
 Technologie-Peripheriegeräte
KI
Die Unterzeitschrift „Nature' der Hillhouse School of Artificial Intelligence der Renmin University versucht, mithilfe multimodaler Grundmodelle den Weg zur allgemeinen künstlichen Intelligenz zu ebnen
Technologie-Peripheriegeräte
KI
Die Unterzeitschrift „Nature' der Hillhouse School of Artificial Intelligence der Renmin University versucht, mithilfe multimodaler Grundmodelle den Weg zur allgemeinen künstlichen Intelligenz zu ebnen
Die Unterzeitschrift „Nature' der Hillhouse School of Artificial Intelligence der Renmin University versucht, mithilfe multimodaler Grundmodelle den Weg zur allgemeinen künstlichen Intelligenz zu ebnen

Kürzlich wurden Professor Lu Zhiwu, Permanent Associate Professor Sun Hao und Dekan Professor Wen Jirong von der Hillhouse School of Artificial Intelligence der Renmin University of China als Co-Korrespondenzautoren in der internationalen Fachzeitschrift „Nature Communications“ (englischer Name: Nature Communications) veröffentlicht , genannt Nat Commun) veröffentlichte eine Forschungsarbeit mit dem Titel „Towards Artificial General Intelligence via a Multimodal Foundation Model“. Der erste Autor des Artikels ist Doktorand Fei Nanyi. Diese Arbeit versucht, multimodale Basismodelle für die allgemeine künstliche Intelligenz zu nutzen und wird weitreichende Auswirkungen auf verschiedene KI+-Bereiche wie Neurowissenschaften und Gesundheitswesen haben. Dieser Artikel ist eine Interpretation dieses Papiers.

- Papierlink: https://www.nature.com/articles/s41467-022-30761-2
- Codelink: https://github.com /neilfei/brivl-nmi
Das grundlegende Ziel der künstlichen Intelligenz besteht darin, die kognitiven Kernaktivitäten des Menschen wie Wahrnehmung, Gedächtnis, logisches Denken usw. nachzuahmen. Obwohl viele Algorithmen oder Modelle der künstlichen Intelligenz in verschiedenen Forschungsbereichen große Erfolge erzielt haben, sind die meisten Forschungsarbeiten zur künstlichen Intelligenz immer noch auf die Erfassung großer Mengen markierter Daten oder unzureichende Rechenressourcen zur Unterstützung des Trainings auf die Erfassung großer Datenmengen beschränkt eine einzelne kognitive Fähigkeit.
Um diese Einschränkungen zu überwinden und einen Schritt in Richtung allgemeiner künstlicher Intelligenz zu machen, haben wir ein multimodales (visuelles) Grundmodell entwickelt, das vorab trainiert wird. Damit das Modell eine starke Generalisierungsfähigkeit erhält, schlagen wir außerdem vor, dass die Bilder und Texte in den Trainingsdaten der Hypothese einer schwachen semantischen Korrelation folgen sollten (wie in Abbildung 1b dargestellt) und nicht der Feinanpassung von Bildbereichen und Wörtern (starke semantische Korrelation), aufgrund der starken semantischen Korrelation. Die Annahme einer semantischen Korrelation führt dazu, dass das Modell die komplexen Emotionen und Gedanken verliert, die Menschen beim Beschriften von Bildern implizieren.
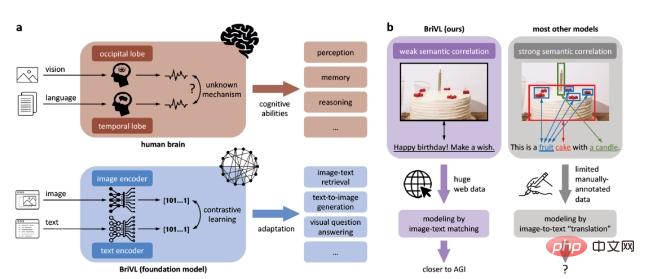

Abbildung 1: BriVL-Modell basierend auf der Annahme einer schwachen semantischen Korrelation. a. Vergleich zwischen unserem BriVL-Modell und dem menschlichen Gehirn bei der Verarbeitung visueller Sprachinformationen. b. Vergleich der Modellierung schwach semantischer Daten und der Modellierung stark semantischer Daten.
Durch das Training an umfangreichen Bild- und Textdaten, die aus dem Internet gecrawlt wurden, zeigt das multimodale Grundmodell, das wir erhalten haben, eine starke Generalisierungsfähigkeit und Vorstellungskraft. Wir glauben, dass unsere Arbeit einen wichtigen (wenn auch möglicherweise kleinen) Schritt in Richtung allgemeiner künstlicher Intelligenz darstellt und weitreichende Auswirkungen auf verschiedene KI+-Bereiche wie Neurowissenschaften und Gesundheitswesen haben wird.
Methode
Wir haben ein groß angelegtes multimodales Basismodell für selbstüberwachtes Training auf riesigen multimodalen Daten entwickelt und es BriVL (Bridging-Vision-and-Language) genannt.
Zunächst verwenden wir einen umfangreichen, aus mehreren Quellen stammenden Bild- und Textdatensatz, der aus dem Internet erstellt wurde und den Namen „Weak Semantic Correlation Dataset“ (WSCD) trägt. WSCD sammelt chinesische Bild-Text-Paare aus mehreren Quellen im Internet, darunter Nachrichten, Enzyklopädien und soziale Medien. Wir haben in WSCD nur pornografische und sensible Daten herausgefiltert, ohne die Originaldaten in irgendeiner Form zu bearbeiten oder zu verändern, um ihre natürliche Datenverteilung aufrechtzuerhalten. Insgesamt verfügt WSCD über etwa 650 Millionen Bild-Text-Paare, die viele Themen wie Sport, Alltag und Filme abdecken.
Zweitens haben wir für unsere Netzwerkarchitektur, da es nicht unbedingt eine feinkörnige regionale Wortübereinstimmung zwischen Bildern und Texten gibt, den zeitaufwändigen Objektdetektor weggeworfen und eine einfache Twin-Tower-Architektur übernommen, damit wir das konnten Übergeben Sie zwei separate Encoder, die Bild- und Texteingaben codieren (Abbildung 2). Die Doppelturmstruktur bietet offensichtliche Effizienzvorteile im Inferenzprozess, da die Merkmale des Kandidatensatzes vor der Abfrage berechnet und indiziert werden können, wodurch die Echtzeitanforderungen realer Anwendungen erfüllt werden. Drittens ist es mit der Entwicklung groß angelegter verteilter Trainingstechnologie und selbstüberwachtem Lernen möglich geworden, Modelle mit riesigen, unbeschrifteten multimodalen Daten zu trainieren.
Um insbesondere die schwache Korrelation von Bild-Text-Paaren zu modellieren und einen einheitlichen semantischen Raum zu erlernen, haben wir einen modalübergreifenden kontrastiven Lernalgorithmus entwickelt, der auf der monomodalen kontrastiven Lernmethode MoCo basiert. Wie in Abbildung 2 dargestellt, nutzt unser BriVL-Modell den Momentum-Mechanismus, um die negative Probenwarteschlange in verschiedenen Trainingschargen dynamisch aufrechtzuerhalten. Auf diese Weise verfügen wir über eine relativ große Anzahl negativer Stichproben (entscheidend für kontrastives Lernen) und verwenden gleichzeitig eine relativ kleine Stapelgröße, um die GPU-Speichernutzung zu reduzieren (d. h. GPU-Ressourceneinsparungen).
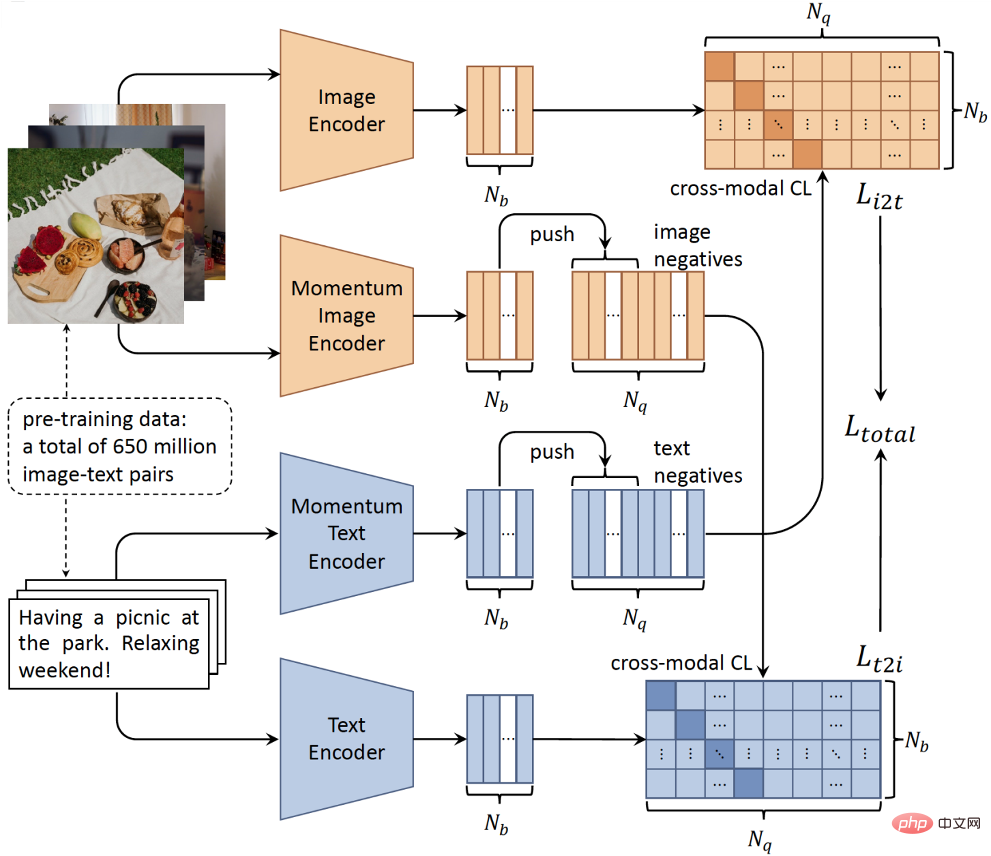
Abbildung 2: Schematische Darstellung des BriVL-Modells für groß angelegtes multimodales Vortraining.
Hauptergebnisse
Visualisierung neuronaler Netze
Wenn wir Wörter oder beschreibende Sätze hören, erscheinen einige Szenen in unserem Kopf. Nachdem unser BriVL anhand einer so großen Anzahl schwach korrelierter Bild-Text-Paare vorab trainiert wurde, sind wir sehr gespannt, was es sich vorstellt, wenn Text gegeben wird.
Konkret geben wir zunächst einen Text ein und erhalten die Texteinbettung über den Text-Encoder von BriVL. Dann initialisieren wir zufällig ein verrauschtes Bild und lassen seine Funktionen über den Bildencoder einbetten. Da das Eingabebild zufällig initialisiert wird, müssen seine Merkmale nicht mit denen des Eingabetextes übereinstimmen. Daher definieren wir das Ziel, zwei Feature-Einbettungen abzugleichen und das Eingabebild durch Backpropagation zu aktualisieren. Das resultierende Bild zeigt deutlich, wie BriVL sich den Eingabetext vorgestellt hat. Hier verwenden wir keine zusätzlichen Module oder Daten und auch das vortrainierte BriVL wird während des gesamten Visualisierungsprozesses eingefroren.
Wir stellen zunächst die Fähigkeit von BriVL vor, sich einige semantische Konzepte auf hoher Ebene vorzustellen (Abbildung 3). Wie Sie sehen, sind diese Konzepte zwar sehr abstrakt, die Visualisierung ist jedoch in der Lage, sie in konkreter Form darzustellen (z. B. „Natur“: eine grasähnliche Pflanze; „Zeit“: eine Uhr; „Wissenschaft“: ein Gesicht mit Gläser und ein Erlenmeyerkolben; „Traumland“: Wolken, eine Brücke zur Tür und eine traumhafte Atmosphäre). Diese Fähigkeit, abstrakte Konzepte auf eine Reihe konkreter Objekte zu verallgemeinern, zeigt die Wirksamkeit unseres multimodalen Vortrainings, bei dem nur schwach semantisch verwandte Daten verwendet werden.

Abbildung 3: Vorstellungskraft des BriVL-Modells für abstrakte Konzepte.
In Abbildung 4 zeigen wir BriVLs Vorstellungskraft für Sätze. BriVLs Fantasie „Es gibt Sonnenschein hinter den Wolken“ verkörpert nicht nur buchstäblich den Sonnenschein hinter den Wolken, sondern scheint auch gefährliche Bedingungen auf See zu zeigen (links sind schiffsähnliche Objekte und Wellen), was die implizite Bedeutung davon zum Ausdruck bringt Satz . In der Visualisierung „Blooming as Summer Flowers“ sehen wir eine Blumentraube. Die komplexeren Texteingaben für die nächsten beiden Szenarien stammen beide aus alten chinesischen Gedichten und ihre Syntax unterscheidet sich völlig von der überwiegenden Mehrheit der Texte im Trainingssatz. Es scheint, dass BriVL sie auch gut verstehen kann: Für „Drei oder zwei Zweige Pfirsichblüten außerhalb des Bambus“ können wir sehen, dass es Bambus und rosa Blumen gibt, für „Die Sonne steht über den Bergen, der Gelbe Fluss fließt hinein“. Meer", können wir sehen. Die Bäume auf dem Berg verdecken die untergehende Sonne, und auf dem Fluss davor liegt ein kleines Boot. Insgesamt haben wir festgestellt, dass BriVL auch bei komplexen Sätzen über starke Vorstellungskraft verfügt.


Abbildung 4: Vorstellungskraft des BriVL-Modells für chinesische Sätze.
In Abbildung 5 werden mehrere ähnliche Texte für die Visualisierung des neuronalen Netzwerks von BriVL verwendet. Für „Berge mit Wäldern“ gibt es mehr grüne Flächen im Bild; für „Berge mit Steinen“ gibt es mehr Felsen im Bild; für „Berge mit Schnee“ ist der Boden um die Bäume in der Mitte entweder weiß oder blau; Bei „Bergen mit Wasserfällen“ ist blaues Wasser zu sehen, das herabfällt, und sogar etwas Wasserdampf. Diese Visualisierungen zeigen, dass BriVL Bergmodifikatoren genau verstehen und sich vorstellen kann.

Abbildung 5: Vorstellung des BriVL-Modells von „Bergen mit…“.
Textgenerierte Diagramme
Die Visualisierung neuronaler Netzwerke ist sehr einfach, aber manchmal schwer zu interpretieren. Deshalb haben wir einen alternativen Visualisierungs-/Interpretierbarkeitsansatz entwickelt, damit die imaginären Inhalte von BriVL für uns Menschen besser verstanden werden können. Insbesondere nutzen wir VQGAN, um Bilder unter der Anleitung von BriVL zu generieren, da VQGAN, vorab auf dem ImageNet-Datensatz trainiert, sehr gut in der Lage ist, realistische Bilder zu erzeugen. Wir erhalten zunächst zufällig eine Token-Sequenz und ein generiertes Bild von einem vorab trainierten VQGAN. Als nächstes geben wir das generierte Bild in den Bild-Encoder von BriVL ein und ein Stück Text in den Text-Encoder. Schließlich definieren wir das Ziel des Abgleichs zwischen Bild- und Texteinbettungen und aktualisieren die anfängliche Token-Sequenz über Backpropagation. Wie bei neuronalen Netzwerkvisualisierungen werden sowohl VQGAN als auch BriVL während des Generierungsprozesses eingefroren. Zum Vergleich zeigen wir auch Bilder, die mit dem CLIP-Modell von OpenAI anstelle von BriVL generiert wurden.
Wir haben zunächst vier Texteingaben ausgewählt und die Ergebnisse des Textgenerierungsdiagramms von CLIP und unserem BriVL in Abbildung 6 bzw. Abbildung 7 gezeigt. Sowohl CLIP als auch BriVL verstehen Text gut, wir beobachten jedoch auch zwei große Unterschiede. Erstens erscheinen in den von CLIP generierten Bildern Elemente im Cartoon-Stil, während die von BriVL generierten Bilder realistischer und natürlicher sind. Zweitens tendiert CLIP dazu, Elemente einfach zusammenzufügen, während BriVL Bilder erzeugt, die global einheitlicher sind. Der erste Unterschied kann auf die unterschiedlichen Trainingsdaten zurückzuführen sein, die von CLIP und BriVL verwendet werden. Die Bilder in unseren Trainingsdaten stammen aus dem Internet (hauptsächlich echte Fotos), während die Trainingsdaten von CLIP möglicherweise eine bestimmte Anzahl von Cartoon-Bildern enthalten. Der zweite Unterschied könnte auf die Tatsache zurückzuführen sein, dass CLIP Bild-Text-Paare mit starker semantischer Korrelation (durch Wortfilterung) verwendet, während wir schwach korrelierte Daten verwenden. Dies bedeutet, dass CLIP während des multimodalen Vortrainings eher Entsprechungen zwischen bestimmten Objekten und Wörtern/Phrasen lernt, während BriVL versucht, jedes Bild mit dem gegebenen Text als Ganzes zu verstehen.

Abbildung 6: CLIP (mit ResNet-50x4) verwendet VQGAN, um ein Beispiel für ein Diagramm zur Textgenerierung zu implementieren.


Abbildung 7: Ein Beispiel dafür, wie unser BriVL VQGAN verwendet, um die Textgenerierung zu erreichen.
Wir haben auch über eine anspruchsvollere Aufgabe nachgedacht, eine Bildfolge basierend auf mehreren aufeinanderfolgenden Sätzen zu erstellen. Wie in Abbildung 8 gezeigt, können wir sehen, dass die vier Bilder visuell kohärent sind und den gleichen Stil haben, obwohl jedes Bild unabhängig generiert wird. Dies zeigt einen weiteren Vorteil des BriVL-Modells: Obwohl die Umgebung und der Hintergrund in Bildern im relevanten Text nur schwer explizit erwähnt werden können, werden sie in unserem groß angelegten multimodalen Vortraining nicht ignoriert.

Abbildung 8: Ein Beispiel unseres BriVL, das VQGAN verwendet, um eine Reihe kohärenter Inhalte zu generieren.
In Abbildung 9 haben wir einige Konzepte/Szenarien ausgewählt, die Menschen selten sehen (wie „brennendes Meer“ und „glühender Wald“), sogar solche, die im wirklichen Leben nicht existieren (wie „Cyberpunk-Stadt“ und „Schloss“) in den Wolken"). Dies beweist, dass die überlegene Leistung von BriVL nicht auf eine Überanpassung an die Daten vor dem Training zurückzuführen ist, da die hier eingegebenen Konzepte/Szenarien im wirklichen Leben nicht einmal existieren (natürlich sind sie höchstwahrscheinlich nicht im Datensatz vor dem Training enthalten). ). Darüber hinaus bestätigen diese generierten Beispiele den Vorteil des Vortrainings von BriVL für schwach semantisch verwandte Daten (da eine feinkörnige regionale Wortausrichtung die Vorstellungskraft von BriVL beeinträchtigen würde).

Abbildung 9: Weitere BriVL-Textgenerierungsergebnisse, deren Konzepte/Szenen von Menschen normalerweise nicht gesehen werden oder im wirklichen Leben gar nicht existieren.
Darüber hinaus haben wir BriVL auch auf mehrere nachgelagerte Aufgaben wie die Zero-Shot-Klassifizierung von Fernerkundungsbildern, die Zero-Shot-Klassifizierung chinesischer Nachrichten, die visuelle Beantwortung von Fragen usw. angewendet und einige interessante Ergebnisse erzielt siehe den Originaltext unseres Artikels.
Fazit und Diskussion
Wir haben ein groß angelegtes multimodales Basismodell namens BriVL entwickelt, das auf 650 Millionen schwach semantisch verwandten Bildern und Texten trainiert wurde. Wir demonstrieren intuitiv den ausgerichteten Bild-Text-Einbettungsraum durch Visualisierung neuronaler Netzwerke und textgenerierte Diagramme. Darüber hinaus zeigen Experimente zu anderen nachgelagerten Aufgaben auch die domänenübergreifenden Lern-/Transferfähigkeiten von BriVL und die Vorteile des multimodalen Lernens gegenüber dem einmodalen Lernen. Insbesondere stellten wir fest, dass BriVL offenbar eine gewisse Vorstellungs- und Denkfähigkeit erworben hat. Wir glauben, dass diese Vorteile hauptsächlich auf der Annahme einer schwachen semantischen Korrelation beruhen, die von BriVL verfolgt wird. Das heißt, durch die Analyse komplexer menschlicher Emotionen und Gedanken in schwach korrelierten Bild-Text-Paaren wird unser BriVL kognitiver.
Wir glauben, dass dieser Schritt, den wir in Richtung allgemeiner künstlicher Intelligenz unternehmen, weitreichende Auswirkungen nicht nur auf den Bereich der künstlichen Intelligenz selbst, sondern auch auf verschiedene KI + -Bereiche haben wird. Für die Forschung im Bereich der künstlichen Intelligenz können Forscher BriVL auf der Grundlage unseres GPU-ressourcensparenden multimodalen Pre-Training-Frameworks problemlos auf größere Größenordnungen und mehr Modalitäten erweitern, um ein allgemeineres Basismodell zu erhalten. Mit Hilfe groß angelegter multimodaler Basismodelle ist es für Forscher auch einfacher, neue Aufgaben zu erkunden (insbesondere solche ohne ausreichende menschliche Annotationsproben). Für den KI+-Bereich kann sich das Basismodell aufgrund seiner starken Generalisierungsfähigkeiten schnell an spezifische Arbeitsumgebungen anpassen. Beispielsweise können multimodale Basismodelle im Bereich des Gesundheitswesens multimodale Daten von Fällen vollständig nutzen, um die Genauigkeit der Diagnose zu verbessern. Im Bereich der Neurowissenschaften können multimodale Basismodelle sogar dabei helfen, herauszufinden, wie multimodale Informationen in Mechanismen funktionieren Fusion im menschlichen Gehirn, da künstliche neuronale Netze einfacher zu untersuchen sind als echte neuronale Systeme im menschlichen Gehirn.
Dennoch sind multimodale Basismodelle immer noch mit einigen Risiken und Herausforderungen konfrontiert. Das Basismodell lernt möglicherweise Vorurteile und Stereotypen über bestimmte Dinge, und diese Probleme sollten vor dem Modelltraining sorgfältig behandelt und in nachgelagerten Anwendungen überwacht und behandelt werden. Darüber hinaus müssen wir, da das Grundmodell immer mehr Fähigkeiten erlangt, darauf achten, dass es nicht von Menschen mit bösen Absichten missbraucht wird, um negative Auswirkungen auf die Gesellschaft zu vermeiden. Darüber hinaus gibt es auch einige Herausforderungen in der zukünftigen Forschung zum Basismodell: Wie können tiefergehende Werkzeuge zur Modellinterpretierbarkeit entwickelt werden, wie können Datensätze vor dem Training mit mehr Modalitäten erstellt werden und wie können effektivere Feinabstimmungstechniken verwendet werden, um das Basismodell zu transformieren? Modell angewendet auf verschiedene nachgelagerte Aufgaben.
Die Autoren dieses Artikels sind: Fei Nanyi, Lu Zhiwu, Gao Yizhao, Yang Guoxing, Huo Yuqi, Wen Jingyuan, Lu Haoyu, Song Ruihua, Gao Xin, Xiang Tao, Sun Hao, Wen Jirong; Korrespondierender Autor ist NPC Gao Ling Professor Lu Zhiwu, ständiger außerordentlicher Professor Sun Hao und Professor Wen Jirong von der School of Artificial Intelligence. Der Artikel wurde in der internationalen Fachzeitschrift „Nature Communications“ (englischer Name: Nature Communications, abgekürzt Nat Commun) veröffentlicht. Dieses Papier wurde von Fei Nanyi interpretiert.
Das obige ist der detaillierte Inhalt vonDie Unterzeitschrift „Nature' der Hillhouse School of Artificial Intelligence der Renmin University versucht, mithilfe multimodaler Grundmodelle den Weg zur allgemeinen künstlichen Intelligenz zu ebnen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1381
1381
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
