
 Backend-Entwicklung
Python-Tutorial
Welche Schritte und Methoden gibt es zum Zeichnen von Diagrammen mit der Python-Matplotlib-Bibliothek?
Backend-Entwicklung
Python-Tutorial
Welche Schritte und Methoden gibt es zum Zeichnen von Diagrammen mit der Python-Matplotlib-Bibliothek?
Welche Schritte und Methoden gibt es zum Zeichnen von Diagrammen mit der Python-Matplotlib-Bibliothek?

Chinesische Schriftarteneinstellung:
# 字体设置 plt.rcParams['font.sans-serif'] = ["SimHei"] plt.rcParams["axes.unicode_minus"] = False
1. Grundlegende Verwendung
Matplotlib: Mit Matplotlib können Entwickler Liniendiagramme und Histogramme mit nur wenigen Codezeilen erstellen Diagramm, Kreisdiagramm, Streudiagramm usw. plot是一个画图的函数,他的参数:plot([x],y,[fmt],data=None,**kwargs)
1.1, Linienstil und -farbe
(1) Gepunktete Linienform
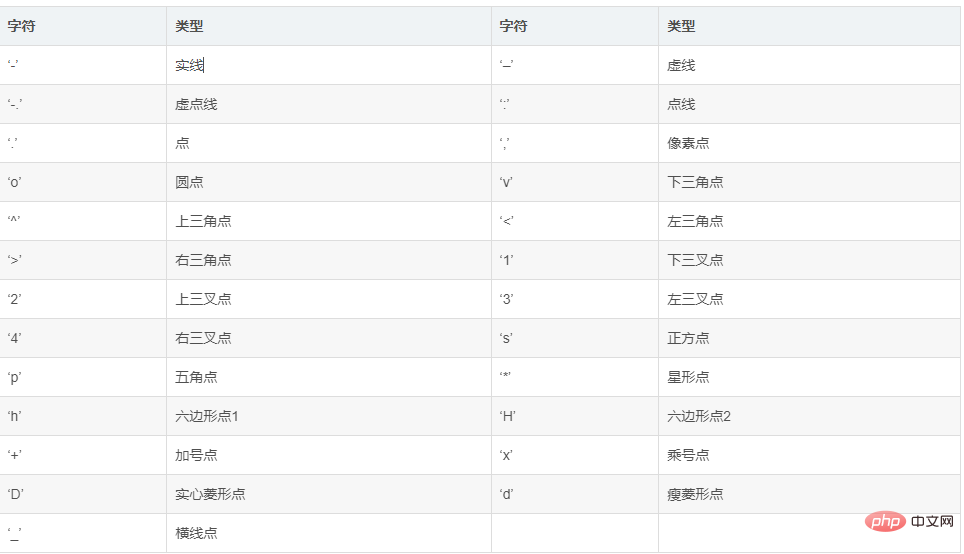
(2) Linienfarbe
import matplotlib.pyplot as plt import numpy as np # 原始线图 plt.plot(range(10),[np.random.randint(0,10) for x in range(10)]) # 点线图 plt.plot(range(10),[np.random.randint(0,10) for x in range(10)],"*") # 线条颜色 plt.plot([1,2,3,4,5],[1,2,3,4,5],'r') #将颜色线条设置成红色
Laufendes Ergebnis:
1.2 Achsen und Titel
1. Stellen Sie den Achsentitel ein: plt.xlabel & plt.ylabel - Titelname
3. Stellen Sie den Achsenmaßstab ein: plt.xticks & plt. yticks - Skalenlänge, Skalentitel
- Beispiel:
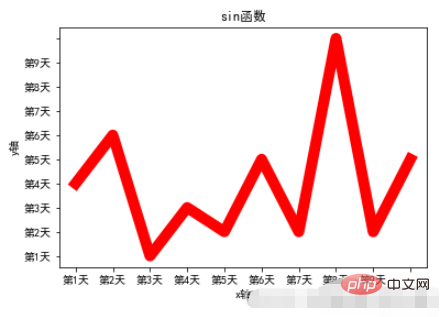
x = range(10)
y = [np.random.randint(0,10) for x in range(10)]
plt.plot(x,y,linewidth=10,color='red')
# 设置图标题
plt.title("sin函数")
# 设置轴标题
plt.xlabel("x轴")
plt.ylabel("y轴")
# 设置轴刻度
plt.xticks(range(10),["第%d天"%x for x in range(1,10)])
plt.yticks(range(10),["第%d天"%x for x in range(1,10)])
# 加载字体
plt.rcParams['font.sans-serif'] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = FalseLaufergebnis:
1.3, Markierung. Einstellungen
marker:关键点重点标记
 Beispiel:
Beispiel:x = range(10) y = [np.random.randint(0,10) for x in range(10)] plt.plot(x,y,linewidth=10,color='red') # 重点标记 plt.plot(x,y,marker="o",markerfacecolor='k',markersize=10)
Laufergebnis:
1.4. Kommentartext
annotate:注释文本
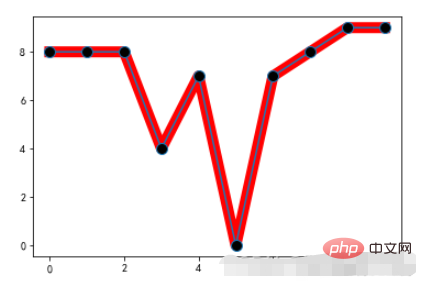 Beispiel:
Beispiel: x = range(10)
y = [np.random.randint(0,10) for x in range(10)]
plt.plot(x,y,linewidth=10,color='red')
# 重点标记
plt.plot(x,y,marker="o",markerfacecolor='k',markersize=10)
# 注释文本设置
plt.annotate('local max', xy=(5, 5), xytext=(10,15),
arrowprops=dict(facecolor='black',shrink=0.05),
)Laufendes Ergebnis:
1.5. Grafikstil festlegen
plt.figure:调整图片的大小和像素 `num`:图的编号, `figsize`:单位是英寸, `dpi`:每英寸的像素点, `facecolor`:图片背景颜色, `edgecolor`:边框颜色, `frameon`:是否绘制画板。
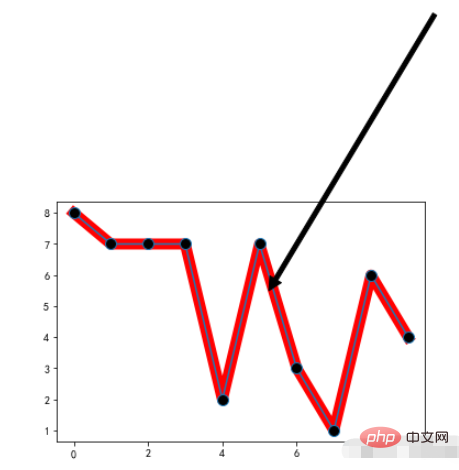 Beispiel:
Beispiel: x = range(10) y = [np.random.randint(0,10) for x in range(10)] # 设置图形样式 plt.figure(figsize=(20,10),dpi=80) plt.plot(x,y,linewidth=10,color='red')
Laufergebnis:
2, Balkendiagramm
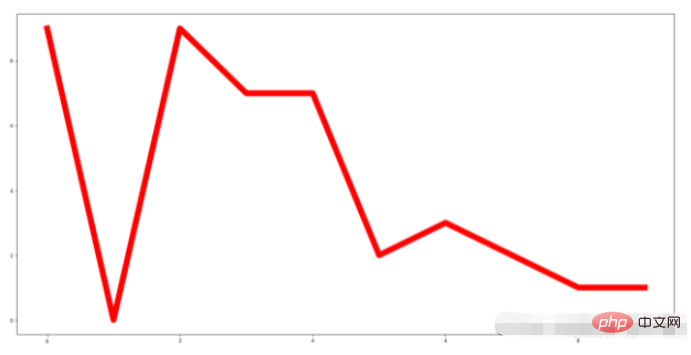
1.
2. Häufigkeitsstatistik.
- Zugehörige Parameter:
barh: Balkendiagramm
1. „x“: ein Array oder eine Liste, die den Koordinatenpunkt der x-Achse des zu zeichnenden Balkendiagramms darstellt.
2. „Höhe“: ein Array oder eine Liste, die den Koordinatenpunkt der y-Achse des zu zeichnenden Balkendiagramms darstellt.
3. „Breite“: Die Breite jedes Balkendiagramms, der Standardwert ist 0,8 Breite.
4. „unten“: Die Grundlinie der „y“-Achse, der Standardwert ist 0, d „center“ ist 0. Die angegebene „x“-Koordinate wird in der Mitte ausgerichtet und „edge“ wird an der Kante ausgerichtet. Ob sie rechts oder links liegt, hängt vom positiven oder negativen Wert von „width“ ab.
6. „Farbe“: Die Farbe des Balkendiagramms. 2.1. Beispiel für ein horizontales Balkendiagramm
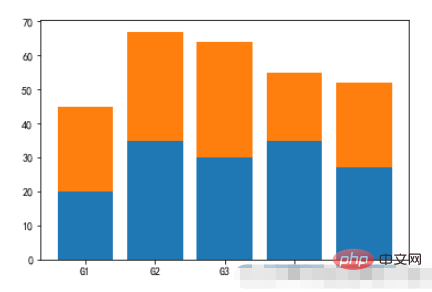
2.3, Stapelbalken-Formdiagramm
- Beispiel:
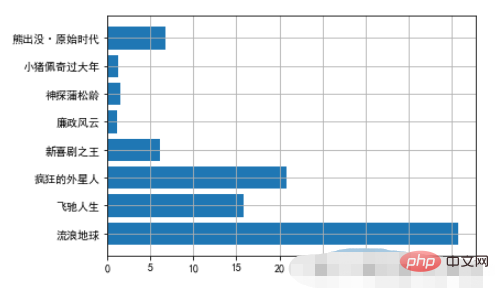
movies = { "流浪地球":40.78, "飞驰人生":15.77, "疯狂的外星人":20.83, "新喜剧之王":6.10, "廉政风云":1.10, "神探蒲松龄":1.49, "小猪佩奇过大年":1.22, "熊出没·原始时代":6.71 } plt.barh(np.arange(len(movies)),list(movies.values())) plt.yticks(np.arange(len(movies)),list(movies.keys()),fontproperties=font) plt.grid()Nach dem Login kopieren
 3, Histogramm
3, Histogramm
1. x: Array oder Sequenz, die kann geloopt sein;
2. Bins: Zahl oder Sequenz (Array/Liste usw.); 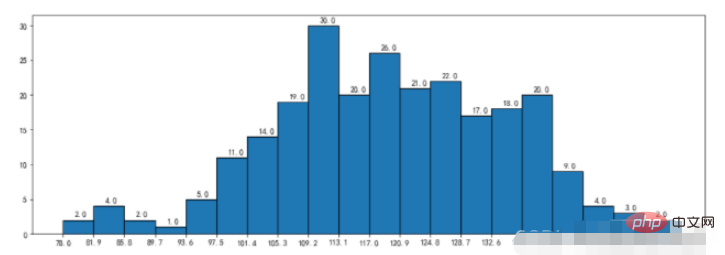
4. Der Standardwert ist „Falsch“, dann wird das Häufigkeitsverteilungshistogramm verwendet.
5 sind beide gleich „True“, dann wird der erste Parameter des Rückgabewerts weiter akkumuliert und ist schließlich gleich „1“.
- 1. Zeigen Sie die Verteilung der Datenanzahl in jeder Gruppe an.
- 2. Wird verwendet, um abnormale oder isolierte Daten zu beobachten.
- 3. Wenn die Anzahl der gezogenen Stichproben zu gering ist, treten große Fehler auf, die Glaubwürdigkeit ist gering und die statistische Signifikanz geht verloren. Daher sollte die Anzahl der Proben nicht weniger als 50 betragen.
- 3.1, Histogramm
- Beispiel:
- Laufergebnis:
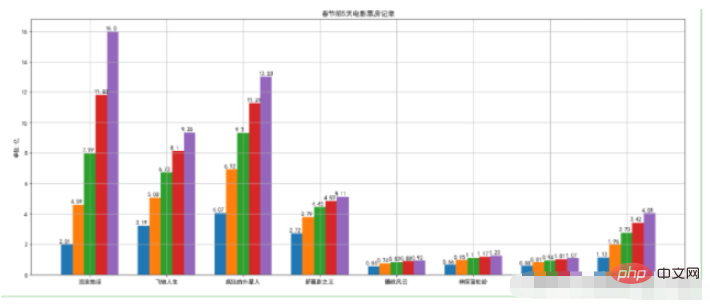
movies = { "流浪地球":[2.01,4.59,7.99,11.83,16], "飞驰人生":[3.19,5.08,6.73,8.10,9.35], "疯狂的外星人":[4.07,6.92,9.30,11.29,13.03], "新喜剧之王":[2.72,3.79,4.45,4.83,5.11], "廉政风云":[0.56,0.74,0.83,0.88,0.92], "神探蒲松龄":[0.66,0.95,1.10,1.17,1.23], "小猪佩奇过大年":[0.58,0.81,0.94,1.01,1.07], "熊出没·原始时代":[1.13,1.96,2.73,3.42,4.05] } plt.figure(figsize=(20,8)) width = 0.75 bin_width = width/5 movie_pd = pd.DataFrame(movies) ind = np.arange(0,len(movies)) # 第一种方案 for index in movie_pd.index: day_tickets = movie_pd.iloc[index] xs = ind-(bin_width*(2-index)) plt.bar(xs,day_tickets,width=bin_width,label="第%d天"%(index+1)) for ticket,x in zip(day_tickets,xs): plt.annotate(ticket,xy=(x,ticket),xytext=(x-0.1,ticket+0.1)) # 设置图例 plt.ylabel("单位:亿") plt.title("春节前5天电影票房记录") # 设置x轴的坐标 plt.xticks(ind,movie_pd.columns) plt.xlim plt.grid(True) plt.show()Nach dem Login kopieren
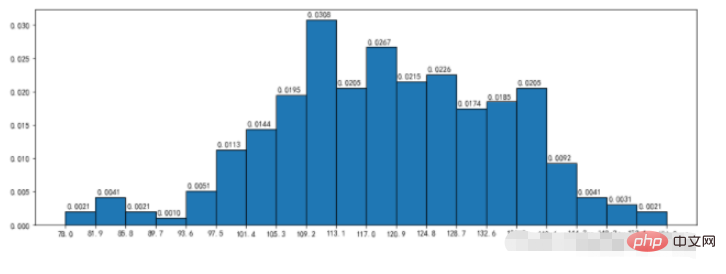
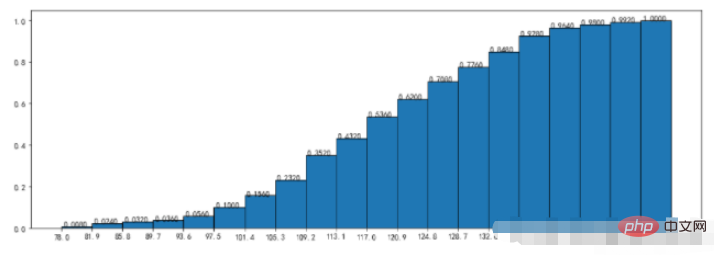
3.2、频率直方图
density:频率直方分布图
范例:
nums,bins,patches = plt.hist(durations,bins=20,edgecolor='k',density=True,cumulative=True)
plt.xticks(bins,bins)
for num,bin in zip(nums,bins):
plt.annotate("%.4f"%num,xy=(bin,num),xytext=(bin+0.2,num+0.0005))运行结果:
3.3、直方图
cumulative参数:nums的总和为1
范例:
plt.figure(figsize=(15,5))
nums,bins,patches = plt.hist(durations,bins=20,edgecolor='k',density=True,cumulative=True)
plt.xticks(bins,bins)
for num,bin in zip(nums,bins):
plt.annotate("%.4f"%num,xy=(bin,num),xytext=(bin+0.2,num+0.0005))运行结果:
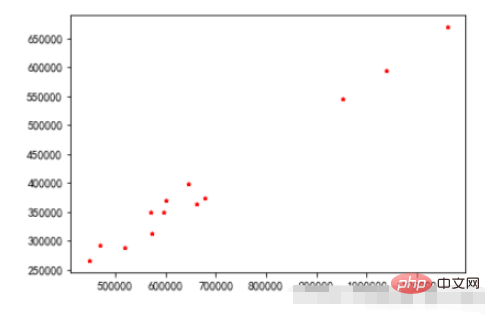
4、散点图
plt.scatter:散点图绘制:
1. x,y:分别是x轴和y轴的数据集。两者的数据长度必须一致。
2. s:点的尺寸。
3. c:点的颜色。
4. marker:标记点,默认是圆点,也可以换成其他的。
范例:
plt.scatter(x =data_month_sum["sumprice"] #传入X变量数据
,y=data_month_sum["Quantity"] #传入Y变量数据
,marker='*' #点的形状
,s=10 #点的大小
,c='r' #点的颜色
)
plt.show()运行结果:
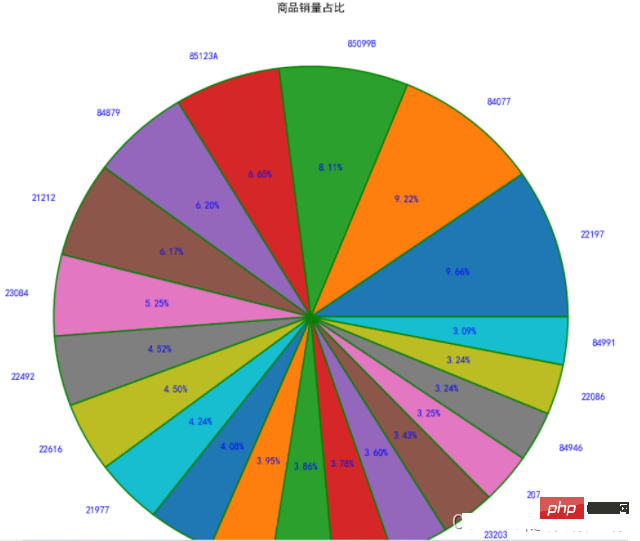
5、饼图
饼图:一个划分为几个扇形的圆形统计图表,用于描述量、频率或百分比之间的相对关系的。
在matplotlib中,可以通过plt.pie来实现,其中的参数如下:
x:饼图的比例序列。labels:饼图上每个分块的名称文字。explode:设置某几个分块是否要分离饼图。autopct:设置比例文字的展示方式。比如保留几个小数等。shadow:是否显示阴影。textprops:文本的属性(颜色,大小等)。 范例
plt.figure(figsize=(8,8),dpi=100,facecolor='white')
plt.pie(x = StockCode.values, #数据传入
radius=1.5, #半径
autopct='%.2f%%' #百分比显示
,pctdistance=0.6, #百分比距离圆心比例
labels=StockCode.index, #标签
labeldistance=1.1, #标签距离圆心比例
wedgeprops ={'linewidth':1.5,'edgecolor':'green'}, #边框的线宽和颜色
textprops={'fontsize':10,'color':'blue'}) #文本字体大小和颜色
plt.title('商品销量占比',pad=100) #设置标题及距离坐标轴的位置
plt.show()运行结果:
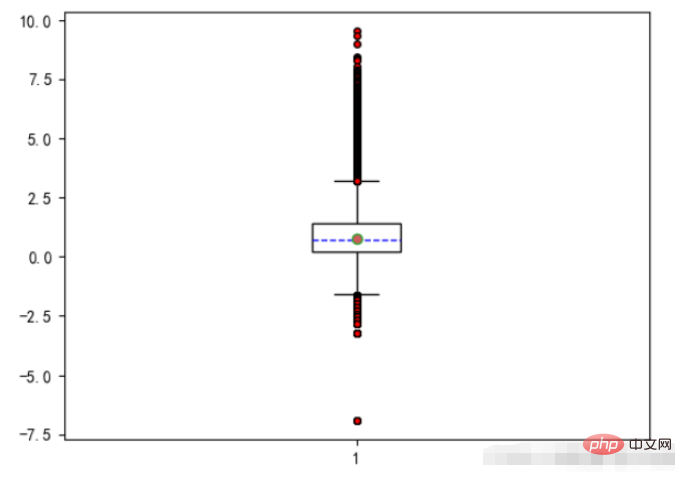
6、箱线图
箱图的绘制方法是:
:1、先找出一组数据的上限值、下限值、中位数(Q2)和下四分位数(Q1)以及上四分位数(Q3)
:2、然后连接两个四分位数画出箱子
:3、再将最大值和最小值与箱子相连接,中位数在箱子中间。
中位数:把数据按照从小到大的顺序排序,然后最中间的那个值为中位数,如果数据的个数为偶数,那么就是最中间的两个数的平均数为中位数。
上下四分位数:同样把数据排好序后,把数据等分为4份。出现在`25%`位置的叫做下四分位数,出现在`75%`位置上的数叫做上四分位数。但是四分位数位置的确定方法不是固定的,有几种算法,每种方法得到的结果会有一定差异,但差异不会很大。
上下限的计算规则是:
IQR=Q3-Q1
上限=Q3+1.5IQR
下限=Q1-1.5IQR
在matplotlib中有plt.boxplot来绘制箱线图,这个方法的相关参数如下:
x:需要绘制的箱线图的数据。notch:是否展示置信区间,默认是False。如果设置为True,那么就会在盒子上展示一个缺口。sym:代表异常点的符号表示,默认是小圆点。vert:是否是垂直的,默认是True,如果设置为False那么将水平方向展示。whis:上下限的系数,默认是1.5,也就是上限是Q3+1.5IQR,可以改成其他的。也可以为一个序列,如果是序列,那么序列中的两个值分别代表的就是下限和上限的值,而不是再需要通过IQR来计算。positions:设置每个盒子的位置。widths:设置每个盒子的宽度。labels:每个盒子的label。meanline和showmeans:如果这两个都为True,那么将会绘制平均值的的线条。
范例:
#箱线图 - 主要观察数据是否有异常(离群点)
#箱须-75%和25%的分位数+/-1.5倍分位差
plt.figure(figsize=(6.4,4.8),dpi=100)
#是否填充箱体颜色,是否展示均值,是否展示异常值,箱体设置,异常值设置,均值设置,中位数设置
plt.boxplot(x=UnitPrice #传入数据
,patch_artist=True #是否填充箱体颜色
,showmeans=True #是否展示均值
,showfliers=True #是否展示异常值
,boxprops={'color':'black','facecolor':'white'} #箱体设置
,flierprops={'marker':'o','markersize':4,'markerfacecolor':'red'} #异常值设置
,meanprops={'marker':'o','markersize':6,'markerfacecolor':'indianred'} #均值设置
,medianprops={'linestyle':'--','color':'blue'} #中位数设置
)
plt.show()运行结果:
7、雷达图
雷达图:又被叫做蜘蛛网图,适用于显示三个或更多的维度的变量的强弱情况
plt.polar来绘制雷达图,x轴的坐标点应该为弧度(2*PI=360°)
范例:
import numpy as np properties = ['输出','KDA','发育','团战','生存'] values = [40,91,44,90,95,40] theta = np.linspace(0,np.pi*2,6) plt.polar(theta,values) plt.xticks(theta,properties) plt.fill(theta,values)
运行结果:
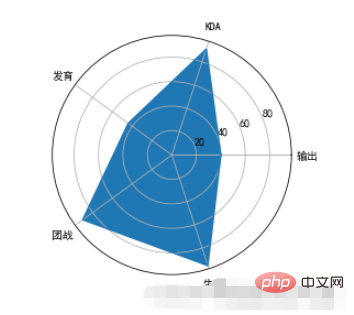
注意事项:
Da
polardas geschlossene Zeichnen der Linie nicht vervollständigt, müssen wir beim Zeichnen von Add am Endethetaundvalueseinfügen Der Wert der 0. Position wiederholt, und dann kann er beim Zeichnen mit dem ersten Punkt geschlossen werden.polar并不会完成线条的闭合绘制,所以我们在绘制的时候需要在theta中和values中在最后多重复添加第0个位置的值,然后在绘制的时候就可以和第1个点进行闭合了。polar只是绘制线条,所以如果想要把里面进行颜色填充,那么需要调用fill函数来实现。polar默认的圆圈的坐标是角度,如果我们想要改成文字显示,那么可以通过xticks
polar zeichnet nur Linien. Wenn Sie sie also mit Farbe füllen möchten, müssen Sie dazu die Funktion fill aufrufen. 🎜🎜🎜🎜polarDie Standardkreiskoordinaten sind Winkel. Wenn wir es auf Textanzeige ändern möchten, können wir es über xticks festlegen. 🎜🎜🎜Das obige ist der detaillierte Inhalt vonWelche Schritte und Methoden gibt es zum Zeichnen von Diagrammen mit der Python-Matplotlib-Bibliothek?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, hochrangige skalierbare Python-Datenbank Hadidb (HadIDB) ist eine leichte Datenbank in Python mit einem hohen Maß an Skalierbarkeit. Installieren Sie HadIDB mithilfe der PIP -Installation: PipinstallHadIDB -Benutzerverwaltung erstellen Benutzer: createUser (), um einen neuen Benutzer zu erstellen. Die Authentication () -Methode authentifiziert die Identität des Benutzers. fromHadidb.operationImportUseruser_obj = user ("admin", "admin") user_obj.
 Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
MySQL kann ohne Netzwerkverbindungen für die grundlegende Datenspeicherung und -verwaltung ausgeführt werden. Für die Interaktion mit anderen Systemen, Remotezugriff oder Verwendung erweiterte Funktionen wie Replikation und Clustering ist jedoch eine Netzwerkverbindung erforderlich. Darüber hinaus sind Sicherheitsmaßnahmen (wie Firewalls), Leistungsoptimierung (Wählen Sie die richtige Netzwerkverbindung) und die Datensicherung für die Verbindung zum Internet von entscheidender Bedeutung.
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Kann sich MySQL Workbench mit Mariadb verbinden?
Apr 08, 2025 pm 02:33 PM
Kann sich MySQL Workbench mit Mariadb verbinden?
Apr 08, 2025 pm 02:33 PM
MySQL Workbench kann eine Verbindung zu MariADB herstellen, vorausgesetzt, die Konfiguration ist korrekt. Wählen Sie zuerst "Mariadb" als Anschlusstyp. Stellen Sie in der Verbindungskonfiguration Host, Port, Benutzer, Kennwort und Datenbank korrekt ein. Überprüfen Sie beim Testen der Verbindung, ob der Mariadb -Dienst gestartet wird, ob der Benutzername und das Passwort korrekt sind, ob die Portnummer korrekt ist, ob die Firewall Verbindungen zulässt und ob die Datenbank vorhanden ist. Verwenden Sie in fortschrittlicher Verwendung die Verbindungspooling -Technologie, um die Leistung zu optimieren. Zu den häufigen Fehlern gehören unzureichende Berechtigungen, Probleme mit Netzwerkverbindung usw. Bei Debugging -Fehlern, sorgfältige Analyse von Fehlerinformationen und verwenden Sie Debugging -Tools. Optimierung der Netzwerkkonfiguration kann die Leistung verbessern
 Benötigt MySQL einen Server?
Apr 08, 2025 pm 02:12 PM
Benötigt MySQL einen Server?
Apr 08, 2025 pm 02:12 PM
Für Produktionsumgebungen ist in der Regel ein Server erforderlich, um MySQL auszuführen, aus Gründen, einschließlich Leistung, Zuverlässigkeit, Sicherheit und Skalierbarkeit. Server haben normalerweise leistungsstärkere Hardware, redundante Konfigurationen und strengere Sicherheitsmaßnahmen. Bei kleinen Anwendungen mit niedriger Last kann MySQL auf lokalen Maschinen ausgeführt werden, aber Ressourcenverbrauch, Sicherheitsrisiken und Wartungskosten müssen sorgfältig berücksichtigt werden. Für eine größere Zuverlässigkeit und Sicherheit sollte MySQL auf Cloud oder anderen Servern bereitgestellt werden. Die Auswahl der entsprechenden Serverkonfiguration erfordert eine Bewertung basierend auf Anwendungslast und Datenvolumen.
