

Eines der wichtigen Merkmale groß angelegter vorab trainierter Sprachmodelle ist die Fähigkeit zum In-Context-Lernen (ICL), das heißt, durch einige beispielhafte Eingabe-Label-Paare können neue Eingabe-Label gelernt werden, ohne Parameter zu aktualisieren .
Obwohl sich die Leistung verbessert hat, ist die Frage, woher die ICL-Fähigkeit großer Modelle kommt, immer noch offen.
Um besser zu verstehen, wie ICL funktioniert, haben Forscher der Tsinghua-Universität, der Peking-Universität und Microsoft gemeinsam einen Artikel veröffentlicht, der Sprachmodelle als Meta-Optimierer (Meta-Optimierer) interpretiert und ICL als implizite Feinabstimmung versteht.

Link zum Papier: https://arxiv.org/abs/2212.10559 Form), und auf dieser Grundlage ist das Verständnis von ICL wie folgt. GPT generiert zunächst Metagradienten basierend auf Demonstrationsinstanzen und wendet diese Metagradienten dann auf das ursprüngliche GPT an, um ein ICL-Modell zu erstellen.
In Experimenten verglichen die Forscher umfassend das Verhalten von ICL und expliziter Feinabstimmung anhand realer Aufgaben, um empirische Beweise zu liefern, die dieses Verständnis stützen.
Die Ergebnisse belegen, dass ICL eine ähnliche Leistung erbringt wie die explizite Feinabstimmung auf der Ebene der Vorhersage, der Darstellung und des Aufmerksamkeitsverhaltens.
Darüber hinaus wurde in dem Artikel, inspiriert vom Verständnis der Metaoptimierung, durch die Analogie zum impulsbasierten Gradientenabstiegsalgorithmus auch eine impulsbasierte Aufmerksamkeit entworfen, die eine bessere Leistung als gewöhnliche Aufmerksamkeit von einem anderen aufweist Ein Aspekt bestätigt erneut die Richtigkeit dieses Verständnisses und zeigt auch das Potenzial auf, dieses Verständnis für die weitere Gestaltung des Modells zu nutzen.
Prinzip von ICLDie Forscher führten zunächst eine qualitative Analyse des linearen Aufmerksamkeitsmechanismus in Transformer durch, um die duale Form zwischen ihm und der auf dem Gradientenabstieg basierenden Optimierung herauszufinden. Anschließend wird ICL mit expliziter Feinabstimmung verglichen und eine Verbindung zwischen diesen beiden Optimierungsformen hergestellt.
Transformer-Aufmerksamkeit ist Metaoptimierung
Angenommen, X ist die Eingabedarstellung der gesamten Abfrage, X' ist die Darstellung des Beispiels, q ist der Abfragevektor, dann ist unter der ICL-Einstellung die Aufmerksamkeit eines Kopfes im Modell Die Ergebnisse sind wie folgt:
Es ist ersichtlich, dass nach Entfernen des Skalierungsfaktors Wurzel d und Softmax der Standard-Aufmerksamkeitsmechanismus wie folgt angenähert werden kann:
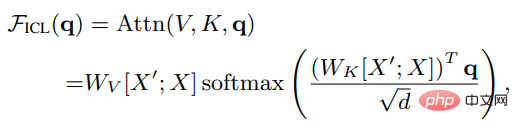
Wenn Sie Wzsl auf Zero-Shot Learning (ZSL) setzen, kann die Transformer-Aufmerksamkeit in die folgende Doppelform umgewandelt werden:
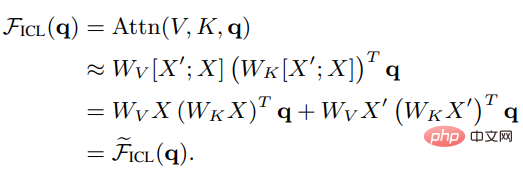
Es ist ersichtlich, dass ICL als Metaoptimierungsprozess interpretiert werden kann:
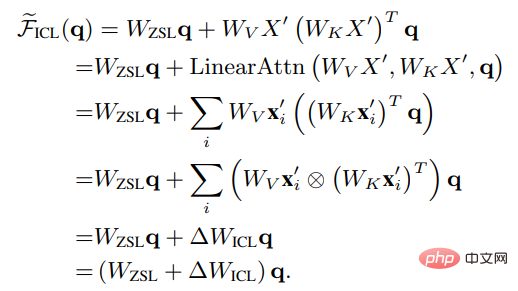
1. Verwenden Sie das auf Transformer basierende vorab trainierte Sprachmodell
2 Berechnen Sie den Metagradienten gemäß dem Demonstrationsbeispiel
3 das Original durch den Aufmerksamkeitsmechanismus Erstellen Sie auf dem Sprachmodell ein ICL-Modell.
Vergleich zwischen ICL und FeinabstimmungUm die Metaoptimierung und die explizite Optimierung von ICL zu vergleichen, haben die Forscher eine spezifische Feinabstimmungseinstellung als Basis für den Vergleich entworfen: unter Berücksichtigung der Tatsache, dass ICL nur direkt auf die Schlüssel und Wert der Aufmerksamkeit, daher aktualisiert die Feinabstimmung nur die Parameter der Schlüssel- und Wertprojektionen.
Ähnlich in der nicht strengen Form der linearen Aufmerksamkeit können die Ergebnisse der Kopfaufmerksamkeit nach der Feinabstimmung wie folgt ausgedrückt werden:
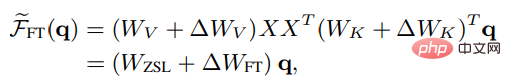
Um einen faireren Vergleich mit ICL zu ermöglichen, sind die Feinabstimmungseinstellungen wie folgt im Experiment weiter eingeschränkt
1. Geben Sie die Trainingsbeispiele als Demonstrationsbeispiele für ICL an
2. Führen Sie für jedes Beispiel nur einen Trainingsschritt durch Reihenfolge von ICL;
3. Jedes Trainingsbeispiel wird mit der von ICL verwendeten Vorlage formatiert und mithilfe des kausalen Sprachmodellierungsziels verfeinert.
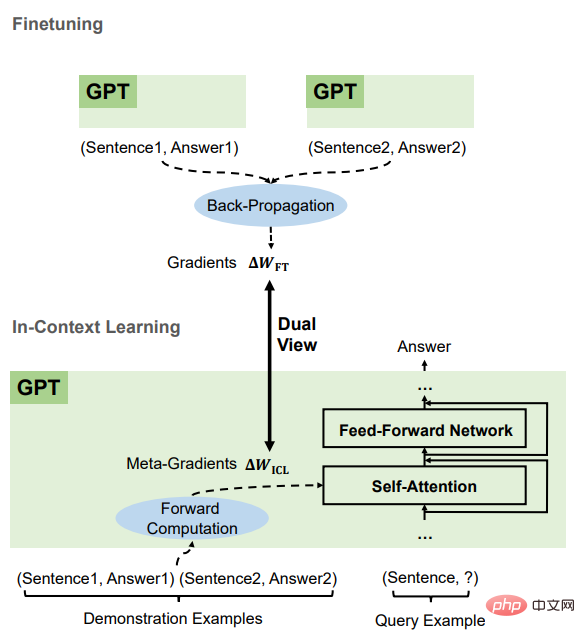
Nach dem Vergleich können wir feststellen, dass ICL und Feinabstimmung viele gemeinsame Attribute haben, darunter hauptsächlich vier Aspekte.
sind alle Gradientenabstieg
Es kann festgestellt werden, dass sowohl ICL als auch die Feinabstimmung Wzsl aktualisiert haben, dh der Gradientenabstieg. Der einzige Unterschied besteht darin, dass ICL Metagradienten durch Vorwärtsberechnung generiert , während die Feinabstimmung durch umgekehrte Berechnungsausbreitung erfolgt, um den wahren Gradienten zu erhalten.
Die gleichen Trainingsinformationen
Der Metagradient von ICL wird basierend auf dem Demonstrationsbeispiel erhalten, und der Gradient der Feinabstimmung wird ebenfalls aus demselben Trainingsbeispiel, nämlich ICL, erhalten und Feinabstimmung verwenden dieselben Quellen für Trainingsinformationen.
Die kausale Reihenfolge der Trainingsbeispiele ist die gleiche
ICL und die Feinabstimmung teilen sich die kausale Reihenfolge der Trainingsbeispiele, sodass ICL nur Decoder verwendet, sodass nachfolgende Token im Beispiel dies tun Da die Reihenfolge der Trainingsbeispiele dieselbe ist und nur eine Epoche trainiert wird, kann sichergestellt werden, dass nachfolgende Proben keinen Einfluss auf vorherige Proben haben.
Beide wirken sich auf die Aufmerksamkeit aus.
Im Vergleich zum Zero-Shot-Lernen beschränkt sich der direkte Einfluss von ICL und Feinabstimmung auf die Berechnung von Schlüssel und Wert der Aufmerksamkeit. Für ICL bleiben die Modellparameter unverändert und die Beispielinformationen werden in zusätzliche Schlüssel und Werte codiert, um das Aufmerksamkeitsverhalten zu ändern. Aufgrund der bei der Feinabstimmung eingeführten Einschränkungen können die Trainingsinformationen nur die Projektion der Aufmerksamkeitsschlüssel beeinflussen Werte in der Matrix.
Basierend auf diesen gemeinsamen Merkmalen zwischen ICL und Feinabstimmung glauben die Forscher, dass es vernünftig ist, ICL als eine Art implizite Feinabstimmung zu verstehen.
Experimenteller TeilAufgaben und Datensätze
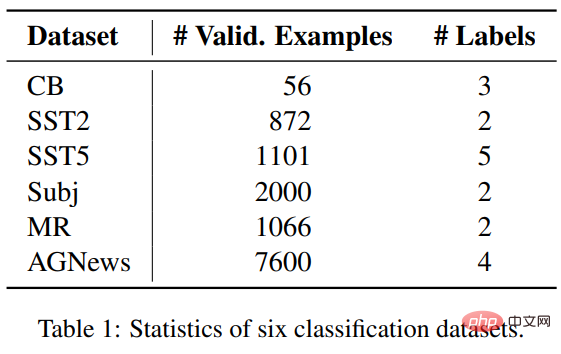
Die Forscher wählten sechs Datensätze aus drei Klassifizierungsaufgaben aus, um ICL und Feinabstimmung zu vergleichen, darunter SST2, SST-5, MR und Subj. Das sind vier Datensätze wird für die Stimmungsklassifizierung verwendet; AGNews ist ein Themenklassifizierungsdatensatz; CB wird für die Argumentation in natürlicher Sprache verwendet.
Experimentelle Einstellungen
Der Modellteil verwendet zwei vorab trainierte Sprachmodelle ähnlich GPT, veröffentlicht von fairseq, mit Parametermengen von 1,3 B bzw. 2,7 B.
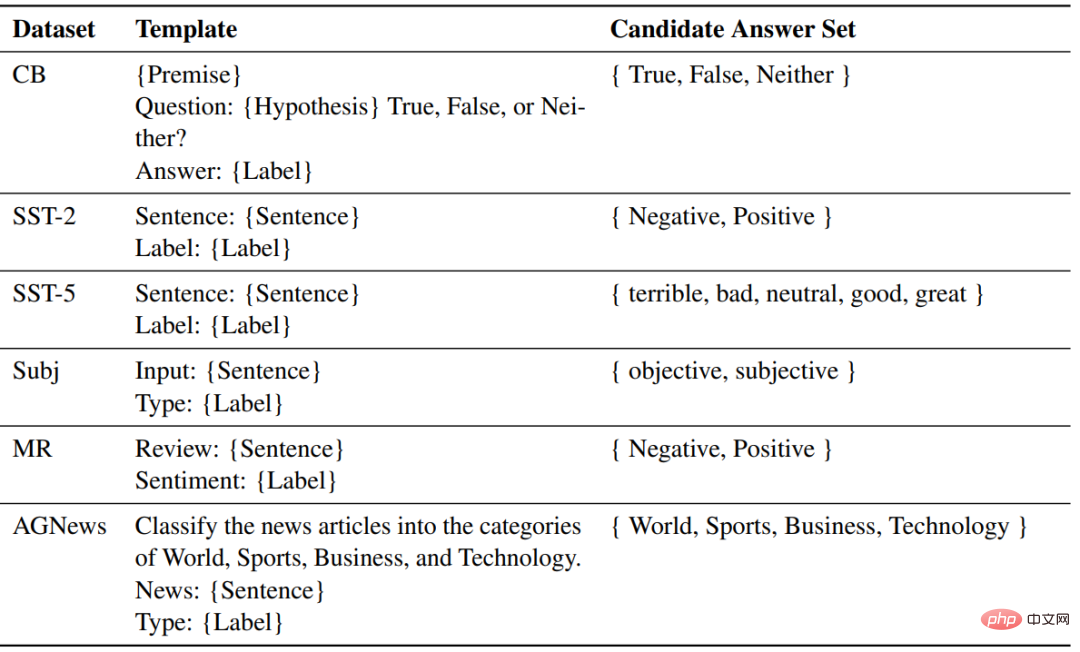
Verwenden Sie für jede Aufgabe dieselbe Vorlage, um Beispiele für ZSL, ICL und Feinabstimmung zu formatieren.
Ergebnisse
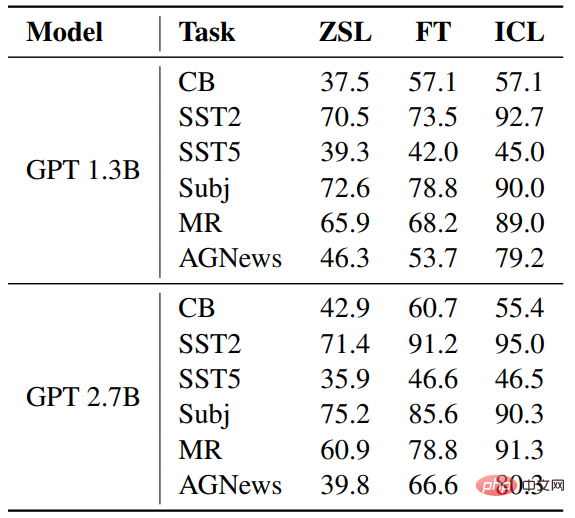
Genauigkeit
Im Vergleich zu ZSL wurden sowohl bei ICL als auch bei der Feinabstimmung erhebliche Verbesserungen erzielt, was bedeutet, dass ihre Optimierung diese nachgelagerten Aufgaben unterstützt. Darüber hinaus ist ICL in einigen Fällen besser als eine Feinabstimmung.
Rec2FTP (Recall to Finetuning Predictions)
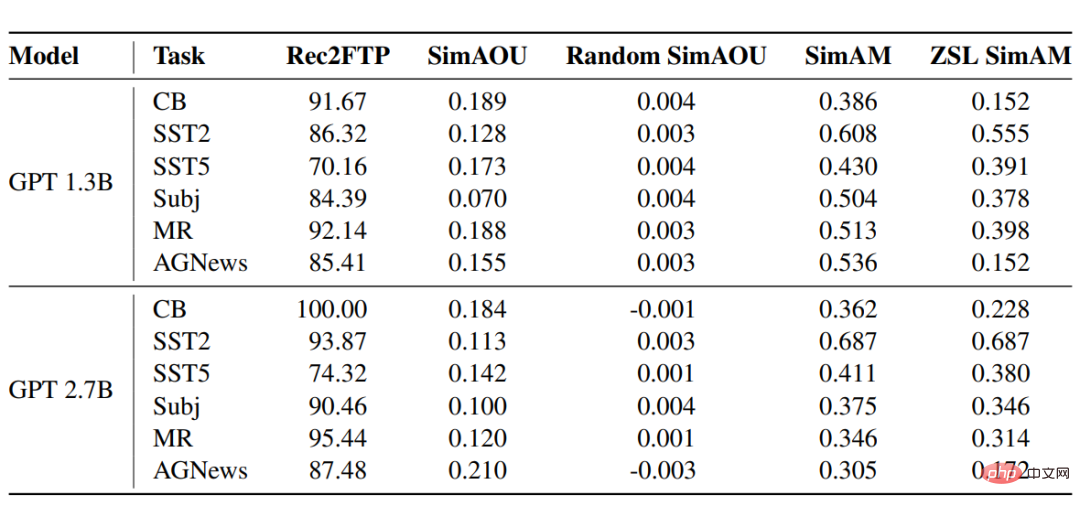
Die Score-Ergebnisse des GPT-Modells für sechs Datensätze zeigen, dass ICL im Durchschnitt 87,64 % der Beispiele korrekt vorhersagen kann, während dies in Ordnung ist -Tuning kann ZSL korrigieren. Auf der Vorhersageebene kann ICL die meisten korrekten Verhaltensweisen zur Feinabstimmung abdecken.
SimAOU (Ähnlichkeit von Aufmerksamkeitsausgabeaktualisierungen)
Aus den Ergebnissen geht hervor, dass die Ähnlichkeit zwischen ICL-Aktualisierungen und Feinabstimmungsaktualisierungen viel höher ist als bei zufälligen Aktualisierungen, was auch bei der Darstellung bedeutet Auf dieser Ebene tendiert ICL dazu, Veränderungen der Aufmerksamkeitsergebnisse in die gleiche Richtung wie Nudge-Änderungen zu bringen.
SimAM (Ähnlichkeit der Aufmerksamkeitskarte)
Als Basismetrik von SimAM berechnet ZSL SimAM die Ähnlichkeit zwischen ICL-Aufmerksamkeitsgewichten und ZSL-Aufmerksamkeitsgewichten. Durch den Vergleich dieser beiden Metriken kann beobachtet werden, dass ICL im Vergleich zu ZSL tendenziell ähnliche Aufmerksamkeitsgewichte erzeugt wie die Feinabstimmung.
Auch auf der Ebene des Aufmerksamkeitsverhaltens belegen experimentelle Ergebnisse, dass sich ICL ähnlich wie die Feinabstimmung verhält.
Das obige ist der detaillierte Inhalt vonQingbei Microsoft befasst sich intensiv mit GPT und versteht kontextbezogenes Lernen! Es ist im Grunde dasselbe wie die Feinabstimmung, außer dass sich die Parameter nicht geändert haben.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was ist der Unterschied zwischen j2ee und springboot?
Was ist der Unterschied zwischen j2ee und springboot?
 Welche Software ist Zoom?
Welche Software ist Zoom?
 So lösen Sie das Problem, dass localhost nicht geöffnet werden kann
So lösen Sie das Problem, dass localhost nicht geöffnet werden kann
 Verwendung der Instr-Funktion in Oracle
Verwendung der Instr-Funktion in Oracle
 Grenzradius
Grenzradius
 Wie Oracle eine Datenbank erstellt
Wie Oracle eine Datenbank erstellt
 Was sind die neuen Funktionen von es6?
Was sind die neuen Funktionen von es6?
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



