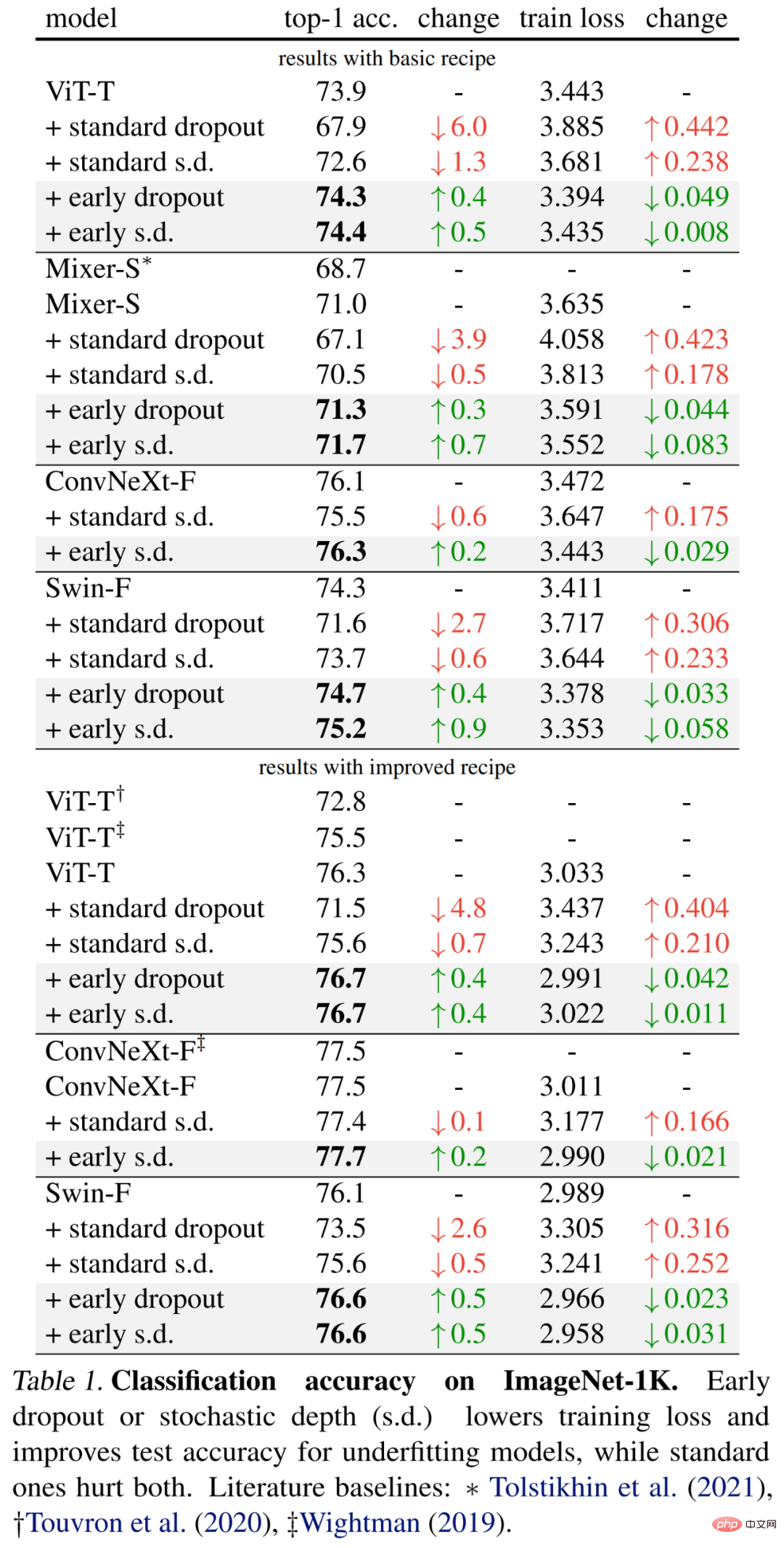
Die spezifischen Ergebnisse sind zunächst in Tabelle 1 (oberer Teil) unten aufgeführt. Ein früher Abbruch verbessert weiterhin die Testgenauigkeit und verringert den Trainingsverlust, was darauf hindeutet, dass ein Abbruch im frühen Stadium dazu beiträgt, dass das Modell besser an die Daten angepasst wird. Die Forscher zeigen auch Vergleichsergebnisse mit einer Drop-Rate von 0,1 im Vergleich zum Standard-Dropout und der stochastischen Tiefe (s.d.), die sich beide negativ auf das Modell auswirken.
Darüber hinaus verbesserten die Forscher die Methode für diese kleinen Modelle, indem sie die Trainingsepochen verdoppelten und die Mixup- und Cutmix-Intensität reduzierten. Die Ergebnisse in Tabelle 1 unten (unten) zeigen erhebliche Verbesserungen der Basisgenauigkeit, die teilweise die Ergebnisse früherer Arbeiten deutlich übertreffen.
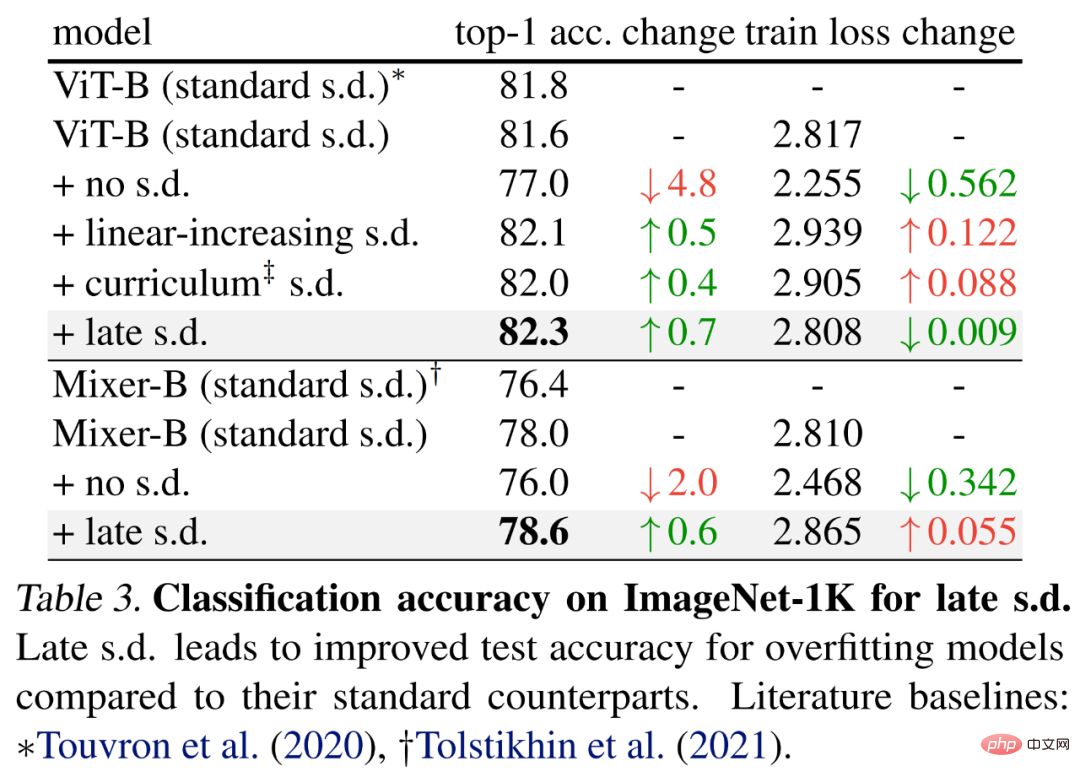
Um den späten Schulabbrecher zu bewerten, wählten die Forscher größere Modelle, nämlich ViT-B und Mixer-B mit 59M bzw. 86M Parametern, unter Verwendung der Basistrainingsmethode.
Die Ergebnisse sind in Tabelle 3 unten aufgeführt. Im Vergleich zum Standard-SD verbessert sich die Testgenauigkeit. Diese Verbesserung wird erreicht, während ViT-B aufrechterhalten oder der Mixer-B-Trainingsverlust erhöht wird, was darauf hindeutet, dass eine späte S.D. die Überanpassung effektiv reduziert.
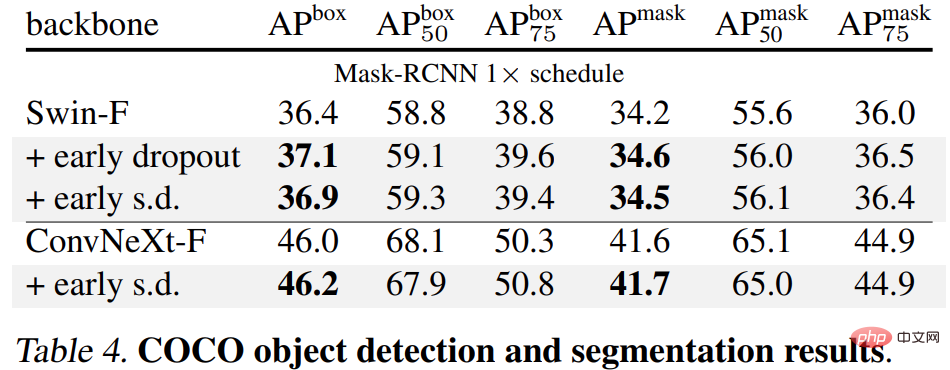
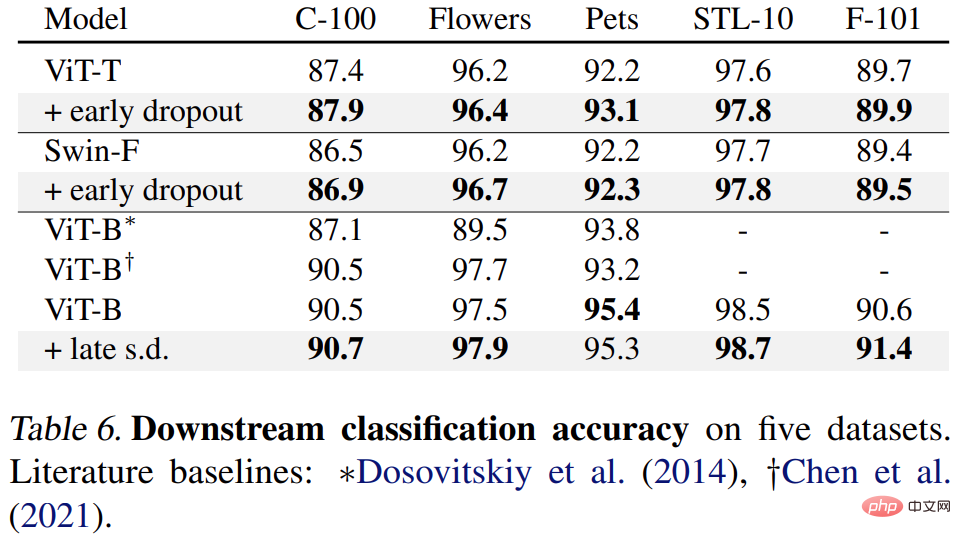
Abschließend haben die Forscher die vorab trainierten ImageNet-1K-Modelle auf nachgelagerte Aufgaben verfeinert und ausgewertet. Zu den nachgelagerten Aufgaben gehören die COCO-Objekterkennung und -Segmentierung, die semantische ADE20K-Segmentierung und die nachgelagerte Klassifizierung von fünf Datensätzen, einschließlich C-100. Ziel ist es, die erlernte Darstellung während der Feinabstimmungsphase zu bewerten, ohne Early Dropout oder Late Dropout zu verwenden.
Die Ergebnisse sind in den Tabellen 4, 5 und 6 unten aufgeführt. Erstens behält das mit Early Dropout oder S.D. vorab trainierte Modell immer einen Vorteil.
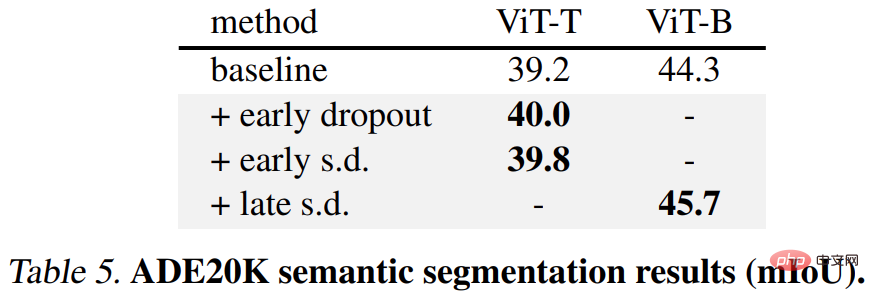
Zweitens ist für die semantische Segmentierungsaufgabe ADE20K das mit dieser Methode vorab trainierte Modell besser als das Basismodell.
Schließlich gibt es nachgelagerte Klassifizierungsaufgaben, die die Generalisierungsleistung bei den meisten Klassifizierungsaufgaben verbessern.
Weitere technische Details und experimentelle Ergebnisse finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonVerbesserter Dropout kann verwendet werden, um Unteranpassungsprobleme zu lindern.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



