
 Technologie-Peripheriegeräte
KI
Die Kerntechnologie von Byte AI Lab gewann die Habitat Challenge 2022 Active Navigation Championship, die traditionelle Methoden mit Nachahmungslernen kombiniert.
Technologie-Peripheriegeräte
KI
Die Kerntechnologie von Byte AI Lab gewann die Habitat Challenge 2022 Active Navigation Championship, die traditionelle Methoden mit Nachahmungslernen kombiniert.
Die Kerntechnologie von Byte AI Lab gewann die Habitat Challenge 2022 Active Navigation Championship, die traditionelle Methoden mit Nachahmungslernen kombiniert.


Objektnavigation ist eine der Grundaufgaben intelligenter Roboter. Bei dieser Aufgabe erkundet und findet der intelligente Roboter aktiv bestimmte, von Menschen bestimmte Arten von Objekten in einer unbekannten neuen Umgebung. Die Aufgabe der Objektzielnavigation orientiert sich an den Anwendungsanforderungen zukünftiger Heimservice-Roboter. Wenn Menschen den Roboter benötigen, um bestimmte Aufgaben zu erledigen, beispielsweise um ein Glas Wasser zu holen, muss der Roboter zunächst den Standort des Wasserbechers finden und sich dorthin bewegen , und dann helfen Sie den Leuten, den Wasserbecher zu bekommen.
Die Habitat Challenge wird gemeinsam von Meta AI und anderen Institutionen organisiert. Sie ist einer der bekanntesten Wettbewerbe im Bereich der Objektnavigation. Insgesamt haben 54 Teams daran teilgenommen in diesem Wettbewerb. Im Wettbewerb schlugen Forscher des ByteDance AI Lab-Research-Teams ein neues Framework für die Objektzielnavigation vor, um die Mängel bestehender Methoden zu beheben. Dieses Framework kombiniert geschickt Nachahmungslernen mit traditionellen Methoden, um sich von der Masse abzuheben und die Meisterschaft zu gewinnen. Ergebnisse, die die Ergebnisse des Zweitplatzierten und der anderen teilnehmenden Teams in der Schlüsselmetrik SPL deutlich übertrafen. Historisch gesehen sind die Championteams dieser Veranstaltung im Allgemeinen bekannte Forschungseinrichtungen wie CMU, UC Berkerly und Facebook.
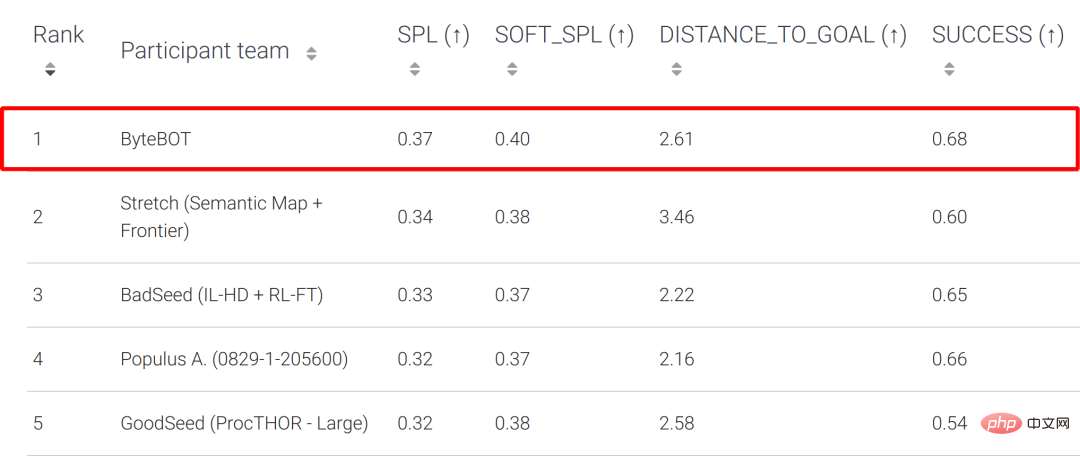
Test-Standard-Liste
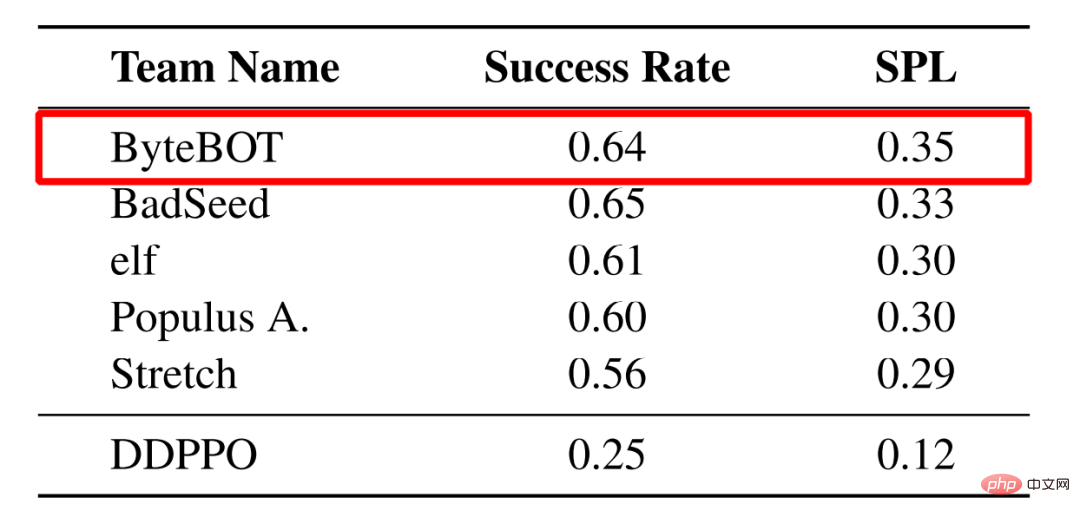
Test-Challenge-Liste
Habitat Challenge Competition Offizielle Website: https://aihabitat.org/challenge/2022/
Habitat Challenge Competition LeaderBoard: https:// eval .ai/web/challenges/challenge-page/1615/leaderboard
1. Forschungsmotivation
Aktuelle Objektzielnavigationsmethoden können grob in zwei Kategorien unterteilt werden: End-to-End-Methoden und kartenbasierte Methoden. Die End-to-End-Methode extrahiert die Eigenschaften der eingegebenen Sensordaten und sendet sie dann an ein Deep-Learning-Modell, um die Aktion zu erhalten. Solche Methoden basieren im Allgemeinen auf Verstärkungslernen oder Imitationslernen (Abbildung 1 Kartenlose Methoden). -basierte Methoden erstellen im Allgemeinen explizite oder implizite Karten, wählen dann durch Verstärkungslernen und andere Methoden einen Zielpunkt auf der Karte aus und planen schließlich den Pfad und erhalten die Aktion (Abbildung 1 Kartenbasierte Methode).
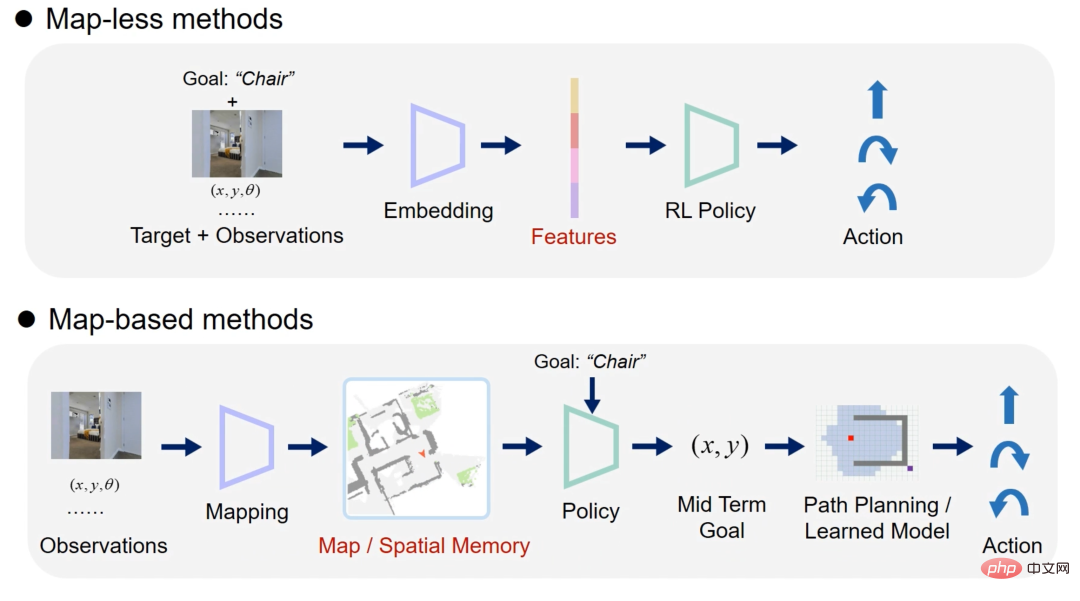
Abbildung 1 Flussdiagramm der End-to-End-Methode (oben) und der kartenbasierten Methode (unten)
Nach einer großen Anzahl von Experimenten zum Vergleich der beiden Methodentypen stellten die Forscher fest, dass beide Typen Verschiedene Methoden haben ihre eigenen Vor- und Nachteile: Die End-to-End-Methode erfordert nicht die Erstellung einer Umgebungskarte, ist daher prägnanter und verfügt über eine stärkere Generalisierungsfähigkeit in verschiedenen Szenarien. Da das Netzwerk jedoch lernen muss, die räumlichen Informationen der Umgebung zu kodieren, ist es auf eine große Menge an Trainingsdaten angewiesen und es ist schwierig, gleichzeitig einige einfache Verhaltensweisen zu erlernen, z. B. das Anhalten in der Nähe des Zielobjekts. Kartenbasierte Methoden verwenden Raster zum Speichern von Features oder Semantik und verfügen über explizite räumliche Informationen, sodass die Lernschwelle für diese Art von Verhalten niedriger ist. Es hängt jedoch stark von genauen Positionierungsergebnissen ab und in einigen Umgebungen wie Treppen ist eine künstliche Wahrnehmungsgestaltung und Wegeplanungsstrategien erforderlich.
Basierend auf den oben genannten Schlussfolgerungen hoffen Forscher des ByteDance AI Lab-Research-Teams, die Vorteile der beiden Methoden zu kombinieren. Allerdings sind die Algorithmusprozesse dieser beiden Methoden sehr unterschiedlich und schwer direkt zu kombinieren. Außerdem ist es schwierig, eine Strategie zu entwerfen, um die Ausgabe der beiden Methoden direkt zu integrieren. Daher entwickelten die Forscher eine einfache, aber effektive Strategie, die es den beiden Arten von Methoden ermöglicht, je nach Status des Roboters abwechselnd aktive Erkundung und Objektsuche durchzuführen und so ihre jeweiligen Vorteile zu maximieren.
2. Wettbewerbsmethode
Der Algorithmus besteht hauptsächlich aus zwei Zweigen: dem Wahrscheinlichkeitskarten-basierten Zweig und dem End-to-End-Zweig. Die Eingabe des Algorithmus ist das RGB-D-Bild und die Roboterpose der ersten Ansicht sowie die zu findende Zielobjektkategorie, und die Ausgabe ist die nächste Aktion (Aktion). Das RGB-Bild wird zunächst segmentiert und zusammen mit anderen Roheingabedaten an beide Zweige übergeben. Die beiden Zweige geben jeweils ihre eigenen Aktionen aus, und eine Umschaltstrategie bestimmt die endgültige Ausgabeaktion.
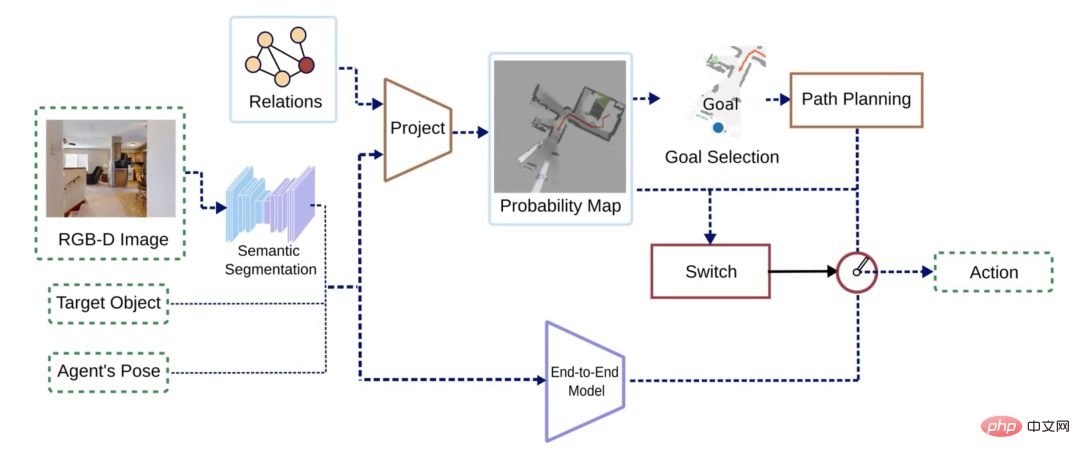
Abbildung 2 Schematische Darstellung des Algorithmusflusses
Der auf der Wahrscheinlichkeitskarte basierende Zweig
Der auf der Wahrscheinlichkeitskarte basierende Zweig basiert auf der Idee der semantischen Verknüpfungskarte[2] und vereinfacht die Methode des Originalpapiers des Autors[3], das auf der IROS Robot Conference veröffentlicht wurde . Dieser Zweig erstellt eine semantische 2D-Karte auf der Grundlage der Segmentierungsergebnisse der Eingabeinstanz, der Tiefenkarte und der Roboterhaltung. Andererseits aktualisiert er eine Wahrscheinlichkeitskarte auf der Grundlage der vorab erlernten Assoziationswahrscheinlichkeiten zwischen Objekten.
Die Aktualisierungsmethoden der Wahrscheinlichkeitskarte umfassen Folgendes: Wenn das Zielobjekt erkannt wird, aber nicht sicher genug ist (der Vertrauenswert liegt unter dem Schwellenwert), sollte die genauere Beobachtung zu diesem Zeitpunkt fortgesetzt werden, sodass der Wahrscheinlichkeitswert des Der entsprechende Bereich auf der Wahrscheinlichkeitskarte sollte vergrößert werden (wie im oberen Teil von Abbildung 3 gezeigt). , erhöht sich auch der Wahrscheinlichkeitswert des entsprechenden Bereichs (wie im unteren Teil von Abbildung 3 dargestellt). Durch die Auswahl des Bereichs mit der höchsten Wahrscheinlichkeit als Zielpunkt ermutigt der Algorithmus den Roboter, sich potenziellen Zielobjekten und verwandten Objekten zur weiteren Beobachtung zu nähern, bis er ein Zielobjekt mit einer Konfidenzwahrscheinlichkeit über dem Schwellenwert findet.
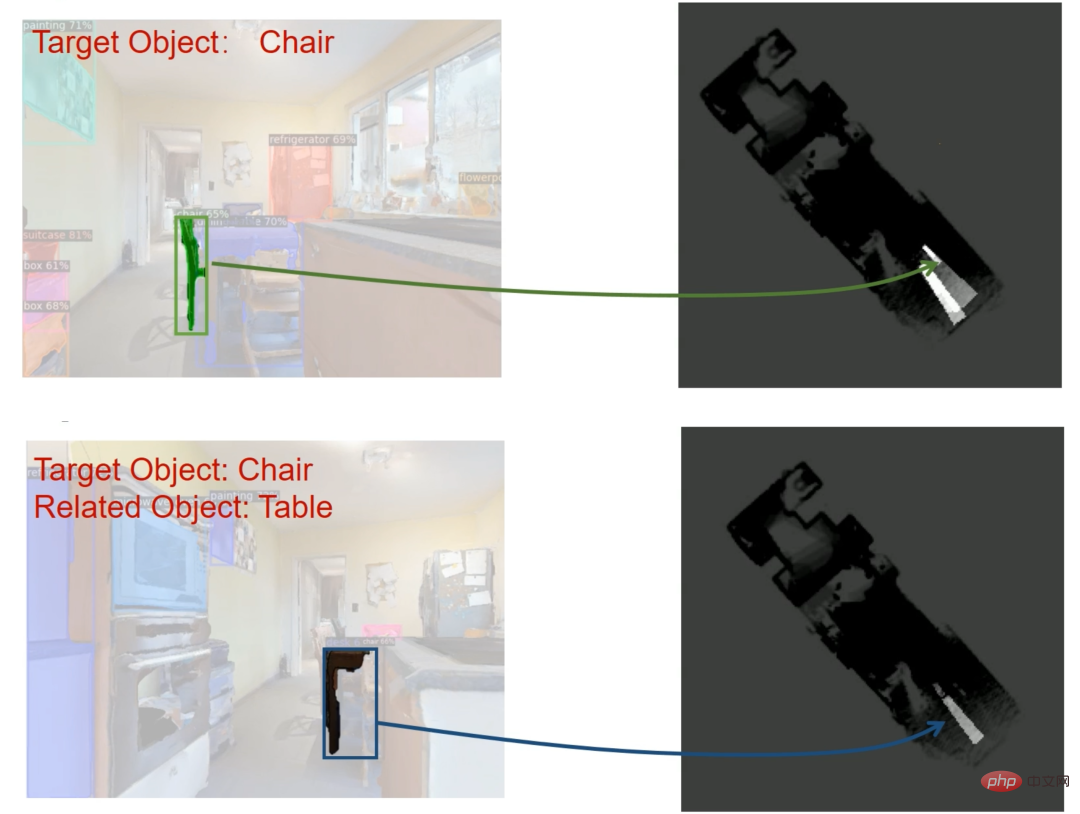
Abbildung 3 Schematische Darstellung der Methode zur Aktualisierung der Wahrscheinlichkeitskarte
End-to-End-Zweig
Die Eingabe des End-to-End-Zweigs umfasst RGB-D-Bilder, Instanzsegmentierungsergebnisse und Roboter Posen und Zielobjektkategorien sowie Direktausgabeaktion. Die Hauptfunktion des End-to-End-Zweigs besteht darin, den Roboter bei der Suche nach Objekten wie Menschen anzuleiten. Daher werden das Modell und der Trainingsprozess der Habitat-Web[4]-Methode übernommen. Die Methode basiert auf Nachahmungslernen, bei dem das Netzwerk trainiert wird, indem Beispiele von Menschen gesammelt werden, die in einem Trainingssatz nach Objekten suchen.
Umschaltstrategie
Die Umschaltstrategie wählt hauptsächlich eine der beiden vom Wahrscheinlichkeitskartenzweig und vom End-to-End-Zweig ausgegebenen Aktionen als endgültige Ausgabe basierend auf den Ergebnissen der Wahrscheinlichkeitskarten- und Pfadplanung aus. Wenn in der Wahrscheinlichkeitskarte kein Raster mit einer Wahrscheinlichkeit größer als der Schwellenwert vorhanden ist, muss der Roboter die Umgebung erkunden. Wenn auf der Karte kein möglicher Pfad geplant werden kann, befindet sich der Roboter möglicherweise in bestimmten Umgebungen (z. B. Treppen). In beiden Fällen werden End-to-End-Methoden verwendet. Durch die End-to-End-Verzweigung erhält der Roboter eine ausreichende Anpassungsfähigkeit an die Umgebung. In anderen Fällen wird der probabilistische Kartenzweig ausgewählt, um seine Vorteile beim Auffinden von Zielobjekten voll auszuschöpfen.
Der Effekt dieser Umschaltstrategie wird im Video gezeigt. Der Roboter nutzt im Allgemeinen den End-to-End-Zweig, um die Umgebung effizient zu erkunden. Sobald ein mögliches Zielobjekt oder ein damit verbundenes Objekt gefunden wird, wechselt er zum Wahrscheinlichkeitskartenzweig Wenn die Konfidenzwahrscheinlichkeit des Zielobjekts größer als der Schwellenwert ist, wird es beim Zielobjekt angehalten. Andernfalls nimmt der Wahrscheinlichkeitswert in dem Bereich weiter ab, bis keine Gitter mehr vorhanden sind, deren Wahrscheinlichkeit größer als der Schwellenwert ist. und der Roboter wechselt wieder in den End-to-End-Modus, um die Erkundung fortzusetzen.
Wie im Video zu sehen ist, vereint diese Methode die Vorteile sowohl des End-to-End-Ansatzes als auch des kartenbasierten Ansatzes. Die beiden Zweige erfüllen ihre eigenen Aufgaben. Die End-to-End-Methode ist hauptsächlich für die Erkundung der Umgebung verantwortlich. Daher kann diese Methode nicht nur komplexe Szenen (z. B. Treppen) erkunden, sondern auch den Schulungsbedarf des End-to-End-Zweigs reduzieren.
3. Zusammenfassung
Für die objektaktive Zielnavigation schlug das ByteDance AI Lab-Research-Team ein Framework vor, das klassische Wahrscheinlichkeitskarten mit modernem Imitationslernen kombiniert. Dieses Framework ist ein erfolgreicher Versuch, traditionelle Methoden mit einem End-to-End-Ansatz zu kombinieren. Im Habitat-Wettbewerb übertraf die vom ByteDance AI Lab-Research-Team vorgeschlagene Methode die Ergebnisse des Zweitplatzierten und anderer teilnehmender Teams deutlich und bewies damit die Weiterentwicklung des Algorithmus. Durch die Einführung traditioneller Methoden in die aktuelle Mainstream-End-to-End-Methode der verkörperten KI können wir einige Mängel der End-to-End-Methode weiter ausgleichen und so intelligente Roboter auf dem Weg zur Hilfe und zum Dienst an Menschen weiterbringen.
Kürzlich wurde die Forschung des ByteDance AI Lab-Research-Teams auf dem Gebiet der Robotik auch in Top-Robotikkonferenzen wie CoRL, IROS und ICRA einbezogen, darunter Objektpositionsschätzung, Objekterfassung, Zielnavigation, automatische Montage und Mensch- Computerinteraktion und andere Kernaufgaben von Robotern.
【CoRL 2022】Generative Form- und Posenschätzung auf Kategorieebene mit semantischen Primitiven
- Papieradresse: https://arxiv.org/abs/2210.01112
【IROS 2022】3D-Teilebaugruppengenerierung mit instanzencodiertem Transformator
- Papieradresse: https://arxiv.org/abs/2207.01779
【IROS 2022】Navigieren zu Objekten in unsichtbaren Umgebungen durch Entfernungsvorhersage
- Papieradresse: https://arxiv.org/abs/2202.03735
【EMNLP 2022】Towards Unifying Reference Expression Generation and Comprehension
- Papieradresse: https://arxiv.org/pdf/2210.13076
【ICRA 2022】Lernen von Design und Konstruktion mit Materialien unterschiedlicher Größe durch priorisierte Speicherrücksetzungen
- Papieradresse: https://arxiv.org/abs/2204.05509
【IROS 2021】Simultanes Semantik- und Kollisionslernen für 6-DoF Grasp Pose Estimation
- Papieradresse: https://arxiv.org/abs/2108.02425
【IROS 2021】Learning to Design and Construct Bridge without Blueprint
- Papieradresse: https://arxiv.org/abs /2108.02439
4. Referenzen
[1] Yadav, Karmesh, et al. „Habitat-Matterport 3D Semantics Dataset“. und Odest Chadwicke Jenkins. „Semantische Verknüpfungskarten für die aktive visuelle Objektsuche.“ 2020 IEEE International Conference on Robotics and Automation, 2020.
[3] Minzhao Zhu, Binglei Zhao und Tao Kong Objekte in unsichtbaren Umgebungen durch Entfernungsvorhersage.“ Tagungsband der IEEE/CVF-Konferenz zu Computer Vision und Mustererkennung. 2022 Er ist im Bereich der Technologieforschung tätig und engagiert sich für die Umsetzung von Forschungsergebnissen in die Praxis sowie für die Bereitstellung grundlegender technischer Unterstützung und Dienstleistungen für die bestehenden Produkte und Geschäfte des Unternehmens. Die technischen Fähigkeiten des Teams werden durch die Volcano Engine der Außenwelt zugänglich gemacht, wodurch KI-Innovationen gefördert werden.
ByteDance AI-Lab NLP&Research Kontaktinformationen
Rekrutierungsberatung: fankaijing@bytedance.comAkademische Zusammenarbeit: luomanping@bytedance.comDas obige ist der detaillierte Inhalt vonDie Kerntechnologie von Byte AI Lab gewann die Habitat Challenge 2022 Active Navigation Championship, die traditionelle Methoden mit Nachahmungslernen kombiniert.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der humanoide Roboter Ameca wurde auf die zweite Generation aufgerüstet! Kürzlich erschien auf der World Mobile Communications Conference MWC2024 erneut der weltweit fortschrittlichste Roboter Ameca. Rund um den Veranstaltungsort lockte Ameca zahlreiche Zuschauer an. Mit dem Segen von GPT-4 kann Ameca in Echtzeit auf verschiedene Probleme reagieren. „Lass uns tanzen.“ Auf die Frage, ob sie Gefühle habe, antwortete Ameca mit einer Reihe von Gesichtsausdrücken, die sehr lebensecht aussahen. Erst vor wenigen Tagen stellte EngineeredArts, das britische Robotikunternehmen hinter Ameca, die neuesten Entwicklungsergebnisse des Teams vor. Im Video verfügt der Roboter Ameca über visuelle Fähigkeiten und kann den gesamten Raum und bestimmte Objekte sehen und beschreiben. Das Erstaunlichste ist, dass sie es auch kann
 Wie kann KI Roboter autonomer und anpassungsfähiger machen?
Jun 03, 2024 pm 07:18 PM
Wie kann KI Roboter autonomer und anpassungsfähiger machen?
Jun 03, 2024 pm 07:18 PM
Im Bereich der industriellen Automatisierungstechnik gibt es zwei aktuelle Hotspots, die kaum zu ignorieren sind: Künstliche Intelligenz (KI) und Nvidia. Ändern Sie nicht die Bedeutung des ursprünglichen Inhalts, optimieren Sie den Inhalt, schreiben Sie den Inhalt neu, fahren Sie nicht fort: „Darüber hinaus sind beide eng miteinander verbunden, da Nvidia nicht auf seine ursprüngliche Grafikverarbeitungseinheit (GPU) beschränkt ist ) erweitert es seine GPU. Die Technologie erstreckt sich auf den Bereich der digitalen Zwillinge und ist eng mit neuen KI-Technologien verbunden. „Vor kurzem hat NVIDIA eine Zusammenarbeit mit vielen Industrieunternehmen geschlossen, darunter führende Industrieautomatisierungsunternehmen wie Aveva, Rockwell Automation und Siemens und Schneider Electric sowie Teradyne Robotics und seine Unternehmen MiR und Universal Robots. Kürzlich hat Nvidia gesammelt
 Nach 2 Monaten kann der humanoide Roboter Walker S Kleidung falten
Apr 03, 2024 am 08:01 AM
Nach 2 Monaten kann der humanoide Roboter Walker S Kleidung falten
Apr 03, 2024 am 08:01 AM
Herausgeber des Machine Power Report: Wu Xin Die heimische Version des humanoiden Roboters + eines großen Modellteams hat zum ersten Mal die Betriebsaufgabe komplexer flexibler Materialien wie das Falten von Kleidung abgeschlossen. Mit der Enthüllung von Figure01, das das multimodale große Modell von OpenAI integriert, haben die damit verbundenen Fortschritte inländischer Kollegen Aufmerksamkeit erregt. Erst gestern veröffentlichte UBTECH, Chinas „größter Bestand an humanoiden Robotern“, die erste Demo des humanoiden Roboters WalkerS, der tief in das große Modell von Baidu Wenxin integriert ist und einige interessante neue Funktionen aufweist. Jetzt sieht WalkerS, gesegnet mit Baidu Wenxins großen Modellfähigkeiten, so aus. Wie Figure01 bewegt sich WalkerS nicht umher, sondern steht hinter einem Schreibtisch, um eine Reihe von Aufgaben zu erledigen. Es kann menschlichen Befehlen folgen und Kleidung falten
 Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Der erste Roboter erscheint, der menschliche Aufgaben autonom erledigt, mit fünf flexiblen Fingern und übermenschlicher Geschwindigkeit, und große Modelle unterstützen das Training im virtuellen Raum
Mar 11, 2024 pm 12:10 PM
Diese Woche gab FigureAI, ein Robotikunternehmen, an dem OpenAI, Microsoft, Bezos und Nvidia beteiligt sind, bekannt, dass es fast 700 Millionen US-Dollar an Finanzmitteln erhalten hat und plant, im nächsten Jahr einen humanoiden Roboter zu entwickeln, der selbstständig gehen kann. Und Teslas Optimus Prime hat immer wieder gute Nachrichten erhalten. Niemand zweifelt daran, dass dieses Jahr das Jahr sein wird, in dem humanoide Roboter explodieren. SanctuaryAI, ein in Kanada ansässiges Robotikunternehmen, hat kürzlich einen neuen humanoiden Roboter auf den Markt gebracht: Phoenix. Beamte behaupten, dass es viele Aufgaben autonom und mit der gleichen Geschwindigkeit wie Menschen erledigen kann. Pheonix, der weltweit erste Roboter, der Aufgaben autonom in menschlicher Geschwindigkeit erledigen kann, kann jedes Objekt sanft greifen, bewegen und elegant auf der linken und rechten Seite platzieren. Es kann Objekte autonom identifizieren
 Zehn humanoide Roboter gestalten die Zukunft
Mar 22, 2024 pm 08:51 PM
Zehn humanoide Roboter gestalten die Zukunft
Mar 22, 2024 pm 08:51 PM
Die folgenden 10 humanoiden Roboter prägen unsere Zukunft: 1. ASIMO: ASIMO wurde von Honda entwickelt und ist einer der bekanntesten humanoiden Roboter. Mit einer Höhe von 1,20 m und einem Gewicht von 50 kg ist ASIMO mit fortschrittlichen Sensoren und künstlichen Intelligenzfunktionen ausgestattet, die es ihm ermöglichen, sich in komplexen Umgebungen zurechtzufinden und mit Menschen zu interagieren. Aufgrund seiner Vielseitigkeit eignet sich ASIMO für eine Vielzahl von Aufgaben, von der Unterstützung von Menschen mit Behinderungen bis hin zur Durchführung von Präsentationen bei Veranstaltungen. 2. Pepper: Pepper wurde von Softbank Robotics entwickelt und möchte ein sozialer Begleiter für Menschen sein. Mit seinem ausdrucksstarken Gesicht und der Fähigkeit, Emotionen zu erkennen, kann Pepper an Gesprächen teilnehmen, im Einzelhandel helfen und sogar pädagogische Unterstützung leisten. Pfeffer
 Der Kehr- und Wischroboter Cloud Whale Xiaoyao 001 hat ein „Gehirn'! |. Erfahrung
Apr 26, 2024 pm 04:22 PM
Der Kehr- und Wischroboter Cloud Whale Xiaoyao 001 hat ein „Gehirn'! |. Erfahrung
Apr 26, 2024 pm 04:22 PM
Kehr- und Wischroboter gehören in den letzten Jahren zu den beliebtesten Smart-Home-Geräten bei Verbrauchern. Die damit verbundene Bequemlichkeit der Bedienung oder sogar die Notwendigkeit einer Bedienung ermöglicht es faulen Menschen, ihre Hände frei zu haben, was es den Verbrauchern ermöglicht, sich von der täglichen Hausarbeit zu „befreien“ und mehr Zeit mit den Dingen zu verbringen, die sie in getarnter Form genießen. Aufgrund dieser Begeisterung stellen fast alle Haushaltsgerätemarken auf dem Markt ihre eigenen Kehr- und Wischroboter her, was den gesamten Markt für Kehr- und Wischroboter sehr lebendig macht. Allerdings wird die schnelle Expansion des Marktes unweigerlich eine versteckte Gefahr mit sich bringen: Viele Hersteller werden die Taktik des Maschinenmeeres nutzen, um schnell mehr Marktanteile zu erobern, was zu vielen neuen Produkten ohne Upgrade-Punkte führen wird Es handelt sich um „Matroschka“-Modelle. Keine Übertreibung. Allerdings sind das nicht alle Kehr- und Wischroboter
 Der humanoide Roboter kann zaubern. Lassen Sie das Programmteam der Frühlingsfest-Gala mehr erfahren
Feb 04, 2024 am 09:03 AM
Der humanoide Roboter kann zaubern. Lassen Sie das Programmteam der Frühlingsfest-Gala mehr erfahren
Feb 04, 2024 am 09:03 AM
Roboter haben im Handumdrehen gelernt, zu zaubern? Es war zu sehen, dass es zuerst den Wasserlöffel auf dem Tisch aufhob und damit dem Publikum bewies, dass nichts darin war ... Dann nahm es den eiähnlichen Gegenstand in seine Hand und stellte den Wasserlöffel zurück auf den Tisch und begann „einen Zauber zu wirken“... …Gerade als es den Wasserlöffel wieder aufhob, geschah ein Wunder. Das ursprünglich hineingelegte Ei verschwand und das Ding, das heraussprang, verwandelte sich in einen Basketball ... Schauen wir uns noch einmal die fortlaufenden Aktionen an: △ Diese Animation zeigt eine Reihe von Aktionen mit doppelter Geschwindigkeit und läuft nur durch Zuschauen reibungslos ab Das Video kann wiederholt mit 0,5-facher Geschwindigkeit verstanden werden. Schließlich habe ich die Hinweise entdeckt: Wenn meine Handgeschwindigkeit schneller wäre, könnte ich es möglicherweise vor dem Feind verbergen. Einige Internetnutzer beklagten, dass die magischen Fähigkeiten des Roboters sogar noch höher seien als ihre eigenen: Mag war derjenige, der diese Magie für uns ausgeführt hat.
 Amerikanische Universität eröffnet „The Legend of Zelda: Tears of the Kingdom'-Ingenieurwettbewerb für Studenten zum Bau von Robotern
Nov 23, 2023 pm 08:45 PM
Amerikanische Universität eröffnet „The Legend of Zelda: Tears of the Kingdom'-Ingenieurwettbewerb für Studenten zum Bau von Robotern
Nov 23, 2023 pm 08:45 PM
„The Legend of Zelda: Tears of the Kingdom“ wurde zum am schnellsten verkauften Nintendo-Spiel der Geschichte. Zonav Technology brachte nicht nur verschiedene „Zelda Creator“-Community-Inhalte mit, sondern wurde auch zum neuen Ingenieurstudiengang der Vereinigten Staaten von Maryland (UMD). Rewrite: The Legend of Zelda: Tears of the Kingdom ist eines der am schnellsten verkauften Spiele von Nintendo aller Zeiten. Zonav Technology bietet nicht nur umfangreiche Community-Inhalte, sondern ist auch Teil des neuen Ingenieurstudiengangs an der University of Maryland. In diesem Herbst eröffnete Associate Professor Ryan D. Sochol von der University of Maryland einen Kurs mit dem Titel „.
