

Dieser Artikel wird mit Genehmigung von AI New Media Qubit (öffentliche Konto-ID: QbitAI) nachgedruckt. Bitte wenden Sie sich für einen Nachdruck an die Quelle.
Google hat einen neuen „KI-Regisseur“ auf den Markt gebracht, der sogar den Protagonisten des Videos in einem Satz ändern kann.
Schau, ein kleiner Bär tanzt auf dem grünen Gras.

(Ein Bär tanzt und springt zu fröhlicher Musik und bewegt dabei seinen ganzen Körper)
Diese KI namensDreamix kann nicht nur Videos „magisch modifizieren“, sondern auch statische Bilder in Animationen umwandeln – Das geht auch in einem Satz Fertig .
Zeigen Sie dieser KI beispielsweise ein „Schildkrötenschwimmfoto“ und sagen Sie ihr: Eine Schildkröte wurde unter Wasser fotografiert und ein Hai näherte sich von hinten.(Unterwasseraufnahme einer Meeresschildkröte mit einem von hinten herannahenden Hai)


veränderlichen Videocharaktere betrifft, ist dies das ursprüngliche Feld:




statische Bildwechselanimation betrifft, ist das Originalbild ein nebliger Dschungel:




Einige Leute haben vielleicht das Gefühl, dass sie etwas mehr Zeit brauchen: Die Animation wurde gemacht, aber die Qualität auch viel geopfert worden.
Dann kannst du der KI auch noch ein paar Bilder zeigen.
Zeigen Sie der KI beispielsweise 7 Fotos von Spielzeug-Feuermeldern auf einmal:

Dann Lassen Sie dann ein Video basierend auf einem Satz generieren, und die Bildqualität wird viel klarer.

Wie dieser „KI-Direktor“ das macht, sagt Google, der Schlüssel liege im „alten Freund“ #🎜 🎜# Diffusionsmodell (Diffusionsmodell).
Das Diffusionsmodell ist auch der Kern des beliebten AIGC-MalwerkzeugsDALL·E 2.
Google-Forscher wiesen darauf hin, dass es tatsächlich schon früher eine ähnliche KI für „textgenerierte Videos“ gab, aber wenn das Videodiffusionsmodell nur auf das Eingabevideo abgestimmt wird, wird es dies einschränken Grad der Bewegungsänderungen. Was diese KI anders macht, ist: Das Team verwendete ein„Hybridziel“ , zusätzlich zur Feinabstimmung des ursprünglichen Ziels. und führt auch eine Feinabstimmung für ungeordnete Frame-Sets durch.
Sie nutzen einen speziellen Aufmerksamkeitsmechanismus beim Deep Learning: Maskierte zeitliche Aufmerksamkeit, der dem Modell hilft, sich auf bestimmte Teile der Eingabeinformationen zu konzentrieren und andere irrelevante Teile zu ignorieren. – Dies verbessert die Fähigkeit des Modells, Sequenzdaten zu verarbeiten, erzeugt eine vielfältigere Dynamik im Video und der Effekt ist natürlicher.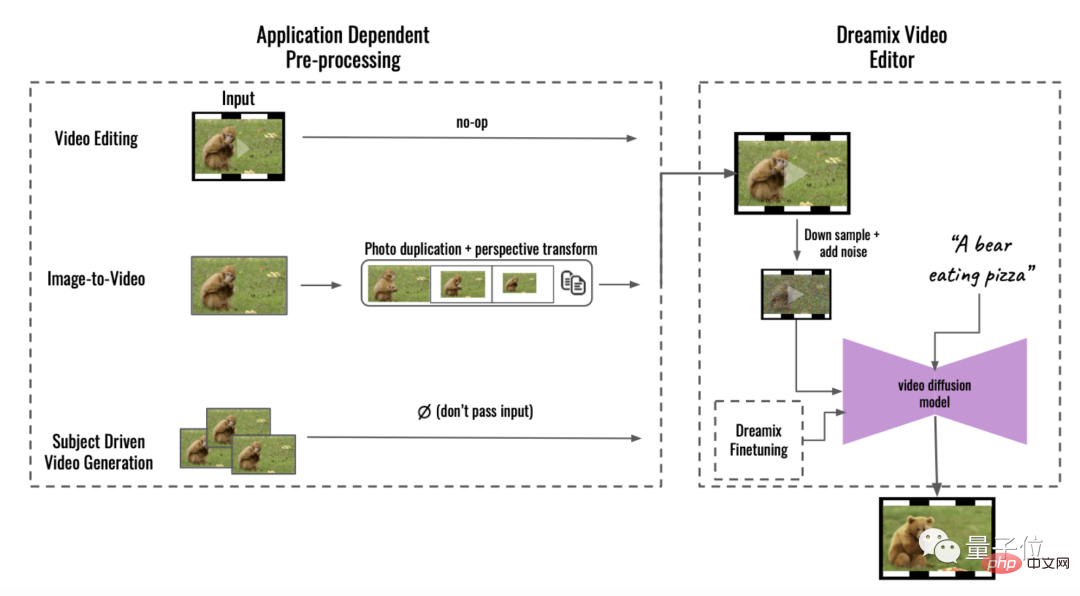
Das obige ist der detaillierte Inhalt vonDer Zauber von Googles neuem „AI Director' besteht darin, dass er den Protagonisten des Videos mit nur einem Satz ändern kann, was erstaunlich ist, und die Bildqualität ist auch sehr gut.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So legen Sie den Linkstil in CSS fest
So legen Sie den Linkstil in CSS fest
 Was bedeutet Metaverse Concept Stock?
Was bedeutet Metaverse Concept Stock?
 So speichern Sie Bilder im Douyin-Kommentarbereich auf dem Mobiltelefon
So speichern Sie Bilder im Douyin-Kommentarbereich auf dem Mobiltelefon
 Die Funktion des Span-Tags
Die Funktion des Span-Tags
 Windows kann nicht auf den angegebenen Gerätepfad oder die angegebene Dateilösung zugreifen
Windows kann nicht auf den angegebenen Gerätepfad oder die angegebene Dateilösung zugreifen
 Verwendung von uniqueResult
Verwendung von uniqueResult
 So überprüfen Sie die Mac-Adresse
So überprüfen Sie die Mac-Adresse
 So ändern Sie den Text im Bild
So ändern Sie den Text im Bild








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



