
 Technologie-Peripheriegeräte
KI
Diese Abbildung veranschaulicht die Anwendung von Lerntechniken in einem Arzneimittelempfehlungssystem.
Technologie-Peripheriegeräte
KI
Diese Abbildung veranschaulicht die Anwendung von Lerntechniken in einem Arzneimittelempfehlungssystem.
Diese Abbildung veranschaulicht die Anwendung von Lerntechniken in einem Arzneimittelempfehlungssystem.


Einleitung: Der Titel dieser Freigabe ist die Anwendung der Lerntechnologie für die grafische Darstellung in Arzneimittelempfehlungssystemen.
Enthält hauptsächlich die folgenden vier Teile:
- Forschungshintergrund und Herausforderungen
- Diskriminierende Arzneimittelpaketempfehlung
- Empfohlenes Paket für generative Medizin
- 1. Zusammenfassung und Ausblick Die Arzneimittelempfehlung ist ein Teilproblem einer intelligenten medizinischen Versorgung. Beginnen wir mit dem allgemeinen Hintergrund einer intelligenten medizinischen Versorgung. Da die Bevölkerung wächst und die Bevölkerung altert, steigt die Nachfrage Die medizinischen Leistungen nehmen weiter zu. Zwei Datensätze in der Abbildung: Erstens beträgt die Zahl der Besuche in medizinischen Einrichtungen im ganzen Land 6,05 Milliarden, was einem Anstieg von 22,4 % gegenüber dem Vorjahr entspricht. Zweitens: Statistiken zum medizinischen und gesundheitlichen Zustand verschiedener Länder in The Lancet zeigen, dass nur 57,4 % der chinesischen Ärzte einen Bachelor-Abschluss oder höher haben, einschließlich Ärzten. Die Zahl der Ärzte pro 10.000 Menschen in 16 Kategorien von Gesundheitsberufen, darunter Krankenschwestern und kommunales Gesundheitspersonal, beträgt in China nur ein Drittel der Zahl in China Vereinigte Staaten. Die Zahl der diagnostizierten und behandelten Menschen in unserem Land steigt weiter, aber die medizinischen Ressourcen und medizinischen Standards sind im Vergleich zu entwickelten Ländern immer noch unzureichend. Darüber hinaus besteht das Problem der ungleichen Verteilung der medizinischen Ressourcen. Das medizinische Niveau primärer medizinischer Einrichtungen ist relativ begrenzt, während das Angebot an Spitzeneinrichtungen die Nachfrage übersteigt. Daher ist es eine wichtige Frage, die dringend gelöst werden muss, wie die Diagnose- und Behandlungserfahrung hochrangiger medizinischer Einrichtungen voll genutzt werden kann, um zur Verbesserung des medizinischen Niveaus primärer medizinischer Einrichtungen beizutragen.
Intelligente medizinische Versorgung, künstliche Intelligenz-Technologie hat den Morgenröte gebracht
- Mit der Beschleunigung der Digitalisierung medizinischer Einrichtungen in den letzten Jahren ist eine große Anzahl medizinischer Einrichtungen in meinem Land, insbesondere Spitzenreiter, entstanden Medizinische Einrichtungen auf hoher Ebene, wie z. B. tertiäre Krankenhäuser, haben sehr umfangreiche elektronische Krankenaktendaten gesammelt. Wenn Big-Data-Technologie der künstlichen Intelligenz genutzt werden kann, um diese Informationen vollständig auszuwerten und relevantes Wissen zu extrahieren, könnte uns das helfen, einige der Diagnose- und Behandlungsmethoden und Ideen von medizinischen Experten in diesen hochrangigen Institutionen zu verstehen und dann eine intelligente Nachverfolgung zu unterstützen Besuche, medizinische Bildanalyse, Nachsorge chronischer Krankheiten usw. Eine Reihe nachgelagerter intelligenter medizinischer Anwendungen ist von erheblicher Bedeutung. 2. Forschungsherausforderungen Einige KI-Technologien, wie beispielsweise die medizinische Bildanalyse, haben beeindruckende Ergebnisse erzielt, werden jedoch selten in Arzneimittelempfehlungssystemen eingesetzt. Der Grund dafür ist, dass sich Arzneimittelempfehlungssysteme stark von herkömmlichen Empfehlungssystemen unterscheiden und es auch viele technische Probleme gibt .
Paketempfehlungssystem
- Die erste Herausforderung besteht darin, dass das Anwendungsszenario traditioneller Empfehlungssysteme, die auf Methoden wie der kollaborativen Filterung basieren, hauptsächlich darin besteht, jeweils einem Benutzer einen Artikel zu empfehlen Die Eingabe ist die Darstellung eines einzelnen Elements und eines einzelnen Benutzers, und die Ausgabe ist eine Bewertung des Übereinstimmungsgrads zwischen den beiden. Bei der Arzneimittelempfehlung müssen Ärzte den Patienten jedoch häufig eine Gruppe von Arzneimitteln gleichzeitig verschreiben. Das Medikamentenempfehlungssystem ist eigentlich ein Paketempfehlungssystem, ein sogenanntes Paketempfehlungssystem, das einem Benutzer gleichzeitig eine Reihe von Medikamenten empfiehlt. Die erste große Herausforderung, vor der wir stehen, besteht darin, die Arzneimittelempfehlung mit dem Paketempfehlungssystem zu kombinieren.
Wechselwirkungen zwischen Medikamenten
Die zweite Herausforderung des Arzneimittelempfehlungssystems sind die vielfältigen Wechselwirkungen zwischen Arzneimitteln. Es gibt synergistische Effekte zwischen einigen Medikamenten, die die Wirkung des anderen verstärken, und es gibt Antagonismen zwischen einigen Medikamenten, die die Wirkung des anderen aufheben. Selbst die Kombination einiger Medikamente kann zu Toxizität oder anderen Nebenwirkungen führen. Der Patient auf dem Bild leidet an einer Nierenerkrankung. Der linke Teil zeigt die vom Arzt verschriebenen Medikamente. Einige der Medikamente haben synergistische Wirkungen und können die Wirksamkeit des Medikaments fördern. Der rechte Teil zeigt die statistisch analysierten symptomatischen Hochfrequenzmedikamente. Es ist ersichtlich, dass diese Medikamente aufgrund einiger antagonistischer Wirkungen möglicherweise nicht ausgewählt werden. Die folgenden Medikamente können für einige vorhandene Medikamente toxisch sein und werden daher von diesem Patienten nicht verwendet. Darüber hinaus werden Arzneimittelwechselwirkungen individualisiert. Wir haben in der Statistik festgestellt, dass eine Vielzahl von Medikamenten mit antagonistischer oder sogar toxischer Wirkung gleichzeitig eingesetzt werden. Laut Analyse verschreiben Ärzte tatsächlich Medikamente basierend auf dem Zustand des Patienten und unter Berücksichtigung der Wechselwirkungen. Beispielsweise können einige Patienten mit gesunden Nieren häufig ein gewisses Maß an Nephrotoxizität von Arzneimitteln tolerieren. Daher müssen wir eine personalisierte Modellierung und Analyse der Wechselwirkungen zwischen Arzneimitteln durchführen. Zum Beispiel können wir im Bild eine Medikamentenpackung basierend auf den darin enthaltenen Interaktionen in einen Graphen konstruieren und ihn über das vorhandene graphische neuronale Netzwerk modellieren. Basierend auf den oben genannten Ideen haben wir mithilfe der Graph-Deep-Learning-Technologie zwei Arbeiten zum Arzneimittelempfehlungssystem durchgeführt, die jeweils in WWW- und TOIS-Zeitschriften veröffentlicht wurden. Im Folgenden finden Sie eine detaillierte Einführung. ... In diesem Artikel wird die in Paketempfehlungssystemen weit verbreitete diskriminierende Modelldefinitionsmethode für die Modellierung verwendet und als Kerntechnologieteil auch die Technologie zum Lernen von Diagrammdarstellungen verwendet. 1. Datenbeschreibung
Arzneimitteldaten
Um die Wechselwirkungen zwischen Arzneimitteln zu untersuchen, haben wir einige Arzneimittelattribute und Interaktionsdaten aus zwei großen Online-Open-Source-Wissensdatenbanken zu Arzneimitteln, DrugBank und Pharmaceutical Network, gesammelt. Arzneimittelwechselwirkungen sind Beschreibungen in natürlicher Sprache, die auf einigen Vorlagen basieren. Wie im Bild oben gezeigt, geht es in der Beschreibungsspalte darum, wie ein bestimmtes Medikament den Stoffwechsel steigern oder schwächen kann usw. Das mittlere Wort ist die Vorlage, und die Vorder- und Rückseite sind die ausgefüllte Medikamentennamen. Solange die Modellklassifizierung klar ist, können daher alle Arzneimittelwechselwirkungen in der Datenbank markiert werden. Daher haben wir unter Anleitung von Fachärzten die Wechselwirkungen mit anderen Arzneimitteln in drei Kategorien eingeteilt: keine Wechselwirkungen, Synergien und Antagonismen, die Vorlage markiert und die Klassifizierung der Wechselwirkungen mit anderen Arzneimitteln erhalten. Für die Datenvorverarbeitung teilen wir die Daten der elektronischen Krankenakte in zwei Teile auf: die Basisinformationen des Patienten und die Laborinformationen, die wir in einem One-Hot-Vektor verarbeiten; Nachdem wir den Textteil der Zustandsbeschreibung erstellt haben, wandeln wir ihn durch Auffüllen und Abschneiden in Text mit fester Länge um. Für Arzneimittelinteraktionsdaten: Wir wandeln sie in eine Arzneimittelinteraktionsmatrix um. Gleichzeitig wird das Problem wie folgt definiert: Anhand einer Reihe von Patientenbeschreibungen und entsprechenden Ground-Truth-Arzneimittelpaketen trainieren wir eine personalisierte Bewertungsfunktion, die das gegebene Patienten- und Probenpaket eingeben und ausgeben kann eine entsprechende Abschlussbewertung. Dies ist eindeutig die Definition eines Diskriminanzmodells. Vorschulungsteil Wir erhalten die erste Darstellung von Patienten und Medikamenten basierend auf dem NCF-Framework. Im Teil zur Konstruktion von Arzneimittelverpackungen schlagen wir eine Methode vor, um eine Arzneimittelverpackung basierend auf der Art der Arzneimittelwechselwirkungsbeziehung in ein Arzneimitteldiagramm zu konstruieren. Der letzte Teil ist ein Empfehlungsrahmen für diagrammbasierte Arzneimittelpakete, in dem zwei verschiedene Varianten entwickelt werden sollen, um zu verstehen, wie die Interaktion zwischen Arzneimitteln aus zwei unterschiedlichen Perspektiven modelliert werden kann. Zunächst wird der Vortrainingsteil nach der traditionellen Eins-zu-Eins-Empfehlungsmethode durchgeführt. Bei einem gegebenen Fall sind die Medikamente, die der Arzt für den Patienten verwendet hat, positive Fälle, und die Medikamente, die nicht verwendet wurden, sind negative Fälle. Von BPRLoss vorab trainiert, erzielen gebrauchte Medikamente eine höhere Punktzahl als solche, die nicht konsumiert wurden. Der Teil vor dem Training dient hauptsächlich der Erfassung grundlegender Informationen zur Arzneimittelwirkung und bietet eine Grundlage für die spätere Erfassung komplexerer Wechselwirkungen. Für den One-Hot-Teil verwenden wir MLP zum Extrahieren von Features; für den Textteil verwenden wir LSTM zum Extrahieren von Textfeatures. Im Vergleich zur herkömmlichen Empfehlung besteht das Kernproblem der Arzneimittelempfehlung darin, die Wechselwirkungen zwischen Arzneimitteln zu berücksichtigen und eine Charakterisierung des Arzneimittelpakets zu erhalten. Auf dieser Grundlage schlägt dieser Artikel eine Methode zur Modellierung pharmazeutischer Verpackungen vor, die auf einem grafischen Modell basiert. Zuerst werden die gekennzeichneten Arzneimittelwechselwirkungsbeziehungen in eine Arzneimittelwechselwirkungsmatrix umgewandelt, in der unterschiedliche Werte unterschiedliche Interaktionstypen darstellen. Basierend auf diesem Moment kann dann jedes gegebene Medikamentenpaket in ein heterogenes Medikamentendiagramm umgewandelt werden. Die Knoten im Diagramm entsprechen den Medikamenten im Medikamentenpaket, und die Knotenattribute entsprechen den vorab trainierten Knoten vorherigen Schritt. Um übermäßige Berechnungen zu vermeiden, haben wir gleichzeitig das Medikamentendiagramm nicht in ein vollständiges Diagramm umgewandelt, das heißt, wir haben keine Kante zwischen zwei Medikamenten zugelassen, sondern diese selektiv beibehalten. Insbesondere haben wir nur diejenigen mit der Bezeichnung „Kanten“ beibehalten der durchlaufenen Arzneimittelpaare und der Kanten, deren Häufigkeit einen bestimmten Schwellenwert überschreitet. Um den Drug-Graph effektiv zu charakterisieren, schlagen wir zwei Möglichkeiten vor, die Kantenattribute auf dem Drug-Graph zu formalisieren. Die erste Form ist DPR-WG, die ein gewichtetes Diagramm zur Darstellung des Arzneimitteldiagramms verwendet. Zunächst werden die Kantenwerte basierend auf den markierten Arzneimittelwechselwirkungen initialisiert, wobei -1 Antagonismus angibt, +1 Synergie angibt und 0 angibt, dass keine Wechselwirkung vorliegt oder unbekannt ist. Der Maskenvektor wird dann verwendet, um personalisierte Aktualisierungen der Kantengewichte im Medikamentendiagramm durchzuführen. Dieser Maskenvektor spiegelt die Wechselwirkung verschiedener Medikamente und den Grad der personalisierten Wirkung auf einen einzelnen Patienten wider. Seine Berechnungsmethode besteht darin, eine nichtlineare Ebene plus eine Sigmoidfunktion zu verwenden, sodass der Wert jeder Dimension zwischen 0 und 1 liegt Dadurch wird die Funktion der Merkmalsauswahl erkannt und personalisierte Anpassungen an der Wechselwirkung von Arzneimitteln vorgenommen. Der Aktualisierungsprozess des Medikamentendiagramms besteht darin, zunächst einen Aktualisierungsfaktor in DPR-WG zu berechnen und dann den Aktualisierungsfaktor durch Multiplikation oder Addition des Gewichts der entsprechenden Kante zu aktualisieren. In nachfolgenden Experimenten wurde festgestellt, dass die Aktualisierungsmethode nur geringe Auswirkungen auf die Ergebnisse hatte. Im Prozess der Darstellung von Arzneimitteldiagrammen haben wir eine Methode zur Darstellung von Arzneimitteln basierend auf gewichteten Diagrammen entwickelt. Zusammenfassend haben wir zunächst einen Informationsaktualisierungsprozess für gewichtete Diagramme entworfen: Aggregation von Nachbarinformationen. Während des Aggregationsprozesses wird der Aggregationsgrad individuell basierend auf dem Gewicht der Kante angepasst. Anschließend haben wir einen Selbstaufmerksamkeitsmechanismus verwendet, um die Gewichte zwischen verschiedenen Knoten zu berechnen, und einen Aggregations-MLP verwendet, um das Diagramm zu aggregieren, um die endgültige Darstellung des gesamten Arzneimitteldiagramms zu erhalten. Anschließend werden die Patientendarstellung und die Arzneimittelbilddarstellung in die Bewertungsfunktion eingegeben und die Ausgabe kann zur Empfehlung abgerufen werden. Darüber hinaus verwendet dieser Artikel BPRLoss zum Trainieren des Modells und stellt eine negative Stichprobenmethode vor, die 1 positiven Stichprobe und 10 negativen Stichproben entspricht. Ähnlich können wir BPRLoss für das Training verwenden, aber der Unterschied besteht darin, dass wir zusätzlich eine Kreuzentropieverlustfunktion für die Kantenklassifizierung einführen, in der Hoffnung, dass der Kantenvektor die Kategorieinformationen von Arzneimittelwechselwirkungen enthalten kann. Da das initialisierte Zeichen in der vorherigen Variante diese Informationen natürlich behält, der Graph dieser Variante jedoch nicht, werden diese Informationen durch die Einführung einer Verlustfunktion ergänzt.
Aus den experimentellen Ergebnissen übertrafen unsere beiden Modelle andere Diskriminanzmodelle bei verschiedenen Bewertungsindikatoren. Gleichzeitig führten wir auch eine Fallanalyse durch: Mithilfe der t-SNE-Methode projizierten wir den zuvor erwähnten Maskenvektor auf einen zweidimensionalen Raum. Wie in der Abbildung gezeigt, neigen beispielsweise die Medikamente, die von schwangeren Frauen, Säuglingen und Leberpatienten verwendet werden, ganz offensichtlich dazu, sich zu Clustern zusammenzuschließen, was die Wirksamkeit unserer Methode beweist. Diese Arbeit behält die Kernidee des Graphendarstellungslernens im vorherigen Artikel bei, während die Problemdefinition und -definition vollständig geändert wird Modell Das generative Modell führt Sequenzgenerierungs- und Reinforcement-Learning-Technologie ein, was den Empfehlungseffekt erheblich verbessert. 1 🎜#Der Hauptunterschied zwischen dem diskriminativen Modell und dem generativen Modell besteht darin, dass das diskriminante Modell die Übereinstimmung zwischen einem bestimmten Patienten und einer bestimmten Medikamentenpackung bewertet, während das generative Modell Kandidatenmedikamente für die Patientenpackung generiert und wählen Sie die beste Medikamentenpackung aus. # 🎜🎜#Angesichts der Mängel des oben vorgeschlagenen Diskriminanzmodells haben wir einige heuristische Generierungsmethoden entwickelt: Durch das Hinzufügen und Löschen einiger Medikamente in den Medikamentenpackungen ähnlicher Patienten werden einige nie dagewesene historische Aufzeichnungen erstellt -gesehene Medikamentenpackungen für Modelle zur Auswahl. Experimentelle Ergebnisse belegen, dass diese einfache Methode sehr effektiv ist und eine Grundlage für nachfolgende Methoden bietet. #🎜 🎜# Als nächstes folgt der in TOIS veröffentlichte Artikel „Empfehlung für wechselwirkungsbewusste Arzneimittelpakete über Policy Gradient“. Das in diesem Artikel vorgeschlagene Modell heißt DPG und unterscheidet sich vom DPR im vorherigen Artikel. G ist hier Generation. Erstellen Sie zunächst die Methode des grafischen neuronalen Netzwerks zur Erfassung der Wechselwirkung zwischen Arzneimitteln. Der Unterschied ist Das Diskriminanzmodell Im Modell ist das Medikamentenpaket vorgegeben und kann leicht in ein Medikamentendiagramm umgewandelt werden. Im generativen Modell ist das Medikamentendiagramm jedoch nicht festgelegt. Aufgrund des Rechenaufwands können nicht alle Medikamentenpakete erstellt werden Grafiken. Dieser Artikel enthält alle Arzneimittel in einem Arzneimittelwechselwirkungsdiagramm und verwendet auch ein attributiertes Diagramm für die grafische Formatierung und die Kanteneinbettungsinformationen werden ebenfalls beibehalten, und schließlich wird ein GNN basierend auf diesem Arzneimittelinteraktionsdiagramm erstellt. Der Patientendarstellungsteil verwendet auch MLP und LSTM, um den Darstellungsvektor des Patienten zu extrahieren, und berechnet auch den Maskenvektor, der anschließend zur Erfassung des personalisierten Darstellungsvektors des Patienten verwendet wird . ? Diese Methode bringt aber auch zwei große Herausforderungen mit sich: Arzneimittelpaketgenerierung basierend auf maximaler Wahrscheinlichkeit
Erstens wird erläutert, wie die Wechselwirkung zwischen Arzneimitteln bei der Erstellung von Arzneimittelpaketen basierend auf maximaler Wahrscheinlichkeit berücksichtigt werden soll. Dieser Teil ist auch die Die Grundlage für den Reinforcement-Learning-Teil wird später verwendet. Methoden zur Sequenzgenerierung, die auf der Maximum-Likelihood-Methode basieren, sind im NLP-Bereich weit verbreitet. Während des Generierungsprozesses ist jedes generierte Medikament von anderen zuvor generierten Medikamenten abhängig. Zuletzt werden die Interaktionsvektoren aller Medikamente summiert und mithilfe von MLP zusammengeführt, um einen umfassenden Interaktionsvektor zu erhalten. Die anschließende Integration dieses Vektors in das klassische Sequenzmodell zur Generierung löst die erste Herausforderung.
Anders als bei der klassischen Sequenzgenerierung ist das Medikamentenpaket tatsächlich ein Satz und es sollten keine doppelten Medikamente vorhanden sein, sodass das Modell das bereits vorhandene Medikament nicht generieren kann generiert wurde, um sicherzustellen, dass das generierte Ergebnis eine Menge sein muss. Schließlich haben wir die MLE-Verlustfunktion basierend auf der maximalen Wahrscheinlichkeit verwendet, um das Modell zu trainieren. Arzneimittelpaketgenerierung basierend auf Verstärkungslernen Der größte Nachteil der oben genannten Methode basierend auf der maximalen Wahrscheinlichkeit besteht darin, dass die Arzneimittelpackung eine strenge Reihenfolge aufweist und einige Methoden die Reihenfolge der Arzneimittel manuell festlegen, z. B. Sortieren nach Häufigkeit, Sortieren nach Anfangsbuchstaben usw. Dadurch werden die Eigenschaften der Sammlung von Medikamentenpaketen zerstört und auch ein Teil der Leistung des Modells verloren. Daher schlagen wir ein Modell zur Generierung von Medikamentenpaketen vor, das auf verstärkendem Lernen basiert. Das Ziel des Modells beim verstärkenden Lernen besteht darin, die künstlich festgelegte Belohnungsfunktion zu maximieren. Nachdem das Modell ein vollständiges Medikamentenpaket generiert hat, kann die Angabe einer von der Reihenfolge unabhängigen Belohnungsverlustfunktion die Abhängigkeit des Modells von der Reihenfolge verringern. Dieser Artikel verwendet den F-Wert als Belohnung, eine reihenfolgeunabhängige Funktion und den Bewertungsindex, um den wir uns Sorgen machen. . Dieser Artikel verwendet den F-Wert als Bewertungsindex und verwendet eine Trainingsmethode, die auf dem Richtliniengradienten in der Trainingsmethode basiert, und wird hier nicht im Detail abgeleitet. Unter den auf Richtliniengradienten basierenden Trainingsmethoden ist sie eine der besten -bekannte Methoden sind Es verwendet eine Basislinie, um die Varianz von Gradientenschätzungen zu verringern und dadurch die Stabilität des Trainings zu erhöhen. Daher haben wir eine auf SCST basierende Trainingsmethode verwendet, nämlich die selbstkritische Sequenztrainingsmethode. Die Basislinie ergibt sich auch aus der Belohnung, die durch das vom Modell selbst generierte Arzneimittelpaket erzielt wird. Die Art und Weise, wie ich sie erzeuge, ist die normale Sequenzgenerierungsmethode der Greedy-Suche. Wir hoffen, dass die Belohnung des vom Modell basierend auf dem Policy-Gradienten abgetasteten Medikamentenpakets höher ist als das vom Modell generierte Medikamentenpaket traditionelle Greedy-Suche. Auf dieser Grundlage entwirft dieser Artikel eine Verlustfunktion für das verstärkende Lernen, wie in der Abbildung gezeigt. Der Ableitungsprozess wird hier nicht im Detail vorgestellt. #? 🎜# #🎜 🎜# Als nächstes folgen die experimentellen Ergebnisse des Modells.
Abschließend haben wir auch viele Fallanalysen durchgeführt und können sehen, dass schwangere Frauen und Babys offensichtlich persönliche Vorlieben haben. Gleichzeitig haben wir einige weitere häufige Krankheiten wie Magenerkrankungen, Herzerkrankungen usw. hinzugefügt. Die Maskenvektoren dieser Krankheiten sind sehr verstreut und bilden keine Cluster. Die Bedingungen von Patienten mit häufigen Krankheiten sind vielfältig und es gibt keine besonders individuellen Situationen. Im Gegensatz zu schwangeren Frauen und Säuglingen gibt es sehr offensichtliche Screenings für Medikamente. Beispielsweise müssen bestimmte pädiatrische Medikamente ausgewiesen werden, und einige Medikamente können nicht verwendet werden von schwangeren Frauen. Gleichzeitig haben wir den Interaktionsvektor des Medikaments projiziert. Wir können sehen, dass die Interaktion zwischen den beiden Medikamenten, Synergie und Antagonismus, zwei unterschiedliche Oppositionssituationen bildet, was darauf hinweist, dass das Modell zwei unterschiedliche Interaktionsbänder erfasst . Kommt mit verschiedenen Effekten. Zusammenfassend geht es in unserer Forschung hauptsächlich um interaktionsbewusste personalisierte Medikamentenpackungsempfehlungen, einschließlich diskriminierender Medikamentenpackungsempfehlungen und generativer Medikamentenpackungsempfehlungen. Den beiden ist gemeinsam, dass sie beide die Lerntechnologie zur grafischen Darstellung verwenden, um die Wechselwirkung zwischen Arzneimitteln zu modellieren, und beide Maskenvektoren verwenden, um den Zustand des Patienten und die personalisierte Wahrnehmung der Wechselwirkung zu berücksichtigen. Der größte Unterschied zwischen den beiden Arbeiten ist der Unterschied in der Problemdefinition. Was wir für das diskriminierende Modell wollen, ist für das generative Modell ein Generator Das generative Modell dient eigentlich der besseren Definition des Problems. 3. Die Technologie zum Lernen von Diagrammdarstellungen ist zu einer neuen Möglichkeit geworden . Mit der rasanten Entwicklung graphischer neuronaler Netze erkennen die Menschen, dass die graphische neuronale Netztechnologie den Kombinationseffekt zwischen Knoten und die Beziehung zwischen Knoten sehr effektiv modellieren kann. Dies inspiriert uns, dass die Technologie des Lernens der Graphendarstellung ein nützliches Werkzeug für den Aufbau von Medikamentenempfehlungssystemen werden kann. Ein scharfes Werkzeug.

Elektronische Falldaten
Stellen Sie zunächst die in der Arbeit verwendete Datenbeschreibung vor.
 Bei diesen elektronischen Krankenakten handelt es sich um heterogene Daten, einschließlich strukturierter Informationen wie Alter, Geschlecht, Labortests und unstrukturierter Textinformationen wie etwa einer Krankheitsbeschreibung.
Bei diesen elektronischen Krankenakten handelt es sich um heterogene Daten, einschließlich strukturierter Informationen wie Alter, Geschlecht, Labortests und unstrukturierter Textinformationen wie etwa einer Krankheitsbeschreibung.
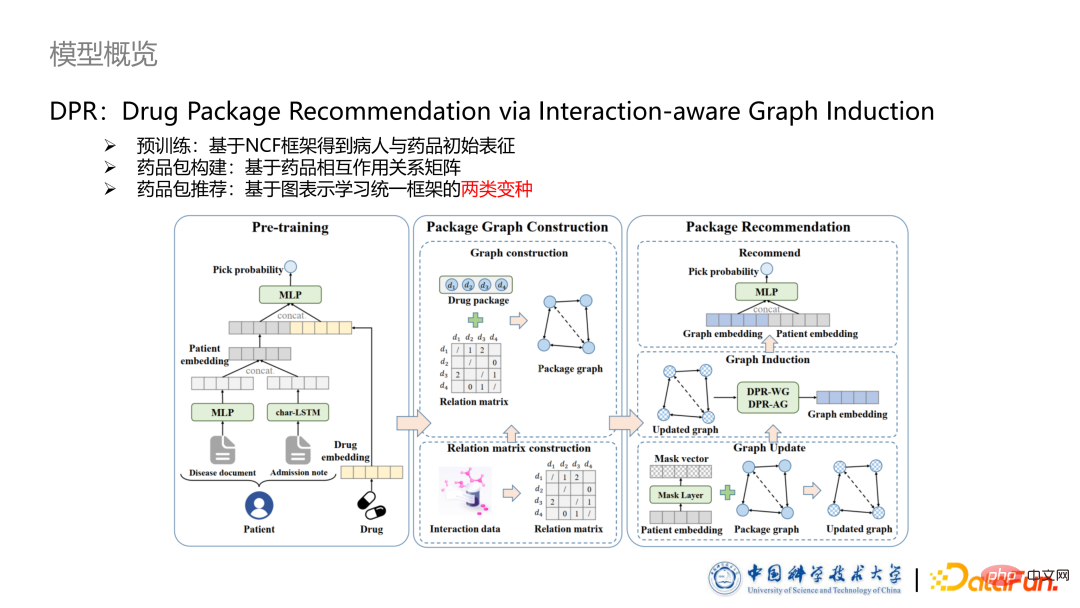 Der in diesem Artikel vorgeschlagene Papiertitel lautet DPR: Drug Package Recommendation via Interaction-aware Graph Induction. Das Modell besteht aus drei Teilen:
Der in diesem Artikel vorgeschlagene Papiertitel lautet DPR: Drug Package Recommendation via Interaction-aware Graph Induction. Das Modell besteht aus drei Teilen: 


 Die zweite Variante besteht darin, Attributgraphen zur Darstellung von Medikamentengraphen zu verwenden. Der erste Schritt besteht darin, den Kantenvektor zu initialisieren, indem die Knotenvektoren an beiden Enden der Kante über einen MLP zusammengeführt werden. Dann wird der Maskenvektor auch zum Aktualisieren des Kantenvektors verwendet. Zu diesem Zeitpunkt ist die Aktualisierungsmethode kein Aktualisierungsfaktor mehr, sondern wird Element für Element mit dem Kantenvektor des Arzneimittels multipliziert die aktualisierten Kantenattribute. Wir haben speziell ein GNN für Attributdiagramme entwickelt. Der Nachrichtenübermittlungsprozess berechnet zunächst die Nachricht basierend auf dem Kantenvektor und der Knoteneinbettung an beiden Enden zur Weitergabe und erhält die Diagrammeinbettung durch Selbstaufmerksamkeits- und Aggregationsmethoden.
Die zweite Variante besteht darin, Attributgraphen zur Darstellung von Medikamentengraphen zu verwenden. Der erste Schritt besteht darin, den Kantenvektor zu initialisieren, indem die Knotenvektoren an beiden Enden der Kante über einen MLP zusammengeführt werden. Dann wird der Maskenvektor auch zum Aktualisieren des Kantenvektors verwendet. Zu diesem Zeitpunkt ist die Aktualisierungsmethode kein Aktualisierungsfaktor mehr, sondern wird Element für Element mit dem Kantenvektor des Arzneimittels multipliziert die aktualisierten Kantenattribute. Wir haben speziell ein GNN für Attributdiagramme entwickelt. Der Nachrichtenübermittlungsprozess berechnet zunächst die Nachricht basierend auf dem Kantenvektor und der Knoteneinbettung an beiden Enden zur Weitergabe und erhält die Diagrammeinbettung durch Selbstaufmerksamkeits- und Aggregationsmethoden. 3. Empfohlenes generatives Medizinpaket Das Modell kann nur aus vorhandenen Medikamentenpaketen auswählen und hat nicht die Möglichkeit, neue Medikamentenpakete zu generieren, was Auswirkungen hat Als nächstes werden wir die Erweiterungsarbeit der im TOIS-Journal veröffentlichten vorherigen Arbeit vorstellen, mit dem Ziel, dass das Modell in der Lage ist, völlig neue Medikamentenpakete zu generieren, die auf neue Patienten zugeschnitten sind.
2. Heuristische Generierungsmethode

3. Modellübersicht

Dieses Modell besteht hauptsächlich aus drei Teilen, nämlich der Informationsverbreitung im Arzneimittelwechselwirkungsdiagramm, der Patientendarstellung und dem Modul zur Erstellung von Arzneimittelpaketen, dem größten Der Unterschied zu den oben genannten besteht im Modul zur Generierung von Medikamentenpaketen. #? 🎜 #

Nach mehreren Runden (normalerweise 2) der Nachrichtenübermittlung extrahieren wir den Knoten Embedding als zu verwendendes Medikament Embedding.

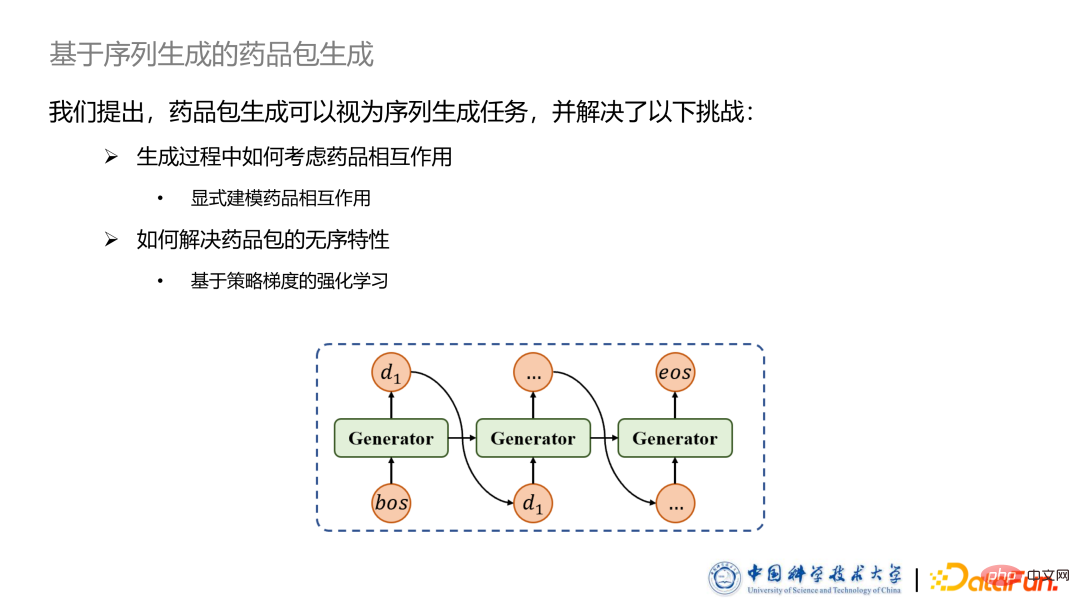 Die zweite Herausforderung besteht darin, dass das Beispielpaket eine Menge ist, die im Wesentlichen ungeordnet ist, aber Sequenzgenerierungsaufgaben zielen häufig auf geordnete Sequenzmethoden ab. Zu diesem Zweck haben wir eine auf Richtliniengradienten basierende Verstärkungslernmethode vorgeschlagen und eine auf SCST basierende Methode hinzugefügt, um die Wirkung und Stabilität dieses Algorithmus zu verbessern.
Die zweite Herausforderung besteht darin, dass das Beispielpaket eine Menge ist, die im Wesentlichen ungeordnet ist, aber Sequenzgenerierungsaufgaben zielen häufig auf geordnete Sequenzmethoden ab. Zu diesem Zweck haben wir eine auf Richtliniengradienten basierende Verstärkungslernmethode vorgeschlagen und eine auf SCST basierende Methode hinzugefügt, um die Wirkung und Stabilität dieses Algorithmus zu verbessern.  Gleichzeitig fügen wir den Maskenvektor und den Interaktionsvektor hinzu, um die entsprechenden Elemente zu multiplizieren und die personalisierten Informationen des Patienten einzuführen.
Gleichzeitig fügen wir den Maskenvektor und den Interaktionsvektor hinzu, um die entsprechenden Elemente zu multiplizieren und die personalisierten Informationen des Patienten einzuführen. 

 Experimentelle Ergebnisse
Experimentelle Ergebnisse
In der obigen Tabelle werden alle Medikamentenpakete mit Greedy Generated durchsucht. Erstens ist die Leistung von Methoden, die auf generativen Modellen basieren, im Allgemeinen besser als Methoden, die auf diskriminierenden Modellen basieren. Dieses Experiment beweist, dass generative Modelle eine bessere Wahl sind. Dieses Modell übertrifft alle anderen Basislinien im F-Wert. Darüber hinaus übertraf die Leistung des auf Verstärkungslernen basierenden Modells die Leistung des auf Maximalwahrscheinlichkeit basierenden Modells bei weitem, was die Wirksamkeit der Verstärkungslernmethode beweist. 
4. Zusammenfassung und Ausblick
Das obige ist der detaillierte Inhalt vonDiese Abbildung veranschaulicht die Anwendung von Lerntechniken in einem Arzneimittelempfehlungssystem.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
