
 Technologie-Peripheriegeräte
KI
Komprimieren Sie 26 Token in einer neuen Methode, um Platz im ChatGPT-Eingabefeld zu sparen
Technologie-Peripheriegeräte
KI
Komprimieren Sie 26 Token in einer neuen Methode, um Platz im ChatGPT-Eingabefeld zu sparen
Komprimieren Sie 26 Token in einer neuen Methode, um Platz im ChatGPT-Eingabefeld zu sparen

Bevor Sie den Text eingeben, berücksichtigen Sie die Eingabeaufforderung eines Transformer-Sprachmodells (LM) wie ChatGPT:

Mit Millionen von Benutzern und Abfragen, die jeden Tag generiert werden, verwendet ChatGPT einen Selbstaufmerksamkeitsmechanismus, um Eingabeaufforderungen zu implementieren Bei wiederholter Codierung nehmen Zeit und Speicherkomplexität quadratisch mit der Eingabelänge zu. Das Zwischenspeichern der Transformer-Aktivierung der Eingabeaufforderung verhindert eine teilweise Neuberechnung, diese Strategie verursacht jedoch immer noch erhebliche Speicher- und Speicherkosten, da die Anzahl der zwischengespeicherten Eingabeaufforderungen zunimmt. Im Maßstab kann bereits eine geringfügige Reduzierung der Eingabeaufforderungslänge zu Rechen-, Speicher- und Speichereinsparungen führen und es dem Benutzer gleichzeitig ermöglichen, mehr Inhalte in das begrenzte Kontextfenster des LM einzufügen.
Dann. Wie lassen sich die Kosten für die prompte Abwicklung senken? Ein typischer Ansatz besteht darin, das Modell so zu verfeinern oder zu destillieren, dass es sich ohne Eingabeaufforderungen ähnlich wie das Originalmodell verhält, möglicherweise unter Verwendung parametereffizienter adaptiver Methoden. Ein grundlegender Nachteil dieses Ansatzes besteht jedoch darin, dass das Modell jedes Mal für eine neue Eingabeaufforderung neu trainiert werden muss (dargestellt in der Mitte von Abbildung 1 unten).
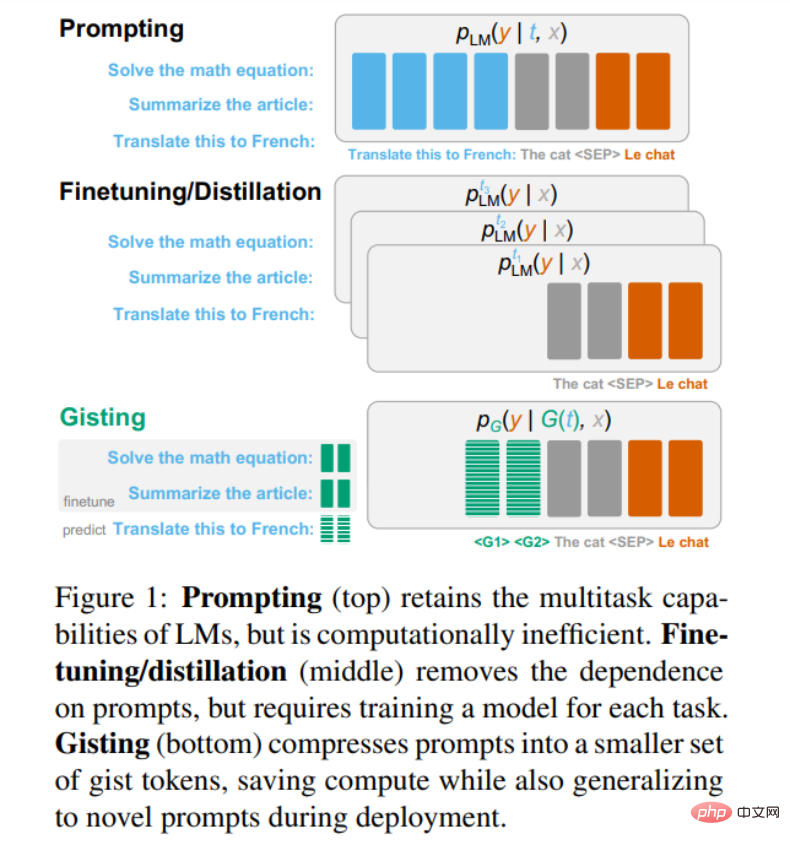
In diesem Artikel schlugen Forscher der Stanford University das Gisting-Modell vor (unten in Abbildung 1 oben), das beliebige Eingabeaufforderungen in einen Satz kleinerer virtueller „Gist“-Tokens komprimiert, ähnlich dem Präfix Fine -Tuning. Die Präfix-Feinabstimmung erfordert jedoch das Lernen des Präfixes für jede Aufgabe durch Gradientenabstieg, während Gisting eine Meta-Lernmethode verwendet, um das Gist-Präfix nur durch Eingabeaufforderungen vorherzusagen, ohne das Präfix für jede Aufgabe zu lernen. Dies amortisiert die Kosten für das Lernen von Präfixen pro Aufgabe und ermöglicht die Verallgemeinerung auf unbekannte Anweisungen ohne zusätzliche Schulung.
Da außerdem das „Gist“-Token viel kürzer ist als die vollständige Eingabeaufforderung, ermöglicht Gisting die Komprimierung, Zwischenspeicherung und Wiederverwendung der Eingabeaufforderung, um die Recheneffizienz zu verbessern.

Papieradresse: https://arxiv.org/pdf/2304.08467v1.pdf
Forscher haben eine sehr einfache Methode vorgeschlagen, um grundlegende Anweisungen zu befolgen, Modell: Simply Optimieren Sie den Befehl, fügen Sie das Gish-Token nach der Eingabeaufforderung ein, und die geänderte Aufmerksamkeitsmaske verhindert, dass das Token nach dem Gist-Token auf das Token vor dem Gist-Token verweist. Dadurch kann das Modell ohne zusätzliche Schulungskosten gleichzeitig die sofortige Komprimierung und das Befolgen von Anweisungen erlernen.
Auf dem Nur-Decoder- (LLaMA-7B) und Encoder-Decoder-LM (FLAN-T5-XXL) erreicht Gisting eine bis zu 26-fache Sofortkomprimierung und behält dabei eine ähnliche Ausgabequalität wie das Originalmodell bei. Dies führt zu einer 40-prozentigen Reduzierung der FLOPs während der Inferenz, einer Latenzbeschleunigung um 4,2 % und deutlich reduzierten Speicherkosten im Vergleich zu herkömmlichen Prompt-Caching-Methoden.
Gisting
Die Forscher beschreiben Gisting zunächst im Zusammenhang mit der Feinabstimmung von Anweisungen. Für die Anweisung nach dem Datensatz 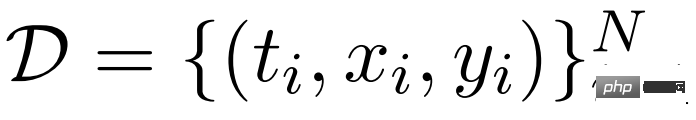
Dieses Muster der Verbindung von t und x hat jedoch Nachteile: Transformer-basiertes LM hat ein begrenztes Kontextfenster, das durch Architektur oder Rechenleistung begrenzt ist. Letzteres ist besonders schwer zu lösen, da die Selbstaufmerksamkeit quadratisch mit der Eingabelänge skaliert. Daher sind sehr lange Eingabeaufforderungen, insbesondere solche, die wiederholt wiederverwendet werden, rechenineffizient. Welche Optionen stehen zur Verfügung, um die Kosten für die Einleitung zu senken?
Ein einfacher Ansatz besteht darin, LM für eine bestimmte Aufgabe t zu optimieren, d. h. wenn ein Datensatz 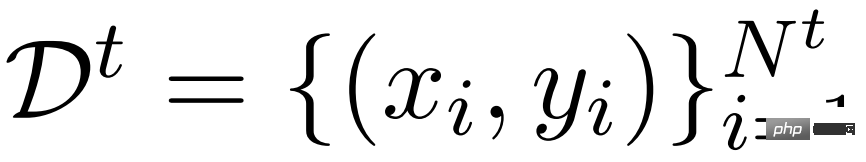
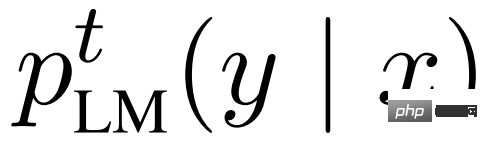
Selbst bessere, parametereffiziente Feinabstimmungsmethoden wie Präfix-/Prompt-Feinabstimmung oder Adapter können das gleiche Ziel zu deutlich geringeren Kosten erreichen als eine vollständige Feinabstimmung. Allerdings bleibt ein Problem bestehen: Mindestens ein Teil der Modellgewichte für jede Aufgabe muss gespeichert werden, und was noch wichtiger ist, für jede Aufgabe t muss der entsprechende Eingabe-/Ausgabepaar-Datensatz D^t erfasst und das Modell neu trainiert werden.
Gisting ist ein anderer Ansatz, der zwei Kosten amortisiert: (1) den Inferenzzeitaufwand für die Konditionierung von p_LM auf t, (2) den Trainingszeitaufwand für das Lernen eines neuen p^t_LM für jedes t. Die Idee besteht darin, während der Feinabstimmung eine komprimierte Version von t G (t) zu lernen, sodass die Schlussfolgerung aus p_G (y | G (t),x) schneller ist als aus p_LM (y|t,x).
In LM-Begriffen wird G (t) ein Satz „virtueller“ Gist-Token sein, deren Anzahl geringer ist als die Token in t, die aber dennoch ein ähnliches Verhalten in LM hervorrufen. Transformatoraktivierungen (z. B. Schlüssel- und Wertmatrizen) auf G (t) können dann zwischengespeichert und wiederverwendet werden, um die Recheneffizienz zu verbessern. Wichtig ist, dass die Forscher hoffen, dass G auf unbekannte Aufgaben verallgemeinert werden kann: Bei einer neuen Aufgabe t kann die entsprechende Gist-Aktivierung G(t) ohne zusätzliches Training vorhergesagt und verwendet werden.
Lernen von Gisting über Masken
Der allgemeine Rahmen von Gisting wurde oben beschrieben, und als nächstes werden wir eine sehr einfache Möglichkeit untersuchen, ein solches Modell zu lernen: die Verwendung des LM selbst als Gist-Prädiktor G. Dies nutzt nicht nur bereits vorhandenes Wissen im LM, sondern ermöglicht auch das Erlernen von Gisting, indem einfach eine Standardanweisungsfeinabstimmung durchgeführt und die Transformer-Aufmerksamkeitsmaske geändert wird, um die Prompt-Komprimierung zu verbessern. Das bedeutet, dass für Gisting kein zusätzlicher Schulungsaufwand anfällt und nur eine Feinabstimmung anhand von Standardanweisungen erforderlich ist!
Fügen Sie insbesondere ein spezielles Gist-Token zum Modellvokabular und zur Einbettungsmatrix hinzu, ähnlich den in solchen Modellen üblichen Satzanfangs-/Endtokens. Verketten Sie dann für ein gegebenes (Aufgaben-, Eingabe-)Tupel (t, x) t und x unter Verwendung einer Menge von k aufeinanderfolgenden Kerntokens in (t, g_1, . . , g_k, x), z. B. 
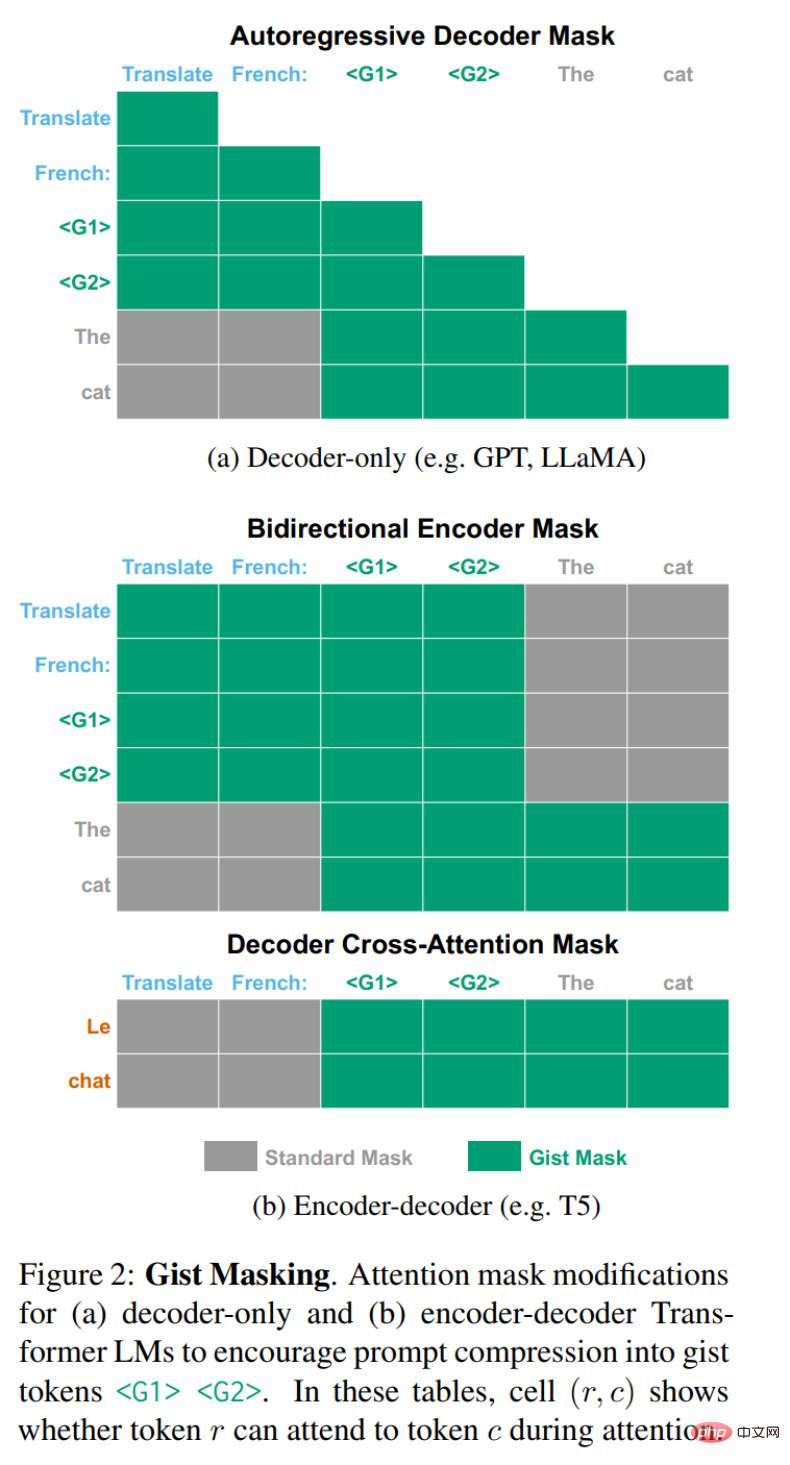
Abbildung 2 unten zeigt die erforderlichen Änderungen. Für reine Decoder-LMs wie GPT-3 oder LLaMA, die typischerweise autoregressive kausale Aufmerksamkeitsmasken verwenden, muss man nur die untere linke Ecke des in Abbildung 2a gezeigten Dreiecks ausblenden. Für einen Encoder-Decoder LM mit einem bidirektionalen Encoder und einem autoregressiven Decoder sind zwei Modifikationen erforderlich (dargestellt in Abbildung 2b).
Zuerst blockieren Sie bei Encodern, die normalerweise keine Masken haben, den Eingabetoken x mit Bezug auf den Eingabeaufforderungstoken t. Es muss aber auch verhindert werden, dass Prompt t und Gist-Token g_i auf das Eingabetoken x verweisen, da der Encoder sonst je nach Eingabe unterschiedliche Gist-Darstellungen lernt. Schließlich arbeitet der Decoder normal, außer während der Queraufmerksamkeitsperioden, in denen verhindert werden muss, dass der Decoder auf den Prompt-Token t verweist.
Experimentelle Ergebnisse
Für unterschiedliche Anzahlen von Gist-Tokens sind die ROUGE-L- und ChatGPT-Bewertungsergebnisse von LLaMA-7B und FLAN-T5-XXL in Abbildung 3 unten dargestellt.
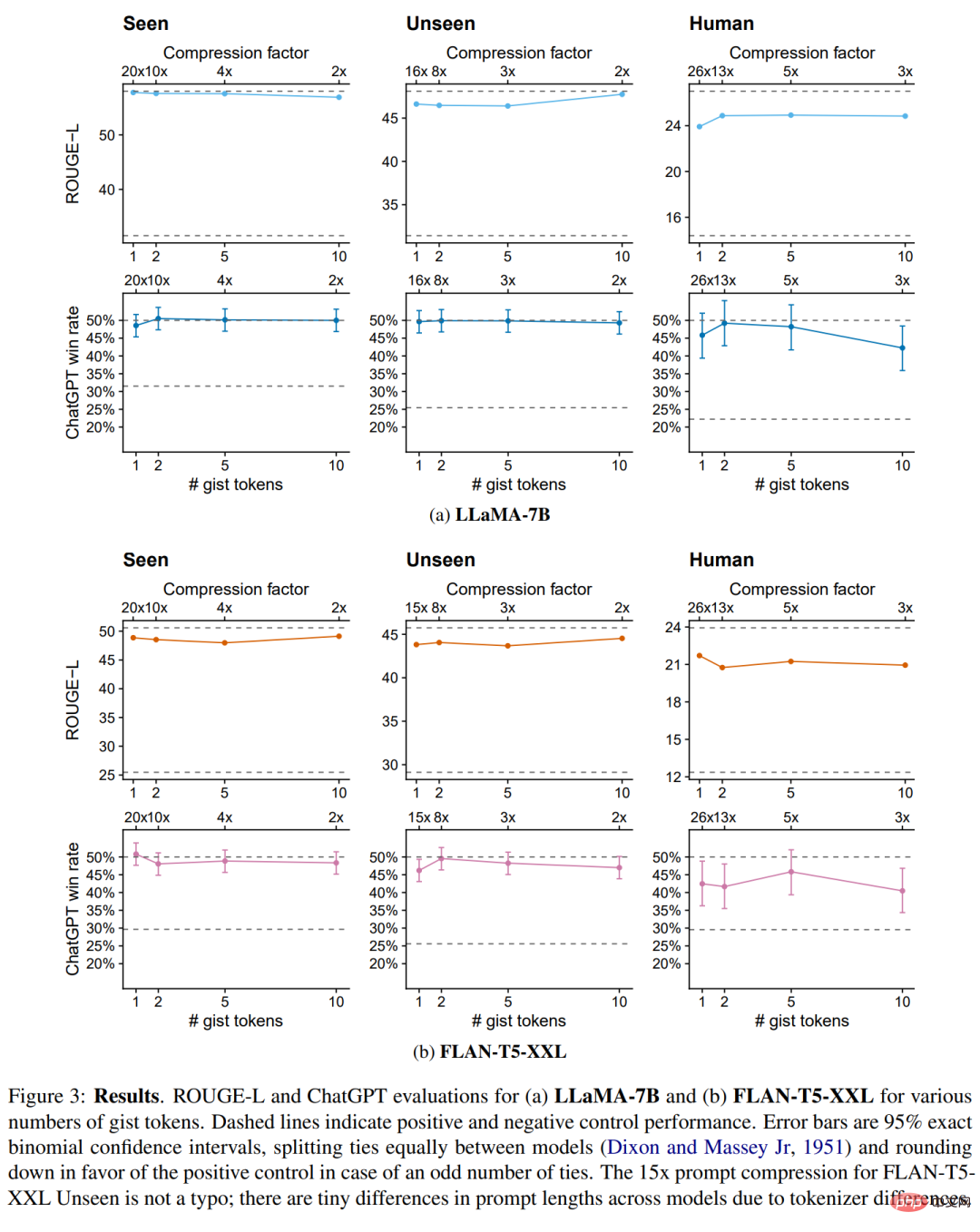
Modelle sind im Allgemeinen unempfindlich gegenüber der Anzahl k der Gist-Tokens: Das Komprimieren von Eingabeaufforderungen in einem einzigen Token führt nicht zu erheblichen Leistungseinbußen. Tatsächlich beeinträchtigen in einigen Fällen zu viele Gist-Tokens die Leistung (z. B. LLaMA-7B, 10 Gist-Tokens), möglicherweise weil die erhöhte Kapazität zu stark zur Trainingsverteilung passt. Daher geben die Forscher die spezifischen Werte des Einzel-Token-Modells in der folgenden Tabelle 1 an und verwenden in den verbleibenden Experimenten ein einzelnes Kernmodell.
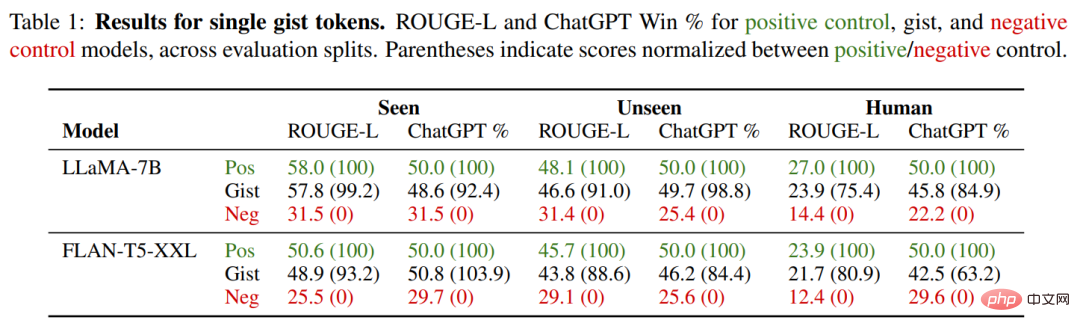
Den gesehenen Anweisungen erreichte das Gist-Modell fast die gleiche ROUGE- und ChatGPT-Leistung wie sein entsprechendes Positivkontrollmodell, mit Gewinnraten von 48,6 % bzw. 48,6 % auf LLaMA-7B FLANT5- XXL. 50,8 %. Was die Forscher hier am meisten interessiert, ist ihre Generalisierungsfähigkeit bei unbekannten Aufgaben, die anhand von zwei anderen Datensätzen gemessen werden muss.
In den unsichtbaren Eingabeaufforderungen im Alpaca+-Trainingsdatensatz können wir sehen, dass das Gist-Modell über eine starke Generalisierungsfähigkeit bei unsichtbaren Eingabeaufforderungen verfügt: 49,7 % (LLaMA) bzw. 46,2 % im Vergleich zur Kontrollgruppe (FLAN-T5), die gewinnt Rate. Beim anspruchsvollsten OOD Human Split sinkt die Gewinnquote des Kernmodells leicht auf 45,8 % (LLaMA) und 42,5 % (FLANT5).
Der Zweck dieses Artikels besteht darin, ein Kernmodell zu schaffen, das die Funktionalität des Originalmodells genau nachahmt. Daher könnte man sich fragen, wann genau ein Kernmodell nicht von einer Kontrollgruppe zu unterscheiden ist. Abbildung 4 unten zeigt, wie oft dies geschieht: Bei gesehenen Aufgaben (aber unsichtbaren Eingaben) liegt das Gist-Modell fast die Hälfte der Zeit auf Augenhöhe mit der Kontrollgruppe. Bei ungesehenen Aufgaben sinkt diese Zahl auf 20–25 %. Für die OOD Human-Aufgabe sinkt diese Zahl wieder auf 10 %. Unabhängig davon ist die Qualität der Kernmodellausgabe sehr hoch.
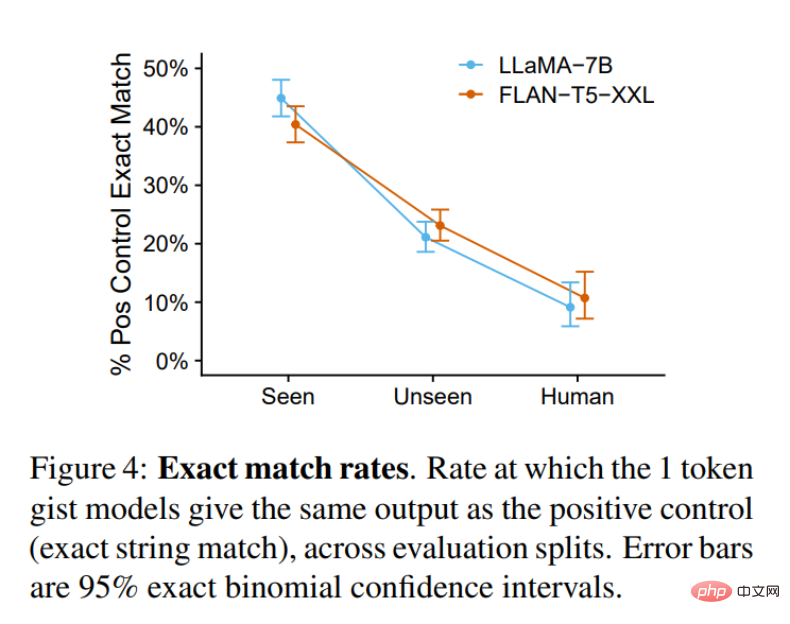
Insgesamt zeigen diese Ergebnisse, dass das Gist-Modell Eingabeaufforderungen zuverlässig komprimieren kann, selbst bei einigen Eingabeaufforderungen außerhalb der Trainingsverteilung, insbesondere bei LLaMA, einem solchen kausalen LM, der nur durch Decoder erfolgt. Encoder-Decoder-Modelle wie FLAN-T5 schneiden etwas schlechter ab. Ein möglicher Grund dafür ist, dass die Kernmaske den bidirektionalen Aufmerksamkeitsfluss im Encoder unterdrückt, was eine größere Herausforderung darstellt, als nur einen Teil des Verlaufs im autoregressiven Decoder zu maskieren. Weitere Arbeiten sind erforderlich, um diese Hypothese in Zukunft zu untersuchen.
Rechen-, Speicher- und Speichereffizienz
Abschließend noch einmal zurück zu einer der Kernmotivationen dieser Arbeit: Welche Effizienzsteigerungen kann Gisting mit sich bringen?
Tabelle 2 unten zeigt die Ergebnisse eines einzelnen Vorwärtsdurchlaufs des Modells (d. h. eines Schritts der autoregressiven Dekodierung mit einem einzelnen Eingabetoken) unter Verwendung des PyTorch 2.0-Profilers, gemittelt über die 252 Anweisungen im Human-Eval-Split-Wert. Das Gist-Caching verbessert die Effizienz im Vergleich zu nicht optimierten Modellen erheblich. Bei beiden Modellen wurden FLOP-Einsparungen von 40 % und eine Taktzeitverkürzung von 4–7 % erzielt.
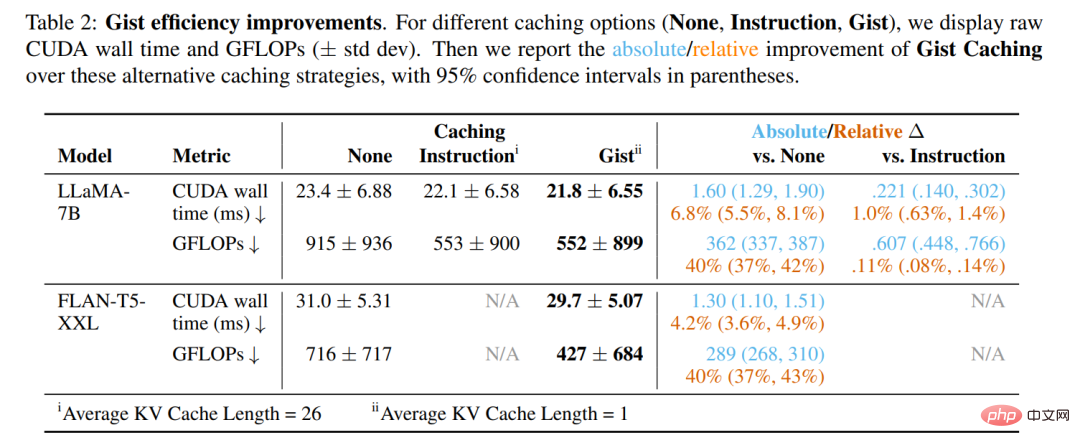
Noch wichtiger ist jedoch, dass der Gist-Cache im Vergleich zum Befehlscache neben der Latenz einen entscheidenden Vorteil hat: Durch die Komprimierung von 26 Token in 1 wird im Eingabekontextfenster mehr Platz frei, der durch begrenzt ist absolute Positionseinbettung oder GPU-VRAM. Speziell für LLaMA-7B benötigt jeder Token im KV-Cache 1,05 MB Speicherplatz. Obwohl der KV-Cache im Verhältnis zum Gesamtspeicher, der für die LLaMA-7B-Inferenz bei den getesteten Eingabeaufforderungslängen erforderlich ist, nur wenig beiträgt, kommt es immer häufiger vor, dass Entwickler viele Eingabeaufforderungen für eine große Anzahl von Benutzern zwischenspeichern, und die Speicherkosten können schnell steigen. Bei gleichem Speicherplatz kann der Gist-Cache 26-mal mehr Eingabeaufforderungen verarbeiten als der vollständige Befehlscache.
Das obige ist der detaillierte Inhalt vonKomprimieren Sie 26 Token in einer neuen Methode, um Platz im ChatGPT-Eingabefeld zu sparen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
In diesem Artikel wird das Problem der genauen Erkennung von Objekten aus verschiedenen Blickwinkeln (z. B. Perspektive und Vogelperspektive) beim autonomen Fahren untersucht, insbesondere wie die Transformation von Merkmalen aus der Perspektive (PV) in den Raum aus der Vogelperspektive (BEV) effektiv ist implementiert über das Modul Visual Transformation (VT). Bestehende Methoden lassen sich grob in zwei Strategien unterteilen: 2D-zu-3D- und 3D-zu-2D-Konvertierung. 2D-zu-3D-Methoden verbessern dichte 2D-Merkmale durch die Vorhersage von Tiefenwahrscheinlichkeiten, aber die inhärente Unsicherheit von Tiefenvorhersagen, insbesondere in entfernten Regionen, kann zu Ungenauigkeiten führen. Während 3D-zu-2D-Methoden normalerweise 3D-Abfragen verwenden, um 2D-Features abzutasten und die Aufmerksamkeitsgewichte der Korrespondenz zwischen 3D- und 2D-Features über einen Transformer zu lernen, erhöht sich die Rechen- und Bereitstellungszeit.
