
 Technologie-Peripheriegeräte
KI
Die Kernmethode von ChatGPT kann für die KI-Malerei verwendet werden, und der Effekt steigt um 47 %. Korrespondierender Autor: ist auf OpenAI umgestiegen
Technologie-Peripheriegeräte
KI
Die Kernmethode von ChatGPT kann für die KI-Malerei verwendet werden, und der Effekt steigt um 47 %. Korrespondierender Autor: ist auf OpenAI umgestiegen
Die Kernmethode von ChatGPT kann für die KI-Malerei verwendet werden, und der Effekt steigt um 47 %. Korrespondierender Autor: ist auf OpenAI umgestiegen

In ChatGPT gibt es eine solche Kerntrainingsmethode namens „Reinforcement Learning with Human Feedback (RLHF)“.
Es kann das Modell sicherer machen und die Ausgabeergebnisse besser mit den menschlichen Absichten übereinstimmen.
Jetzt haben Forscher von Google Research und der UC Berkeley herausgefunden, dass die Anwendung dieser Methode auf KI-Malerei die Situation „behandeln“ kann, in der das Bild nicht genau mit der Eingabe übereinstimmt, und der Effekt ist überraschend gut –
kann bis zu 47 erreichen % verbessern.

△ Links ist die stabile Diffusion, rechts ist der verbesserte Effekt
Zu diesem Zeitpunkt scheinen die beiden beliebten Modelle im AIGC-Bereich eine Art „Resonanz“ gefunden zu haben.
Wie verwende ich RLHF für KI-Malerei?
RLHF, der vollständige Name lautet „Reinforcement Learning from Human Feedback“, ist eine Reinforcement-Learning-Technologie, die 2017 von OpenAI und DeepMind gemeinsam entwickelt wurde.
Wie der Name schon sagt, nutzt RLHF die menschliche Bewertung der Modellausgabeergebnisse (d. h. Feedback), um das Modell in LLM direkt zu optimieren und so die „Modellwerte“ besser mit den menschlichen Werten in Einklang zu bringen.
Im AI-Bildgenerierungsmodell kann das generierte Bild vollständig an der Textaufforderung ausgerichtet werden.
Erfassen Sie insbesondere zunächst menschliche Feedbackdaten.
Hier haben die Forscher insgesamt mehr als 27.000 „Text-Bild-Paare“ generiert und dann einige Menschen gebeten, diese zu bewerten.
Der Einfachheit halber umfassen Textaufforderungen nur die folgenden vier Kategorien, bezogen auf Menge, Farbe, Hintergrund und Mischoptionen, die nur in „gut“, „schlecht“ und „weiß nicht (überspringen)“ unterteilt sind. ".

Zweitens lernen Sie die Belohnungsfunktion.
Dieser Schritt besteht darin, den gerade erhaltenen Datensatz aus menschlichen Bewertungen zu verwenden, um eine Belohnungsfunktion zu trainieren und diese Funktion dann zu verwenden, um die Zufriedenheit des Menschen mit der Modellausgabe vorherzusagen (roter Teil der Formel).
Auf diese Weise weiß das Modell, wie sehr seine Ergebnisse mit dem Text übereinstimmen.
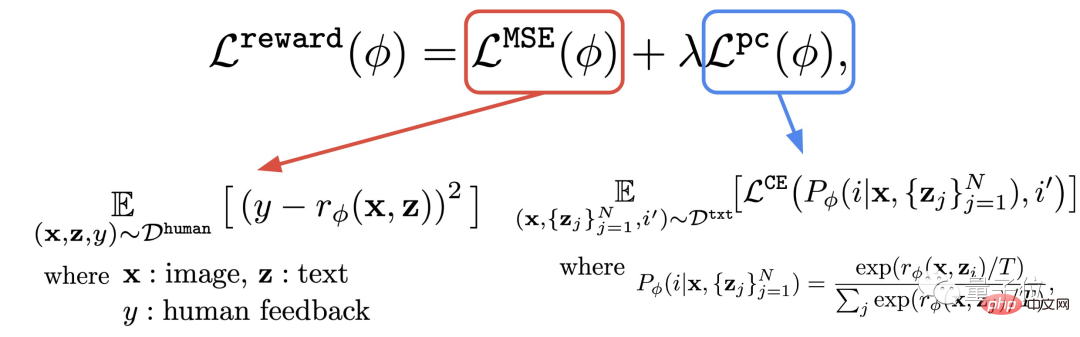
Zusätzlich zur Belohnungsfunktion schlägt der Autor auch eine Hilfsaufgabe vor (blauer Teil der Formel).
Das heißt, nach Abschluss der Bildgenerierung gibt das Modell eine Menge Text aus, von denen jedoch nur einer der Originaltext ist, und lässt das Belohnungsmodell „selbst prüfen“, ob das Bild mit dem Text übereinstimmt.
Dieser umgekehrte Vorgang kann den Effekt einer „doppelten Versicherung“ bewirken (er kann das Verständnis von Schritt 2 im Bild unten erleichtern).
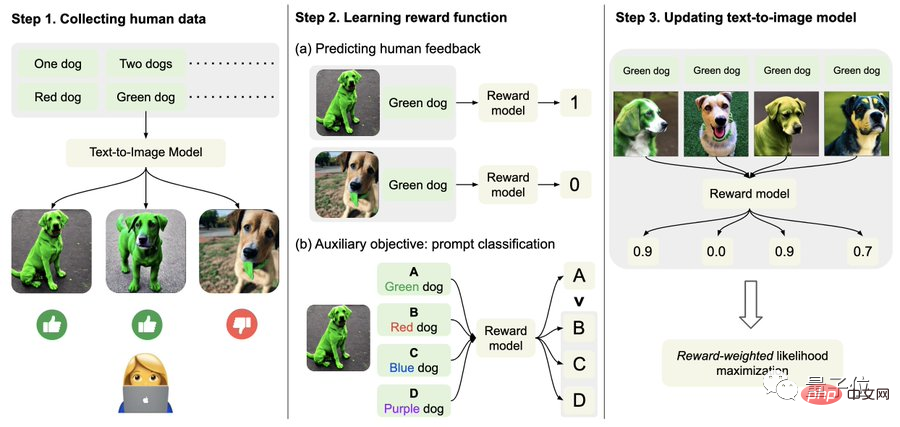
Am Ende geht es um die Feinabstimmung.
Das heißt, das Text-Bild-Generierungsmodell wird durch belohnungsgewichtete Wahrscheinlichkeitsmaximierung aktualisiert (das erste Element der Formel unten).
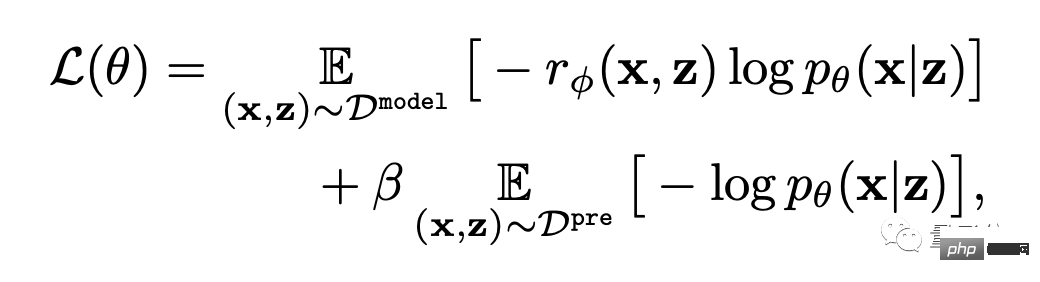
Um eine Überanpassung zu vermeiden, minimierte der Autor den NLL-Wert (den zweiten Term der Formel) im Datensatz vor dem Training. Dieser Ansatz ähnelt InstructionGPT (dem „direkten Vorgänger“ von ChatGPT).
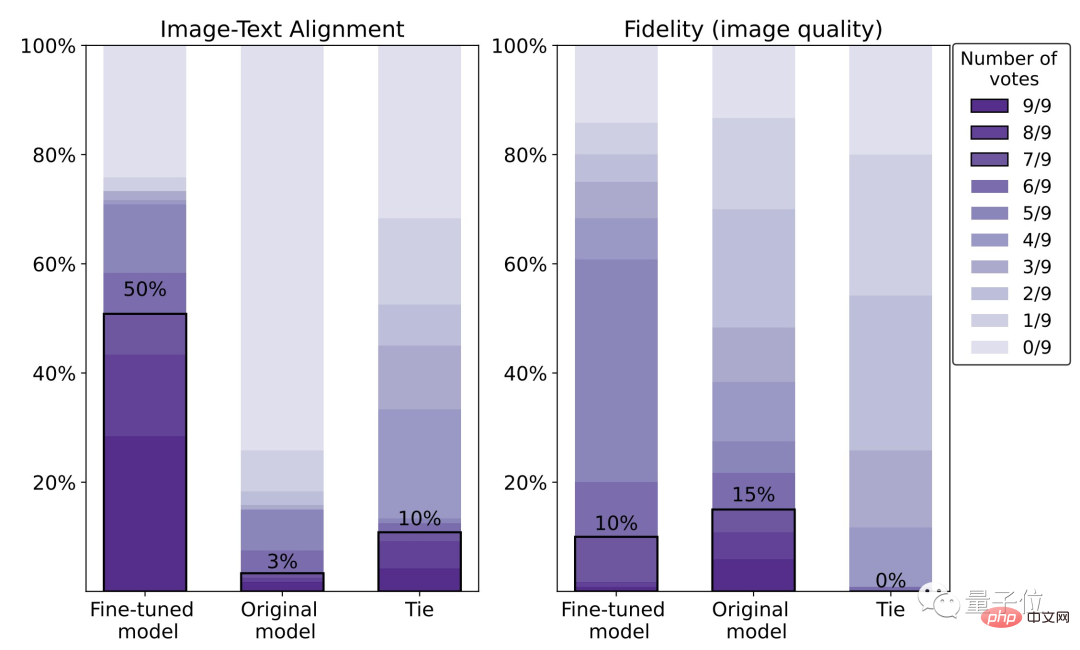
Der Effekt nahm um 47 % zu, aber die Klarheit sank um 5 %
Wie in der folgenden Reihe von Effekten gezeigt, kann das mit RLHF fein abgestimmte Modell im Vergleich zur ursprünglichen Stable Diffusion:
(1) Erhalten Sie die „“ im Text korrekter „Zwei“ und „grün“; es kann zu einem „röteren“ Ergebnis führen.
Den spezifischen Daten zufolge beträgt die menschliche Zufriedenheitsrate des fein abgestimmten Modells 50 %, was einer Verbesserung von 47 % im Vergleich zum Originalmodell (3 %) entspricht.
 Der Preis ist jedoch ein Verlust von 5 % Bildschärfe.
Der Preis ist jedoch ein Verlust von 5 % Bildschärfe.
Auf dem Bild unten können wir auch deutlich erkennen, dass der Wolf auf der rechten Seite offensichtlich unschärfer ist als der auf der linken Seite:
In diesem Zusammenhang gab der Autor an, dass die Verwendung eines größeren menschlichen Bewertungsdatensatzes und Eine bessere Optimierungsmethode (RL) kann diese Situation verbessern.
Über den Autor
 Für diesen Artikel gibt es insgesamt 9 Autoren.
Für diesen Artikel gibt es insgesamt 9 Autoren.

Als Google-KI-Forscherin Kimin Lee, Ph.D. vom Korea Institute of Science and Technology, forschte sie als Postdoktorandin an der UC Berkeley.

Es gibt drei chinesische Autoren:
Liu Hao, ein Doktorand an der UC Berkeley, dessen Hauptforschungsinteresse Feedback-Neuronale Netze sind.
Du Yuqing ist Doktorand an der UC Berkeley. Seine Hauptforschungsrichtung sind unbeaufsichtigte Reinforcement-Learning-Methoden.
Shixiang Shane Gu (Gu Shixiang), der korrespondierende Autor, studierte bei Hinton, einem der drei Giganten, für seinen Bachelor-Abschluss und schloss sein Studium mit der Promotion an der Universität Cambridge ab.

△ Gu Shixiang
Erwähnenswert ist, dass er beim Schreiben dieses Artikels noch Googler war, nun aber zu OpenAI gewechselt ist, wo er direkt dem Verantwortlichen von ChatGPT unterstellt ist.
Papieradresse:
https://arxiv.org/abs/2302.12192
Referenzlink: [1]https://www.php.cn/link/4d42d2f5010c1c13f23492a35645d6a7
[2 ] https://openai.com/blog/instruction-following/
Das obige ist der detaillierte Inhalt vonDie Kernmethode von ChatGPT kann für die KI-Malerei verwendet werden, und der Effekt steigt um 47 %. Korrespondierender Autor: ist auf OpenAI umgestiegen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
Um eine Datentabelle mithilfe von PHPMYADMIN zu erstellen, sind die folgenden Schritte unerlässlich: Stellen Sie eine Verbindung zur Datenbank her und klicken Sie auf die neue Registerkarte. Nennen Sie die Tabelle und wählen Sie die Speichermotor (innoDB empfohlen). Fügen Sie Spaltendetails hinzu, indem Sie auf die Taste der Spalte hinzufügen, einschließlich Spaltenname, Datentyp, ob Nullwerte und andere Eigenschaften zuzulassen. Wählen Sie eine oder mehrere Spalten als Primärschlüssel aus. Klicken Sie auf die Schaltfläche Speichern, um Tabellen und Spalten zu erstellen.
 Wie geht es mit Redis -Speicherfragmentierung um?
Apr 10, 2025 pm 02:24 PM
Wie geht es mit Redis -Speicherfragmentierung um?
Apr 10, 2025 pm 02:24 PM
Redis -Gedächtnisfragmentierung bezieht sich auf die Existenz kleiner freier Bereiche in dem zugewiesenen Gedächtnis, die nicht neu zugewiesen werden können. Zu den Bewältigungsstrategien gehören: Neustart von Redis: Der Gedächtnis vollständig löschen, aber den Service unterbrechen. Datenstrukturen optimieren: Verwenden Sie eine Struktur, die für Redis besser geeignet ist, um die Anzahl der Speicherzuweisungen und -freisetzungen zu verringern. Konfigurationsparameter anpassen: Verwenden Sie die Richtlinie, um die kürzlich verwendeten Schlüsselwertpaare zu beseitigen. Verwenden Sie den Persistenzmechanismus: Daten regelmäßig sichern und Redis neu starten, um Fragmente zu beseitigen. Überwachen Sie die Speicherverwendung: Entdecken Sie die Probleme rechtzeitig und ergreifen Sie Maßnahmen.
 Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Das Erstellen einer Oracle -Datenbank ist nicht einfach, Sie müssen den zugrunde liegenden Mechanismus verstehen. 1. Sie müssen die Konzepte von Datenbank und Oracle DBMS verstehen. 2. Beherrschen Sie die Kernkonzepte wie SID, CDB (Containerdatenbank), PDB (Pluggable -Datenbank); 3.. Verwenden Sie SQL*Plus, um CDB zu erstellen und dann PDB zu erstellen. Sie müssen Parameter wie Größe, Anzahl der Datendateien und Pfade angeben. 4. Erweiterte Anwendungen müssen den Zeichensatz, den Speicher und andere Parameter anpassen und die Leistungsstimmung durchführen. 5. Achten Sie auf Speicherplatz, Berechtigungen und Parametereinstellungen und überwachen und optimieren Sie die Datenbankleistung kontinuierlich. Nur indem Sie es geschickt beherrschen, müssen Sie die Erstellung und Verwaltung von Oracle -Datenbanken wirklich verstehen.
 So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
Um eine Oracle -Datenbank zu erstellen, besteht die gemeinsame Methode darin, das dbca -grafische Tool zu verwenden. Die Schritte sind wie folgt: 1. Verwenden Sie das DBCA -Tool, um den DBNAME festzulegen, um den Datenbanknamen anzugeben. 2. Setzen Sie Syspassword und SystemPassword auf starke Passwörter. 3.. Setzen Sie Charaktere und NationalCharacterset auf AL32UTF8; 4. Setzen Sie MemorySize und tablespacesize, um sie entsprechend den tatsächlichen Bedürfnissen anzupassen. 5. Geben Sie den Logfile -Pfad an. Erweiterte Methoden werden manuell mit SQL -Befehlen erstellt, sind jedoch komplexer und anfällig für Fehler. Achten Sie auf die Kennwortstärke, die Auswahl der Zeichensatz, die Größe und den Speicher von Tabellenräumen
 Überwachen Sie Redis Tröpfchen mit Redis Exporteur Service
Apr 10, 2025 pm 01:36 PM
Überwachen Sie Redis Tröpfchen mit Redis Exporteur Service
Apr 10, 2025 pm 01:36 PM
Eine effektive Überwachung von Redis -Datenbanken ist entscheidend für die Aufrechterhaltung einer optimalen Leistung, die Identifizierung potenzieller Engpässe und die Gewährleistung der Zuverlässigkeit des Gesamtsystems. Redis Exporteur Service ist ein leistungsstarkes Dienstprogramm zur Überwachung von Redis -Datenbanken mithilfe von Prometheus. In diesem Tutorial führt Sie die vollständige Setup und Konfiguration des Redis -Exporteur -Dienstes, um sicherzustellen, dass Sie nahtlos Überwachungslösungen erstellen. Durch das Studium dieses Tutorials erhalten Sie voll funktionsfähige Überwachungseinstellungen
 Was sind die Redis -Speicherkonfigurationsparameter?
Apr 10, 2025 pm 02:03 PM
Was sind die Redis -Speicherkonfigurationsparameter?
Apr 10, 2025 pm 02:03 PM
** Der Kernparameter der Redis -Speicherkonfiguration ist MaxMemory, der die Menge an Speicher einschränkt, die Redis verwenden kann. Wenn diese Grenze überschritten wird, führt Redis eine Eliminierungsstrategie gemäß MaxMemory-Policy durch, einschließlich: Noeviction (direkt abgelehnt), Allkeys-LRU/Volatile-LRU (eliminiert von LRU), Allkeys-Random/Volatile-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random (eliminiert) und volatile TTL (eliminierte Zeit). Andere verwandte Parameter umfassen MaxMemory-Samples (LRU-Probenmenge), RDB-Kompression
 So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
Der Kern von Oracle SQL -Anweisungen ist ausgewählt, einfügen, aktualisiert und löschen sowie die flexible Anwendung verschiedener Klauseln. Es ist wichtig, den Ausführungsmechanismus hinter der Aussage wie die Indexoptimierung zu verstehen. Zu den erweiterten Verwendungen gehören Unterabfragen, Verbindungsabfragen, Analysefunktionen und PL/SQL. Häufige Fehler sind Syntaxfehler, Leistungsprobleme und Datenkonsistenzprobleme. Best Practices für Leistungsoptimierung umfassen die Verwendung geeigneter Indizes, die Vermeidung von Auswahl *, optimieren Sie, wo Klauseln und gebundene Variablen verwenden. Das Beherrschen von Oracle SQL erfordert Übung, einschließlich des Schreibens von Code, Debuggen, Denken und Verständnis der zugrunde liegenden Mechanismen.
 Was ist der Redis Memory Management -Mechanismus?
Apr 10, 2025 pm 01:39 PM
Was ist der Redis Memory Management -Mechanismus?
Apr 10, 2025 pm 01:39 PM
REDIS nimmt einen mechanischen Mechanismus zur Verwaltung von Granulargedächtnissen an, darunter: Eine gut gestaltete Speicher-freundliche Datenstruktur, ein Multi-Memory-Allocator, der Allokationsstrategien für verschiedene Größen von Speicherblöcken optimiert, ein Speicher-Elimination-Mechanismus, der eine Eliminierungsstrategie ausgewählt, die auf bestimmten Anforderungen basiert, und Tools zur Überwachungsverwendung. Das Ziel dieses Mechanismus ist es, die endgültige Leistung durch feine Kontrolle und effiziente Verwendung des Speichers zu erzielen, die Gedächtnisfragmentierung zu minimieren und die Zugangseffizienz zu verbessern, um sicherzustellen, dass Redis in verschiedenen Szenarien stabil und effizient ausgeführt wird.
