
 Technologie-Peripheriegeräte
KI
Das schnelle und genaue Zielerkennungs-Framework von YOLOv6 ist Open Source
Technologie-Peripheriegeräte
KI
Das schnelle und genaue Zielerkennungs-Framework von YOLOv6 ist Open Source
Das schnelle und genaue Zielerkennungs-Framework von YOLOv6 ist Open Source

Autoren: Chu Yi, Kai Heng usw.
Kürzlich hat die Abteilung für visuelle Intelligenz von Meituan YOLOv6 entwickelt, ein Zielerkennungs-Framework für industrielle Anwendungen, das sich sowohl auf Erkennungsgenauigkeit als auch auf Argumentationseffizienz konzentrieren kann. Während des Forschungs- und Entwicklungsprozesses forschte und optimierte die Abteilung für visuelle Intelligenz weiter und stützte sich dabei auf einige hochmoderne Entwicklungen und wissenschaftliche Forschungsergebnisse aus Wissenschaft und Industrie. Experimentelle Ergebnisse mit COCO, dem maßgeblichen Zielerkennungsdatensatz, zeigen, dass YOLOv6 andere Algorithmen derselben Größe in Bezug auf Erkennungsgenauigkeit und -geschwindigkeit übertrifft. Es unterstützt auch die Bereitstellung verschiedener Plattformen, was die Anpassungsarbeit während der Projektbereitstellung erheblich vereinfacht . Dies ist Open Source, in der Hoffnung, mehr Studenten zu helfen.
1. Übersicht
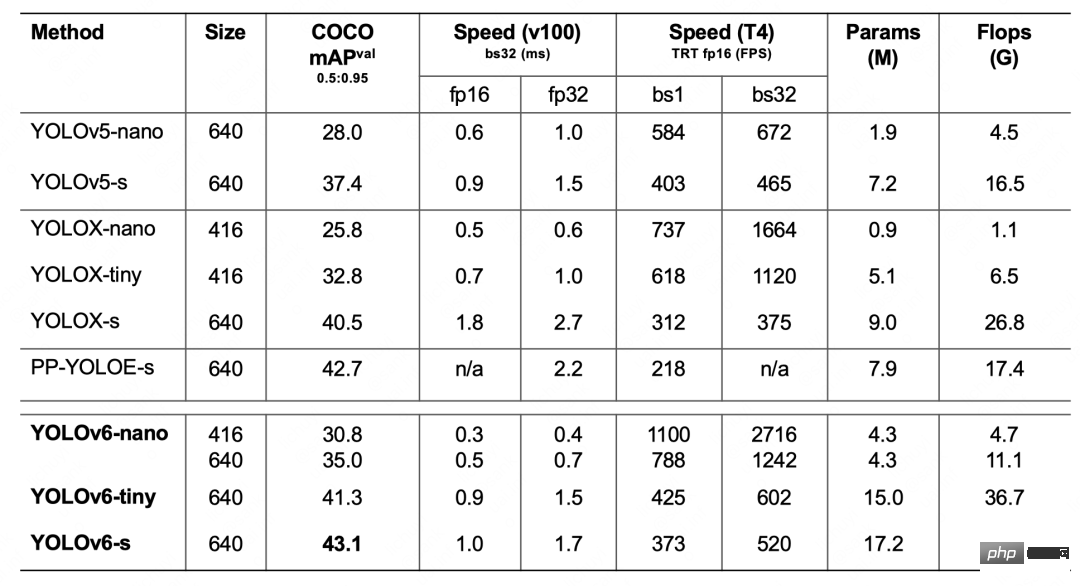
YOLOv6 ist ein Zielerkennungs-Framework, das von der Abteilung für visuelle Intelligenz von Meituan entwickelt wurde und für industrielle Anwendungen bestimmt ist. Dieses Framework konzentriert sich sowohl auf die Erkennungsgenauigkeit als auch auf die Inferenzeffizienz. Zu den in der Branche am häufigsten verwendeten Größenmodellen gehört: YOLOv6-nano hat eine Genauigkeit von bis zu 35,0 % AP auf COCO und eine Inferenzgeschwindigkeit von bis zu 1242 FPS T4; YOLOv6 – Die Genauigkeit von s auf COCO kann 43,1 % AP erreichen, und die Inferenzgeschwindigkeit auf T4 kann 520 FPS erreichen. In Bezug auf die Bereitstellung unterstützt YOLOv6 die Bereitstellung verschiedener Plattformen wie GPU (TensorRT), CPU (OPENVINO), ARM (MNN, TNN, NCNN), was die Anpassungsarbeiten während der Projektbereitstellung erheblich vereinfacht. Derzeit ist das Projekt als Open Source auf Github verfügbar, Portal: YOLOv6. Freunde in Not sind bei Star herzlich willkommen, es abzuholen und jederzeit darauf zuzugreifen.
Ein neues Framework mit weitaus höherer Genauigkeit und Geschwindigkeit als YOLOv5 und YOLOX
Die Objekterkennung als Basistechnologie im Bereich Computer Vision ist in der Branche weit verbreitet, wobei die Algorithmen der YOLO-Serie umfassender sind Leistung und wird nach und nach zum bevorzugten Rahmen für die meisten industriellen Anwendungen. Bisher hat die Branche viele YOLO-Erkennungsframeworks abgeleitet, von denen YOLOv5[1], YOLOX[2] und PP-YOLOE[3] die repräsentativsten sind. Im tatsächlichen Einsatz haben wir jedoch festgestellt, dass dies der Fall ist Bei den oben genannten Frameworks gibt es hinsichtlich Geschwindigkeit und Genauigkeit noch viel Raum für Verbesserungen. Auf dieser Grundlage haben wir ein neues Zielerkennungs-Framework – YOLOv6 – entwickelt, indem wir bestehende fortschrittliche Technologien in der Branche erforscht und darauf zurückgegriffen haben. Das Framework unterstützt die gesamte Kette industrieller Anwendungsanforderungen wie Modelltraining, Inferenz und plattformübergreifende Bereitstellung und hat eine Reihe von Verbesserungen und Optimierungen auf Algorithmusebene vorgenommen, z. B. Netzwerkstruktur und Trainingsstrategien am COCO-Datensatz YOLOv6 Die relevanten Ergebnisse sind in Abbildung 1 dargestellt und übertreffen sowohl Genauigkeit als auch Geschwindigkeit:
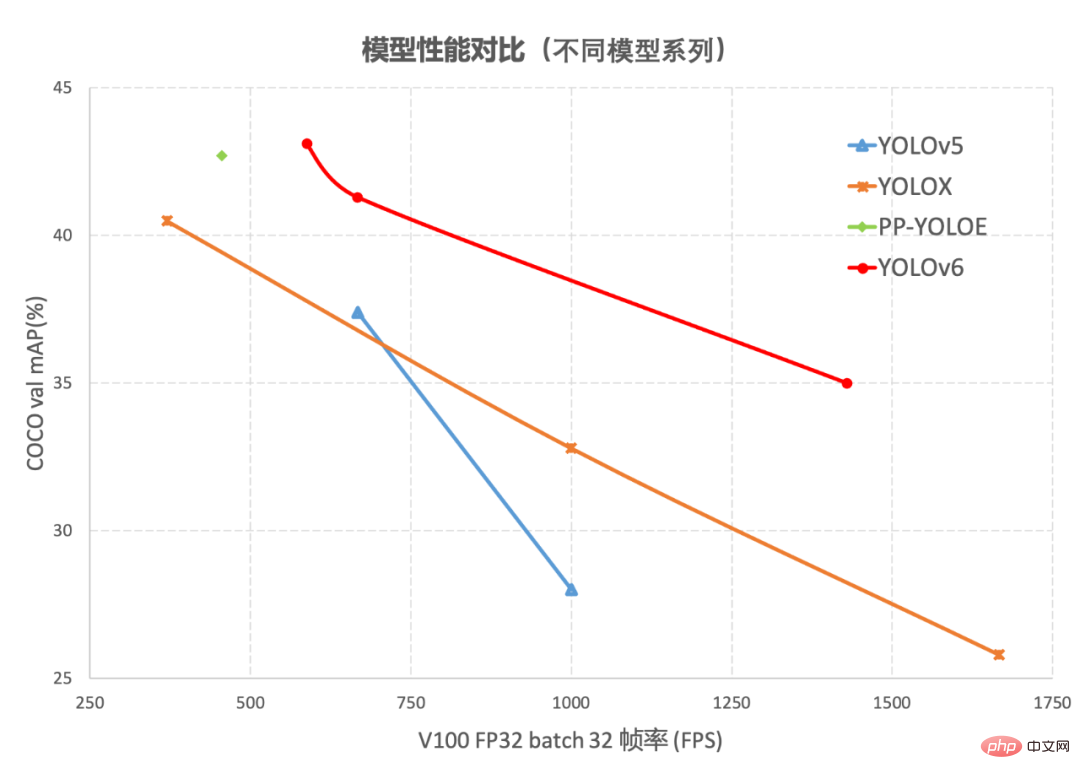
Abbildung 1-1 Leistungsvergleich von YOLOv6-Modellen verschiedener Größen und anderen Modellen
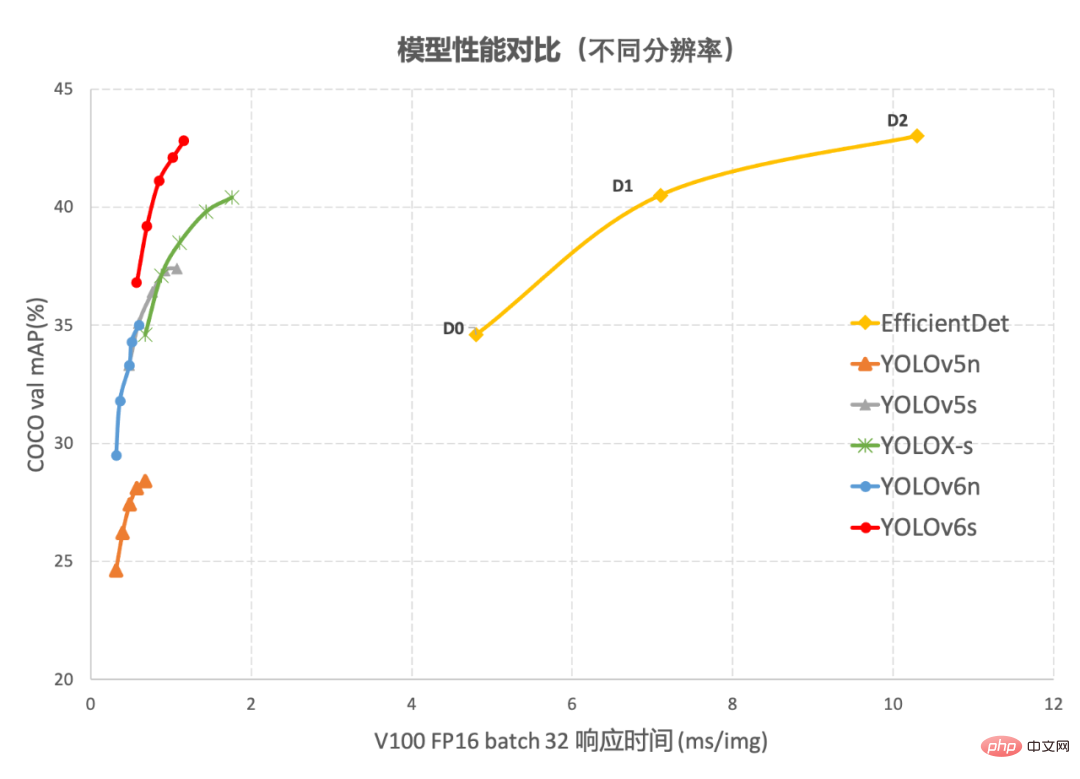
Abbildung 1-2 YOLOv6 Leistungsvergleich mit anderen Modellen bei unterschiedlichen Auflösungen Abbildung 1-1 zeigt den Leistungsvergleich jedes Erkennungsalgorithmus unter Netzwerken unterschiedlicher Größe. Die Punkte auf der Kurve stellen jeweils die dar Leistung des Erkennungsalgorithmus unter Netzwerkmodellen unterschiedlicher Größe (s /winzig/nano) Wie aus der Abbildung ersichtlich ist, übertrifft YOLOv6 andere Algorithmen der YOLO-Serie derselben Größe in Bezug auf Genauigkeit und Geschwindigkeit. Abbildung 1-2 zeigt den Leistungsvergleich jedes Erkennungsnetzwerkmodells, wenn sich die Eingabeauflösung ändert. Die Punkte auf der Kurve von links nach rechts stellen dar, wenn die Bildauflösung sequentiell zunimmt (384/448/512/576/640). Leistung dieses Modells, wie aus der Abbildung ersichtlich ist, behält YOLOv6 unter verschiedenen Auflösungen immer noch einen großen Leistungsvorteil bei.
2. Einführung in die Schlüsseltechnologien von YOLOv6
YOLOv6 hat viele Verbesserungen vor allem in den Bereichen Rückgrat, Nacken, Kopf und Trainingsstrategien vorgenommen:
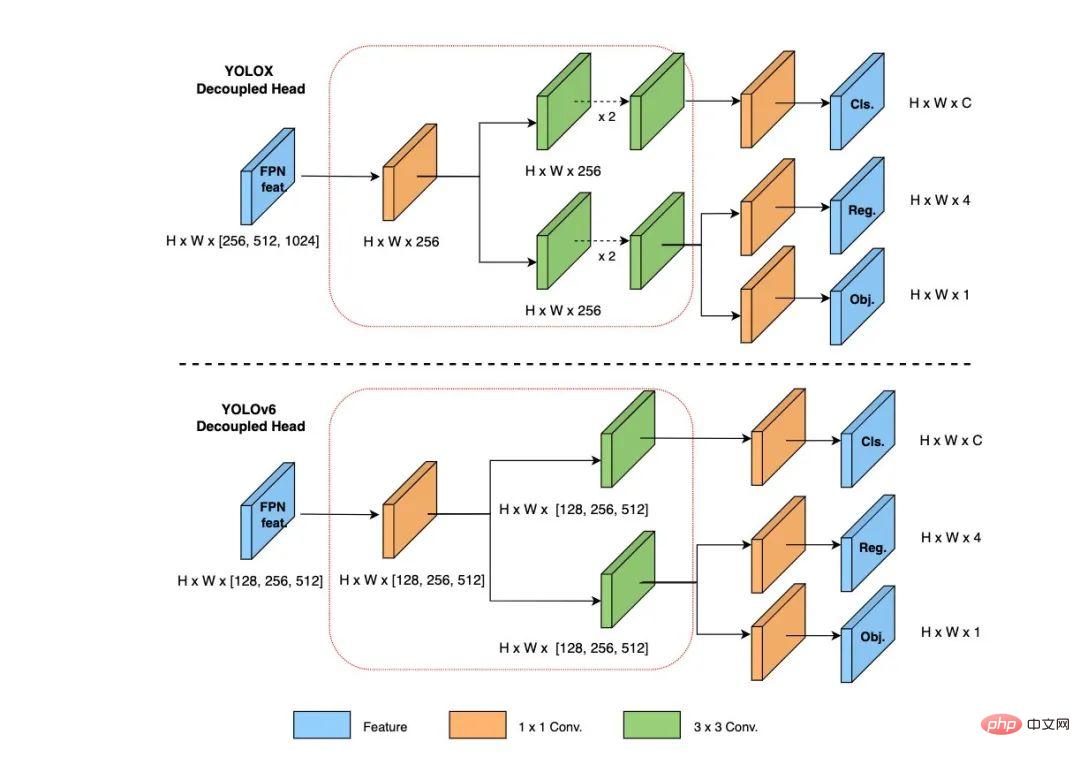
- Wir haben ein effizienteres Backbone und einen Hals auf einheitliche Weise entworfen: Inspiriert von den Designideen hardwarebewusster neuronaler Netze haben wir reparametrisierbare und effizientere Backbone-Netzwerke EfficientRep Backbone und Rep-PAN basierend auf dem RepVGG-Stil entworfen[4 ] Hals.
- Optimiert und entwickelt ein prägnanterer und effektiverer, effizienter entkoppelter Kopf, der den zusätzlichen Verzögerungsaufwand, der durch allgemeine entkoppelte Köpfe verursacht wird, weiter reduziert und gleichzeitig die Genauigkeit beibehält.
- In Bezug auf die Trainingsstrategie verwenden wir das Anker-freie Anker-freie Paradigma, ergänzt durch SimOTA[2] Etikettenzuordnungsstrategie und SIoU[9] Bounding-Box-Regressionsverlust, um die Erkennungsgenauigkeit weiter zu verbessern.
2.1 Hardwarefreundliches Backbone-Netzwerkdesign
Das von YOLOv5/YOLOX verwendete Backbone und Neck basieren beide auf CSPNet[5] und verwenden einen Multi-Branch-Ansatz und eine Reststruktur. Bei Hardware wie GPUs erhöht diese Struktur die Latenz bis zu einem gewissen Grad und verringert die Auslastung der Speicherbandbreite. Abbildung 2 unten ist eine Einführung in das Roofline-Modell[8] im Bereich der Computerarchitektur und zeigt die Beziehung zwischen Rechenleistung und Speicherbandbreite in Hardware.
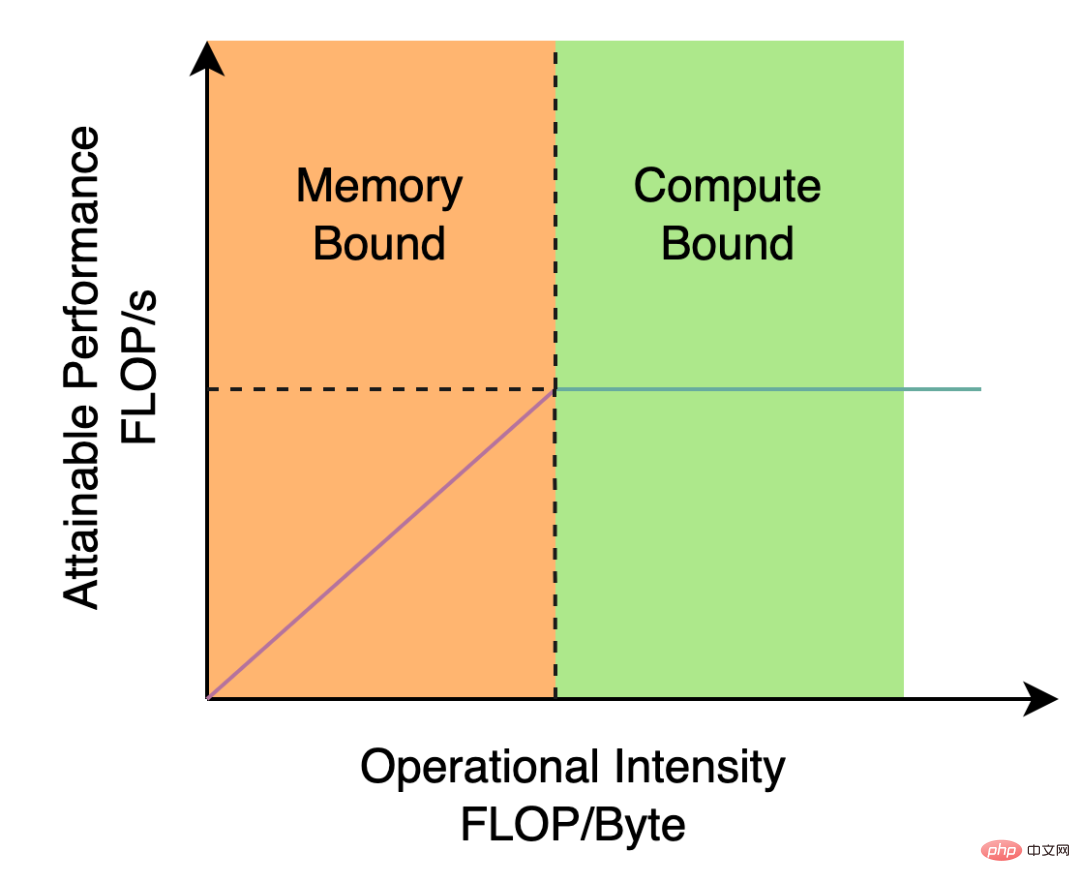
Abbildung 2 Einführungsdiagramm des Dachlinienmodells
Also haben wir Backbone und Neck basierend auf der Idee des hardwarebewussten neuronalen Netzwerkdesigns neu gestaltet und optimiert. Diese Idee basiert auf den Eigenschaften der Hardware und den Eigenschaften des Inferenz-Frameworks/Kompilierungs-Frameworks. Beim Aufbau des Netzwerks werden die Hardware-Rechenleistung und die Speicherbandbreite umfassend berücksichtigt , Kompilierungsoptimierungseigenschaften, Netzwerkdarstellungsfunktionen usw. und dann Erhalten Sie eine schnelle und gute Netzwerkstruktur. Für die beiden oben genannten neu gestalteten Erkennungskomponenten nennen wir sie in YOLOv6 EfficientRep Backbone bzw. Rep-PAN Neck. Ihre Hauptbeiträge sind:
- Einführung der RepVGG-Stilstruktur. Rückgrat und Nacken werden basierend auf der Idee des Hardware-Bewusstseins neu gestaltet.
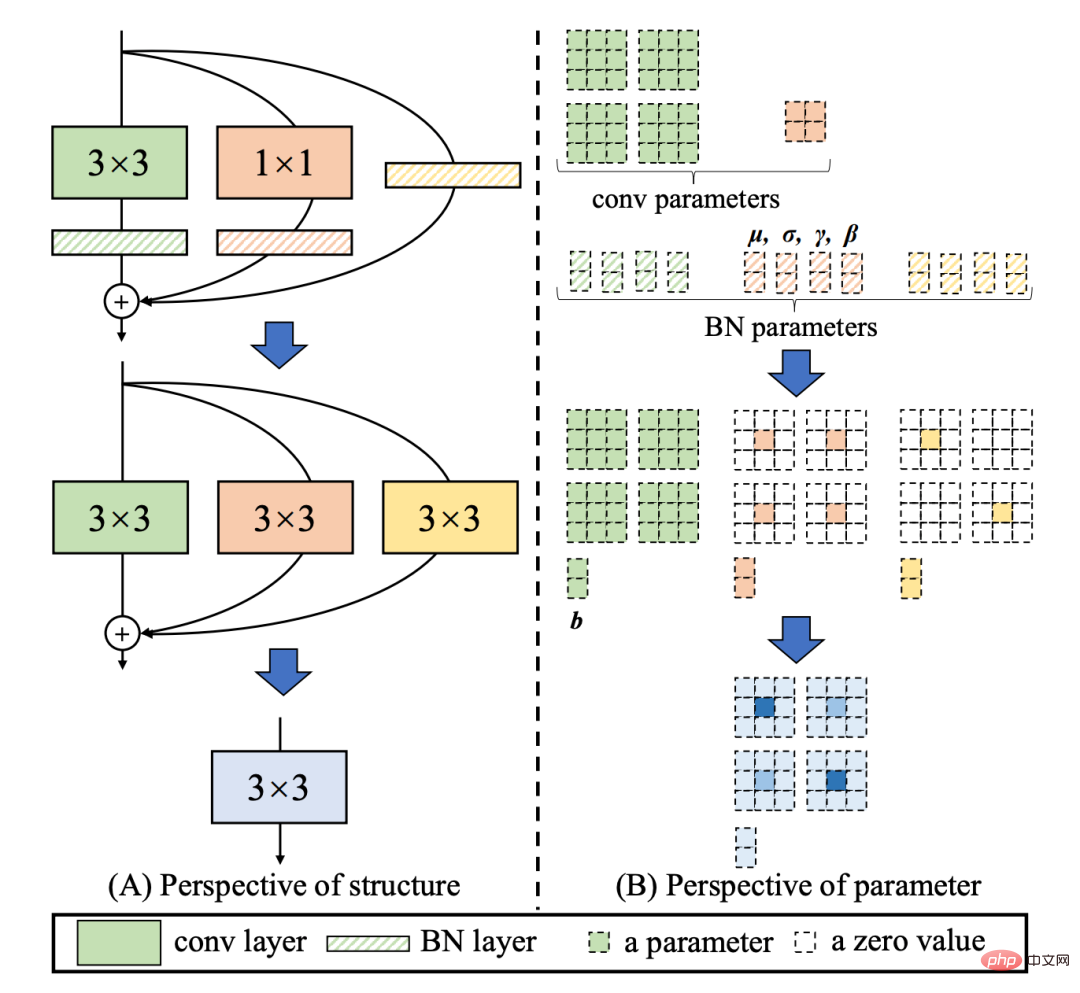
[4] Die Style-Struktur ist eine reparametrisierbare Struktur, die während des Trainings eine Topologie mit mehreren Zweigen aufweist und während der tatsächlichen Bereitstellung äquivalent zu einer einzelnen 3x3-Faltung verschmolzen werden kann (Fusion Der Prozess ist in Abbildung 3 dargestellt unten). Durch die verschmolzene 3x3-Faltungsstruktur kann die Rechenleistung rechenintensiver Hardware (wie GPU) effektiv genutzt werden, und es kann auch die Hilfe von NVIDIA cuDNN- und Intel MKL-Kompilierungsframeworks in Anspruch genommen werden, die auf GPU/CPU stark optimiert wurden .
Experimente zeigen, dass YOLOv6 durch die obige Strategie Hardwareverzögerungen reduziert und die Genauigkeit des Algorithmus erheblich verbessert, wodurch das Erkennungsnetzwerk schneller und stärker wird. Am Beispiel des Nano-Modells verbessert diese Methode im Vergleich zur von YOLOv5-nano verwendeten Netzwerkstruktur die Geschwindigkeit um 21 % und die Genauigkeit um 3,6 % AP. Abbildung 3: Fusionsprozess des Rep-Operators [4] Im Vergleich zum in YOLOv5 verwendeten CSP-Backbone kann dieses Backbone die Rechenleistung der Hardware (z. B. GPU) effizient nutzen und verfügt außerdem über starke Darstellungsfähigkeiten.Abbildung 4 unten ist das spezifische Designstrukturdiagramm von EfficientRep Backbone. Wir haben die gewöhnliche Conv-Ebene mit Schritt = 2 im Backbone durch die RepConv-Ebene mit Schritt = 2 ersetzt. Gleichzeitig wird der ursprüngliche CSP-Block in RepBlock umgestaltet, wobei der erste RepConv von RepBlock die Kanaldimension transformiert und ausrichtet. Darüber hinaus optimieren wir den ursprünglichen SPPF zu einem effizienteren SimSPPF. Abbildung 4: EfficientRep Backbone-Strukturdiagramm Basierend auf der Idee des hardwarebewussten neuronalen Netzwerkdesigns wird eine effektivere Feature-Fusion-Netzwerkstruktur für YOLOv6 entwickelt.
Rep-PAN basiert auf der PAN[6]-Topologie, verwendet RepBlock, um den in YOLOv5 verwendeten CSP-Block zu ersetzen, und passt gleichzeitig die Operatoren im gesamten Neck an, um eine effiziente Argumentation zu erreichen Hardware. Behält gute Multiskalen-Feature-Fusion-Fähigkeiten bei (Rep-PAN-Strukturdiagramm ist in Abbildung 5 unten dargestellt). Abbildung 5 Rep-PAN-Strukturdiagramm Der Erkennungskopf des ursprünglichen YOLOv5 wird durch Zusammenführen und Teilen der Klassifizierungs- und Regressionszweige implementiert, während der Erkennungskopf von YOLOX die Klassifizierungs- und Regressionszweige entkoppelt und zwei zusätzliche 3x3-Faltungsschichten hinzufügt. Die Erkennungsgenauigkeit wird zwar verbessert, aber das Netzwerk Die Verzögerung wird bis zu einem gewissen Grad erhöht.
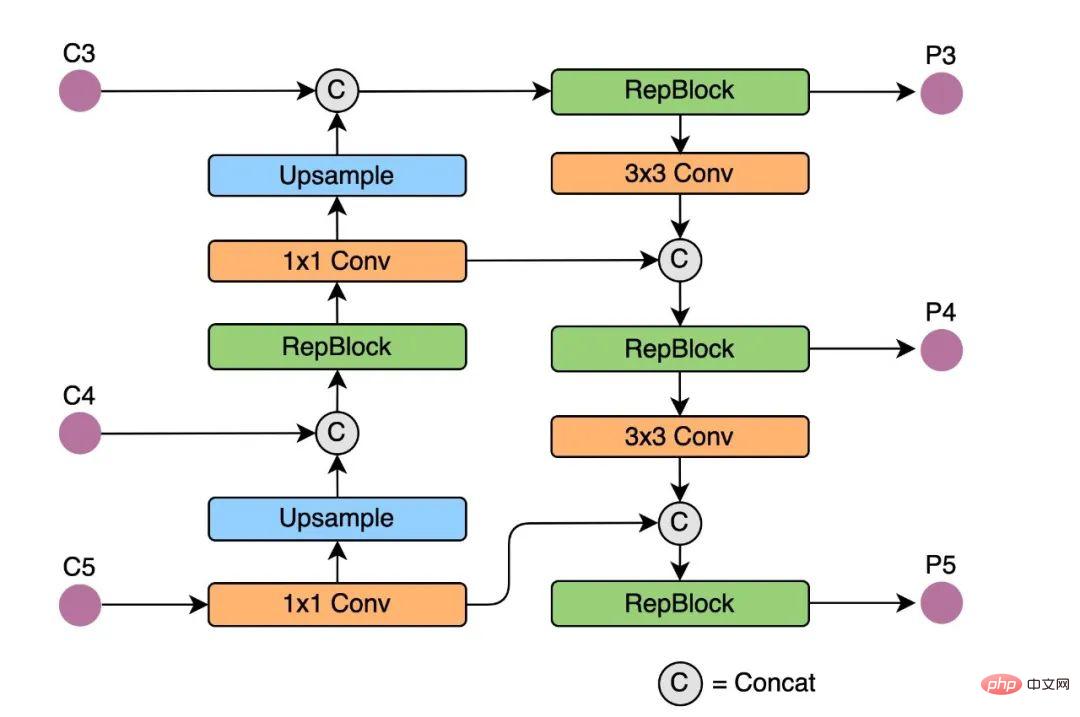 Aus diesem Grund haben wir das Design des Entkopplungskopfs optimiert und dabei das Gleichgewicht zwischen den zugehörigen Bedienerdarstellungsfunktionen und dem Hardware-Rechenaufwand berücksichtigt und mithilfe der Hybrid-Channels-Strategie einen effizienteren Entkopplungskopf neu entworfen. Die Struktur reduziert die Verzögerung bei gleichzeitiger Beibehaltung der Genauigkeit und verringert den zusätzlichen Verzögerungsaufwand, der durch die 3x3-Faltung im Entkopplungskopf verursacht wird. Durch die Durchführung von Ablationsexperimenten an einem Nanomodell und den Vergleich der Entkopplungskopfstruktur mit der gleichen Anzahl von Kanälen wird die Genauigkeit um 0,2 % AP und die Geschwindigkeit um 6,8 % erhöht.
Aus diesem Grund haben wir das Design des Entkopplungskopfs optimiert und dabei das Gleichgewicht zwischen den zugehörigen Bedienerdarstellungsfunktionen und dem Hardware-Rechenaufwand berücksichtigt und mithilfe der Hybrid-Channels-Strategie einen effizienteren Entkopplungskopf neu entworfen. Die Struktur reduziert die Verzögerung bei gleichzeitiger Beibehaltung der Genauigkeit und verringert den zusätzlichen Verzögerungsaufwand, der durch die 3x3-Faltung im Entkopplungskopf verursacht wird. Durch die Durchführung von Ablationsexperimenten an einem Nanomodell und den Vergleich der Entkopplungskopfstruktur mit der gleichen Anzahl von Kanälen wird die Genauigkeit um 0,2 % AP und die Geschwindigkeit um 6,8 % erhöht.
Abbildung 6: Effizientes entkoppeltes Kopfstrukturdiagramm
2.3 Effektivere Trainingsstrategie
Um die Erkennungsgenauigkeit weiter zu verbessern, haben wir den fortgeschrittenen Forschungsfortschritt anderer Erkennungsrahmen in der Wissenschaft und im akademischen Bereich aufgenommen und daraus gelernt Branche: Ankerfreies Ankerfreies Paradigma, SimOTA-Label-Zuweisungsstrategie und SIoU-Bounding-Box-Regressionsverlust.Ankerfreies ankerfreies Paradigma
YOLOv6 verwendet eine prägnantere ankerfreie Erkennungsmethode. Da ankerbasierte Detektoren vor dem Training eine Clusteranalyse durchführen müssen, um den optimalen Ankersatz zu bestimmen, erhöht dies in gewissem Maße die Komplexität des Detektors und führt in einigen Edge-End-Anwendungen zu einer großen Anzahl von Erkennungsergebnissen Die Notwendigkeit, zwischen Hardwareschritten transportiert zu werden, führt ebenfalls zu zusätzlichen Verzögerungen. Das ankerfreie ankerfreie Paradigma wurde in den letzten Jahren aufgrund seiner starken Generalisierungsfähigkeit und einfacheren Decodierungslogik häufig verwendet. Nach experimentellen Untersuchungen zu Anchor-Free haben wir festgestellt, dass der Anchor-Free-Detektor im Vergleich zu der zusätzlichen Verzögerung, die durch die Komplexität des Anchor-basierten Detektors verursacht wird, eine Geschwindigkeitsverbesserung von 51 % aufweist.
SimOTA-Label-Zuweisungsstrategie
Um mehr qualitativ hochwertige positive Proben zu erhalten, führt YOLOv6 den SimOTA-Algorithmus
[4]ein, um positive Proben dynamisch zuzuweisen und so die Erkennungsgenauigkeit weiter zu verbessern. Die Etikettenzuordnungsstrategie von YOLOv5 basiert auf dem Shape-Matching und erhöht die Anzahl positiver Proben durch die gitterübergreifende Matching-Strategie, wodurch das Netzwerk schnell konvergiert. Diese Methode ist jedoch eine statische Zuordnungsmethode und wird nicht mit der angepasst Prozess des Netzwerktrainings.
In den letzten Jahren sind viele Methoden entstanden, die auf der dynamischen Etikettenzuweisung basieren. Solche Methoden werden positive Proben basierend auf der Netzwerkausgabe während des Trainingsprozesses zuweisen und dadurch mehr hochwertige positive Proben generieren, was wiederum das Netzwerk fördert Optimierung. OTA[7] modelliert beispielsweise den Sample-Matching als optimales Übertragungsproblem und ermittelt die beste Sample-Matching-Strategie unter globalen Informationen, um die Genauigkeit zu verbessern. OTA verwendet jedoch den Sinkhorn-Knopp-Algorithmus, der die Trainingszeit verlängert [4]
Der Algorithmus verwendet die Top-K-Approximationsstrategie, um die beste Übereinstimmung der Stichproben zu erhalten, was das Training erheblich beschleunigt. Daher übernimmt YOLOv6 die dynamische Zuordnungsstrategie von SimOTA und kombiniert sie mit dem ankerfreien Paradigma, um die durchschnittliche Erkennungsgenauigkeit beim Nanomodell um 1,3 % AP zu erhöhen.
SIoU-Bounding-Box-Regressionsverlust
Um die Regressionsgenauigkeit weiter zu verbessern, verwendet YOLOv6 die SIoU[9]Bounding-Box-Regressionsverlustfunktion, um das Lernen des Netzwerks zu überwachen. Das Training von Zielerkennungsnetzwerken erfordert im Allgemeinen die Definition von mindestens zwei Verlustfunktionen: Klassifizierungsverlust und Bounding-Box-Regressionsverlust, und die Definition der Verlustfunktion hat oft einen größeren Einfluss auf die Erkennungsgenauigkeit und Trainingsgeschwindigkeit. In den letzten Jahren gehören zu den häufig verwendeten Bounding-Box-Regressionsverlusten IoU-, GIoU-, CIoU-, DIoU-Verluste usw. Diese Verlustfunktionen berücksichtigen den Grad der Überlappung, den Mittelpunktabstand und das Seitenverhältnis zwischen den Vorhersagerahmen und der Zielrahmen und andere Faktoren, um die Lücke zwischen den beiden zu messen und so das Netzwerk so zu steuern, dass der Verlust minimiert wird, um die Regressionsgenauigkeit zu verbessern. Diese Methoden berücksichtigen jedoch nicht die Übereinstimmung der Richtung zwischen der Vorhersagebox und der Zielbox . Die SIoU-Verlustfunktion definiert den Distanzverlust neu, indem sie den Vektorwinkel zwischen erforderlichen Regressionen einführt, wodurch der Freiheitsgrad der Regression effektiv verringert, die Netzwerkkonvergenz beschleunigt und die Regressionsgenauigkeit weiter verbessert wird. Durch die Verwendung des SIoU-Verlusts für Experimente mit YOLOv6s wird die durchschnittliche Erkennungsgenauigkeit im Vergleich zum CIoU-Verlust um 0,3 % AP erhöht. Nach den oben genannten Optimierungsstrategien und Verbesserungen hat YOLOv6 in mehreren Modellen unterschiedlicher Größe eine hervorragende Leistung erzielt. Tabelle 1 unten zeigt die experimentellen Ablationsergebnisse von YOLOv6-nano. Aus den experimentellen Ergebnissen können wir ersehen, dass unser selbst entwickeltes Erkennungsnetzwerk große Fortschritte in Bezug auf Genauigkeit und Geschwindigkeit gebracht hat. Tabelle 1 YOLOv6-Nano-Ablations-ExperimentergebnisseTabelle 2 unten zeigt YOLOv6 und andere derzeit gängige Algorithmen der YOLO-Serie. Vergleichsexperiment Ergebnisse. Wie aus der Tabelle ersichtlich ist: Tabelle 2 Vergleich der Leistung jedes Größenmodells von YOLOv6 mit anderen models#🎜🎜 # Dieser Artikel stellt die Arbeit von Meituans Visual Intelligence vor Abteilung Basierend auf der Optimierung und praktischen Erfahrung des Zielerkennungs-Frameworks haben wir die Trainingsstrategie, das Backbone-Netzwerk, die Multi-Scale-Feature-Fusion, den Erkennungskopf usw. für das YOLO-Serien-Framework durchdacht und optimiert und ein neues Erkennungs-Framework entworfen – YOLOv6 Die ursprüngliche Absicht bestand darin, praktische Probleme zu lösen, die bei der Implementierung industrieller Anwendungen auftreten. Beim Aufbau des YOLOv6-Frameworks haben wir einige neue Methoden erforscht und optimiert, wie zum Beispiel das selbst entwickelte EfficientRep Backbone und Rep-Neck basierend auf hardwarebewussten Designideen für neuronale Netze . und Efficient De Coupled Head, aber auch einige hochmoderne Fortschritte und Ergebnisse aus Wissenschaft und Industrie, wie z. B. Anchor-Free, SimOTA und SIoU-Regressionsverlust. Experimentelle Ergebnisse des COCO-Datensatzes zeigen, dass YOLOv6 hinsichtlich Erkennungsgenauigkeit und -geschwindigkeit zu den Besten gehört. In Zukunft werden wir das YOLOv6-Ökosystem weiter aufbauen und verbessern. Die Hauptarbeit umfasst die folgenden Aspekte: #🎜🎜 #3. Experimentelle Ergebnisse

4. Zusammenfassung und Ausblick
Verbessern Sie die gesamte Palette der YOLOv6-Modelle und verbessern Sie weiterhin die Erkennungsleistung.
Das obige ist der detaillierte Inhalt vonDas schnelle und genaue Zielerkennungs-Framework von YOLOv6 ist Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Zehn empfohlene Open-Source-Tools für kostenlose Textanmerkungen
Mar 26, 2024 pm 08:20 PM
Zehn empfohlene Open-Source-Tools für kostenlose Textanmerkungen
Mar 26, 2024 pm 08:20 PM
Bei der Textanmerkung handelt es sich um die Arbeit mit entsprechenden Beschriftungen oder Tags für bestimmte Inhalte im Text. Sein Hauptzweck besteht darin, zusätzliche Informationen zum Text für eine tiefere Analyse und Verarbeitung bereitzustellen, insbesondere im Bereich der künstlichen Intelligenz. Textanmerkungen sind für überwachte maschinelle Lernaufgaben in Anwendungen der künstlichen Intelligenz von entscheidender Bedeutung. Es wird zum Trainieren von KI-Modellen verwendet, um Textinformationen in natürlicher Sprache genauer zu verstehen und die Leistung von Aufgaben wie Textklassifizierung, Stimmungsanalyse und Sprachübersetzung zu verbessern. Durch Textanmerkungen können wir KI-Modellen beibringen, Entitäten im Text zu erkennen, den Kontext zu verstehen und genaue Vorhersagen zu treffen, wenn neue ähnliche Daten auftauchen. In diesem Artikel werden hauptsächlich einige bessere Open-Source-Textanmerkungstools empfohlen. 1.LabelStudiohttps://github.com/Hu
 15 empfohlene kostenlose Open-Source-Bildanmerkungstools
Mar 28, 2024 pm 01:21 PM
15 empfohlene kostenlose Open-Source-Bildanmerkungstools
Mar 28, 2024 pm 01:21 PM
Bei der Bildanmerkung handelt es sich um das Verknüpfen von Beschriftungen oder beschreibenden Informationen mit Bildern, um dem Bildinhalt eine tiefere Bedeutung und Erklärung zu verleihen. Dieser Prozess ist entscheidend für maschinelles Lernen, das dabei hilft, Sehmodelle zu trainieren, um einzelne Elemente in Bildern genauer zu identifizieren. Durch das Hinzufügen von Anmerkungen zu Bildern kann der Computer die Semantik und den Kontext hinter den Bildern verstehen und so den Bildinhalt besser verstehen und analysieren. Die Bildanmerkung hat ein breites Anwendungsspektrum und deckt viele Bereiche ab, z. B. Computer Vision, Verarbeitung natürlicher Sprache und Diagramm-Vision-Modelle. Sie verfügt über ein breites Anwendungsspektrum, z. B. zur Unterstützung von Fahrzeugen bei der Identifizierung von Hindernissen auf der Straße und bei der Erkennung und Diagnose von Krankheiten durch medizinische Bilderkennung. In diesem Artikel werden hauptsächlich einige bessere Open-Source- und kostenlose Bildanmerkungstools empfohlen. 1.Makesens
 So gelangen Sie zum Meituan-Imbissschalter
Apr 08, 2024 pm 03:41 PM
So gelangen Sie zum Meituan-Imbissschalter
Apr 08, 2024 pm 03:41 PM
1. Wenn der Zusteller das Essen in den Schrank stellt, benachrichtigt er den Kunden per SMS, Telefonanruf oder Meituan-Nachricht, das Essen abzuholen. 2. Kunden können den QR-Code auf dem Lebensmittelschrank über die WeChat- oder Meituan-App scannen, um auf das Smart Food Cabinet-Applet zuzugreifen. 3. Geben Sie den Abholcode ein oder nutzen Sie die Funktion „Schranköffnung mit einem Klick“, um ganz einfach die Schranktür zu öffnen und den Imbiss herauszunehmen.
 Empfohlen: Ausgezeichnetes JS-Open-Source-Projekt zur Gesichtserkennung und -erkennung
Apr 03, 2024 am 11:55 AM
Empfohlen: Ausgezeichnetes JS-Open-Source-Projekt zur Gesichtserkennung und -erkennung
Apr 03, 2024 am 11:55 AM
Die Technologie zur Gesichtserkennung und -erkennung ist bereits eine relativ ausgereifte und weit verbreitete Technologie. Derzeit ist JS die am weitesten verbreitete Internetanwendungssprache. Die Implementierung der Gesichtserkennung und -erkennung im Web-Frontend hat im Vergleich zur Back-End-Gesichtserkennung Vor- und Nachteile. Zu den Vorteilen gehören die Reduzierung der Netzwerkinteraktion und die Echtzeiterkennung, was die Wartezeit des Benutzers erheblich verkürzt und das Benutzererlebnis verbessert. Die Nachteile sind: Es ist durch die Größe des Modells begrenzt und auch die Genauigkeit ist begrenzt. Wie implementiert man mit js die Gesichtserkennung im Web? Um die Gesichtserkennung im Web zu implementieren, müssen Sie mit verwandten Programmiersprachen und -technologien wie JavaScript, HTML, CSS, WebRTC usw. vertraut sein. Gleichzeitig müssen Sie auch relevante Technologien für Computer Vision und künstliche Intelligenz beherrschen. Dies ist aufgrund des Designs der Webseite erwähnenswert
 So rufen Sie das vergessene Zahlungspasswort von Meituan ab_So rufen Sie das vergessene Zahlungspasswort von Meituan ab
Mar 28, 2024 pm 03:29 PM
So rufen Sie das vergessene Zahlungspasswort von Meituan ab_So rufen Sie das vergessene Zahlungspasswort von Meituan ab
Mar 28, 2024 pm 03:29 PM
1. Zuerst rufen wir die Meituan-Software auf, suchen auf der Seite „Mein Menü“ nach „Einstellungen“ und klicken, um „Einstellungen“ aufzurufen. 2. Dann finden wir die Zahlungseinstellungen auf der Einstellungsseite und klicken, um die Zahlungseinstellungen einzugeben. 3. Rufen Sie das Zahlungscenter auf, suchen Sie nach den Einstellungen für das Zahlungspasswort und klicken Sie, um die Einstellungen für das Zahlungspasswort einzugeben. 4. Suchen Sie auf der Seite zum Festlegen des Zahlungskennworts nach der Option zum Abrufen des Zahlungskennworts und klicken Sie, um die Seitenoption aufzurufen. 5. Geben Sie die Informationen zum Zahlungspasswort ein, die Sie abrufen möchten, klicken Sie auf „Bestätigen“ und Sie können das Zahlungspasswort nach der Eingabe abrufen.
 Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Neues SOTA für multimodale Dokumentverständnisfunktionen! Das Alibaba mPLUG-Team hat die neueste Open-Source-Arbeit mPLUG-DocOwl1.5 veröffentlicht, die eine Reihe von Lösungen zur Bewältigung der vier großen Herausforderungen der hochauflösenden Bildtexterkennung, des allgemeinen Verständnisses der Dokumentstruktur, der Befolgung von Anweisungen und der Einführung externen Wissens vorschlägt. Schauen wir uns ohne weitere Umschweife zunächst die Auswirkungen an. Ein-Klick-Erkennung und Konvertierung von Diagrammen mit komplexen Strukturen in das Markdown-Format: Es stehen Diagramme verschiedener Stile zur Verfügung: Auch eine detailliertere Texterkennung und -positionierung ist einfach zu handhaben: Auch ausführliche Erläuterungen zum Dokumentverständnis können gegeben werden: Sie wissen schon, „Document Understanding“. " ist derzeit ein wichtiges Szenario für die Implementierung großer Sprachmodelle. Es gibt viele Produkte auf dem Markt, die das Lesen von Dokumenten unterstützen. Einige von ihnen verwenden hauptsächlich OCR-Systeme zur Texterkennung und arbeiten mit LLM zur Textverarbeitung zusammen.
 So löschen Sie Bewertungen auf Meituan. So löschen Sie Bewertungen
Mar 12, 2024 pm 07:31 PM
So löschen Sie Bewertungen auf Meituan. So löschen Sie Bewertungen
Mar 12, 2024 pm 07:31 PM
Wenn wir diese Plattform nutzen, gibt es auch Bewertungen zu verschiedenen Lebensmittel- und Konsumaspekten. Einige der Bedienungsmethoden sind auch äußerst einfach. Wenn wir zum Konsum gehen, sollten wir in der Lage sein, einige funktionale Optionen zu bewerten und von uns selbst bewertet. Manchmal müssen wir jedoch möglicherweise selbst falsche Bewertungen in einigen Geschäften löschen, aber Benutzer wissen nicht, wie sie diese Bewertungen vornehmen sollen. Daher werde ich Ihnen im heutigen Herausgeber einige der oben genannten Funktionen ausführlich erläutern Wenn Sie Ideen haben, wird Ihnen der Herausgeber heute ausführlich erklären, wie Sie es löschen können. Wenn Sie interessiert sind, schauen Sie sich das jetzt mit dem Herausgeber an. Ich glaube, dass jeder etwas darüber wissen sollte vermisse es. Löschen
 Wo kann ich meine Meituan-Adresse ändern? Tutorial zur Änderung der Meituan-Adresse!
Mar 15, 2024 pm 04:07 PM
Wo kann ich meine Meituan-Adresse ändern? Tutorial zur Änderung der Meituan-Adresse!
Mar 15, 2024 pm 04:07 PM
1. Wo kann ich meine Meituan-Adresse ändern? Tutorial zur Änderung der Meituan-Adresse! Methode (1) 1. Geben Sie Meituan My Page ein und klicken Sie auf Einstellungen. 2. Wählen Sie persönliche Informationen aus. 3. Klicken Sie erneut auf die Lieferadresse. 4. Wählen Sie abschließend die Adresse aus, die Sie ändern möchten, klicken Sie auf das Stiftsymbol rechts neben der Adresse und ändern Sie sie. Methode (2) 1. Klicken Sie auf der Startseite der Meituan-App auf „Takeout“ und dann nach der Eingabe auf „Weitere Funktionen“. 2. Klicken Sie in der Benutzeroberfläche „Mehr“ auf Adresse verwalten. 3. Wählen Sie in der Benutzeroberfläche „Meine Lieferadresse“ die Option „Bearbeiten“. 4. Ändern Sie sie nacheinander entsprechend Ihren Anforderungen und klicken Sie abschließend, um die Adresse zu speichern.
