
 Technologie-Peripheriegeräte
KI
ChatGPT: die Verschmelzung leistungsstarker Modelle, Aufmerksamkeitsmechanismen und verstärkendes Lernen
Technologie-Peripheriegeräte
KI
ChatGPT: die Verschmelzung leistungsstarker Modelle, Aufmerksamkeitsmechanismen und verstärkendes Lernen
ChatGPT: die Verschmelzung leistungsstarker Modelle, Aufmerksamkeitsmechanismen und verstärkendes Lernen

Dieser Artikel stellt hauptsächlich das maschinelle Lernmodell vor, das ChatGPT antreibt. Es beginnt mit der Einführung großer Sprachmodelle, befasst sich mit dem revolutionären Selbstaufmerksamkeitsmechanismus, der das Training von GPT-3 ermöglicht, und befasst sich dann mit dem verstärkenden Lernen aus menschlichem Feedback , was die herausragende neue Technologie von ChatGPT ermöglicht.
Großes Sprachmodell
ChatGPT ist eine Art maschinelles Lernmodell zur Verarbeitung natürlicher Sprache zur Inferenz, das als großes Sprachmodell (LLM) bezeichnet wird. LLM verarbeitet große Mengen an Textdaten und leitet daraus Beziehungen zwischen Wörtern im Text ab. In den letzten Jahren haben sich diese Modelle mit zunehmender Rechenleistung weiterentwickelt. Mit zunehmender Größe des Eingabedatensatzes und Parameterraums nehmen auch die Fähigkeiten von LLM zu.
Das grundlegendste Training eines Sprachmodells besteht darin, ein Wort in einer Wortfolge vorherzusagen. Am häufigsten wird dies bei Next-Token-Vorhersage- und Maskierungssprachmodellen beobachtet.
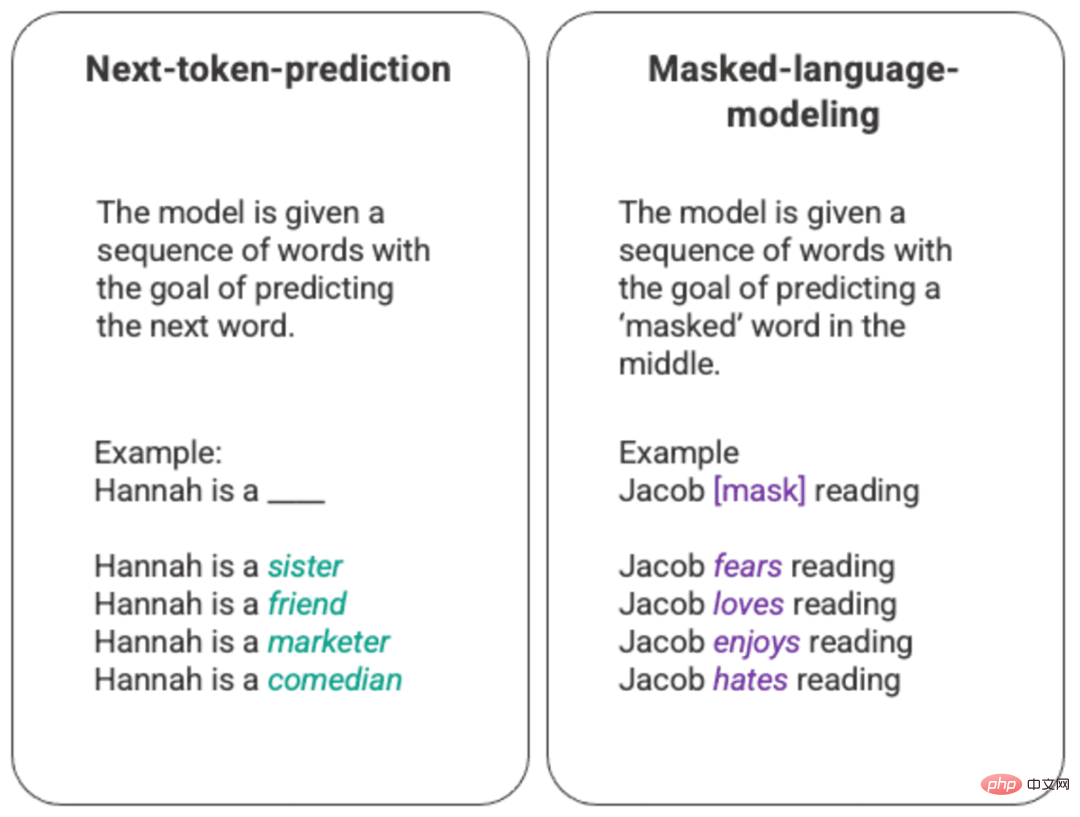
Beliebiges Beispiel für ein generiertes Next-Token-Vorhersage- und Maskierungssprachmodell
Bei dieser grundlegenden Ranking-Technik wird es normalerweise über ein Long-Short-Memory-Modell (LSTM) bereitgestellt, das auf die gegebene Umgebung und den jeweiligen Kontext trainiert wird Füllen Sie die Lücken mit dem statistisch wahrscheinlichsten Wort aus. Diese sequentielle Modellierungsstruktur weist zwei Hauptbeschränkungen auf.
- Das Modell kann einigen umgebenden Wörtern nicht mehr Gewicht verleihen als anderen. Während im obigen Beispiel „Lesen“ am häufigsten mit „Hass“ assoziiert wird, könnte „Jacob“ in der Datenbank ein begeisterter Leser sein und das Modell sollte „Jacob“ höher bewerten als „Jacob“. „Lesen“ und „Liebe“ wählen über „Hass“.
- Eingabedaten werden einzeln und nacheinander verarbeitet und nicht als gesamter Korpus. Dies bedeutet, dass beim Training eines LSTM das Kontextfenster festgelegt ist und sich nur für einige Schritte in der Sequenz über eine einzelne Eingabe hinaus erstreckt. Dies schränkt die Komplexität der Beziehungen zwischen Wörtern und der daraus erschließbaren Bedeutungen ein.
Um dieses Problem zu lösen, führte ein Team von Google Brain 2017 Konverter ein. Im Gegensatz zu LSTM kann der Transformator alle Eingabedaten gleichzeitig verarbeiten. Mithilfe eines Selbstaufmerksamkeitsmechanismus kann das Modell verschiedenen Teilen der Eingabedaten relativ zu jeder Position in der Sprachsequenz unterschiedliche Gewichte zuweisen. Diese Funktion ermöglicht weitreichende Verbesserungen bei der Bedeutungseinbringung in LLM und die Fähigkeit, größere Datensätze zu verarbeiten.
GPT und Selbstaufmerksamkeit
Das Generative Pretrained Transformer (GPT)-Modell wurde erstmals 2018 von OpenAI unter dem Namen GPT-1 eingeführt. Diese Modelle wurden 2019 in GPT-2, 2020 in GPT-3 und zuletzt 2022 in InstructGPT und ChatGPT weiterentwickelt. Vor der Einbeziehung menschlicher Rückmeldungen in das System wurden die größten Fortschritte in der GPT-Modellentwicklung durch Fortschritte bei der Recheneffizienz vorangetrieben, die es GPT-3 ermöglichten, auf deutlich mehr Daten als GPT-2 zu trainieren, was ihm eine vielfältigere Wissensbasis und Leistungsfähigkeit verlieh ein breiteres Aufgabenspektrum.

Vergleich von GPT-2 (links) und GPT-3 (rechts).
Alle GPT-Modelle nutzen eine Transformatorstruktur, das heißt, sie verfügen über einen Encoder zur Verarbeitung der Eingabesequenz und einen Decoder zur Erzeugung der Ausgabesequenz. Sowohl der Encoder als auch der Decoder verfügen über mehrköpfige Selbstaufmerksamkeitsmechanismen, die es dem Modell ermöglichen, verschiedene Teile der Sequenz unterschiedlich zu gewichten, um auf Bedeutung und Kontext zu schließen. Darüber hinaus nutzt der Encoder maskierte Sprachmodelle, um die Beziehungen zwischen Wörtern zu verstehen und verständlichere Antworten zu erzeugen.
Der Selbstaufmerksamkeitsmechanismus, der GPT antreibt, funktioniert durch die Umwandlung eines Tokens (ein Textfragment, das ein Wort, ein Satz oder eine andere Textgruppierung sein kann) in einen Vektor, der die Bedeutung des Tokens in der Eingabesequenz darstellt. Dazu dieses Modell:
- 1. Erstellen Sie ein
query,keyundvaluevector.query,key,和value向量。 - 2.通过取两个向量的点积,计算步骤1中的
query向量与其他每个标记的key向量之间的相似性。 - 3.通过将第2步的输出输入一个
softmax函数中来生成归一化的权重。 - 4.通过将步骤3中产生的权重与每个标记的
value向量相乘,产生一个最终向量,代表该序列中标记的重要性。
GPT使用的“multi-head”注意机制是自我注意的一种进化。该模型不是一次性执行第1-4步,而是并行地多次迭代这一机制,每次都会生成一个新的query,key,和value
query vector with KeyDie Ähnlichkeit zwischen Vektoren.  3. Durch Eingabe der Ausgabe von Schritt 2 in einen
3. Durch Eingabe der Ausgabe von Schritt 2 in einen softmax Funktion zum Generieren normalisierter Gewichte.
4. Durch Kombinieren der in Schritt 3 generierten Gewichtung mit dem value Vektoren werden multipliziert, um einen endgültigen Vektor zu erzeugen, der die Wichtigkeit des Tokens in der Sequenz darstellt.
multi-head" Der Aufmerksamkeitsmechanismus ist eine Weiterentwicklung der Selbstaufmerksamkeit. Anstatt die Schritte 1–4 auf einmal auszuführen, iteriert das Modell diesen Mechanismus mehrmals parallel und generiert jedes Mal einen neuen query, valueLineare Projektion von ein Vektor. Durch die Erweiterung der Selbstaufmerksamkeit auf diese Weise ist das Modell in der Lage, Teilbedeutungen und komplexere Beziehungen in den Eingabedaten zu erfassen. - Screenshot generiert von ChatGPT.
- Obwohl GPT-3 erhebliche Fortschritte in der Verarbeitung natürlicher Sprache mit sich bringt, ist es nur begrenzt in der Lage, sich an die Benutzerabsichten anzupassen. GPT-3 könnte beispielsweise die folgende Ausgabe erzeugen:
Mangelnde Interpretierbarkeit macht es für Menschen schwierig zu verstehen, wie das Modell zu einer bestimmten Entscheidung oder Vorhersage gelangt ist. Enthält schädliche oder anstößige Inhalte sowie schädliche oder voreingenommene Inhalte, die Fehlinformationen verbreiten.
In ChatGPT werden innovative Trainingsmethoden eingeführt, um einige der inhärenten Probleme des Standard-LLM auszugleichen.
ChatGPT
ChatGPT ist eine Ableitung von InstructGPT, die eine neuartige Methode einführt, um menschliches Feedback in den Trainingsprozess einzubeziehen, sodass die Ausgabe des Modells besser mit der Absicht des Benutzers integriert wird. Reinforcement Learning from Human Feedback (RLHF) wird ausführlich im openAI-Papier „Training language models to follow Instructions with human feedback“ aus dem Jahr 2022 beschrieben und im Folgenden kurz erläutert.
🎜Schritt 1: Supervised Fine-Tuned (SFT)-Modell 🎜🎜🎜🎜Die erste Entwicklung umfasste die Feinabstimmung des GPT-3-Modells und die Einstellung von 40 Auftragnehmern, um einen überwachten Trainingsdatensatz mit einer bekannten Eingabe zu erstellen. Die Ausgabe wird verwendet Modelllernen. Eingaben oder Eingabeaufforderungen werden aus tatsächlichen Benutzereingaben in die offene API erfasst. Der Tagger schreibt dann entsprechende Antworten auf die Eingabeaufforderungen und erstellt so für jede Eingabe eine bekannte Ausgabe. Anschließend wird das GPT-3-Modell mithilfe dieses neuen, überwachten Datensatzes verfeinert, um GPT-3.5, auch bekannt als SFT-Modell, zu erstellen. 🎜🎜Um die Vielfalt des Tipps-Datensatzes zu maximieren, können nur 200 Tipps von einer bestimmten Benutzer-ID stammen und alle Tipps mit langen gemeinsamen Präfixen werden entfernt. Schließlich wurden alle Tipps entfernt, die personenbezogene Daten (PII) enthielten. 🎜Nach der Aggregation der Eingabeaufforderungsinformationen aus der OpenAI-API wurden die Etikettierer auch gebeten, Eingabeaufforderungsinformationsbeispiele zu erstellen, um diese Kategorien mit sehr wenigen echten Beispieldaten zu füllen. Zu den interessanten Kategorien gehören:
- Allgemeine Tipps: Alle zufälligen Anfragen.
- Ein paar Hinweise: Anweisungen, die mehrere Abfrage-/Antwortpaare enthalten.
- Benutzerbasierte Tipps: Entsprechen Sie dem spezifischen Anwendungsfall, der für die OpenAI-API angefordert wird.
Beim Generieren einer Antwort müssen Tagger ihr Bestes geben, um Rückschlüsse auf die Anweisungen des Benutzers zu ziehen. In diesem Dokument werden die drei Hauptmethoden beschrieben, mit denen Eingabeaufforderungen Informationen anfordern können.
- Direkt: „Erzähl mir von…“
- Wenige Worte: Nenne Beispiele für diese beiden Geschichten und schreibe eine weitere Geschichte zum gleichen Thema.
- Fortsetzung: Geben Sie einen Anfang einer Geschichte und beenden Sie sie.
Zusammenstellung von Eingabeaufforderungen der OpenAI-API und handschriftlichen Eingabeaufforderungen von Etikettierern, was zu 13.000 Eingabe-/Ausgabebeispielen zur Verwendung in überwachten Modellen führt.
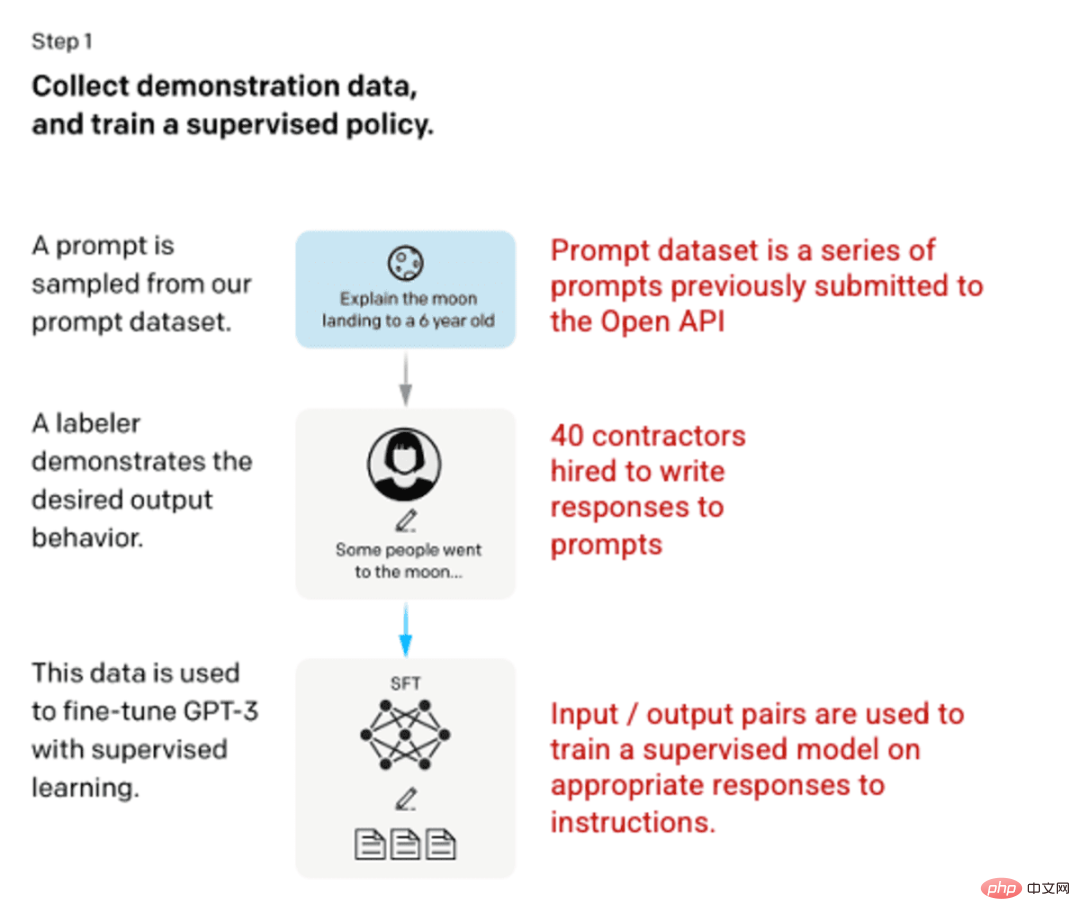
Bild (links) eingefügt aus „Sprachmodelle trainieren, um Anweisungen mit menschlichem Feedback zu befolgen“ OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. (Rechts) Zusätzlicher Kontext in Rot hinzugefügt.
Schritt 2: Belohnen Sie das Modell
Nach dem Training des SFT-Modells in Schritt 1 erzeugte das Modell bessere, konsistente Antworten auf Benutzeraufforderungen. Die nächste Verbesserung kam in Form von Trainingsbelohnungsmodellen, bei denen die Eingabe in das Modell eine Folge von Hinweisen und Reaktionen und die Ausgabe ein skalierter Wert ist, der als Belohnung bezeichnet wird. Um die Vorteile des Reinforcement Learning nutzen zu können, ist ein Belohnungsmodell erforderlich, bei dem das Modell lernt, Ergebnisse zu erzeugen, die seine Belohnung maximieren (siehe Schritt 3).
Um das Belohnungsmodell zu trainieren, stellen Etikettierer 4 bis 9 SFT-Modellausgaben für eine einzige Eingabeaufforderung bereit. Sie wurden gebeten, diese Ergebnisse vom besten zum schlechtesten zu ordnen und so ergebnisbewertete Kombinationen wie diese zu erstellen:

Beispiel für antwortbewertete Kombinationen.
Das Einbeziehen jeder Kombination in das Modell als separater Datenpunkt führt zu einer Überanpassung (der Unfähigkeit, über die gesehenen Daten hinaus zu extrapolieren). Um dieses Problem zu lösen, wird das Modell erstellt, indem jeder Satz von Rankings als separater Stapel von Datenpunkten verwendet wird.
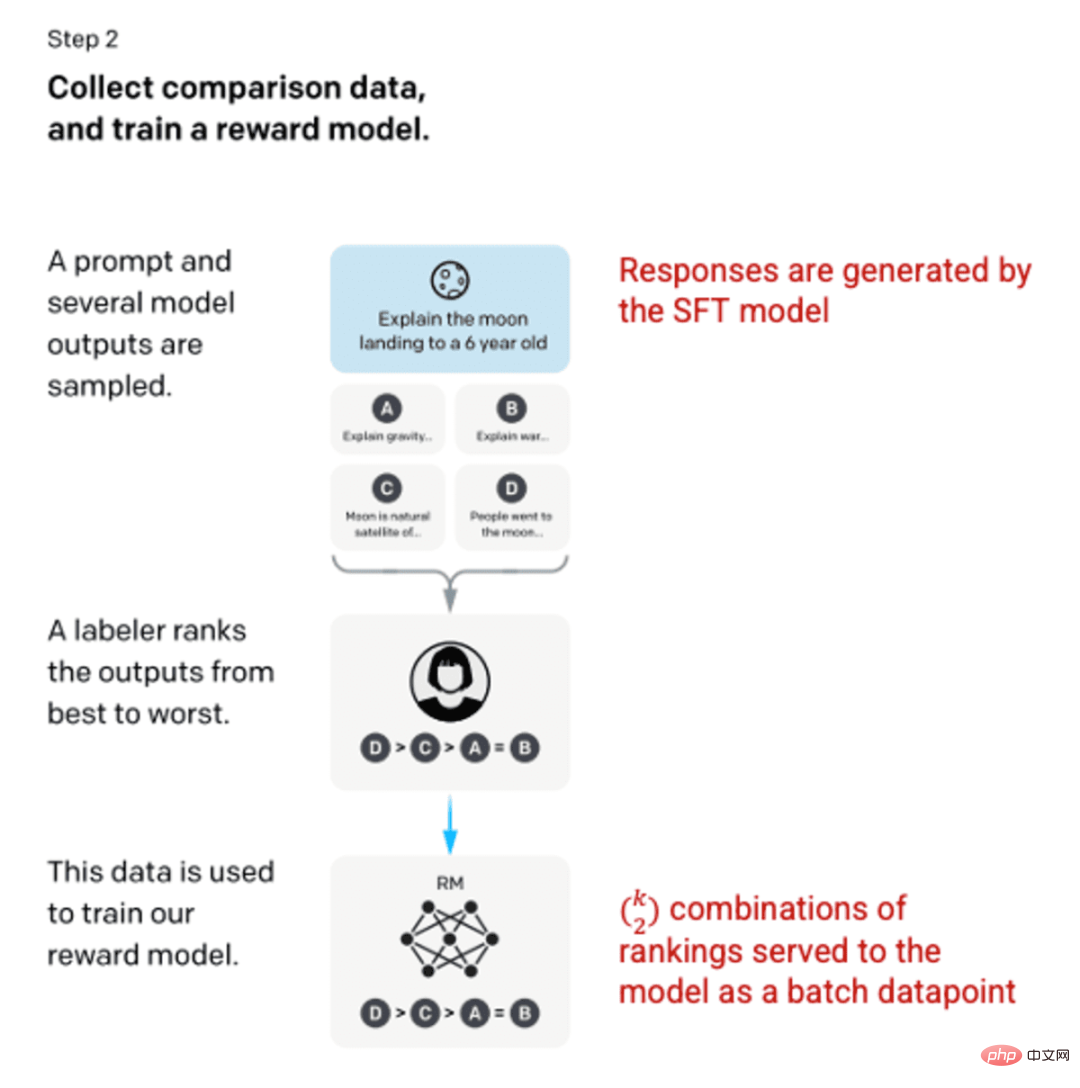
Bild (links) eingefügt aus „Sprachmodelle trainieren, um Anweisungen mit menschlichem Feedback zu befolgen“ OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. (Rechts) Zusätzlicher Kontext in Rot hinzugefügt.
Schritt 3: Reinforcement Learning Model
In der letzten Phase wird dem Modell eine zufällige Eingabeaufforderung präsentiert und eine Antwort zurückgegeben. Die Antwort wird anhand der „Richtlinie“ generiert, die das Modell in Schritt 2 gelernt hat. Die Richtlinie stellt die Strategie dar, die die Maschine verwendet hat, um in diesem Fall ihr Ziel zu erreichen und ihre Belohnung zu maximieren. Basierend auf dem in Schritt 2 entwickelten Belohnungsmodell wird dann ein skalierter Belohnungswert für die Cue- und Response-Paare ermittelt. Die Belohnungen werden dann wieder in das Modell eingespeist, um die Strategie zu entwickeln.
Im Jahr 2017 führten Schulman et al. die Proximal Policy Optimization (PPO) ein, eine Methode zur Aktualisierung der Modellrichtlinie, wenn jede Antwort generiert wird. PPO integriert die Kullback-Leibler (KL)-Strafe in das SFT-Modell. Die KL-Divergenz misst die Ähnlichkeit zweier Verteilungsfunktionen und bestraft extreme Abstände. In diesem Fall kann die Verwendung der KL-Strafe den Abstand der Antwort von der Ausgabe des in Schritt 1 trainierten SFT-Modells verringern, um eine Überoptimierung des Belohnungsmodells und eine zu starke Abweichung vom Datensatz der menschlichen Absicht zu vermeiden.
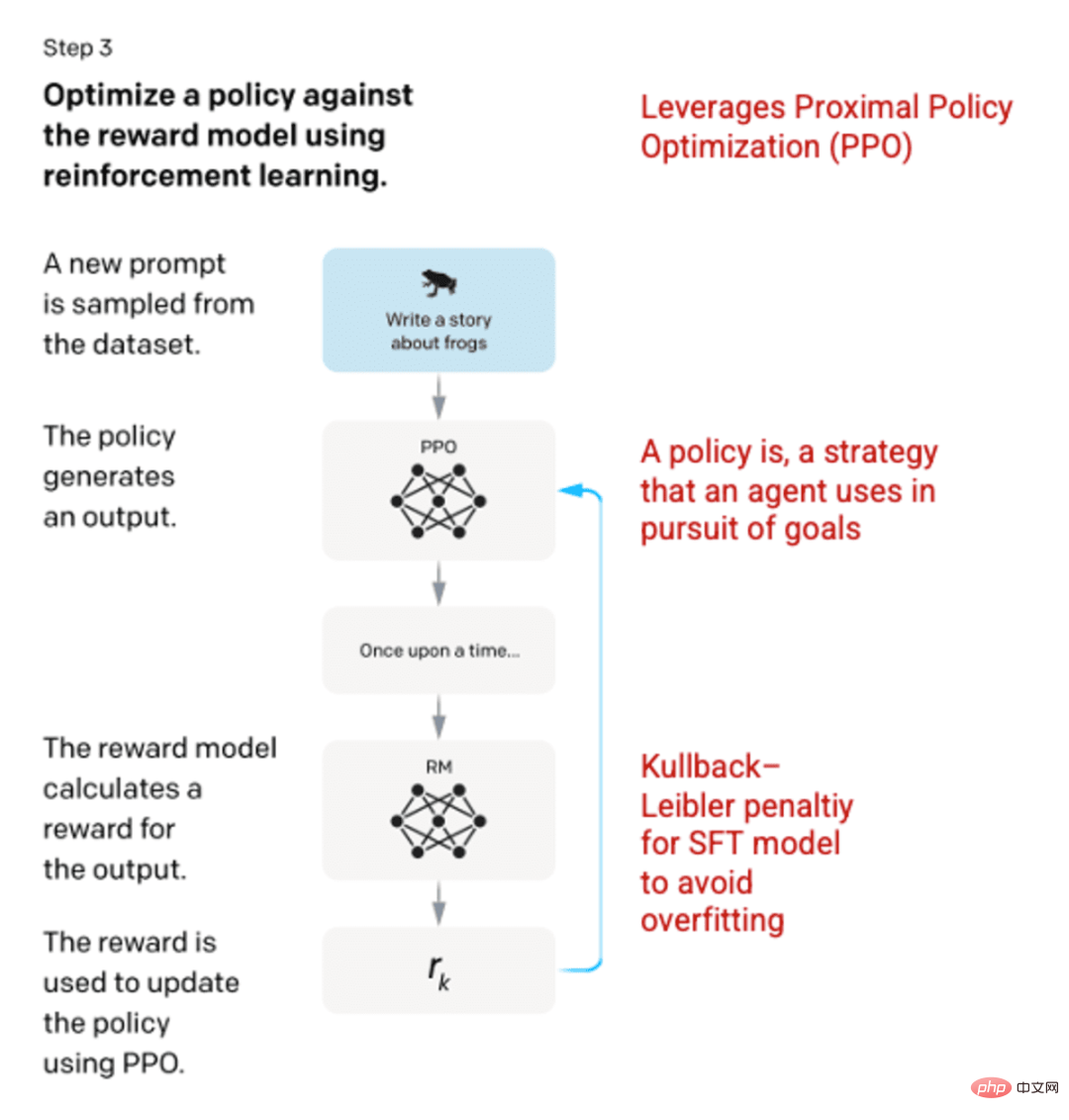
Bild (links) eingefügt aus „Sprachmodelle trainieren, um Anweisungen mit menschlichem Feedback zu befolgen“ OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. (Rechts) Zusätzlicher Kontext in Rot hinzugefügt.
Schritte 2 und 3 des Prozesses können immer wieder wiederholt werden, obwohl dies in der Praxis noch nicht weit verbreitet ist.

Screenshot generiert von ChatGPT.
Bewertung des Modells
Die Bewertung des Modells erfolgt durch Reservieren eines Testsatzes, der vom Modell während des Trainings nicht gesehen wurde. Am Testsatz wird eine Reihe von Bewertungen durchgeführt, um festzustellen, ob das Modell eine bessere Leistung als sein Vorgänger GPT-3 erbringt.
Nützlichkeit: Die Fähigkeit des Modells, Benutzeranweisungen abzuleiten und zu befolgen. Etikettierer bevorzugten die Ausgabe von InstructGPT in 85 ± 3 % der Fälle gegenüber GPT-3.
Authentizität: Die Neigung des Models zu Halluzinationen. Verwenden von TruthfulQA-Datensatzes zeigte die vom PPO-Modell erzeugte Ausgabe eine leichte Steigerung der Authentizität und Aussagekraft. TruthfulQA数据集进行评估时,PPO模型产生的输出在真实性和信息量方面都有小幅增加。
无害性:模型避免不适当的、贬低的和诋毁的内容的能力。无害性是使用RealToxicityPrompts
RealToxicityPromptszu testender Datensatz. Der Test wurde unter drei Bedingungen durchgeführt. - Anweisungen sorgen für eine respektvolle Reaktion: Dies führt zu einer deutlichen Reduzierung schädlicher Reaktionen.
- Anweisungen liefern Reaktionen ohne Einstellungen bezüglich des Respekts: keine spürbare Änderung der Schädlichkeit.
- Anleitung sorgt für schädliche Reaktionen: Die Reaktionen sind tatsächlich deutlich schädlicher als beim GPT-3-Modell.
Weitere Informationen zu den Methoden zur Erstellung von ChatGPT und InstructGPT finden Sie im Originalpapier „Trainieren von Sprachmodellen zum Befolgen von Anweisungen mit menschlichem Feedback“, veröffentlicht von OpenAI, 2022 https://arxiv.org/pdf/2203.02155. pdf
.
Das obige ist der detaillierte Inhalt vonChatGPT: die Verschmelzung leistungsstarker Modelle, Aufmerksamkeitsmechanismen und verstärkendes Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
DALL-E 3 wurde im September 2023 offiziell als deutlich verbessertes Modell gegenüber seinem Vorgänger eingeführt. Er gilt als einer der bisher besten KI-Bildgeneratoren und ist in der Lage, Bilder mit komplexen Details zu erstellen. Zum Start war es jedoch exklusiv
 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
MetaFAIR hat sich mit Harvard zusammengetan, um einen neuen Forschungsrahmen zur Optimierung der Datenverzerrung bereitzustellen, die bei der Durchführung groß angelegten maschinellen Lernens entsteht. Es ist bekannt, dass das Training großer Sprachmodelle oft Monate dauert und Hunderte oder sogar Tausende von GPUs verwendet. Am Beispiel des Modells LLaMA270B erfordert das Training insgesamt 1.720.320 GPU-Stunden. Das Training großer Modelle stellt aufgrund des Umfangs und der Komplexität dieser Arbeitsbelastungen einzigartige systemische Herausforderungen dar. In letzter Zeit haben viele Institutionen über Instabilität im Trainingsprozess beim Training generativer SOTA-KI-Modelle berichtet. Diese treten normalerweise in Form von Verlustspitzen auf. Beim PaLM-Modell von Google kam es beispielsweise während des Trainingsprozesses zu Instabilitäten. Numerische Voreingenommenheit ist die Hauptursache für diese Trainingsungenauigkeit.
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 ChatGPT ist jetzt mit der Veröffentlichung einer speziellen App für macOS verfügbar
Jun 27, 2024 am 10:05 AM
ChatGPT ist jetzt mit der Veröffentlichung einer speziellen App für macOS verfügbar
Jun 27, 2024 am 10:05 AM
Die ChatGPT-Mac-Anwendung von Open AI ist jetzt für alle verfügbar, während sie in den letzten Monaten nur denjenigen mit einem ChatGPT Plus-Abonnement vorbehalten war. Die App lässt sich wie jede andere native Mac-App installieren, sofern Sie über ein aktuelles Apple S verfügen
 Maschinelles Lernen in C++: Ein Leitfaden zur Implementierung gängiger Algorithmen für maschinelles Lernen in C++
Jun 03, 2024 pm 07:33 PM
Maschinelles Lernen in C++: Ein Leitfaden zur Implementierung gängiger Algorithmen für maschinelles Lernen in C++
Jun 03, 2024 pm 07:33 PM
In C++ umfasst die Implementierung von Algorithmen für maschinelles Lernen: Lineare Regression: Wird zur Vorhersage kontinuierlicher Variablen verwendet. Zu den Schritten gehören das Laden von Daten, das Berechnen von Gewichtungen und Verzerrungen, das Aktualisieren von Parametern und die Vorhersage. Logistische Regression: Wird zur Vorhersage diskreter Variablen verwendet. Der Prozess ähnelt der linearen Regression, verwendet jedoch die Sigmoidfunktion zur Vorhersage. Support Vector Machine: Ein leistungsstarker Klassifizierungs- und Regressionsalgorithmus, der die Berechnung von Support-Vektoren und die Vorhersage von Beschriftungen umfasst.
