Die Grundeinheit des Computerspeichers ist das Byte, das aus 8 Bits besteht. Da Englisch nur aus 26 Buchstaben plus einer Reihe von Symbolen besteht, können englische Zeichen direkt in Bytes gespeichert werden. Andere Sprachen (wie Chinesisch, Japanisch, Koreanisch usw.) müssen jedoch aufgrund der großen Anzahl von Zeichen mehrere Bytes für die Codierung verwenden.
Mit der Verbreitung der Computertechnologie entwickelt sich die Technologie zur Kodierung nicht-lateinischer Zeichen weiter, es gibt jedoch immer noch zwei wesentliche Einschränkungen:
Unterstützt keine Mehrsprachensprache: Das Kodierungsschema einer Sprache kann nicht für eine andere Sprache verwendet werden
Es gibt keinen einheitlichen Standard: Chinesisch hat beispielsweise mehrere Kodierungsstandards wie GBK, GB2312, GB18030 usw.
Da die Kodierungsmethoden nicht einheitlich sind, müssen Entwickler zwischen verschiedenen Kodierungen hin und her konvertieren , was unweigerlich zu vielen Fehlern führt. Um dieses Inkonsistenzproblem zu lösen, wurde der Unicode-Standard vorgeschlagen. Unicode organisiert und kodiert die meisten Schriftsysteme der Welt und ermöglicht es Computern, Texte auf einheitliche Weise zu verarbeiten. Unicode umfasst derzeit mehr als 140.000 Zeichen und unterstützt selbstverständlich mehrere Sprachen. (Unicodes Uni ist die Wurzel von „Vereinigung“)
2 Unicode in Python
2.1 Vorteile von Unicode-Objekten
Nach Python 3 wird das str-Objekt intern durch Unicode dargestellt, sodass es im Quellcode zu einem Unicode-Objekt wird. Der Vorteil der Verwendung der Unicode-Darstellung besteht darin, dass die Kernlogik des Programms Unicode einheitlich verwendet und nur auf der Eingabe- und Ausgabeebene dekodiert und kodiert werden muss, wodurch verschiedene Kodierungsprobleme weitestgehend vermieden werden können.
Das Diagramm sieht wie folgt aus:
2.2 Pythons Optimierung von Unicode
Problem: Da Unicode mehr als 140.000 Zeichen enthält, benötigt jedes Zeichen mindestens 4 Bytes zum Speichern (dies sollte daran liegen, dass ein Abschnitt mit 2 Zeichen nicht ausreicht). , es werden also 4 Bytes anstelle von 3 Bytes verwendet.) Der ASCII-Code für englische Zeichen erfordert nur 1 Byte. Durch die Verwendung von Unicode vervierfachen sich die Kosten für häufig verwendete englische Zeichen.
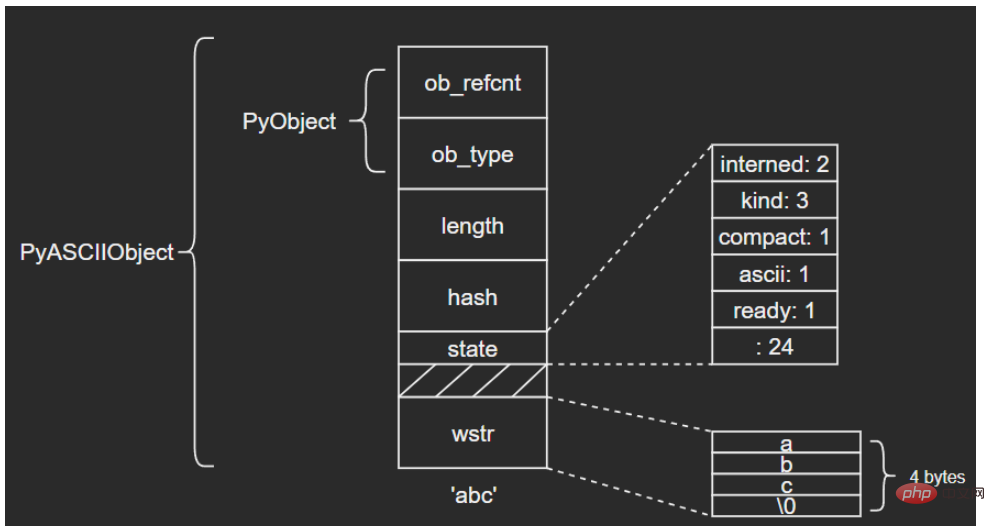
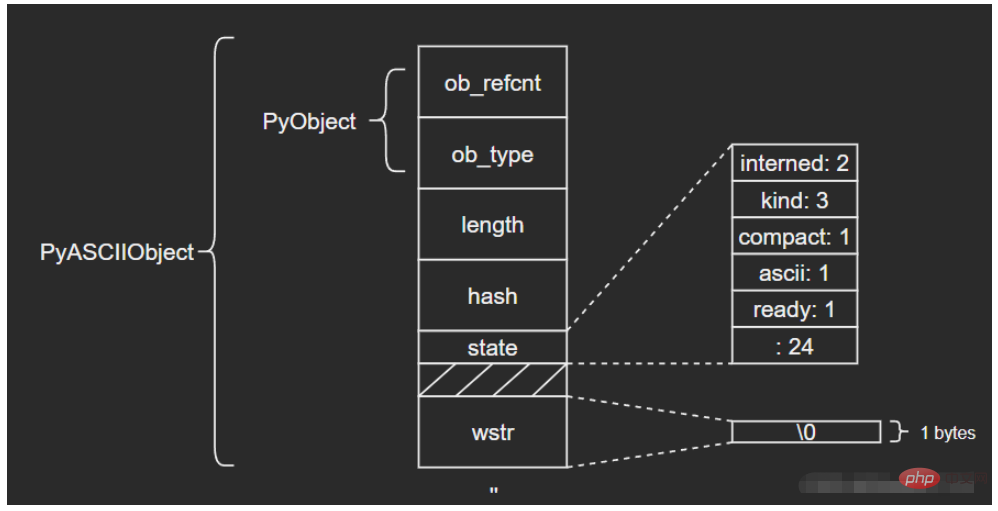
Werfen wir zunächst einen Blick auf die Größenunterschiede verschiedener Formen von Str-Objekten in Python:
Man erkennt, dass Python Unicode-Objekte intern optimiert: Basierend auf dem Textinhalt wird die zugrunde liegende Speichereinheit ausgewählt.
Der zugrunde liegende Speicher von Unicode-Objekten ist entsprechend dem Unicode-Codepunktbereich der Textzeichen in drei Kategorien unterteilt:
PyUnicode_1BYTE_KIND: Alle Zeichencodepunkte liegen zwischen U+0000 und U+00FF
PyUnicode_2BYTE_KIND: Alle Zeichencodepunkte liegen zwischen U+0000 und U+FFFF, und der Codepunkt mindestens eines Zeichens ist größer als U+00FF
PyUnicode_1BYTE_KIND: Alle Zeichencodepunkte liegen zwischen U+0000 und U+10FFFF, und es gibt at Codepunkt mindestens eines Zeichens größer als U+FFFF
Die entsprechende Aufzählung lautet wie folgt:
enum PyUnicode_Kind {
/* String contains only wstr byte characters. This is only possible
when the string was created with a legacy API and _PyUnicode_Ready()
has not been called yet. */
PyUnicode_WCHAR_KIND = 0,
/* Return values of the PyUnicode_KIND() macro: */
PyUnicode_1BYTE_KIND = 1,
PyUnicode_2BYTE_KIND = 2,
PyUnicode_4BYTE_KIND = 4
};
Nach dem Login kopieren
Wählen Sie je nach Klassifizierung unterschiedliche Speichereinheiten aus:
/* Py_UCS4 and Py_UCS2 are typedefs for the respective
unicode representations. */
typedef uint32_t Py_UCS4;
typedef uint16_t Py_UCS2;
typedef uint8_t Py_UCS1;
Nach dem Login kopieren
Die entsprechende Beziehung lautet wie folgt:
Text Typ
Zeichenspeichereinheit
Größe der Zeichenspeichereinheit (Byte)
PyUnicode_1BYTE_KIND
Py_UCS1
1
PyUnicode_2BYTE_KIND
Py_UCS 2
2
PyUnicode_4BYTE_KIND
Py_UCS4
4
Aufgrund der internen Speicherstruktur von Unicode variieren Texttypen, daher muss die Typart als öffentliches Unicode-Objektfeld gespeichert werden. Python definiert intern einige Flag-Bits als öffentliche Unicode-Felder: (Aufgrund der begrenzten Ebene des Autors werden alle Felder hier nicht im folgenden Inhalt vorgestellt. Sie können später selbst mehr darüber erfahren. Halten Sie Ihre Faust ~)
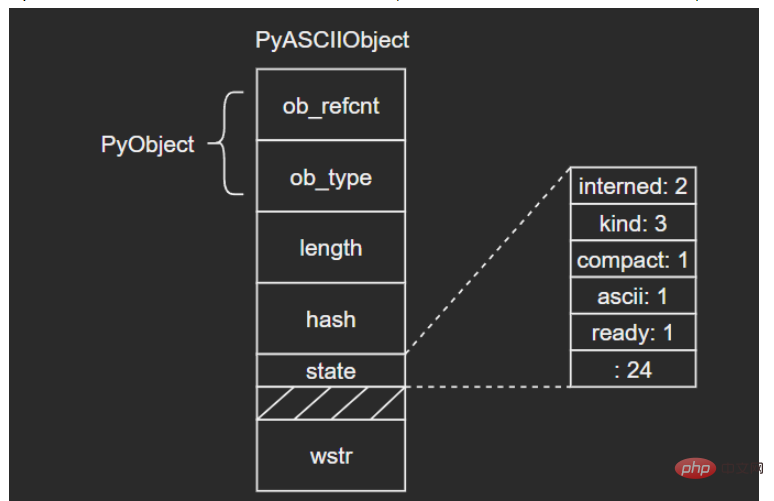
intern: ob es sich um eine internierte Mechanismuswartung handelt
Art: Typ, der zur Unterscheidung der Größe der zugrunde liegenden Zeichenspeichereinheit verwendet wird
kompakt: Speicherzuweisungsmethode, ob Objekt und Textpuffer getrennt sind
asscii: ob der Text ausschließlich reines ASCII ist
Verwenden Sie die Funktion PyUnicode_New, um das Unicode-Objekt entsprechend der Anzahl der Textzeichen und der maximalen Zeichengröße maxchar zu initialisieren. Diese Funktion wählt hauptsächlich die kompakteste Zeichenspeichereinheit und zugrunde liegende Struktur für Unicode-Objekte basierend auf maxchar aus: (Der Quellcode ist relativ lang und wird daher hier nicht aufgeführt. Sie können ihn selbst verstehen. Er wird unten in Tabellenform angezeigt )
maxchar < 128
128 <= maxchar < 256
256 <= maxchar <
kind
PyUnicode_1BYTE_KIND
PyUnicode_1BYTE_KIND
PyUnicode_2BYTE_KIND
PyUnicode_4BYTE_KIND
ascii
1
0
0
0
Größe der Zeichenspeichereinheit (Bytes)
1
1
2
4
Untere Struktur
PyASCIIObject
PyCompactUnicodeObject
PyCompactUnicodeObject
PyCompactUnicodeObject
3 Unicode对象的底层结构体
3.1 PyASCIIObject
C源码:
typedef struct {
PyObject_HEAD
Py_ssize_t length; /* Number of code points in the string */
Py_hash_t hash; /* Hash value; -1 if not set */
struct {
unsigned int interned:2;
unsigned int kind:3;
unsigned int compact:1;
unsigned int ascii:1;
unsigned int ready:1;
unsigned int :24;
} state;
wchar_t *wstr; /* wchar_t representation (null-terminated) */
} PyASCIIObject;
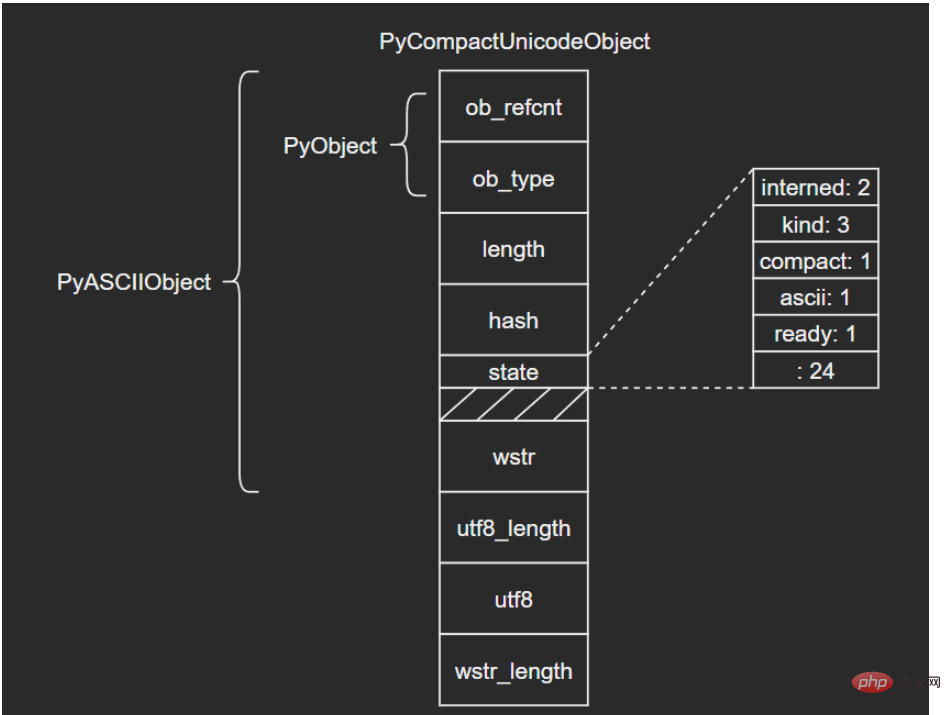
/* Non-ASCII strings allocated through PyUnicode_New use the
PyCompactUnicodeObject structure. state.compact is set, and the data
immediately follow the structure. */
typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length; /* Number of bytes in utf8, excluding the
* terminating \0. */
char *utf8; /* UTF-8 representation (null-terminated) */
Py_ssize_t wstr_length; /* Number of code points in wstr, possible
* surrogates count as two code points. */
} PyCompactUnicodeObject;
/* Strings allocated through PyUnicode_FromUnicode(NULL, len) use the
PyUnicodeObject structure. The actual string data is initially in the wstr
block, and copied into the data block using _PyUnicode_Ready. */
typedef struct {
PyCompactUnicodeObject _base;
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data; /* Canonical, smallest-form Unicode buffer */
} PyUnicodeObject;
Nach dem Login kopieren
3.4 示例
在日常开发时,要结合实际情况注意字符串拼接前后的内存大小差别:
>>> import sys
>>> text = 'a' * 1000
>>> sys.getsizeof(text)
1049
>>> text += '????'
>>> sys.getsizeof(text)
4080
/* This dictionary holds all interned unicode strings. Note that references
to strings in this dictionary are *not* counted in the string's ob_refcnt.
When the interned string reaches a refcnt of 0 the string deallocation
function will delete the reference from this dictionary.
Another way to look at this is that to say that the actual reference
count of a string is: s->ob_refcnt + (s->state ? 2 : 0)
*/
static PyObject *interned = NULL;
void
PyUnicode_InternInPlace(PyObject **p)
{
PyObject *s = *p;
PyObject *t;
#ifdef Py_DEBUG
assert(s != NULL);
assert(_PyUnicode_CHECK(s));
#else
if (s == NULL || !PyUnicode_Check(s))
return;
#endif
/* If it's a subclass, we don't really know what putting
it in the interned dict might do. */
if (!PyUnicode_CheckExact(s))
return;
if (PyUnicode_CHECK_INTERNED(s))
return;
if (interned == NULL) {
interned = PyDict_New();
if (interned == NULL) {
PyErr_Clear(); /* Don't leave an exception */
return;
}
}
Py_ALLOW_RECURSION
t = PyDict_SetDefault(interned, s, s);
Py_END_ALLOW_RECURSION
if (t == NULL) {
PyErr_Clear();
return;
}
if (t != s) {
Py_INCREF(t);
Py_SETREF(*p, t);
return;
}
/* The two references in interned are not counted by refcnt.
The deallocator will take care of this */
Py_REFCNT(s) -= 2;
_PyUnicode_STATE(s).interned = SSTATE_INTERNED_MORTAL;
}
>>> a = 'abc'
>>> b = 'ab' + 'c'
>>> id(a), id(b), a is b
(2752416949872, 2752416949872, True)
Nach dem Login kopieren
Das obige ist der detaillierte Inhalt vonIn Python integrierte Quellcodeanalyse vom Typ str. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Erklärung dieser Website
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn
PHP ist hauptsächlich prozedurale Programmierung, unterstützt aber auch die objektorientierte Programmierung (OOP). Python unterstützt eine Vielzahl von Paradigmen, einschließlich OOP, funktionaler und prozeduraler Programmierung. PHP ist für die Webentwicklung geeignet, und Python eignet sich für eine Vielzahl von Anwendungen wie Datenanalyse und maschinelles Lernen.
PHP eignet sich für Webentwicklung und schnelles Prototyping, und Python eignet sich für Datenwissenschaft und maschinelles Lernen. 1.PHP wird für die dynamische Webentwicklung verwendet, mit einfacher Syntax und für schnelle Entwicklung geeignet. 2. Python hat eine kurze Syntax, ist für mehrere Felder geeignet und ein starkes Bibliotheksökosystem.
PHP entstand 1994 und wurde von Rasmuslerdorf entwickelt. Es wurde ursprünglich verwendet, um Website-Besucher zu verfolgen und sich nach und nach zu einer serverseitigen Skriptsprache entwickelt und in der Webentwicklung häufig verwendet. Python wurde Ende der 1980er Jahre von Guidovan Rossum entwickelt und erstmals 1991 veröffentlicht. Es betont die Lesbarkeit und Einfachheit der Code und ist für wissenschaftliche Computer, Datenanalysen und andere Bereiche geeignet.
Python eignet sich besser für Anfänger mit einer reibungslosen Lernkurve und einer kurzen Syntax. JavaScript ist für die Front-End-Entwicklung mit einer steilen Lernkurve und einer flexiblen Syntax geeignet. 1. Python-Syntax ist intuitiv und für die Entwicklung von Datenwissenschaften und Back-End-Entwicklung geeignet. 2. JavaScript ist flexibel und in Front-End- und serverseitiger Programmierung weit verbreitet.
Um den Python-Code im Sublime-Text auszuführen, müssen Sie zuerst das Python-Plug-In installieren, dann eine .py-Datei erstellen und den Code schreiben, und drücken Sie schließlich Strg B, um den Code auszuführen, und die Ausgabe wird in der Konsole angezeigt.
Das Schreiben von Code in Visual Studio Code (VSCODE) ist einfach und einfach zu bedienen. Installieren Sie einfach VSCODE, erstellen Sie ein Projekt, wählen Sie eine Sprache aus, erstellen Sie eine Datei, schreiben Sie Code, speichern und führen Sie es aus. Die Vorteile von VSCODE umfassen plattformübergreifende, freie und open Source, leistungsstarke Funktionen, reichhaltige Erweiterungen sowie leichte und schnelle.
VS -Code kann zum Schreiben von Python verwendet werden und bietet viele Funktionen, die es zu einem idealen Werkzeug für die Entwicklung von Python -Anwendungen machen. Sie ermöglichen es Benutzern: Installation von Python -Erweiterungen, um Funktionen wie Code -Abschluss, Syntax -Hervorhebung und Debugging zu erhalten. Verwenden Sie den Debugger, um Code Schritt für Schritt zu verfolgen, Fehler zu finden und zu beheben. Integrieren Sie Git für die Versionskontrolle. Verwenden Sie Tools für die Codeformatierung, um die Codekonsistenz aufrechtzuerhalten. Verwenden Sie das Lining -Tool, um potenzielle Probleme im Voraus zu erkennen.
Das Ausführen von Python-Code in Notepad erfordert, dass das ausführbare Python-ausführbare Datum und das NPPEXEC-Plug-In installiert werden. Konfigurieren Sie nach dem Installieren von Python und dem Hinzufügen des Pfades den Befehl "Python" und den Parameter "{current_directory} {file_name}" im NPPExec-Plug-In, um Python-Code über den Shortcut-Taste "F6" in Notoza auszuführen.