

Welche Methoden der Python-OCR-Texterkennung gibt es?

将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition,OCR)。可以实现OCR 的底层库并不多,目前很多库都是使用共同的几个底层OCR 库,或者是在上面进行定制。
方法一: 使用easyocr模块
easyocr是基于torch的深度学习模块
easyocr安装后调用过程中出现opencv版本不兼容问题,所以放弃此方案。
方法二:通过pytesseract调用tesseract
优点:部署快,轻量级,离线可用,免费
缺点:自带的中文库识别率较低,需要自己建数据进行训练
Tesseract 是一个OCR 库,目前由Google 赞助(Google 也是一家以OCR 和机器学习技术闻名于世的公司)。Tesseract 是目前公认最优秀、最精确的开源OCR 系统。
除了极高的精确度,Tesseract 也具有很高的灵活性。它可以通过训练识别出任何字体(只要这些字体的风格保持不变就可以),也可以识别出任何Unicode 字符。
Tesseract的安装与使用
python 识别图片上的数字,使用pytesseract库从图像中提取文本,而识别引擎采用 tesseract-ocr。
pytesseract是python包装器,它为可执行文件提供了pythonic API。
1、安装必要的包:
pip install pillow pip install pytesseract
2、安装tesseract-ocr的识别引擎
最新版本下载地址: https://github.com/UB-Mannheim/tesseract/wiki
或者更多版本的tesseract下载地址:https://digi.bib.uni-mannheim.de/tesseract/
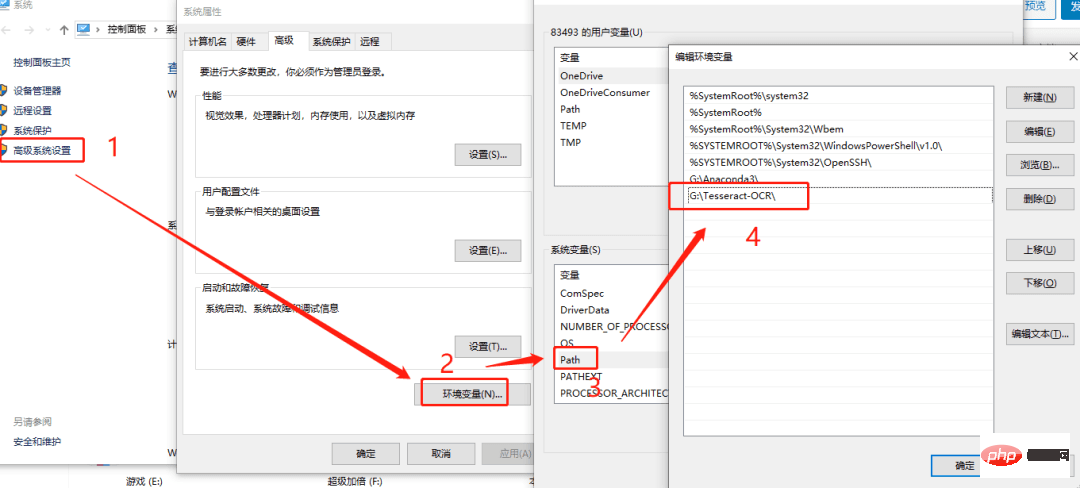
安装完后,需要将Tesseract添加到系统变量中。
环境变量: 我的电脑 ->属性 -> 高级系统设置 ->环境变量 ->系统变量 ,在 path 中添加 安装路径。
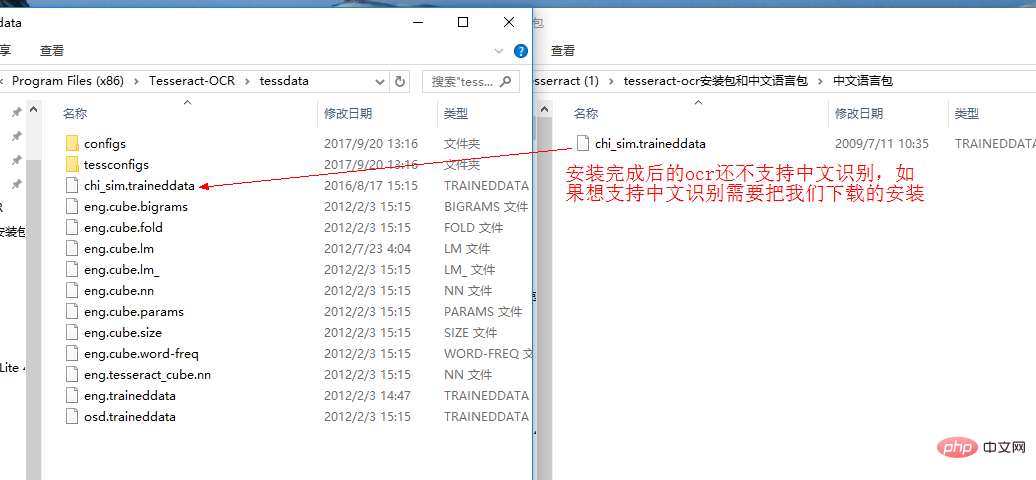
并将训练好的模型文件 chi_sim.traineddata 放入该目录中,这样安装就完成了。
在命令行 WIN+R 输入cmd :输入 tesseract -v ,出现版本信息,则配置成功。

tesseract-ocr默认不支持中文识别。支持中文识别.png
3、解决pytesseract 找不到路径的问题。
在自己安装的pytesseract包中,找到pytesseract.py文件
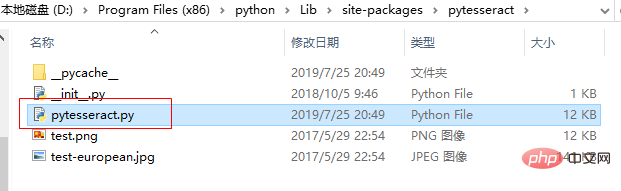
打开pytesseract.py文件,修改 tesseract_cmd 的值:tesseract.exe 的安装路径 。
为了避免其他的错误,使用双反斜杠,或者斜杠
4、简单使用
import pytesseract
from PIL import Image
if __name__ == '__main__':
text = pytesseract.image_to_string(Image.open("D:\\test.png"),lang="eng")
# 如果你想试试Tesseract识别中文,只需要将代码中的eng改为chi_sim即可
print(text)测试图片:
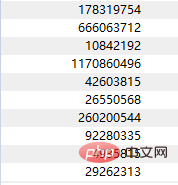
输出结果:
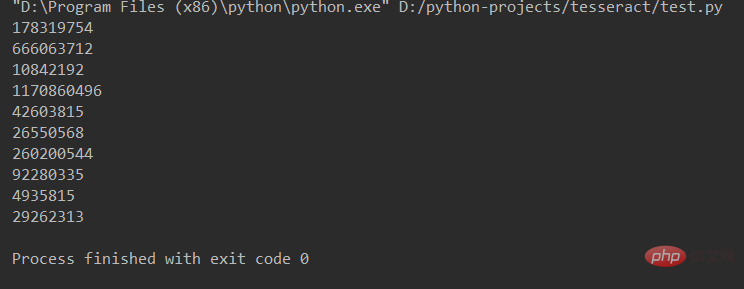
用Tesseract可以识别格式规范的文字,主要具有以下特点:
使用一个标准字体(不包含手写体、草书,或者十分“花哨的”字体)
虽然被复印或拍照,字体还是很清晰,没有多余的痕迹或污点
排列整齐,没有歪歪斜斜的字
没有超出图片范围,也没有残缺不全,或紧紧贴在图片的边缘
下面将给出几个tesseract识别图片中文字的例子。
首先是E://figures/other/poems.jpg, 输入命令 tesseract E://figures/other/poems.jpg E://figures/other/poems.txt, 则会将poems.jpg中的识别文字写入到poems.txt中,如下图:



接着是稍微有点倾斜的文字图片th.jpg,识别情况如下:

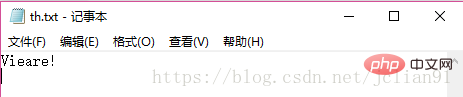
可以看到识别的情况不如刚才规范字体的好,但是也能识别图片中的大部分字母。
最后是识别简体中文,需要事先安装简体中文语言包,再讲chi_sim.traineddata放在C:\Program Files (x86)\Tesseract-OCR\tessdata目录下。我们以图片timg.jpg为例:

输入命令:
tesseract E://figures/other/timg.jpg E://figures/other/timg.txt -l chi_sim
识别结果如下:

只识别错了一个字,识别率还是不错的。
最后加一句,Tesseract对于彩色图片的识别效果没有黑白图片的效果好。
pytesseract
pytesseract是Tesseract关于Python的接口,可以使用pip install pytesseract安装。安装完后,就可以使用Python调用Tesseract了,不过,你还需要一个Python的图片处理模块,可以安装pillow.
输入以下代码,可以实现同上述Tesseract命令一样的效果:
import pytesseract from PIL import Image pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe' text = pytesseract.image_to_string(Image.open('E://figures/other/poems.jpg')) print(text)
运行结果如下:

cnocr 第二种 Python 开源识别工具的效果
两个工具的使用方法和对比效果。
安装 cnocr:
pip install cnocr
看到 Successfully installed xxx 则说明安装成功。
如果你只想对图片中的中文进行识别,那么 cnocr 是一个不错的选择,你只需要安装 cnocr 包即可。
但如果你想试试其他语言的OCR识别,Tesseract 是更好的选择。
cnocr 识别图片的中文
cnocr 主要针对的是排版简单的印刷体文字图片,如截图图片,扫描件等。目前内置的文字检测和分行模块无法处理复杂的文字排版定位。
尽管它分别提供了单行识别函数和多行识别函数,但在本人实测下,单行识别函数的效果非常糟糕,或者说要求的条件十分苛刻,基本上连截图的文字都识别不出来。
不过多行识别函数还不错,使用该函数识别的代码如下:
from cnocr import CnOcr
ocr = CnOcr()
res = ocr.ocr('test.png')
print("Predicted Chars:", res)用于识别这个图片里的文字:
效果如下:

如果不是很吹毛求疵,这样的效果已经很不错了。
方法三:调用百度API
优点:使用方便,功能强大
缺点:大量使用需要收费
我自己采用的是调用百度API的方式,下面是我的步骤:
注册百度账号,创建OCR应用可以参考其他教程。
购买后使用python调用方法
方式一: 通过urllib直接调用,替换自己的api_key和secret_key即可
# coding=utf-8
import sys
import json
import base64
# 保证兼容python2以及python3
IS_PY3 = sys.version_info.major == 3
if IS_PY3:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
from urllib.parse import quote_plus
else:
import urllib2
from urllib import quote_plus
from urllib2 import urlopen
from urllib2 import Request
from urllib2 import URLError
from urllib import urlencode
# 防止https证书校验不正确
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
API_KEY = 'YsZKG1wha34PlDOPYaIrIIKO'
SECRET_KEY = 'HPRZtdOHrdnnETVsZM2Nx7vbDkMfxrkD'
OCR_URL = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
""" TOKEN start """
TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token'
"""
获取token
"""
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode('utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req, timeout=5)
result_str = f.read()
except URLError as err:
print(err)
if (IS_PY3):
result_str = result_str.decode()
result = json.loads(result_str)
if ('access_token' in result.keys() and 'scope' in result.keys()):
if not 'brain_all_scope' in result['scope'].split(' '):
print ('please ensure has check the ability')
exit()
return result['access_token']
else:
print ('please overwrite the correct API_KEY and SECRET_KEY')
exit()
"""
读取文件
"""
def read_file(image_path):
f = None
try:
f = open(image_path, 'rb')
return f.read()
except:
print('read image file fail')
return None
finally:
if f:
f.close()
"""
调用远程服务
"""
def request(url, data):
req = Request(url, data.encode('utf-8'))
has_error = False
try:
f = urlopen(req)
result_str = f.read()
if (IS_PY3):
result_str = result_str.decode()
return result_str
except URLError as err:
print(err)
if __name__ == '__main__':
# 获取access token
token = fetch_token()
# 拼接通用文字识别高精度url
image_url = OCR_URL + "?access_token=" + token
text = ""
# 读取测试图片
file_content = read_file('test.jpg')
# 调用文字识别服务
result = request(image_url, urlencode({'image': base64.b64encode(file_content)}))
# 解析返回结果
result_json = json.loads(result)
print(result_json)
for words_result in result_json["words_result"]:
text = text + words_result["words"]
# 打印文字
print(text)方式二:通过HTTP-SDK模块进行调用
from aip import AipOcr
APP_ID = '25**9878'
API_KEY = 'VGT8y***EBf2O8xNRxyHrPNr'
SECRET_KEY = 'ckDyzG*****N3t0MTgvyYaKUnSl6fSw'
client = AipOcr(APP_ID,API_KEY,SECRET_KEY)
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('test.jpg')
res = client.basicGeneral(image)
print(res)
#res = client.basicAccurate(image)
#print(res)直接识别屏幕指定区域上的文字
from aip import AipOcr APP_ID = '25**9878' API_KEY = 'VGT8y***EBf2O8xNRxyHrPNr' SECRET_KEY = 'ckDyzG*****N3t0MTgvyYaKUnSl6fSw' client = AipOcr(APP_ID,API_KEY,SECRET_KEY) from io import BytesIO from PIL import ImageGrab out_buffer = BytesIO() img = ImageGrab.grab((100,200,300,400)) img.save(out_buffer,format='PNG') res = client.basicGeneral(out_buffer.getvalue()) print(res)
Das obige ist der detaillierte Inhalt vonWelche Methoden der Python-OCR-Texterkennung gibt es?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Effizientes Training von Pytorch -Modellen auf CentOS -Systemen erfordert Schritte, und dieser Artikel bietet detaillierte Anleitungen. 1.. Es wird empfohlen, YUM oder DNF zu verwenden, um Python 3 und Upgrade PIP zu installieren: Sudoyumupdatepython3 (oder sudodnfupdatepython3), PIP3Install-upgradepip. CUDA und CUDNN (GPU -Beschleunigung): Wenn Sie Nvidiagpu verwenden, müssen Sie Cudatool installieren
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
Bei der Auswahl einer Pytorch -Version unter CentOS müssen die folgenden Schlüsselfaktoren berücksichtigt werden: 1. Cuda -Version Kompatibilität GPU -Unterstützung: Wenn Sie NVIDIA -GPU haben und die GPU -Beschleunigung verwenden möchten, müssen Sie Pytorch auswählen, der die entsprechende CUDA -Version unterstützt. Sie können die CUDA-Version anzeigen, die unterstützt wird, indem Sie den Befehl nvidia-smi ausführen. CPU -Version: Wenn Sie keine GPU haben oder keine GPU verwenden möchten, können Sie eine CPU -Version von Pytorch auswählen. 2. Python Version Pytorch
 So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
Die Installation von CentOS-Installationen erfordert die folgenden Schritte: Installieren von Abhängigkeiten wie Entwicklungstools, PCRE-Devel und OpenSSL-Devel. Laden Sie das Nginx -Quellcode -Paket herunter, entpacken Sie es, kompilieren Sie es und installieren Sie es und geben Sie den Installationspfad als/usr/local/nginx an. Erstellen Sie NGINX -Benutzer und Benutzergruppen und setzen Sie Berechtigungen. Ändern Sie die Konfigurationsdatei nginx.conf und konfigurieren Sie den Hörport und den Domänennamen/die IP -Adresse. Starten Sie den Nginx -Dienst. Häufige Fehler müssen beachtet werden, z. B. Abhängigkeitsprobleme, Portkonflikte und Konfigurationsdateifehler. Die Leistungsoptimierung muss entsprechend der spezifischen Situation angepasst werden, z. B. das Einschalten des Cache und die Anpassung der Anzahl der Arbeitsprozesse.
 So machen Sie Datenvorverarbeitung mit Pytorch auf CentOS
Apr 14, 2025 pm 02:15 PM
So machen Sie Datenvorverarbeitung mit Pytorch auf CentOS
Apr 14, 2025 pm 02:15 PM
Effizient verarbeiten Pytorch-Daten zum CentOS-System, die folgenden Schritte sind erforderlich: Abhängigkeit Installation: Aktualisieren Sie zuerst das System und installieren Sie Python3 und PIP: Sudoyumupdate-Judoyuminstallpython3-Tysudoyuminstallpython3-Pip-y, Download und installieren Sie Cudatoolkit und Cudnn-Model von der NVIDIA-offiziellen Website. Konfiguration der virtuellen Umgebung (empfohlen): Verwenden Sie Conda, um eine neue virtuelle Umgebung zu erstellen und zu aktivieren, zum Beispiel: condacreate-n
