
 Technologie-Peripheriegeräte
KI
Von Mäusen, die durch das Labyrinth laufen, bis hin zu AlphaGo, das Menschen besiegt, die Entwicklung des verstärkenden Lernens
Technologie-Peripheriegeräte
KI
Von Mäusen, die durch das Labyrinth laufen, bis hin zu AlphaGo, das Menschen besiegt, die Entwicklung des verstärkenden Lernens
Von Mäusen, die durch das Labyrinth laufen, bis hin zu AlphaGo, das Menschen besiegt, die Entwicklung des verstärkenden Lernens

Wenn es um Reinforcement Learning geht, steigt der Adrenalinspiegel bei vielen Forschern unkontrolliert an! Es spielt eine sehr wichtige Rolle in KI-Spielsystemen, modernen Robotern, Chipdesignsystemen und anderen Anwendungen.
Es gibt viele verschiedene Arten von Reinforcement-Learning-Algorithmen, sie werden jedoch hauptsächlich in zwei Kategorien unterteilt: „modellbasiert“ und „modellfrei“.
In einem Gespräch mit TechTalks diskutierte der Neurowissenschaftler und Autor von „The Birth of Intelligence“ Daeyeol Lee verschiedene Modelle des verstärkenden Lernens bei Menschen und Tieren, künstliche Intelligenz und natürliche Intelligenz sowie zukünftige Forschungsrichtungen.

Modellfreies verstärkendes Lernen
Im späten 19. Jahrhundert wurde das vom Psychologen Edward Thorndike vorgeschlagene „Gesetz der Wirkung“ zur Grundlage des modellfreien verstärkenden Lernens. Thorndike schlug vor, dass Verhaltensweisen, die sich in einer bestimmten Situation positiv auswirken, in dieser Situation mit größerer Wahrscheinlichkeit erneut auftreten, während Verhaltensweisen, die negative Auswirkungen haben, mit geringerer Wahrscheinlichkeit erneut auftreten.
Thorndike hat dieses „Wirkungsgesetz“ in einem Experiment erforscht. Er setzte eine Katze in ein Labyrinth und maß die Zeit, die die Katze brauchte, um aus der Box zu entkommen. Um zu entkommen, muss die Katze eine Reihe von Geräten wie Seilen und Hebeln bedienen. Thorndike beobachtete, dass die Katze bei der Interaktion mit der Puzzle-Box Verhaltensweisen lernte, die ihr bei der Flucht halfen. Mit der Zeit entkommt die Katze immer schneller der Kiste. Thorndike kam zu dem Schluss, dass Katzen aus den Belohnungen und Strafen, die ihr Verhalten mit sich bringt, lernen können. Das „Gesetz der Wirkung“ ebnete später den Weg für den Behaviorismus. Behaviorismus ist ein Zweig der Psychologie, der versucht, menschliches und tierisches Verhalten anhand von Reizen und Reaktionen zu erklären. Das „Gesetz der Wirkung“ ist auch die Grundlage des modellfreien Verstärkungslernens. Beim modellfreien Verstärkungslernen nimmt ein Agent die Welt wahr und ergreift dann Maßnahmen, während er Belohnungen misst.
Beim modellfreien Verstärkungslernen gibt es kein direktes Wissen oder Weltmodell. RL-Agenten müssen die Ergebnisse jeder Aktion durch Versuch und Irrtum direkt erleben.
Modellbasiertes Verstärkungslernen
Thorndikes „Gesetz der Wirkung“ blieb bis in die 1930er Jahre beliebt. Ein anderer damaliger Psychologe, Edward Tolman, entdeckte eine wichtige Erkenntnis, als er untersuchte, wie Ratten schnell lernten, durch Labyrinthe zu navigieren. Während seiner Experimente erkannte Tolman, dass Tiere ohne Verstärkung etwas über ihre Umwelt lernen können.
Wenn beispielsweise eine Maus in einem Labyrinth freigelassen wird, erkundet sie den Tunnel frei und versteht nach und nach die Struktur der Umgebung. Wenn die Ratte dann wieder in die gleiche Umgebung eingeführt wird und ihr ein verstärkendes Signal gegeben wird, etwa die Suche nach Futter oder das Finden eines Ausgangs, kann sie das Ziel schneller erreichen als ein Tier, das das Labyrinth nicht erkundet hat. Tolman nennt dies „latentes Lernen“, das zur Grundlage des modellbasierten Verstärkungslernens wird. „Latentes Lernen“ ermöglicht es Tieren und Menschen, eine mentale Repräsentation ihrer Welt zu bilden, hypothetische Szenarien in ihrem Kopf zu simulieren und Ergebnisse vorherzusagen.
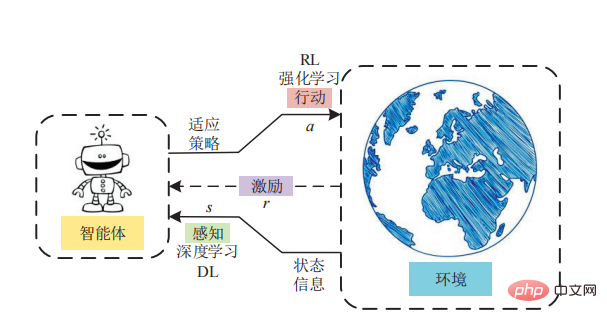
Der Vorteil des modellbasierten Verstärkungslernens besteht darin, dass der Agent keine Versuche mehr in der Umgebung durchführen muss. Hervorzuheben ist, dass modellbasiertes Reinforcement Learning besonders erfolgreich bei der Entwicklung künstlicher Intelligenzsysteme war, die Brettspiele wie Schach und Go beherrschen, möglicherweise weil die Umgebungen dieser Spiele deterministisch sind.

Modellbasiertes vs. modellfreies Lernen
Im Allgemeinen ist modellbasiertes Verstärkungslernen sehr zeitaufwändig und kann tödlich sein, wenn es extrem zeitkritisch ist. „Rechnerisch gesehen ist modellbasiertes Verstärkungslernen viel komplexer“, sagte Lee. „Zuerst muss man das Modell erhalten, eine mentale Simulation durchführen und dann die Flugbahn des neuronalen Prozesses ermitteln und dann Maßnahmen ergreifen.“ Modellbasiertes Verstärkungslernen ist nicht unbedingt komplizierter als modellfreies RL „Wenn die Umgebung sehr komplex ist und mit einem relativ einfachen Modell modelliert werden kann (das schnell erhalten werden kann), ist die Simulation viel einfacher.“ und kostengünstig.
Mehrere Lernmodi
Tatsächlich ist weder modellbasiertes Reinforcement Learning noch modellfreies Reinforcement Learning eine perfekte Lösung. Wo immer Sie ein Reinforcement-Learning-System sehen, das ein komplexes Problem löst, ist es wahrscheinlich, dass es sowohl modellbasiertes als auch modellfreies Reinforcement-Learning und möglicherweise sogar noch mehr Formen des Lernens verwendet. Untersuchungen in den Neurowissenschaften zeigen, dass sowohl Menschen als auch Tiere über mehrere Lernmethoden verfügen und dass das Gehirn zu jedem Zeitpunkt ständig zwischen diesen Modi wechselt. In den letzten Jahren besteht ein wachsendes Interesse an der Entwicklung künstlicher Intelligenzsysteme, die mehrere Reinforcement-Learning-Modelle kombinieren. Aktuelle Forschungen von Wissenschaftlern der UC San Diego zeigen, dass durch die Kombination von modellfreiem Verstärkungslernen und modellbasiertem Verstärkungslernen eine überlegene Leistung bei Steuerungsaufgaben erzielt werden kann. „Wenn Sie sich einen komplexen Algorithmus wie AlphaGo ansehen, verfügt er sowohl über modellfreie RL-Elemente als auch über modellbasierte RL-Elemente“, sagte Lee. „Er lernt Zustandswerte basierend auf der Platinenkonfiguration. Es handelt sich im Grunde genommen um modellfreies RL.“ Aber es wird auch eine modellbasierte Vorwärtssuche durchgeführt
Trotz bedeutender Erfolge waren die Fortschritte beim verstärkenden Lernen langsam. Sobald ein RL-Modell einer komplexen und unvorhersehbaren Umgebung ausgesetzt ist, beginnt seine Leistung zu sinken.
Lee sagte: „Ich denke, unser Gehirn ist eine komplexe Welt von Lernalgorithmen, die sich entwickelt haben, um mit vielen verschiedenen Situationen umzugehen.“
Das Gehirn schafft es nicht nur, ständig zwischen diesen Lernmodi zu wechseln, sondern sie auch aufrechtzuerhalten und zu aktualisieren. auch wenn sie nicht aktiv an Entscheidungen beteiligt sind.
Der Psychologe Daniel Kahneman sagte: „Die Pflege und gleichzeitige Aktualisierung verschiedener Lernmodule kann dazu beitragen, die Effizienz und Genauigkeit von Systemen der künstlichen Intelligenz zu verbessern.
Wir müssen auch noch etwas anderes verstehen – wie wir die Effizienz und Genauigkeit von Systemen der künstlichen Intelligenz verbessern können.“ . Wenden Sie die richtige induktive Voreingenommenheit an, um sicherzustellen, dass sie auf kostengünstige Weise die richtigen Dinge lernen. Milliarden Jahre der Evolution haben Menschen und Tieren die induktive Voreingenommenheit verliehen, die sie benötigen, um effektiv zu lernen und dabei so wenig Daten wie möglich zu nutzen. Induktive Voreingenommenheit kann so verstanden werden, dass die Regeln der im wirklichen Leben beobachteten Phänomene zusammengefasst werden und dem Modell dann bestimmte Einschränkungen auferlegt werden, die die Rolle der Modellauswahl spielen können, d. h. der Auswahl eines Modells, das den realen Regeln besser entspricht der Hypothesenraum. „Wir erhalten nur sehr wenige Informationen aus der Umgebung. Anhand dieser Informationen müssen wir verallgemeinern“, sagte Lee. „Der Grund dafür ist, dass das Gehirn eine induktive Voreingenommenheit hat und eine Tendenz zur Verallgemeinerung aus einer kleinen Anzahl von Beispielen besteht.“ „Produkt der Evolution.“ Immer mehr Neurowissenschaftler interessieren sich dafür.“ Während induktive Voreingenommenheit bei Objekterkennungsaufgaben leicht zu verstehen ist, wird sie bei abstrakten Problemen wie dem Aufbau sozialer Beziehungen unklar. Auch in Zukunft müssen wir noch viel wissen~~~
Referenzmaterialien:
https://thenextweb.com/news/everything-you-need-to-know-about-model-free- und modellbasiertes Verstärkungslernen
Das obige ist der detaillierte Inhalt vonVon Mäusen, die durch das Labyrinth laufen, bis hin zu AlphaGo, das Menschen besiegt, die Entwicklung des verstärkenden Lernens. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 So führen Sie die digitale Signaturüberprüfung mit Debian OpenSSL durch
Apr 13, 2025 am 11:09 AM
So führen Sie die digitale Signaturüberprüfung mit Debian OpenSSL durch
Apr 13, 2025 am 11:09 AM
Unter Verwendung von OpenSSL für die digitale Signaturüberprüfung im Debian -System können Sie folgende Schritte befolgen: Vorbereitung für die Installation von OpenSSL: Stellen Sie sicher, dass Ihr Debian -System OpenSSL installiert hat. Wenn nicht installiert, können Sie den folgenden Befehl verwenden, um es zu installieren: sudoaptupdatesudoaptininTallopenSSL, um den öffentlichen Schlüssel zu erhalten: Die digitale Signaturüberprüfung erfordert den öffentlichen Schlüssel des Unterzeichners. In der Regel wird der öffentliche Schlüssel in Form einer Datei wie Public_key.pe bereitgestellt
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
