
 Technologie-Peripheriegeräte
KI
Google hat das größte Allzweckmodell der Geschichte veröffentlicht, PaLM-E, das über 562 Milliarden Parameter verfügt, als das leistungsstärkste Gehirn im Terminator gilt und über Bilder mit Robotern interagieren kann.
Technologie-Peripheriegeräte
KI
Google hat das größte Allzweckmodell der Geschichte veröffentlicht, PaLM-E, das über 562 Milliarden Parameter verfügt, als das leistungsstärkste Gehirn im Terminator gilt und über Bilder mit Robotern interagieren kann.
Google hat das größte Allzweckmodell der Geschichte veröffentlicht, PaLM-E, das über 562 Milliarden Parameter verfügt, als das leistungsstärkste Gehirn im Terminator gilt und über Bilder mit Robotern interagieren kann.

Die schnelle „Mutation“ großer Sprachmodelle hat die Richtung der menschlichen Gesellschaft zunehmend zu Science-Fiction gemacht. Nach dem Aufleuchten dieses Technologiebaums scheint uns die Realität von „Terminator“ immer näher zu rücken.
Vor ein paar Tagen hat Microsoft gerade ein experimentelles Framework angekündigt, das ChatGPT zur Steuerung von Robotern und Drohnen nutzen kann.
Natürlich ist Google nicht weit dahinter. Am Montag hat ein Team von Google und der Technischen Universität Berlin das größte visuelle Sprachmodell der Geschichte auf den Markt gebracht – PaLM-E.

Papieradresse: https://arxiv.org/abs/2303.03378
Als multimodales verkörpertes visuelles Sprachmodell (VLM) kann PaLM-E nicht nur Bilder verstehen können auch Sprache verstehen und erzeugen und sogar beides kombinieren, um komplexe Roboteranweisungen zu verarbeiten.
Darüber hinaus beträgt die endgültige Anzahl der Parameter von PaLM-E durch die Kombination des PaLM-540B-Sprachmodells und des visuellen Transformer-Modells ViT-22B bis zu 562 Milliarden.

Ein „generalistisches“ Modell, das die Bereiche Robotik und Vision-Sprache umfasst.
PaLM-E, der vollständige Name von Pathways Language Model mit Embodied, ist ein verkörpertes visuelles Sprachmodell.
Seine Stärke liegt in seiner Fähigkeit, visuelle Daten zu nutzen, um seine Sprachverarbeitungsfähigkeiten zu verbessern.

Was passiert, wenn wir das größte visuelle Sprachmodell trainieren und es mit einem Roboter kombinieren? Das Ergebnis ist PaLM-E, ein universeller, verkörperter visueller Sprachgeneralist mit 562 Milliarden Parametern – der Robotik, Vision und Sprache umfasst. Dem Papier zufolge ist PaLM-E ein reines Decoder-LLM mit einem Präfix oder einer Eingabeaufforderung , kann die Textvervollständigung autoregressiv generiert werden.
Die Trainingsdaten sind multimodale Sätze mit visueller, kontinuierlicher Zustandsschätzung und Texteingabekodierung.
Nach dem Training mit einer einzigen Bildaufforderung kann PaLM-E den Roboter nicht nur bei der Ausführung einer Vielzahl komplexer Aufgaben anleiten, sondern auch eine Sprache zur Beschreibung des Bildes generieren.
Man kann sagen, dass PaLM-E eine beispiellose Flexibilität und Anpassungsfähigkeit aufweist und einen großen Fortschritt darstellt, insbesondere im Bereich der Mensch-Computer-Interaktion.
Noch wichtiger ist, dass die Forscher zeigten, dass das Training verschiedener gemischter Aufgabenkombinationen mehrerer Roboter und allgemeiner visueller Sprache verschiedene Methoden zur Übertragung von visueller Sprache auf verkörperte Entscheidungsfindung ermöglichen kann, damit Roboter Daten planen können effektiv.
Darüber hinaus zeichnet sich PaLM-E besonders dadurch aus, dass es über eine starke positive Migrationsfähigkeit verfügt. 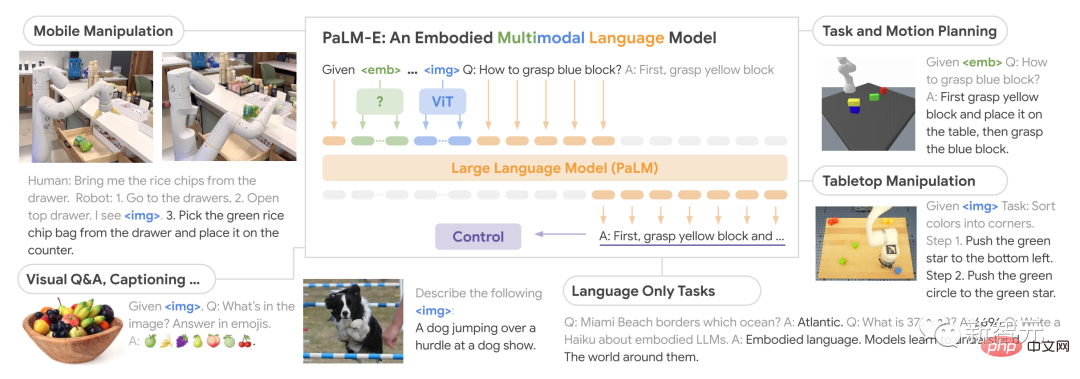
PaLM-E, das in verschiedenen Bereichen trainiert wurde, einschließlich allgemeiner Seh- und Sprachaufgaben im Internetmaßstab, erzielt eine deutlich verbesserte Leistung im Vergleich zu Robotermodellen, die einzelne Aufgaben ausführen.
Und im Modellmaßstab beobachteten die Forscher einen deutlichen Vorteil. 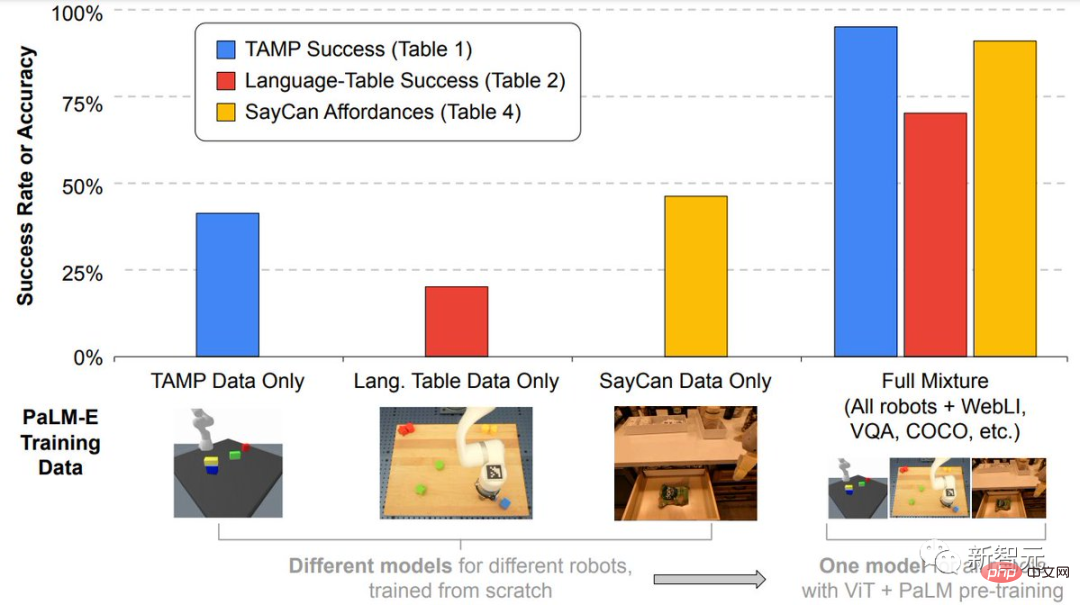
Je größer das Sprachmodell, desto stärker bleibt die Sprachfähigkeit beim Training visueller Sprache und Roboteraufgaben erhalten.
Aus der Perspektive des Modellmaßstabs behält PaLM-E mit 562 Milliarden Parametern fast alle seine Sprachfähigkeiten bei.
Obwohl PaLM-E nur an einem einzigen Bild trainiert wurde, zeigt es herausragende Fähigkeiten bei Aufgaben wie dem multimodalen Denken in Ketten und dem Denken mit mehreren Bildern.
PaLM-E erreicht neue SOTA beim OK-VQA-Benchmark.
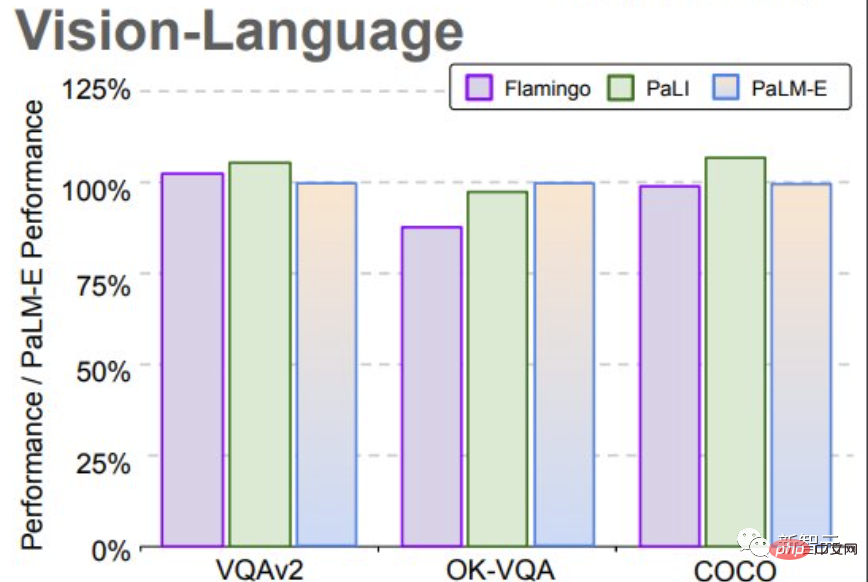
Bewertungsergebnisse
Im Test zeigten die Forscher, wie sie mit PaLM-E Planungs- und Langzeitaufgaben für zwei verschiedene Einheiten durchführen können.
Es ist erwähnenswert, dass alle diese Ergebnisse mit demselben Modell erzielt wurden, das auf denselben Daten trainiert wurde.
In der Vergangenheit benötigten Roboter normalerweise menschliche Hilfe, um umfangreiche Aufgaben zu erledigen. Aber jetzt kann PaLM-E dies durch unabhängiges Lernen tun.

Anweisungen wie „Nimm die Kartoffelchips aus der Schublade“ beinhalten beispielsweise mehrere Planungsschritte und visuelles Feedback von der Kamera des Roboters.
PaLM-E, das durchgängig trainiert wurde, kann den Roboter direkt aus Pixeln planen. Da das Modell in einen Regelkreis eingebunden ist, ist der Roboter robust gegenüber Störungen unterwegs beim Aufnehmen von Kartoffelchips.
Mensch: Bring mir ein paar Kartoffelchips.
Roboter: 1. Gehe zur Schublade. 2. Öffne die obere Schublade. 3. Nimm die grünen Kartoffelchips aus der oberen Schublade. 4. Lege sie auf die Arbeitsplatte.

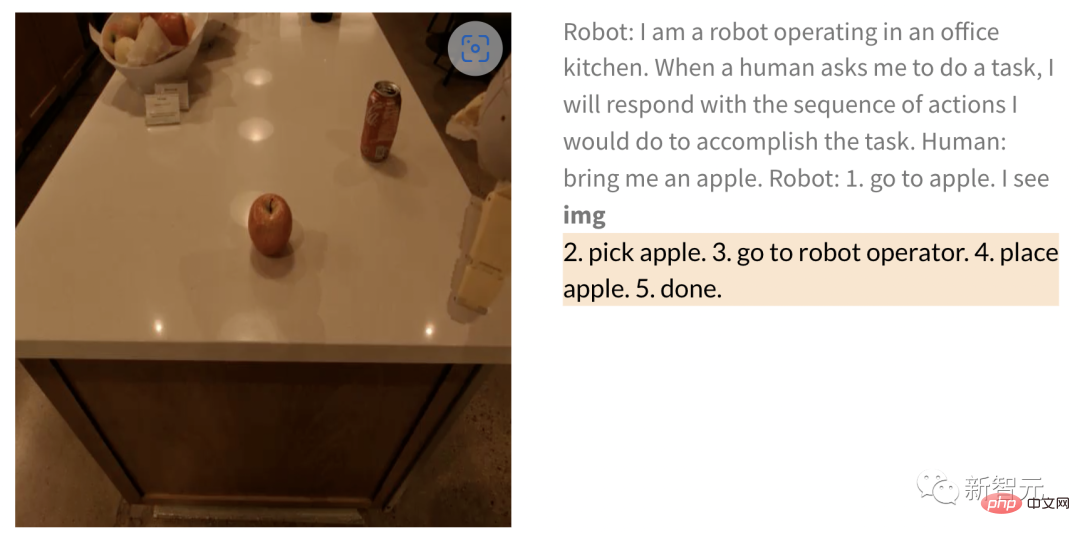
Ähnlicherweise führt der Roboter die Aufgabe wie folgt aus, wenn er den Roboter bittet, einen Apfel zu holen, nachdem er ihm das Bild gegeben hat:
Mensch: Hol mir einen Apfel.
Roboter: 1. Auf den Apfel zugehen 2. Den Apfel aufheben 3. Zum Bediener bringen 4. Den Apfel ablegen 5. Fertig.
PaLM-E kann es dem Roboter nicht nur ermöglichen, weiträumige Aufgaben auszuführen, sondern auch Planungsaufgaben durchzuführen, beispielsweise das Anordnen von Bausteinen.
Die Forscher führten erfolgreich eine mehrstufige Planung durch, die auf visuellen und verbalen Eingaben basierte und mit langfristigem visuellem Feedback kombiniert wurde, wodurch das Modell eine langfristige Aufgabe erfolgreich planen konnte, nämlich „Bausteine nach Farbe in verschiedene Kategorien zu sortieren“. . Ecke".
Wie unten gezeigt, verwandelt sich der Roboter in der Anordnung und Kombination in einen Generalisten und sortiert die Bausteine nach Farben.
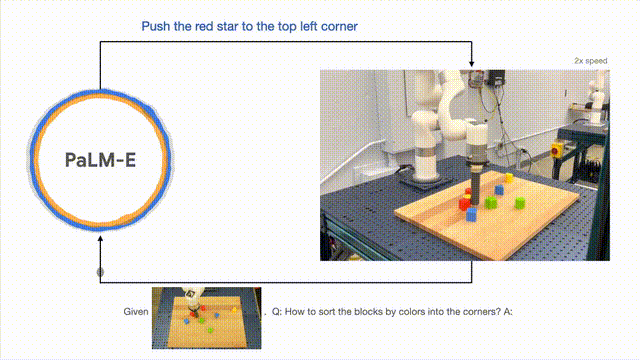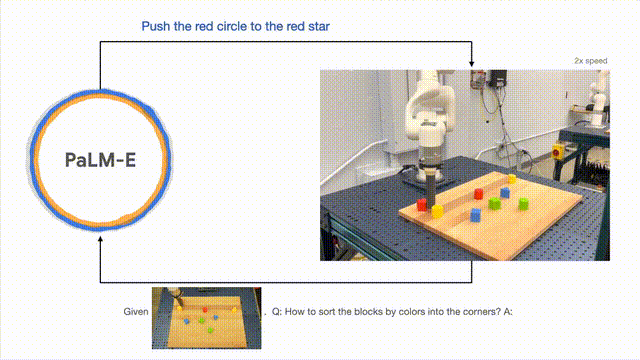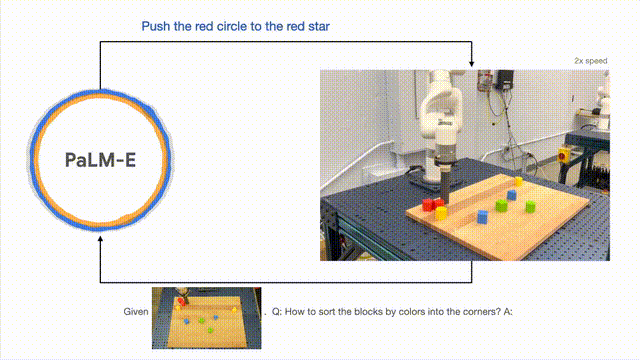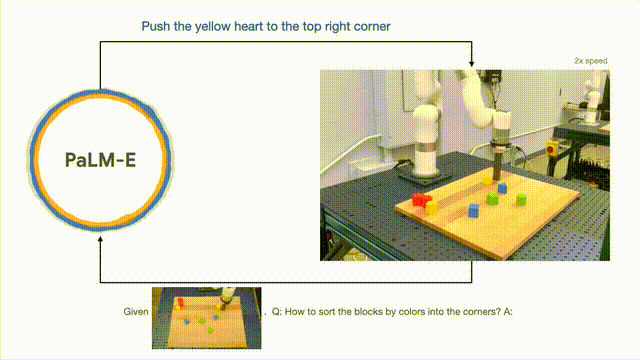
Um das Modell zu verallgemeinern, kann der von PaLM-E gesteuerte Roboter den roten Baustein an die Seite der Kaffeetasse bewegen.
Erwähnenswert ist, dass der Datensatz nur drei Demos mit Kaffeetassen enthält, aber keines davon enthält rote Bausteine. Auch wenn das Modell noch nie zuvor eine Schildkröte gesehen hat, kann es die grünen Blöcke dennoch reibungslos zur Schildkröte schieben - E kann anhand von Bildern Witze erzählen und hat Fähigkeiten wie Wahrnehmung, visionsbasierten Dialog und Planung unter Beweis gestellt.

PaLM-E kann auch die Beziehung zwischen mehreren Bildern verstehen, beispielsweise wo sich Bild 1 (links) in Bild 2 (rechts) befindet.

Darüber hinaus kann PaLM-E anhand eines Bildes mit handgeschriebenen Ziffern mathematische Operationen ausführen.
Wie viel kosten zum Beispiel 2 Pizzen für das handgeschriebene Bild der Restaurantkarte unten? 
sowie allgemeine Qualitätssicherung und Anmerkungs- und andere Aufgaben. 
Schließlich zeigen die Forschungsergebnisse auch, dass das Einfrieren von Sprachmodellen ein gangbarer Weg zu universellen verkörperten multimodalen Modellen ist, die ihre Sprachfähigkeiten vollständig behalten.
Gleichzeitig entdeckten die Forscher aber auch einen alternativen Weg zum Auftauen des Modells, d. h. eine Vergrößerung des Sprachmodells kann das katastrophale Vergessen deutlich reduzieren. 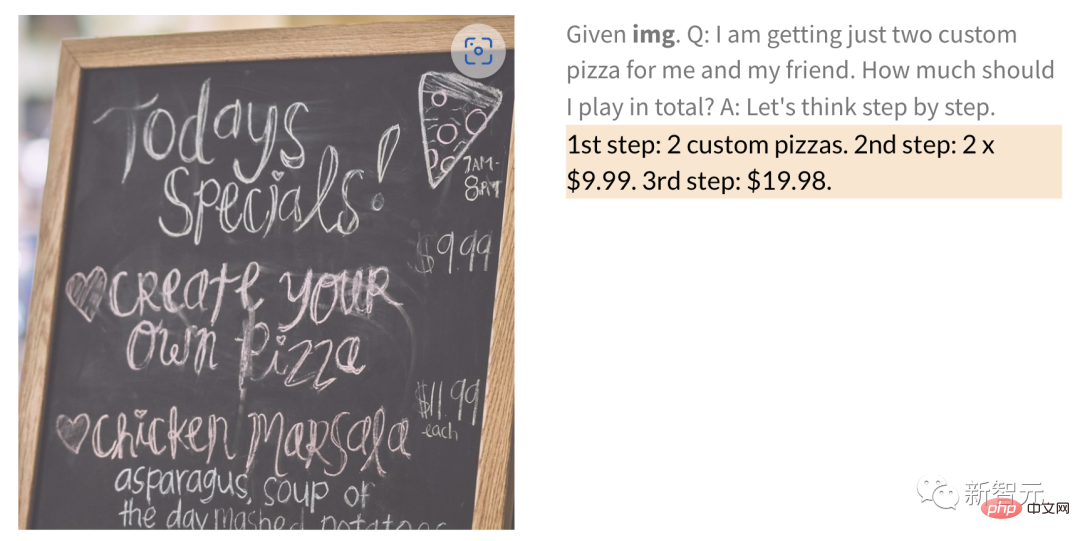
Das obige ist der detaillierte Inhalt vonGoogle hat das größte Allzweckmodell der Geschichte veröffentlicht, PaLM-E, das über 562 Milliarden Parameter verfügt, als das leistungsstärkste Gehirn im Terminator gilt und über Bilder mit Robotern interagieren kann.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Wie man Deepseek kommentiert
Feb 19, 2025 pm 05:42 PM
Deepseek ist ein leistungsstarkes Informations -Abruf -Tool. .
 So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
So suchen Sie Deepseek
Feb 19, 2025 pm 05:39 PM
Deepseek ist eine proprietäre Suchmaschine, die nur schneller und genauer in einer bestimmten Datenbank oder einem bestimmten System sucht. Bei der Verwendung wird den Benutzern empfohlen, das Dokument zu lesen, verschiedene Suchstrategien auszuprobieren, Hilfe und Feedback zur Benutzererfahrung zu suchen, um die Vorteile optimal zu nutzen.
 Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
In diesem Artikel wird der Registrierungsprozess der Webversion Sesam Open Exchange (GATE.IO) und die Gate Trading App im Detail vorgestellt. Unabhängig davon, ob es sich um eine Webregistrierung oder eine App -Registrierung handelt, müssen Sie die offizielle Website oder den offiziellen App Store besuchen, um die Genuine App herunterzuladen, und dann den Benutzernamen, das Kennwort, die E -Mail, die Mobiltelefonnummer und die anderen Informationen eingeben und eine E -Mail- oder Mobiltelefonüberprüfung abschließen.
 Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden?
Feb 21, 2025 pm 10:57 PM
Warum kann der Bybit -Exchange -Link nicht direkt heruntergeladen und installiert werden? Bitbit ist eine Kryptowährungsbörse, die den Benutzern Handelsdienste anbietet. Die mobilen Apps der Exchange können aus den folgenden Gründen nicht direkt über AppStore oder Googleplay heruntergeladen werden: 1. App Store -Richtlinie beschränkt Apple und Google daran, strenge Anforderungen an die im App Store zulässigen Anwendungsarten zu haben. Kryptowährungsanträge erfüllen diese Anforderungen häufig nicht, da sie Finanzdienstleistungen einbeziehen und spezifische Vorschriften und Sicherheitsstandards erfordern. 2. Die Einhaltung von Gesetzen und Vorschriften In vielen Ländern werden Aktivitäten im Zusammenhang mit Kryptowährungstransaktionen reguliert oder eingeschränkt. Um diese Vorschriften einzuhalten, kann die Bitbit -Anwendung nur über offizielle Websites oder andere autorisierte Kanäle verwendet werden
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download -Adresse
Feb 28, 2025 am 10:51 AM
Es ist wichtig, einen formalen Kanal auszuwählen, um die App herunterzuladen und die Sicherheit Ihres Kontos zu gewährleisten.
 Gate.io Exchange Official Registration Portal
Feb 20, 2025 pm 04:27 PM
Gate.io Exchange Official Registration Portal
Feb 20, 2025 pm 04:27 PM
Gate.io ist ein führender Kryptowährungsaustausch, der eine breite Palette von Krypto -Vermögenswerten und Handelspaaren bietet. Registrierung von Gate.io ist sehr einfach. Vervollständigen Sie die Registrierung. Mit Gate.io können Benutzer ein sicheres und bequemes Kryptowährungshandelserlebnis genießen.
 Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Binance Binance Offizielle Website Neueste Version Anmeldeportal
Feb 21, 2025 pm 05:42 PM
Befolgen Sie diese einfachen Schritte, um auf die neueste Version des Binance -Website -Login -Portals zuzugreifen. Gehen Sie zur offiziellen Website und klicken Sie in der oberen rechten Ecke auf die Schaltfläche "Anmeldung". Wählen Sie Ihre vorhandene Anmeldemethode. Geben Sie Ihre registrierte Handynummer oder E -Mail und Kennwort ein und vervollständigen Sie die Authentifizierung (z. B. Mobilfifizierungscode oder Google Authenticator). Nach einer erfolgreichen Überprüfung können Sie auf das neueste Version des offiziellen Website -Login -Portals von Binance zugreifen.
 Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Eine detaillierte Einführung in den Anmeldungsbetrieb der Sesame Open Exchange -Webversion, einschließlich Anmeldeschritte und Kennwortwiederherstellungsprozess.
