

Bloom-Filter wurde 1970 von Bloom vorgeschlagen. Es besteht tatsächlich aus einem sehr langen binären Array + einer Reihe von Hash-Algorithmus-Zuordnungsfunktionen, mit denen ermittelt wird, ob ein Element in der Menge vorhanden ist.
Bloom-Filter können verwendet werden, um abzufragen, ob sich ein Element in einer Sammlung befindet. Sein Vorteil besteht darin, dass die Speicherplatzeffizienz und die Abfragezeit viel besser sind als bei herkömmlichen Algorithmen. Der Nachteil besteht darin, dass es eine gewisse Fehlerkennungsrate und Schwierigkeiten beim Löschen gibt.
Angenommen, es gibt 1 Milliarde Mobiltelefonnummern und stellt dann fest, ob eine bestimmte Mobiltelefonnummer in der Liste enthalten ist?
MySQL OK?
Wenn die Datenmenge unter normalen Umständen nicht groß ist, können wir die Verwendung von MySQL-Speicher in Betracht ziehen. Speichern Sie alle Daten in der Datenbank und fragen Sie dann die Datenbank ab, um festzustellen, ob sie vorhanden ist. Wenn die Datenmenge jedoch zu groß ist und mehrere zehn Millionen überschreitet, ist die Effizienz der MySQL-Abfrage sehr gering, was insbesondere die Leistung beeinträchtigt.
HashSet OK?
Wir können die Daten in das HashSet einfügen und die natürliche Deduplizierung des HashSets verwenden. Die Abfrage muss nur die Methode „contains“ aufrufen, aber das Hashset wird im Speicher gespeichert Die Datenmenge ist zu groß.
Einfügung und Abfrage sind effizient und beanspruchen weniger Platz, aber die zurückgegebenen Ergebnisse sind unsicher.
Wenn festgestellt wird, dass ein Element existiert, existiert es möglicherweise nicht tatsächlich. Wenn jedoch festgestellt wird, dass ein Element nicht existiert, dann darf es nicht existieren.
Der Bloom-Filter kann Elemente hinzufügen, , darf aber keine Elemente löschen, , was zu einem Anstieg der Fehleinschätzungsraten führt.
Ein Bloom-Filter ist eigentlich ein BIT-Array, das den entsprechenden Hash durch eine Reihe von Hash-Algorithmen zuordnet und dann Ändern Sie die Array-Indexposition, die dem Hash entspricht, auf 1. Bei der Abfrage wird eine Reihe von Hash-Algorithmen für die Daten ausgeführt, um den Index zu erhalten, z. B. . Wenn es 1 ist, bedeutet dies, dass die Daten möglicherweise vorhanden sind. es bedeutet, dass es definitiv nicht existiert verwendet wird, ist es möglich, dass die von zwei verschiedenen Daten generierten Hashes tatsächlich dasselbe sind, was wir oft als Hash-Konflikt bezeichnen.
Fügen Sie zuerst ein Datenelement ein: Technologie gut lernenFügen Sie ein Datenelement ein:
#🎜 🎜## 🎜🎜#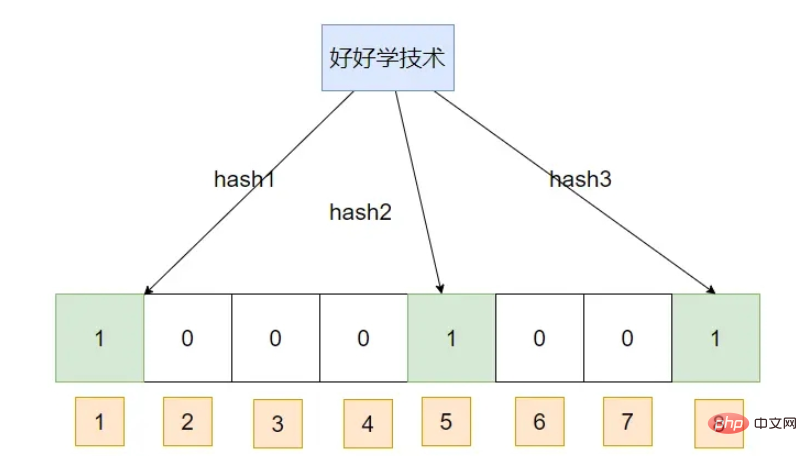 Das heißt, wenn Sie ein Datenelement abfragen und davon ausgehen, dass sein Hash-Index bereits als 1 markiert ist, geht der Bloom-Filter davon aus, dass es existiert
Das heißt, wenn Sie ein Datenelement abfragen und davon ausgehen, dass sein Hash-Index bereits als 1 markiert ist, geht der Bloom-Filter davon aus, dass es existiert
package com.fandf.test.redis;
import java.util.BitSet;
/**
* java布隆过滤器
*
* @author fandongfeng
*/
public class MyBloomFilter {
/**
* 位数组大小
*/
private static final int DEFAULT_SIZE = 2 << 24;
/**
* 通过这个数组创建多个Hash函数
*/
private static final int[] SEEDS = new int[]{4, 8, 16, 32, 64, 128, 256};
/**
* 初始化位数组,数组中的元素只能是 0 或者 1
*/
private final BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* Hash函数数组
*/
private final MyHash[] myHashes = new MyHash[SEEDS.length];
/**
* 初始化多个包含 Hash 函数的类数组,每个类中的 Hash 函数都不一样
*/
public MyBloomFilter() {
// 初始化多个不同的 Hash 函数
for (int i = 0; i < SEEDS.length; i++) {
myHashes[i] = new MyHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 添加元素到位数组
*/
public void add(Object value) {
for (MyHash myHash : myHashes) {
bits.set(myHash.hash(value), true);
}
}
/**
* 判断指定元素是否存在于位数组
*/
public boolean contains(Object value) {
boolean result = true;
for (MyHash myHash : myHashes) {
result = result && bits.get(myHash.hash(value));
}
return result;
}
/**
* 自定义 Hash 函数
*/
private class MyHash {
private int cap;
private int seed;
MyHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 计算 Hash 值
*/
int hash(Object obj) {
return (obj == null) ? 0 : Math.abs(seed * (cap - 1) & (obj.hashCode() ^ (obj.hashCode() >>> 16)));
}
}
public static void main(String[] args) {
String str = "好好学技术";
MyBloomFilter myBloomFilter = new MyBloomFilter();
System.out.println("str是否存在:" + myBloomFilter.contains(str));
myBloomFilter.add(str);
System.out.println("str是否存在:" + myBloomFilter.contains(str));
}
}<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>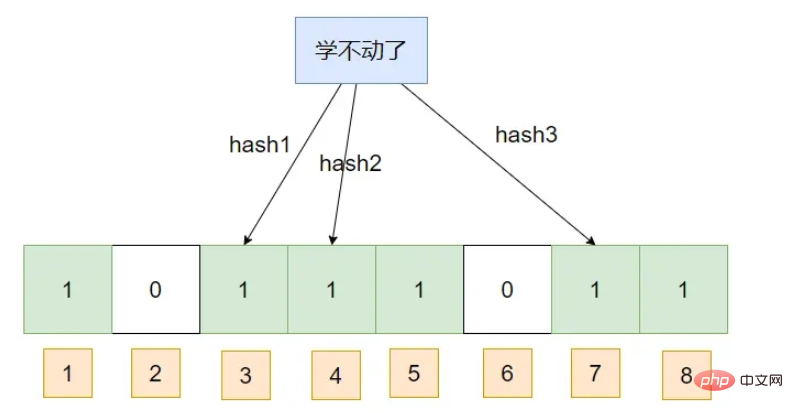 hutool implementiert Bloom-Filter
hutool implementiert Bloom-FilterEinführung von Abhängigkeiten
package com.fandf.test.redis;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* @author fandongfeng
*/
public class GuavaBloomFilter {
public static void main(String[] args) {
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),100000,0.01);
bloomFilter.put("好好学技术");
System.out.println(bloomFilter.mightContain("不好好学技术"));
System.out.println(bloomFilter.mightContain("好好学技术"));
}
}<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.3</version>
</dependency>Redisson. implementieren s Tuch lang filter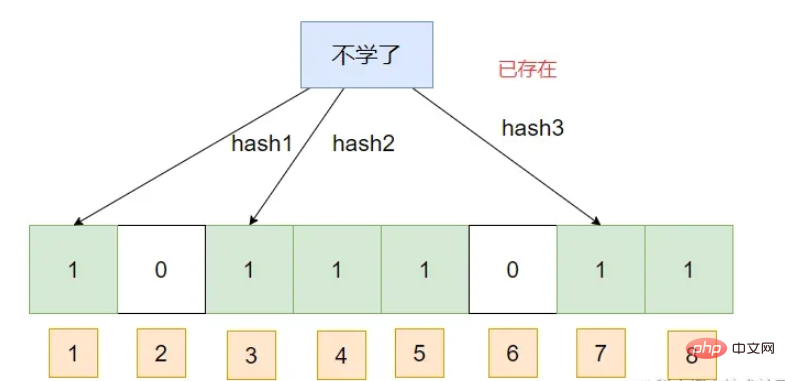
package com.fandf.test.redis;
import cn.hutool.bloomfilter.BitMapBloomFilter;
import cn.hutool.bloomfilter.BloomFilterUtil;
/**
* @author fandongfeng
*/
public class HutoolBloomFilter {
public static void main(String[] args) {
BitMapBloomFilter bloomFilter = BloomFilterUtil.createBitMap(1000);
bloomFilter.add("好好学技术");
System.out.println(bloomFilter.contains("不好好学技术"));
System.out.println(bloomFilter.contains("好好学技术"));
}
}Das obige ist der detaillierte Inhalt vonWie implementiert man einen Bloom-Filter in Java?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



