

In dem Artikel, den ich vor dieser Ausgabe geschrieben habe, habe ich Ihnen einmal vorgestellt, dass der Java Stream-Pipeline-Stream eine Java-API ist, die zur Vereinfachung der Verarbeitung von Sammlungsklassenelementen verwendet wird. Der Nutzungsprozess gliedert sich in drei Phasen. Bevor ich mit diesem Artikel beginne, muss ich meiner Meinung nach noch einigen neuen Freunden diese drei Phasen vorstellen, wie im Bild gezeigt:
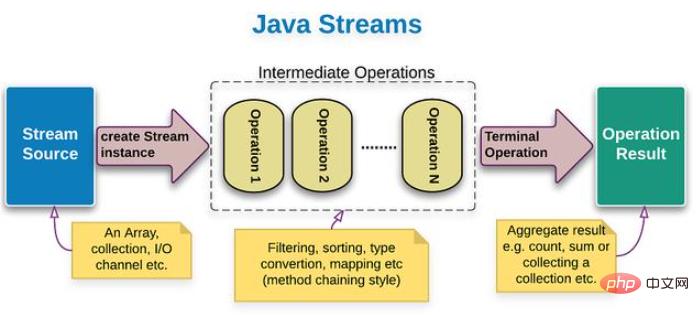
Die erste Phase (im Bild blau): Sammlung, Array oder Zeile konvertieren Textdateien Die zweite Stufe des Java-Stream-Pipeline-Flusses
(der gestrichelte Teil in der Abbildung): Pipeline-Streaming-Datenverarbeitungsvorgang, bei dem jedes Element in der Pipeline verarbeitet wird. Die Ausgabeelemente der vorherigen Pipe dienen als Eingabeelemente für die nächste Pipe.
Die dritte Stufe (grün im Bild): Verarbeitungsvorgang für Pipeline-Flussergebnisse, der den Kerninhalt dieses Artikels darstellt.
Bevor Sie mit dem Lernen beginnen, müssen Sie sich noch ein Beispiel ansehen, das wir Ihnen zuvor erklärt haben:
List<String> nameStrs = Arrays.asList("Monkey", "Lion", "Giraffe","Lemur");
List<String> list = nameStrs.stream()
.filter(s -> s.startsWith("L"))
.map(String::toUpperCase)
.sorted()
.collect(toList());
System.out.println(list);Verwenden Sie zuerst die Methode stream(), um die Zeichenfolge List in einen Pipeline-Stream-Stream umzuwandeln
Führen Sie dann Pipeline-Datenverarbeitungsvorgänge aus Verwenden Sie zunächst die Filterfunktion, um alle Zeichenfolgen zu filtern, die mit dem Großbuchstaben L beginnen, konvertieren Sie dann die Zeichenfolgen in der Pipeline in Großbuchstaben in Großbuchstaben und rufen Sie dann die sortierte Methode zum Sortieren auf. Die Verwendung dieser APIs wurde in früheren Artikeln dieses Artikels vorgestellt. Es werden auch Lambda-Ausdrücke und Funktionsreferenzen verwendet.
Verwenden Sie abschließend die Sammelfunktion für die Ergebnisverarbeitung, um den Java Stream-Pipeline-Stream in eine Liste umzuwandeln. Die endgültige Ausgabe der Liste lautet: [LEMUR, LION][LEMUR, LION]
如果你不使用java Stream管道流的话,想一想你需要多少行代码完成上面的功能呢?回到正题,这篇文章就是要给大家介绍第三阶段:对管道流处理结果都可以做哪些操作呢?下面开始吧!
如果我们只是希望将Stream管道流的处理结果打印出来,而不是进行类型转换,我们就可以使用forEach()方法或forEachOrdered()方法。
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEach(System.out::println);
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEachOrdered(System.out::println);parallel()函数表示对管道中的元素进行并行处理,而不是串行处理,这样处理速度更快。但是这样就有可能导致管道流中后面的元素先处理,前面的元素后处理,也就是元素的顺序无法保证
forEachOrdered从名字上看就可以理解,虽然在数据处理顺序上可能无法保障,但是forEachOrdered方法可以在元素输出的顺序上保证与元素进入管道流的顺序一致。也就是下面的样子(forEach方法则无法保证这个顺序):
Monkey
Lion
Giraffe
Lemur
Lion
java Stream 最常见的用法就是:一将集合类转换成管道流,二对管道流数据处理,三将管道流处理结果在转换成集合类。那么collect()方法就为我们提供了这样的功能:将管道流处理结果在转换成集合类。
通过Collectors.toSet()方法收集Stream的处理结果,将所有元素收集到Set集合中。
Set<String> collectToSet = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ) .collect(Collectors.toSet()); //最终collectToSet 中的元素是:[Monkey, Lion, Giraffe, Lemur],注意Set会去重。
同样,可以将元素收集到List使用toList()收集器中。
List<String> collectToList = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ).collect(Collectors.toList()); // 最终collectToList中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
上面为大家介绍的元素收集方式,都是专用的。比如使用Collectors.toSet()收集为Set类型集合;使用Collectors.toList()收集为List类型集合。那么,有没有一种比较通用的数据元素收集方式,将数据收集为任意的Collection接口子类型。 所以,这里就像大家介绍一种通用的元素收集方式,你可以将数据元素收集到任意的Collection类型:即向所需Collection类型提供构造函数的方式。
LinkedList<String> collectToCollection = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ).collect(Collectors.toCollection(LinkedList::new)); //最终collectToCollection中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
注意:代码中使用了LinkedList::new,实际是调用LinkedList的构造函数,将元素收集到Linked List。当然你还可以使用诸如LinkedHashSet::new和PriorityQueue::new将数据元素收集为其他的集合类型,这样就比较通用了。
通过toArray(String[]::new)方法收集Stream的处理结果,将所有元素收集到字符串数组中。
String[] toArray = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ) .toArray(String[]::new); //最终toArray字符串数组中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
使用Collectors.toMap()方法将数据元素收集到Map里面,但是出现一个问题:那就是管道中的元素是作为key,还是作为value。我们用到了一个Function.identity()方法,该方法很简单就是返回一个“ t -> t ”(输入就是输出的lambda表达式)。另外使用管道流处理函数distinct()
Map<String, Integer> toMap = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.distinct()
.collect(Collectors.toMap(
Function.identity(), //元素输入就是输出,作为key
s -> (int) s.chars().distinct().count()// 输入元素的不同的字母个数,作为value
));
// 最终toMap的结果是: {Monkey=6, Lion=4, Lemur=5, Giraffe=6}🎜Affe🎜Drei Elemente Die häufigste Verwendung von Collect🎜🎜Java Stream ist: Erstens die Sammlungsklasse in einen Pipeline-Stream konvertieren, zweitens die Pipeline-Stream-Daten verarbeiten und drittens das Ergebnis der Pipeline-Stream-Verarbeitung in eine Sammlungsklasse konvertieren. Dann stellt uns die Methode „collect()“ die Funktion zur Verfügung, die Verarbeitungsergebnisse des Pipeline-Streams in eine Sammlungsklasse umzuwandeln. 🎜🎜3.1. Als Set sammeln🎜🎜Sammeln Sie die Verarbeitungsergebnisse von Stream über die Methode Collectors.toSet() und sammeln Sie alle Elemente in der Set-Sammlung. 🎜
Löwe
Giraffe
Lemur
Löwe🎜
Map<Character, List<String>> groupingByList = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.collect(Collectors.groupingBy(
s -> s.charAt(0) , //根据元素首字母分组,相同的在一组
// counting() // 加上这一行代码可以实现分组统计
));
// 最终groupingByList内的元素: {G=[Giraffe], L=[Lion, Lemur, Lion], M=[Monkey]}
//如果加上counting() ,结果是: {G=1, L=3, M=1}toList() in List gesammelt werden. 🎜boolean containsTwo = IntStream.of(1, 2, 3).anyMatch(i -> i == 2);
// 判断管道中是否包含2,结果是: true
long nrOfAnimals = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur"
).count();
// 管道中元素数据总计结果nrOfAnimals: 4
int sum = IntStream.of(1, 2, 3).sum();
// 管道中元素数据累加结果sum: 6
OptionalDouble average = IntStream.of(1, 2, 3).average();
//管道中元素数据平均值average: OptionalDouble[2.0]
int max = IntStream.of(1, 2, 3).max().orElse(0);
//管道中元素数据最大值max: 3
IntSummaryStatistics statistics = IntStream.of(1, 2, 3).summaryStatistics();
// 全面的统计结果statistics: IntSummaryStatistics{count=3, sum=6, min=1, average=2.000000, max=3}LinkedHashSet::new und PriorityQueue::new verwenden, um Datenelemente in anderen Sammlungstypen zu sammeln, was vielseitiger ist. 🎜🎜3.4. In Array sammeln🎜🎜Sammeln Sie die Verarbeitungsergebnisse des Streams über die Methode toArray(String[]::new) und sammeln Sie alle Elemente in einem String-Array. 🎜rrreee🎜3.5. In der Karte gesammelt🎜🎜 Verwenden Sie die Methode Collectors.toMap(), um Datenelemente in der Karte zu sammeln, aber es gibt ein Problem: ob die Elemente in der Pipeline als Schlüssel oder als Werte verwendet werden. Wir haben eine Function.identity()-Methode verwendet, die einfach ein „t -> t“ zurückgibt (die Eingabe ist der Lambda-Ausdruck der Ausgabe). Verwenden Sie außerdem die Pipeline-Stream-Verarbeitungsfunktion distinct(), um die Eindeutigkeit des Map-Schlüsselwerts sicherzustellen. 3.6. GroupingBy 🎜Map<Character, List<String>> groupingByList = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.collect(Collectors.groupingBy(
s -> s.charAt(0) , //根据元素首字母分组,相同的在一组
// counting() // 加上这一行代码可以实现分组统计
));
// 最终groupingByList内的元素: {G=[Giraffe], L=[Lion, Lemur, Lion], M=[Monkey]}
//如果加上counting() ,结果是: {G=1, L=3, M=1}这是该过程的说明:groupingBy第一个参数作为分组条件,第二个参数是子收集器。
boolean containsTwo = IntStream.of(1, 2, 3).anyMatch(i -> i == 2);
// 判断管道中是否包含2,结果是: true
long nrOfAnimals = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur"
).count();
// 管道中元素数据总计结果nrOfAnimals: 4
int sum = IntStream.of(1, 2, 3).sum();
// 管道中元素数据累加结果sum: 6
OptionalDouble average = IntStream.of(1, 2, 3).average();
//管道中元素数据平均值average: OptionalDouble[2.0]
int max = IntStream.of(1, 2, 3).max().orElse(0);
//管道中元素数据最大值max: 3
IntSummaryStatistics statistics = IntStream.of(1, 2, 3).summaryStatistics();
// 全面的统计结果statistics: IntSummaryStatistics{count=3, sum=6, min=1, average=2.000000, max=3}Das obige ist der detaillierte Inhalt vonAnalysieren Sie Beispiele für Terminaloperationen in der Java Stream API. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



