

ChatGPT-Thema eins: Entwicklungsgeschichte der GPT-Familie

Zeitleiste
Juni 2018
OpenAI veröffentlicht GPT-1-Modell mit 110 Millionen Parametern.
Im November 2018
OpenAI veröffentlichte das GPT-2-Modell mit 1,5 Milliarden Parametern, aber aufgrund von Missbrauchsbedenken sind der gesamte Code und die Daten des Modells nicht für die Öffentlichkeit zugänglich.
Februar 2019
OpenAI hat einige Codes und Daten des GPT-2-Modells geöffnet, der Zugriff ist jedoch weiterhin eingeschränkt.
10. Juni 2019
OpenAI hat das GPT-3-Modell mit 175 Milliarden Parametern veröffentlicht und einigen Partnern Zugriff gewährt.
September 2019
OpenAI hat den gesamten Code und die Daten von GPT-2 geöffnet und eine größere Version veröffentlicht.
Mai 2020
OpenAI kündigte die Einführung der Betaversion des GPT-3-Modells an, das 175 Milliarden Parameter aufweist und das bisher größte Modell zur Verarbeitung natürlicher Sprache ist.
März 2022
OpenAI hat InstructGPT unter Verwendung von Instruction Tuning veröffentlicht
30. November 2022
OpenAI hat die GPT-3.5-Serie großer Sprachmodelle verfeinert und das neue Konversations-KI-Modell ChatGPT wurde offiziell veröffentlicht.
15. Dezember 2022
ChatGPT wird zum ersten Mal aktualisiert, verbessert die Gesamtleistung und fügt neue Funktionen zum Speichern und Anzeigen historischer Gesprächsaufzeichnungen hinzu.
9. Januar 2023
ChatGPT wird zum zweiten Mal aktualisiert, wodurch die Authentizität der Antworten verbessert und eine neue Funktion „Generierung stoppen“ hinzugefügt wird.
21. Januar 2023
OpenAI hat eine kostenpflichtige Version von ChatGPT Professional veröffentlicht, die auf einige Benutzer beschränkt ist.
30. Januar 2023
ChatGPT wird zum dritten Mal aktualisiert, was nicht nur die Authentizität der Antworten, sondern auch die mathematischen Fähigkeiten verbessert.
2. Februar 2023
OpenAI hat den Abonnementdienst für die kostenpflichtige Version von ChatGPT offiziell eingeführt. Im Vergleich zur kostenlosen Version reagiert die neue Version schneller und läuft stabiler.
15. März 2023
OpenAI hat überraschenderweise das groß angelegte multimodale Modell GPT-4 auf den Markt gebracht, das nicht nur Text lesen, sondern auch Bilder erkennen und Textergebnisse generieren kann. Es ist jetzt mit ChatGPT verbunden und für Plus geöffnet Benutzer.
GPT-1: Vorab trainiertes Modell basierend auf Einwegtransformator
Vor dem Aufkommen von GPT wurden NLP-Modelle hauptsächlich auf der Grundlage großer Mengen annotierter Daten für bestimmte Aufgaben trainiert. Dies führt zu einigen Einschränkungen:
Annotationsdaten in großem Maßstab sind nicht einfach zu erhalten.
Das Modell ist auf das erhaltene Training beschränkt und seine Generalisierungsfähigkeit ist nicht ausreichend. Standardaufgaben, die die Anwendung des Modells einschränken.
Um diese Probleme zu überwinden, hat OpenAI den Weg eingeschlagen, große Modelle vorab zu trainieren. GPT-1 ist das erste vorab trainierte Modell, das 2018 von OpenAI veröffentlicht wurde. Es verwendet ein einseitiges Transformer-Modell und verwendet mehr als 40 GB Textdaten für das Training. Die Hauptmerkmale von GPT-1 sind: generatives Vortraining (unüberwacht) + diskriminierende Aufgaben-Feinabstimmung (überwacht). Zuerst nutzten wir das Vortraining für unbeaufsichtigtes Lernen und verbrachten einen Monat mit 8 GPUs, um die Sprachfähigkeiten des KI-Systems aus einer großen Menge unbeschrifteter Daten zu verbessern und eine große Menge an Wissen zu erhalten. Anschließend führten wir eine überwachte Feinabstimmung durch Verglich es mit großen Datensätzen, um die Systemleistung bei NLP-Aufgaben zu verbessern. GPT-1 zeigte eine hervorragende Leistung bei Textgenerierungs- und Textverständnisaufgaben und wurde zu einem der fortschrittlichsten Modelle für die Verarbeitung natürlicher Sprache seiner Zeit.
GPT-2: Multitasking-Vortrainingsmodell
Aufgrund der fehlenden Verallgemeinerung von Einzeltask-Modellen und des Multitasking-Lernens, das eine große Anzahl effektiver Trainingspaare erfordert, wird GPT-2 erweitert und optimiert Auf der Grundlage von GPT-1 wird das überwachte Lernen entfernt und nur das unbeaufsichtigte Lernen beibehalten. GPT-2 verwendet für das Training größere Textdaten und leistungsfähigere Rechenressourcen, und die Parametergröße erreicht 150 Millionen und übertrifft damit die 110 Millionen Parameter von GPT-1 bei weitem. Neben der Verwendung größerer Datensätze und größerer Modelle zum Lernen schlägt GPT-2 auch eine neue und schwierigere Aufgabe vor: Zero-Shot-Lernen (Zero-Shot), bei dem vorab trainierte Modelle direkt auf viele nachgelagerte Aufgaben angewendet werden. GPT-2 hat bei mehreren Aufgaben der Verarbeitung natürlicher Sprache eine hervorragende Leistung gezeigt, darunter Textgenerierung, Textklassifizierung, Sprachverständnis usw.
 GPT-3: Erstellen Sie neue Funktionen zur Generierung und zum Verständnis natürlicher Sprache.
GPT-3: Erstellen Sie neue Funktionen zur Generierung und zum Verständnis natürlicher Sprache.
GPT-3 ist das neueste Modell in der GPT-Modellreihe und verwendet eine größere Parameterskala und umfangreichere Trainingsdaten. Die Parameterskala von GPT-3 erreicht 1,75 Billionen, was mehr als dem Hundertfachen der von GPT-2 entspricht. GPT-3 hat erstaunliche Fähigkeiten bei der Erzeugung natürlicher Sprache, der Dialoggenerierung und anderen Sprachverarbeitungsaufgaben gezeigt. Bei einigen Aufgaben kann es sogar neue Formen des Sprachausdrucks schaffen.
GPT-3 schlägt ein sehr wichtiges Konzept vor: In-Context-Lernen. Der spezifische Inhalt wird im nächsten Tweet erläutert.
InstructGPT & ChatGPT
Das Training von InstructGPT/ChatGPT ist in drei Schritte unterteilt, und die für jeden Schritt erforderlichen Daten unterscheiden sich geringfügig. Lassen Sie uns sie unten separat vorstellen.
Beginnen Sie mit einem vorab trainierten Sprachmodell und wenden Sie die folgenden drei Schritte an.
Schritt 1: Überwachte Feinabstimmung von SFT: Sammeln Sie Demonstrationsdaten und trainieren Sie eine überwachte Richtlinie. Unser Tagger liefert eine Demonstration des gewünschten Verhaltens bei der Eingabeaufforderungsverteilung. Anschließend verwenden wir überwachtes Lernen, um das vorab trainierte GPT-3-Modell anhand dieser Daten zu verfeinern.
Schritt 2: Schulung des Belohnungsmodells. Sammeln Sie Vergleichsdaten und trainieren Sie ein Belohnungsmodell. Wir haben einen Datensatz mit Vergleichen zwischen Modellausgaben gesammelt, in dem Labeler angeben, welche Ausgabe sie für eine bestimmte Eingabe bevorzugen. Anschließend trainieren wir ein Belohnungsmodell, um vom Menschen bevorzugte Ergebnisse vorherzusagen.
Schritt 3: Verstärkung des Lernens durch proximale Richtlinienoptimierung (PPO) am Belohnungsmodell: Verwenden Sie die Ausgabe des RM als skalare Belohnung. Wir verwenden den PPO-Algorithmus zur Feinabstimmung der Überwachungsstrategie, um diese Belohnung zu optimieren.
Die Schritte 2 und 3 können kontinuierlich wiederholt werden. Es werden weitere Vergleichsdaten zur aktuellen optimalen Strategie gesammelt, die zum Trainieren eines neuen RM und anschließend einer neuen Strategie verwendet werden.
Die Eingabeaufforderungen für die ersten beiden Schritte stammen aus Benutzernutzungsdaten auf der Online-API von OpenAI und wurden von beauftragten Annotatoren handgeschrieben. Der letzte Schritt wird vollständig aus den API-Daten abgetastet:
1. Der SFT-Datensatz wird verwendet, um das überwachte Modell im ersten Schritt zu trainieren Gesammelte Daten. Passen Sie GPT-3 entsprechend der Trainingsmethode von GPT-3 an. Da GPT-3 ein generatives Modell ist, das auf promptem Lernen basiert, ist der SFT-Datensatz auch eine Stichprobe, die aus Prompt-Antwort-Paaren besteht. Ein Teil der SFT-Daten stammt von Benutzern von OpenAIs PlayGround und der andere Teil stammt von den 40 von OpenAI eingesetzten Labelern. Und sie haben den Etikettierer geschult. In diesem Datensatz besteht die Aufgabe des Annotators darin, basierend auf dem Inhalt selbst Anweisungen zu schreiben.
2. RM-Datensatz
Der RM-Datensatz wird zum Trainieren des Belohnungsmodells in Schritt 2 verwendet. Wir müssen auch ein Belohnungsziel für das Training von InstructGPT/ChatGPT festlegen. Dieses Belohnungsziel muss nicht differenzierbar sein, aber es muss möglichst umfassend und realistisch mit dem übereinstimmen, was das Modell generieren soll. Natürlich können wir diese Belohnung durch manuelle Annotation bereitstellen, indem wir den generierten Inhalten mit Voreingenommenheit niedrigere Bewertungen geben, um das Modell dazu zu ermutigen, keine Inhalte zu generieren, die den Menschen nicht gefallen. Der Ansatz von InstructGPT/ChatGPT besteht darin, das Modell zunächst einen Stapel Kandidatentexte generieren zu lassen und dann den generierten Inhalt mithilfe des Labelers nach der Qualität der generierten Daten zu sortieren.
3. PPO-Datensatz
Die PPO-Daten von InstructGPT sind nicht mit Anmerkungen versehen, sie stammen von GPT-3-API-Benutzern. Es gibt verschiedene Arten von Generierungsaufgaben, die von verschiedenen Benutzern bereitgestellt werden, wobei der höchste Anteil Generierungsaufgaben (45,6 %), Qualitätssicherung (12,4 %), Brainstorming (11,2 %), Dialog (8,4 %) usw. umfasst.
Anhang: Die verschiedenen Funktionsquellen von ChatGPT: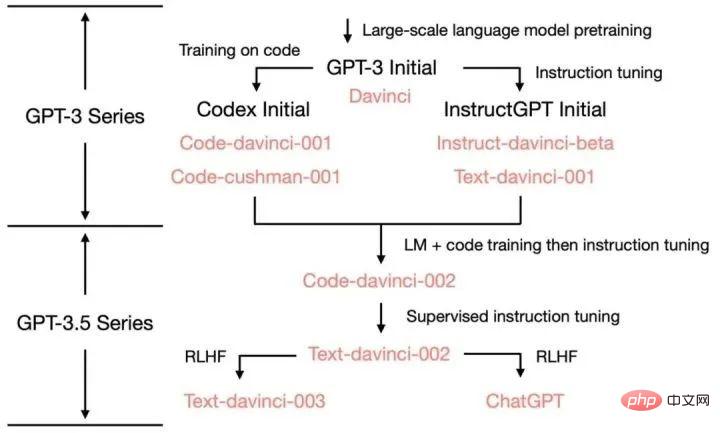

Das obige ist der detaillierte Inhalt vonChatGPT-Thema eins: Entwicklungsgeschichte der GPT-Familie. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
Mit ChatGPT können kostenlose Benutzer jetzt Bilder mithilfe von DALL-E 3 mit einem Tageslimit generieren
Aug 09, 2024 pm 09:37 PM
DALL-E 3 wurde im September 2023 offiziell als deutlich verbessertes Modell gegenüber seinem Vorgänger eingeführt. Er gilt als einer der bisher besten KI-Bildgeneratoren und ist in der Lage, Bilder mit komplexen Details zu erstellen. Zum Start war es jedoch exklusiv
 YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Feb 26, 2024 am 11:31 AM
YOLO ist unsterblich! YOLOv9 wird veröffentlicht: Leistung und Geschwindigkeit SOTA~
Feb 26, 2024 am 11:31 AM
Heutige Deep-Learning-Methoden konzentrieren sich darauf, die am besten geeignete Zielfunktion zu entwerfen, damit die Vorhersageergebnisse des Modells der tatsächlichen Situation am nächsten kommen. Gleichzeitig muss eine geeignete Architektur entworfen werden, um ausreichend Informationen für die Vorhersage zu erhalten. Bestehende Methoden ignorieren die Tatsache, dass bei der schichtweisen Merkmalsextraktion und räumlichen Transformation der Eingabedaten eine große Menge an Informationen verloren geht. Dieser Artikel befasst sich mit wichtigen Themen bei der Datenübertragung über tiefe Netzwerke, nämlich Informationsengpässen und umkehrbaren Funktionen. Darauf aufbauend wird das Konzept der programmierbaren Gradienteninformation (PGI) vorgeschlagen, um die verschiedenen Änderungen zu bewältigen, die tiefe Netzwerke zur Erreichung mehrerer Ziele erfordern. PGI kann vollständige Eingabeinformationen für die Zielaufgabe zur Berechnung der Zielfunktion bereitstellen und so zuverlässige Gradienteninformationen zur Aktualisierung der Netzwerkgewichte erhalten. Darüber hinaus wird ein neues, leichtgewichtiges Netzwerk-Framework entworfen
 Die perfekte Kombination aus ChatGPT und Python: Erstellen eines intelligenten Kundenservice-Chatbots
Oct 27, 2023 pm 06:00 PM
Die perfekte Kombination aus ChatGPT und Python: Erstellen eines intelligenten Kundenservice-Chatbots
Oct 27, 2023 pm 06:00 PM
Die perfekte Kombination aus ChatGPT und Python: Erstellen eines intelligenten Kundenservice-Chatbots Einführung: Im heutigen Informationszeitalter sind intelligente Kundenservicesysteme zu einem wichtigen Kommunikationsinstrument zwischen Unternehmen und Kunden geworden. Um den Kundenservice zu verbessern, greifen viele Unternehmen auf Chatbots zurück, um Aufgaben wie Kundenberatung und Beantwortung von Fragen zu erledigen. In diesem Artikel stellen wir vor, wie Sie mithilfe des leistungsstarken ChatGPT-Modells und der Python-Sprache von OpenAI einen intelligenten Kundenservice-Chatbot erstellen und verbessern können
 So installieren Sie ChatGPT auf einem Mobiltelefon
Mar 05, 2024 pm 02:31 PM
So installieren Sie ChatGPT auf einem Mobiltelefon
Mar 05, 2024 pm 02:31 PM
Installationsschritte: 1. Laden Sie die ChatGTP-Software von der offiziellen ChatGTP-Website oder dem mobilen Store herunter. 2. Wählen Sie nach dem Öffnen in der Einstellungsoberfläche die Sprache aus. 3. Wählen Sie in der Spieloberfläche das Mensch-Maschine-Spiel aus 4. Geben Sie nach dem Start Befehle in das Chatfenster ein, um mit der Software zu interagieren.
 Soll ich MBR oder GPT als Festplattenformat für Win7 wählen?
Jan 03, 2024 pm 08:09 PM
Soll ich MBR oder GPT als Festplattenformat für Win7 wählen?
Jan 03, 2024 pm 08:09 PM
Wenn wir das Betriebssystem Win7 verwenden, kann es manchmal vorkommen, dass wir das System neu installieren und die Festplatte partitionieren müssen. In Bezug auf die Frage, ob das Win7-Festplattenformat MBR oder GPT erfordert, ist der Herausgeber der Meinung, dass Sie immer noch eine Entscheidung basierend auf den Details Ihres eigenen Systems und Ihrer Hardwarekonfiguration treffen müssen. Aus Kompatibilitätsgründen ist es am besten, das MBR-Format zu wählen. Schauen wir uns für Details an, was der Editor getan hat. Das Win7-Festplattenformat erfordert mbr oder gpt1. Wenn das System mit Win7 installiert ist, wird empfohlen, MBR zu verwenden, das eine gute Kompatibilität aufweist. 2. Wenn es 3T überschreitet oder Win8 installiert, können Sie GPT verwenden. 3. Obwohl GPT tatsächlich weiter fortgeschritten ist als MBR, ist MBR in Bezug auf die Kompatibilität definitiv unschlagbar. GPT- und MBR-Bereiche
 Detailliertes Verständnis des Win10-Partitionsformats: GPT- und MBR-Vergleich
Dec 22, 2023 am 11:58 AM
Detailliertes Verständnis des Win10-Partitionsformats: GPT- und MBR-Vergleich
Dec 22, 2023 am 11:58 AM
Bei der Partitionierung ihrer eigenen Systeme wissen viele Benutzer aufgrund der unterschiedlichen Festplatten, die von Benutzern verwendet werden, nicht, ob das Win10-Partitionsformat GPT oder MBR ist. Aus diesem Grund haben wir Ihnen eine detaillierte Einführung zusammengestellt, damit Sie den Unterschied zwischen den beiden kennen zwei. Win10-Partitionsformat gpt oder mbr: Antwort: Wenn Sie eine Festplatte mit mehr als 3 TB verwenden, können Sie gpt verwenden. gpt ist weiter fortgeschritten als mbr, aber in Bezug auf die Kompatibilität ist mbr immer noch besser. Selbstverständlich kann dies auch nach den Vorlieben des Nutzers gewählt werden. Der Unterschied zwischen gpt und mbr: 1. Anzahl der unterstützten Partitionen: 1. MBR unterstützt bis zu 4 primäre Partitionen. 2. GPT ist nicht durch die Anzahl der Partitionen begrenzt. 2. Unterstützte Festplattengröße: 1. MBR unterstützt nur bis zu 2 TB
 1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
Papieradresse: https://arxiv.org/abs/2307.09283 Codeadresse: https://github.com/THU-MIG/RepViTRepViT funktioniert gut in der mobilen ViT-Architektur und zeigt erhebliche Vorteile. Als nächstes untersuchen wir die Beiträge dieser Studie. In dem Artikel wird erwähnt, dass Lightweight-ViTs bei visuellen Aufgaben im Allgemeinen eine bessere Leistung erbringen als Lightweight-CNNs, hauptsächlich aufgrund ihres Multi-Head-Selbstaufmerksamkeitsmoduls (MSHA), das es dem Modell ermöglicht, globale Darstellungen zu lernen. Allerdings wurden die architektonischen Unterschiede zwischen Lightweight-ViTs und Lightweight-CNNs noch nicht vollständig untersucht. In dieser Studie integrierten die Autoren leichte ViTs in die effektiven
 Die ultimative Waffe für das Kubernetes-Debugging: K8sGPT
Feb 26, 2024 am 11:40 AM
Die ultimative Waffe für das Kubernetes-Debugging: K8sGPT
Feb 26, 2024 am 11:40 AM
Im Zuge der Weiterentwicklung der Technologien für künstliche Intelligenz und maschinelles Lernen haben Unternehmen und Organisationen damit begonnen, aktiv innovative Strategien zu erforschen, um diese Technologien zur Verbesserung der Wettbewerbsfähigkeit zu nutzen. K8sGPT[2] ist eines der leistungsstärksten Tools in diesem Bereich. Es handelt sich um ein auf k8s basierendes GPT-Modell, das die Vorteile der k8s-Orchestrierung mit den hervorragenden Funktionen des GPT-Modells zur Verarbeitung natürlicher Sprache kombiniert. Was ist K8sGPT? Schauen wir uns zunächst ein Beispiel an: Laut der offiziellen Website von K8sGPT ist K8sgpt ein Tool zum Scannen, Diagnostizieren und Klassifizieren von Kubernetes-Clusterproblemen. Es integriert SRE-Erfahrung in seine Analyse-Engine, um die relevantesten Informationen bereitzustellen. Durch den Einsatz künstlicher Intelligenztechnologie bereichert K8sgpt seine Inhalte weiterhin und hilft Benutzern, schneller und genauer zu verstehen.
