
 Technologie-Peripheriegeräte
KI
Die neueste Stanford-Forschung erinnert uns daran, nicht zu sehr auf die Entstehungsfähigkeit großer Modelle zu vertrauen, da diese nur das Ergebnis der metrischen Auswahl ist.
Technologie-Peripheriegeräte
KI
Die neueste Stanford-Forschung erinnert uns daran, nicht zu sehr auf die Entstehungsfähigkeit großer Modelle zu vertrauen, da diese nur das Ergebnis der metrischen Auswahl ist.
Die neueste Stanford-Forschung erinnert uns daran, nicht zu sehr auf die Entstehungsfähigkeit großer Modelle zu vertrauen, da diese nur das Ergebnis der metrischen Auswahl ist.

„Seien Sie nicht zu abergläubisch, was die Entstehung großer Modelle angeht. Wo gibt es so viele Wunder auf der Welt?“ Forscher der Stanford University fanden heraus, dass die Entstehung großer Modelle stark mit den Bewertungsindikatoren der Aufgabe zusammenhängt ist nicht das grundlegende Verhalten des Modells unter bestimmten Aufgaben und Maßstäben. Nach dem Wechsel zu einigen kontinuierlicheren und glatteren Indikatoren wird das Emergenzphänomen weniger offensichtlich und näher an der Linearität sein.
Da Forscher kürzlich beobachtet haben, dass große Sprachmodelle (LLMs) wie GPT, PaLM und LaMDA bei verschiedenen Aufgaben sogenannte „emergente Fähigkeiten“ aufweisen können, hat dieser Begriff in diesem Bereich große Popularität erlangt Maschinelles Lernen. Große Aufmerksamkeit:
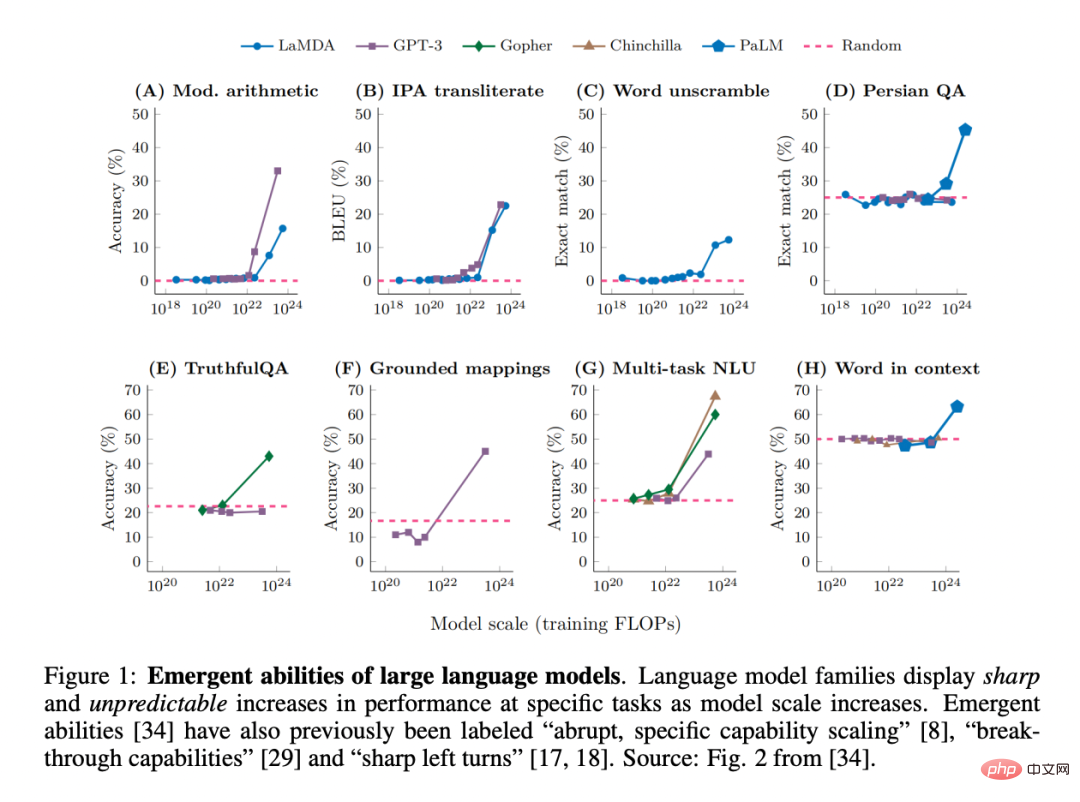
Tatsächlich standen die sich abzeichnenden Eigenschaften komplexer Systeme schon immer im Mittelpunkt der Forschung in der Physik, Biologie, Mathematik und anderen Disziplinen.
Ein erwähnenswerter Punkt ist, dass der Nobelpreisträger P.W. Anderson „More Is Different“ vorgeschlagen hat. Diese Ansicht besagt, dass mit zunehmender Systemkomplexität neue Eigenschaften entstehen können, auch wenn sie nicht (leicht oder überhaupt) aus einem präzisen quantitativen Verständnis der mikroskopischen Details des Systems vorhergesagt werden können.
Wie definiert man „Emergenz“ im Bereich großer Modelle? Umgangssprachlich wird dies so ausgedrückt: „Fähigkeiten, die in Modellen im kleinen Maßstab nicht vorhanden sind, in Modellen im großen Maßstab jedoch vorhanden sind“ und daher nicht durch einfache Extrapolation von Leistungsverbesserungen aus Modellen im kleinen Maßstab vorhergesagt werden können.
Diese neue Fähigkeit wurde möglicherweise erstmals in der GPT-3-Familie entdeckt. Einige spätere Arbeiten unterstrichen dieses Ergebnis: „Während die Modellleistung auf allgemeiner Ebene vorhersehbar ist, zeigt sich ihre Leistung bei bestimmten Aufgaben manchmal in einem Ausmaß, das ziemlich unvorhersehbar ist.“ Tatsächlich sind diese neu entstehenden Fähigkeiten so überraschend, dass die „plötzliche, spezifische Erweiterung der Fähigkeiten“ als eines der beiden prägendsten Merkmale des LLM genannt wurde. Darüber hinaus werden auch Begriffe wie „Durchbruchsfähigkeiten“ und „scharfe Linkskurven“ verwendet.
Zusammenfassend können wir zwei entscheidende Merkmale der Emergenzfähigkeit von LLM identifizieren:
1 Acuity scheint nur ein sofortiger Übergang zu sein;
2 . Unvorhersehbarkeit, Übergänge innerhalb scheinbar unvorhersehbarer Modellmaßstäbe.
In der Zwischenzeit bleiben einige Fragen unbeantwortet: Was steuert, welche Fähigkeiten entstehen? Was steuert die Entstehung von Fähigkeiten? Wie können wir dafür sorgen, dass wünschenswerte Fähigkeiten schneller entstehen und sicherstellen, dass weniger wünschenswerte Fähigkeiten nie entstehen?
Diese Fragen hängen eng mit der Sicherheit und Ausrichtung künstlicher Intelligenz zusammen, denn neue Fähigkeiten sagen voraus, dass größere Modelle eines Tages ohne Vorwarnung die Kontrolle über gefährliche Fähigkeiten erlangen könnten, was Menschen nicht wollen.
In einem aktuellen Artikel stellten Forscher der Stanford University die Behauptung in Frage, dass LLM über neue Fähigkeiten verfügt.

Artikel: https://arxiv.org/pdf/2304.15004.pdf
Konkret geht es hier um die Modellausgabe als Funktion der Modellgröße in einer bestimmten Aufgabe unvorhersehbare Veränderungen, die auftreten.
Ihre Skepsis basiert auf der Beobachtung, dass Modelle nur dann auftauchend zu sein scheinen, wenn sie auf einem beliebigen Maß der Fehlerrate pro Token des Modells nichtlinear oder diskontinuierlich skalieren. Beispielsweise wurden in der BIG-Bench-Aufgabe >92 % der neuen Fähigkeiten unter diesen beiden Metriken entwickelt:

Dies eröffnet die Möglichkeit einer anderen Erklärung für den Ursprung der Emergenzfähigkeit von LLMs: Obwohl die Fehlerrate pro Token der Modellfamilie mit zunehmender Modellgröße gleichmäßig, nachhaltig und vorhersehbar sein wird, ändert sich der Boden , aber scheinbar scharfe und unvorhersehbare Veränderungen können durch die von den Forschern gewählte Messmethode verursacht werden.
Mit anderen Worten, die Emergenzfähigkeit kann eine Fata Morgana sein, vor allem weil die Forscher eine Methode gewählt haben, die die Fehlerrate pro Token nichtlinear oder diskontinuierlich ändert. Dies liegt zum Teil daran, dass zu wenige Testdaten vorliegen, um die Leistung kleinerer Modelle genau abzuschätzen (was dazu führt, dass kleinere Modelle den Eindruck erwecken, dass sie die Aufgabe überhaupt nicht erfüllen können), und teilweise daran, dass zu wenige groß angelegte Modelle evaluiert werden.Um diese Erklärung zu veranschaulichen, verwendeten die Forscher sie als einfaches mathematisches Modell und zeigten, wie sie quantitativ reproduziert werden kann, um die Emergenzfähigkeit von LLM zu unterstützen . Wir haben diese Erklärung dann auf drei komplementäre Arten getestet:
1 Unter Verwendung der Modellfamilie InstructGPT [24]/GPT-3 [3] gemäß der Alternativhypothese , testet und bestätigt drei Vorhersagen.
2 Führte eine Metaanalyse einiger früherer Ergebnisse durch und zeigte, dass im Bereich der Familientripel mit Aufgabenmetrikmodellen die Fähigkeiten, die auftauchen, nur in einigen Modellen vorkommen Familien (Spalten) für Metriken, nicht für Aufgaben. Die Studie zeigt außerdem, dass bei einer festen Modellausgabe eine Änderung der Metrik dazu führt, dass das Emergenzphänomen verschwindet.
3. Bewusstes Induzieren neuer Fähigkeiten über mehrere Sehaufgaben hinweg (was noch nie zuvor demonstriert wurde) in tiefen neuronalen Netzen verschiedener Architekturen, um so etwas wie „Wie metrische Entscheidungen scheinbar induzieren“ zu zeigen neue Fähigkeiten.
Test 1: GPT/GPT-3-Modellserienanalyse anweisen
Der Forscher wählte das GPT-Serienmodell für die weitere Analyse, weil es so ist öffentlich abfragbar, im Gegensatz zu anderen Modellreihen (z. B. PaLM, LaMDA, Gopher, Chinchilla). In früheren Untersuchungen wurde angenommen, dass die GPT-Modellfamilie neue Fähigkeiten bei ganzzahligen Rechenaufgaben aufweist. Auch hier wählten die Forscher die Aufgabe der Ganzzahlarithmetik.
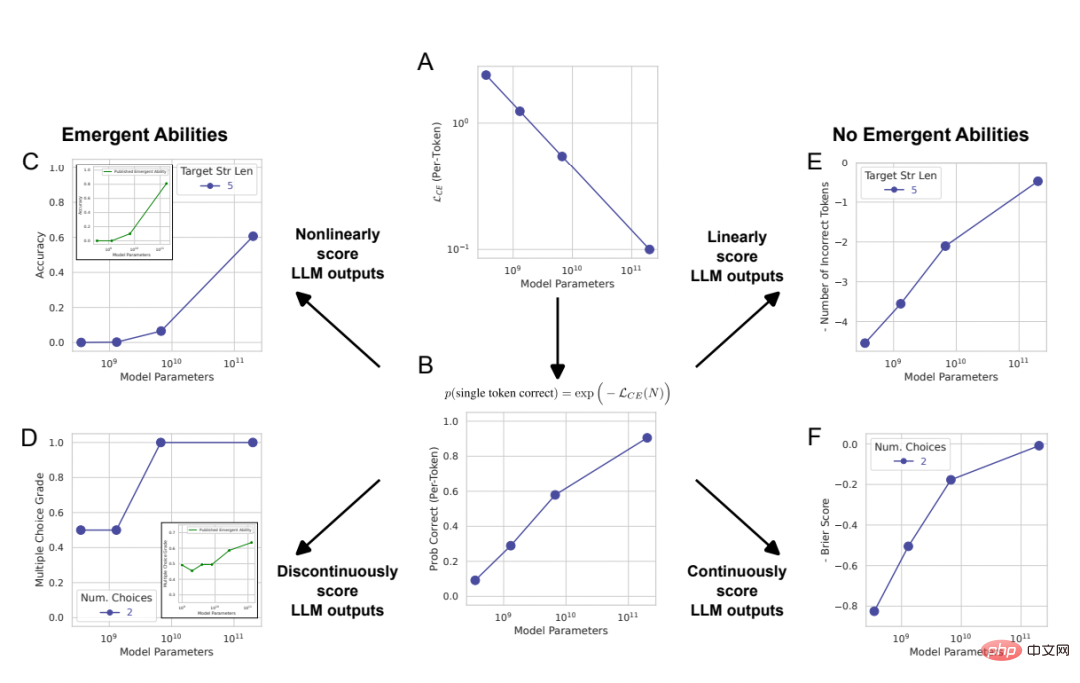
# 🎜 🎜#Abbildung 2: Die Emergenzfähigkeit großer Sprachmodelle ist eine Schöpfung der Analyse der Forscher und keine grundlegende Änderung der Modellausgabe, wenn sich der Maßstab ändert. Wie in Abschnitt 2 mathematisch und grafisch erläutert, sagt die von den Forschern vorgeschlagene alternative Erklärung drei Ergebnisse voraus: 1 Wenn die Metrik von geändert wird Wenn Sie von einer nichtlinearen/diskontinuierlichen Metrik (Abbildung 2CD) zu einer linearen/kontinuierlichen Metrik (Abbildung 2EF) wechseln, sollte es zu gleichmäßigen, kontinuierlichen und vorhersehbaren Leistungsverbesserungen kommen.
2 Wenn bei nichtlinearen Messungen die Auflösung der gemessenen Modellleistung durch Erhöhen der Größe des Testdatensatzes verbessert wird, sollte das Modell geglättet, kontinuierlich, vorhersehbare Verbesserung, und der Anteil dieser Verbesserung entspricht den vorhersehbaren nichtlinearen Effekten der gewählten Metrik.
3. Unabhängig von der verwendeten Metrik sollte eine Erhöhung der Ziel-Stringlänge einen Einfluss auf die Modellleistung als Funktion der Ziel-Stringlänge 1 haben: Die Genauigkeit beträgt nahezu geometrische Funktion, und der Token-Bearbeitungsabstand ist eine nahezu quasilineare Funktion.
Um diese drei Vorhersageschlussfolgerungen zu testen, sammelten die Forscher die String-Ausgabeergebnisse der Modelle der InstructGPT/GPT-3-Serie für zwei Rechenaufgaben: mithilfe der OpenAI-API Führt eine Multiplikation mit zwei Stichproben zwischen zwei zweistelligen Ganzzahlen und eine Addition mit zwei Stichproben zwischen zwei vierstelligen Ganzzahlen durch. Abbildung 3: Mit zunehmender Modellgröße können geänderte Metriken die Leistung verbessern und zu reibungslosen, kontinuierlichen und vorhersehbaren Änderungen führen.
Von links nach rechts: mathematisches Modell, 2 zweistellige Ganzzahlmultiplikationsaufgaben, 2 vierstellige Ganzzahladditionsaufgaben. Die obige Grafik zeigt die Modellleistung, die mithilfe einer nichtlinearen Metrik wie der Genauigkeit gemessen wird. Sie können sehen, dass die Leistung der InstructGPT/GPT-3-Modellfamilie bei längeren Ziellängen schärfer und weniger vorhersehbar erscheint. Die folgende Abbildung zeigt die Modellleistung, die anhand einer linearen Metrik (z. B. der Token-Bearbeitungsentfernung) gemessen wird. Diese Modellreihe zeigt reibungslose und vorhersehbare Leistungsverbesserungen, die laut Forschern entstehen.
Vorhersage: Emergente Fähigkeit verschwindet unter linearer Messung
Ein Bei diesen beiden ganzzahligen Multiplikations- und Additionsaufgaben weist die GPT-Modellfamilie neue arithmetische Fähigkeiten auf, wenn die Länge der Zielzeichenfolge 4 oder 5 Ziffern beträgt und die Leistung anhand der Genauigkeit gemessen wird (obere Reihe von Abbildung 3). Wenn Sie jedoch eine Metrik von nichtlinear auf linear ändern und dabei die Ausgabe des Modells konstant halten, verbessert sich die Leistung der Modellfamilie reibungslos, kontinuierlich und vorhersehbar. Dies bestätigt die Vorhersagen der Forscher und legt nahe, dass die Ursache für Schärfe und Unsicherheit in der von den Forschern gewählten Metrik liegt und nicht in Änderungen in der Modellausgabe. Es ist auch ersichtlich, dass bei Verwendung der Token-Bearbeitungsentfernung die Länge der Zielzeichenfolge von 1 auf 5 erhöht wird. Es ist vorhersehbar, dass die Leistung dieser Modellreihe abnimmt und der Abwärtstrend nahezu linear ist. was mit der dritten und ersten Hälfte der Prognose übereinstimmt.
Vorhersage: Die aufkommende Macht verschwindet mit dem Aufkommen höher aufgelöster Beurteilungen
#🎜 🎜##🎜 🎜#Dann kommt die zweite Vorhersage: Auch bei nichtlinearen Maßen wie der Genauigkeit wird die Genauigkeit kleinerer Modelle nicht Null sein, sondern eher ein Wert ungleich Null über dem Zufall, proportional zu Wählen Sie „Genauigkeit verwenden“ als entsprechende Metrik aus. Um die Auflösung zu verbessern und die Modellgenauigkeit noch genauer abzuschätzen, generierten die Forscher auch einige andere Testdaten und stellten dann fest, dass alle InstructGPT/GPT-3 unabhängig davon, ob es sich um die Ganzzahlmultiplikationsaufgabe oder die Ganzzahladditionsaufgabe handelte Serie Alle Modelle erreichten eine positive Genauigkeit, die den Zufall übertraf (Abbildung 4). Dies bestätigt die zweite Vorhersage. Es ist ersichtlich, dass mit zunehmender Länge der Zielzeichenfolge die Genauigkeit nahezu geometrisch mit der Länge der Zielzeichenfolge abnimmt, was mit der zweiten Hälfte der dritten Vorhersage übereinstimmt. Diese Ergebnisse zeigen auch, dass die von den Forschern gewählte Genauigkeit einige (ungefähre) Effekte hat, die wir erwarten sollten, nämlich einen nahezu geometrischen Zerfall mit der Ziellänge.
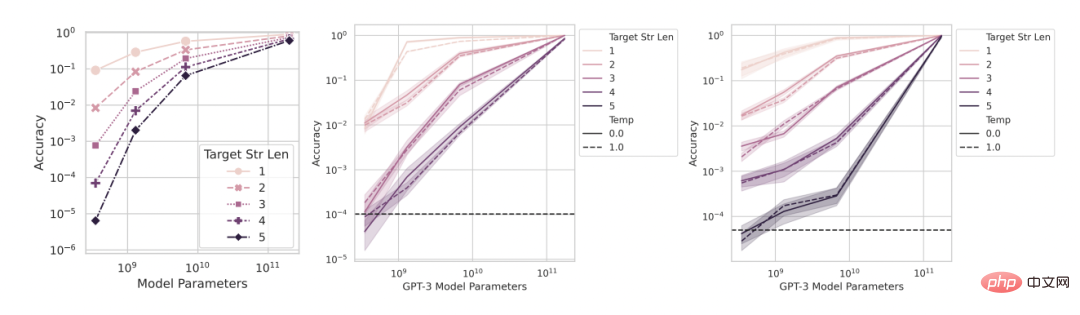
# 🎜 🎜#Abbildung 4: Die Verwendung von mehr Testdatensätzen führte zu besseren Genauigkeitsschätzungen, die zeigten, dass Leistungsänderungen reibungslos, kontinuierlich und vorhersehbar waren. Von links nach rechts: mathematisches Modell, 2 zweistellige Ganzzahlmultiplikationsaufgaben, 2 vierstellige Ganzzahladditionsaufgaben. Die Verbesserung der Auflösung durch die Generierung weiterer Testdaten zeigt, dass die Leistung der Modelle der InstructGPT/GPT-3-Serie selbst bei Genauigkeitsmessungen über jeden Zufall erhaben ist und dass die Verbesserung beider aufkommenden Fähigkeiten reibungslos erfolgt. Die Ergebnisse dieser beiden aufkommenden Fähigkeiten sind kontinuierlich und vorhersehbar sind, qualitativ mit mathematischen Modellen übereinstimmen.
Test 2: Metaanalyse der Modellentstehung
Da die Modelle der GPT-Serie öffentlich zur Abfrage verfügbar sind, können sie analysiert werden. Andere Modelle, von denen einige behaupten, dass sie über neue Fähigkeiten verfügen (z. B. PaLM, Chinchilla, Gopher), sind jedoch nicht öffentlich verfügbar, und die von ihnen generierten Ergebnisse sind nicht öffentlich, was bedeutet, dass Forscher nur begrenzte Möglichkeiten zur Analyse veröffentlichter Ergebnisse haben. Die Forscher gaben zwei Vorhersagen ab, die auf ihren eigenen Alternativhypothesen basierten:
- Erstens auf der „Bevölkerungsebene“ des Tripletts „Aufgabenmetrik-Modellreihe“, wenn Sie sich für die Verwendung nichtlinearer und/oder diskontinuierlicher Metriken entscheiden, um die Modellleistung zu bewerten, das Modell sollte Emergenzfähigkeiten bei der Aufgabe nachweisen.
- Zweitens gilt für das spezifische „Aufgaben-Metrik-Modell-Serie“-Triplett, das neue Fähigkeiten aufweist, wenn die Metrik in eine lineare und/oder kontinuierliche Metrik geändert wird Die entstehende Fähigkeit sollte beseitigt werden.
Um diese beiden Hypothesen zu testen, untersuchten die Forscher die Fähigkeiten, die angeblich in der BIG-Bench-Evaluierungssuite aufgrund der Der Benchmark ist öffentlich verfügbar und gut dokumentiert.
Vorhersage: Neue Fähigkeiten sollten hauptsächlich bei nichtlinearen/diskontinuierlichen Maßnahmen auftreten
#🎜🎜 ##🎜 🎜#Um die erste Vorhersage zu testen, analysierten die Forscher, anhand welcher Indikatoren verschiedene „Aufgaben-Modell-Serien“-Paarungen über neue Fähigkeiten verfügen würden. Um festzustellen, ob ein Tripel aus einer „Aufgaben-Metrik-Modell-Familie“ wahrscheinlich neue Fähigkeiten aufweist, haben sie sich die Definition ausgeliehen, die in der Arbeit „Beyond the imitation game: Quantifying and extrapolating the Capabilities of Language Models“ eingeführt wurde. Lassen Sie y_i ∈ R die Modellleistung darstellen, wenn die Modellgröße x_i ∈ R ist, und machen Sie x_i Als Ergebnis stellten die Forscher fest, dass die meisten der von BIG-Bench verwendeten Metriken keine „Aufgabenmodellreihe“ aufwiesen, die Emergenzfähigkeit zeigte: Von den 39 bevorzugten BIG-Bench-Metriken Die meisten fünf zeigten neue Fähigkeiten (Abbildung 5A). Die meisten dieser 5 sind nichtlinear/nichtkontinuierlich, wie z. B. exakte Zeichenfolgenübereinstimmung, Multiple-Choice-Ranking und ROUGE-L-Summe. Es ist erwähnenswert, dass BIG-Bench normalerweise mehrere Maßnahmen zur Bewertung der Aufgabenleistung des Modells verwendet. Der Mangel an Emergenzfähigkeit bei anderen Maßnahmen zeigt, dass die Emergenzfähigkeit nicht auftritt, wenn andere Maßnahmen zur Bewertung der Modellausgabe verwendet werden. .Da der Emergenzwert nur die Emergenzfähigkeit angibt, analysierten die Forscher die manuell beschriftete „Aufgabenmessung“ im Artikel „137 Emergenzfähigkeiten großer Sprachmodelle“ weiter Triplett „-Modellreihe“. Manuell kommentierte Daten zeigten, dass nur 4 der 39 Maßnahmen aufkommende Fähigkeiten aufwiesen (Abbildung 5B), und zwei von ihnen machten mehr als 92 % der beanspruchten aufkommenden Fähigkeiten aus (Abbildung 5C). Mehrfachauswahl-Binning und exakte Zeichenfolgenübereinstimmung. Das Multiple-Choice-Binning ist nicht kontinuierlich und die exakte Zeichenfolgenübereinstimmung ist nicht linear (die Änderung der Ziellängenmetrik ist nahezu geometrisch). Insgesamt deuten diese Ergebnisse darauf hin, dass neue Fähigkeiten nur bei einer sehr kleinen Anzahl nichtlinearer und/oder diskontinuierlicher Maßnahmen auftreten. 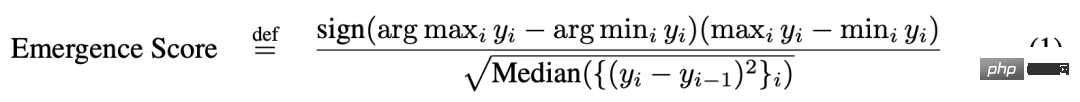
Vorhersage: Neue Fähigkeiten sollten eliminiert werden, wenn nichtlineare/diskontinuierliche Maßnahmen ersetzt werden
# 🎜🎜# Für die zweite Vorhersage analysierten die Forscher die Emergenzfähigkeit manueller Anmerkungen in dem oben zitierten Artikel. Sie konzentrierten sich auf die LaMDA-Familie, da deren Ergebnisse über BIG-Bench verfügbar sind, während dies bei Ausgaben anderer Modellfamilien nicht der Fall ist. Unter den veröffentlichten LaMDA-Modellen verfügt das kleinste über 2 Milliarden Parameter, aber viele LaMDA-Modelle in BIG-Bench sind viel kleiner, und die Forscher gaben an, dass sie bei der Analyse nicht berücksichtigt wurden, da sie den Ursprung dieser kleineren Modelle nicht bestimmen konnten . In der Analyse identifizierten die Forscher Aufgaben, bei denen LaMDA neue Fähigkeiten auf der hierarchischen Multiple-Choice-Messung zeigte, und fragten dann: Kann LaMDA bei Verwendung einer anderen BIG-Bench-Maßnahme, dem Brier-Score, neue Fähigkeiten demonstrieren? Der Brier-Score ist eine Reihe streng korrekter Bewertungsregeln, die die Vorhersage sich gegenseitig ausschließender Ergebnisse messen. Für die Vorhersage eines binären Ergebnisses wird der Brier-Score auf den mittleren quadratischen Fehler zwischen dem Ergebnis und seiner vorhergesagten Wahrscheinlichkeitsmasse vereinfacht. Die Forscher fanden heraus, dass die Emergenzfähigkeit von LaMDA verschwindet, wenn das nicht kontinuierliche metrische Multi-Choice-Ranking zum kontinuierlichen metrischen Brier-Score wird (Abbildung 6). Dies verdeutlicht weiter, dass die Ursache der Emergenzfähigkeit nicht in der wesentlichen Änderung des Modellverhaltens mit zunehmendem Maßstab liegt, sondern in der Verwendung diskontinuierlicher Maßnahmen. Test 3: DNN dazu bringen, Emergenzfähigkeit zu haben , um dies zu beweisen, zeigten sie Wie man unterschiedliche Architekturen (vollständig verbunden, Faltung, Selbstaufmerksamkeit) herstellt, damit tiefe neuronale Netze neue Fähigkeiten erzeugen. Die Forscher konzentrierten sich hier aus zwei Gründen auf visuelle Aufgaben. Erstens konzentriert man sich derzeit auf die entstehenden Fähigkeiten groß angelegter Sprachmodelle, da bei visuellen Modellen noch kein plötzlicher Wechsel von der Fähigkeit „kein Modell“ zu „ja“ beobachtet wurde. Zweitens können einige Vision-Aufgaben mit Netzwerken bescheidener Größe gelöst werden, sodass Forscher eine vollständige Familie von Modellen über mehrere Größenordnungen aufbauen können. Das Faltungsnetzwerk entstand mit der Fähigkeit, handschriftliche MNIST-Ziffern zu klassifizieren Die Forscher veranlassten zunächst die Implementierung der LeNet-Faltungs-Neuronalen Netzwerkreihe mit der Fähigkeit zur Klassifizierung, und der Trainingsdatensatz war der MNIST-Datensatz handgeschriebener Ziffern. Diese Serie zeigt einen sanften Anstieg der Testgenauigkeit mit zunehmender Anzahl von Parametern (Abbildung 7B). Um die Genauigkeitsmetrik zu simulieren, die in Veröffentlichungen zur Emergenz verwendet wird, wird hier die Teilmengengenauigkeit verwendet: Wenn das Netzwerk K Daten aus K (unabhängigen) Testdaten korrekt klassifiziert, dann beträgt die Teilmengengenauigkeit des Netzwerks 1, andernfalls 0. Basierend auf dieser Genauigkeitsdefinition zeigt diese Modellfamilie mit zunehmendem K von 1 auf 5 die Fähigkeit, den MNIST-Ziffernsatz korrekt zu klassifizieren, insbesondere in Kombination mit einer spärlichen Stichprobe der Modellgröße (Abb. 7c). Die neue Klassifizierungsfähigkeit dieser Faltungsreihe stimmt qualitativ mit der neuen Fähigkeit in veröffentlichten Artikeln überein, wie beispielsweise den Ergebnissen zur topografischen Kartierungsaufgabe von BIG-Bench (Abbildung 7A).
Nichtlinearer Autoencoder Emergent Reconstruction Power auf CIFAR100 Natural Image Set Um hervorzuheben, dass die Schärfe der von den Forschern gewählten Metrik für die Emergent Power verantwortlich ist, und um zu zeigen, dass diese Schärfe der Grad ist Die Forscher beschränkten sich nicht nur auf Messungen wie die Genauigkeit, sondern führten auch dazu, dass der flache (d. h. eine einzelne verborgene Schicht) nichtlineare Autoencoder, der auf dem natürlichen Bildsatz CIFAR100 trainiert wurde, die Fähigkeit erhielt, die Bildeingabe zu rekonstruieren. Zu diesem Zweck definieren sie bewusst eine neue Diskontinuitätsmetrik zur Messung der Modellfähigkeit, bei der es sich um die durchschnittliche Anzahl von Testdaten mit quadrierten Rekonstruktionsfehlern unterhalb eines festen Schwellenwerts c handelt:
wobei I (・) eine Zufallsindikatorvariable und x^n die Rekonstruktion von x_n durch den Autoencoder ist. Die Forscher untersuchten die Anzahl der Engpasseinheiten im Autoencoder und stellten fest, dass der mittlere quadratische Rekonstruktionsfehler des Netzwerks mit zunehmender Modellgröße einen sanften Abwärtstrend zeigt (Abbildung 8B), wenn jedoch die neu definierte Rekonstruktionsmetrik verwendet wird ausgewählt c. Die Fähigkeit dieser Autoencoder-Reihe, diesen Datensatz zu rekonstruieren, ist scharf und nahezu unvorhersehbar (Abbildung 8C). Dieses Ergebnis stimmt qualitativ mit der Fähigkeit überein, die in veröffentlichten Arbeiten wie der BIG-Bench-Aufgabe erzielt wird (Abbildung 8A). . Abbildung 8: Induzieren von Emergent-Rekonstruktionsfunktionen in flachen nichtlinearen Autoencodern. (A) Neue Fähigkeiten basierend auf der BIG-Bench-Aufgabe für periodische Elemente aus einem veröffentlichten Artikel. (B) Ein auf CIFAR100 trainierter flacher nichtlinearer Autoencoder weist einen gleichmäßig abnehmenden mittleren quadratischen Rekonstruktionsfehler auf. (C) Unvorhersehbare Änderungen werden mithilfe der neu definierten Rekonstruktionsmetrik (Gleichung 2) induziert. Autoregressiver Transformer mit Klassifizierungsfunktionen für den Omniglot-Zeichensatz Als nächstes kommt die neue Funktion von Transformer, die die autoregressive Methode zur Klassifizierung handgeschriebener Omniglot-Zeichen verwendet. Der von den Forschern verwendete Versuchsaufbau ist ähnlich: Das Omniglot-Bild wird zuerst durch eine Faltungsschicht eingebettet, und dann wird der Nur-Decoder-Transformer als Folge von Paaren [eingebettetes Bild, Bildkategoriebezeichnung] eingegeben und das Trainingsziel dafür festgelegt Transformer soll das Omniglot-Kategorieetikett vorhersagen. Der Forscher hat die Bildklassifizierungsleistung an einer Folge der Länge L ∈ [1, 5] gemessen, die auch anhand der Teilmengengenauigkeit gemessen wurde: Wenn alle L Bilder korrekt klassifiziert sind (Abbildung 9B), beträgt die Teilmengengenauigkeit 1, andernfalls 0 . Causal Transformer scheint neue Fähigkeiten bei der korrekten Klassifizierung handschriftlicher Omniglot-Zeichen zu zeigen (Abbildung 9C), ein Ergebnis, das qualitativ mit den neuen Fähigkeiten in veröffentlichten Artikeln übereinstimmt, wie zum Beispiel das umfassende Sprachverständnis für mehrere Aufgaben (Abbildung 9A). 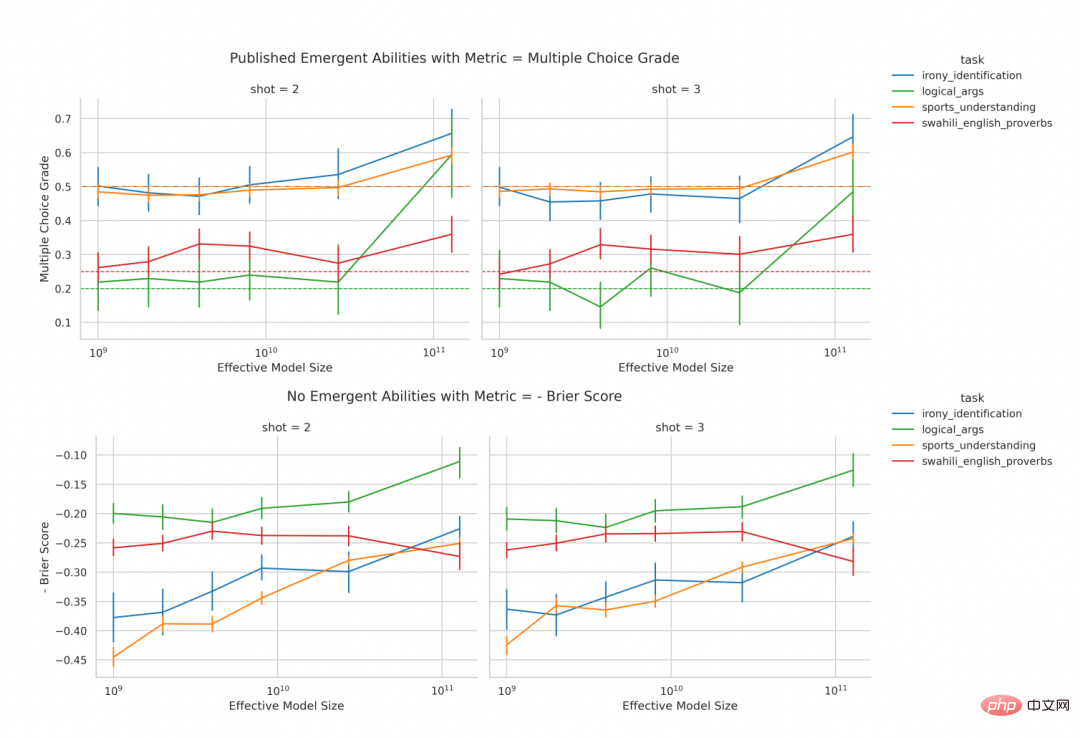
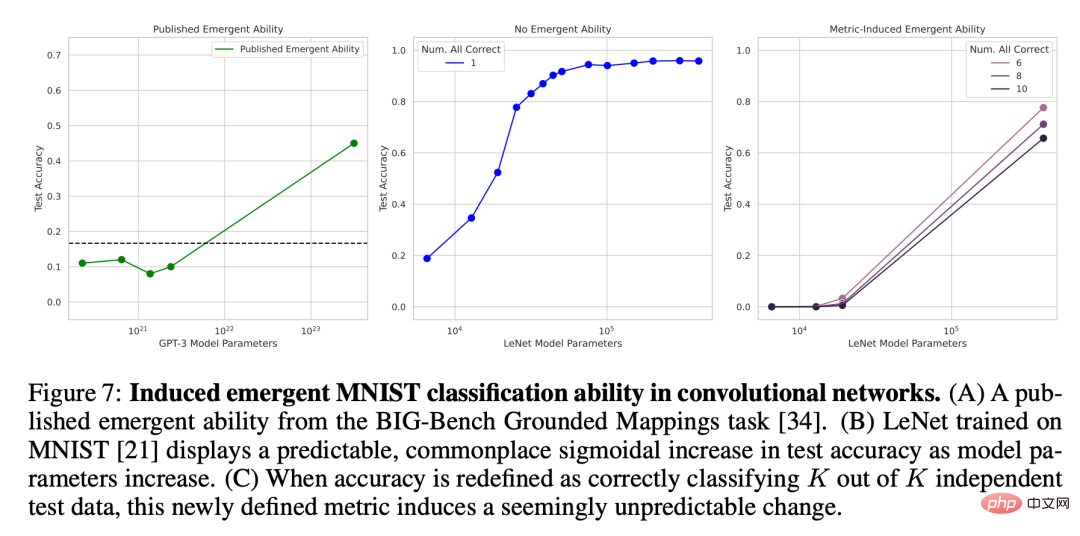
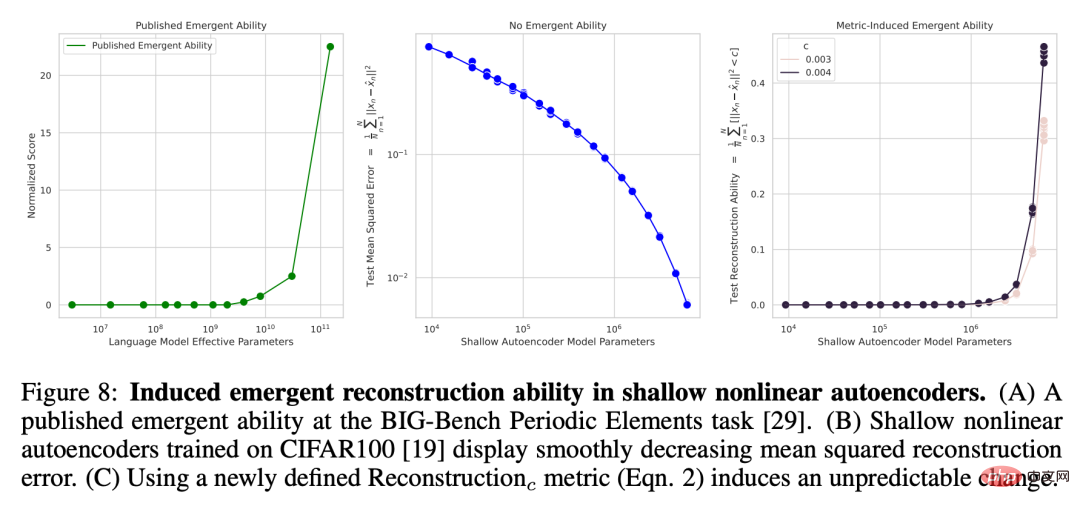
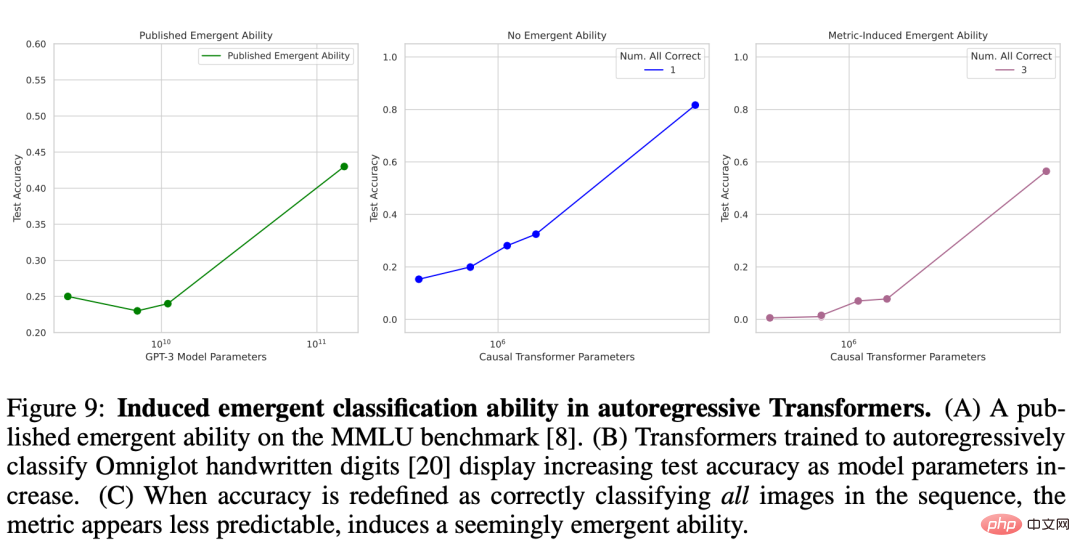
Abbildung 9: Induzieren entstehender Klassifizierungsfunktionen in einem autoregressiven Transformer. (A) Neue Fähigkeiten basierend auf dem MMLU-Benchmark in einem veröffentlichten Artikel. (B) Mit zunehmenden Modellparametern steigt auch die Testgenauigkeit von Transformer, der die autoregressive Methode zur Klassifizierung handschriftlicher Omniglot-Ziffern verwendet. (C) Wenn Genauigkeit als korrekte Klassifizierung aller Bilder in einer Sequenz neu definiert wird, ist die Metrik schwieriger vorherzusagen, was auf die Induktion von Emergenzfähigkeit hinzuweisen scheint.
Das obige ist der detaillierte Inhalt vonDie neueste Stanford-Forschung erinnert uns daran, nicht zu sehr auf die Entstehungsfähigkeit großer Modelle zu vertrauen, da diese nur das Ergebnis der metrischen Auswahl ist.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
In diesem Artikel wird das Problem der genauen Erkennung von Objekten aus verschiedenen Blickwinkeln (z. B. Perspektive und Vogelperspektive) beim autonomen Fahren untersucht, insbesondere wie die Transformation von Merkmalen aus der Perspektive (PV) in den Raum aus der Vogelperspektive (BEV) effektiv ist implementiert über das Modul Visual Transformation (VT). Bestehende Methoden lassen sich grob in zwei Strategien unterteilen: 2D-zu-3D- und 3D-zu-2D-Konvertierung. 2D-zu-3D-Methoden verbessern dichte 2D-Merkmale durch die Vorhersage von Tiefenwahrscheinlichkeiten, aber die inhärente Unsicherheit von Tiefenvorhersagen, insbesondere in entfernten Regionen, kann zu Ungenauigkeiten führen. Während 3D-zu-2D-Methoden normalerweise 3D-Abfragen verwenden, um 2D-Features abzutasten und die Aufmerksamkeitsgewichte der Korrespondenz zwischen 3D- und 2D-Features über einen Transformer zu lernen, erhöht sich die Rechen- und Bereitstellungszeit.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
