
 Technologie-Peripheriegeräte
KI
Das Team von Zhu Jun hat das erste groß angelegte multimodale Diffusionsmodell auf Basis von Transformer an der Tsinghua-Universität als Open-Source-Lösung erstellt und es nach dem Umschreiben von Text und Bildern vollständig fertiggestellt.
Technologie-Peripheriegeräte
KI
Das Team von Zhu Jun hat das erste groß angelegte multimodale Diffusionsmodell auf Basis von Transformer an der Tsinghua-Universität als Open-Source-Lösung erstellt und es nach dem Umschreiben von Text und Bildern vollständig fertiggestellt.
Das Team von Zhu Jun hat das erste groß angelegte multimodale Diffusionsmodell auf Basis von Transformer an der Tsinghua-Universität als Open-Source-Lösung erstellt und es nach dem Umschreiben von Text und Bildern vollständig fertiggestellt.

Es wird berichtet, dass GPT-4 diese Woche veröffentlicht wird und Multimodalität zu einem seiner Highlights wird. Das aktuelle große Sprachmodell wird zu einer universellen Schnittstelle zum Verständnis verschiedener Modalitäten und kann Antworttexte basierend auf unterschiedlichen modalen Informationen liefern. Der vom großen Sprachmodell generierte Inhalt ist jedoch nur auf Text beschränkt. Andererseits haben die aktuellen Diffusionsmodelle DALL・E 2, Imagen, Stable Diffusion usw. eine Revolution in der visuellen Erstellung ausgelöst, aber diese Modelle unterstützen nur eine einzige modalübergreifende Funktion von Text zu Bild und sind noch weit davon entfernt aus einer universellen generativen Distanz. Das multimodale Großmodell wird in der Lage sein, die Fähigkeiten verschiedener Modalitäten zu erschließen und die Konvertierung zwischen beliebigen Modalitäten zu realisieren, was als zukünftige Entwicklungsrichtung universeller generativer Modelle angesehen wird.
Ein kürzlich veröffentlichter Artikel „One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale“ vom TSAIL-Team unter der Leitung von Professor Zhu Jun vom Fachbereich Informatik bei Die Tsinghua-Universität wurde erstmals veröffentlicht. Einige Forschungsarbeiten zu multimodalen generativen Modellen haben zu einer gegenseitigen Transformation zwischen allen Modalitäten geführt.

# 🎜 🎜#Papierlink: https://ml.cs.tsinghua.edu.cn/diffusion/unidiffuser.pdf
Open Source Code: https://github.com/thu-ml/unidiffuser
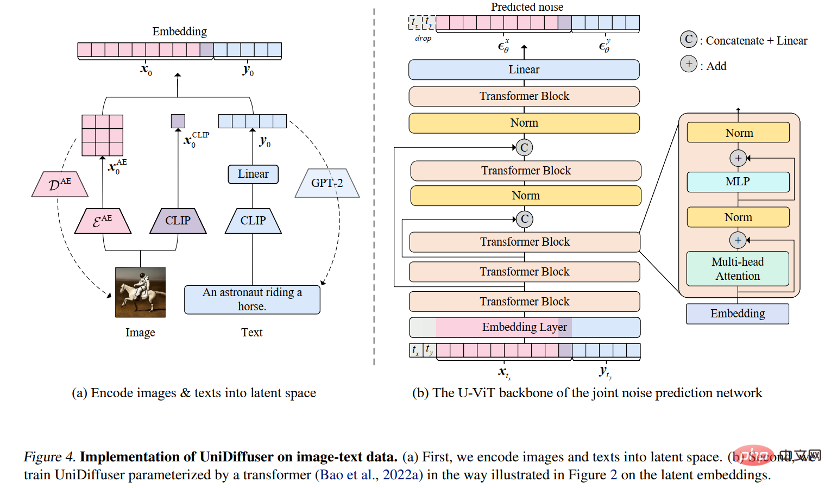
Dieses Papier schlägt UniDiffuser vor, ein probabilistisches Modellierungsframework, das für Multimodalität entwickelt wurde. und übernahm die vom Team vorgeschlagene transformatorbasierte Netzwerkarchitektur U-ViT, um ein Modell mit einer Milliarde Parametern auf dem Open-Source-Grafikdatensatz LAION-5B zu trainieren, wodurch ein zugrunde liegendes Modell eine Vielzahl von Aufgaben mit hoher Qualität erledigen kann . Aufgaben generieren (Abbildung 1). Vereinfacht ausgedrückt kann es neben der einseitigen Bildgenerierung von Bildern auch mehrere Funktionen wie Bildgenerierung von Text, gemeinsame Bild-Text-Generierung, bedingungslose Bild-Text-Generierung, Bild-Text-Umschreibung usw. realisieren Verbessert die Produktionseffizienz von Text-Bild-Inhalten erheblich und verbessert die Anwendungseffizienz des Formelmodells weiter.
Der Erstautor dieser Arbeit, Bao Fan, ist derzeit Doktorand. Er war der vorherige Antragsteller von Analytic-DPM und gewann den ICLR 2022 Outstanding Paper Award ( Derzeit die einzige preisgekrönte Arbeit, die unabhängig von einer Einheit auf dem Festland verfasst wurde.
Darüber hinaus hat Machine Heart bereits über den vom TSAIL-Team vorgeschlagenen schnellen DPM-Solver-Algorithmus berichtet, der immer noch der schnellste Generierungsalgorithmus für Diffusionsmodelle ist. Das multimodale große Modell ist eine konzentrierte Darstellung der langfristigen, detaillierten Ansammlung von Algorithmen und Prinzipien tiefer probabilistischer Modelle durch das Team. Zu den Mitarbeitern dieser Arbeit gehören Li Chongxuan von der Hillhouse School of Artificial Intelligence der Renmin University, Cao Yue vom Beijing Zhiyuan Research Institute und andere.

Es ist erwähnenswert, dass die Papiere und der Code dieses Projekts Open Source.
EffektanzeigeAbbildung 8 unten zeigt die Wirkung von UniDiffuser auf die Bild- und Textverbindungsgenerierung: # 🎜🎜#
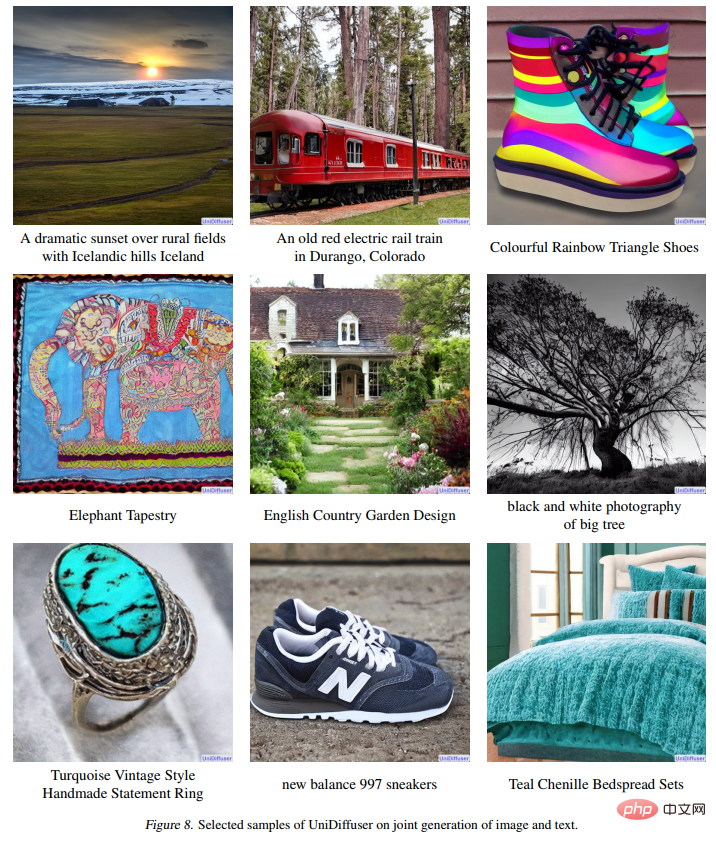
#🎜 🎜#

Abbildung 11 unten zeigt die Wirkung von UniDiffuser auf die bedingungslose Bilderzeugung:  #🎜 🎜##🎜 🎜#
#🎜 🎜##🎜 🎜#
Die folgende Abbildung 12 zeigt die Wirkung von UniDiffuser auf das Umschreiben von Bildern: 
Die folgende Abbildung 15 zeigt, dass UniDiffuser zwischen den beiden Bild- und Textmodi hin und her springen kann:

Abbildung 16 unten zeigt, dass UniDiffuser zwei reale Bilder interpolieren kann:
Methodenübersicht
Das Forschungsteam hat den Entwurf des allgemeinen generativen Modells in zwei Unterprobleme unterteilt:
- Probabilistischer Modellierungsrahmen: Ist es möglich, einen probabilistischen Modellierungsrahmen zu finden, der alle Verteilungen zwischen Modi, wie Randverteilungen, bedingte Verteilungen, gemeinsame Verteilungen zwischen Bildern und Texten usw., gleichzeitig modellieren kann?
- Netzwerkarchitektur: Kann eine einheitliche Netzwerkarchitektur so gestaltet werden, dass sie verschiedene Eingabemodalitäten unterstützt?
Probabilistisches Modellierungs-Framework
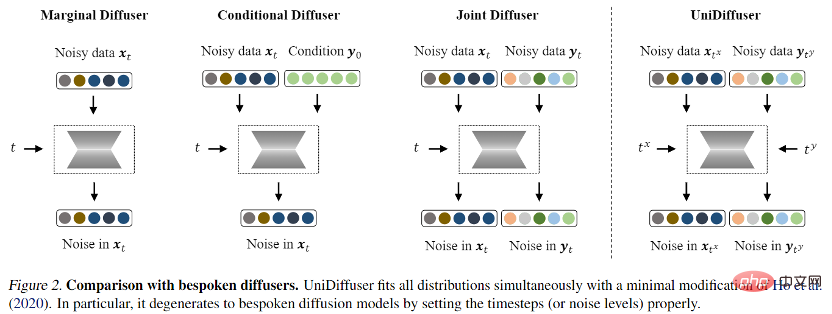
Für das probabilistische Modellierungs-Framework schlug das Forschungsteam UniDiffuser vor, ein probabilistisches Modellierungs-Framework, das auf dem Diffusionsmodell basiert. UniDiffuser kann alle Verteilungen in multimodalen Daten explizit modellieren, einschließlich Randverteilungen, bedingter Verteilungen und gemeinsamer Verteilungen. Das Forschungsteam fand heraus, dass das Diffusionsmodelllernen über unterschiedliche Verteilungen in einer Perspektive vereinheitlicht werden kann: Zuerst wird den Daten der beiden Modalitäten eine bestimmte Größe des Rauschens hinzugefügt und dann wird das Rauschen anhand der Daten der beiden Modalitäten vorhergesagt. Die Menge an Rauschen in den beiden Modaldaten bestimmt die spezifische Verteilung. Das Festlegen der Rauschgröße des Textes auf 0 entspricht beispielsweise der bedingten Verteilung des Vincentschen Diagramms; das Festlegen der Rauschgröße des Textes auf den Maximalwert entspricht der Einstellung der Rauschgröße des Bildes und; Der gleiche Textwert entspricht der gemeinsamen Verteilung von Bildern und Texten. Gemäß dieser einheitlichen Perspektive muss UniDiffuser nur geringfügige Änderungen am Trainingsalgorithmus des ursprünglichen Diffusionsmodells vornehmen, um alle oben genannten Verteilungen gleichzeitig zu lernen. Wie in der folgenden Abbildung gezeigt, fügt UniDiffuser allen Modi gleichzeitig Rauschen hinzu Geben Sie anstelle eines einzelnen Modus die Rauschgröße ein, die allen Modi entspricht, und das vorhergesagte Rauschen für alle Modi.
Am Beispiel des bimodalen Modus lautet die endgültige Trainingszielfunktion wie folgt:
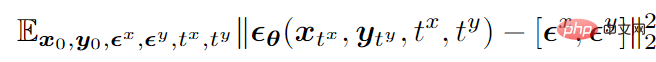
wobei

stellt Daten dar,

stellt das Standard-Gaußsche Rauschen dar, das den beiden Modi hinzugefügt wird,

stellt die Größe (d. h. Zeit) des Rauschens dar, das den beiden Modi hinzugefügt wird, und die beiden sind unabhängig von { 1, 2,…,T} mittlere Abtastung,
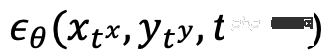
ist ein Lärmvorhersagenetzwerk, das Lärm auf zwei Modalitäten gleichzeitig vorhersagt.
Nach dem Training ist UniDiffuser in der Lage, eine bedingungslose, bedingte und gemeinsame Generierung zu erreichen, indem die entsprechende Zeit für die beiden Modi im Geräuschvorhersagenetzwerk eingestellt wird. Wenn Sie beispielsweise die Zeit des Textes auf 0 setzen, können Sie eine Text-zu-Bild-Generierung erreichen. Wenn Sie die Zeit des Texts auf den Maximalwert setzen, können Sie eine bedingungslose Bildgenerierung erreichen gemeinsame Generierung von Bildern und Texten.
Die Trainings- und Sampling-Algorithmen von UniDiffuser sind unten aufgeführt. Es ist ersichtlich, dass diese Algorithmen im Vergleich zum ursprünglichen Diffusionsmodell nur geringfügige Änderungen vorgenommen haben und einfach zu implementieren sind.

Da UniDiffuser außerdem sowohl bedingte als auch bedingungslose Verteilungen modelliert, unterstützt UniDiffuser natürlich eine klassifikatorfreie Führung. Abbildung 3 unten zeigt die Wirkung der bedingten Generierung und der gemeinsamen Generierung von UniDiffuser unter verschiedenen Führungsskalen:

Netzwerkarchitektur
Für die Netzwerkarchitektur schlug das Forschungsteam die Verwendung transformatorbasierter Architektur vor zur Parametrisierung von Lärmvorhersagenetzwerken. Konkret übernahm das Forschungsteam die kürzlich vorgeschlagene U-ViT-Architektur. U-ViT behandelt alle Eingaben als Token und fügt U-förmige Verbindungen zwischen Transformatorblöcken hinzu. Das Forschungsteam übernahm außerdem die Strategie der stabilen Diffusion, um Daten verschiedener Modalitäten in den latenten Raum umzuwandeln und dann das Diffusionsmodell zu modellieren. Es ist erwähnenswert, dass die U-ViT-Architektur ebenfalls von diesem Forschungsteam stammt und unter https://github.com/baofff/U-ViT als Open Source verfügbar ist.
Experimentelle Ergebnisse
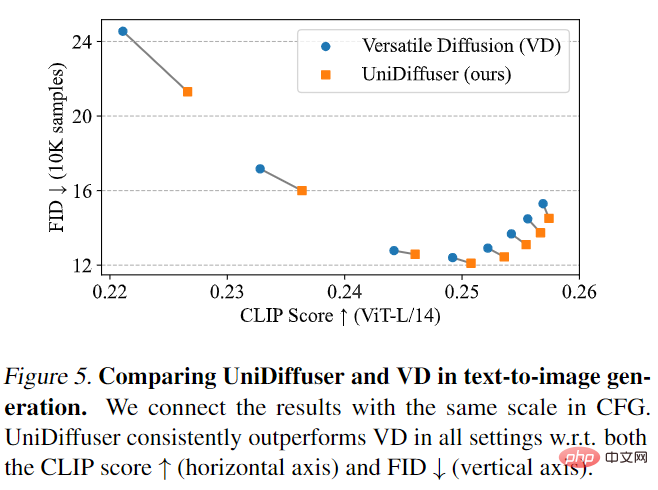
UniDiffuser zuerst im Vergleich mit Versatile Diffusion. Versatile Diffusion ist ein früheres multimodales Diffusionsmodell, das auf einem Multitask-Framework basiert. Zunächst wurden UniDiffuser und Versatile Diffusion hinsichtlich der Text-zu-Bild-Effekte verglichen. Wie in Abbildung 5 unten dargestellt, ist UniDiffuser sowohl beim CLIP-Score als auch bei den FID-Metriken unter verschiedenen klassifikatorfreien Orientierungsskalen besser als Versatile Diffusion.
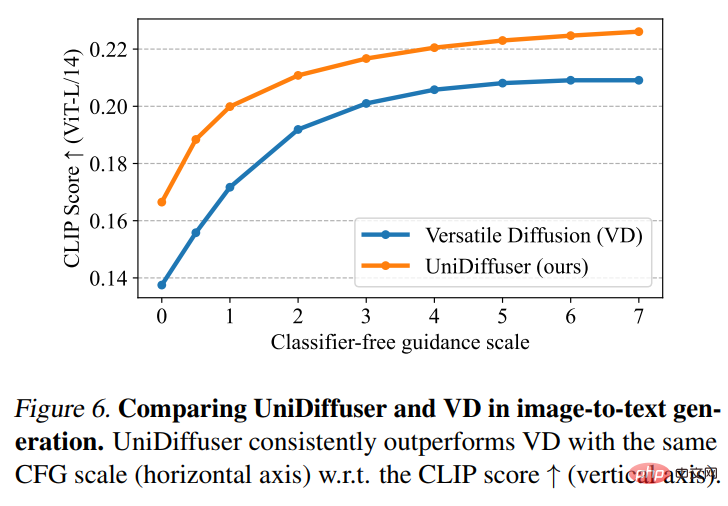
Dann führten UniDiffuser und Versatile Diffusion einen Bild-zu-Text-Effektvergleich durch. Wie in Abbildung 6 unten gezeigt, hat UniDiffuser einen besseren CLIP-Score beim Bild-zu-Text.
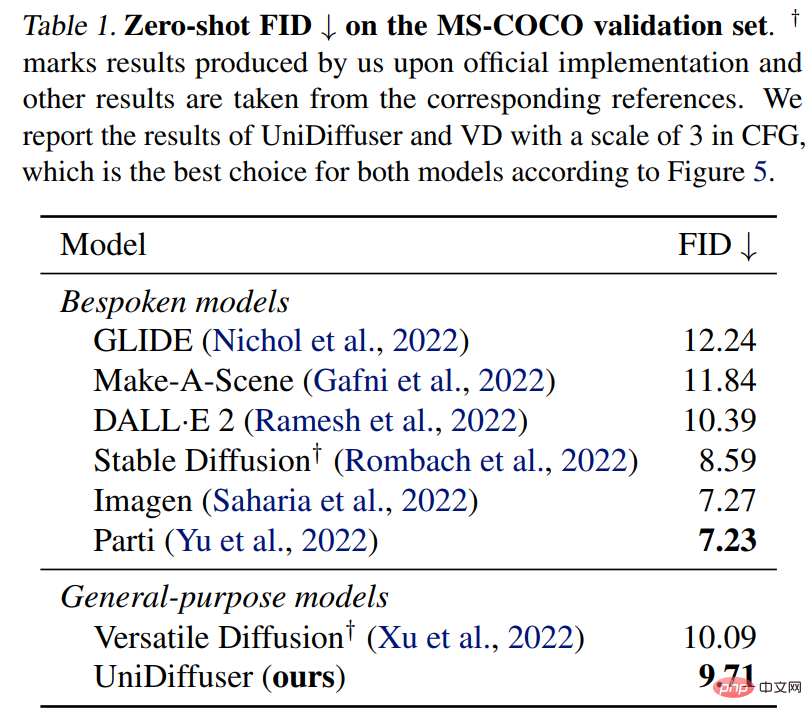
UniDiffuser wird auch mit einem speziellen Text-to-Graph-Modell für Zero-Shot-FID auf MS-COCO verglichen. Wie in Tabelle 1 unten gezeigt, kann UniDiffuser vergleichbare Ergebnisse mit speziellen Text-zu-Grafik-Modellen erzielen.
Das obige ist der detaillierte Inhalt vonDas Team von Zhu Jun hat das erste groß angelegte multimodale Diffusionsmodell auf Basis von Transformer an der Tsinghua-Universität als Open-Source-Lösung erstellt und es nach dem Umschreiben von Text und Bildern vollständig fertiggestellt.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an. Diese innovative Errungenschaft erzielte einen bedeutenden Durchbruch bei Codegenerierungsaufgaben, übertraf erfolgreich CodeLlama-70B-Instruct und erreichte die Spitze der Codegenerierungsleistungsliste. Die Einzigartigkeit von StarCoder2-15B-Instruct liegt in seiner reinen Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar. Das Modell generiert über StarCoder2-15B Tausende von Anweisungen als Reaktion auf die Feinabstimmung des StarCoder-15B-Basismodells, ohne auf teure manuelle Annotationen angewiesen zu sein.
 Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
1. Einleitung In den letzten Jahren haben sich YOLOs aufgrund ihres effektiven Gleichgewichts zwischen Rechenkosten und Erkennungsleistung zum vorherrschenden Paradigma im Bereich der Echtzeit-Objekterkennung entwickelt. Forscher haben das Architekturdesign, die Optimierungsziele, Datenerweiterungsstrategien usw. von YOLO untersucht und erhebliche Fortschritte erzielt. Gleichzeitig behindert die Verwendung von Non-Maximum Suppression (NMS) bei der Nachbearbeitung die End-to-End-Bereitstellung von YOLO und wirkt sich negativ auf die Inferenzlatenz aus. In YOLOs fehlt dem Design verschiedener Komponenten eine umfassende und gründliche Prüfung, was zu erheblicher Rechenredundanz führt und die Fähigkeiten des Modells einschränkt. Es bietet eine suboptimale Effizienz und ein relativ großes Potenzial zur Leistungsverbesserung. Ziel dieser Arbeit ist es, die Leistungseffizienzgrenze von YOLO sowohl in der Nachbearbeitung als auch in der Modellarchitektur weiter zu verbessern. zu diesem Zweck
 Die Tsinghua-Universität übernahm und YOLOv10 kam heraus: Die Leistung wurde erheblich verbessert und es stand auf der GitHub-Hotlist
Jun 06, 2024 pm 12:20 PM
Die Tsinghua-Universität übernahm und YOLOv10 kam heraus: Die Leistung wurde erheblich verbessert und es stand auf der GitHub-Hotlist
Jun 06, 2024 pm 12:20 PM
Die Benchmark-Zielerkennungssysteme der YOLO-Serie haben erneut ein großes Upgrade erhalten. Seit der Veröffentlichung von YOLOv9 im Februar dieses Jahres wurde der Staffelstab der YOLO-Reihe (YouOnlyLookOnce) in die Hände von Forschern der Tsinghua-Universität übergeben. Letztes Wochenende erregte die Nachricht vom Start von YOLOv10 die Aufmerksamkeit der KI-Community. Es gilt als bahnbrechendes Framework im Bereich Computer Vision und ist für seine End-to-End-Objekterkennungsfunktionen in Echtzeit bekannt. Es führt das Erbe der YOLO-Serie fort und bietet eine leistungsstarke Lösung, die Effizienz und Genauigkeit vereint. Papieradresse: https://arxiv.org/pdf/2405.14458 Projektadresse: https://github.com/THU-MIG/yo
 Technischer Bericht von Google Gemini 1.5: Einfache Prüfung von Mathematik-Olympiade-Fragen, die Flash-Version ist fünfmal schneller als GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Technischer Bericht von Google Gemini 1.5: Einfache Prüfung von Mathematik-Olympiade-Fragen, die Flash-Version ist fünfmal schneller als GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Im Februar dieses Jahres brachte Google das multimodale Großmodell Gemini 1.5 auf den Markt, das durch technische und Infrastrukturoptimierung, MoE-Architektur und andere Strategien die Leistung und Geschwindigkeit erheblich verbesserte. Mit längerem Kontext, stärkeren Argumentationsfähigkeiten und besserem Umgang mit modalübergreifenden Inhalten. Diesen Freitag hat Google DeepMind offiziell den technischen Bericht zu Gemini 1.5 veröffentlicht, der die Flash-Version und andere aktuelle Upgrades behandelt. Das Dokument ist 153 Seiten lang. Link zum technischen Bericht: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf In diesem Bericht stellt Google Gemini1 vor
 So bewerten Sie die Kosteneffizienz der kommerziellen Unterstützung für Java-Frameworks
Jun 05, 2024 pm 05:25 PM
So bewerten Sie die Kosteneffizienz der kommerziellen Unterstützung für Java-Frameworks
Jun 05, 2024 pm 05:25 PM
Die Bewertung des Kosten-/Leistungsverhältnisses des kommerziellen Supports für ein Java-Framework umfasst die folgenden Schritte: Bestimmen Sie das erforderliche Maß an Sicherheit und Service-Level-Agreement-Garantien (SLA). Die Erfahrung und das Fachwissen des Forschungsunterstützungsteams. Erwägen Sie zusätzliche Services wie Upgrades, Fehlerbehebung und Leistungsoptimierung. Wägen Sie die Kosten für die Geschäftsunterstützung gegen Risikominderung und Effizienzsteigerung ab.
 Rezension! Fassen Sie umfassend die wichtige Rolle von Basismodellen bei der Förderung des autonomen Fahrens zusammen
Jun 11, 2024 pm 05:29 PM
Rezension! Fassen Sie umfassend die wichtige Rolle von Basismodellen bei der Förderung des autonomen Fahrens zusammen
Jun 11, 2024 pm 05:29 PM
Oben geschrieben und das persönliche Verständnis des Autors: Mit der Entwicklung und den Durchbrüchen der Deep-Learning-Technologie haben kürzlich groß angelegte Grundlagenmodelle (Foundation Models) bedeutende Ergebnisse in den Bereichen natürlicher Sprachverarbeitung und Computer Vision erzielt. Große Entwicklungsperspektiven bietet auch die Anwendung von Basismodellen beim autonomen Fahren, die das Verständnis und die Argumentation von Szenarien verbessern können. Durch Vortraining mit umfangreichen Sprach- und visuellen Daten kann das Basismodell verschiedene Elemente in autonomen Fahrszenarien verstehen und interpretieren und Schlussfolgerungen ziehen, indem es Sprach- und Aktionsbefehle für die Entscheidungsfindung und Planung im Fahrbetrieb bereitstellt. Das Basismodell kann durch Datenergänzung mit einem Verständnis des Fahrszenarios ergänzt werden, um jene seltenen realisierbaren Merkmale in Long-Tail-Verteilungen bereitzustellen, die bei routinemäßigem Fahren und bei der Datenerfassung unwahrscheinlich anzutreffen sind.
 Wie ist die Lernkurve von PHP-Frameworks im Vergleich zu anderen Sprach-Frameworks?
Jun 06, 2024 pm 12:41 PM
Wie ist die Lernkurve von PHP-Frameworks im Vergleich zu anderen Sprach-Frameworks?
Jun 06, 2024 pm 12:41 PM
Die Lernkurve eines PHP-Frameworks hängt von Sprachkenntnissen, Framework-Komplexität, Dokumentationsqualität und Community-Unterstützung ab. Die Lernkurve von PHP-Frameworks ist im Vergleich zu Python-Frameworks höher und im Vergleich zu Ruby-Frameworks niedriger. Im Vergleich zu Java-Frameworks haben PHP-Frameworks eine moderate Lernkurve, aber eine kürzere Einstiegszeit.
 Haben unterschiedliche Datensätze unterschiedliche Skalierungsgesetze? Und Sie können es mit einem Komprimierungsalgorithmus vorhersagen
Jun 07, 2024 pm 05:51 PM
Haben unterschiedliche Datensätze unterschiedliche Skalierungsgesetze? Und Sie können es mit einem Komprimierungsalgorithmus vorhersagen
Jun 07, 2024 pm 05:51 PM
Im Allgemeinen gilt: Je mehr Berechnungen zum Trainieren eines neuronalen Netzwerks erforderlich sind, desto besser ist seine Leistung. Bei der Skalierung einer Berechnung muss eine Entscheidung getroffen werden: Erhöhen Sie die Anzahl der Modellparameter oder erhöhen Sie die Größe des Datensatzes – zwei Faktoren, die innerhalb eines festen Rechenbudgets abgewogen werden müssen. Der Vorteil einer Erhöhung der Anzahl der Modellparameter besteht darin, dass dadurch die Komplexität und Ausdrucksfähigkeit des Modells verbessert und dadurch die Trainingsdaten besser angepasst werden können. Zu viele Parameter können jedoch zu einer Überanpassung führen, wodurch das Modell bei unsichtbaren Daten eine schlechte Leistung erbringt. Andererseits kann die Erweiterung der Datensatzgröße die Generalisierungsfähigkeit des Modells verbessern und Überanpassungsprobleme reduzieren. Wir sagen Ihnen: Solange Sie Parameter und Daten richtig zuordnen, können Sie die Leistung innerhalb eines festgelegten Rechenbudgets maximieren. Viele frühere Studien haben die Skalierung neuronaler Sprachmodelle untersucht.
